虚拟机的结构
一、类加载子系统
- 核心功能:从文件系统/网络加载Class信息,加载后的类信息会存储到方法区中。
二、内存区域(JVM核心存储区域)
内存区域分为线程共享区域 和线程私有区域两类:
(1)线程共享的内存区域
所有线程可共同访问的内存空间:
-
方法区
- 版本变化:JDK1.7称为"永久区",JDK1.8后替换为元空间(Meta space) ,元空间实际分配在直接内存中。
- 存储内容:类信息、运行时常量池(包含字符串字面量、数字常量,是Class文件常量池的内存映射)。
-
Java堆
- 创建时机:虚拟机启动时建立。
- 存储内容:几乎所有Java对象实例都存于此。
- 特点:是线程共享区域,是与Java应用关联最密切的内存区间。
-
直接内存
- 位置:Java堆外、直接向系统申请的内存区间。
- 优势:访问速度优于Java堆,适合读写频繁的高性能场景。
- 内存限制:不受
Xmx指定的最大堆大小限制,但"Java堆+直接内存"的总和受操作系统最大内存限制。
(2)线程私有的内存区域
每个线程独立拥有的内存空间:
-
虚拟机栈(Java栈/线程栈)
- 创建时机:线程创建时同步创建。
- 存储内容:局部变量、方法参数,同时保存帧信息,与Java方法的调用、返回密切相关。
-
本地方法栈
- 功能:与虚拟机栈类似,但用于**本地方法(通常为C编写)**的调用。
-
PC寄存器(程序计数器)
- 创建时机:线程创建时同步创建。
- 功能:记录当前线程正在执行的"当前方法"的执行位置。
三、垃圾回收系统
- 回收范围:可回收方法区、Java堆、直接内存。
- 工作重点:以Java堆为核心回收区域。
四、执行引擎
- 核心功能:负责执行虚拟机的字节码。
- 优化方式:通过即时编译技术,将方法编译为机器码后再执行,提升运行效率。
Java虚拟机(JVM)参数设置
一、JVM参数的分类
根据规范和稳定性,HotSpot的JVM参数分为三类,格式和用途差异如下:
| 类型 | 前缀 | 特点 | 示例 |
|---|---|---|---|
| 标准参数 | - |
所有JVM实现都支持,稳定且向后兼容 | -version、-cp |
| 非标准参数 | -X |
HotSpot特有,相对稳定,主要用于内存配置 | -Xmx32m、-Xms16m |
| 高级调优参数 | -XX |
HotSpot特有,不稳定(版本可能变更),细粒度调优 | -XX:+UseG1GC、-XX:MetaspaceSize=128m |
注:
-XX参数细分:
- 布尔型:
-XX:+<选项>(启用)、-XX:-<选项>(禁用),如-XX:+UseParallelGC;- 数值型:
-XX:<选项>=<数值>,如-XX:MaxHeapSize=512m;- 字符串型:
-XX:<选项>=<字符串>,如-XX:HeapDumpPath=/tmp/heapdump.hprof。
二、核心参数详解
按JVM内存结构和功能维度分类,覆盖最常用的调优/配置参数:
1. 堆内存参数(核心,对应Java堆)
Java堆是对象实例的主要存储区域,参数控制堆的初始/最大大小、新生代/老年代比例等。
| 参数 | 含义 | 示例 |
|---|---|---|
-Xms<size> |
堆初始大小(等价于-XX:InitialHeapSize),建议与-Xmx设为相同值避免动态扩容 |
-Xms256m(初始堆256MB) |
-Xmx<size> |
堆最大可用大小(等价于-XX:MaxHeapSize),是最常用的堆配置参数 |
-Xmx1024m(最大堆1GB) |
-Xmn<size> |
新生代堆大小(Eden+Survivor区),直接指定新生代大小,优先级高于NewRatio |
-Xmn512m(新生代512MB) |
-XX:NewRatio=<n> |
老年代/新生代的比例(老年代大小 = 新生代大小 × n),默认值为2 |
-XX:NewRatio=3(老年代:新生代=3:1) |
-XX:SurvivorRatio=<n> |
Eden区/单个Survivor区的比例(Survivor区有2个:From/To),默认值为8 | -XX:SurvivorRatio=8(Eden:From:To=8:1:1) |
-XX:MaxTenuringThreshold=<n> |
对象进入老年代的年龄阈值(经历Minor GC的次数),默认15 | -XX:MaxTenuringThreshold=10 |
单位说明:
size支持k/K(KB)、m/M(MB)、g/G(GB),如-Xmx512k、-Xmx2G。
2. 方法区/元空间参数(对应方法区)
方法区存储类信息、常量池等,JDK版本差异导致参数不同:
- JDK1.7及之前:方法区称为"永久代",用
PermSize相关参数; - JDK1.8及之后:永久代被元空间(MetaSpace)替代,元空间分配在直接内存中,用
MetaspaceSize相关参数。
| 参数 | 适用版本 | 含义 | 示例 |
|---|---|---|---|
-XX:PermSize=<size> |
JDK1.7及之前 | 永久代初始大小 | -XX:PermSize=64m |
-XX:MaxPermSize=<size> |
JDK1.7及之前 | 永久代最大大小(避免OOM: PermGen Space) | -XX:MaxPermSize=128m |
-XX:MetaspaceSize=<size> |
JDK1.8及之后 | 元空间初始大小(达到该值触发Full GC) | -XX:MetaspaceSize=128m |
-XX:MaxMetaspaceSize=<size> |
JDK1.8及之后 | 元空间最大大小(默认无上限,建议指定避免占满直接内存) | -XX:MaxMetaspaceSize=256m |
3. 栈内存参数(虚拟机栈/本地方法栈)
栈为线程私有,存储局部变量、方法调用帧,参数控制单个栈的大小:
| 参数 | 含义 | 示例 |
|---|---|---|
-Xss<size> |
单个线程的虚拟机栈大小(等价于-XX:ThreadStackSize),JDK5+默认1MB |
-Xss1m(每个线程栈1MB) |
-XX:NativeStackSize=<size> |
本地方法栈大小(极少调整) | -XX:NativeStackSize=512k |
注意:栈过大会导致创建线程数减少(总内存=堆+栈×线程数+其他),过小会触发
StackOverflowError。
4. 直接内存参数
直接内存(堆外内存)不受-Xmx限制,但可通过参数控制最大值:
| 参数 | 含义 | 示例 |
|---|---|---|
-XX:MaxDirectMemorySize=<size> |
直接内存最大大小(默认等于-Xmx) |
-XX:MaxDirectMemorySize=512m |
5. 垃圾回收(GC)相关参数
控制GC算法、GC日志、回收策略等,是性能调优的核心:
(1)指定GC收集器
| 参数 | 含义 | 适用场景 |
|---|---|---|
-XX:+UseSerialGC |
启用串行GC(新生代Serial + 老年代Serial Old),单线程回收 | 单核、小内存应用(如嵌入式) |
-XX:+UseParallelGC |
启用并行GC(新生代Parallel Scavenge + 老年代Serial Old),多线程回收 | 多核、后台计算型应用 |
-XX:+UseParallelOldGC |
启用并行老年代GC(新生代Parallel Scavenge + 老年代Parallel Old) | 多核、高吞吐量场景 |
-XX:+UseConcMarkSweepGC |
启用CMS GC(新生代ParNew + 老年代CMS),低延迟优先 | 响应时间敏感的应用(如Web) |
-XX:+UseG1GC |
启用G1 GC(区域化分代式GC),兼顾吞吐量和延迟 | 大内存、多核应用(JDK9默认) |
-XX:+UseZGC |
启用ZGC(低延迟GC),JDK11+支持 | 超低延迟、大内存场景 |
(2)GC日志参数(故障排查必备)
| 参数 | 含义 |
|---|---|
-XX:+PrintGCDetails |
打印GC详细日志(包括回收前后内存大小、耗时等) |
-XX:+PrintGCTimeStamps |
打印GC发生的时间戳(相对于JVM启动) |
-XX:+PrintGCDateStamps |
打印GC发生的具体日期时间(如2025-12-29T19:56:46) |
-Xloggc:<file> |
将GC日志输出到指定文件(替代标准输出) |
-XX:+HeapDumpOnOutOfMemoryError |
OOM时自动生成堆转储文件(hprof),用于分析内存泄漏 |
-XX:HeapDumpPath=<path> |
指定堆转储文件的路径和文件名 |
示例:-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/tmp/gc.log
6. 诊断与调优辅助参数
| 参数 | 含义 |
|---|---|
-XX:+PrintCommandLineFlags |
打印JVM启动时生效的所有参数(包括默认参数) |
-XX:+UnlockExperimentalVMOptions |
解锁实验性参数(如ZGC、Shenandoah GC需要) |
-XX:+UnlockDiagnosticVMOptions |
解锁诊断性参数(用于深度调优/排查) |
-verbose:class |
打印类加载/卸载的详细日志(排查类加载问题) |
-verbose:gc |
打印简易GC日志(基础版,不如PrintGCDetails详细) |
7. 标准参数(通用)
所有JVM都支持的基础参数,用于指定类路径、主类、参数传递等:
| 参数 | 含义 | 示例 |
|---|---|---|
-version |
打印JVM版本信息并退出 | java -version |
-cp/-classpath <路径> |
指定类加载路径(多个路径用;(Windows)/:(Linux)分隔) |
-cp ./lib/*:./classes |
-D<key>=<value> |
设置系统属性(可通过System.getProperty(key)获取) |
-Duser.timezone=GMT+8 |
三、参数使用示例
1. 基础示例(结合用户提供的SimpleArgs类)
用户示例中核心是区分JVM参数 和main函数参数:
bash
# 命令格式:java [JVM参数] 主类名 [main函数参数]
java -Xmx32m SimpleArgs a-Xmx32m:JVM参数,设置堆最大为32MB(生效后Runtime.getRuntime().maxMemory()返回约32MB);a:main函数参数,会被args数组接收,输出"参数1:a"。
2. 生产环境典型配置(Web应用,如Spring Boot)
bash
java -Xms2G -Xmx2G -Xmn1G \
-XX:SurvivorRatio=8 \
-XX:+UseG1GC \
-XX:MaxMetaspaceSize=256m \
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/tmp/app-gc.log \
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/oom.hprof \
-Dspring.profiles.active=prod \
-cp ./app.jar com.example.Application参数说明:
- 堆初始/最大2GB,新生代1GB,Eden:Survivor=8:1;
- 启用G1 GC,元空间最大256MB;
- 输出GC日志到指定文件,OOM时自动生成堆转储文件;
- 设置系统属性指定生产环境配置,指定主类启动。
四、参数生效验证
启动Java程序后,可通过以下方式验证参数是否生效:
1. 代码验证(如用户示例)
通过Runtime类获取堆信息:
java
// 获取最大堆内存(对应-Xmx)
long maxHeap = Runtime.getRuntime().maxMemory() / 1024 / 1024;
System.out.println("最大堆内存:" + maxHeap + "MB");
// 获取初始堆内存(对应-Xms)
long initHeap = Runtime.getRuntime().totalMemory() / 1024 / 1024;
System.out.println("初始堆内存:" + initHeap + "MB");2. 命令行验证
(1)查看JVM进程参数(Linux/macOS)
bash
# 查找Java进程ID
jps -l
# 查看进程的JVM参数(替换<pid>为进程ID)
jinfo -flags <pid>输出示例(关键片段):
VM Flags:
-XX:InitialHeapSize=2147483648 (-Xms2G)
-XX:MaxHeapSize=2147483648 (-Xmx2G)
-XX:MaxMetaspaceSize=268435456 (-XX:MaxMetaspaceSize=256m)
-XX:+UseG1GC(2)查看堆内存详情(jmap)
bash
jmap -heap <pid>可查看堆的分代大小、GC收集器、Survivor比例等实际配置。
五、注意事项
- 参数一致性 :
-Xms建议等于-Xmx,避免JVM运行时动态调整堆大小(消耗性能); - 版本兼容性 :JDK1.8+不再支持
PermSize,误用会报错,需替换为MetaspaceSize; - 调优原则:先监控(如通过JVisualVM、Arthas),再调优,避免盲目修改参数;
- 内存总和限制:堆+栈+元空间+直接内存的总和不能超过操作系统可用内存,否则会OOM或进程被杀死。
Java堆(Java Heap)
一、Java堆的核心特征
Java堆是JVM规范中明确的核心内存区域,具备以下关键属性:
| 特征 | 说明 |
|---|---|
| 线程共享 | 所有Java线程均可访问,是JVM中最大的一块内存空间(可通过-Xmx配置上限) |
| 启动即创建 | 随JVM启动而初始化,销毁随JVM进程结束 |
| 自动内存管理 | 完全由GC机制管理(无需开发者手动分配/释放对象),俗称"GC堆" |
| 对象存储核心区 | 几乎所有Java对象实例、数组都分配在堆中(仅少数例外:如逃逸分析优化后的栈上分配) |
| 内存可动态调整 | 初始大小(-Xms)和最大大小(-Xmx)可配置,默认会根据系统内存动态调整 |
补充:Java堆的物理内存可以是不连续的,但逻辑上是连续的;堆内存不足时会抛出
java.lang.OutOfMemoryError: Java heap space异常。
二、Java堆的内存结构(分代模型)
为了优化GC效率,JVM采用"分代回收"思想将Java堆划分为新生代 和老年代(部分GC收集器如G1会进一步划分为多个"Region",但核心分代逻辑不变),最经典的结构如下:
1. 整体划分(默认比例)
Java堆总空间 = 新生代 + 老年代
默认比例:新生代占1/3,老年代占2/3(可通过`-XX:NewRatio`调整,如`NewRatio=2`表示老年代:新生代=2:1)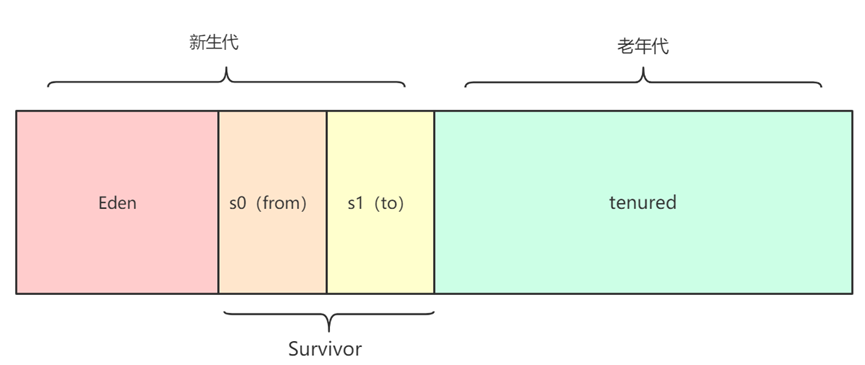
2. 新生代(Young Generation)
新生代是新对象分配的首要区域,特点是对象"朝生夕死"(大部分对象创建后很快变为垃圾),因此GC频率高但回收速度快。新生代又细分为3部分:
- Eden区:对象创建的"首选区域",绝大多数新对象首先分配到Eden区(大对象除外);
- Survivor区 :分为两个大小相等、角色可互换的子区域------
From区(S0)和To区(S1)(也叫s0/s1),用于存放新生代GC后存活的对象; - 默认比例:
Eden : S0 : S1 = 8 : 1 : 1(可通过-XX:SurvivorRatio=<n>调整,如SurvivorRatio=8表示Eden是单个Survivor区的8倍)。
3. 老年代(Old Generation)
老年代用于存放存活时间长的对象(如长期使用的业务缓存、全局对象),特点是对象存活率高,GC频率低但单次回收耗时较长。
三、对象在Java堆中的分配与晋升流程
对象从创建到进入老年代的完整生命周期,是理解Java堆的核心:
步骤1:对象优先分配到Eden区
当执行new Object()(如示例中的new SimpleHeap(1))时,JVM首先在Eden区为对象分配内存(若Eden区空间不足,触发新生代GC(Minor GC))。
步骤2:新生代GC(Minor GC)与Survivor区流转
- Eden区满时触发Minor GC,JVM会标记Eden区中存活的对象;
- 采用复制算法 ,将Eden区存活对象复制到To区(S1),同时清空Eden区和From区(S0);
- 交换From区和To区的角色(原S0变S1,原S1变S0)------ 确保每次Minor GC后,总有一个Survivor区是空的;
- 存活对象的"年龄计数器"+1(年龄代表对象经历的Minor GC次数)。
步骤3:对象晋升到老年代
当Survivor区中的对象年龄达到年龄阈值 (默认15,可通过-XX:MaxTenuringThreshold=<n>调整),会被转移到老年代;
补充:两种特殊情况会直接晋升老年代:
- 大对象(如超大数组):为避免在Survivor区频繁复制,直接分配到老年代(可通过
-XX:PretenureSizeThreshold指定阈值);- Survivor区相同年龄的对象总和超过Survivor区50%:年龄≥该年龄的对象直接晋升老年代。
步骤4:老年代GC(Major GC/Full GC)
老年代空间不足时触发Major GC (仅回收老年代),若Major GC后仍不足则触发Full GC(回收整个Java堆+方法区)------ Full GC耗时极长,应尽量避免。
四、Java堆的垃圾回收机制
Java堆的GC策略与分代结构强绑定,核心算法和特点如下:
| 回收区域 | 核心算法 | 回收类型 | 特点 |
|---|---|---|---|
| 新生代 | 复制算法 | Minor GC | 速度快(仅处理少量存活对象) |
| 老年代 | 标记-清除/标记-整理 | Major GC | 速度慢(对象存活率高) |
| 整个堆 | 混合算法 | Full GC | 耗时最长,业务易卡顿 |
复制算法优势:无内存碎片;劣势:需要预留To区空间(Survivor区)。
标记-整理算法优势:无内存碎片;劣势:需要移动对象,耗时较长。
五、结合示例代码拆解堆、栈、方法区的关联
以你提供的SimpleHeap代码为例,清晰梳理对象、变量在各内存区域的分布:
java
public class SimpleHeap {
private int id; // 实例字段
public SimpleHeap(int id) {this.id = id;} // 构造方法
public void show() {System.out.println("My ID is " + id);} // 实例方法
public static void main(String[] args) {
SimpleHeap s1 = new SimpleHeap(1); // 创建对象1
SimpleHeap s2 = new SimpleHeap(2); // 创建对象2
s1.show();
s2.show();
}
}内存分布拆解:
| 内存区域 | 存储内容 |
|---|---|
| 方法区(元空间) | 1. SimpleHeap类的元信息:类名、父类、访问修饰符、字段(id)、方法(构造方法、show()、main())的字节码; 2. 运行时常量池:字符串常量(如"My ID is ")、类符号引用等。 |
| Java堆(新生代Eden区) | 1. new SimpleHeap(1):完整的对象实例,包含id=1的字段值; 2. new SimpleHeap(2):完整的对象实例,包含id=2的字段值; (注:默认情况下,新对象优先分配到Eden区) |
| 虚拟机栈(main线程栈) | 1. main方法的栈帧中,局部变量s1和s2:存储的是堆中对象的引用地址 (而非对象本身); 2. 调用show()方法时,会创建show()的栈帧,入栈后执行,执行完出栈。 |
执行流程中的内存变化:
- JVM启动后,加载
SimpleHeap类到方法区,初始化Java堆和main线程的虚拟机栈; - 执行
new SimpleHeap(1):在Eden区分配内存创建对象,将对象地址赋值给栈中的s1; - 执行
new SimpleHeap(2):同理,Eden区创建第二个对象,地址赋值给s2; - 执行
s1.show():创建show()栈帧,通过s1的引用找到堆中对象,读取id=1并输出; - 执行
s2.show():同理,读取堆中第二个对象的id=2并输出; - main方法执行完毕,栈帧出栈,若后续无其他引用,两个对象会在Minor GC中被标记为垃圾并清理。
六、Java堆的配置与调优
通过JVM参数可精准控制Java堆的大小和行为,核心参数如下(呼应前文参数设置内容):
| 参数 | 作用 | 示例 |
|---|---|---|
-Xms<size> |
堆初始大小(建议与-Xmx相同,避免动态扩容) |
-Xms2G(初始堆2GB) |
-Xmx<size> |
堆最大大小(核心参数,直接决定堆的上限) | -Xmx4G(最大堆4GB) |
-Xmn<size> |
新生代大小(Eden+S0+S1),优先级高于NewRatio |
-Xmn1G(新生代1GB) |
-XX:NewRatio=<n> |
老年代/新生代比例(如NewRatio=3表示老年代:新生代=3:1) |
-XX:NewRatio=2 |
-XX:SurvivorRatio=<n> |
Eden/单个Survivor区比例(默认8) | -XX:SurvivorRatio=8 |
-XX:MaxTenuringThreshold=<n> |
对象晋升老年代的年龄阈值(默认15) | -XX:MaxTenuringThreshold=10 |
-XX:PretenureSizeThreshold=<size> |
大对象直接进入老年代的阈值(如超过1MB的对象) | -XX:PretenureSizeThreshold=1M |
调优核心原则:
- 优先保证堆大小 :根据业务场景设置
-Xmx,避免堆不足导致OOM; - 新生代调优 :
- 高频创建/销毁对象的业务(如电商接口):增大新生代(如占堆的50%),减少Minor GC次数;
- 新生代过小会导致Minor GC频繁,过大则Full GC耗时增加;
- 年龄阈值调优:短期存活对象多的场景,降低阈值(如设为8),让对象更快晋升老年代;
- 避免大对象:大对象会频繁触发Major GC,尽量拆分或优化存储方式。
七、常见问题与排查
- OOM: Java heap space :堆内存不足,排查方向:
- 检查是否有内存泄漏(如未释放的集合引用);
- 适当调大
-Xmx,或优化对象创建逻辑(如减少大对象、复用对象);
- Minor GC频繁 :新生代过小,调大
-Xmn; - Full GC频繁:老年代空间不足,或新生代对象晋升过快,需调整分代比例或GC收集器(如改用G1)。
总结:Java堆是对象存储的核心,其分代结构是GC效率的关键,理解对象在堆中的分配、流转和回收流程,是JVM调优和故障排查的基础。
Java栈(虚拟机栈)的出入栈(栈帧操作)
一、Java栈的核心特征(出入栈的基础)
理解出入栈前,需先明确Java栈的底层属性,决定了栈帧操作的规则:
| 特征 | 说明 |
|---|---|
| 线程私有 | 每个线程独立拥有一个Java栈,栈帧的出入栈仅影响当前线程,与其他线程隔离 |
| 操作单一性 | 仅支持"入栈(栈帧压入)"和"出栈(栈帧弹出)"两种核心操作,遵循后进先出(LIFO) 原则 |
| 栈帧大小固定 | 单个函数的栈帧大小在编译期确定(局部变量表、操作数栈深度均编译期固定),运行时不可变 |
| 生命周期与线程绑定 | Java栈随线程创建而创建,线程终止时销毁,栈帧也随之全部释放 |
| 异常类型 | 栈空间不足触发StackOverflowError(无OutOfMemoryError,因栈是连续内存且大小固定) |
二、栈帧:Java栈的最小操作单元
栈帧是函数调用的"数据载体",每次函数调用 = 一个栈帧入栈 ,函数执行结束 = 对应栈帧出栈。一个栈帧至少包含以下三个核心区域(JVM规范强制要求):
1. 栈帧的核心组成
| 区域 | 功能 | 与示例的关联(TestStackDeep.recursion) |
|---|---|---|
| 局部变量表 | 存储函数的方法参数 、局部变量,以"变量槽(Slot)"为单位(每个Slot占4字节) | 1. 参数a/b/c占用前3个Slot; 2. 局部变量e/f/g/h/i/k/q/x/y/z占用后续Slot; 3. 所有变量在编译期确定占用的Slot数量 |
| 操作数栈 | 临时存储函数执行的中间运算结果,作为指令执行的"工作台"(基于栈操作) | 执行count++时,先将count的值压入操作数栈,自增后弹出结果写回 |
| 帧数据区 | 存储: ① 常量池引用(解析方法调用/字段访问); ② 异常表(处理try-catch); ③ 返回地址(函数返回后回到调用方的指令位置) | 1. 递归调用recursion(a,b,c)时,通过常量池引用找到该方法; 2. 异常表捕获StackOverflowError; 3. 返回地址记录调用方的下一条指令(若递归正常返回,会回到该位置) |
2. 栈帧的内存占用
栈帧的总大小 = 局部变量表大小 + 操作数栈大小 + 帧数据区大小,单个栈帧越大,Java栈可容纳的栈帧数量越少(调用深度越浅) 。
例如示例中recursion(long a, long b, long c)的栈帧:
long类型占2个Slot →a/b/c + e-z共12个long变量,占用12×2×4=96字节;- 操作数栈+帧数据区约占20~50字节;
- 单个栈帧总大小约120~150字节。
三、Java栈的出入栈完整流程
栈帧的入栈/出栈是JVM执行函数调用的核心逻辑,以下分"正常调用"和"异常终止"两种场景拆解:
1. 栈帧入栈(函数调用时)
当线程执行invokestatic(调用静态方法,如recursion(1,2,3))等指令时,JVM执行以下步骤:
步骤1:合法性校验 → 验证方法参数数量/类型是否匹配(编译期已检查,运行期二次校验)
步骤2:分配栈帧空间 → 从Java栈的"栈底→栈顶"方向,为新栈帧分配内存(需剩余空间足够)
步骤3:初始化栈帧 →
① 填充局部变量表:将方法参数(1/2/3)、局部变量(e=1等)赋值到对应Slot;
② 清空操作数栈:准备接收运算数据;
③ 设置帧数据区:关联常量池、记录返回地址(调用方的PC寄存器值)
步骤4:入栈完成 → 新栈帧成为"当前栈帧"(位于Java栈顶),PC寄存器指向函数第一条指令(如`count++`),开始执行函数体2. 栈帧出栈(函数结束时)
函数结束分"正常返回"和"异常终止"两种情况,最终都会触发栈帧出栈:
(1)正常返回(return指令)
步骤1:处理返回值 → 若函数有返回值,将值压入调用方的操作数栈(示例中recursion无返回值,此步骤跳过)
步骤2:恢复调用方状态 → 将PC寄存器恢复为帧数据区中保存的"返回地址"(回到调用方的下一条指令)
步骤3:栈帧出栈 → 当前栈帧从Java栈顶弹出,释放占用的内存空间
步骤4:控制权转移 → 调用方的栈帧重新成为"当前栈帧",继续执行(2)异常终止(抛出未捕获的异常,如StackOverflowError)
步骤1:查找异常处理器 → 在当前栈帧的"异常表"中查找匹配的异常类型(如StackOverflowError)
步骤2:无匹配处理器 → 弹出当前栈帧,将异常向上传递给调用方的栈帧,重复步骤1
步骤3:逐层弹出 → 递归调用的栈帧从最顶层开始,依次弹出(如第2700层→2699层→...→main层)
步骤4:异常捕获 → 直到main方法的catch块找到匹配的异常处理器,执行异常处理逻辑(打印count和堆栈)
步骤5:最终出栈 → 异常处理完成后,相关栈帧全部弹出四、结合递归示例拆解出入栈过程
以TestStackDeep的recursion(1,2,3)调用为例,完整还原栈帧出入栈的生命周期:
1. 初始状态
JVM启动后,main线程创建Java栈,main方法的栈帧首先入栈(成为第一个栈帧)。
2. 递归调用的栈帧入栈循环
main栈帧(当前帧)→ 调用recursion(1,2,3) → 第1个recursion栈帧入栈(count=1)
第1个recursion栈帧(当前帧)→ 调用recursion(1,2,3) → 第2个recursion栈帧入栈(count=2)
第2个recursion栈帧(当前帧)→ 调用recursion(1,2,3) → 第3个recursion栈帧入栈(count=3)
......
第N个recursion栈帧入栈时 → Java栈剩余空间不足,无法分配新栈帧 → 触发StackOverflowError3. 异常触发后的栈帧出栈
第N个recursion栈帧抛出异常 → 无本地异常处理器 → 弹出第N个栈帧
异常传递到第N-1个recursion栈帧 → 无处理器 → 弹出第N-1个栈帧
......
异常传递到main栈帧 → catch块捕获异常 → 打印count(此时count=N)和堆栈信息
main栈帧执行完异常处理 → 弹出main栈帧 → 线程终止 → Java栈销毁4. -Xss参数对调用深度的影响
-Xss<size>指定单个线程的Java栈最大空间,直接决定栈帧的最大入栈数量(调用深度):
| 参数配置 | Java栈总空间 | 单个栈帧大小 | 最大栈帧数量(调用深度) | 示例输出count |
|---|---|---|---|---|
-Xss128k |
128KB=131072字节 | ~150字节 | 131072 ÷ 150 ≈ 873 → 扣除main栈帧(~500字节),实际≈2700 | deep of calling = 2700 |
-Xss256k |
256KB=262144字节 | ~150字节 | 262144 ÷ 150 ≈ 1747 → 扣除main栈帧,实际≈5400 | deep of calling = 5400 |
关键结论:
-Xss越大,Java栈可容纳的栈帧越多,递归调用深度越深;反之则越浅。
五、Java栈出入栈的关键特性
- 后进先出(LIFO):最后入栈的栈帧(当前执行的函数)最先出栈(如递归的最顶层栈帧最先弹出);
- 无内存碎片:Java栈是连续的内存空间,栈帧入栈/出栈仅移动"栈顶指针",无需内存整理;
- 编译期确定性:栈帧的大小、局部变量表/操作数栈的深度均在编译期确定,运行时无动态调整;
- 线程隔离性:不同线程的Java栈独立,一个线程的栈帧出入栈不会影响其他线程的栈。
六、Java栈的参数配置与调优
1. 核心参数:-Xss<size>
- 格式:支持
k/K(KB)、m/M(MB)、g/G(GB),如-Xss128k、-Xss1m; - 默认值(JDK8):Windows/Linux默认1MB,macOS默认256KB;
- 查看默认值:
java -XX:+PrintCommandLineFlags -version(输出中-XX:ThreadStackSize即为-Xss的等价参数)。
2. 调优原则
| 场景 | -Xss配置策略 |
风险提示 |
|---|---|---|
| 高并发场景(如Web服务器) | 调小(如256k~512k) | 避免栈空间过大导致可创建线程数减少(总内存=堆+栈×线程数) |
| 深层递归/嵌套函数 | 调大(如1m~2m) | 栈过大会减少线程数,且单次栈溢出的恢复成本更高 |
七、常见问题与排查
1. StackOverflowError(栈溢出)
- 触发原因:函数调用深度超过Java栈的最大容量(如无限递归、深层嵌套函数);
- 排查步骤:
- 查看异常栈轨迹:找到递归/嵌套最深的函数(异常信息的最顶层);
- 分析调用逻辑:检查是否有无限递归(无终止条件)、嵌套层级是否合理;
- 临时解决:调大
-Xss参数(治标); - 根本解决:优化代码(如递归改循环、减少函数嵌套)。
2. 线程创建失败(OutOfMemoryError: unable to create new native thread)
- 间接关联:
-Xss设置过大,每线程栈占用过多内存,导致系统无法创建新线程; - 解决方案:调小
-Xss(如从1m改为256k),降低单线程栈占用。
八、扩展:Java栈 vs 本地方法栈
| 维度 | Java栈 | 本地方法栈 |
|---|---|---|
| 处理对象 | Java方法调用 | Native方法(C/C++编写)调用 |
| 出入栈规则 | 遵循JVM规范,栈帧结构固定 | 无统一规范(不同JVM实现不同) |
| 异常类型 | StackOverflowError | StackOverflowError |
| 参数配置 | -Xss控制 |
部分JVM支持-XX:NativeStackSize |
总结
Java栈的出入栈本质是栈帧的压入与弹出 ,其核心逻辑围绕函数调用展开:函数调用触发栈帧入栈,函数结束(正常/异常)触发栈帧出栈。理解栈帧的结构、出入栈流程,以及-Xss参数对调用深度的影响,是排查栈溢出、优化线程模型的核心基础。
栈帧核心组件:局部变量表
一、局部变量表的核心定义与定位
| 核心属性 | 详细说明 |
|---|---|
| 归属 | 栈帧的必选组成部分,线程私有,随栈帧创建而创建、销毁而销毁 |
| 核心功能 | 存储方法的形参 (含实例方法隐含的this)、方法内声明的局部变量 |
| 作用域 | 仅在当前方法调用内有效,方法执行完毕栈帧销毁,局部变量表也随之释放 |
| 大小特性 | 容量(Slot数)在编译期确定(写死在Class文件中),运行时不可动态扩展 |
| 内存占用 | 直接影响单个栈帧的大小,进而决定Java栈可容纳的栈帧数量(方法调用深度) |
二、局部变量表的底层结构:变量槽(Slot)
局部变量表的最小存储单元是变量槽(Slot),所有变量均通过Slot分配空间,其规则是理解局部变量表的核心:
1. Slot的基本规则
- 单个Slot占用4字节(32位),是JVM定义的固定内存单位;
- 数据类型与Slot占用数强绑定(编译期确定),规则如下:
| 数据类型分类 | 包含类型 | Slot占用数 | 示例 |
|---|---|---|---|
| 占用1个Slot | boolean/byte/char/short/int/float/引用类型(reference)/returnAddress | 1 | int a; Object obj; |
| 占用2个Slot(宽类型) | long/double | 2 | long b; double c; |
补充:实例方法的第一个Slot默认分配给
this(静态方法无this),因此实例方法的局部变量表Slot数从1开始,静态方法从0开始。
2. 容量计算示例(TestStackDeep)
结合你提供的递归示例,验证Slot容量计算逻辑:
- 方法1:
recursion(long a, long b, long c)+ 10个long局部变量(e-z)
总变量数 = 3个参数 + 10个局部变量 = 13个long类型;
总Slot数 = 13 × 2 = 26(与jclasslib工具显示的"最大局部变量表大小为26个字"完全一致)。 - 方法2:
recursion()(无参数、无局部变量)
总Slot数 = 0(仅保留returnAddress的基础Slot,无实际变量占用)。
三、局部变量表的核心特性:Slot复用
Slot是可复用的内存单元,编译器会自动复用超出作用域的变量Slot,以节省栈帧空间,这是局部变量表的关键优化机制。
1. 复用原理
当局部变量超出其语法作用域 (如代码块{}结束),后续声明的局部变量可复用该变量的Slot,无需分配新Slot;
复用由编译器在编译期决定,写入Class文件的局部变量表信息中,运行时无额外开销。
2. 复用示例拆解(局部变量复用代码)
对比两个方法的Slot使用情况,清晰体现复用逻辑:
| 方法 | 代码逻辑 | Slot分配(含this) | 复用结果 |
|---|---|---|---|
| localvar1() | a和b作用域至方法末尾 byte[] a = ...; int b = ...; |
this→Slot0,a→Slot1,b→Slot2 总Slot数:3 | 无复用,b占用新Slot |
| localvar2() | a作用域在代码块内,b在块外 {byte[] a = ...;} int b = ...; |
this→Slot0,a→Slot1(块内)→块结束后b复用Slot1 总Slot数:2 | b复用a的Slot1,节省1个Slot |
3. 复用的关键价值
- 减少单个栈帧的内存占用,相同
-Xss(栈总容量)下可容纳更多栈帧,提升方法调用深度; - 触发GC回收:复用Slot会覆盖原有变量的引用,使原引用指向的对象失去可达性(见下文GC关联部分)。
四、局部变量表与垃圾回收(GC)的强关联
局部变量表是GC Roots的核心来源 (属于"虚拟机栈中的引用"),只要对象被局部变量表中的变量直接/间接引用,就属于"可达对象",不会被GC回收。以下结合LocalVarGCTest示例,拆解不同场景下的GC行为:
1. GC核心规则
- 可达性判定:局部变量表中的变量引用 → 属于GC Roots → 引用的对象不可回收;
- 引用断开的唯一方式:① 变量置
null;② Slot被复用;③ 栈帧销毁(方法返回)。
2. 示例方法逐行分析(LocalVarGCTest)
| 方法 | 核心逻辑 | 局部变量表状态 | 6MB数组是否被GC回收 | 核心原因 |
|---|---|---|---|---|
| localvarGc1() | 数组引用a → 直接GC | a的Slot有效,引用指向数组 | ❌ 不回收 | 数组属于GC Roots可达对象 |
| localvarGc2() | a置null → 再GC | a的Slot仍存在,但引用为null | ✅ 回收 | 主动断开引用,数组失去GC Roots关联 |
| localvarGc3() | a超出作用域 → 再GC | a的Slot未被复用,引用仍指向数组 | ❌ 不回收 | 仅超出作用域≠引用断开,Slot仍保留原引用 |
| localvarGc4() | a超出作用域 + 声明c复用Slot → GC | c复用a的Slot,原引用被覆盖/销毁 | ✅ 回收 | Slot复用导致数组引用断开,变为不可达 |
| localvarGc5() | 调用localvarGc1后 → 再GC | localvarGc1栈帧销毁,a的Slot随之销毁 | ✅ 回收 | 方法返回后栈帧销毁,局部变量表全部失效,引用断开 |
3. 验证方式(-XX:+PrintGC)
执行localvarGc4()时,GC日志显示:
GC前堆空间:10081KB → GC后堆空间:816KB差值≈6MB,验证数组已被回收;核心原因是变量c复用了a的Slot,原数组引用被覆盖。
五、局部变量表对方法调用深度的影响
局部变量表的大小直接决定单个栈帧的内存占用,进而影响Java栈可容纳的栈帧数量(即方法递归/嵌套调用深度)。
1. 核心逻辑
Java栈总容量(-Xss)= 单个栈帧大小 × 最大栈帧数量(调用深度)
→ 局部变量表越大 → 单个栈帧越大 → 最大栈帧数量越少 → 调用深度越浅2. 示例验证(TestStackDeep + -Xss128k)
| 方法 | 局部变量表大小 | 单个栈帧占用空间 | 最大递归调用深度 | 结果对比 |
|---|---|---|---|---|
| recursion(long...) | 26 Slot | 更大(≈150字节) | ~2700次 | 深度浅 |
| recursion() | 0 Slot | 更小(≈20字节) | ~5400次 | 深度翻倍(相同-Xss) |
关键结论:相同栈容量下,局部变量/参数越少(尤其是long/double类型),方法调用深度越深。
六、工具分析:jclasslib查看局部变量表
jclasslib是可视化分析Class文件的工具,可直接验证局部变量表的编译期属性,核心查看项如下:
| 查看项 | 作用 | 示例(recursion(long a,b,c)) |
|---|---|---|
| Max local variables | 局部变量表的最大Slot数 | 26(对应13个long变量×2) |
| Index(槽位索引) | Slot的序号(静态方法从0开始,实例方法0为this) | a→0,b→2,c→4(long占2个Slot,索引跳2) |
| Name(变量名) | 局部变量/参数的名称 | a、b、c、e、f等 |
| Descriptor(类型) | 变量的数据类型(J=long,I=int,[B=byte数组等) | J(所有变量均为long) |
| Scope(作用域) | 变量的有效代码行范围 | a的作用域覆盖整个方法 |
七、调优启示与最佳实践
1. 栈深度优化(递归/嵌套方法)
- 精简方法参数/局部变量:移除不必要的变量,优先使用占用1个Slot的类型(如int替代long),降低局部变量表大小;
- 高并发场景:平衡
-Xss与局部变量表大小 ------ 调小-Xss(如256k)以增加线程数,同时精简局部变量表保证基础调用深度。
2. GC优化(大对象场景)
- 主动置null:方法内大对象使用完毕后,主动将引用置
null(如localvarGc2),无需等待Slot复用; - 利用Slot复用:大对象放在代码块内,后续声明变量复用其Slot(如localvarGc4),加速GC回收;
- 避免方法末尾释放引用:大对象引用尽早断开,减少内存占用峰值。
3. 常见误区规避
| 误区 | 正确认知 |
|---|---|
| "变量超出作用域就会被GC回收" | 错误:Slot未复用前,引用仍保存在局部变量表中,对象仍可达 |
| "局部变量表大小运行时可调整" | 错误:编译期已固定,Class文件中写入Max local variables,运行时不可改 |
| "所有局部变量都占1个Slot" | 错误:long/double占2个Slot,引用类型/基本类型(除long/double)占1个 |
八、总结
局部变量表是栈帧的"数据底座",其核心特性可总结为:
- 编译期确定性:大小、Slot分配、复用规则均在编译期确定;
- 内存复用性:Slot可复用,节省栈空间并影响GC;
- GC关联性:作为GC Roots直接决定对象可达性;
- 深度影响性:大小直接决定方法调用深度。
栈帧核心组件:操作数栈(Operand Stack)
一、操作数栈的核心定义与定位
操作数栈是方法执行的"临时运算区",其核心属性决定了方法执行的底层逻辑:
| 核心属性 | 详细说明 |
|---|---|
| 归属 | 栈帧的必选组成部分,线程私有,随栈帧创建/销毁而创建/销毁 |
| 核心功能 | 1. 存储方法执行的中间运算结果 ; 2. 为字节码指令提供操作数(如算术运算、字段访问); 3. 方法调用时传递参数、接收返回值 |
| 操作规则 | 仅支持"压栈(push)"和"弹栈(pop)",严格遵循LIFO(后进先出) |
| 深度特性 | 最大栈深度(Max stack)在编译期确定(写死在Class文件中),运行时不可动态扩展 |
| 数据类型 | 支持JVM所有基本类型和引用类型,宽类型(long/double)占用2个栈深度单位,其他类型占用1个 |
| 内存访问 | 无直接地址访问能力,只能通过压栈/弹栈操作访问数据,无内存碎片 |
关键区别:局部变量表是"命名存储"(通过Slot索引访问),操作数栈是"匿名存储"(仅通过栈顶位置访问),两者协同完成方法执行。
二、操作数栈的底层规则
1. 栈深度(Max Stack)
操作数栈的最大深度是编译器根据方法的字节码指令流计算出的"峰值需求",写入Class文件的Code属性中,运行时JVM会为栈帧分配对应大小的操作数栈空间。
- 示例:执行
a = b + c时,操作数栈需依次压入b、c,执行加法后弹出结果,峰值深度为2 → 该方法的Max Stack=2。 - 宽类型规则:long/double压栈时会占用2个栈深度单位,弹栈时也需一次性弹出2个单位(JVM保证宽类型的原子性,不会拆分)。
2. 数据类型处理规则
| 数据类型分类 | 栈深度占用 | 操作规则 |
|---|---|---|
| 窄类型(int/byte/char等) | 1 | 压栈时自动扩展为int(如byte值10压栈后为int类型),运算后再缩窄 |
| 宽类型(long/double) | 2 | 压栈时占用连续2个栈深度单位,栈顶指针直接+2;弹栈时指针-2,不可拆分操作 |
| 引用类型(Object/数组等) | 1 | 压栈的是对象的引用地址(指向堆内存),而非对象本身 |
3. 空操作数栈初始化
栈帧创建时,操作数栈初始化为空,方法执行过程中,字节码指令会不断向栈中压入/弹出数据,始终保证栈深度不超过Max Stack。
三、操作数栈的核心操作
操作数栈的所有行为均对应JVM字节码指令,核心操作可分为基础操作 、运算操作 、方法调用/返回操作三类:
1. 基础操作(数据入栈/出栈)
| 字节码指令 | 功能 | 示例(操作数栈变化) |
|---|---|---|
iload_<n> |
从局部变量表第n个Slot加载int值压栈 | 局部变量表Slot1=10 → 执行iload_1 → 操作数栈:10 |
ldc <常量> |
从常量池加载常量(int/float/字符串)压栈 | 常量池有100 → 执行ldc 100 → 操作数栈:100 |
istore_<n> |
将栈顶int值弹出,存入局部变量表第n个Slot | 操作数栈:20 → 执行istore_2 → 局部变量表Slot2=20,栈空 |
pop |
弹出栈顶1个单位数据(窄类型) | 栈:5, 8 → pop → 栈:5 |
pop2 |
弹出栈顶2个单位数据(宽类型) | 栈:9L(占2单位)→ pop2 → 栈空 |
dup |
复制栈顶数据并压栈 | 栈:7 → dup → 栈:7, 7 |
swap |
交换栈顶两个窄类型数据的位置 | 栈:3, 6 → swap → 栈:6, 3 |
2. 运算操作(基于栈顶数据计算)
所有算术/逻辑运算均需先将操作数压入栈,再执行指令弹出计算,结果压回栈顶:
| 字节码指令 | 功能 | 示例(操作数栈变化) |
|---|---|---|
iadd |
栈顶两int相加 | 栈:4, 5 → iadd → 栈:9 |
lsub |
栈顶两long相减 | 栈:10L, 3L → lsub → 栈:7L |
if_icmpgt |
栈顶两int比较(大于则跳转) | 栈:8, 5 → if_icmpgt 0x08 → 8>5,跳转到0x08指令 |
3. 方法调用/返回操作
方法调用时的参数传递、返回值接收完全依赖操作数栈:
(1)方法调用(以invokestatic为例)
步骤1:调用方将参数按顺序压入操作数栈(如调用recursion(1,2,3),依次压入1L、2L、3L);
步骤2:执行`invokestatic`指令,弹出所有参数并传递给被调用方法的局部变量表;
步骤3:被调用方法的栈帧入栈,操作数栈初始化,开始执行;(2)方法返回(以ireturn为例)
步骤1:被调用方法将返回值压入自身操作数栈(如返回int 10 → 压入10);
步骤2:执行`ireturn`指令,弹出返回值并压入调用方的操作数栈;
步骤3:被调用方法的栈帧出栈,调用方继续执行(如将返回值存入局部变量表);四、操作数栈与局部变量表的交互(核心执行流程)
方法的执行本质是"局部变量表取数 → 操作数栈运算 → 结果存回局部变量表"的循环,以下以TestStackDeep中的count++为例,拆解完整交互流程:
示例:count++的字节码与操作数栈/局部变量表交互
count是静态变量(类变量),但核心逻辑可类推局部变量的运算,字节码指令流及交互步骤如下:
java
// 源码:count++;
// 核心字节码指令(简化):
1. getstatic #2 // 从常量池加载count的引用,压入操作数栈 → 栈:[count当前值]
2. iconst_1 // 压入常量1 → 栈:[count当前值, 1]
3. iadd // 两int相加 → 栈:[count+1]
4. putstatic #2 // 弹出结果,赋值给count → 栈空更典型的局部变量运算示例(int a = b + c)
java
// 源码:
int b = 5;
int c = 3;
int a = b + c;
// 字节码+交互流程:
1. bipush 5 // 压入5 → 栈:[5]
2. istore_1 // 弹出5,存入局部变量表Slot1(b)→ 栈空
3. bipush 3 // 压入3 → 栈:[3]
4. istore_2 // 弹出3,存入局部变量表Slot2(c)→ 栈空
5. iload_1 // 加载Slot1的b=5 → 栈:[5]
6. iload_2 // 加载Slot2的c=3 → 栈:[5, 3]
7. iadd // 相加 → 栈:[8]
8. istore_3 // 弹出8,存入Slot3(a)→ 栈空五、实战示例拆解:操作数栈在递归/GC场景中的作用
结合前文TestStackDeep和LocalVarGCTest,拆解操作数栈的实际影响:
1. 递归调用(TestStackDeep)中的操作数栈
recursion(long a, long b, long c)的调用流程中,操作数栈负责:
- 压入参数:调用方将
1L、2L、3L依次压入操作数栈(占用6个栈深度单位,因long占2单位); - 执行
invokestatic:弹出参数并赋值给被调用方法的局部变量表; count++运算:如上文所述,完成自增操作。
关键影响:操作数栈的Max Stack越大,单个栈帧占用空间越多 → 递归深度越浅(与局部变量表的影响逻辑一致)。
2. GC场景(LocalVarGCTest)中的操作数栈
localvarGc2()中a = null的执行流程:
java
// 源码:a = null;
// 字节码+操作数栈:
1. aconst_null // 压入null引用 → 栈:[null]
2. astore_1 // 弹出null,存入局部变量表Slot1(覆盖原数组引用)→ 栈空操作数栈在此过程中完成"null值压栈 → 覆盖局部变量表引用",最终使数组失去GC Roots关联,触发回收。
六、工具分析:jclasslib查看操作数栈属性
通过jclasslib可直接查看Class文件中操作数栈的编译期属性,核心查看项:
| 查看项 | 作用 | 示例(recursion(long a,b,c)) |
|---|---|---|
| Max stack | 操作数栈的最大深度(编译期确定) | 比如10(满足参数压栈、count++运算的峰值需求) |
| Code属性指令流 | 每个字节码指令对应的操作数栈变化 | getstatic(压栈)→ iconst_1(压栈)→ iadd(弹栈+压栈) |
| Stack map table | (JVM验证用)记录每个指令位置的操作数栈类型、深度,保证类型安全 | 验证iadd指令时,栈顶必须是两个int类型 |
七、操作数栈的关键特性与调优启示
1. 核心特性总结
- 编译期确定性:Max Stack、类型规则均在编译期确定,运行时无动态调整,保证执行效率;
- 无内存碎片:压栈/弹栈仅移动栈顶指针,无需内存整理;
- 类型安全:JVM通过栈映射表(Stack map table)验证操作数栈的类型匹配(如
iadd只能操作int),避免类型错误。
2. 调优启示
- 精简运算指令:减少不必要的压栈/弹栈操作(如避免冗余的
dup/swap),降低操作数栈峰值深度,减小栈帧大小; - 避免宽类型滥用:long/double占用2个栈深度单位,频繁使用会增加Max Stack,进而增大栈帧 → 递归/嵌套方法优先使用int;
- 方法内联优化:JIT即时编译会将小方法内联,减少操作数栈的参数传递开销(如压栈/弹栈次数),提升执行效率。
八、常见误区与问题
1. 误区:操作数栈与局部变量表可混用
错误认知:"操作数栈的数据可直接访问局部变量表";
正确逻辑:两者是独立区域,数据交互仅能通过iload/istore等指令(压栈/弹栈),无直接访问能力。
2. 异常:操作数栈溢出
JVM规范中操作数栈无OutOfMemoryError,因Max Stack编译期确定,栈帧分配时已预留足够空间;仅当栈帧总数超过Java栈容量时,触发StackOverflowError(整体栈溢出)。
3. 宽类型操作的原子性
long/double压栈时占用2个栈深度单位,JVM保证其原子性------ 不会出现"压入1个单位后中断"的情况,避免数据损坏。
九、总结
操作数栈是方法执行的"运算核心",其核心价值在于:
- 为字节码指令提供无地址依赖的临时存储,保证执行效率;
- 完成方法参数传递、返回值处理,是方法调用的"数据桥梁";
- 与局部变量表协同,构成方法执行的完整数据链路。