from selenium import webdriver
from pyquery import PyQuery as pq
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
browser.get('https://antispider3.scrape.center/')
#目标就是等待CSS=item的节点全部加载完成
WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.item')))
#等待上面要求的节点全部加载完成了,再提取页面代码
html = browser.page_source
doc = pq(html)
names = doc('.item .name')
for name in names.items():
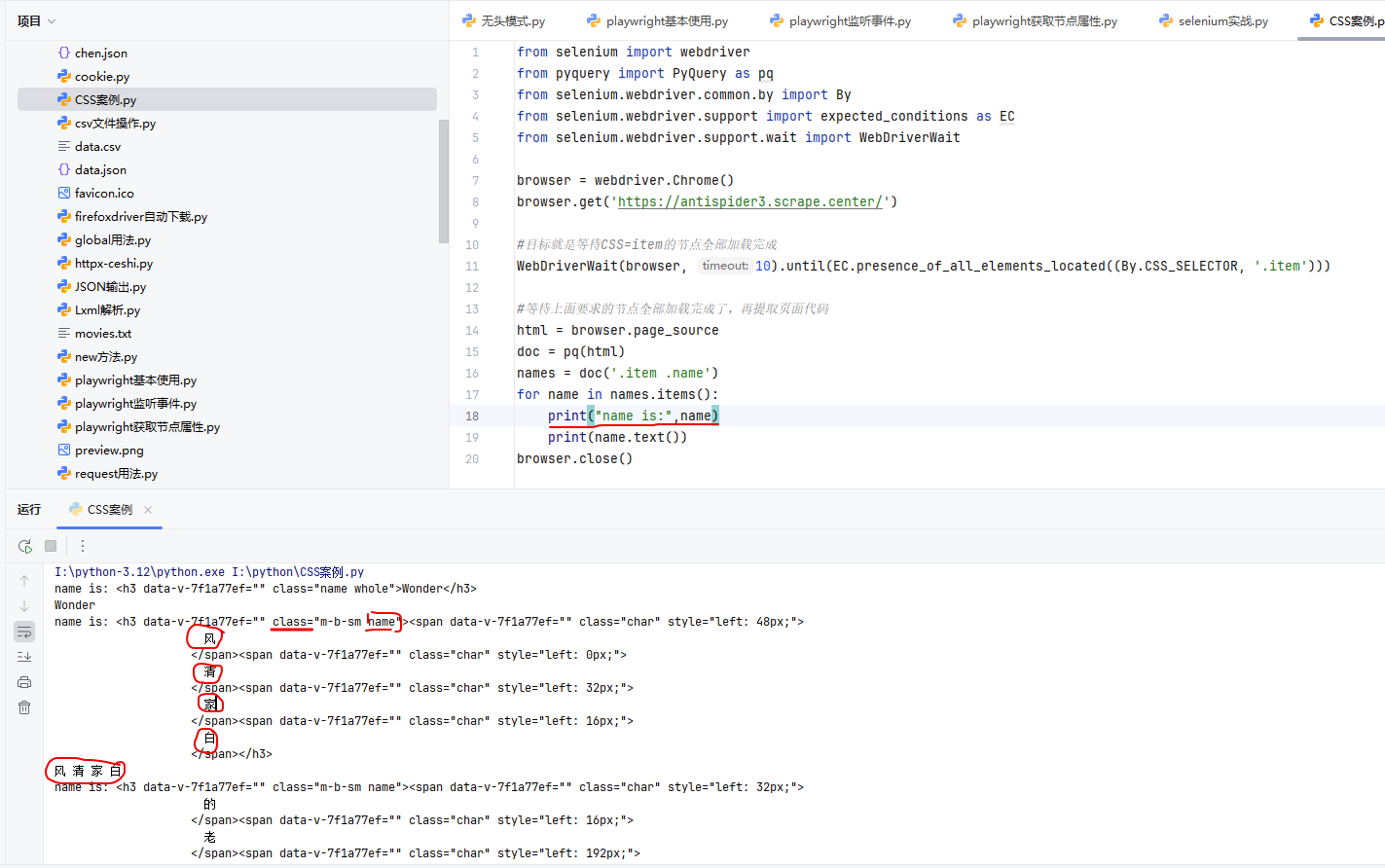
print("name is:",name)
print(name.text())
browser.close()关键知识点解析:
1、显式等待目标元素加载完成:WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.item')))
WebDriverWait(browser, 10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.item')))- 整体功能:设置一个最长 10 秒的显式等待,直到页面中所有匹配
.itemCSS 选择器的元素都存在于 DOM 树中 ,否则超时抛出TimeoutException异常。 - 逐部分拆解:
WebDriverWait(browser, 10):创建WebDriverWait实例,传入两个参数:browser(浏览器驱动实例,用于监控页面状态)、10(最长等待时间,单位:秒)。.until(...):调用WebDriverWait实例的until()方法,传入 "预期满足的条件",该方法会循环判断条件是否成立:- 条件成立:立即返回,继续执行后续代码。
- 条件不成立:持续等待,直到达到最长等待时间(10 秒),抛出超时异常。
EC.presence_of_all_elements_located(...):指定预期条件,含义是 "等待所有目标元素都存在于 DOM 树中"(注意:仅要求元素存在,不要求元素可见、可点击)。(By.CSS_SELECTOR, '.item'):传入元素定位参数,是一个元组:- 第一个元素
By.CSS_SELECTOR:指定定位策略为 "CSS 选择器"。 - 第二个元素
.item:指定 CSS 选择器为 "类名为 item 的元素"。
- 第一个元素
- 核心作用:解决动态加载页面的元素定位问题,避免因 "元素未加载完成就尝试提取" 导致的报错,确保后续解析页面时目标元素已存在。
2. 获取浏览器当前页面的完整源码:html = browser.page_source
html = browser.page_source- 功能:调用
browser实例的page_source属性,获取当前浏览器页面渲染完成后的完整 HTML 源码(包含动态加载的元素、JS 渲染后的内容等)。 - 作用:将完整的 HTML 源码赋值给变量
html,后续用于传递给PyQuery进行数据解析;page_source返回的是字符串格式的 HTML 内容。
3. 初始化 PyQuery 解析实例:doc = pq(html)
doc = pq(html)- 功能:创建
PyQuery解析实例,将获取到的 HTML 源码字符串html传入作为解析对象,并将实例赋值给变量doc。 - 作用:后续通过
doc实例调用PyQuery的相关方法,通过 CSS 选择器等方式提取目标数据,doc实例本质上是对 HTML 文档树的封装。
4. 通过 CSS 选择器提取目标元素:names = doc('.item .name')
names = doc('.item .name')- 功能:调用
doc实例的 CSS 选择器方法,传入选择器.item .name。 - 选择器含义:匹配所有 "类名为 item 的元素" 内部的 "类名为 name 的子元素"(后代选择器,支持多层嵌套匹配)。
- 作用:将所有匹配该选择器的元素提取出来,封装为
PyQuery集合对象并赋值给变量names;该集合对象包含了所有符合条件的元素,支持遍历、进一步筛选等操作。
5. 遍历元素集合并打印文本内容:for name in names.items(): print(name.text())
for name in names.items():
print(name.text())- 整体功能:遍历
names中的所有元素,逐个提取并打印元素的文本内容(去除 HTML 标签、空格、换行符等冗余内容)。 - 逐部分拆解:
names.items():调用PyQuery集合对象的items()方法,返回一个可迭代的生成器,每次迭代会返回集合中的一个单个元素(封装为PyQuery实例)。for name in names.items():通过 for 循环遍历该生成器,将每次迭代得到的单个元素赋值给变量name。print(name.text()):调用单个元素name的text()方法,提取该元素的纯文本内容 ,并通过print()打印输出。
升级抓取方法:
from selenium import webdriver
from pyquery import PyQuery as pq
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import re
def parse_name(name_html):
chars = name_html('.char')
items = []
for char in chars.items():
items.append({
'text': char.text().strip(),
'left': int(re.search(r'(\d+)px', char.attr('style')).group(1))
})
items = sorted(items, key=lambda x: x['left'], reverse=False)
return ''.join([item.get('text') for item in items])
# 初始化浏览器
browser = webdriver.Chrome()
browser.get('https://antispider3.scrape.center/')
WebDriverWait(browser, 10).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.item'))
)
# 获取页面源码并解析
html = browser.page_source
doc = pq(html)
names = doc('.item .name')
# 提取并打印每个名字
for name_html in names.items():
name = parse_name(name_html)
print(name)
# 关闭浏览器
browser.close()names 和 name_html 的关系:
我们从两者的定义、数据类型、层级关系以及遍历中的对应关系四个方面详细拆解,让你清晰理解它们的关联:
一、先明确两者的各自定义与数据类型
1. names 的定义与类型
names = doc('.item .name')- 数据类型 :
names是一个PyQuery集合对象 (可以理解为「多个单个节点的容器」),它不是单个节点,而是包含了页面中所有匹配.item .name选择器的节点的集合。 - 来源:从整个页面源码解析后的
doc(根PyQuery对象)中,筛选出所有满足「.item节点下的.name节点」条件的元素,全部存入names中。 - 通俗理解:
names是一个「名称节点列表」,里面装着页面上所有要提取的名称对应的节点(比如页面上有 10 个商品名称,names就包含 10 个.name节点)。
2. name_html 的定义与类型
for name_html in names.items():
name = parse_name(name_html)- 数据类型 :
name_html是一个 单个的PyQuery节点对象 ,它对应names集合中的「某一个元素」。 - 来源:它是遍历
names集合时,每次迭代取出的「单个节点」,仅代表页面上的一个.item .name节点(比如某一个商品的名称节点)。 - 通俗理解:
name_html是names这个「容器」里的「单个物品」,每次遍历取一个,直到把names中的所有节点取完。
二、核心关系总结
-
**层级关系:
names是集合(父 / 容器),name_html是集合中的单个元素(子 / 成员)**这是最核心的关系,类比理解:- 把
names看作一个「装着苹果的篮子」(篮子里有多个苹果); - 把
name_html看作篮子里的「单个苹果」,每次从篮子里拿一个出来处理。没有names这个集合,就无法迭代得到name_html这个单个节点。
- 把
-
遍历关系:通过
names.items()实现从names到name_html的迭代提取names作为PyQuery集合,不能直接用for ... in names遍历出单个有效节点,必须调用.items()方法;.items()方法会将PyQuery集合转换为「可迭代对象」,每次迭代返回一个单个的PyQuery节点,赋值给name_html;- 遍历过程中,
names中的所有节点会被逐个取出作为name_html,直到遍历结束,不存在遗漏(一一对应,无重复)。
-
功能承接关系:
name_html是names集合的「最小处理单元」names仅负责「收集所有目标节点」,无法直接传入parse_name()函数进行解析(parse_name()要求传入单个PyQuery节点,用于提取单个名称);- 而
name_html作为单个节点,正好满足parse_name()函数的入参要求,是实现「批量解析所有名称」的中间桥梁(批量遍历 → 单个处理 → 汇总结果)。
三、补充验证:两者的对应性
- 若
names中包含n个.item .name节点,那么for循环会执行n次,每次的name_html对应其中一个唯一的节点; - 每个
name_html传入parse_name()后,都会返回一个完整名称,最终就能得到n个名称,与names收集的节点数量一致。
总结
names是PyQuery集合(多节点容器),name_html是单个PyQuery节点(集合成员);- 核心关联:
name_html来自于names集合的迭代遍历,是names的最小处理单元; - 功能上:通过遍历将「批量节点」转换为「单个节点」,实现批量解析名称的需求。
- chars也是
PyQuery集合对象,相当于一层一层拆解下来的**PyQuery集合对象。**
sorted(items, key=lambda x: x['left']) 详细解析
你想要深入理解这段排序代码,它是还原被打乱字符顺序的核心步骤,我们从整体功能、各组成部分详解、执行流程、上下文适配以及补充说明几个方面逐一拆解,帮你彻底掌握其逻辑:
一、整体核心功能
在该爬虫代码的上下文里,sorted(items, key=lambda x: x['left']) 的核心功能是:以 items 列表中每个字典元素的 'left' 键对应的值(字符水平位置像素值)作为排序依据,对存储字符信息的字典列表进行升序排序,从而还原字符的正确阅读顺序(从左到右)。
没有这段排序,字符会保持被反爬打乱的顺序,最终无法拼接出正确的名称。
二、逐部分拆解详解
1. 核心函数:sorted() 内置排序函数
- 本质 :Python 内置的可迭代对象排序函数,用于对列表、元组等可迭代对象进行排序,返回一个全新的排序后的列表(不会修改原列表,若需修改原列表可使用
list.sort()方法)。 - 基本语法 :
sorted(iterable, key=None, reverse=False) - 针对本场景 :
iterable就是items列表(元素为字典),后续重点解析key参数,reverse未显式指定时默认值为False(升序排序)。
2. 排序对象:items 列表的结构前提
要理解这段排序,必须先明确 items 列表的元素格式,这是排序的基础:
-
items是一个由字典组成的列表,每个字典元素都有固定格式:# items 列表的典型结构 items = [ {'text': '机', 'left': 50}, # 字符「机」,水平位置 50 像素 {'text': '手', 'left': 10} # 字符「手」,水平位置 10 像素 ] -
每个字典中的
'left'键对应一个整数(水平位置像素值),这是排序的核心依据;'text'键对应单个字符,是最终需要拼接的内容。
3. 关键参数:key 的作用
key 是 sorted() 函数实现「自定义规则排序」的核心可选参数,其核心功能与规则如下:
- 作用:指定一个「排序映射函数」,告诉
sorted()不要直接比较可迭代对象中的元素本身,而是先将每个元素传入该函数,以函数的返回值作为「排序关键字」进行比较排序。 - 要求:
key参数必须传入一个「可调用对象」(可以是普通命名函数、lambda 匿名函数、类的方法等),该可调用对象必须满足「接收单个参数,返回一个可用于比较排序的值(如整数、字符串等)」。 - 本场景必要性:如果没有
key参数,sorted()会直接尝试比较items中的字典元素本身,而 Python 中字典无法直接进行大小比较,会抛出TypeError: '<' not supported between instances of 'dict' and 'dict'异常,无法完成排序。
4. 映射函数:lambda x: x['left'] 匿名函数
lambda x: x['left'] 是一个 Python 匿名函数(lambda 表达式),专门为 key 参数提供排序映射逻辑,逐部分解析:
-
lambda 表达式的基本语法 :
lambda 参数列表: 返回值表达式,它是一种简化的小型函数,无需手动命名,适合这种简单的「取值 / 转换」场景。 -
各部分详解 :
lambda:Python 关键字,标识这是一个匿名函数,无法单独调用,通常作为参数直接传入其他函数。x:匿名函数的单个参数 ,在sorted()排序过程中,这个参数会被sorted()自动赋值 ------ 遍历items列表时,每次取出一个字典元素,就将该字典传给x。::分隔符,用于分隔「参数列表」和「返回值表达式」,左边是传入的参数,右边是要返回的结果。x['left']:匿名函数的返回值表达式 ,核心逻辑是「从传入的字典参数x中,提取'left'键对应的取值」(即字符的水平位置像素值,整数类型),这个整数就是后续排序的关键字。
-
等价于普通命名函数 :为了更直观理解,该 lambda 匿名函数完全等价于以下普通命名函数,只是 lambda 表达式更简洁,无需单独定义,适合内联使用:
# 与 lambda x: x['left'] 功能完全一致 def get_left_key(x): # x 对应 items 中的单个字典元素 return x['left'] # 提取字典的 'left' 键值并返回此时排序代码可改写为:
sorted(items, key=get_left_key),效果完全相同。
5. 排序规则:默认升序(reverse=False)
reverse 是 sorted() 函数的另一个可选参数,本代码中未显式指定,默认值为 False:
reverse=False:表示「升序排序」,即按照「排序关键字」(这里是'left'对应的像素值)从小到大进行排序。- 上下文适配性:在页面渲染中,
left像素值越小,代表字符越靠左侧(符合人类从左到右的阅读顺序),升序排序恰好能将字符从左到右排列,彻底还原被打乱的字符顺序。 - 补充:若设置
reverse=True,则为降序排序,字符会从右到左排列,得到反向的错误名称。
三、具体执行流程(可视化示例)
我们以一个简化的 items 列表为例,直观展示整个排序的执行步骤:
步骤 1:准备排序前的乱序 items 列表
# 排序前:字符顺序被打乱(「手机」变成了「机手」)
items = [
{'text': '机', 'left': 50}, # 元素 1
{'text': '手', 'left': 10} # 元素 2
]步骤 2:sorted() 开始遍历并处理元素
sorted()取出第一个元素{'text': '机', 'left': 50},传给lambda x,x即为该字典,匿名函数返回x['left']→50。sorted()取出第二个元素{'text': '手', 'left': 10},传给lambda x,x即为该字典,匿名函数返回x['left']→10。
步骤 3:比较排序关键字,完成排序
sorted()比较两个返回的排序关键字50和10,按照升序规则(从小到大),确定元素 2 应排在元素 1 前面。sorted()生成一个全新的排序后列表,保持元素的完整结构不变。
步骤 4:得到排序后的正确列表
# 排序后:字符顺序还原(「手」在前,「机」在后)
sorted_items = [
{'text': '手', 'left': 10},
{'text': '机', 'left': 50}
]四、补充总结与关键要点
- 整体逻辑:
sorted()借助key参数,通过 lambda 函数提取字典的'left'键值作为排序依据,实现字典列表的自定义升序排序。 - 核心价值:解决了「字典无法直接排序」的问题,同时精准还原了被反爬打乱的字符顺序,是后续拼接正确名称的前提。
- 可扩展性:若需按其他字段排序(如字符大小、像素值降序),只需修改
key后的 lambda 表达式或reverse参数即可。 - 区别于
list.sort():sorted(items)返回新列表,不修改原items;items.sort()直接修改原列表,无返回值,两者的key和reverse参数用法完全一致。