现在的 RAG 项目,十个有九个会卡在同一个地方:"单点检索很强,跨段落推理很弱"。
你问"A公司的CEO是谁",向量检索(Vector Search)一搜一个准。但你问"A公司去年的投资策略对B公司的股价有什么隐形影响",传统的 RAG 就歇菜了。因为向量库里,这些信息是散落在不同切片(Chunks)里的,模型看不出它们之间的"线"。
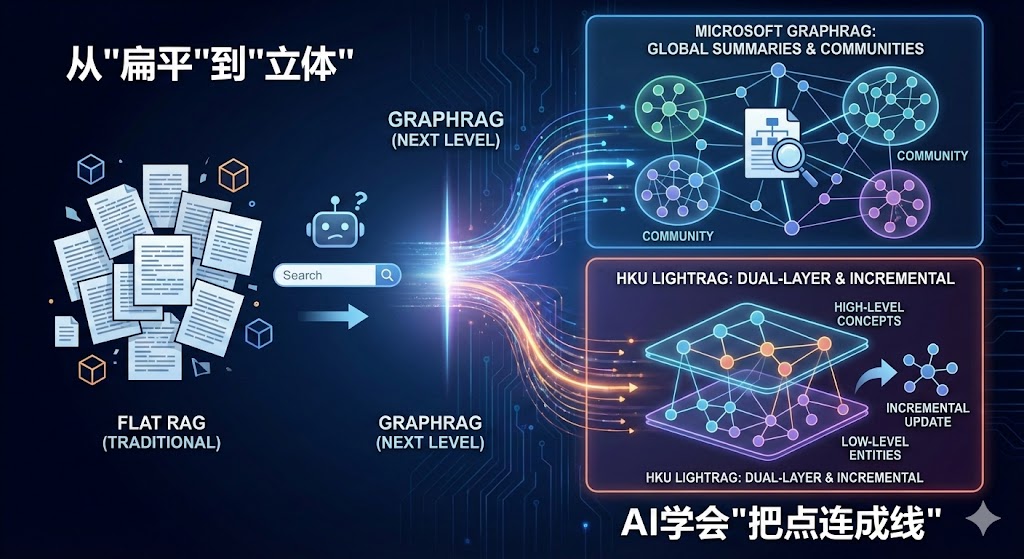
为了把这些点连成线,最近社区主要就看两个流派:微软的 GraphRAG 和港大的 LightRAG。
这两篇虽然都是讲图,但路子完全不同。看完这两篇文章,核心的差异其实就这么几点:
1. 微软 GraphRAG:本质是"用算力换智力"的暴力美学
微软这套方案(基于 From Local to Global 论文),说白了就是预计算。
它的逻辑是: 既然用户提问时再去找关系来不及,那我就在索引阶段,把所有的关系都算好,甚至把答案都提前写好。
-
它最狠的一招叫"社区报告(Community Reports)": 它不是简单地把实体连起来,而是用算法(Leiden)把节点聚类。比如把一本书分成"宏观主题"、"具体情节"、"人物关系"几个层级的社区。 然后------重点来了------它会强制 LLM 把每个社区里的内容读一遍,写成摘要报告存下来。
-
这就解释了为什么它能回答宏观问题: 当你问"这本书讲了啥"的时候,它根本没去翻原文,而是直接把那几个最高层级的"社区报告"甩给你。这也是为什么它用了 MapReduce 的逻辑。
代价是什么?
-
贵,且慢。 构建索引的过程非常烧 Token,因为要让 LLM 疯狂读图、写摘要。
-
更新极难。 今天新加一篇文档,整个图的社区结构可能变了,这在工程上几乎意味着重跑。
适合谁? 适合处理静态的长文档(比如财报库、法律卷宗、历史书),且你需要极高质量的全局总结,不在乎构建成本。
2. HKU LightRAG:更符合工程直觉的"敏捷派"
相比微软的重型武器,港大的 LightRAG 明显更懂实际工程痛点。它不想搞那么复杂的预计算,而是把精力花在了**"怎么找"和"怎么存"**上。
-
双层检索(Dual-Level Retrieval): 它把索引分成了"具体实体"和"抽象概念"。
-
问细节(谁、哪年):走低层,直接搜向量。
-
问逻辑(影响、意义):走高层,在知识图谱里顺藤摸瓜。 这种分流策略,比微软那种全部依赖社区报告的逻辑要灵活很多。
-
-
杀手级特性:增量更新(Incremental Update) 这是最打动开发者的一点。新来个文档,LightRAG 不会推倒重来,而是对比现在的图结构,只把新的节点和关系"缝"进去。
适合谁? 适合动态数据(新闻流、日志分析),或者你不想花天价去构建索引,只想在现有 RAG 基础上增加一点推理能力。
3. 落地时的"大实话"
如果你打算上手写代码,文章里提到的几个坑要注意:
-
显存焦虑: 别看 LightRAG 叫"Light",如果你在本地用 Ollama 跑(比如 deepseek-r1:1.5b),8GB 显存是底线。图谱构建需要大量的 LLM 推理来提取实体,显存不够直接报 503 或 OOM。想舒服点,还是得接 API 或者上 24GB+ 的卡。
-
Prompt 决定生死: 图谱好不好用,全看实体提取(Entity Extraction)那一步。如果你的 Prompt 没写好,提取出来的全是"我"、"他"、"这个"这种无意义节点,那整张图就是垃圾。
-
可视化是调试工具,不是花瓶: 代码里给的
.graphml导出功能,一定要用。用 Gephi 或者生成的 HTML 打开看看。如果发现你的图是无数个孤立的点,说明关系提取失败了,这时候上层 RAG 效果再好也没用。
总结一下
| 维度 | Microsoft GraphRAG | HKU LightRAG |
|---|---|---|
| 擅长场景 | 静态、复杂的长文本(如书籍、历史档案、法律卷宗);需要回答宏观总结性问题。 | 动态数据(如新闻、业务文档);既有细节查询又有逻辑推理;对成本敏感。 |
| 构建成本 | 极高。需要大量 LLM 调用来生成"社区报告"。 | 中等。主要是实体提取的开销,没有繁重的社区摘要步骤。 |
| 数据更新 | 困难。牵一发而动全身,通常适合离线批量处理。 | 丝滑。支持增量插入(Incremental Insert),无需重建索引。 |
| 检索逻辑 | MapReduce 模式(全局)+ 邻居搜索(局部)。 | 双层路由:关键词匹配向量 + 图谱关系游走。 |
| 技术栈 | NetworkX, Leiden 算法, 强依赖高性能 LLM。 | NetworkX, Pyvis (可视化), 兼容 Ollama/Zhipu 等轻量模型。 |
| 输出产物 | 包含丰富的层级化社区报告(Summary of summaries)。 | GraphML 图文件、KV 存储(JSON)、向量索引。 |
不要觉得加上"Graph"就无敌了。
-
如果是死资料、要在宏观层面做深度挖掘 ,硬着头皮上 Microsoft GraphRAG。
-
如果是活数据、要兼顾成本和逻辑关联 ,无脑选 LightRAG。
现在的趋势很明显,纯 Vector RAG 的天花板到了,Graph 是必须要补的课,但没必要一上来就搞最复杂的,先跑通流程才是正经事。