Java String类
- [Java String类介绍](#Java String类介绍)
- 字符串常量
- 字符串的构造器
- 字符串的值相等性判定
- 空字符串和null的区别
Java String类介绍
java.lang.String 是 Java 语言提供的不可变引用类型,用于封装 UTF-16 编码的字符序列,该类属于 java.lang 包(无需显式导入),是 Java 中使用最频繁的核心类之一。
String 作为引用类型,其实例统一存储于堆内存:
- 字符串字面量实例存储在堆内的字符串常量池(JDK 7 及之后常量池移至堆,JDK 6 及之前位于方法区),本质是堆内专门缓存字面量的区域,用于复用相同字符序列的实例;
- 通过构造方法创建的实例存储在堆的非常量池区域,与常量池实例相互独立。
JDK 8 及之前版本中,java.lang.String 类的 private final char\[\] value 是实现该不可变性语义的核心底层存储载体 ------ 该私有成员变量为字符数组,用于存储字符串的全部字符序列,其不可变性由以下机制严格保障:
① final 修饰 value 数组引用:final 关键字约束 value 数组引用在 String 实例初始化完成后,无法被重新赋值指向新的字符数组;
② private 私有访问控制修饰 value:通过私有访问权限限制 value 数组仅能被 String 类内部方法访问,外部类无法直接获取该数组的引用,从访问权限层面杜绝外部代码直接篡改数组内容;
③ 无任何公有(public)方法暴露修改 value 数组元素的接口:String 类未提供任何直接修改 value 数组元素的公有方法;
④ 所有语义上的修改类方法均返回新 String 实例:对于 substring ()、replace ()、concat ()、toUpperCase () 等看似修改字符序列的公有方法,其实现逻辑均为基于原实例的 value 数组创建新的字符数组,再初始化新的 String 实例并返回,原 String 实例的 value 数组及对应的字符序列在生命周期内始终保持不变。
字符串常量
字符串常量是指以双引号包裹的字符序列(如 "abc"、"123"、""),是 Java 编译期常量的核心类型,具备以下核心特征:
值的确定性:编译阶段即可确定字符序列的完整内容,无需运行时动态计算生成;
不可变性:依托 String 类的不可变性实现,常量的字符序列一旦创建无法修改,符合 String 类创建后值不可变的核心语义;
常量池复用:JVM 保证同一个字符序列的字符串常量在字符串常量池中仅存在一份实例;
归属:字符串常量本质是 String 实例,但其实例会被纳入专门的字符串常量池(String Pool)管理;
补充编译期常量的判定标准:仅当拼接的所有部分都是编译期常量(如字符串字面量、final 修饰且编译期可确定值的字符串变量)时,拼接结果才是字符串常量;若包含运行期变量(如非 final 的字符串变量),则拼接结果为普通 String 对象,无法纳入常量池自动复用。
字符串常量的共享特性
JVM 在类加载解析阶段会对编译期可确定字符序列的字符串常量(包括字符串字面量、编译期常量拼接结果、final 常量拼接结果)执行先检查后复用或创建的逻辑,即先检查常量池是否存在相同字符序列的实例,存在则直接返回引用复用,不存在则创建实例,确保相同字符序列的常量在常量池中全局唯一,该特性通过复用相同字符序列的实例减少内存占用,同时因共享实例引用一致。
java
public class StringDemo {
public static void main(String[] args) {
String s1 = "abc";
String s2 = "abc";
System.out.println("s1 == s2: " + (s1 == s2));
}
}
s1 和 s2 都是直接赋值字符串常量 "abc",JVM 加载类时会先检查常量池,若没有 "abc" 则创建,之后 s1 和 s2 都复用这个实例的引用,因此 == 返回 true。
编译期常量拼接的共享特性
字符串编译期常量拼接的共享特性,核心是编译器对编译期可确定字符序列的字符串拼接操作(包括纯字符串字面量拼接或 final 修饰的字符串常量拼接)进行预优化。编译器会直接将拼接表达式合并为单个完整的字符串常量,随后 JVM 在类加载的解析阶段,遵循字符串常量池先检查后复用或创建的共享规则,最终所有指向该编译期拼接结果的变量均共享常量池中同一个实例。
java
public class StringDemo {
public static void main(String[] args) {
String s1 = "abc";
String s2 = "a" + "b" + "c";
String s3 = "ab" + "c";
System.out.println("s1 == s2: " + (s1 == s2));
System.out.println("s1 == s3: " + (s1 == s3));
}
}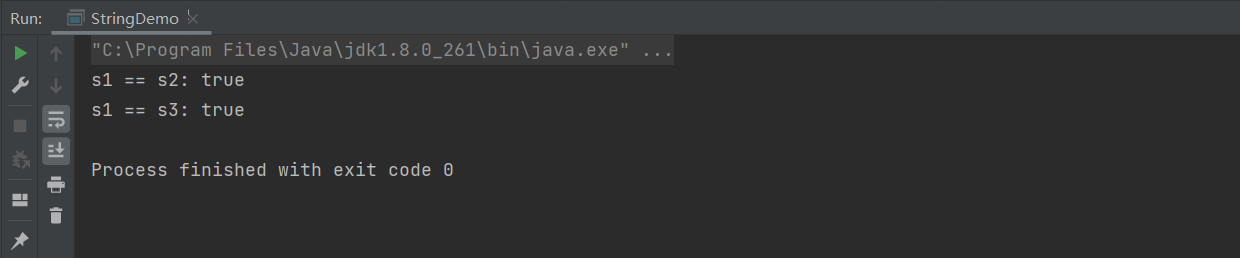
编译器在编译 .class 文件时,会将 "a"+"b"+"c" 直接替换为 "abc",因此 s2、s3 与 s1 共享同一个常量池实例。
字符串拼接产生新字符串
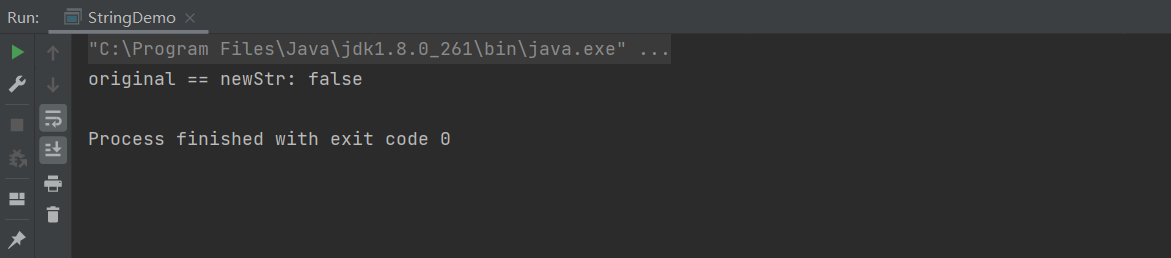
java
public class StringDemo {
public static void main(String[] args) {
String original = "abc";
String newStr = original + "d";
System.out.println("original == newStr: " + (original == newStr));
}
}
在终端运行 javap -c StringDemo.class 进行反编译,反编译结果如下:
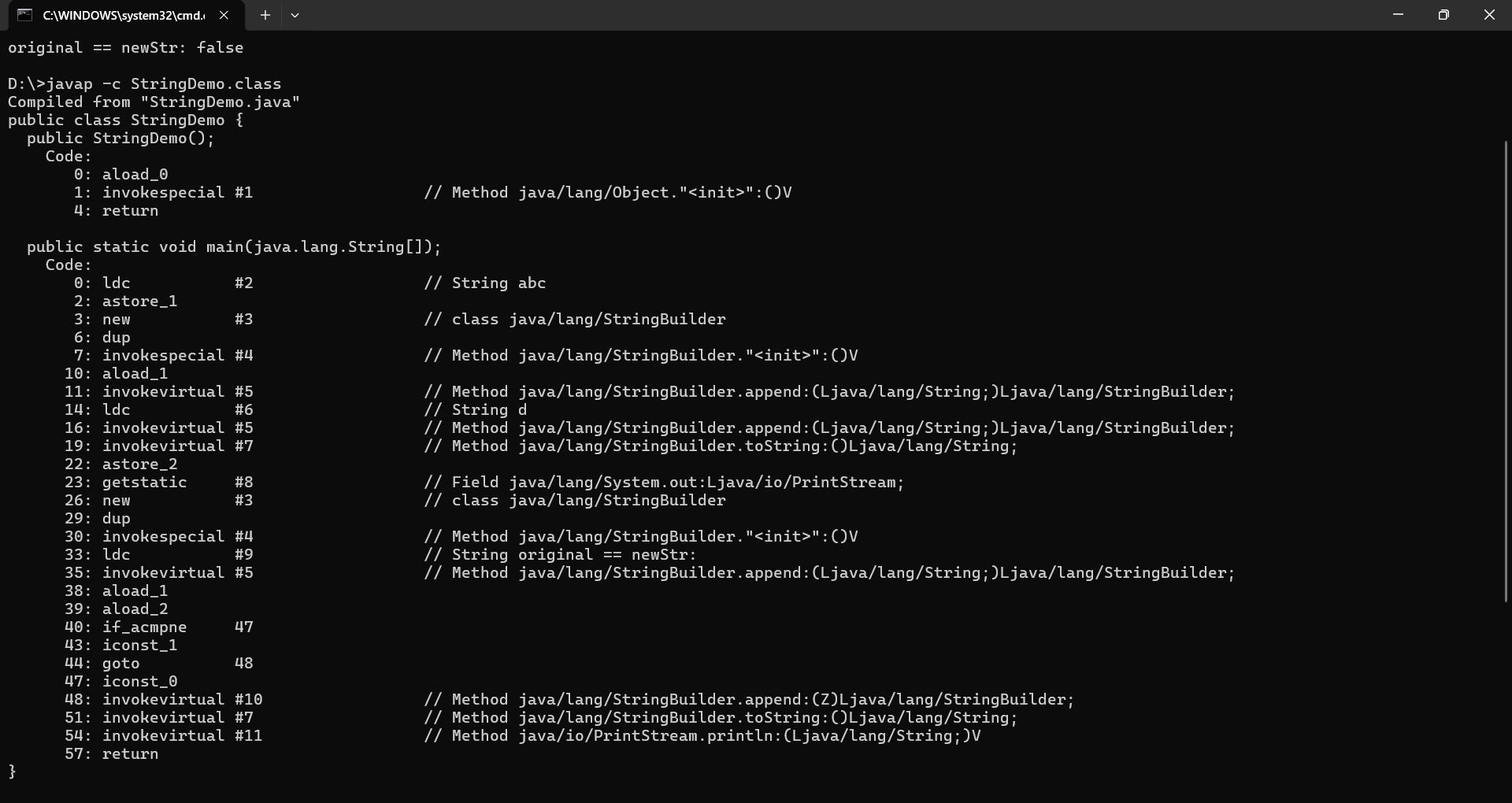
从反编译结果来看,当执行 original + "d" 时,由于original是运行期变量而非编译期常量,Java 编译器会自动做性能优化:先创建一个 StringBuilder 实例,调用其无参构造初始化容量为 16 的可变字符数组;接着依次调用 append(original) 和 append("d"),将原字符串 "abc" 和拼接的 "d" 逐个追加到 StringBuilder 的字符数组中(过程中会检查数组容量,足够则直接复制字符,不足则扩容);拼接完成后调用 StringBuilder.toString() 方法,该方法会通过 new String(value, 0, count) 创建一个新的 String 对象,这个新对象会复制 StringBuilder 中的字符数组(避免共享可变数组),并存储在堆内存的非常量池区域;最终这个新 String 对象的引用被赋值给 newStr。
整个过程中,原字符串 original 指向的常量池 "abc" 实例从未被修改,而 newStr 指向的是堆中新建的 "abcd" 实例,二者引用地址不同,因此 original == newStr 返回 false。
StringBuilder.toString() 源码:

字符串的构造器
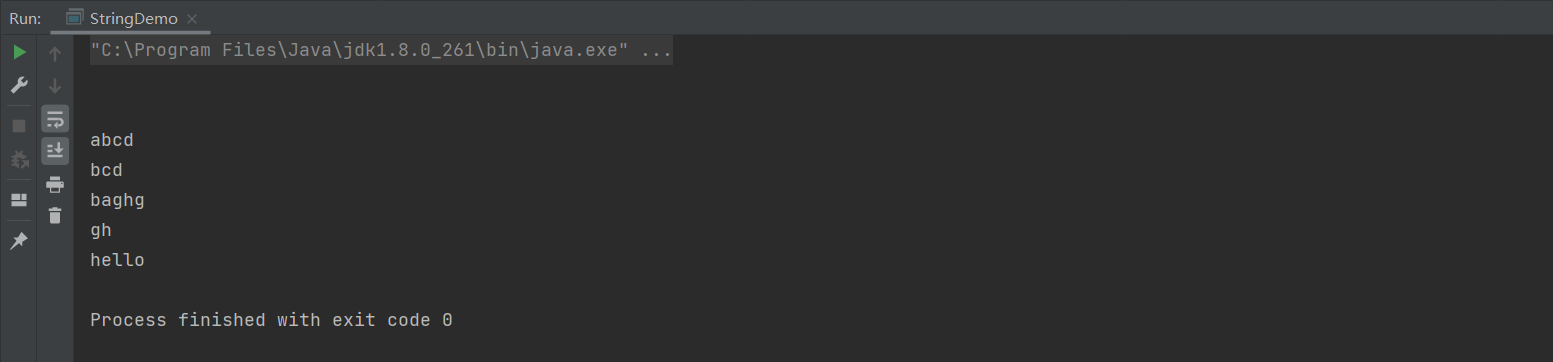
java
public class StringDemo {
public static void main(String[] args) {
String s1 = "";
System.out.println(s1);
String s = new String();
System.out.println(s);
byte[] bs = {97,98,99,100};
//通过字节数组创建字符串
String s2 = new String(bs);
System.out.println(s2);
//通过字节数组创建字符串,offset就是索引的开始位置,length取的长度
String s3 = new String(bs, 1, 3);
System.out.println(s3);
char[] cs = {'b','a','g','h','g'};
//通过字符的数组来创建一个字符串
String s4 = new String(cs);
System.out.println(cs);
//通过字符数组创建字符串,offset就是索引的开始位置,length取的长度
String s5 = new String(cs, 2, 2);
System.out.println(s5);
//通过字符串的常量创建字符串的对象
String s6 = new String("hello");
System.out.println(s6);
}
}
String s2 = "abc"; 与 String s1 = new String ("abc"); 有什么区别?
- String s2 = "abc":类加载时检查字符串常量池,无则在常量池创建 "abc" 实例,有则直接复用,s2 指向常量池的 "abc" 实例。
- String s1 = new String("abc"):
如果没有在字符串的常量池中没有"abc":运行期会先在常量池创建 1 个 "abc" 实例,再在堆中创建 1 个独立的 String 实例,堆中的实例引用字符串常量池中的实例,s1 指向堆中的实例;
如果没有在字符串的常量池中有"abc":仅在堆中创建 1 个独立的 String 实例,堆中的实例来引用字符串常量池中的实例,s1 指向堆实例;
核心区别:s2 指向常量池的复用实例,s1 指向堆的独立实例,二者引用地址不同,但内容相同。
这里我们需要注意的是通过 new 创建出来的 String 对象一定不是字符串常量,而是堆内存中的对象。
字符串的值相等性判定
java.lang.String 重写了 java.lang.Object 的 equals() 方法,源码如下:
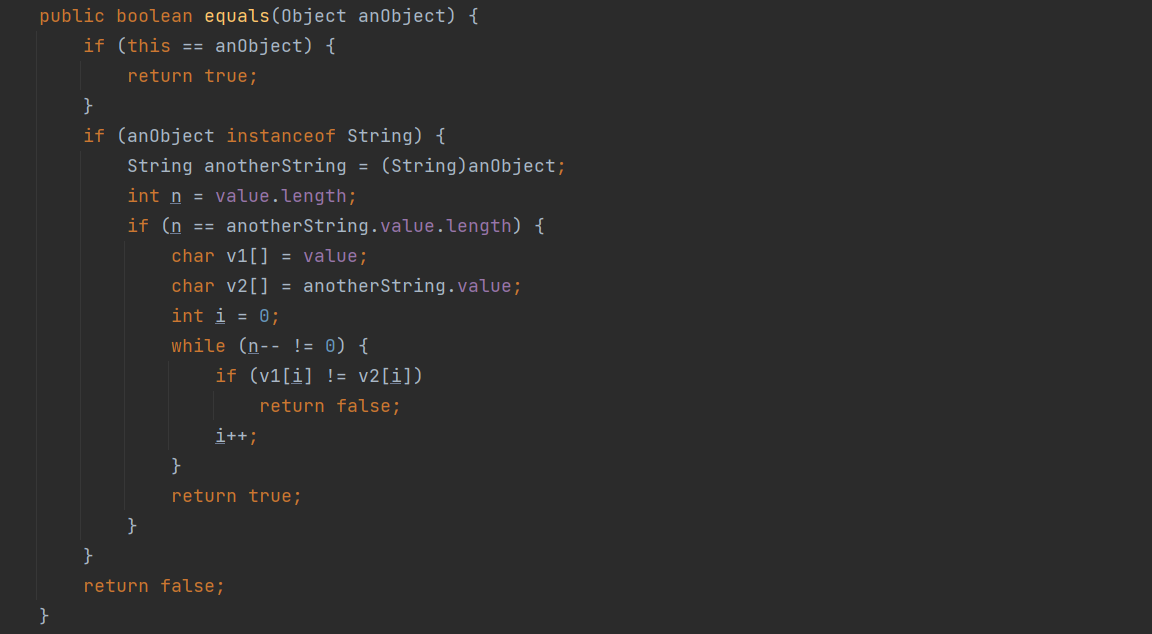
java.lang.String 重写了 java.lang.Object 类的 equals () 方法,其核心设计目标是判定两个字符串的值相等性(字符序列是否完全一致),而非 Object 类默认的引用同一性(是否指向同一个对象)。

调用 strA.equals(strB) 时,方法会按先快速校验后精准比对的逻辑依次执行以下不可逆步骤,任一环节不满足则立即终止流程并返回结果:
- 引用同一性快速校验
方法首先判定调用方 strA 与入参 strB 是否为同一个对象(判定逻辑:this == anObject):
若判定结果为 true,无需执行后续内容比对,直接返回结果,若判定结果为 false,进入下一步校验。 - 入参合法性校验
方法通过 anObject instanceof String 判定入参 strB 的合法性:
若 instanceof 运算符的左操作数为 null 时,无论右操作数是何种引用类型,运算结果必然为 false;
若 strB 不是 String 类型那么 anObject instanceof String 结果为 false,方法立即终止并返回 false;
若 strB 是 String 类型且非 null,则进入下一步校验。 - 字符序列长度校验
方法先获取调用方 strA 底层存储的字符序列长度,并与入参 strB 的字符序列长度做一致性比对:
若二者长度不一致,方法立即终止并返回 false,若二者长度完全一致,进入下面的逐位精准校验。 - 逐字符 / 字节精准校验
对字符序列进行逐位精准比对,判定所有位置的字符是否完全匹配:
基于底层 char\[\] value 数组,逐位比较对应位置字符的 Unicode 码点值,比对过程中,只要发现任意一位的字符不匹配,方法立即终止并返回 false,若所有位的字符均匹配,方法返回 true。
空字符串和null的区别
| 类型 | String str = null; |
String str = ""; |
|---|---|---|
| 本质 | 引用变量 str 没有指向任何对象(空引用) | 引用变量 str1 指向一个合法的 String 对象(空字符序列) |
| 归属 | null 是所有引用类型的默认值 | 空字符串是 String 类的编译期常量 |
| 语义 | 表示不存在、未初始化、无结果 | 表示存在但内容为空 |
空字符串对应的引用是有效引用:
该引用指向内存中字符串常量池内一个完整且合法的 String 对象,该对象的核心特征是内部封装的字符序列长度为 0;同时 JVM 保证全局所有空字符串字面量均指向常量池中同一个实例,因此所有空字符串对应的引用共享唯一的内存地址。
null 表示引用类型变量的空引用状态:
持有 null 的引用变量不指向任何内存区域,JVM 不会为该变量关联的对象分配任何内存空间;对空引用直接调用任意实例方法必然抛出 NullPointerException(空指针异常);此外,null 是所有引用数据类型变量未显式初始化时的默认值。
针对字符串既非null也非空串的判断逻辑,需依赖短路逻辑运算符&&的特性:
Java中&&是短路与,若左侧表达式结果为false,右侧表达式会直接被短路,因此必须将 str != null 放在判断条件的左侧
java
if (str != null && str.length() != 0) {
// 逻辑处理
}