Apache Dubbo 深度技术架构解析
1. 整体介绍
1.1 项目概况与现状
Apache Dubbo 是一个由 Apache 软件基金会托管的开源高性能 RPC(远程过程调用)与微服务框架。项目托管于 GitHub,地址为 github.com/apache/dubb... GitHub 统计数据(Star、Fork 数)反映了其在开源社区的广泛采纳度和活跃度,是构建分布式系统,特别是微服务架构的主流技术选型之一。
1.2 核心功能与架构
Dubbo 的核心设计围绕服务治理展开,采用经典的"消费者-提供者"模型,并通过注册中心实现解耦。其架构简化视图如下:
其主要功能模块包括:
- 通信协议:支持 Triple(gRPC 兼容)、Dubbo2、REST 等。
- 服务注册与发现:集成多种注册中心(Nacos、Zookeeper 等)。
- 流量治理:负载均衡、路由、限流、熔断、降级。
- 可观测性:指标(Metrics)、追踪(Tracing)、日志。
- 配置管理:动态配置更新。
- 扩展机制:基于 SPI 的高度可扩展架构。
1.3 面临问题与目标场景
Dubbo 主要解决企业级应用在向分布式、微服务架构演进过程中遇到的典型问题:
- 服务间通信复杂度:直接 socket 通信或简单的 HTTP 客户端难以处理连接管理、超时、重试、序列化等,代码侵入性强且易错。
- 服务动态治理缺失:服务实例扩缩容后,调用方无法自动感知,缺乏动态路由、负载均衡和流量保护能力。
- 运维可观测性差:服务间调用链路过长,问题定位困难,缺乏系统性的监控指标。
- 异构系统集成难:不同语言开发的服务之间需要统一的通信协议和治理标准。
对应人群与场景:适用于中大型互联网企业、金融机构等需要构建高可用、可扩展、易维护的分布式服务化体系的技术团队。典型场景包括电商系统、支付清算、用户中心等核心业务的服务化拆分。
1.4 解决方案与演进优势
传统方式:早期常基于 HTTP+JSON/RESTful API 或自行封装 TCP 协议进行服务间调用,配合静态配置或简单的服务发现组件(如 Ribbon + Eureka)。治理功能(如限流)需在每个服务中重复实现。
Dubbo 新方式:
- 透明化 RPC:提供像调用本地方法一样的远程调用体验,框架屏蔽底层网络通信细节。
- 中心化治理:将流量控制、服务发现等能力抽象为独立的中心化组件(注册中心、配置中心),并通过统一控制台(dubbo-admin)进行管理,规则动态生效。
- 生态集成:与 Spring/Spring Boot 深度集成,提供 Starter,降低使用门槛;支持多协议、多注册中心,具备良好的生态兼容性。
核心优势 :将分布式服务的通信 、治理 和观测三大关注点从业务逻辑中彻底解耦,通过专业化的中间件提供标准化、平台化的解决方案,提升了开发效率和系统可靠性。
1.5 商业价值逻辑估算
商业价值可从"成本节约"和"效益提升"两个维度进行逻辑推演:
- 成本节约 :
- 开发成本:一个中等规模(50+微服务)的系统,若自研具备同等治理能力的 RPC 框架,至少需要 3-5 名高级工程师 6-12 个月的持续投入。按市场人力成本估算,直接研发成本可高达数百万元。采用 Dubbo 可将此成本降至近乎为零(仅学习与集成成本)。
- 维护成本:自研框架的长期维护、升级、Bug 修复成本高昂。Dubbo 由开源社区和 Apache 基金会支撑,维护成本被分摊。
- 效益提升 :
- 稳定性收益:内置的熔断、限流、集群容错等机制能有效防止局部故障扩散,降低系统级联故障风险,直接关联业务连续性和收入保障。
- 运维效率:可视化的控制台和完善的可观测性工具链,能大幅缩短故障平均恢复时间(MTTR)。
- 标准化收益:统一技术栈,降低团队间协作和人员流动带来的知识传递成本。
估算逻辑:价值 ≈ (自研同等能力框架的人力与时间成本 + 避免的系统宕机潜在损失) - (采用 Dubbo 的集成、学习与云资源成本)。对于大多数企业,此差值通常为正且显著。
2. 详细功能拆解
从产品与技术结合视角,Dubbo 的核心功能可拆解为以下层次:
| 功能层级 | 产品视角 | 技术视角(核心设计) |
|---|---|---|
| 接入层 | 快速启动,开箱即用 | Spring Boot Starter 自动装配;@DubboService / @DubboReference 注解驱动编程模型。 |
| 通信层 | 支持多种调用方式,兼容异构系统 | 协议扩展 SPI (Protocol);序列化扩展 SPI (Serialization);支持 Triple (基于 HTTP/2+gRPC)、Dubbo2 等协议。 |
| 治理层 | 服务可管可控,规则动态生效 | 路由链 (Router)、负载均衡 (LoadBalance)、集群容错 (ClusterInvoker)、过滤器链 (Filter) 组成的调用流程;规则通过配置中心动态推送。 |
| 核心层 | 服务注册与发现,调用透明代理 | 注册中心扩展 SPI (RegistryFactory);代理工厂 (ProxyFactory) 生成 Consumer 存根和 Provider 调用器;Invoker 为核心调用抽象。 |
| 观测层 | 运行状态可视化,问题可追溯 | Metrics SPI 收集指标;Tracing SPI 集成链路追踪;指标数据上报至监控中心。 |
| 扩展层 | 可按需定制,适应特殊场景 | 基于 Dubbo SPI 的微内核架构,所有核心组件均可扩展或替换。 |
关键技术设计:
- URL 统一模型:Dubbo 使用 URL(统一资源定位符)作为配置信息的标准格式,贯穿于注册、订阅、调用等全流程,实现了配置的标准化和传递的一致性。
- Invoker 调用抽象 :
Invoker是 Dubbo 的核心抽象,代表一个可执行对象。无论是本地调用、远程调用,还是集群调用,都被统一为Invoker,从而在调用链上可以方便地插入各种过滤器和拦截器,实现治理逻辑。 - Directory 与 Router :
Directory维护了某个服务的所有可用Invoker列表。Router则根据预设规则(如标签路由、权重)对此列表进行过滤和排序,实现精细化流量调度。
3. 技术难点挖掘
- 高性能网络通信与序列化:在保证功能丰富的同时,需设计低延迟、高吞吐的通信协议(如 Triple 协议基于 HTTP/2 的多路复用)和高效的序列化/反序列化机制(如 Hessian2、Kryo、Protobuf)。
- 动态治理下的数据一致性:服务实例列表、路由规则等数据在注册中心、消费者、提供者之间需要保证最终一致性,且在网络分区等异常情况下要有妥善的处理策略,避免大规模路由错误。
- 高度扩展性与兼容性平衡:作为基础框架,需要提供强大的 SPI 扩展能力,同时又要保证不同版本间、不同扩展实现间的兼容性,这对模块划分和接口设计提出了很高要求。
- 透明代理与上下文传递:如何在复杂的调用链(可能经过多级过滤器、路由、集群容错)中,无损地传递调用上下文(如跟踪 ID、隐式参数),且对开发者透明,是一个工程挑战。
- 云原生适配:如何与 Kubernetes、Service Mesh(如 Istio)等云原生基础设施无缝集成,实现从"框架治理"到"基础设施治理"的平滑演进。
4. 详细设计图
4.1 核心架构图
以下为 Dubbo 核心模块交互的逻辑架构图:
4.2 核心调用链路序列图
一次 Dubbo RPC 调用的简化序列图如下:
4.3 核心类关系图(简略)
围绕 Invoker 和 URL 的核心类关系:
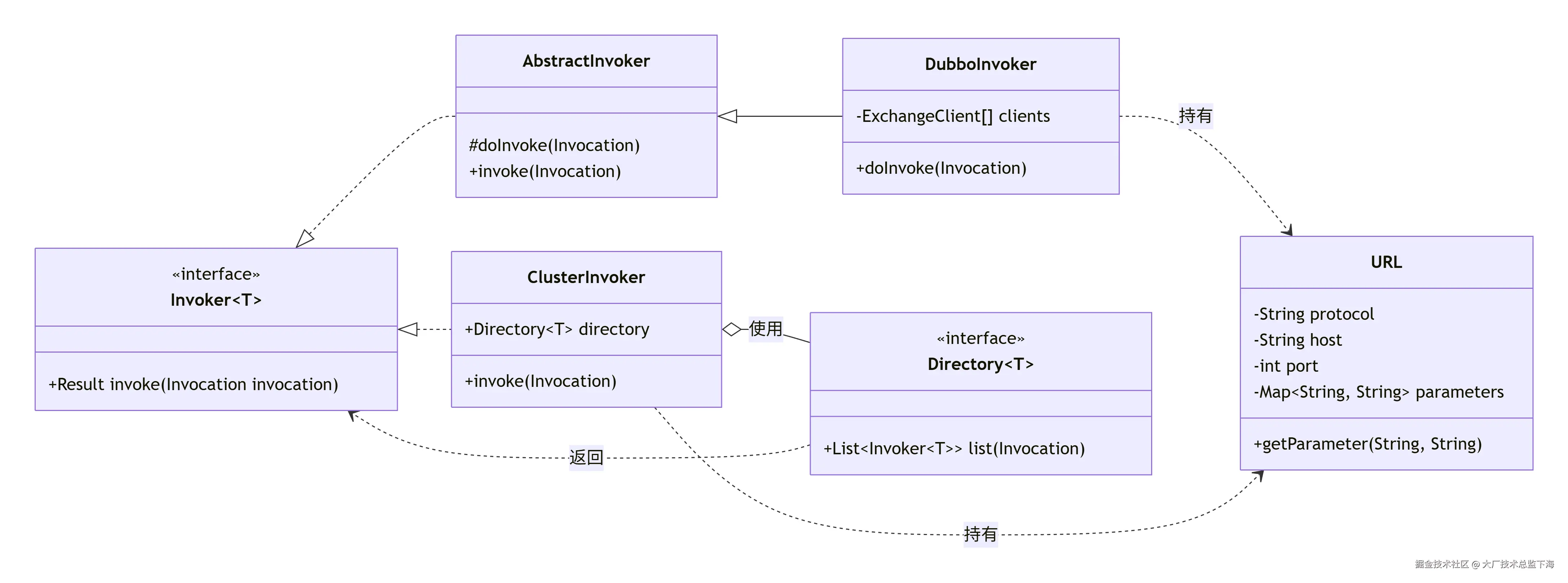 说明 :
说明 :Invoker 是执行单元;Directory 管理 Invoker 集合;ClusterInvoker 包含集群调用逻辑;DubboInvoker 是具体的远程通信实现;URL 是贯穿全局的配置载体。
5. 核心函数与代码解析
5.1 核心 SPI 与配置:从 pom.xml 看模块化
项目根 pom.xml 揭示了 Dubbo 的高度模块化设计。<modules> 部分定义了数十个子模块,如 dubbo-rpc, dubbo-cluster, dubbo-registry 等,每个模块职责单一,通过 Maven 依赖进行组装。
关键配置解析:
xml
<!-- 使用 revision 属性统一管理版本,便于多模块协同发布 -->
<version>${revision}</version>
<properties>
<revision>3.3.7-SNAPSHOT</revision>
</properties>
<!-- 依赖管理:通过 BOM (Bill of Materials) 统一管理所有子模块和第三方依赖的版本 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-dependencies-bom</artifactId>
<version>${project.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<!-- 条件化模块引入:根据 JDK 版本动态引入支持新特性的模块 -->
<profiles>
<profile>
<id>jdk-version-ge-17</id>
<activation><jdk>[17,)</jdk></activation>
<modules>
<module>dubbo-spring-boot-project/dubbo-spring-boot-3-autoconfigure</module>
<module>dubbo-plugin/dubbo-spring6-security</module>
<module>dubbo-plugin/dubbo-mutiny</module> <!-- Reactive支持 -->
</modules>
</profile>
</profiles>设计要点 :这种结构支持"按需引入",用户可以根据项目需要只依赖 dubbo-spring-boot-starter,或精细引入 dubbo-rpc-triple 等特定模块,有效控制应用包大小。
5.2 服务提供者启动示例
提供的 ProviderApplication.java 是一个典型的 Spring Boot 启动类:
java
package org.apache.dubbo.springboot.demo.servlet;
import org.apache.dubbo.config.spring.context.annotation.EnableDubbo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@EnableDubbo // 关键注解:启用 Dubbo 的注解驱动及自动配置
public class ProviderApplication {
public static void main(String[] args) {
SpringApplication.run(ProviderApplication.class, args);
}
}@EnableDubbo:该注解是 Dubbo 与 Spring 集成的关键。它内部会导入DubboComponentScanRegistrar等配置类,完成以下工作:- 扫描被
@DubboService注解标记的类,将其注册为 Spring Bean 并导出为 Dubbo 服务。 - 扫描被
@DubboReference注解标记的字段,为其注入一个远程服务的代理对象。 - 根据配置文件(
application.yaml)初始化ApplicationConfig,RegistryConfig,ProtocolConfig等核心配置 Bean。
- 扫描被
5.3 核心调用抽象 Invoker.invoke
Invoker.invoke 方法是整个调用链的起点和核心。以下为简化逻辑:
java
// Invoker 接口定义
public interface Invoker<T> {
// 执行一次调用, invocation 封装了方法名、参数类型、实际参数值等。
Result invoke(Invocation invocation) throws RpcException;
// 获取该 Invoker 关联的 URL (配置信息)
URL getUrl();
// 判断 Invoker 是否可用
boolean isAvailable();
// 销毁 Invoker
void destroy();
}
// 一个典型的 AbstractInvoker 实现片段(示意)
public abstract class AbstractInvoker<T> implements Invoker<T> {
@Override
public Result invoke(Invocation inv) throws RpcException {
// 1. 预处理:检查服务状态,设置调用ID等附加信息
beforeInvoke(inv);
// 2. 执行具体的调用(由子类实现,如远程调用或本地调用)
Result result = doInvoke(inv);
// 3. 后处理:结果处理,异常转换
afterInvoke(result, inv);
return result;
}
// 模板方法,子类需实现具体的调用逻辑
protected abstract Result doInvoke(Invocation invocation) throws Throwable;
}Invocation:封装了单次调用的所有信息,是一个数据契约对象。Result:封装调用结果,包含返回值、异常状态等。- 设计模式 :这里使用了模板方法模式 。
AbstractInvoker定义了invoke的通用流程框架(前后处理),而将具体的网络通信等差异点留给DubboInvoker、HttpInvoker等子类实现。
5.4 集群容错与负载均衡(简化流程)
在 ClusterInvoker(如 FailoverClusterInvoker)中,核心调用逻辑示意如下:
java
public Result invoke(final Invocation invocation) throws RpcException {
// 1. 从 Directory 获取所有可用的服务提供者 Invoker 列表
List<Invoker<T>> invokers = directory.list(invocation);
// 2. 根据配置的负载均衡策略(如 RandomLoadBalance)选择一个 Invoker
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
Invoker<T> selectedInvoker = loadbalance.select(invokers, ..., invocation);
// 3. 进行调用,如果失败且配置了重试,则选择下一个 Invoker 再次调用(容错逻辑)
for (int i = 0; i < retries + 1; i++) {
try {
return selectedInvoker.invoke(invocation);
} catch (RpcException e) {
if (shouldRetry(e, i)) {
// 重试前,重新获取列表(可能已变化),并重新选择(排除已失败的)
invokers = reselectExcluded(invokers, selectedInvoker);
selectedInvoker = loadbalance.select(invokers, ..., invocation);
continue;
}
throw e;
}
}
// ...
}此流程清晰展示了 Dubbo 如何将服务发现 (directory.list)、负载均衡 和集群容错(重试机制)串联在一次 RPC 调用中,体现了其治理能力的落地。
总结
Apache Dubbo 通过清晰的分层架构、以 Invoker 和 URL 为核心的一致抽象、以及基于 SPI 的强大扩展机制,成功构建了一个功能完备、性能良好且高度可定制的企业级 RPC 与微服务治理框架。它不仅仅是通信工具,更是一套提升分布式系统可维护性、可观测性和稳定性的系统性解决方案。其成功源于对分布式服务核心痛点的准确把握,以及工程化上的精良设计与持续迭代。对于面临服务化挑战的技术团队而言,深入理解其架构设计,能更好地驾驭并发挥其最大价值。