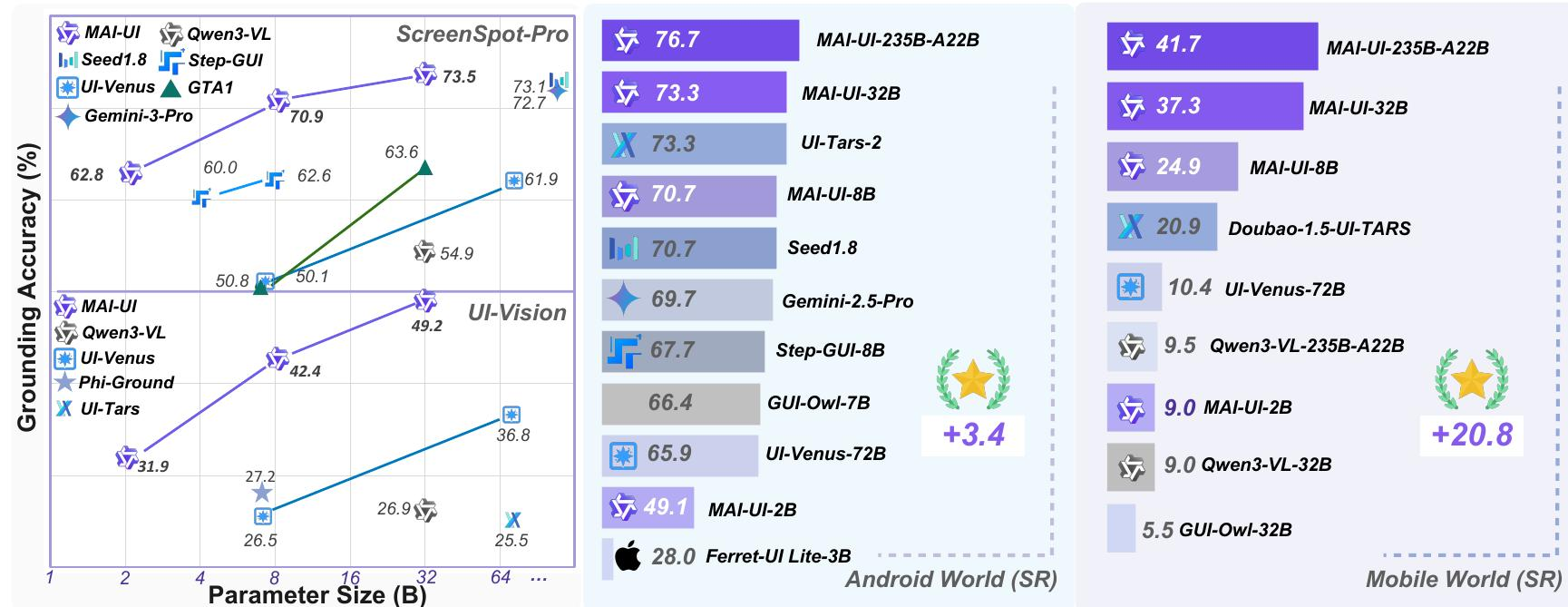
摘要
我们确定了实际部署的四个关键挑战:缺乏原生代理-用户交互,仅限UI操作的局限性,缺乏实用的部署架构,以及动态环境中的脆弱性。MAI-UI通过一种统一的方法来解决这些问题:一个自我进化的数据管道,扩展导航数据以包括用户交互和MCP工具调用;一个原生设备-云协作系统,通过任务状态来路由执行;以及一个在线RL框架,具有先进的优化,可以扩展并行环境和上下文长度。
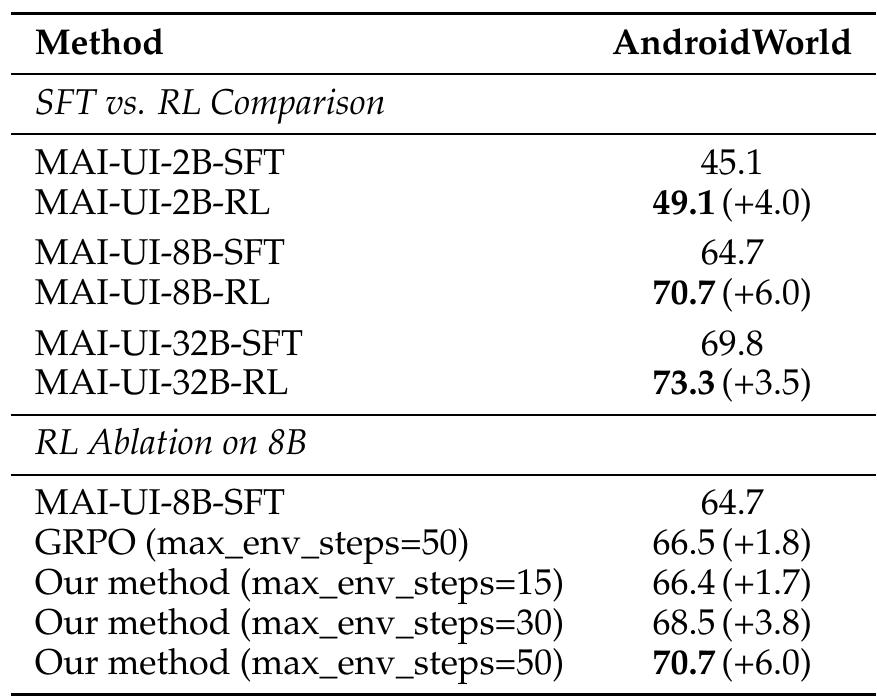
我们的在线RL实验表明,将并行环境从32扩展到512(+5.2个点)以及将环境步数预算从15增加到50(+4.3个点)可以获得显著收益。最后,原生设备-云协作系统将设备上的性能提高了33%,减少了超过40%的云模型调用,并保护了用户隐私。
备注:环境步数预算是什么概念?
1 引言
尽管技术飞速发展,但当今的 GUI 代理在实践中仍不足以实现可靠、稳健和安全的部署。我们重点强调了几个需要解决的开放性挑战,以弥合这一差距。(1)代理-用户交互 :现有系统通常针对端到端执行进行优化,然而,现实世界中的用户指令通常是模糊或不完整的。为了确保与用户意图保持一致,代理必须主动提出澄清问题,收集缺失的细节,并征求对敏感操作的同意 。因此,有效的代理-用户交互是一项至关重要但经常被忽视的能力。(2)超越仅限 UI 的操作 :仅依赖 UI 操作会带来两个问题:(i)漫长的、多步骤的 UI 操作序列会增加每一步错误的脆弱性,并放大错误传播;(ii)它将代理限制在 UI 可访问的任务中。通过模型上下文协议(MCP)集成外部工具提供了结构化的快捷方式,可以将漫长而脆弱的 UI 操作序列压缩为几个 API 调用,并解锁以前在移动设备上不可行的任务。例如,通过 MCP 工具,移动代理可以操作 GitHub 存储库 ,将传统的仅限桌面工作流程引入移动设备。(3)原生设备-云协作能力 :当前的 GUI 代理通常分为轻量级的、设备上的变体或只能用作云服务的大型模型。然而,仅限云的解决方案会带来隐私风险、更高的成本以及对网络连接的依赖,而仅限设备上的方法则受到模型容量和能力的限制。因此,基础 GUI 代理缺乏原生设备-云协作能力,无法实现隐私感知和成本效益的路由以及无缝切换。(4)对动态环境的鲁棒性:在静态的、预先收集的轨迹上训练的代理通常会过度拟合特定的界面模式,并在领域外场景中表现不佳。在实践中,现实世界的 GUI 是高度动态的:布局在应用程序版本和设备之间各不相同,并且可能会意外出现弹出窗口或权限对话框。如果没有在训练中接触到动态环境,代理的泛化能力会很差,并且仍然容易受到现实世界不可预测性的影响。
为了增强GUI代理的能力并解决实际部署中的这些挑战,我们引入了MAI-UI,这是一个用于通用GUI基础和移动导航的基础GUI代理。
- 智能体-用户交互和MCP增强。为了使GUI智能体具备用户交互和MCP工具使用能力,我们引入了一个自演进的数据管道 ,该管道整合了通用导航以及这两种能力的训练数据。该数据管道使用三种数据源迭代更新模型和训练语料库:拒绝采样轨迹、手动标注轨迹和自动智能体推演。动作空间也进行了扩展,以允许智能体在UI操作、用户互动和MCP工具使用之间进行选择。
- 设备-云协同系统。为了实现真实的部署,MAI-UI 引入了一种开创性的原生设备-云协同系统,该系统可以根据任务执行状态和数据敏感性动态选择设备端或云端执行。该系统由一个充当 GUI 代理和轨迹监视器的本地 GUI 代理、一个高容量的云 GUI 代理以及一个在本地和云代理之间保持一致信息交换的本地统一轨迹内存组成。
- 动态环境中的强化学习。MAI-UI 将在线强化学习作为核心训练组件 ,从而能够通过与动态环境的交互进行改进。我们的系统级优化可扩展到 500 多个 GUI 环境以进行并行展开。我们还支持异步展开和混合并行以进行训练,从而能够在长时程 GUI 任务上进行训练,最多可进行 50 个交互步骤。此训练阶段可产生改进的 GUI。
导航精度和对现实世界不可预测性的更强鲁棒性。
2 MAI-UI
本节详细介绍了MAI-UI的方法论。我们的方法整合了(i)GUI接地的训练范式,(ii)一个自我演化的轨迹数据管道,(iii)代理-用户交互和MCP工具增强的训练,(iv)在线强化学习,以及(v)一个原生设备-云协作系统。图2展示了MAI-UI的一个演示轨迹。
2.1 系统概述
两个任务:grounding和GUI 导航能力
动作空间:
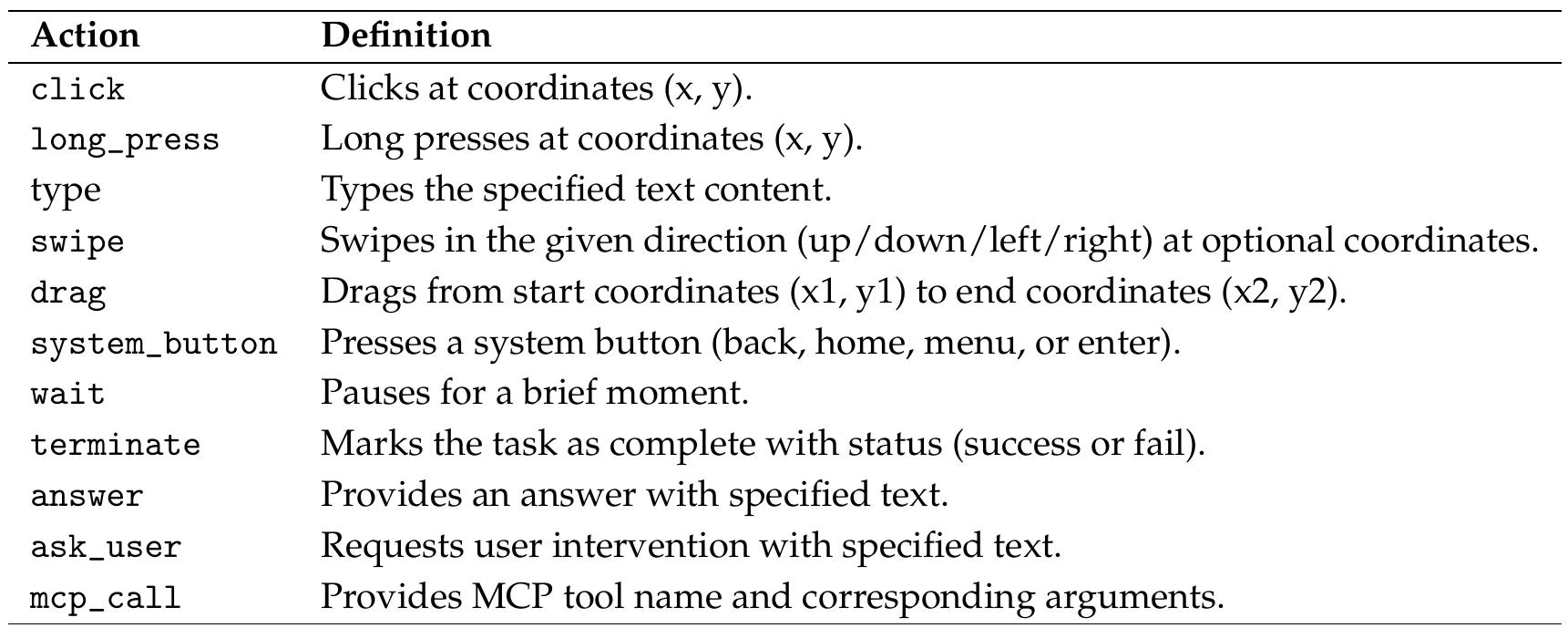
grounding提示词:
"""You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
For each function call, return the thinking process in <thinking> </thinking> tags, and a json object with function name and arguments within <tool_call></tool_call> XML tags:
```
<thinking>
...
</thinking>
<tool_call>
{"name": "mobile_use", "arguments": <args-json-object>}
</tool_call>
```
## Action Space
{"action": "click", "coordinate": [x, y]}
{"action": "long_press", "coordinate": [x, y]}
{"action": "type", "text": ""}
{"action": "swipe", "direction": "up or down or left or right", "coordinate": [x, y]} # "coordinate" is optional. Use the "coordinate" if you want to swipe a specific UI element.
{"action": "open", "text": "app_name"}
{"action": "drag", "start_coordinate": [x1, y1], "end_coordinate": [x2, y2]}
{"action": "system_button", "button": "button_name"} # Options: back, home, menu, enter
{"action": "wait"}
{"action": "terminate", "status": "success or fail"}
{"action": "answer", "text": "xxx"} # Use escape characters \\', \\", and \\n in text part to ensure we can parse the text in normal python string format.
## Note
- Write a small plan and finally summarize your next action (with its target element) in one sentence in <thinking></thinking> part.
- Available Apps: `["Camera","Chrome","Clock","Contacts","Dialer","Files","Settings","Markor","Tasks","Simple Draw Pro","Simple Gallery Pro","Simple SMS Messenger","Audio Recorder","Pro Expense","Broccoli APP","OSMand","VLC","Joplin","Retro Music","OpenTracks","Simple Calendar Pro"]`.
You should use the `open` action to open the app as possible as you can, because it is the fast way to open the app.
- You must follow the Action Space strictly, and return the correct json object within <thinking> </thinking> and <tool_call></tool_call> XML tags.
""".strip()非思考模式:
MAI_MOBILE_SYS_PROMPT_NO_THINKING = """You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
```
<tool_call>
{"name": "mobile_use", "arguments": <args-json-object>}
</tool_call>
```
## Action Space
{"action": "click", "coordinate": [x, y]}
{"action": "long_press", "coordinate": [x, y]}
{"action": "type", "text": ""}
{"action": "swipe", "direction": "up or down or left or right", "coordinate": [x, y]} # "coordinate" is optional. Use the "coordinate" if you want to swipe a specific UI element.
{"action": "open", "text": "app_name"}
{"action": "drag", "start_coordinate": [x1, y1], "end_coordinate": [x2, y2]}
{"action": "system_button", "button": "button_name"} # Options: back, home, menu, enter
{"action": "wait"}
{"action": "terminate", "status": "success or fail"}
{"action": "answer", "text": "xxx"} # Use escape characters \\', \\", and \\n in text part to ensure we can parse the text in normal python string format.
## Note
- Available Apps: `["Camera","Chrome","Clock","Contacts","Dialer","Files","Settings","Markor","Tasks","Simple Draw Pro","Simple Gallery Pro","Simple SMS Messenger","Audio Recorder","Pro Expense","Broccoli APP","OSMand","VLC","Joplin","Retro Music","OpenTracks","Simple Calendar Pro"]`.
You should use the `open` action to open the app as possible as you can, because it is the fast way to open the app.
- You must follow the Action Space strictly, and return the correct json object within <thinking> </thinking> and <tool_call></tool_call> XML tags.
""".strip()用户提问提示词
# Placeholder prompts for future features
MAI_MOBILE_SYS_PROMPT_ASK_USER_MCP = Template(
"""You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
For each function call, return the thinking process in <thinking> </thinking> tags, and a json object with function name and arguments within <tool_call></tool_call> XML tags:
```
<thinking>
...
</thinking>
<tool_call>
{"name": "mobile_use", "arguments": <args-json-object>}
</tool_call>
```
## Action Space
{"action": "click", "coordinate": [x, y]}
{"action": "long_press", "coordinate": [x, y]}
{"action": "type", "text": ""}
{"action": "swipe", "direction": "up or down or left or right", "coordinate": [x, y]} # "coordinate" is optional. Use the "coordinate" if you want to swipe a specific UI element.
{"action": "open", "text": "app_name"}
{"action": "drag", "start_coordinate": [x1, y1], "end_coordinate": [x2, y2]}
{"action": "system_button", "button": "button_name"} # Options: back, home, menu, enter
{"action": "wait"}
{"action": "terminate", "status": "success or fail"}
{"action": "answer", "text": "xxx"} # Use escape characters \\', \\", and \\n in text part to ensure we can parse the text in normal python string format.
{"action": "ask_user", "text": "xxx"} # you can ask user for more information to complete the task.
{"action": "double_click", "coordinate": [x, y]}
{% if tools -%}
## MCP Tools
You are also provided with MCP tools, you can use them to complete the task.
{{ tools }}
If you want to use MCP tools, you must output as the following format:
```
<thinking>
...
</thinking>
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
```
{% endif -%}
## Note
- Available Apps: `["Contacts", "Settings", "Clock", "Maps", "Chrome", "Calendar", "files", "Gallery", "Taodian", "Mattermost", "Mastodon", "Mail", "SMS", "Camera"]`.
- Write a small plan and finally summarize your next action (with its target element) in one sentence in <thinking></thinking> part.
""".strip()
)grounding提示词
MAI_MOBILE_SYS_PROMPT_GROUNDING = """
You are a GUI grounding agent.
## Task
Given a screenshot and the user's grounding instruction. Your task is to accurately locate a UI element based on the user's instructions.
First, you should carefully examine the screenshot and analyze the user's instructions, translate the user's instruction into a effective reasoning process, and then provide the final coordinate.
## Output Format
Return a json object with a reasoning process in <grounding_think></grounding_think> tags, a [x,y] format coordinate within <answer></answer> XML tags:
<grounding_think>...</grounding_think>
<answer>
{"coordinate": [x,y]}
</answer>
""".strip()2.2 GUI 基础与感知
GUI 的基础能力包括理解和感知,这使得智能体能够理解屏幕布局,并能根据自然语言指令定位正确的 UI 元素。本节将介绍我们的数据管道和训练方法,用于构建这些能力。
2.2.1 数据管道
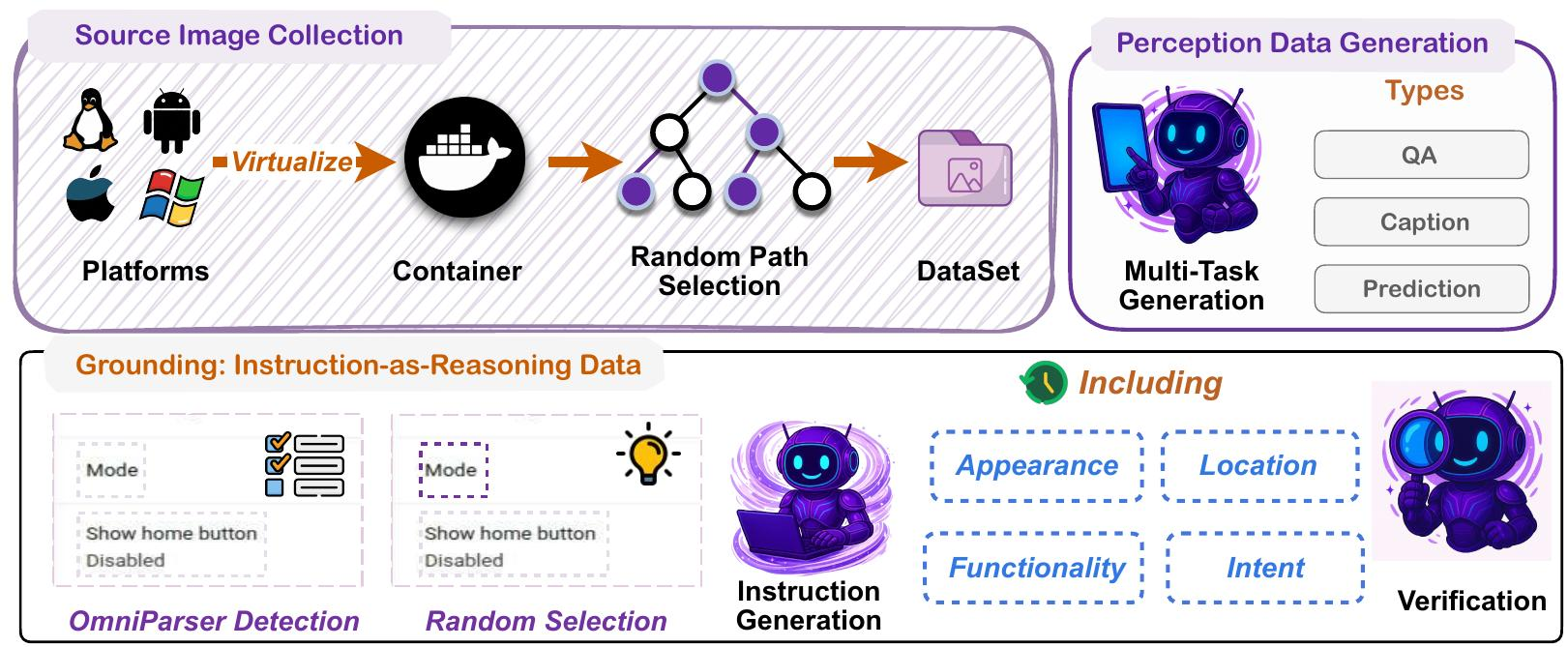
如Figure 3所示,除了开源数据集,我们的流程还从真实的GUI环境中收集屏幕截图,以构建一个强大的GUI代理。这个过程产生了多任务感知数据和多视角 grounding 数据。
数据收集。为了从真实场景中收集多样化的GUI数据,我们不仅使用了诸如JEDI (Xie et al., 2025a) 和 OS-Altas (Wu et al., 2024) 等开源数据集,还在容器化环境中虚拟化了操作系统。我们采用了MLLM引导的探索策略来导航这些环境 。在每一步中,我们都要求MLLM从当前状态识别有效的操作。此过程不断改变界面状态并产生新的屏幕截图。最后,我们使用a11y树或OmniParser V2 (Lu et al., 2024b) 来精确定位UI元素。
备注:我们应该也是基于大模型探索,提示词是否可以继续优化? 这两个开源数据可以关注,但不一定需要训练。
感知数据生成。为了促进训练数据的多样性,对于每个屏幕截图,我们随机选择一到三个UI元素作为输入,并提示MLLM基于这些元素生成各种任务,包括问答、Caption和状态预测。这些多样化的任务使模型能够对界面形成全面的理解,特别是增强其在语义理解、关系理解和布局理解方面的能力。
备注:状态预测、图片描述是否就是我们目前做的,问答? 可以参考提到的文章UI-Ins
grounding数据生成。正如我们在之前的UI-Ins工作(Chen et al., 2025)中所展示的那样,指令的多样性和正确性对于GUI基础至关重要,但往往被忽视:
- 指令质量:在开源的 grounding 数据集中,大约 23.3% 的指令存在质量问题,这可能会在训练期间对模型性能产生积极的损害。
- 指令多样性:当在多样化的指令视角 上进行训练时,性能会显著提高;当模型学会选择在不同场景下合适的指令视角时,性能会进一步提高。
遵循我们在 UI-Ins 中引入的 Instruction-as-Reasoning 范式(Chen et al., 2025),我们要求 MLLM 从四种不同的人类视角创建指令,包括外观、功能、位置和意图。这种设计的动机是人类的 UI 接地行为:人们有策略地在指令视角之间切换,选择对任务最有用的一个来支持有效的推理。我们将这些指令用作输入和显式推理路径,从而将结构化推理注入到模型中。这种训练方法将在以下章节中介绍。
2.2.2 训练范式
算法。为了构建具有强大基础能力的模型,我们遵循UI-Ins中的Instruction-as-Reasoning范式(Chen et al., 2025)。使用上述的grounding数据,我们首先执行监督微调(SFT)以灌输instruction-as-reasoning能力:在预测坐标之前,利用不同的指令视角作为显式的分析推理。为了鼓励在不同场景中动态地、上下文感知地选择适当的推理视角,我们随后使用GRPO算法进行强化学习(RL)阶段。
奖励。对于GUI的grounding,我们结合使用了格式奖励和点在框内的奖励。在我们的实验中,密集的奖励公式产生了相似的性能,因此我们采用了这种简单而有效的方案。
- 格式奖励
- 盒内奖励,坐标点是否在边界框内
- 放大策略。在推理过程中,我们为复杂和高分辨率的GUI场景引入了一种可选的放大策略。在第一遍中,模型预测一个粗略的坐标。然后,我们裁剪一个以该点为中心的窗口,其宽度和高度等于原始图像尺寸的一半,并将裁剪后的图像调整回原始分辨率。在第二遍中,模型通过输出放大区域上的精确坐标来细化预测。
备注:grounding带来的操作能力提升是多少?
2.3 移动GUI导航
除了在通用设置下的GUI感知和基础能力之外,MAI-UI在移动GUI导航任务中表现出色。GUI导航的训练流程包括两个主要阶段:监督微调(SFT)和在线强化学习(RL)。在第一阶段,我们构建一个自我演进的数据管道,以收集和合成多样化的多步轨迹,并使用这些轨迹训练模型,以获得强大的导航能力。在第二阶段,我们通过在动态环境中进行在线强化学习来增强模型对真实世界场景的泛化能力。以下章节将详细描述这两个组成部分。
2.3.1 监督式微调
MAI-UI采用了一种自进化的SFT数据管道(概述见图4),它包含三个关键组成部分:导航任务生成、轨迹合成和迭代拒绝采样。 在导航任务生成阶段,我们利用多种来源(APP手册、专家设计的任务和开源数据 )来构建高质量的种子任务。在轨迹合成阶段,我们首先扩展种子任务,然后结合基于模型的合成和人工标注来生成多样化的轨迹。生成的轨迹经过两个质量控制步骤:通过自动评估进行细粒度的正确性判断,以及由人工审核员进行标注质量检查。这确保了合成轨迹的多样性和质量。在最后阶段,即迭代拒绝采样中,我们首先使用一组第二阶段的轨迹作为冷启动数据来初始化训练,以获得初始的SFT模型。然后,**我们在微调模型和部署更新后的策略以推出新的轨迹之间交替进行。新生成的轨迹通过拒绝采样进行过滤,仅保留与模型不断发展的能力相符的高质量示例。**与此同时,我们不断从第二阶段注入新的轨迹,以扩大覆盖范围并提高性能上限。这种训练和数据合成的闭环使得模型和训练语料库都能够自我进化。
导航任务生成。在此阶段,导航任务指令源自三个不同的来源:(1)应用手册,从中解析常见的使用场景并提炼成意图级别的任务描述 ;(2)专家设计的任务,由人工标注员制定符合常用场景的、现实且多样的移动导航目标;以及(3)开源数据集,通过任务复杂度和可达性进行筛选。这种多源策略扩展了任务的多样性和规模,同时严格的来源选择和过滤确保了数据质量。
轨迹合成。在第二阶段,我们首先扩展任务集以增加多样性,然后通过并行管道生成轨迹数据,这些管道利用基于模型的展开和人工标注。
- 种子任务扩展。从种子任务开始,我们提示多模态大型语言模型 (MLLM) 生成各种新颖的任务。我们将这种多样性分为两个级别:L1 调整原始任务目标的关键参数,典型参数包括日期/时间范围、数值阈值、排序/过滤标准等;L2 替换任务中涉及的核心对象,同时保持对相同场景和应用集的约束。
- 模型合成与人工标注。 鉴于扩展的任务集,我们通过两个并行管道生成执行轨迹:(1)人工标注:标注员在 Android 模拟器上手动执行任务,并记录每个步骤的屏幕截图和真实动作序列。(2)基于模型的合成:由于人工标注耗时且成本高昂,我们还采用多个 GUI 代理来自动生成用于导航任务的有效动作序列 。 值得注意的是,对于给定的任务目标,通常存在多个有效的执行路径。 通过结合这些互补的来源,我们显着扩大了轨迹覆盖范围并增强了数据集的鲁棒性。
- 细粒度的正确性判断和标注质量验证。在从模型合成和人工标注生成不同的轨迹后,我们通过两个独立的验证流程进行质量评估:
-
- 人工质量检查:所有人工标注的轨迹均由第二位标注员审查,以验证动作序列、屏幕截图和原始任务目标之间的一致性。不一致或不明确的演示将被更正或丢弃。
-
- 细粒度正确性判断。GUI代理rollout产生的轨迹由MLLM-as-a-judge模块(Gu et al., 2025a)进行检查。该评判模块分析任务指令、动作历史和屏幕截图,以评估轨迹和步骤层面的正确性。由于某些扩展任务不可行,并且rollout模型在复杂任务中可能表现不佳,因此许多生成的轨迹无法完全实现预期目标。然而,失败的轨迹通常包含大量正确动作的前缀,错误通常仅发生在中间或后续步骤。认识到失败轨迹中的并非所有步骤都是错误的,我们采用细粒度的评判方法来识别和保留有用的子轨迹。备注:这里也是通过大模型判断的,且仅保留正确的前段轨迹。
- 评估包括两个组成部分:(1)总体轨迹判断:MLLM作为评判者评估端到端的成功,优先考虑来自屏幕截图的视觉证据,而不是GUI代理生成的文本声明;(2)错误轨迹重用:对于失败的轨迹,评判者识别在首次偏差之前最长的正确动作前缀。这使得能够重用失败的轨迹,减少数据浪费,并使模型能够从部分成功中学习。
-
迭代拒绝采样。我们采用一种迭代自改进循环,逐步完善模型和轨迹数据分布。设M(t)表示我们在第t轮微调后的模型,并设Iexpansion为来自多样化任务扩展的多样化任务指令集。在第t + 1轮中,我们使用M(t)作为 rollout 策略,以在Iexpansion:上生成新的轨迹:
其中,每次展开都通过细粒度的正确性判断模块进行过滤,以仅保留高质量或部分正确的片段。然后,通过将新生成的拒绝采样数据与从轨迹合成阶段合成的新轨迹混合,来构建下一次迭代的训练集:
其中 Dsynthesis 表示从人工标注和智能体展开生成的轨迹。然后,模型 M(t+1) 在 D(t+1) 上进行微调,完成迭代。拒绝采样数据有助于缩小 pass@1 和 pass@N 之间的差距,而每次迭代中引入的新轨迹不断提高 pass@N 的性能上限。这个过程鼓励数据分布逐渐与模型不断发展的能力对齐。
2.3.2 启用代理-用户交互和MCP工具使用
为了教导模型与用户互动并使用MCP工具,我们通过明确涵盖代理-用户互动和MCP增强的轨迹来扩充我们的自演化数据管道。这些轨迹被混合到SFT中,使模型能够学习何时从用户那里获取缺失的信息,以及何时使用MCP工具来高效地完成任务。
代理-用户交互。我们构建的任务刻意省略了关键信息。当标注/展开到达需要缺失信息的步骤时,它会发出 ask_user 动作。然后,**查询被路由到一个用标准LLM实现的合成用户代理,该代理以包含缺失信息的隐藏上下文为条件。用户代理返回简洁、符合上下文的回复,包括澄清、更正或在适用的情况下拒绝。**我们将查询-响应对记录在历史记录中,并继续标注/展开,以便轨迹可以整合返回的信息以完成任务。我们生成单轮和多轮交互。
MCP增强。我们设计的任务需要或受益于外部MCP工具(例如,高德地图、Github、Stockstart)。在轨迹标注或展开期间,标注者/代理可以使用工具名称和参数发出mcp_call。MCP服务器执行调用并返回结构化输出。我们记录工具模式、参数、结果以及后续的UI操作,并且保留展示正确MCP工具选择的轨迹。
2.3.3 在线强化学习
为了增强模型在长时程任务和动态真实世界环境中的可靠性 ,我们采用了一种与在线GUI环境集成的基于代理的强化学习(RL)框架,如图5所示。该框架通过两个交替阶段运行,从而驱动迭代改进:(1)在rollout阶段,模型与GUI环境执行多轮交互以完成任务并收集完整的执行轨迹;(2)在训练阶段,模型使用轨迹级别的奖励执行端到端的策略更新。通过这种迭代过程,每个改进的策略都会为后续训练生成更高质量的rollout,从而逐步增强模型的鲁棒性和泛化能力。
备注:训练和推理模型无法做到同一个吧?
可扩展的GUI环境。扩展自主强化学习的一个关键瓶颈在于有效地扩展有状态环境。与用于数学推理或代码生成的无状态环境不同,GUI环境本质上是有状态且资源密集型的,需要每次rollout在隔离的实例中运行。这种约束促使我们使用虚拟化环境而不是物理设备。
受到AndroidWorld中一项实验性功能(Rawles等人,2024a)的启发,我们构建了一个容器化解决方案,该方案将整个GUI环境封装在一个Docker镜像中,包括一个已root的Android虚拟设备(AVD)、自托管的后端服务以及一个用于编排的专用REST API服务器。该解决方案经过精心设计,以确保以下三个特性:
- 一致性。统一的容器化消除了外部依赖性,并保证了在异构主机系统上的行为一致性。
- 泛化性。为了构建一个通用的移动使用环境,我们集成了超过35个应用程序,包括系统实用程序和开源软件,如Mattermost(企业通信)、Mastodon(社交媒体)和Mall4Uni(电子商务)。自托管这些应用程序提供了完整的后端访问权限,从而能够精确地操纵初始任务状态并确定性地验证执行结果。
- RL原生设计。我们采用AVD快照机制来实现可复现的任务初始化,并通过容器化的API服务器公开标准的RL原语(重置、步进、获取观测、评估和关闭),从而实现模拟器实例的并行部署。
- 备注:应用数很少,是否是中文?AVD快照如何实现用户状态保存?
为了进一步在分布式基础设施上扩展环境,我们引入了一个集中式的环境管理器,用于协调跨多个物理机的容器实例。这种架构具有三个关键功能:(1)高效的资源利用率:通过自动容器重用,环境在部署完成后会被重置和重新分配,而不是被销毁;(2)跨机器编排:管理器公开了一个统一的 REST API,该 API 提供对异构主机上分布式资源的透明访问;(3)容错性:我们引入了自动检测和恢复机制来处理容器故障,并采用故障转移协议,从备用池中无缝替换受损实例。通过协调仅 10 台标准的阿里云 ECS 服务器 (ecs.ebmg5s.24xlar ge),该管理器最多支持 512 个并发环境实例用于并行部署执行,同时保持持续在线 RL 训练所需的高可用性。
长程强化学习 。训练用于长程任务的强化学习智能体面临两个相互关联的挑战:传统的同步展开流程由于广泛的多轮环境交互而变得效率低下,成为瓶颈;由此产生的超长轨迹(每个轨迹最多可达数百万个token)超过了单GPU的内存容量 ,因此需要先进的并行策略来实现端到端的策略训练。为了应对这些挑战,我们采用了一个严格的on-policy、异步强化学习训练框架,该框架建立在verl(Sheng et al., 2024)之上,如图6所示,并具有两个关键优化:
- 多轮效率的异步推出。我们实现了一个自定义的代理循环,该循环将请求异步分派到一组托管最新策略模型的推理服务器,从而减轻了环境交互期间的 GPU 空闲。代理循环进一步结合了与会话管理的异步环境交互,维护备份会话以实现无缝故障转移和替换。在服务器端,我们采用负载平衡和预填充缓存来加速多轮设置中的生成效率。
- 超长序列的混合并行。为了支持数百万 tokens 轨迹的端到端训练,我们利用 Megatron 的混合多维并行(TP+PP+CP)来跨 GPU 分片每个长 rollout 轨迹,沿着张量、流水线和上下文维度,从而实现可扩展的训练,同时保持每个 GPU 的内存有界。此外,我们将图像大小调整为其原始分辨率的一半,这在不影响模型性能的情况下显着提高了训练效率。
任务和验证器设计。有效的强化学习训练需要一个结构良好的任务分布,以平衡探索和利用。我们手动策划了一组超过35个应用程序,涵盖从简单的单应用程序操作到复杂的多应用程序工作流程。任务根据当前策略的pass@K成功率(SR)动态地分为四个难度级别:前沿任务(0--25% SR)推动模型能力边界,探索任务(25--50% SR)驱动技能发展,接近掌握的任务(50--75% SR)接近熟练程度,以及利用任务(75--100% SR)强化已学习的行为。
备注:这35个是否就是androidworld评测集中的应用?
在此分层的基础上,我们实施了一种自动课程,可在整个训练过程中逐步调整任务抽样。早期阶段强调更简单的任务,以建立基础技能,而随着成功率的提高,分布逐渐转向具有挑战性的任务。这种自适应策略可防止因过度困难而导致的训练崩溃,同时确保持续的学习信号,从而有效地解决探索-利用的权衡问题。
备注:要防止过度困难导致训练崩溃,确保有持续的学习信号,值得参考
为了实现可扩展的评估,我们开发了一种根据任务特性量身定制的混合验证方法。对于具有明确成功标准的确定性任务,我们使用基于规则的验证器,并具有根级AVD访问权限,以进行精确的状态验证。对于基于规则 的验证工作量大的复杂任务,我们采用MLLM-as-a-Judge框架来评估执行轨迹与任务目标的一致性。这种混合方法与人工标注达成83%的一致性,从而实现可靠的大规模验证,而无需手动瓶颈。
强化算法:GRPO,group size在16的规模在有效性和性能上取得平衡
我们还加入了以下特性,以鼓励探索和提高稳定性:
奖励设计。奖励信号包含两个组成部分:任务完成奖励和动作级别重复惩罚。任务完成被衡量为成功执行的二元指标,由基于规则的验证器或上述的 MLLM-as-a-Judge 框架确定。为了阻止无成效的循环,我们惩罚重复出现的动作序列(从单个重复动作到 3-5 个动作的循环模式)。具有相同类型但不同参数的动作不会受到惩罚,从而在防止非进展性行为循环的同时实现灵活的执行。
备注:DAPO有惩罚重复能力吗?
剪裁更高。遵循DAPO(Yu et al., 2025),我们采用无KL散度的token级别损失。

经验回放。我们维护一个在训练期间收集的成功轨迹的回放缓冲区。当一个 rollout 组不包含任何成功完成时,我们用从缓冲区随机抽样的轨迹来扩充它。缓冲区会不断更新新近成功的经验,每个任务仅保留最近的八个轨迹,以保持近策略学习。这种机制确保了即使在具有挑战性的探索阶段也能获得持续的学习信号,从而稳定训练并加速收敛。
备注:这个如果从来没成功,哪里来的正确轨迹? 是否就是标注数据?
2.4 设备-云协同
在上述训练过程的基础上,我们可以获得用于云服务的高容量代理以及轻量级但功能强大的设备端代理。然而,单独使用任何一种模式都不能完全满足实际部署的要求。设备端解决方案受到模型大小的限制,因此GUI代理能力有限。云部署存在高延迟、隐私风险和网络依赖性问题。为了解决这些局限性,我们引入了一种原生设备-云协同架构,该架构可以根据任务上下文和数据敏感性自适应地在设备和云之间路由计算。
2.4.1 系统架构
我们的设备-云协作系统的总体结构如图 7 所示。该系统由一个本地 GUI 代理(具有 GUI 代理和轨迹监视器的能力)、一个云 GUI 代理和一个本地统一轨迹存储器组成,该存储器维护本地和云代理之间一致的信息交换。这些模块的具体功能如下所示:
本地代理。本地代理在设备上运行,同时充当GUI代理和监视器。作为GUI代理,它感知当前屏幕,并为任务的每个步骤生成动作。作为监视器,它评估到目前为止的轨迹是否与用户指令保持一致。监视器检查诸如动作执行失败、无进展的重复动作、不正确的输入或一般的任务偏差等指标。如果轨迹偏离用户指令,并且当前上下文不包含隐私敏感数据,则监视器会触发切换到云代理。此外,监视器每次检测到偏差时都会生成错误摘要,我们发现这对于轨迹恢复非常有效。
云代理。仅当监视器检测到轨迹偏差时才调用云代理。除了标准的GUI代理输入之外,它还会收到来自监视器的错误摘要,解释触发切换的原因。给定轨迹历史和错误摘要,云代理执行后续步骤,利用其更高的能力来完成任务。
局部统一轨迹记忆。在设备端,我们维护一个统一的历史记录,记录任务指令、历史屏幕截图以及模型过去的输出,包括思考和行动。在执行行动期间,记忆模块将统一的历史记录投影到设备和云模型期望的行动空间中,使任何一个模型都能够从任何状态无歧义地恢复。
执行循环。用户向本地代理提供任务指令。在每个步骤中,本地代理观察当前屏幕截图,决定一个动作并执行它。然后,环境观察和模型输出被写入本地统一轨迹记忆。每隔几个步骤,本地代理评估用户指令与到目前为止的轨迹之间的一致性。如果一致性得到满足,则循环在设备上继续。如果检测到偏差且不涉及敏感数据,则系统调用云代理以完成任务。
2.4.2 局部代理训练
我们训练了一个单一的设备端模型,它统一了两个角色:一个用于GUI导航的代理,以及一个用于对齐评估的轨迹监控器。与先前的工作(Jiang & Huang, 2025)相比,我们的本地代理引入了设备端实际部署所需的两项关键创新:
集成监控能力。在实践中,监控器必须处理各种复杂的情况,而仅仅依靠提示工程不太可能提供可靠的监控。设备上的模型经过专门训练,可以判断到目前为止的轨迹是否在不同的应用程序、布局和任务中与用户指令保持一致。
误差反馈生成。当检测到偏差时,我们的模型会进一步生成简洁的误差总结,以指导轨迹恢复。由于仅在轨迹已经偏离用户指令后才会发生移交,因此该信号对于云代理正确完成任务至关重要。
训练流程。我们联合训练本地代理在两个数据源上:(i)涵盖感知、基础和导航的标准GUI代理数据,以及(ii)包含对齐推理、对齐决策和错误总结的监控数据。这种多任务训练方法教导设备上的模型同时执行和监控,而无需单独的模型或脆弱的提示工程。
2.5 MobileWorld 基准测试
现有的移动GUI代理基准测试通常无法捕捉到真实世界移动使用的复杂性。许多评估依赖于简单的应用程序或有限的应用程序类别,并且它们通常假设理想化的交互模型,其中用户指令非常清晰,并且代理仅通过GUI操作来运行(Rawles et al., 2024b; Xu et al., 2025a)。基准性能与实际应用之间的这种差距变得越来越明显。为了评估MAI-UI的实际能力,我们采用了我们的MOBILEWORLD(Kong et al., 2025)基准测试,这是一个旨在弥合这一评估差距的综合基准测试。MOBILEWORLD包含200多个实际任务,涵盖15个以上的开源应用程序,涉及关键领域,包括电子商务(Mall4Uni,镜像Temu/Amazon)、企业通信(Mattermost,镜像Microsoft Teams/Slack)、社交媒体(Mastodon,镜像X/Twitter)和日常生产力工具。
此外,MOBILEWORLD 不仅限于标准 GUI 操作,还扩展到评估两个重要的现实世界能力,这与 MAI-UI 的实际部署设计直接一致。
代理-用户交互,其中代理必须检测到含糊不清的用户请求,并主动寻求澄清,而不是做出不正确的假设。
MCP工具集成,其中智能体必须在手动GUI导航和通过MCP(Anthropic,2024)的基于API的操作之间做出明智的决定,以优化效率。
3 实验
3.1 实验设置
实现细节 MAI-UI 使用 Qwen3-VL (Bai et al., 2025a) 作为多个模型尺寸(2B、8B、32B 和 235B-A22B)的主干,以满足实际部署需求。训练分为四个阶段:(i)在感知和 grounding 数据上进行 SFT;(ii)在移动用途的导航数据上进行 SFT,并包含少量 grounding 数据;(iii)对 grounding 进行 RL,以开发强大的 UI grounding 能力;(iv)在动态环境中对移动用途的导航进行在线 RL,以增强稳健性和泛化能力。为了进一步增强大型云模型变体,我们使用更多真实世界的轨迹来扩充 32B 和 235B-A22B 模型的训练。
3.5 在线强化学习分析


备注:720p为:1280×720的分辨率,我们实际上的图片尺寸只有540p,待改进。
案例研究:增强的鲁棒性。图13和14展示了在线RL训练后鲁棒性的定性改进 。图13展示了MAI-UI在任务执行期间处理意外权限对话框和弹窗的能力。在为"Emilia Gonzalez"创建新联系人时,智能体遇到离线训练期间不存在的通知权限请求。经过RL训练的模型成功地关闭了对话框,并继续执行任务而没有偏差,而基础模型通常无法从这种中断中恢复。图14展示了智能体在复杂的费用管理任务中从失败的操作中恢复的能力。当被指示删除重复费用时,智能体最初导航到错误的应用程序。尽管如此,MAI-UI在后续步骤中纠正了轨迹并完成了任务。这些案例研究表明,在线RL训练大大提高了智能体对现实世界不可预测性的鲁棒性。这很难仅通过离线训练获得,因为离线训练中边缘情况和失败模式的多样性本质上是有限的。
备注:50步的探索长度,给了很多试错空间
3.6 grounding分析
正如我们之前在UI-Ins(Chen et al., 2025)中的工作所展示的那样,我们的Instruction-as-Reasoning方法从多个角度提供了益处:
- 有助于实现基础认知的推理。先前的研究发现,一般的思维链式推理通常会降低基础认知性能(Lu et al., 2025;Yang et al., 2025a;Zhou et al., 2025)。受到人类进行基础认知的方式的启发,我们训练模型使用多样化的指令视角作为显式方法推理路径,使推理具有可操作性,并有益于GUI基础。
- 在SFT + RL框架中缓解策略崩溃。策略崩溃通常发生在仅使用坐标监督的SFT之后的对齐过程中(Zhang et al., 2025a)。Instruction-as-Reasoning通过预训练模型生成多样化的推理路径来稳定RL,从而增强探索行为并稳定RL阶段的策略优化。
- 备注:多样化的推理路径可以稳定RL,SFT不同检查点的版本,可能导致的效果也不同。
- 涌现的多视角能力。在使用我们的指令即推理方法后,模型可以根据不同的上下文策略性地选择合适的推理视角,并将多个视角组合成一个连贯的视角。有趣的是,它还可以生成超出四个训练视角之外的新颖分析角度。
- 备注:并没有说明grounding对操作能力的提升影响。
Phi-Ground(Zhang et al., 2025a)也证明了SFT+RL框架容易发生策略崩溃 。我们的定位方法通过使用SFT阶段来教授模型通过不同的指令视角进行多样化的推理来克服这个问题,然后利用RL阶段来进一步激励模型选择适当的推理路径,从而为SFT+RL训练范式建立一个有效的例子。
4、论文值得借鉴的点
(1)提高分辨率到720p(1280x720),540p会大幅降低性能。
(2)参考完整训练路径:不要放在一起做强化,可以加入少量grounding一起SFT
完整的路径为:感知+grounding SFT->操作能力+少量grounding微调->grounding强化->操作能力强化
其中操作能力强化需要将尝试步数提升到50步,才能较大幅度提升效果,15步只能提升1-2个点。
(3)DAPO能提高采样空间,提升稳定性,Step-GUI和UI-Tars都提到了
(4)需要使用拒绝采样提高SFT效果,再做强化。其中仅操作能力提升SFT才用到了拒绝采样。合成数据仅合成指令,采样后,通过模型选择成功的轨迹前缀进行训练。
(5)SFT+RL框架容易发生策略崩溃。我们的grounding方法通过使用SFT阶段来教授模型通过不同的指令视角进行多样化的推理来克服这个问题。但是否这个收益持续提升到指令操作的强化?
(6)不同任务(grounding和指令操作)的强化,可以分阶段进行,不需要混合在一块
(7)grounding带来的指令操作提升,文章中并没有证明
(8)可以参考UI-Ins文章进一步挖掘我们的爬虫数据