本文探讨如何利用TextIn文档解析引擎与火山引擎Coze/HiAgent平台,构建智能文档处理系统以应对企业多语言、多格式文档处理的挑战。以搭建"跨国采购合同审查Agent"为例,详细演示在Coze平台通过拖拽配置工作流,集成文档解析、条款分割、模板比对与大模型分析,最终生成审查报告的全流程。该方案为企业实现从文档解析到智能理解与执行的自动化,提供了高效、低代码的一体化解决方案。
目录
[二、技术选型:为什么选择TextIn + Coze/HiAgent?](#二、技术选型:为什么选择TextIn + Coze/HiAgent?)
[3.1 准备工作](#3.1 准备工作)
[3.2 步骤一:创建智能体并配置TextIn插件](#3.2 步骤一:创建智能体并配置TextIn插件)
[3.3 步骤二:构建工作流](#3.3 步骤二:构建工作流)
[3.4 步骤三:配置智能体发布设置](#3.4 步骤三:配置智能体发布设置)
[3.5 步骤四:测试与验证](#3.5 步骤四:测试与验证)
一、背景与需求:智能文档处理的现状与挑战
随着企业数字化进程的加速,文档处理已成为各类业务场景中的高频需求。无论是制造业的多语言产品手册翻译、跨国采购合同审查,还是贸易融资单据核验,传统的人工处理方式不仅效率低下,还容易因疲劳或疏忽导致错误。尤其是在全球化业务中,多语言、多格式的文档处理更是成为技术实施的难点。
近年来,大模型与Agent技术的兴起,为文档智能处理提供了新的可能性。然而,大多数RAG(检索增强生成)系统仍停留在"纯文本召回"层面,对文档中的表格、标题、版面结构等信息缺乏深度理解,导致召回准确率不高、语义理解偏差等问题。
TextIn文档解析引擎 的出现,正好填补了这一技术空白。它支持50+语言、20+格式的文档解析,并输出带版式坐标的Markdown结构,可直接用于向量化与智能召回。结合火山引擎的Coze/HiAgent平台,我们可以快速搭建一个支持多维度文档理解的智能体,实现从"解析→召回→Prompt→调用LLM→回写"的全流程自动化。
二、技术选型:为什么选择TextIn + Coze/HiAgent?
TextIn 解析引擎亮点:
-
多语言多格式支持:覆盖PDF、Word、图片、扫描件等常见格式,支持中、英、德、日等50+语言。
-
结构化输出:不仅提取文本,还保留段落、表格、标题、图示编号等版面信息,输出带bbox坐标的Markdown格式。
-
即插即用:提供API和插件,可与现有系统无缝集成。
Coze/HiAgent 平台优势:
-
低代码 搭建:通过拖拽节点即可构建复杂业务流程。
-
支持热更新、灰度发布、操作审计,适合企业级应用。
-
内置 大模型 与工具调用能力,支持自定义插件与工作流编排。
三、实战:在Coze平台搭建跨国采购合同审查Agent
下面以跨国采购合同条款一致性审查为例,演示如何利用TextIn插件在Coze平台快速搭建一个智能审查Agent。
3.1 准备工作
3.1.1 账号与权限
1. Coze平台账号 :访问 Coze.cn 注册并登录。
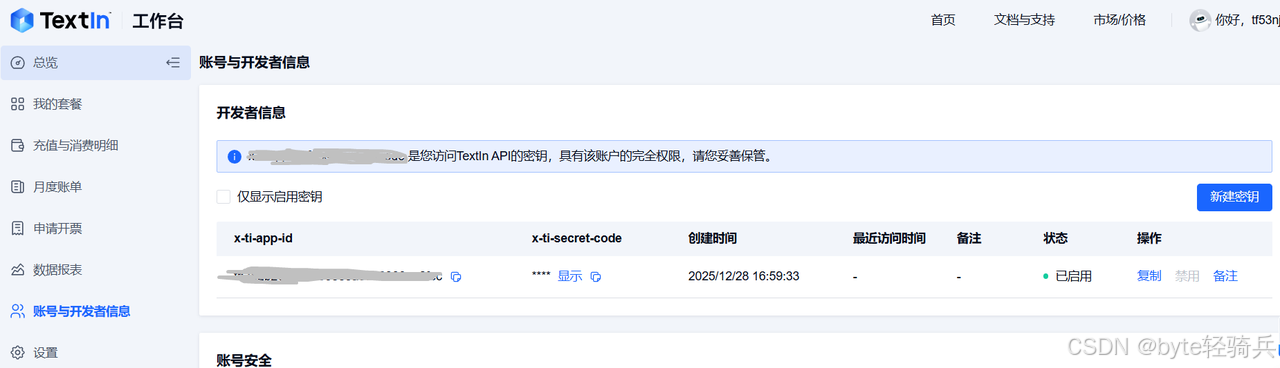
2. TextIn API 密钥 :访问 TextIn官网 注册账号,进入控制台创建API Key,保存好api_key和api_secret。
3.1.2 测试文档准备
准备两份文档用于测试:
standard_contract_template.docx:标准合同模板(中英文)
purchase_contract_2024.pdf:待审查的采购合同(含中德英三语)
3.2 步骤一:创建智能体并配置TextIn插件
3.2.1 创建新智能体
- 登录Coze平台https://www.coze.cn/open/docs/cozespace/overview,点击左上角"创建" → 选择"智能体"。
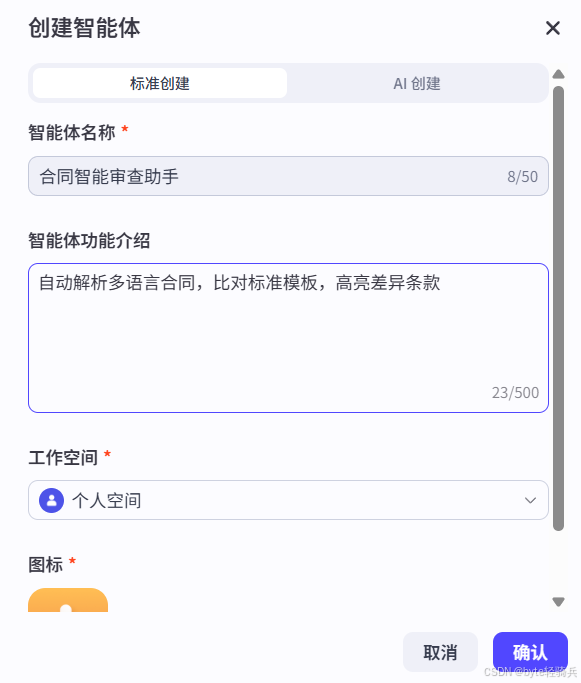
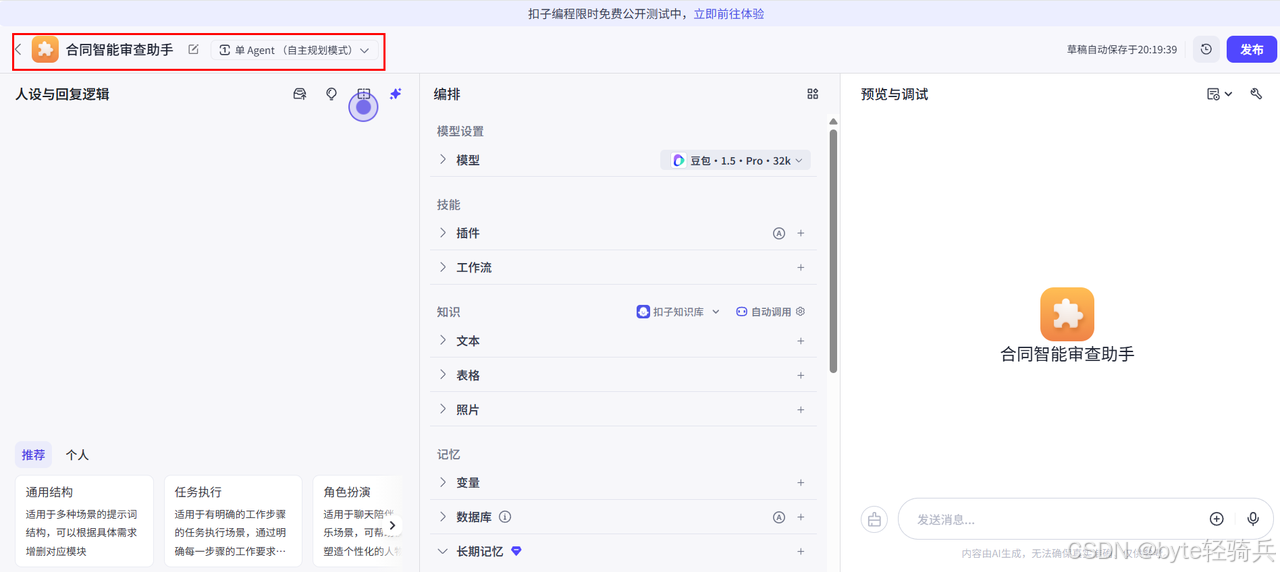
2.输入智能体名称:合同智能审查助手
- 描述:
自动解析多语言合同,比对标准模板,高亮差异条款
- 点击创建。
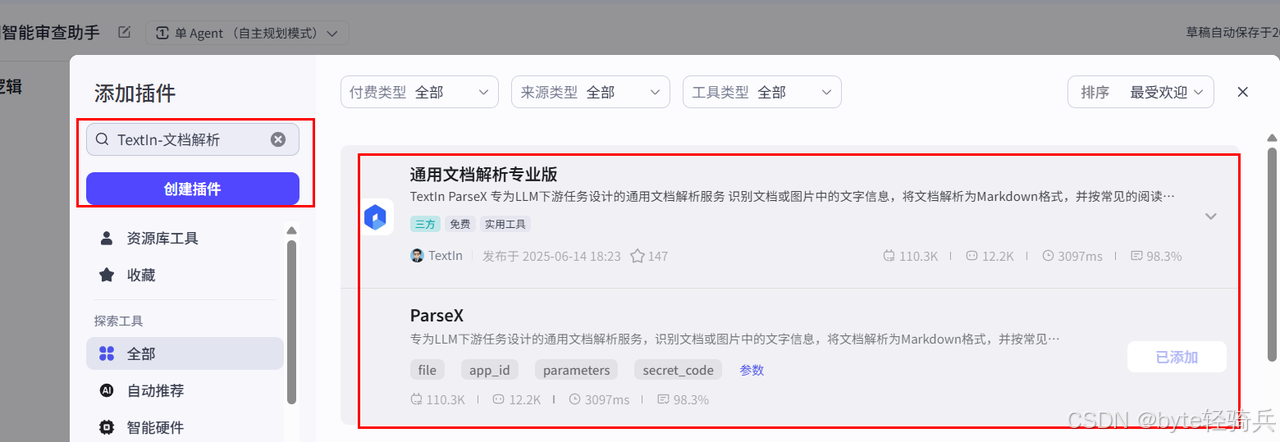
3.2.2 添加TextIn文档解析插件
-
在智能体编辑界面,点击左侧"插件"标签。
-
点击"添加插件",在搜索框输入"TextIn"。
-
找到"TextIn-通用文档解析专业版"插件,点击"添加"。
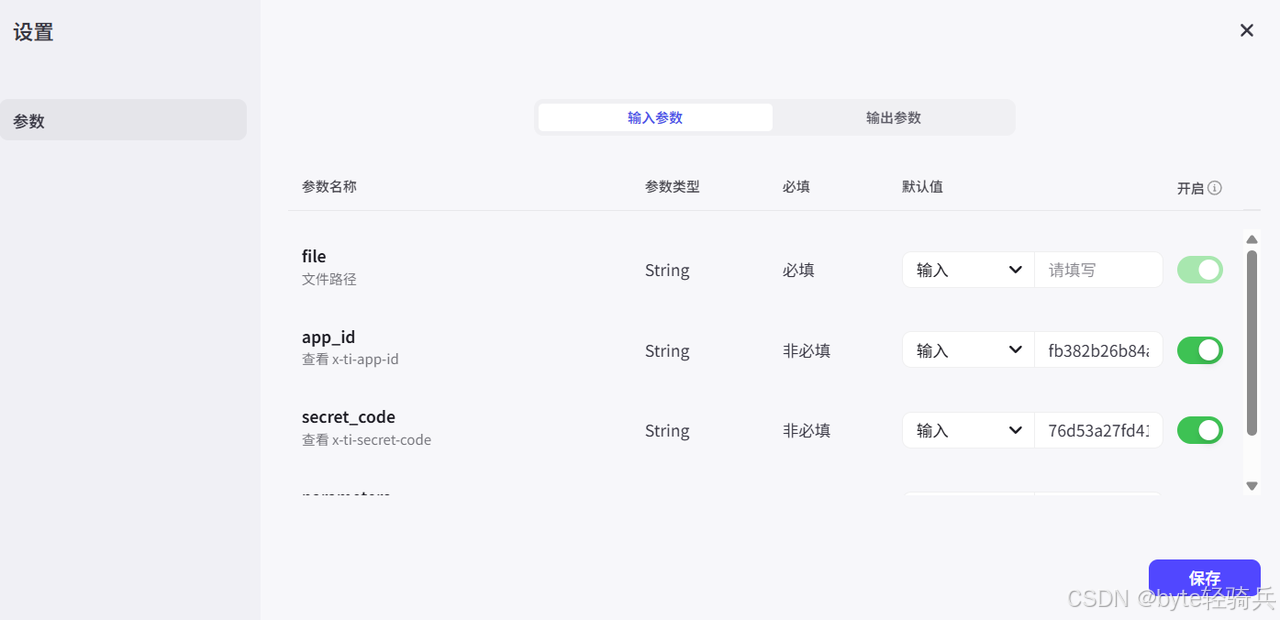
-
关键配置:在插件配置区域,填写以下信息:
插件名称:TextIn文档解析(可以保持默认) 接口地址:通常已自动填充 身份认证参数: API Key: [您的TextIn API Key] API Secret: [您的TextIn API Secret]注:可在TextIn控制台的"账户设置"-"密钥管理"中找到
3.3 步骤二:构建工作流
3.3.1 进入工作流编辑器
-
在智能体编辑页面,点击"工作流"标签。
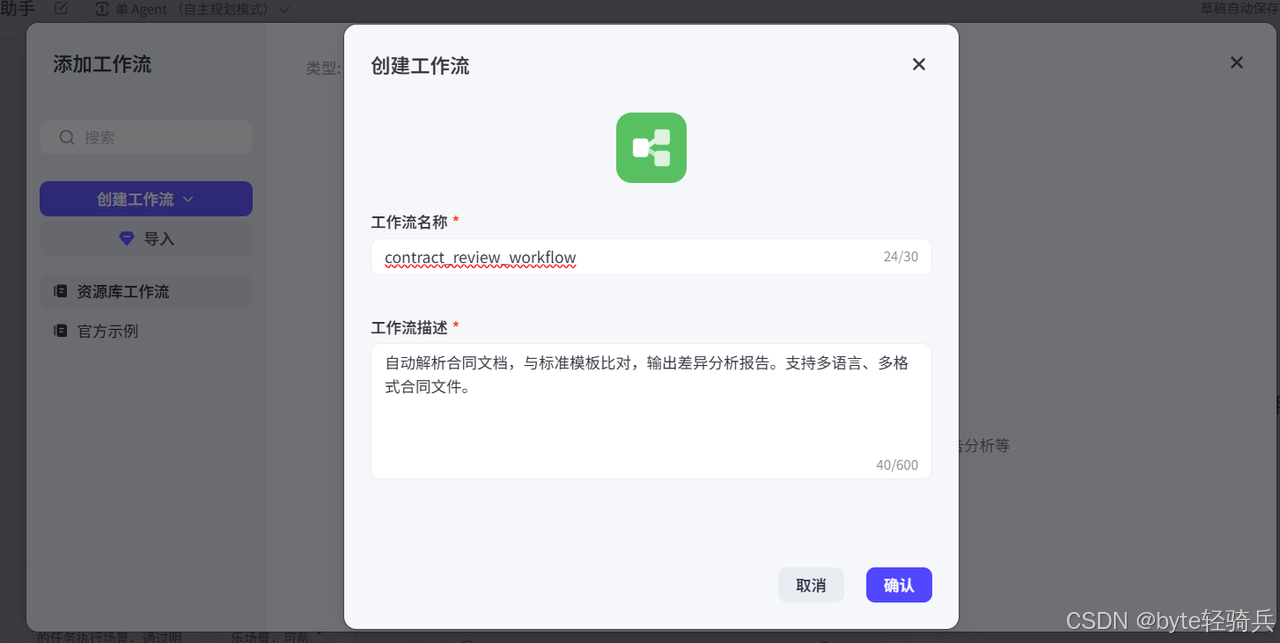
-
点击"创建工作流",命名为
contract_review_workflow。 -
工作流描述:输入 "自动解析合同文档,与标准模板比对,输出差异分析报告。支持多语言、多格式合同文件。"
-
开启"作为插件运行",这样智能体可直接调用此工作流。
3.3.2 节点1:文档上传与解析
1. 添加开始节点:从左侧拖入"开始"节点。
2. 添加TextIn解析节点:
-
从左侧插件列表拖入"TextIn文档解析"节点
-
连线:开始节点 → TextIn节点
-
配置参数:
输入类型:选择"文件URL"或"base64" (建议:上传文件到Coze知识库获取URL) 语言检测:开启 输出格式:markdown 表格识别:开启 版面分析:开启代码配置示例(节点设置中的"高级配置"):
{ "file_url": "{{input.file_url}}", "lang": "auto", "format": "markdown", "enable_table": true, "enable_layout": true }
3. 测试解析:点击节点右上角"测试",上传一个PDF合同,查看解析输出的Markdown是否包含表格和段落结构。
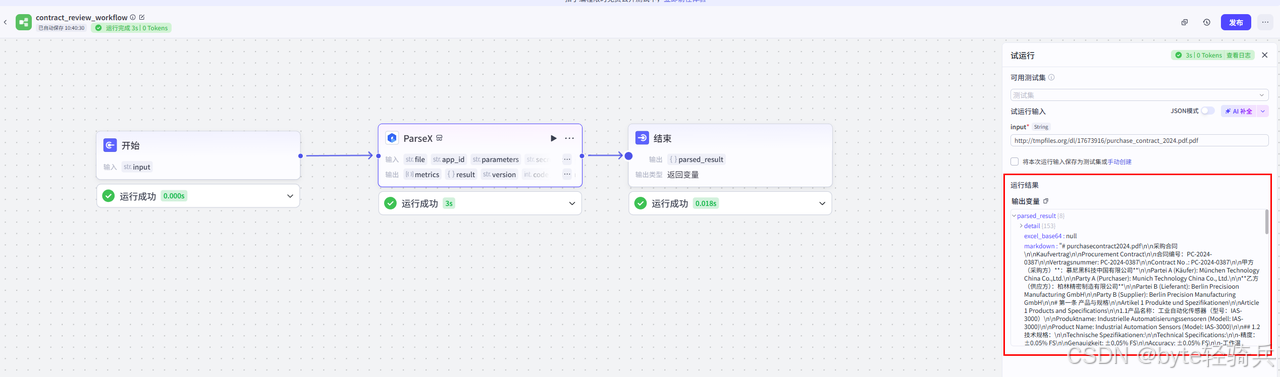
3.3.3 节点2:条款结构化与向量化
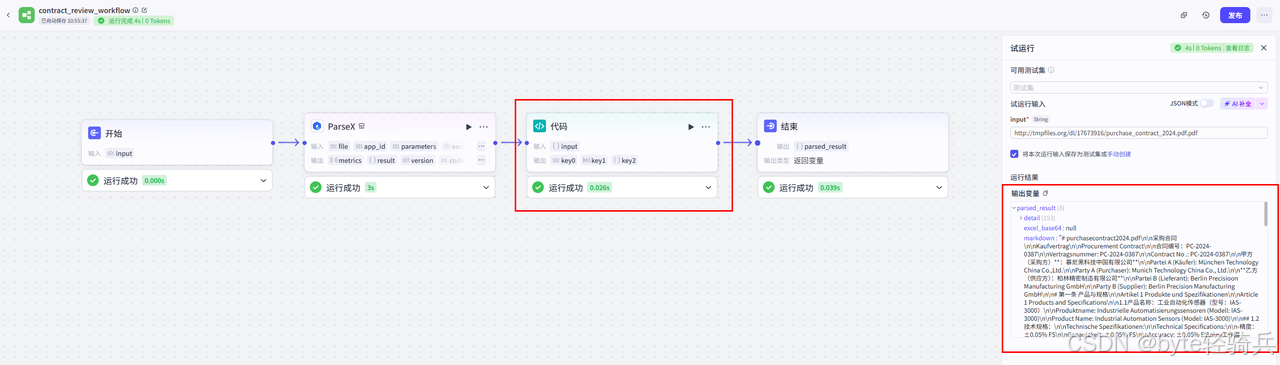
1. 添加代码节点:
-
拖入"代码"节点,选择Python
-
连线:TextIn节点 → 代码节点
2. 编写条款处理代码:
import re
async def main(input_data):
"""
处理ParseX解析结果,将合同文本分割为结构化条款
"""
# 调试:打印输入数据以了解结构
print(f"输入数据类型: {type(input_data)}")
print(f"输入数据键: {input_data.keys() if isinstance(input_data, dict) else '不是字典'}")
# 尝试多种方式获取markdown文本
markdown_text = ""
# 方式1:直接从input_data获取markdown
if isinstance(input_data, dict):
markdown_text = input_data.get('markdown', '')
# 方式2:如果markdown为空,尝试从detail中提取
if not markdown_text or markdown_text.strip() == "":
if isinstance(input_data, dict):
detail = input_data.get('detail', [])
text_parts = []
for item in detail:
if isinstance(item, dict):
text = item.get('text', '').strip()
if text:
text_parts.append(text)
if text_parts:
markdown_text = '\n\n'.join(text_parts)
# 方式3:如果还是空,尝试从原始数据中查找
if not markdown_text or markdown_text.strip() == "":
# 尝试将整个输入转换为字符串
import json
try:
markdown_text = json.dumps(input_data, ensure_ascii=False, indent=2)
except:
markdown_text = str(input_data)
# 如果markdown_text仍然为空,返回错误信息
if not markdown_text or markdown_text.strip() == "":
return {
"error": "未找到合同文本内容",
"input_data_keys": list(input_data.keys()) if isinstance(input_data, dict) else [],
"input_data_type": str(type(input_data)),
"markdown_found": False
}
# 初始化条款列表
clauses = []
current_clause = None
# 按行分割文本
lines = markdown_text.split('\n')
for line_num, line in enumerate(lines):
line = line.strip()
if not line:
continue
# 检测条款标题
is_clause_title = False
clause_info = {}
# 中文条款模式
zh_patterns = [
r'^第[一二三四五六七八九十]+条',
r'^第\d+条',
r'^[一二三四五六七八九十]+、',
r'^[0-9]+\.',
]
# 德文条款模式
de_patterns = [
r'^Artikel\s+\d+',
r'^§\s*\d+',
]
# 英文条款模式
en_patterns = [
r'^Article\s+\d+',
r'^Clause\s+\d+',
r'^Section\s+\d+',
]
# 检查是否匹配任何条款模式
for pattern in zh_patterns + de_patterns + en_patterns:
if re.search(pattern, line, re.IGNORECASE):
is_clause_title = True
# 确定语言
language = "unknown"
if any(re.search(p, line) for p in zh_patterns):
language = "zh"
elif any(re.search(p, line, re.IGNORECASE) for p in de_patterns):
language = "de"
elif any(re.search(p, line, re.IGNORECASE) for p in en_patterns):
language = "en"
# 提取条款编号
clause_match = re.search(r'\d+', line)
clause_number = clause_match.group() if clause_match else "unknown"
clause_info = {
"title": line,
"number": clause_number,
"language": language
}
break
if is_clause_title:
# 保存上一个条款(如果有)
if current_clause:
clauses.append(current_clause)
# 开始新条款
current_clause = {
"title": clause_info["title"],
"number": clause_info["number"],
"language": clause_info["language"],
"content": [line],
"lines": [line_num],
"start_line": line_num,
"end_line": line_num,
"full_content": line
}
elif current_clause:
# 继续当前条款
current_clause["content"].append(line)
current_clause["end_line"] = line_num
current_clause["full_content"] += "\n" + line
# 添加最后一个条款
if current_clause:
clauses.append(current_clause)
# 如果没有找到条款,将整个文档作为一个条款
if not clauses:
clauses = [{
"title": "完整合同",
"number": "1",
"language": "multi",
"content": lines,
"full_content": markdown_text,
"is_complete": True
}]
# 统计信息
stats = {
"total_clauses": len(clauses),
"total_lines": len(lines),
"total_characters": len(markdown_text),
"languages_found": list(set([c.get("language", "unknown") for c in clauses])),
"markdown_preview": markdown_text[:200] + "..." if len(markdown_text) > 200 else markdown_text
}
# 提取关键条款
key_clauses = []
key_terms = ["付款", "支付", "交付", "交货", "质量", "责任", "违约", "保密", "争议", "仲裁"]
for clause in clauses:
content = clause.get("full_content", "").lower()
for term in key_terms:
if term.lower() in content:
key_clauses.append({
"clause_number": clause.get("number"),
"title": clause.get("title"),
"key_term": term,
"preview": content[:200] + "..." if len(content) > 200 else content
})
break
return {
"structured_clauses": clauses,
"statistics": stats,
"key_clauses": key_clauses,
"original_markdown_length": len(markdown_text),
"parsing_status": "success",
"message": f"成功处理合同文本,分割为 {len(clauses)} 个条款"
}
3.3.4 节点3:模板比对与差异分析
1. 添加知识库节点:
-
拖入"知识库"节点
-
创建名为
standard_contract_templates的知识库 -
上传标准合同模板文件,开启向量化
-
配置召回参数:Top K=5,相似度阈值=0.7
2. 添加大模型节点:
-
拖入"大模型"节点,选择豆包(Doubao)或GPT
-
连线:代码节点 → 知识库节点 → 大模型节点
3. 配置Prompt模板:
你是一个专业的合同审查专家。请对比以下两份合同条款:
【待审合同条款】
{{clauses}}
【标准模板条款】
{{knowledge_base_results}}
请按以下格式输出对比结果:
1. 一致性分析:逐条说明条款是否与模板一致
2. 差异详情:对不一致的条款,说明具体差异
3. 风险等级:高/中/低
4. 修改建议:提供具体的修改文本
特别注意:
- 金额、日期、责任条款必须精确匹配
- 多语言条款需检查语义一致性
- 使用红色高亮标记关键差异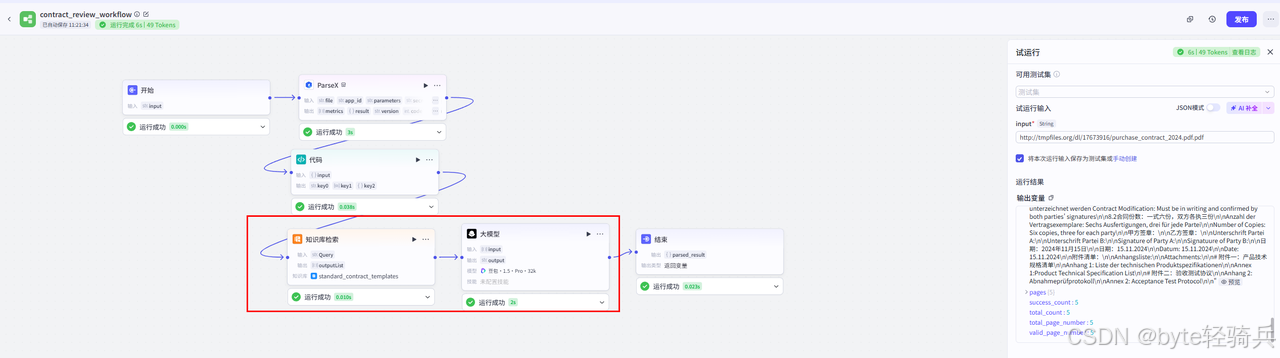
3.3.5 节点4:结果生成与返回
1. 添加格式化节点:
-
拖入"代码"节点(Python)
-
编写结果格式化代码:
import asyncio from datetime import datetime async def main(input_data): # 如果输入是字符串,则视为llm_output if isinstance(input_data, str): analysis = input_data file_name = 'unknown' total_clauses = 0 else: analysis = input_data.get('llm_output', '') file_name = input_data.get('file_name', 'unknown')a total_clauses = input_data.get('total_clauses', 0) current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S") # 生成结构化报告 report = { "审查时间": current_time, "合同文件": file_name, "总条款数": total_clauses, "审查结果": [], "风险统计": {"高风险": 0, "中风险": 0, "低风险": 0} } # 解析LLM输出 lines = analysis.split('\n') for line in lines: if "高风险" in line: report["风险统计"]["高风险"] += 1 elif "不一致" in line or "差异" in line: report["审查结果"].append({ "状态": "需复核", "内容": line, "建议操作": "联系法务部门" }) # 生成可视化HTML报告 html_report = f""" <!DOCTYPE html> <html> <head><title>合同审查报告</title></head> <body> <h2>合同智能审查报告</h2> <p>文件:{report['合同文件']}</p> <p>审查时间:{report['审查时间']}</p> <h3>风险概览</h3> <ul> <li style='color:red'>高风险:{report['风险统计']['高风险']}条</li> </ul> <h3>详细差异</h3> <pre>{analysis}</pre> </body> </html> """ # 返回字典 return { "text_report": analysis, "structured_report": report, "html_report": html_report, "has_issues": report["风险统计"]["高风险"] > 0 }
3. 添加结束节点:
-
拖入"结束"节点
-
配置输出变量:
{``{formatting_output}}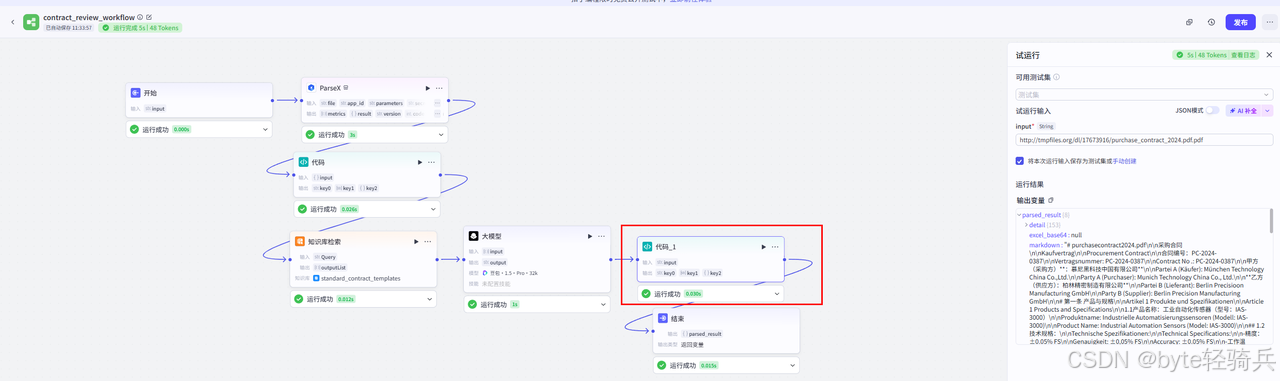
3.4 步骤三:配置智能体发布设置
3.4.1 人设与回复逻辑
-
点击"人设与回复"标签
-
配置系统提示词:
你是合同审查专家,专门处理跨国采购合同。 能力: 1. 支持中英德等多语言合同解析 2. 自动比对标准模板,识别条款差异 3. 提供风险评估和修改建议 工作流程: 1. 请用户上传合同文件 2. 调用工作流进行分析 3. 以表格形式展示关键差异 4. 提供可下载的审查报告
3.4.2 添加开场白
欢迎使用合同智能审查助手!
请上传您的合同文件(PDF/Word/图片),我将:
1. 解析多语言条款
2. 对比标准模板
3. 高亮显示差异
4. 生成审查报告
支持格式:PDF, DOC, DOCX, JPG, PNG
支持语言:中文、英文、德文、法文等50+语言3.4.3 发布配置
-
点击右上角"发布"
-
选择发布渠道:Web、API、或嵌入企业系统
-
设置权限:仅团队成员或公开访问
-
点击"确认发布"
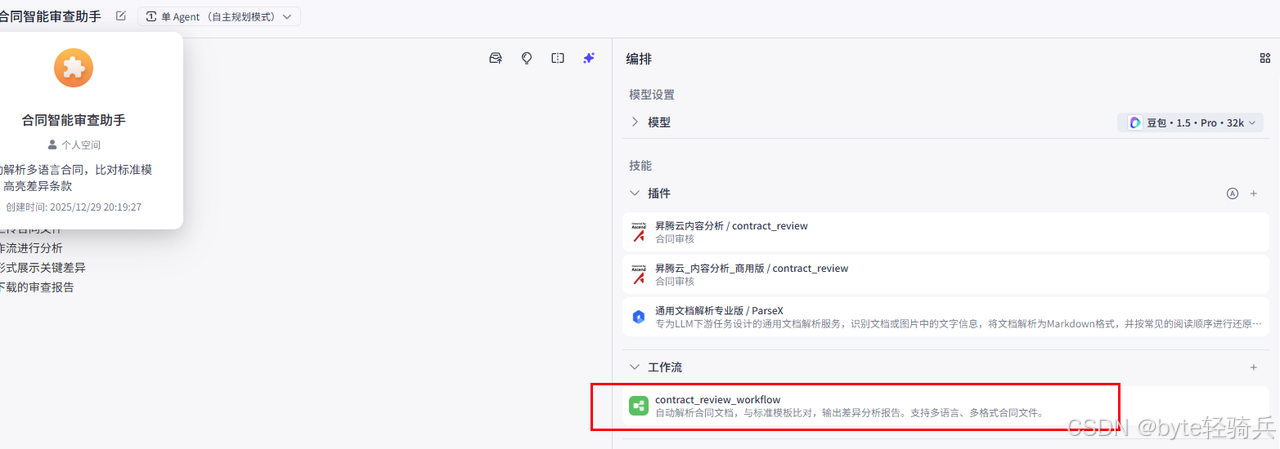
3.5 步骤四:测试与验证
3.5.1 上传测试文件
-
在Coze Playground中,点击"开始对话"
-
上传
purchase_contract_2024.pdf -
观察工作流执行过程
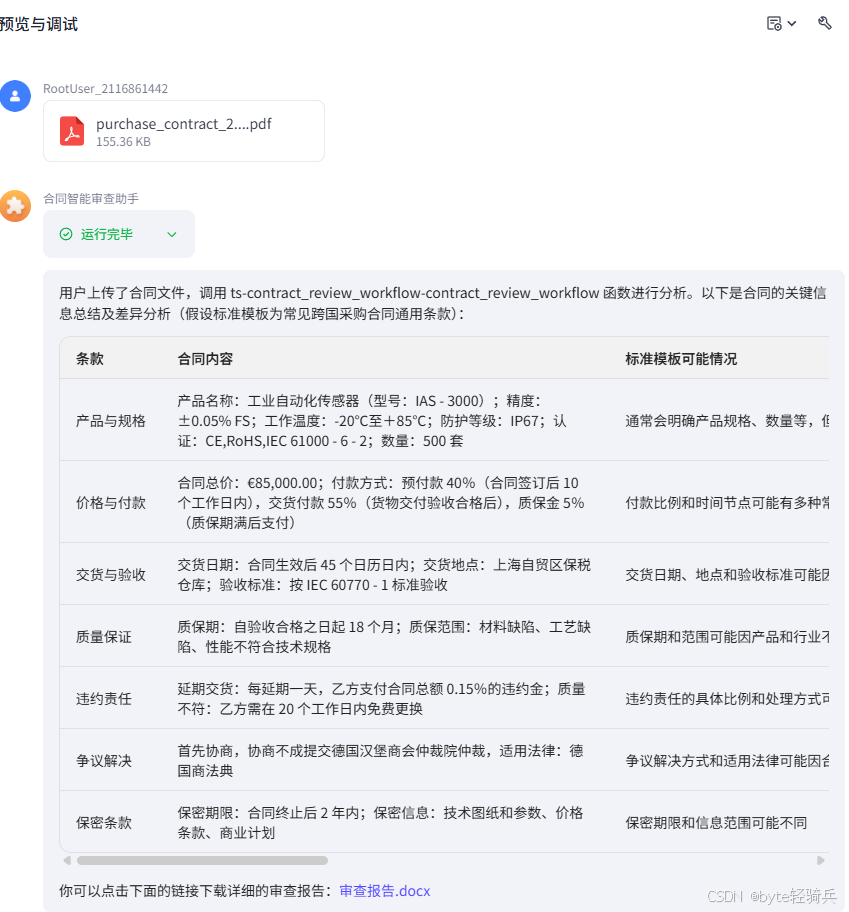
3.5.2 预期输出示例
用户上传了合同文件,调用ts-contract_review_workflow-contract_review_workflow函数进行分析。以下是合同的关键信息总结及差异分析(假设标准模板为常见跨国采购合同通用条款):
|--------|---------------------------------------------------------------------------------------------------------|-------------------------------|--------------------------|----------------------------------------------------------|-------------------------------------|
| 条款 | 合同内容 | 标准模板可能情况 | 差异 | 风险评估 | 修改建议 |
| 产品与规格 | 产品名称:工业自动化传感器(型号:IAS - 3000);精度:±0.05% FS;工作温度:-20℃至+85℃;防护等级:IP67;认证:CE,RoHS,IEC 61000 - 6 - 2;数量:500套 | 通常会明确产品规格、数量等,但具体参数和认证可能因产品而异 | 产品具体型号、参数、认证等细节可能与标准模板不同 | 若标准模板有更严格或通用的规格要求,可能导致产品不符合通用市场标准或其他潜在合作要求 | 确认行业通用标准和潜在合作方要求,与双方协商是否调整产品规格和认证要求 |
| 价格与付款 | 合同总价:€85,000.00;付款方式:预付款40%(合同签订后10个工作日内),交货付款55%(货物交付验收合格后),质保金5%(质保期满后支付) | 付款比例和时间节点可能有多种常见模式 | 付款比例和时间节点与标准模板可能不同 | 预付款比例过高可能使采购方资金压力大,交货付款和质保金比例及时间安排不合理可能影响双方利益平衡 | 根据市场惯例和双方资金状况,协商调整付款比例和时间节点 |
| 交货与验收 | 交货日期:合同生效后45个日历日内;交货地点:上海自贸区保税仓库;验收标准:按IEC 60770 - 1标准验收 | 交货日期、地点和验收标准可能因交易情况不同 | 交货日期、地点和验收标准与标准模板可能不一致 | 交货日期过长可能影响采购方生产计划,交货地点偏远可能增加运输成本,验收标准不明确或不符合行业通用标准可能引发争议 | 与双方协商确定合理的交货日期和地点,采用行业通用且明确的验收标准 |
| 质量保证 | 质保期:自验收合格之日起18个月;质保范围:材料缺陷、工艺缺陷、性能不符合技术规格 | 质保期和范围可能因产品和行业不同 | 质保期和范围与标准模板可能有差异 | 质保期过短可能无法保障采购方权益,质保范围不明确可能导致争议 | 根据产品特性和行业惯例,明确合理的质保期和范围 |
| 违约责任 | 延期交货:每延期一天,乙方支付合同总额0.15%的违约金;质量不符:乙方需在20个工作日内免费更换 | 违约责任的具体比例和处理方式可能不同 | 违约金比例和质量不符处理方式与标准模板可能不同 | 违约金比例过高或过低都可能影响公平性,质量不符处理时间过长可能影响采购方使用 | 参考市场惯例和类似合同,协商调整违约责任的比例和处理方式 |
| 争议解决 | 首先协商,协商不成提交德国汉堡商会仲裁院仲裁,适用法律:德国商法典 | 争议解决方式和适用法律可能因合同主体和交易情况不同 | 争议解决方式和适用法律与标准模板可能不一致 | 仲裁地点和适用法律对双方可能存在不同的便利性和法律风险 | 考虑双方实际情况,协商选择更公平、便利的争议解决方式和适用法律 |
| 保密条款 | 保密期限:合同终止后2年内;保密信息:技术图纸和参数、价格条款、商业计划 | 保密期限和信息范围可能不同 | 保密期限和信息范围与标准模板可能有差异 | 保密期限过短可能无法充分保护敏感信息,保密信息范围不明确可能导致争议 | 根据信息的敏感性和重要性,明确合理的保密期限和信息范围 |
3.5.3 调试技巧
-
查看执行日志:工作流每个节点都有详细日志
-
测试单个节点:点击节点右上角"测试"按钮
-
修改后热更新:工作流修改后自动生效,无需重新发布
四、效果与价值
|-------|--------|-----------------|
| 指标 | 人工处理 | 智能体处理 |
| 审查耗时 | 3 小时 | 3 分钟 |
| 条款漏审率 | 20%+ | 4.4%(下降 78%) |
| 格式支持 | 仅 Word | PDF / 扫描件 / 多语言 |
| 系统对接 | 手动录入 | 自动推送法务系统 |
五、扩展应用场景
该智能体框架可灵活扩展至其他场景:
-
产品手册翻译:解析多语言手册,调用翻译Agent+术语库,实现版本对比与自动同步。
-
贸易单据核验:结合印章识别与结构化Agent,实现发票、提单、保单的交叉验证。
-
直播合规检测:解析字幕与弹幕,实时检测敏感词,支持语音转写同步审查。
TextIn文档解析引擎与火山引擎Coze/HiAgent平台的结合,为智能文档处理提供了"解析-理解-执行"的一体化解决方案。通过低代码拖拽方式,企业可快速搭建符合自身业务需求的文档智能体,实现从"文本提取"到"多维度理解"的跨越。
未来,随着多模态大模型与Agent技术的进一步发展,文档智能处理将在企业数字化转型中扮演更加关键的角色。我们也期待更多开发者加入这一生态,共同推动AI落地应用的创新与实践。