一、背景
当今世界,图像几乎成为了我们生活日常领域最常见的信息载体。在互联网时代,我们获取图片的方式多种多样,但同时获取到的图片并不都是我们想要的理想图片,或者说图片上存在着一些影响我们对图片理解和我们并不需要的信息。例如:通过手机拍摄的数字图像中会存在"背景人物",从网站上下载下来的图片会存在水印、矩形、表情符号等影响图片语义的内容。因此对目标物体进行移除来获得真实图片开始慢慢变成一个迫切的需求。换一个角度,对目标的移除也可以看成对图像的修复,即对图片中各类形状、大小不同的破损区域进行填充。所以这个领域也可应用在对一些时间影响或者被人为破坏的图片进行语义方面的重建,让输出图片在整体语义上为观察者提供更加完整的信息量。
二、文献调研
2.1 传统图像修复方法
传统的图像修复的经典方法可以分为局部或非局部方法。它们大多数都是通过输入图片上的已知信息以及图像的先验信息来处理问题的。比如TV(Total Variation)1,2采用了自然图像的平滑特性来对小范围损坏进行修复,或者对杂散噪声的去除。又如Patch Offsets(贴片偏移量)3、Planatity(平面度)4、Low Rank(低秩)5这些先验信息的正确使用也能实现不错的修复效果。特别是Patch Match(PM)6能够在输入图片的已知区域找到相似的补丁,并且因为其质量好而且修复效率高成为了当时最成功的图像修复方法。但是这些方法都只能对单张图像进行修复,且假设输入图像中包含了修复过程中需要的信息,比如:相似的像素、结构或者补丁,但是在平时的修复任务中这种假设是很难成立的,因为实际上修复的任务往往面对的是大面积且位置形状随机的破损。
为了解决这个大区域缺失的问题,研究人员开始尝试一些非局部方法。比如:在一个巨大的数据集中剪切并粘贴一个语义相似的补丁到图像的缺失区域7或通过Internet检索到的补丁来替换场景中的目标区域8。这些基于检索的方法都要求精确的匹配,当测试场景和数据集中的数据有很大不同时就容易出错。
2.2 基础结构的修复网络
深度卷积神经网络的发展让大区域图像修复这个领域有了不错的发展前景,由于它的每个人工神经元仅响应一部分覆盖范围内的单元,这就使得CNN9在图像处理中具有出色表现。而近年来,基于CNN的深度学习网络捕获高级的图像抽象信息的能力正被慢慢发掘,同时在纹理合成和图像风格转换的研究10、11中,证明了一个训练好的CNN网络提取的图像特征可以作为目标函数的一部分,使得一个生成网络生成的图片与目标图片在语义上更加相似。
生成对抗网络(GAN)12的广泛研究,证明了通过对抗可以强化生成网络生成图像的视觉效果。而且随着研究热度的慢慢提升,从Goodfellow首次提出GAN的概念到如今已存在的用途、性能都大相径庭的GAN网络的变种,这种网络已经从最开始的生成图片质量差、容易出现模式崩塌的问题慢慢转变为可以生成高分辨率图片,且保证生成图片的多样性。学界对这些研究背景知识的广泛研究使得基于深度学习的图像修复方法在近期得到了广泛的研究。
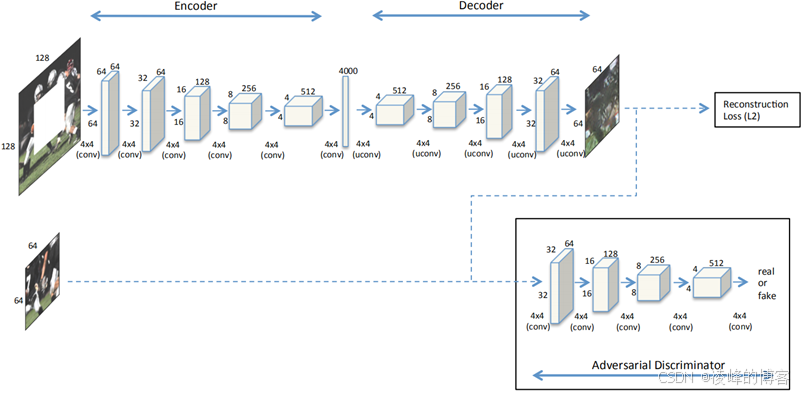
Context encoder 网络结构图
基于深度学习的图像修复方法是在2016年由Pathak等人13首次提出的,他们设计了一种上下文编码器对破损图像进行编码和解码的操作,实现了一个从图像到图像的输入、输出过程,并采用重建损失引导这个过程,让生成的图片越来越接近真实样本,其网络结构如图2-1所示。此外,这篇文章还利用了生成对抗网络的思想,引入了一个判决器,来实现对真实图片样本和网络生成图片的判断。这种方法相比于传统的图像修复方法在大区域缺损修复问题上效果有了质的提升,修复结果整体上呈现出合理的语义和不错的视觉效果。虽然这种方法还存在许多问题,如:修复区域存在伪影、网络训练时间过长,修复区域与周围区域的语义不连贯等,但是这种采用编码器的方法对后来的研究来说有着不少的借鉴意义,此后,基于深度卷积自编码器以及生成对抗模型的图像修复方法开始发展起来了。但是最开始这一阶段都只是在保持源网络不变的基础上针对不同的问题,修改其损失函数或者添加其他网络模块,所以称这一阶段的修复模型为采用基础结构的图像修复。
Iizuka等人14提出在判决器部分加上一个全局对抗损失,这样就能缓解修复区域与周围语义不连续的现象;又如:Li等人15在他们专门针对人脸图像的修复任务中,为了让修复区域的五官更加适用于人的观察标准,引入了一种类似于分割网络的机制,让编码器输出图像进入分割网络,让五官呈现出不同的颜色,然后再与分割的真实样本计算损失,以此来达到不错的人脸修复效果。后来随着Li Feifei团队提出感知损失16,人们在设置损失函数开始将更多的注意力放在了图片经过了CNN的特征图上,这种损失引导下生成的图片相比于像素级别的损失函数与目标图片在语义上更加相似。Yang等人17就利用了这种感知损失实现了高分辨率图像的修复,具体做法就是先对编码器的部分进行训练,将编码器生成的图片喂入采用ImageNet训练好之后的VGG16网络中,并抽取其中一层的特征图,计算特征图上破损区域和最邻近非破损区域的损失,以此让破损区域的特征更加接近周围区域的特征。
2.3 多层结构的修复网络
其实上述的Yang的方法中多层结构就已经初现端倪,在文中他将基础的编解码器结构成为内容修复网络,将固定权重的VGG16特征提取网络称为纹理修复网络,这种思路是借鉴于风格迁移的。然而Yang的VGG16网络仅仅只是为了计算局部纹理损失,最终还是反馈给了前面的编解码器,最终的结果依然是由基础网络结构产生的。所以只能说在这里Yang的方法成为了基础网咯结构到多层网络结构的一个桥梁。
直到2018年的CVPR中Yu等人的Coarse-to-fine网络18的提出,给出了一种基于上下文注意力的生成图像修复方法。这种方法首先是在原先的网络结构上增加了一个编解码器,对粗修复的图像进行进一步精细修复,其网络结构如图所示。文章又针对以前的修复方法在缺损边缘会出现与周围区域不一致的混乱的结构和纹理,提出了采用上下文注意力机制来解决这个问题。
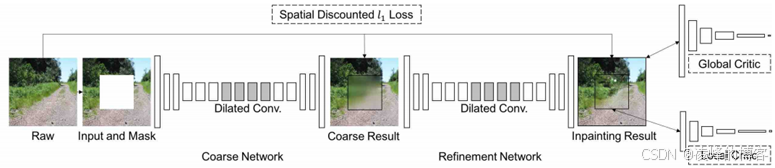
Coarse-to-fine精修复网络结构
这一阶段的网络结构也开始朝着多层网络进行过渡,其中包括Song等人19提出的基于上下文的图像修复,这篇文章中作者将网络分为三个部分即:推断、匹配、翻译。也是由一个编解码器网络开始,这个基础网络属于推断过程,紧跟着是一个VGG16特征提取网络,在特征图上使用补丁匹配交换的方式对图像进行修复,所以这个部分称为匹配过程。最后通过一个小型的编解码器,将实现特征图到图像的输出,最后这部分称为翻译过程,这就是一个完整的修复过程。其网络结构如图所示。
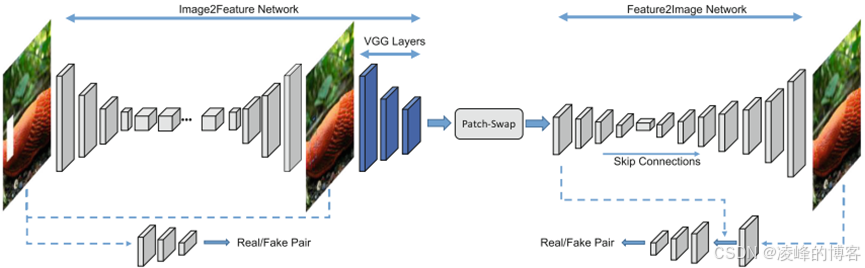
Infer、Match、Translate网络结构
具有代表性的还有一篇2018年发表在ACMMM上的Zhang等人20的语义图像修复的文章。这篇文章中采用课程学习的思想,并没有通过一次训练来实现对整个破损区域的修复,而是循序渐进,从外往里逐步进行修复,这种修复方法针对大孔洞破损有着非常好的效果。此外,文章还采用了长短期记忆模块,来实现前一段与后一段的良好衔接。其网络结构如图所示。
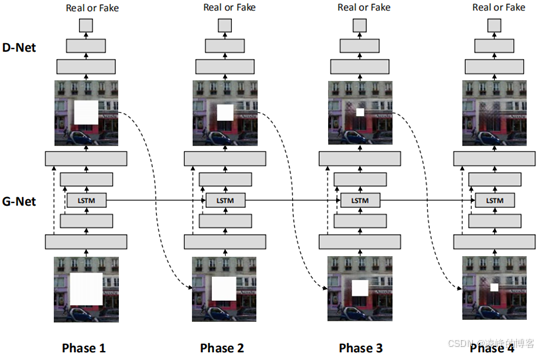
以上这些网络结构相比于基础模型阶段的修复效果有了很大的提升,特别是在大区域图像修复方面取得了不错的结果,修复之后的破损区域有着更少的伪影,与周围区域的语义连接性也得到了增强。
2.4 其他修复方法
通过上面两节的介绍,可以发现以上网络结构中都包含一个重要的基础结构,即:卷积自编码器,基于这种结构的修复方法是目前学界研究热度最高,同时也是成果最多的一种修复方案。但是这个方法也有自身的局限性,即:针对规则形状(矩形、椭圆等)修复效果较好,一旦碰到诸如图所示的这一类随机形状的缺损时修复结果就会大打折扣。

针对这一类随机区域的修复问题,也慢慢发展出一些除卷积自编码器外的其他网络结构,比如2017年CVPR中Yeh等人21提出了一种基于GAN的图形修复方法,在文章中作者认为图像修复就是一个有条件限制的图像生成问题,他训练了一个有一定深度的生成对抗网络,致力于寻找一个最接近潜在空间的图像的受损图像的编码。然后利用该编码来使用生成器重建图像。定义"最近"的方法是采用加权上下文损失来接近输入图像的破损区域,以及先验损失来惩罚不真实的图像,其网络框架如图2-5所示。这种方法就能成功解决任意缺损的修复情况,由于其主干框架是基于DCGAN的,这就给予了网络强大的图片生成能力,他甚至可以对遮挡区域面积达到整张图片面积80%的情况进行修复。此外,相比于原先的修复方法针对不同类型的缺损都需要重新训练之后才能进行效果较好的图像修复的现象,这种基于GAN的方法,只需对GAN进行较好的训练,后面的修复过程只是一个时间较短的推断过程,这就让图像修复的效率得到了很大的提升。当然,这种方法也存在致命的缺点,就是其修复网络过分依赖于GAN,从而导致只能针对较单一的图像数据进行修复,比如人脸数据、街景数据等,一旦遇到较为复杂的场景,修复效果就会比较糟糕。其次,这种方法过于直接,就会出现修复结果与原图相比还原度不高的情况,比如:在进行人脸修复的时候,如果把头发区域完全遮挡起来,那么最后修复输出的结果可能就是和原图发型完全不同的一张图片。针对这种情况,2018年CVPR中Dolhansky等人22提出了一种解决方案,那就是通过图像对的方式,由于这种修复方法是针对的人像图片的修复,所以接下来也直接用这个应用场景进行解释。此篇文章提出的网络结构和不尽需要使用者输入一张待修复的人脸照片,而且需要待修复照片中人在其他时间、其他姿势拍摄的一张照片,这样我们就能通过对这张完好照片上人的五官等特征进行提取来实现对破损区域的高度还原的修复,下图展示的就是这种网络对人眼部位的修复结果,通过观察可以发现,修复出来的五官特征与原先的图片高度相似。
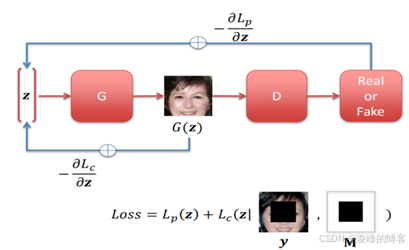
基于GAN的修复方法网络结构

Exemplar Generative Adversarial Networks修复结果
2018年ECCV中NVIDIA提出了一种新型的卷积结构,称为:部分卷积(Partial Convolution)23,这种卷积在图形修复中有着十分出色的表现。我们可以回忆一下原先的修复方法,以前都是将一整张待修复的图片喂入网络中,然后通过各种损失与机制来引导整个网络产生更好的参数,从而产生更好的修复结果。注意这个过程中破损区域也是随着图片的卷积一起进行卷积运算的,但就是这些破损区域中有着与周围区域不同的语义内容,如果参与进行计算的话会导致最终生成的图像中出现"噪声"。所以作者们提出了一种新的卷积运算,即:只用完好的区域进行计算卷积运算,具体操作就是随着图像喂入网络的还有一张二进制掩膜,大小和图像一致,上面破损区域值为0,完好区域的值为1,每次进行卷积的时候,网络都会使用掩膜将感受野中的完好区域挑出来进行运算,最后再根据有效区域的大小除以一个适当的缩放因子。在每一层卷积计算结束之后,对二进制掩膜进行更新,这样缺损区域就会越来越小,从而达到了图像修复的效果。至于网络结构,文章中采用的是2015年Ronoberger等人提出的U-net网络模24。这种部分卷积模型能够适用于各种网络结构,并且根据修复任务的不同来进行调整,最重要的是,它能实现对各种随机缺损的修复。
我们知道基于学习的方法是一种直接的方法,它将噪声图像作为输入数据,原始图像作为输出数据去训练深度卷积网络进行学习。另一方面,基于非学习的方法或手动制作先验的方法是我们从合成数据里强行加入和告知了什么类型的图像是自然的、真实的等等。用数学表达像自然这样的状态变数非常困难。而2018年CVPR中的文章Deep Image Pirior25开始思考基于深度学习之间的方法与传统方法之间的关系。这篇文章的作者提到了超分辨重建、图像去噪、图像修复都能使用这种方法来对图像进行恢复。作者将受噪声污染、低分辨率图片、破损图片称为退化图片并针对不同的重建任务设计了不同的损失,来实现对这些退化图片的模仿与拟合,即尽力让网络能够生成这些退化图片,在这过程中发现,在一定迭代次数,网络会输出自然图像,即没有噪声、高分辨或者完好图像,之后才慢慢开始拟合那些噪声或者破损区域又或者开始让图片变得更模糊。这种现象来自于卷积的不变性,和深度网络逐层抽象的结构。在这个网络中,唯一的先验信息就是网络的结构,其他都是网络在后面的学习中自己生成的。虽然修复结果没有当前一些最先进的方法效果好,但是其提出的思想十分具有参考价值,而且成为了两类方法之间的一个桥梁。
2.5 研究现状梳理
通过以上对近几年文章以及修复技术的回顾,我们可以梳理一下基于深度学习的图像修复方法主要的一些研究前景:
- 首先也是最重要,当然就是修复结果、输出图像质量要高。最终修复出来的破损区域不能有明显伪影,且修复结果需要与周围区域在语义上保持一致。
- 对大面积缺损的修复,当面积达到整张图像的25%甚至更高的时候,依然比较正确地修复这个区域内的语义信息。
- 对随机区域的修复,现实生活中很少有矩形或者规则的缺损区域等待着被修复,往往都是一些随机的缺损区域。所以只有在这种情况下达到较好的性能才能在实际生活中有不错的应用截止
- 图像的修复速度需要加快,这也是和实际应用紧密相关的,就像上文中NVIDIA采用Partial Convolution开发的一个应用,能够实时对添加上去的掩膜进行修复。
在不同任务之间切换的灵活性还有待加强,比如当掩膜从矩形切换到随机形状的时候,如果仍然需要较长时间去重新训练网络,那么在实际生活中应用起来就会十分困难。
2.6 文献搜集
搜索基于深度学习的图像修复的文章主要是一些会议文章,而且像CVPR这一类的计算机视觉顶级会议偏多,其次就是ACMMM等杂志每年基本上会出一篇比较经典的论文。接下来这个部分我先将文章进行分类,主要分为仿真文献、精读文献、略读文献三种,具体收集结果见表
|------|--------------------------------------------------------------------------------|--------|----|
| 年份 | 论文名字 | 来源 | 类别 |
| 2016 | 1Context Encoders:Feature Learning by Inpainting | CVPR | 精读 |
| 2017 | 2Globally and Locally Consistent Image Completion | ACMMM | 仿真 |
| 2017 | 3Generative Face Completion | CVPR | 略读 |
| 2017 | 4High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis | CVPR | 精读 |
| 2017 | 5Semantic Image Inpainting with Deep Generative Models | CVPR | 仿真 |
| 2017 | 6On-Demand Learning for Deep Image Restoration | ICCV | 略读 |
| 2018 | 7Generative Image Inpainting with Contextual Attention | CVPR | 精读 |
| 2018 | 8Contextual-Based Image Inpainting_ Infer, Match, and Translate | ECCV | 略读 |
| 2018 | 9Shift-Net Image Inpainting via Deep Feature Arrangement | ECCV | 仿真 |
| 2018 | 10ACMMM Semantic Image Inpainting with Progressive Generative Networks | ACMMM | 精读 |
| 2018 | 11Eye In-Painting with Exenplar Generative Adversarial Networks | CVPR | 精读 |
| 2018 | 12Image Inpainting for Irregular Holes Using partial convolutions | ECCV | 仿真 |
| 2018 | 13Deep Image Pirior | CVPR | 略读 |
| ||||
| 2018 | 14Free-Form Image Inpainting with Gated Convolution | CVPR未中 | |
| 2018 | 15Deep Structured Energy-Based Image Inpainting. | ICPR | |
|------|-----------------------------------------------------------------------------------------------------|--------|---|
| 2019 | 16CISI-net_ Explicit Latent Content Inference and Imitated Style Rendering for Image Inpainting | AAAI | |
| 2019 | 17Coherent Semantic Attention for Image Inpainting | CVPR | |
| 2019 | 18Coordinate-based Texture Inpainting for Pose-Guided Human Image Generation | CVPR | |
| 2019 | 19Learning Pyramid-Context Encoder Network for High-Quality Image Inpainting | CVPR | |
| 2019 | 20PEPSI:Fast Image Inpainting with Parallel Decoding Network | CVPR | |
| 2019 | 19Foreground-aware Image Inpainting | CVPR | |
| 2019 | 20Pluralistic Image Completion | CVPR | |
| 2019 | 21Privacy Protectin in Street-View Panoramas using Depth and Multi-View Imagery | CVPR | |
| 2019 | 22PEPSI++:Fast and Lightweight Network for Image Inpainting | CVPR未中 | |
| 2019 | 23Generative Image Inpainting with Submanifold Alignment | IJCAI | |
| 2019 | 24MUSICAL:Multi-Scale Image Contextual Attention Learning for Inpainting | IJCAI | |