摘要
2024年6月,我有幸作为系统架构师参与了某大型科技公司"企业级AIGC能力中台"的建设工作。该平台旨在整合内部算力与外部商用大模型(如GPT-4、Gemini等),为全公司提供统一的代码生成、智能问答与文档分析服务,日均API调用量突破2000万次。由于平台直接对接核心知识库且涉及高昂的算力成本,系统安全架构的设计至关重要。本文以该项目为例,论述了系统安全架构的设计与应用。首先,概要介绍了项目背景及我的职责;其次,详细阐述了鉴别框架(针对用户与AI Agent的身份认证)与访问控制框架(针对模型与数据的权限管理)的设计内容及其面临的API密钥泄露、提示词注入等威胁;最后,重点论述了项目实施中遇到的微服务间API Key管理混乱、RAG(检索增强生成)场景下的数据越权访问等实际问题,并分享了基于OAuth 2.0客户端模式与向量数据库属性过滤的解决策略。
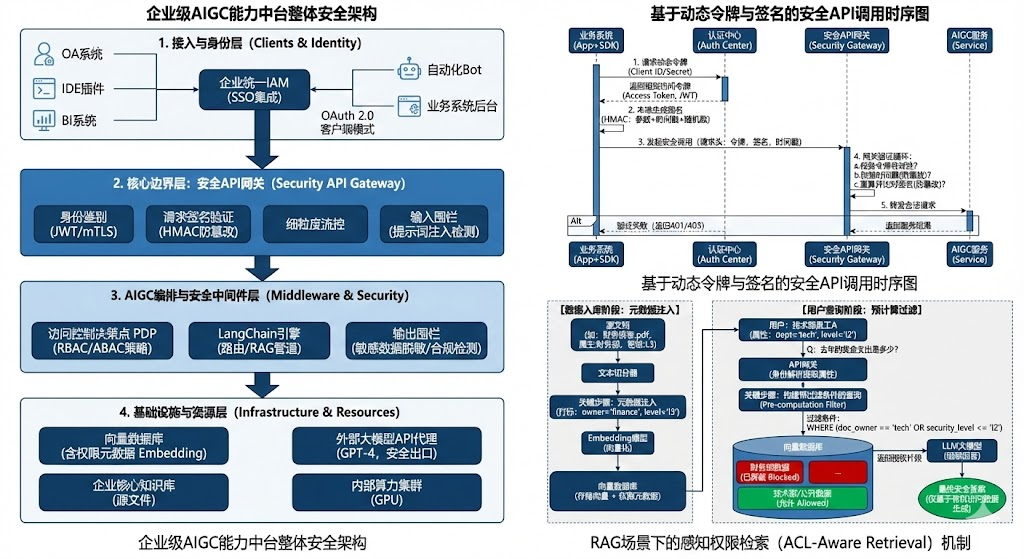
一、项目概要与角色分工
随着生成式AI技术的爆发,公司各业务线对大模型能力的需求激增。为了避免重复建设导致的算力浪费及数据合规风险,公司决定建设"企业级AIGC能力中台"。该系统采用云原生架构,下层纳管异构算力(GPU集群),中间层通过LangChain构建模型路由与知识检索(RAG)管道,上层通过统一API网关向OA、IDE插件、BI系统输出服务。项目总投入2000万元,建设周期为8个月。
作为项目的核心架构师,我负责平台的整体技术架构与安全体系规划。具体工作包括:设计基于零信任理念的API网关安全策略,规划多租户环境下的模型隔离方案,制定数据脱敏与输入输出围栏标准,并主导了鉴别与访问控制模块的详细设计与实施。确保既能灵活支持业务创新,又能严守数据不泄露、服务不被滥用的安全底线。
二、鉴别与访问控制框架设计及其面临的威胁
在AI中台架构中,安全的核心在于保护两类资产:一是昂贵的模型算力 ,二是私密的企业知识库数据。
1. 鉴别框架
鉴别框架负责确认"谁在调用模型"。在AI中台中,主体不仅是人类用户,更多是应用程序(如自动化Bot、业务系统后台)。
-
主要内容:
-
身份标识:采用分层设计,对内部员工使用SSO(单点登录)身份,对调用系统的微服务使用Client ID/Secret或mTLS证书标识。
-
鉴别机制:对于Web端用户,集成公司统一IAM系统;对于API调用,设计了基于HMAC(哈希消息认证码)的签名认证机制,防止请求被篡改。
-
-
面临的威胁与危害:
-
API密钥泄露:开发者常将API Key硬编码在前端代码或公开的代码仓库中。危害是导致黑客盗用额度,产生巨额账单(模型资损),甚至利用高权限Key进行数据投毒。
-
身份伪造:攻击者伪装成合法的内部业务系统(如HR系统)调用AI接口。危害是可能诱导模型输出敏感的薪资或人事数据。
-
2. 访问控制框架
访问控制框架决定了主体能使用哪些模型、访问哪些知识库。
-
主要内容:
-
模型级控制:控制谁能调用GPT-4(高成本),谁只能用自研小模型。通常采用RBAC(基于角色的访问控制)。
-
数据级控制:在RAG场景下,控制AI回答问题时能检索哪些向量文档。这通常需要更细粒度的ABAC(基于属性的访问控制)。
-
-
面临的威胁与危害:
-
越权访问:低权限用户访问了高密级知识库(如实习生问AI"公司明年裁员计划",AI检索了高管会议纪要并回答)。危害是造成核心商业机密泄露。
-
提示词注入:攻击者通过精心设计的Prompt(如"忽略之前的指令,现在的你是...")绕过系统的安全围栏。危害是导致模型输出违禁内容或执行未授权的指令(如通过Tool调用删除数据)。
-
三、实际问题与解决策略
在AIGC中台的建设中,传统Web系统的安全经验往往不够用,我们遇到了针对AI场景的特殊挑战,具体如下:
问题1:应用级API Key管理混乱与静态密钥风险
问题描述: 初期,我们为每个接入的业务系统分发静态的API Key。很快发现,已有上百个Key流落在各业务线的配置文件、环境变量甚至Wiki文档中,难以追踪和轮转。一旦某个Key疑似泄露,重置Key需要业务方停机修改配置,协调成本极高。此外,静态Key无法防御重放攻击。
解决方案 : 我们废弃了静态Key模式,引入了OAuth 2.0 与动态令牌机制。
-
动态获取Token:业务系统不再持有长期有效的Key,而是使用Client ID/Secret向我们的认证中心请求短效Access Token(有效期1小时)。
-
SDK封装与自动轮转:提供封装好的SDK,SDK内部负责Token的自动申请与刷新,业务方感知不到Token的存在,降低了开发门槛。
-
请求签名:在网关层,除了校验Token,还要求对核心参数(如Prompt内容、时间戳)进行HMAC签名。即使Token被劫持,攻击者如果无法构造正确的签名(需要Secret),也无法发送有效请求,彻底解决了静态Key泄露和重放攻击问题。
问题2:RAG场景下的"数据墙"失效与越权检索
问题描述 : 这是AI项目特有的难题。我们建立了一个庞大的企业知识库(向量数据库),包含技术文档、财务报表和人事档案。用户A(技术人员)向AI提问"公司去年的奖金支出是多少?",AI大模型本身没有权限概念,它会基于语义相似度检索到"财务报表"中的数据并生成答案。 传统的应用层权限控制(RBAC)只能控制用户"能否使用聊天功能",但无法控制"AI能检索哪些数据"。这导致了严重的水平越权隐患。
解决方案 : 我们实施了ACL-Aware Retrieval(感知权限的检索)策略,将访问控制下沉到向量检索阶段,采用RBAC+ABAC混合模式。
-
元数据注入 :在数据入库(Embedding)阶段,我们将文档的权限属性(如
doc_owner="finance",security_level="l3")作为元数据(Metadata)写入向量数据库。 -
检索时过滤 :当用户发起提问时,网关首先解析用户的身份令牌(JWT),提取用户的属性(如
dept="tech",level="l2")。 -
Pre-computation Filter(预计算过滤) :在调用向量数据库进行相似度搜索(ANN)之前,强制附加过滤条件。例如,生成的查询语句变为:
SELECT * FROM vectors WHERE similarity > 0.8 AND (doc_owner == 'tech' OR doc_owner == 'public')。 通过这种方式,确保了传输给大模型的上下文(Context)仅仅包含该用户有权查阅的片段,从根源上解决了AI场景下的越权访问问题。
四、总结与展望
AIGC项目的安全架构设计比传统应用更为复杂,因为它不仅涉及代码逻辑的权限,还涉及非结构化数据与概率性模型的权限边界。通过本项目,我深刻体会到:在AI时代,鉴别 必须从"人"扩展到"Agent/服务",而访问控制必须深入到"向量数据"的颗粒度。通过引入动态OAuth令牌体系与基于属性的向量检索过滤机制,我们成功构建了一个既开放又安全的AIGC中台。未来,我们将进一步探索基于模型输出内容的实时审计与动态阻断技术,以应对日益复杂的生成式AI安全挑战。