原文为Denny Zhou(Google Deepmind负责人)在Stanford为CS25课程做的一个报告。这篇博客是其笔记。

当我向AI提出一个复杂的问题时,它不仅会给出答案,还会给出详细的、一步一步的、看起来逻辑严密的解题过程。
但是面对很多复杂的问题,或者面对不同体量的模型,这个回答又可能错得很离谱。
这带来一个问题:LLM 展现出的推理能力,究竟是智能的涌现,还是基于海量数据训练出来的更高级的模式匹配?
换句话说,大源模型是真的在推理,还是从网上海量的解题步骤中,选出最像的一个?
关于"LLM是否能够推理"这个问题,学界和工业界一直在争论。
但是讨论这个问题之前,首先应该从定义上明确:什么是LLM的推理?
一个很显然的定义:
从人类给出的问题到最终答案之间的所有中间输出步骤都叫做大语言模型的推理。
这个定义不一定是完美的,但是至少把哲学意义上的思考或者推理转化成了可以明确讨论的东西。

下面是一个很简单的例子:让大语言模型提取每一个单词的末位字母并进行拼接。

显然,左侧就是答案,右侧在输出答案之前进行了一些推理过程。
这不就是人类思考的过程吗?但是没有这么简单,因为llm并不是人类,而是一个概率模型。最好不要将其直接拟人化。
需要指出的是,Zhou他们一开始尝试的是首字母拼接任务,但是所有的模型都可以做得很好。原因可能在于,互联网上有大量的英文首字母缩写,模型可能记住了首字母拼接这样的模式,但是并没有真正理解拼接这个动作。

那么为什么推理步骤很重要?一方面我个人理解是关于大语言模型的可解释性,模型的"思考"过程是可解释性的一部分。
更重要的是,Denny Zhou的一项研究表明,对于一个可解的复杂度为T的模型,一个固定大小的模型可以通过生成O(T)的中间token(推理步骤)来解决它;但是如果直接生成答案,要么需要很深的网络,要么根本做不到这件事情。
用大白话来说,一个简单的模型,只要思考过程足够长,那么它有潜力解决几乎任何的可以计算的问题;但是如果强迫模型直接说出最终答案,模型需要足够的深度来内化整个思考过程。
说实话这个和田渊栋提到的一句话很像:一个人只思考而不动笔,这个人就是一个有限状态机;一个人又思考又动笔,这个人就是一个图灵机。这里提到的动笔就像是显式地输出思考过程,思考就像是模型内部的计算。
这从计算理论原理上体现了推理的重要性。
因此在训练和使用大语言模型的时候,不仅要追求答案,更需要追求过程。

既然我们知道推理过程非常重要,一个自然的问题是,如何让模型来生成推理过程?
此前人们普遍认为,一个普通的、只经过预训练的大语言模型是不会推理的,必须通过思维链或者是微调才能够学会推理。
如下图,Zhou认为这个观点是错的,预训练模型已经准备好进行推理,只需要改变解码的过程。

在下面的这个例子中,采用贪婪解码,也就是说每一步选择概率最高的token进行输出。
但是,在模型输出的概率分布中,如果我们考察概率次高的几个token,会发现正确的答案确实存在于模型的输出空间。
这说明,模型学习了海量文本中蕴含的逻辑关系,具备推理的潜力。
于是问题从教会模型推理,变成如何引导模型把它的思考以正确的形式表达出来。
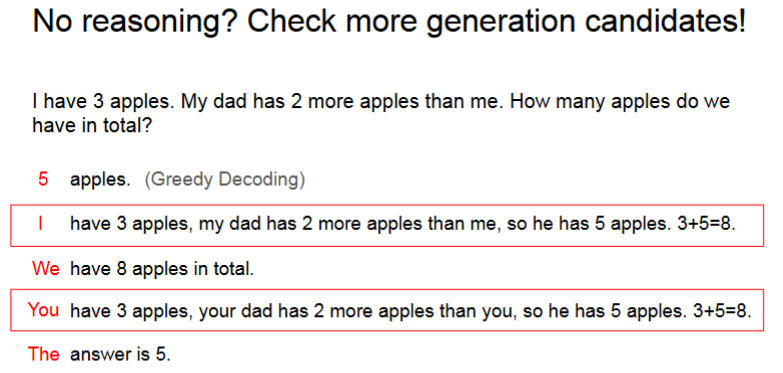
在上一步产生的若干输出中,如何知道哪一些输出是最好的呢?
如上所示,一个自然的想法是看长度。

但是Zhou发现:包含了正确思维链的回答具有非常高的答案置信度。
在这个苹果的例子里,模型预测"8"这个词的概率可能高达98%。
这是一个非常强的信号,因为对于一个拥有巨大词汇表的模型来说,通常每个词的概率都接近于零。
这就像一个人在经过深思熟虑后对自己得出的结论会非常笃定一样。

这个decoding总结起来就是两步,生成一些候选回答,然后选择答案执行度最高的回答。
上面的方法仍然需要你采很多的回答样本。这对于一些token成本敏感性的业务不太友好,而且大多数人玩大模型的时候也不知道如何去看这个置信度。
一个自然的想法是,如何让大语言模型直接把带思考过程的、优秀的答案在内部排个序,最优先输出?

有两种办法,但是他们本质上都算是思维链。
- 第一种办法是向模型输入一个相似问题的题干和回答,给出的例子会极大提升模型生成类似"思考过程"的句式的概率;
- 第二种办法就是直接告诉模型"逐步思考"。

"逐步思考"这种零样本提示证明了我们可以用非常通用的方式来激发模型的推理潜能,虽然效果可能比少样本的烂。

但是这整个事情还是比较奇怪,一个聪明人需要你专门告诉他一步步思考吗?不告诉他这么思考他就不会思考了是吗?
这显然不符合我们对一个真正的智能体的期望。
我们希望思考能力是内化到模型本身,而不是需要被外部触发的。
一个方法就是监督微调。

想法很简单,
- 雇一帮人针对大量的问题写出高质量的一步步的解决方案
- 把标准答案喂给模型
- 把微调过的模型部署到(所有的)新问题中
这个方法是很通用的,但是泛化能力并不好。起初人们以为这可能是数据量不够,然后试图大力出奇迹,扩大了数据规模,找更多的人标出了更多的数据。
但是问题始终存在。

一个教训就是不要盲目地扩大规模。
当你的范式本身是错误的时候,再多的数据也无济于事。
路线错了,知识越多越xx。
那么,SFT 的范式,错在哪了呢?

Zhou:问题出在人身上。人写的答案虽然是对的,但是一定是最好的吗?
第一个尝试是:使用Self-Improve。

分为两步:
- 收集模型生成的答案
- 用正确的答案来训练,用一个验证器(verifier)判断一个答案是否正确
形成一个"自我进化"的闭环。

为什么模型自己生成的数据会比人类专家的数据效果更好呢?
这背后蕴含着机器学习的一个第一性原理:直接优化你想要的东西。
我们假设人类的思维过程就是最优的。实际上,人的思维方式千差万别,充满了跳跃和不一致。
人给出的标准答案会不会也存在着许多假设性的东西?对于模型来说这可能并不是最容易学习和泛化的路径。
这让人想起示教学习的原理,小模型直接学习人类的标注结果可能学的不好,但是让大模型教小模型学习,效果就可能好很多
我们不再关心模型的解题过程是否和人类一模一样,我们只关心一件事它最终的答案是否正确。
相当于用强化学习里的奖励信号来指导模型的学习,类似于policy gradient,模型需要调整自己的参数,尽可能生成获得高奖励的序列。
相当于我们直接优化这个东西:给定问题和模型,最大化回答的质量。如下图。

这么看来,我们其实不需要什么激励模型去思考这种把大语言模型当成人看的思路,直接定义优化目标,计算梯度,然后反向传播就完事了。

模型会自己去探索什么样的"思考过程",能够最稳定、最泛化地导向正确答案,这些过程可能看起来跟人类的思维不完全一样,但是它们更符合模型自身内部结构的学习路径。
这个范式的转变,具有很大的意义。
这意味着模型的自我进化最需要的是一个"验证器"verifier,能够可靠地、自动地判断答案好坏。
as an old saying goes:

一句题外话,下面这张幻灯片其实并没有出现在实际的talk中。
这张片子上讲的问题是,根据前面从计算理论分析模型reasoning能力的结论,如果我们想提升模型的能力,两个重要的指标就是提升输出长度以及提升模型的深度。

大模型展现出的智慧是来自于逐个token的预测,而不像是深蓝计算机(可能来自于穷举的搜索)。

下面是一个例子,让大模型玩一个复杂的24点游戏,当然这里比"24"点复杂得多。这是一个困难的组合优化问题。传统方法需要进行暴力搜索。
模型首先说2025这个数字比较大,因此乘法在解题中很重要。
基于此更进一步,模型甚至能注意到2025是45的平方。然后通过这样的自我推理,模型得到了答案。整个过程没有任何的穷举搜索。

萨顿这个人说,人工智能领域的研究表明,能够大规模应用并且成功的只有两种方法,一种是学习一种是搜索。
Zhou在这里有不同意见:也许只需要学习就足够了。搜索可以作为被调用的功能,但是在构建模型的核心推理能力时重点应该放在"学习"上。
虽然在下面这张ppt中他完全没有说这个话。他说的是:"我们要的是像人类一样具备'发现能力'的 AI 智能体,而不是肚子里装满了人类'已经发现的知识'的机器。把我们的发现直接植入到 AI 中,只会让我们更难看清(或阻碍我们理解)真正的发现过程是如何实现的。"

RL微调(SFT)的优缺点很明显:对于可以自动判断正误的问题,泛化性很好。
但是并不是所有的任务都是可以自动判断正误的。你比如,如何给一篇作文打分?

下面是两种进一步提升LLM性能的技术:聚合与检索。

时刻记住,大模型是模型而不是人,他们以预测下一个token为生。

这就引出了一个问题,大语言模型做推理的时候(贪婪解码),从数学上看实际在干什么?实际上在根据问题,生成最好的推理和最好的回答。
即选择思考过程+答案整个序列联合概率最高的那一个。这和我们想要的东西不同:我们只想要最好的回答。

于是通过一些简单的全概率公式就可以得到:

通过独立采样来近似概率分布。选择的是最频繁出现的答案。此即第一项技术:自洽性。

它背后的直觉是,如果一个答案是正确的,那么通往这个答案的"道路"应该有很多条。

即使模型在某条路上犯了小错误,它在另一条路上可能就走对了。正确的答案会在多次尝试中反复、稳定地出现。
这充分说明,模型的单一输出可能存在偶然性,但是它多次输出的"共识"则具有高度的可靠性。
以下是几个相关的小问题:

如果模型不生成中间步骤直接输出答案,用自洽性还有用吗?
- 没用,而且没必要。因为在这种情况下我们直接就可以看到每个答案的概率,选择概率最高的那个就行了。自洽性是专门为"推理"这种包含隐藏变量的场景设计的。
我能不能不进行多次采样而是让模型一次性生成多个不同的答案呢?
- 这样做没有意义,违背了用独立采样来近似概率分布都原则
自洽性也有局限:答案需要是唯一的。

比如上面这种问题,它的答案是排名不分先后的,这就带来了非唯一性。
提出通用的自洽性:在这种非唯一性下,让模型自己判断什么回答算是一致的。

第二项技术是检索(Retrieval)
关于大语言模型的另一个永恒的争论是,它到底是在"推理",还是在"检索"?
它是在进行逻辑推导还是仅仅从记忆里找一个相似的已知答案?
Zhou:为什么要在两者之间做选择呢?把检索和推理结合起来,效果就是更好。有没有可能答案是both?

一个类比推理的例子。在大模型求解问题之前,先让它想想可能相关的问题。------先在自己的记忆库中检索。

另一个例子叫"退一步思考"(Step-Back Prompting),在解决一个具体的、复杂的物理问题前先提示模型,退一步思考一下解决这类问题所需的基本物理原理是什么?
模型会先总结出相关的定律和公式然后再用这些"检索"到的原理来指导具体的解题过程。
所以不必再纠结于推理和检索的二元对立。
一个强大的推理系统必然是一个开放的、懂得如何利用外部知识的系统。
Take aways:

我们今天讨论的强化学习微调和自洽性等核心技术,都严重依赖于"任务答案可被自动验证"这一前提,无论是拥有唯一解的数学题,还是能通过单元测试的代码题。
然而在现实世界中,大量更具价值的任务并不具备这种天然的"验证器"。
赏析诗歌,评价代码可读性,计划可行性etc
面对这些缺乏唯一标准答案、充满主观性与复杂权衡的领域,如何定义"奖励"并构建有效的"验证器"?
此外,将精力从容易随着模型能力提升而达到"饱和"的基准测试"刷分"中抽离出来,转而投向构建那些真正能够解决实际问题的应用。
结束语:

真相最终总是比你想象的要简单(The truth always turns out to be simpler than you thought)