一、深度学习的介绍
1.深度学习是什么?
我们知道机器学习就是让机器学会像人类一样会学习和推理。
神经网络之于机器就相当于人脑之于人。(神经网络是一种由多个神经元(或称为节点)组成的计算模型,它模拟了生物神经系统中神经元之间的连接方式。)
所以深度学习无非就是研究如何让这个机器的'脑子'(神经网络)更好用,更精进,更像人脑。
2.深度学习的内容
深度学习就是让机器自动学习多层次的、抽象的特征表示,从而处理更复杂的模式(如图像、语音、自然语言等)。
主要特点是使用多层次的神经网络来提取和学习数据中的特征,并通过反向传播算法来优化网络参数,从而实现对复杂数据的建模与分类。
3.神经网络
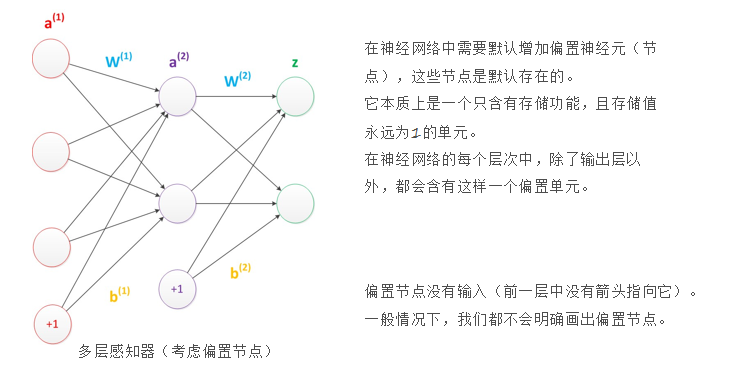
(1)神经网络的构造
神经网络有输入层、隐藏层和输出层组成,其中输入层用于接收外界的输入信号,输出层用于输出预测结果,隐藏层则用于处理输入信号并产生中间结果。
- 设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定;
- 神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别;
- 结构图里的关键不是圆圈(代表"神经元"),而是连接线(代表"神经元"之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。
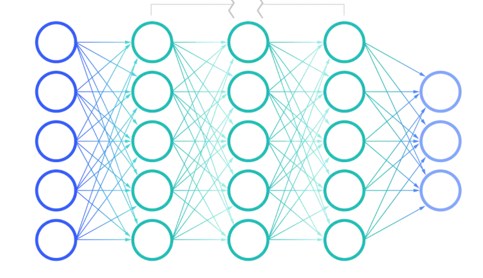
一般情况下神经网络:
- 神经网络:每个节点代表一种特定的是由大量的节点(或称"神经元")和之间相互的联接构成。
- 输出函数:称为激励函数、激活函数(activation function)。
- 每两个节点间的联接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。
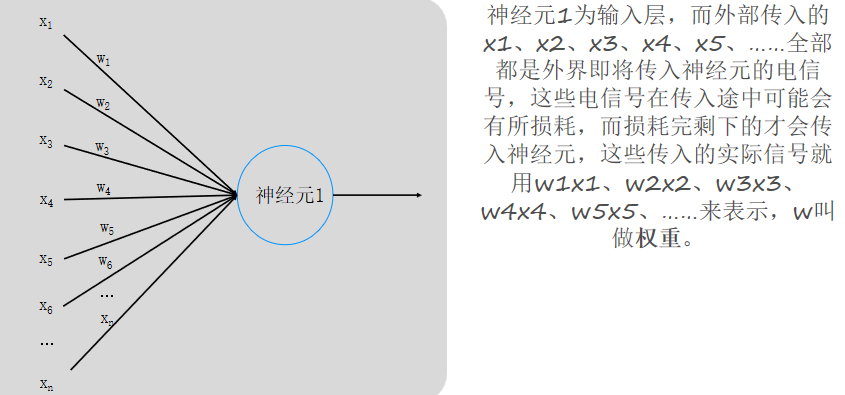
(2)神经网络的本质
通过参数与激活函数来拟合特征与目标之间的真实函数关系。但在一个神经网络的程序中,不需要神经元和线,本质上是矩阵的运算,实现一个神经网络最需要的是线性代数库。
4.从线性模型到向量化演变的过程
机器学习中我们学习逻辑回归就是给数据进行分类,在类之间拟合一条直线,把这条直线的公式进行变换到最后权重形式也就是向量化,这描述的是线性模型从代数形式到几何与向量化表示的演变过程。

5.感知器
由两层神经元组成的神经网络--"感知器"(Perceptron),感知器只能线性划分数据。
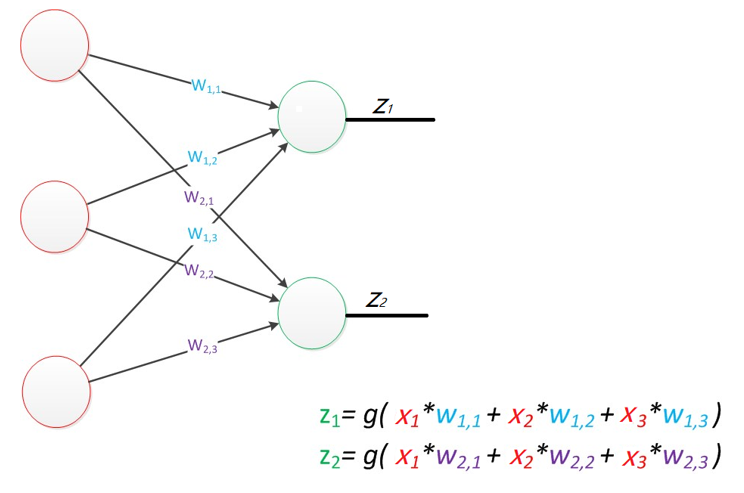

输出的结果与训练集标签进行损失函数计算,与逻辑回归基本一致。
多层感知器
加了一个中间层,也就是隐藏层
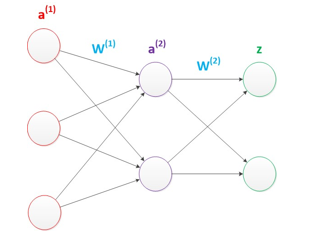
6.偏置(Bias)
偏置 是神经网络中每个神经元自带的一个可学习的常数项,相当于一个"调节阀"。偏置让神经元有"灵活性",可以学习到数据中固有的偏移量,提高模型的拟合能力。
类比理解

7.深度学习的训练方法---梯度下降
模型训练的目的是使得参数尽可能的与真实的模型逼近。
那么我们先举个例子,充分理解一下几个概念之间的关系。
假设,如果'我'是老师,机器是我的学生,损失函数是机器写作业的错误数量。
我选择了梯度下降这种教学方式,目的是提高机器的正确率。
梯度下降'教学方式'中有-log惩罚和正则化惩罚两种工具,这两种工具就是我提升机器'作业'正确率的两种方法,所以-log和正则化惩罚是协同作用在损失函数上的。
-log惩罚就相当于,我批改机器的'作业',说明他哪里正确哪里错误,这样下次遇到一样'题目'的时候,就会写对,从而提高他的正确率。
但是他只是会了'这一题'可不行,要学会举一反三,所以正则化惩罚就是让他在这道题目里总结经验规律,不仅是'这一题',类似的'题目'也能写对。
梯度下降就是这套"批改 → 指导 → 再练习 → 再批改"的循环教学过程。
(1)损失函数
损失函数用于判断预测的结果和真实值的误差,损失函数用一种方式量化了这个误差,可以在使用梯度下降优化算法训练数据的时候调整参数来尽可能的减小损失。
常用的损失函数:
- 0-1损失函数
- 均方差损失
- 平均绝对差损失
- 交叉熵损失
- 合页损失
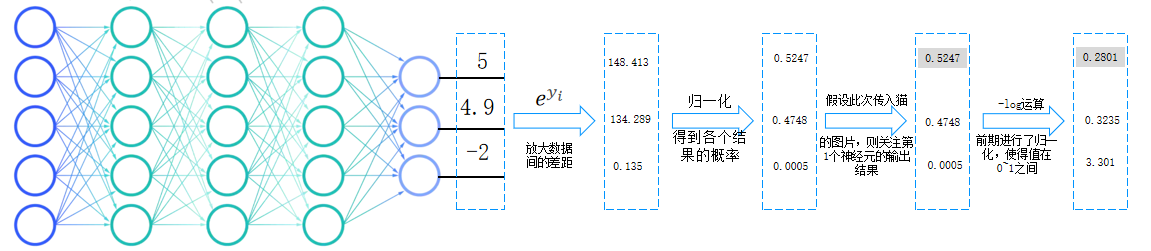
(2)-log惩罚
输出层得到原始分数,使用softmax进行归一化概率,取真实类别概率的-log作为损失,为什么用-log,概率越接近1,损失越接近0,概率越低,损失越大。
以上就是-log惩罚(交叉熵损失),衡量预测与真实标签的误差,是损失函数的主体,直接表达预测与真实的差距。目的是让模型预测更准确(拟合数据),通过梯度影响所有参数更新。
(3)正则化惩罚
正则化惩罚在每次训练迭代中,向损失函数添加一个与权重大小相关的惩罚项,主要用于惩罚权重参数w,一般有L1和L2正则化,使得选择的权重能尽可能依赖重要特征。
以上就是正则化惩罚,惩罚权重参数本身的大小,是损失函数的附加项,目的是防止模型过拟合(控制复杂度),直接对权重进行约束。
具体解释可以参考链接文章最末第六点:
(4)梯度下降
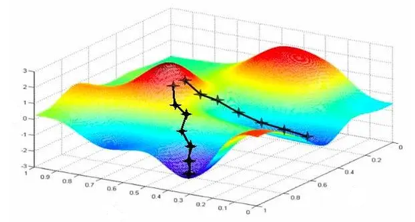
梯度下降就是通过计算损失函数对每个权重的偏导数(梯度),然后沿梯度下降方向一点点调整权重,让损失越来越小的方法。学习率是'步长',初始化是'起点',目标是找到损失最低的'谷底'。
偏导:求每个权重的更新方向
梯度:把所有偏导数组合成更新方向向量
梯度下降法(最陡下降法):沿梯度反方向调整权重(因为要最小化损失)
学习率:控制更新步长(决定沿着帝都方向走多远,太小收敛慢,太大可能跳过最优点甚至发散)
初始化:随机设定起点,影响收敛路径
全局最优策略:多次随机初始化,避免陷入局部最优
二、深度学习相关配置
电脑有显卡的从第一点开始看,如果没有显卡,cpu用于学习深度学习也是完全够用的,从第二点torch包开始看。
1.CUDA
(1)cuda是啥?
CUDA 是 NVIDIA 公司开发的一种并行计算平台和编程模型,简单说就是让显卡(GPU)不仅能打游戏、看视频,还能帮CPU做科学计算和数据处理。
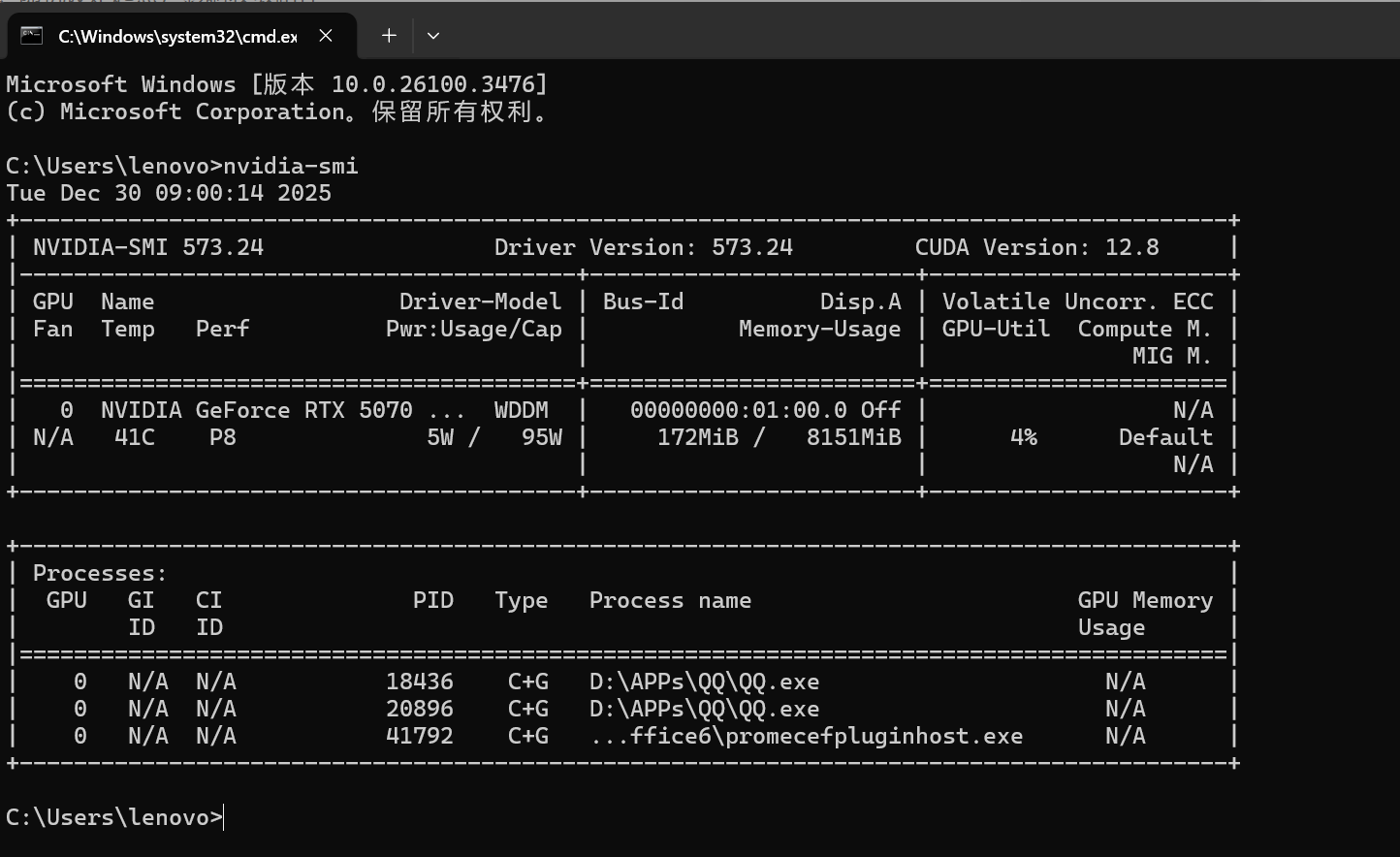
(2)查看电脑支持的版本号
win+r输入cmd,打开命令提示符,输入命令nvidia-smi,输出cuda version就是电脑所支持的最高版本号,我这里是12.8
(3)下载cuda
到cuda官网下载:
https://developer.nvidia.com/cuda-toolkit-archive
我这里浏览器自动翻译成中文了,点进网站一开始应该是全英的

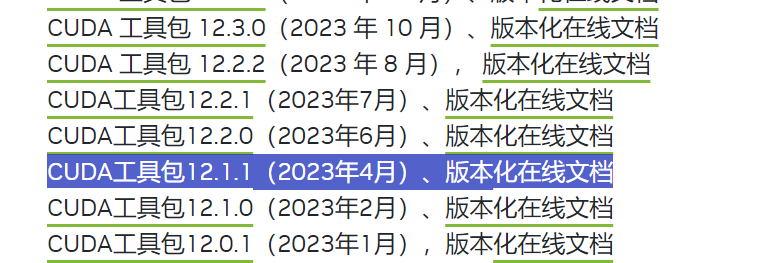
找到对应的版本:选择低于电脑支持版本,防止出现不稳定的情况
这里我选择12.1.1版本
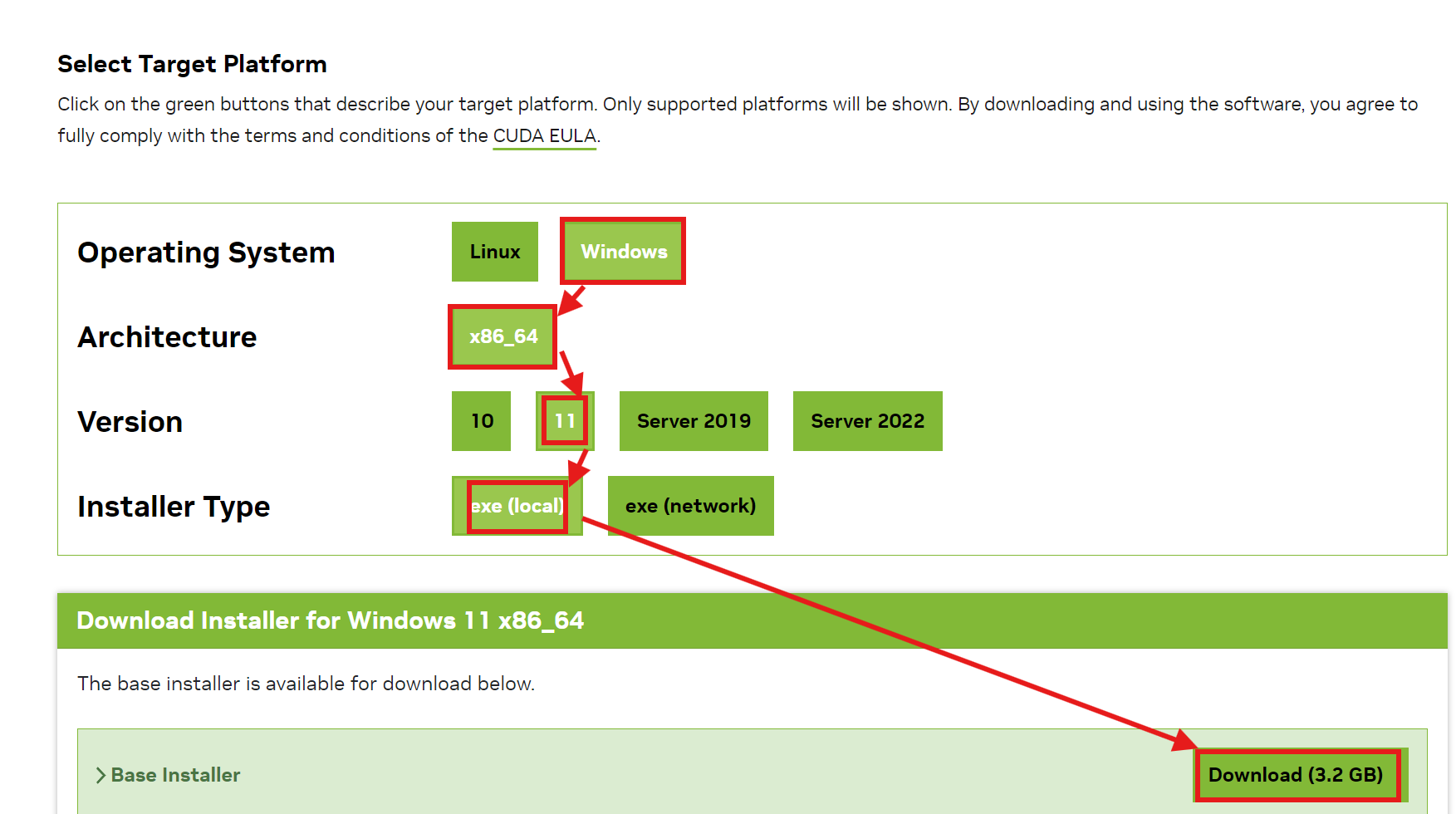
下载完之后进行安装

同意并继续
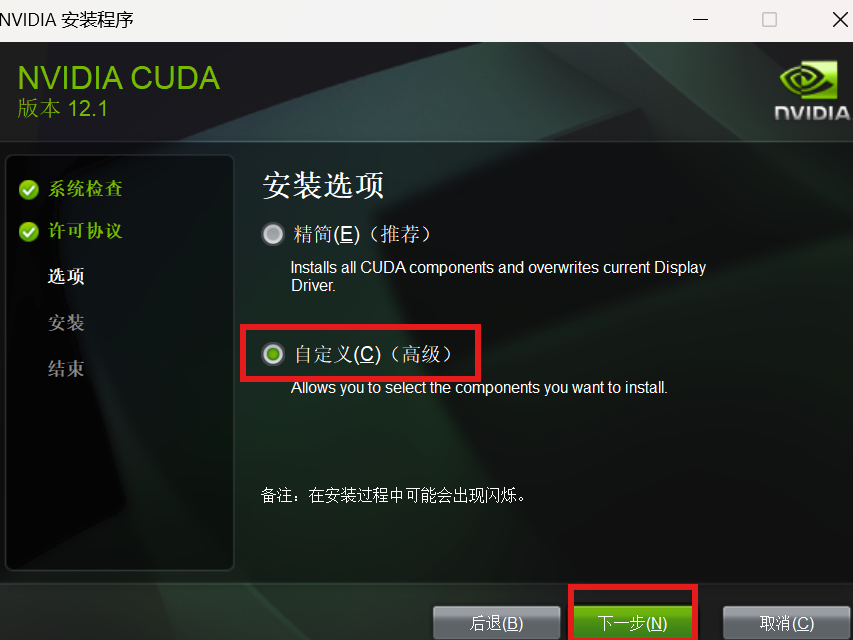
点开cuda取消红框的这一项
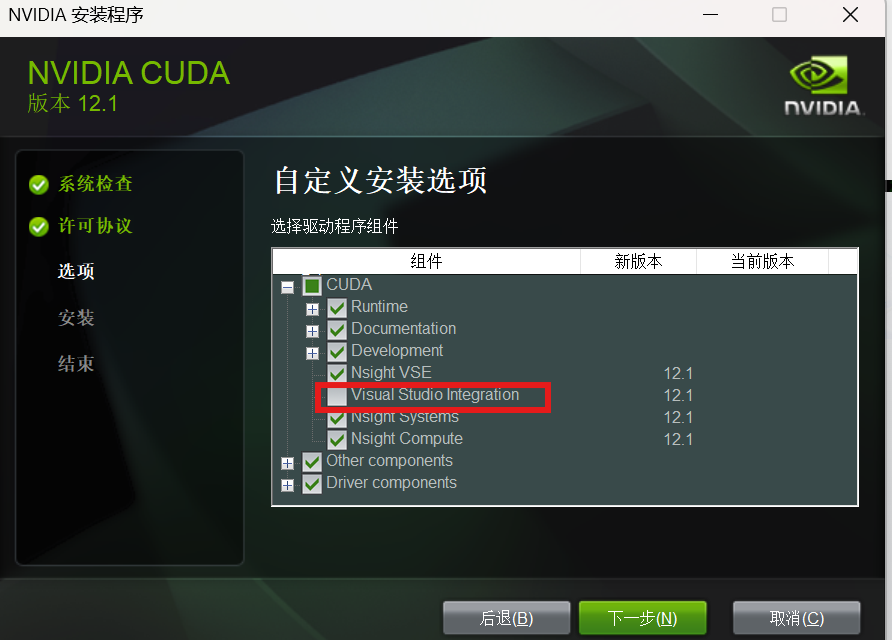
一般情况下不要轻易改这个路径,防止出现问题
安装中......安装后下一步,完成就好了
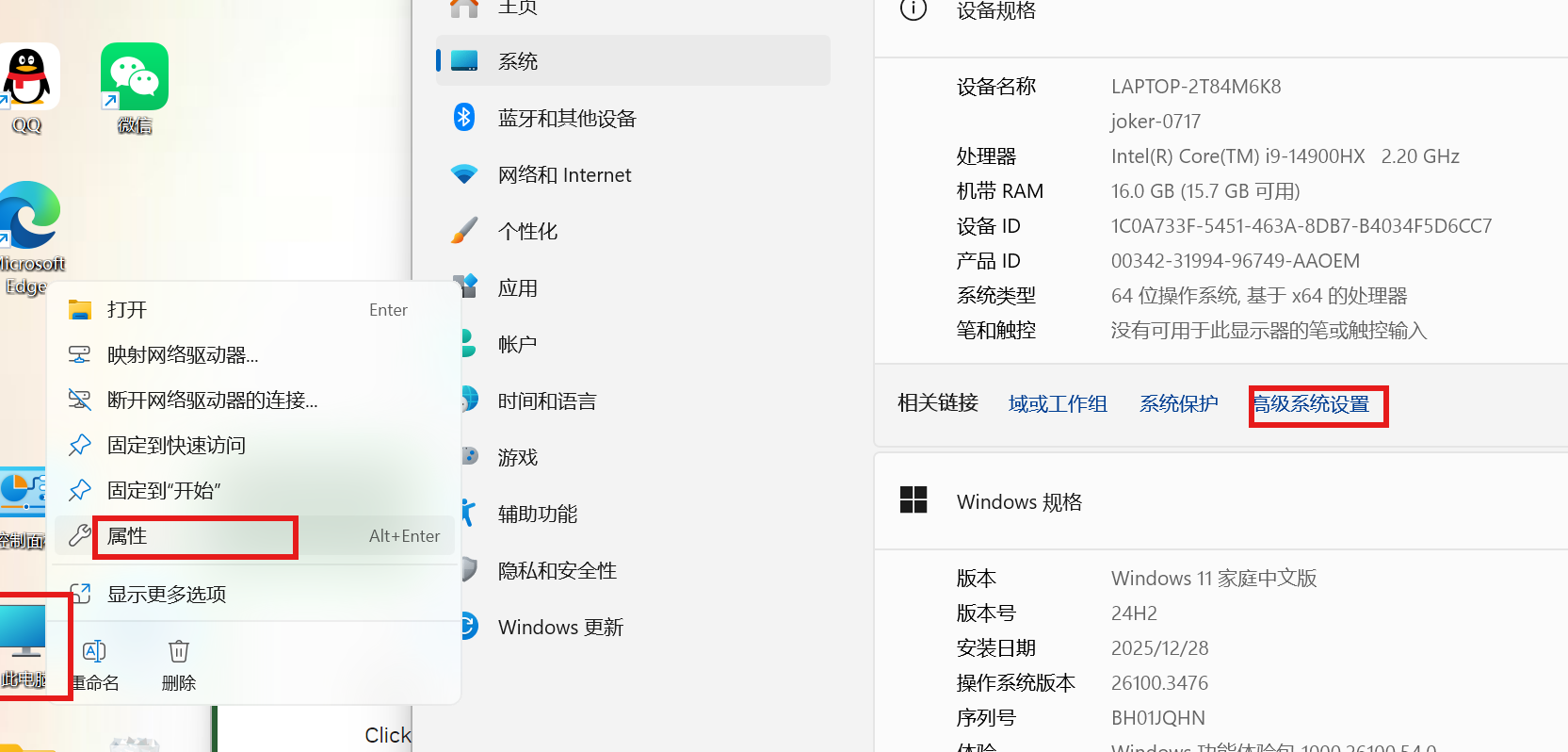
(4)检查环境变量,检查方法有两种
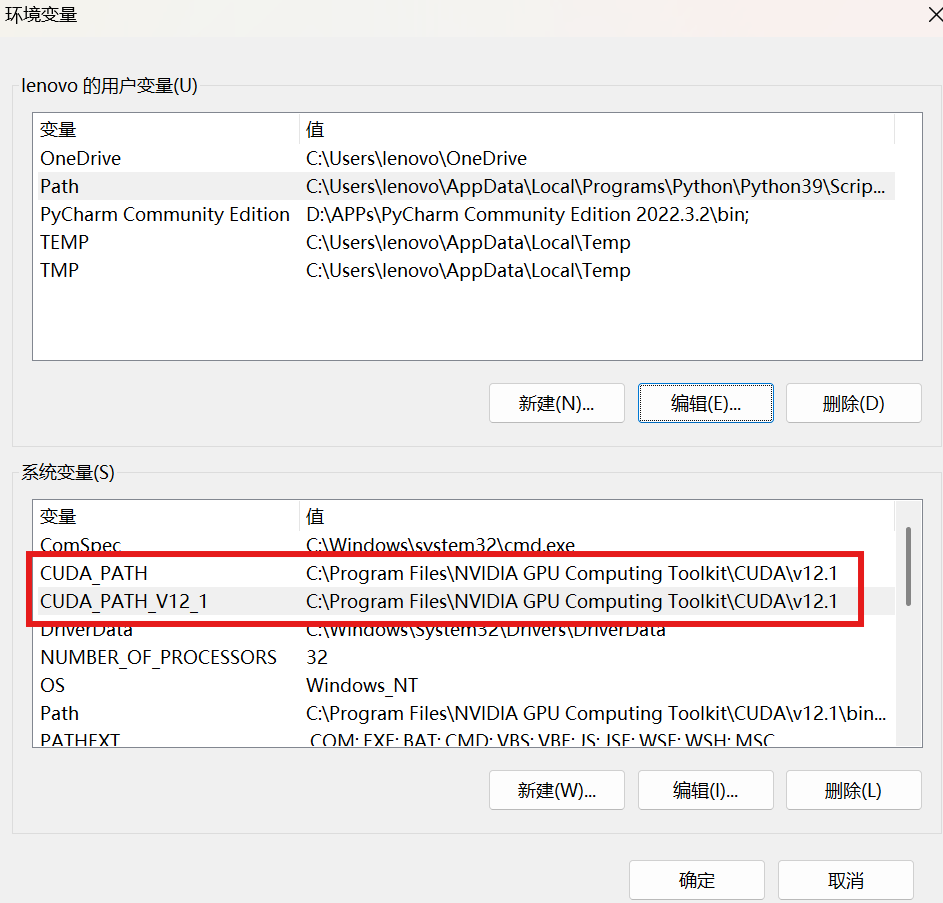
我们检查环境变量的目的就是确保CUDA能被系统找到,确保CUDA_PATH和CUDA_PATH_V12_1在环境变量中
方法一,窗口中查看环境变量
右击此电脑,点击属性,弹窗后点击高级系统设置,新窗口中点击环境变量
或者可以系统搜索栏中直接搜索环境变量
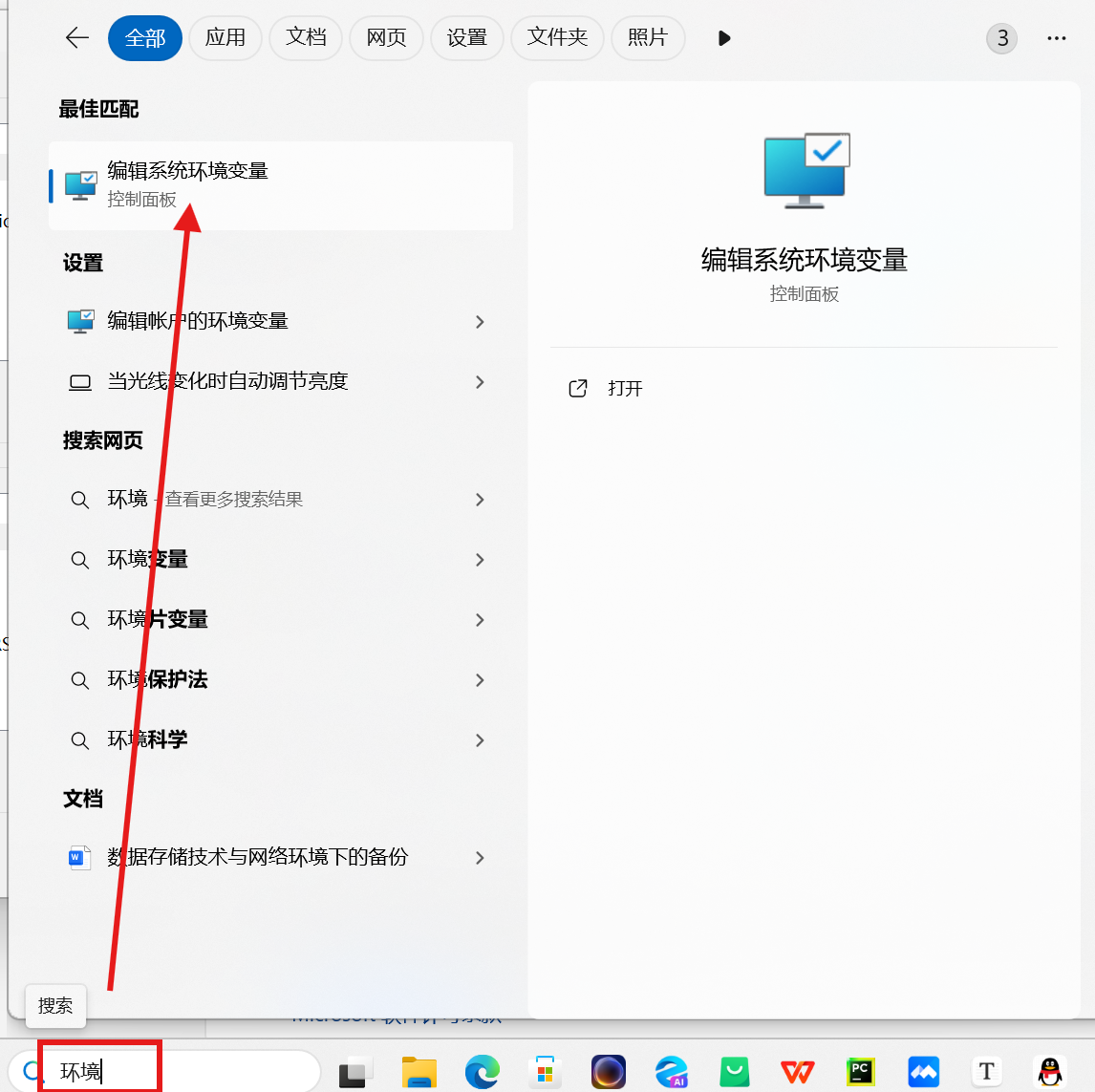
查看是否有这两个环境变量,如果没有需要自己手动添加
方法二,命令提示符
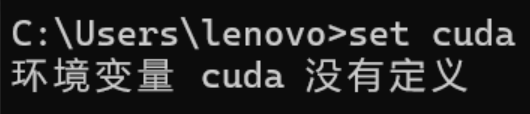
重新打开一个命令提示符窗口输入set cuda。

下载cuda之前打开的命令提示符窗口还没有刷新,输入set cuda是没有反应的,会出现下面情况
(5)测试是否成功安装
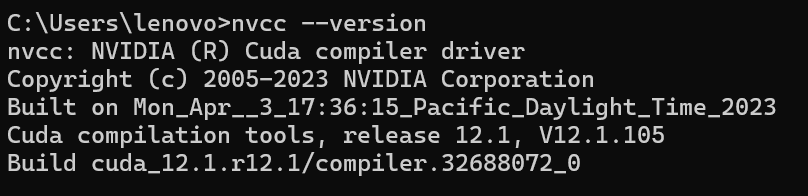
输入nvcc --version或者nvcc -V,查看是否有cuda,如果有则安装成功
2.下载pytorch
Torch(现在叫PyTorch)是一个深度学习的"工具箱",专门用来搭建和训练人工智能模型。
pytorch官网:https://pytorch.org/
打开官网后,不要按照他给的下载,我们只看他给的命令后面的网址,把网址复制到浏览器打开
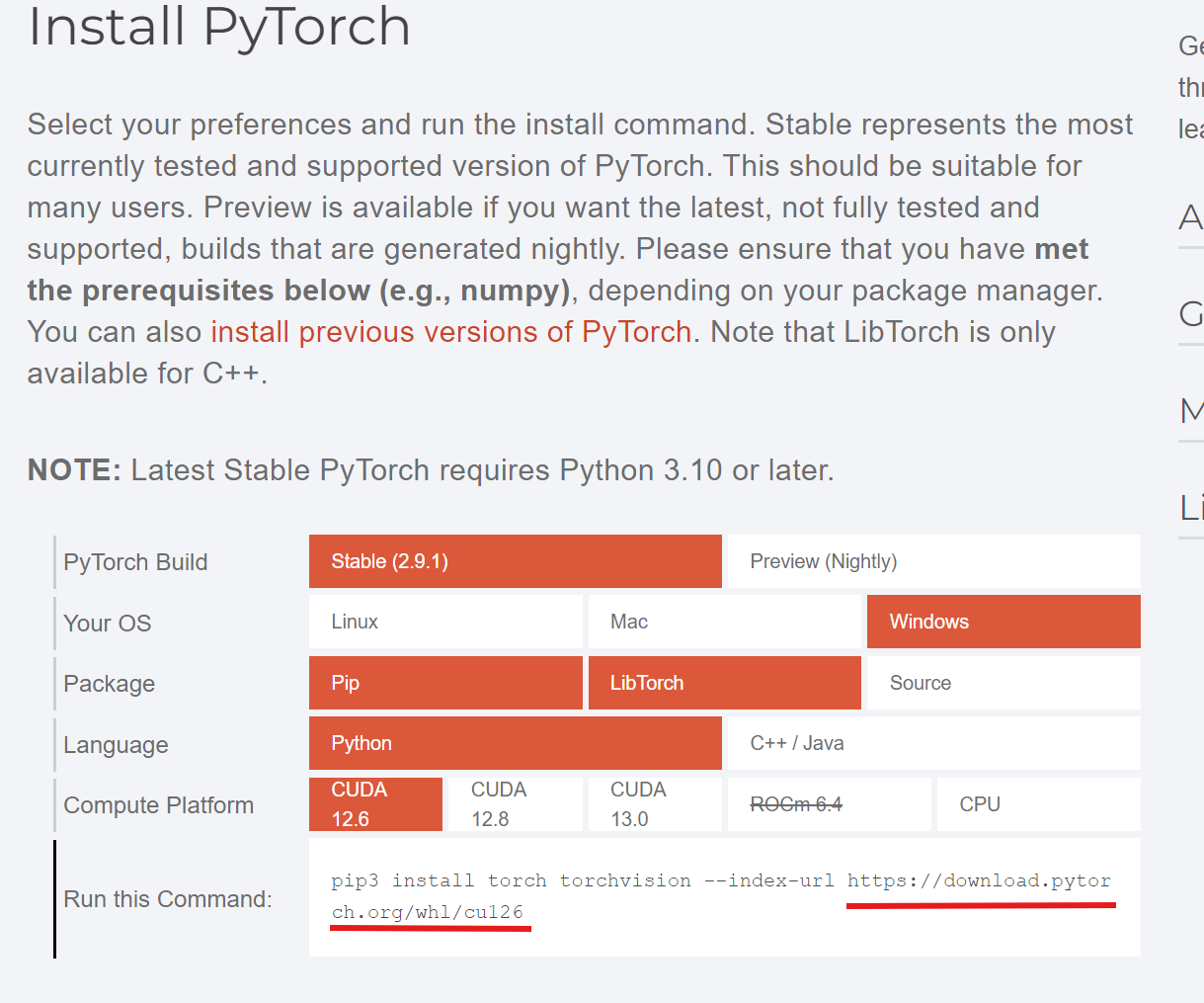
出现这样的界面,在这个列表中找到torch并点击
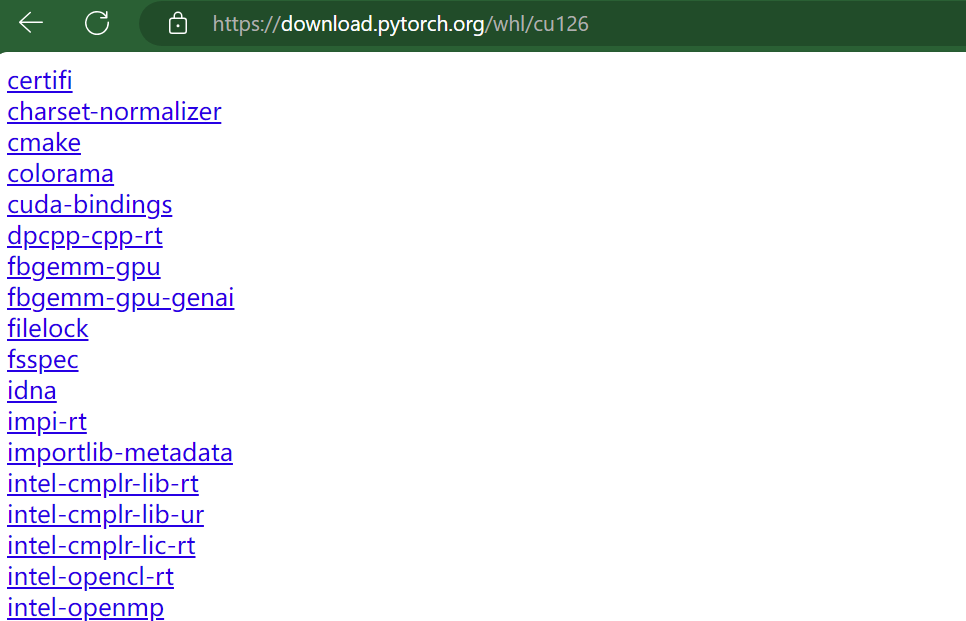
选择适合自己的版本,cu121是cuda版本12.1的意思,cp39是python3.9,win是windows系统,如果是使用cpu,就下载cpu版本就好,在该网页按ctrl+f键可以搜索你想要的版本
下载好之后,复制文件的绝对路径

pip install 绝对路径
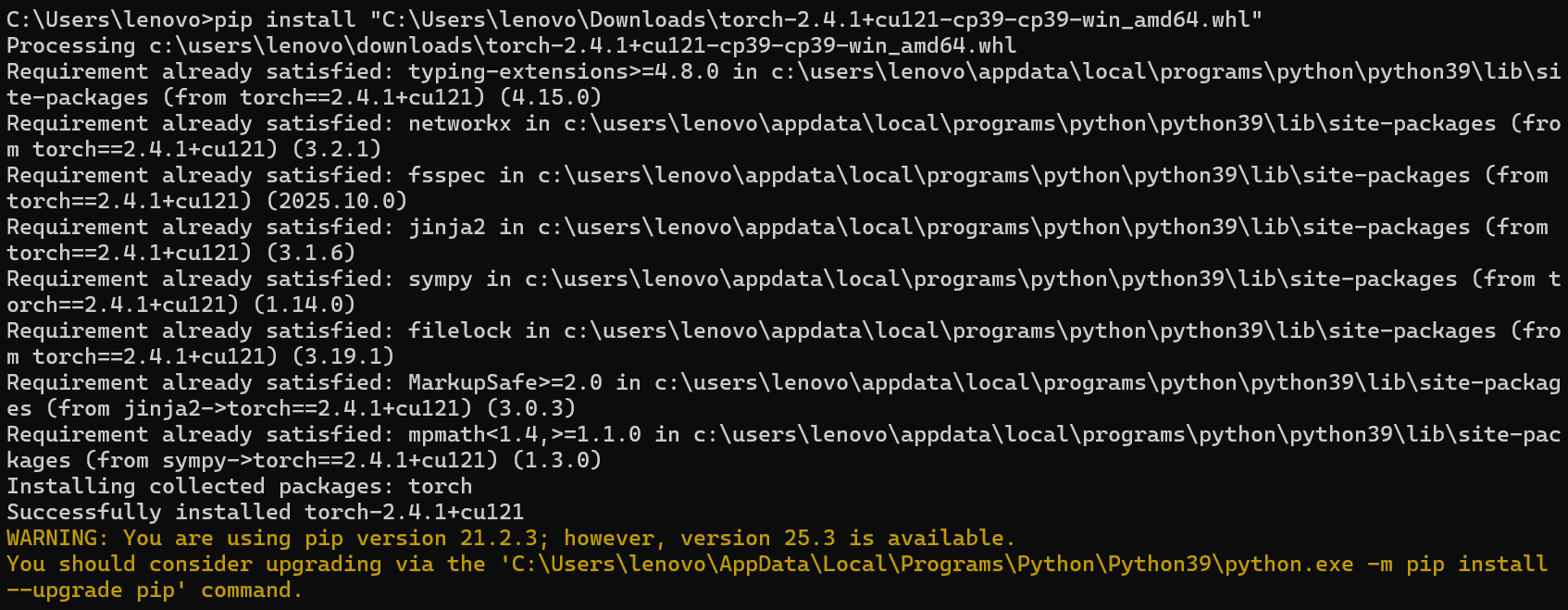
3.下载torchaudio库
TorchAudio 是 PyTorch 的"耳朵"------专门处理音频数据的工具箱。
和下载torch一样,在网址列表中找到torchaudio
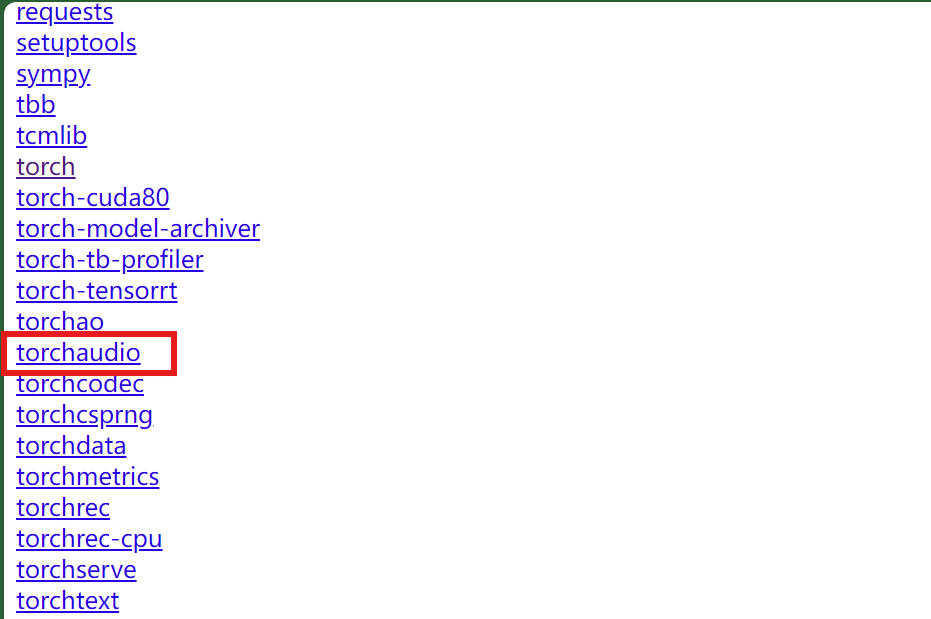
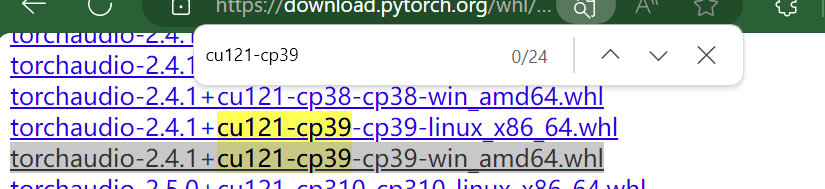
下载和torch对应的版本
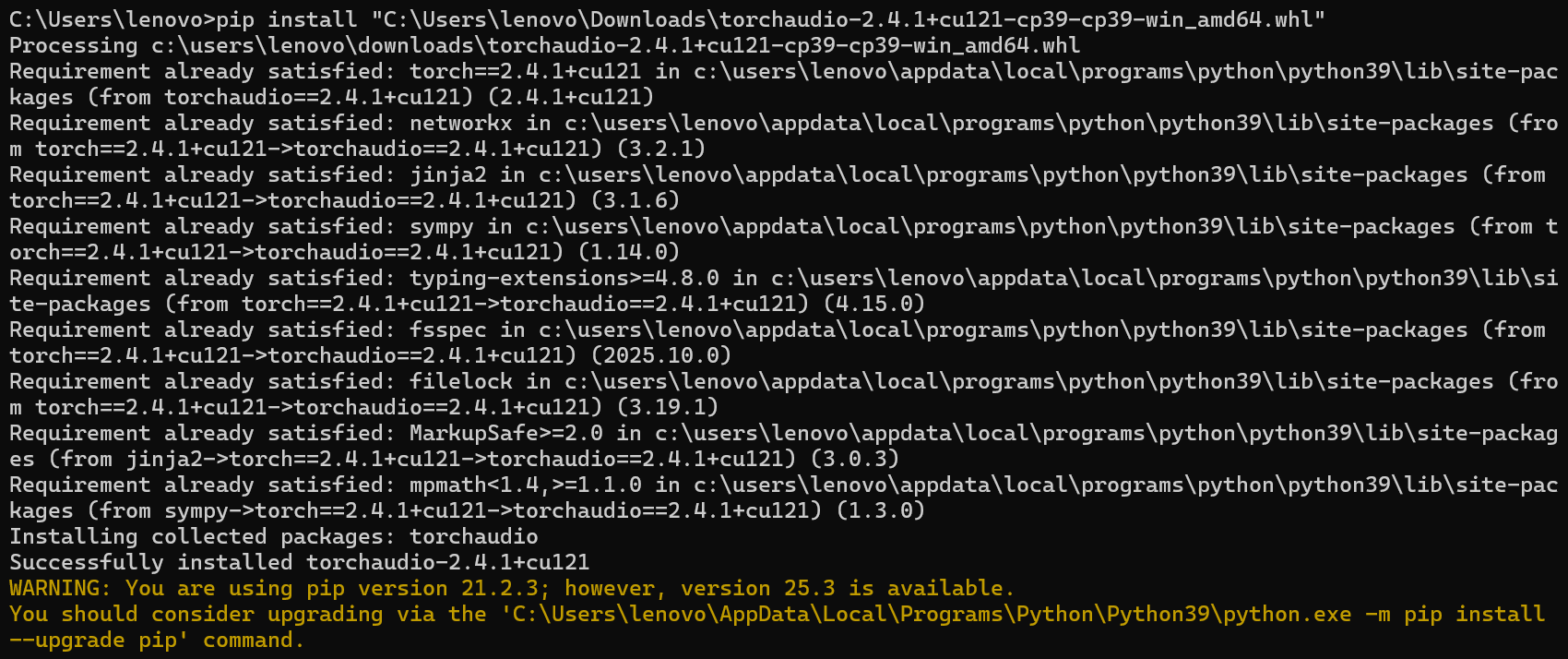
下载好后也是复制文件绝对路径,pip install 绝对路径
4.下载torchvision
TorchVision 是 PyTorch 的"眼睛"------专门处理图像和视频的工具箱。
在网页列表中找到torchvision

找到对应的,不能随便下载,虽然这里不像torchaudio和torch有一样的版本号,但是也是对应的,这个可以询问大模型对应的版本进行下载
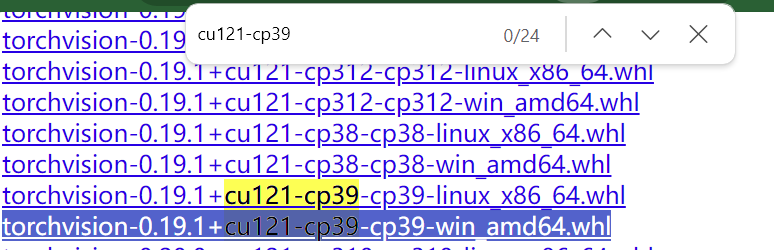
复制文件绝对路径,pip install 绝对路径
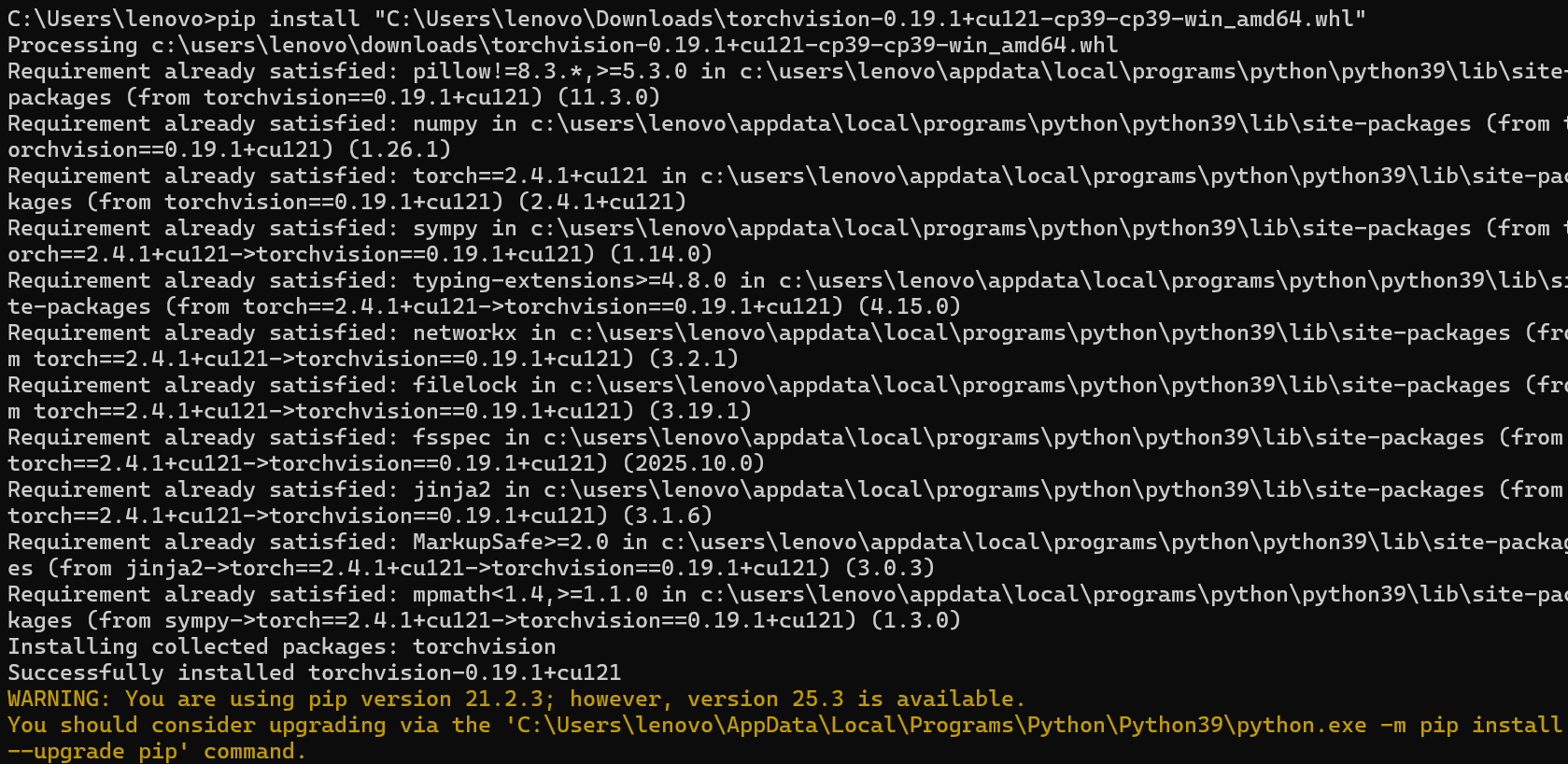
输入pip list,可以查看

用cpu的也是这样下载的
演示一遍cpu的下载过程(演示之前我已经把前面cu版本的三个库全部卸载)
我选的是这个版本,什么版本合适该下载哪个版本可以询问大模型

也是pip install 文件绝对路径
