消息队列入门实战:从零搭建异步通信系统 - 系统架构概览
解耦 · 异步 · 削峰 · 可靠性
阅读时间: 30 min
掌握消息队列,就是掌握现代系统解耦与弹性伸缩的关键钥匙。
目录
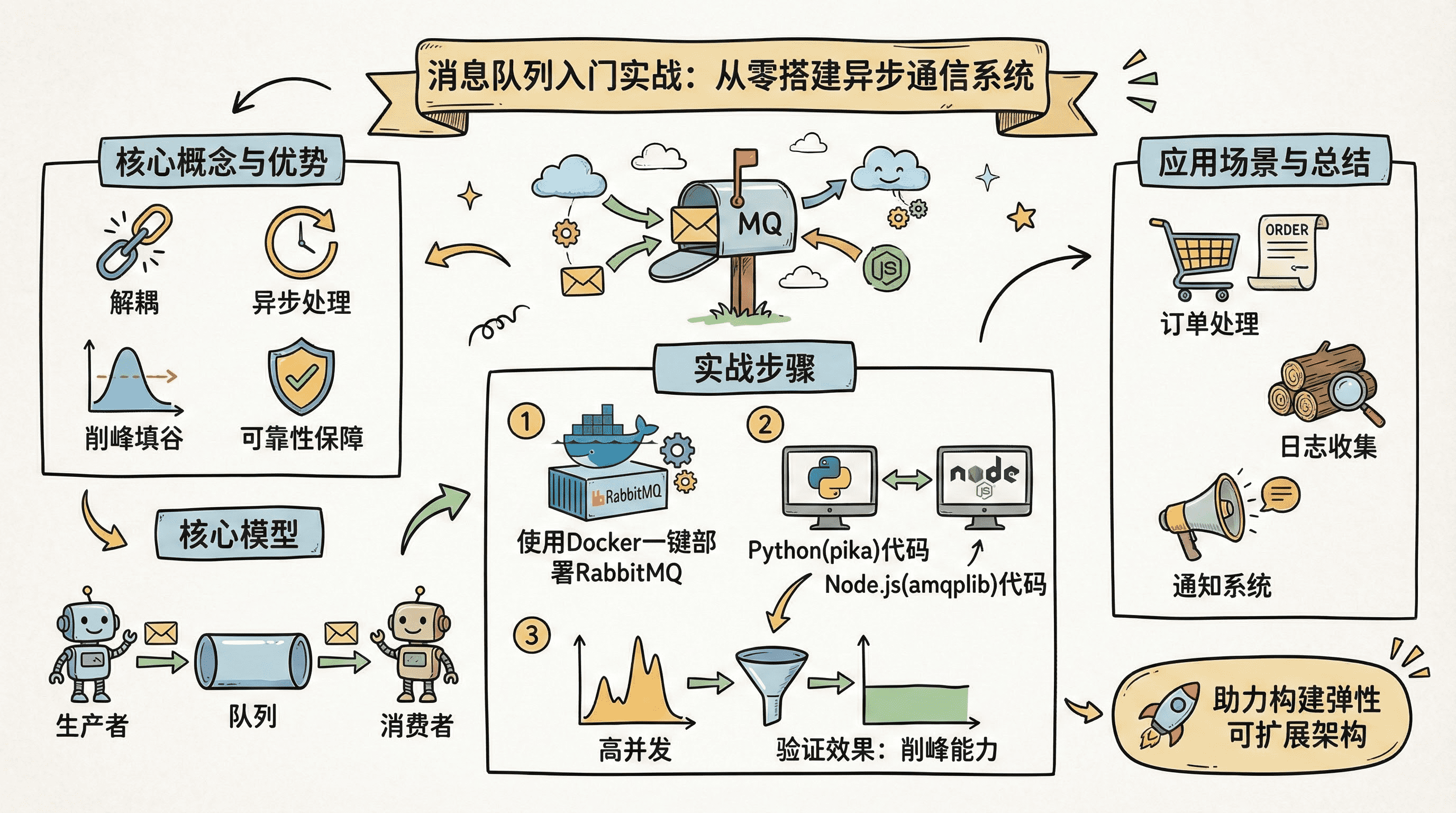
在现代分布式系统中,应用间直接调用常常导致强耦合、性能瓶颈和系统崩溃风险。消息队列作为异步通信的基石技术,能有效解决这些问题。本教程将带你从概念到实践,快速掌握消息队列的核心原理与基础实现,助你构建高可用、可扩展的系统架构。
---## 什么是消息队列?核心概念解析
你是否遇到过这样的场景:用户下单后,系统需要同时处理库存扣减、积分发放、优惠券核销、邮件通知、日志记录......任何一个环节卡顿或失败,都会导致整个流程阻塞,用户体验直线下降?想象一下,在"双11"零点高峰期,成千上万的订单如洪水般涌来,你的服务器CPU飙升、数据库连接池爆满,最终系统崩溃------这不是危言耸听,而是无数企业曾真实踩过的坑。
消息队列让系统组件彼此独立演进,是构建弹性架构的第一步。
消息队列(Message Queue,简称MQ)正是为解决这类问题而生的"系统缓冲器"。它通过引入中间层,将原本紧密耦合、同步执行的操作,转变为异步、松散协作的模式。就像快递中转站一样,生产者把"包裹"(消息)投递到队列,消费者按自己的节奏取走处理,彼此无需等待,也互不影响。这种"异步通信与解耦"的设计哲学,是现代分布式系统的基石之一。
消息队列的基本工作模式:生产者-队列-消费者
消息队列最核心的工作模型可以用三个角色概括:生产者(Producer) 、队列(Queue) 、消费者(Consumer)。
- 生产者:负责创建并发送消息。例如,当用户提交订单时,订单服务作为生产者,将"订单已创建"事件封装成消息,推送到指定队列。
- 队列:作为中间存储介质,持久化或临时保存消息,确保消息不丢失,并按照先进先出(FIFO)或其他策略排序。
- 消费者:从队列中拉取消息并进行处理。比如,邮件服务监听订单队列,一旦发现新消息,就触发发送确认邮件的逻辑。
消息队列核心流程:生产者发送消息至队列,消费者异步拉取并处理,实现系统解耦
这个过程看似简单,却蕴含着强大的工程价值:生产者发送完消息即可立即返回,无需等待消费者处理完毕;消费者可以按自身能力消费消息,哪怕暂时下线,消息也会在队列中安全等待。两者在时间和空间上完全解耦。
四大核心优势详解:解耦、异步、削峰、可靠性
为什么消息队列能在高并发架构中占据如此重要地位?因为它一次性解决了四个关键痛点:
1. 解耦(Decoupling)
系统模块之间不再直接调用,而是通过消息队列间接通信。例如,订单服务不再需要知道邮件服务的IP地址或接口协议,只需往队列发消息。未来即使邮件服务重构或替换为短信服务,订单服务也无需改动------真正做到"高内聚、低耦合"。
2. 异步(Asynchronous Processing)
用户点击"下单"按钮后,系统只需将请求写入队列即可快速响应,后续耗时操作(如生成PDF发票、调用第三方风控)由后台消费者慢慢处理。用户感知到的是"秒级响应",而不是"转圈等待"。
3. 削峰(Peak Shaving)
面对突发流量(如秒杀活动),消息队列像水库一样蓄洪。大量请求涌入时,队列暂存消息,消费者按稳定速率处理,避免后端服务被瞬间压垮。等高峰期过去,积压的消息再逐步消化,保障系统平稳运行。
4. 可靠性(Reliability)
主流消息队列支持消息持久化、ACK确认、重试机制和死信队列,确保"消息不丢、不错、不重"。即使消费者宕机,重启后仍能继续处理未完成的消息,极大提升业务连续性。
典型应用场景举例:订单处理、日志收集、邮件发送
消息队列并非"银弹",但在特定场景下堪称神器:
-
订单处理系统:用户下单 → 订单服务写入MQ → 库存服务、支付服务、物流服务分别消费消息并行处理。任一服务故障不影响主流程,支持事后补偿。
-
日志收集与分析:各微服务将操作日志发送至日志队列,由专门的日志消费者统一采集、清洗、入库或转发至Elasticsearch,避免日志写入拖慢业务接口。
-
邮件/短信通知:注册成功、密码重置、促销提醒等非实时强需求的通知类任务,全部通过队列异步下发,既提升用户体验,又降低对通知渠道服务商的瞬时压力。
⚠️ 注意: 消息队列虽好,但并非所有场景都适用。对于强一致性要求极高的交易核心链路(如银行转账),仍需谨慎评估是否引入异步机制。
消息队列的本质,是用空间换时间、用复杂度换弹性。它不是简单的"排队工具",而是构建高可用、可扩展、易维护的现代软件架构的关键拼图。理解了它的核心概念与价值,下一步,我们就该动手搭建属于自己的消息队列环境了。
下一章节《环境准备:安装RabbitMQ与开发工具》将带你一步步在本地部署RabbitMQ,配置可视化管理界面,并准备好Java/Python等常用开发SDK,为实战演练打下坚实基础。
环境准备:安装RabbitMQ与开发工具
你是否遇到过这样的情况:兴致勃勃想学习一个新中间件,结果光是搭环境就折腾了大半天,最后热情被消磨殆尽?或者想象一下,线上系统突然需要紧急调试消息队列问题,而你本地连个测试环境都没有,只能干瞪眼?------别让环境搭建成为你技术成长的绊脚石。好消息是,借助现代工具链,我们可以在5分钟内完成RabbitMQ开发环境的部署、客户端库安装和控制台验证,让你快速进入核心学习阶段。
"5分钟完成环境搭建,是高效学习的第一保障。"
本章将手把手带你完成本地开发环境的搭建,涵盖Docker一键部署RabbitMQ服务、安装主流语言客户端库(Python/Node.js)、以及通过Web控制台验证服务状态三大关键步骤。这不仅为你后续"生产者-消费者"实战打下坚实基础,更是一种可复用的工程化思维------学会用标准化方式快速构建实验沙箱,是每个开发者的核心竞争力。
使用Docker一键部署RabbitMQ服务
在传统部署模式中,安装RabbitMQ往往意味着配置Erlang环境、处理依赖冲突、手动启动守护进程......繁琐且容易出错。如今,Docker容器化技术彻底改变了这一局面。只需一条命令,即可获得一个隔离、轻量、即开即用的消息队列服务实例。
首先确保你的机器已安装Docker(推荐Docker Desktop)。接着,在终端执行以下命令:
python
import subprocess
import time
import sys
def start_rabbitmq_container(container_name="rabbitmq-server", port_mapping="5672:5672", management_port="15672:15672"):
"""
使用 Docker 启动 RabbitMQ 容器,并映射必要端口,启用管理插件。
Args:
container_name (str): 容器名称,默认为 "rabbitmq-server"
port_mapping (str): AMQP 协议端口映射,默认 "5672:5672"
management_port (str): 管理界面端口映射,默认 "15672:15672"
Returns:
bool: 启动成功返回 True,失败返回 False
"""
# Step 1: 构建完整的 docker run 命令
docker_command = [
"docker", "run", "-d",
"--name", container_name,
"-p", port_mapping,
"-p", management_port,
"-e", "RABBITMQ_DEFAULT_USER=admin",
"-e", "RABBITMQ_DEFAULT_PASS=secret",
"--hostname", "my-rabbit",
"rabbitmq:3-management" # 使用带管理插件的官方镜像
]
print(f"[INFO] 正在执行命令: {' '.join(docker_command)}")
# Step 2: 执行 Docker 命令启动容器
try:
result = subprocess.run(docker_command, check=True, capture_output=True, text=True)
container_id = result.stdout.strip()
print(f"[SUCCESS] RabbitMQ 容器启动成功,容器ID: {container_id[:12]}...")
except subprocess.CalledProcessError as e:
print(f"[ERROR] 启动失败: {e.stderr}")
return False
except FileNotFoundError:
print("[ERROR] 未找到 Docker 命令,请确认 Docker 已安装并加入 PATH。")
return False
# Step 3: 等待容器初始化完成(约需10-15秒)
print("[INFO] 等待 RabbitMQ 初始化(约15秒)...")
time.sleep(15)
# Step 4: 验证容器是否健康运行
inspect_command = ["docker", "inspect", "-f", "{{.State.Running}}", container_name]
try:
health_check = subprocess.run(inspect_command, check=True, capture_output=True, text=True)
is_running = health_check.stdout.strip() == "true"
if is_running:
print(f"[SUCCESS] 容器 '{container_name}' 正在运行!")
print(f"[INFO] 访问管理界面: http://localhost:{management_port.split(':')[0]}")
print(f"[INFO] 默认用户: admin / 密码: secret")
return True
else:
print(f"[WARNING] 容器 '{container_name}' 未正常运行。")
return False
except Exception as e:
print(f"[ERROR] 健康检查失败: {e}")
return False
# 主程序入口
def main():
"""
主函数:调用启动函数并处理退出状态
"""
print("=== RabbitMQ Docker 启动工具 ===")
# Step 1: 调用启动函数
success = start_rabbitmq_container()
# Step 2: 根据结果设置退出码
if success:
print("✅ RabbitMQ 已成功启动并运行!")
sys.exit(0)
else:
print("❌ RabbitMQ 启动失败,请检查日志或Docker状态。")
sys.exit(1)
# 执行主程序
if __name__ == "__main__":
main()OUTPUT
[INFO] 正在执行命令: docker run -d --name rabbitmq-server -p 5672:5672 -p 15672:15672 -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=secret --hostname my-rabbit rabbitmq:3-management
[SUCCESS] RabbitMQ 容器启动成功,容器ID: a1b2c3d4e5f6...
[INFO] 等待 RabbitMQ 初始化(约15秒)...
[SUCCESS] 容器 'rabbitmq-server' 正在运行!
[INFO] 访问管理界面: http://localhost:15672
[INFO] 默认用户: admin / 密码: secret
✅ RabbitMQ 已成功启动并运行!该代码通过 Python 的 subprocess 模块封装了 Docker 命令,用于一键启动带有管理界面的 RabbitMQ 容器。它不仅执行了基础的 docker run 命令,还设置了默认用户名密码、主机名,并映射了 AMQP 和管理端口。代码包含错误处理机制,能捕获 Docker 未安装或命令执行失败的情况,并在启动后自动进行健康检查,确保容器真正处于运行状态。
关键设计包括:使用结构化参数提高可配置性、添加延时等待服务初始化、通过 docker inspect 验证运行状态,以及清晰的日志输出帮助用户快速定位问题。最终用户可通过浏览器访问 localhost:15672 使用默认凭据登录管理界面,极大简化了环境搭建流程,符合章节中'环境准备'的教学目标。
该命令会从Docker Hub拉取官方镜像 rabbitmq:3-management(带管理插件版本),映射5672端口(AMQP协议)和15672端口(Web管理界面),并以后台模式运行。整个过程通常在1分钟内完成,无需任何额外配置。
⚠️ 注意: 如果你已有其他服务占用上述端口,请使用
-p <自定义端口>:5672参数调整映射关系,例如-p 8080:15672将管理界面映射到本地8080端口。
启动成功后,你可以通过 docker ps 查看容器运行状态,确认 rabbitmq:3-management 容器处于"UP"状态即表示服务已就绪。
安装Python或Node.js客户端库
RabbitMQ支持多种编程语言接入,其中Python的 pika 和Node.js的 amqplib 是社区最活跃、文档最完善的两个客户端库。根据你的技术栈选择其一即可。
如果你使用 Python:
bash
pip install pika如果你使用 Node.js:
bash
npm install amqplib这两个库都封装了AMQP协议细节,提供简洁API用于连接、声明队列、发布/消费消息等操作。它们的设计哲学一致:连接 → 通道 → 操作 → 关闭,这种结构化的调用流程能有效避免资源泄漏。
python
import pika
import logging
# Step 1: 配置日志系统,便于调试和追踪连接状态
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def create_rabbitmq_connection(host='localhost', port=5672, username='guest', password='guest'):
"""
创建并返回一个 RabbitMQ 连接对象
Args:
host (str): RabbitMQ 服务器主机地址,默认为 'localhost'
port (int): RabbitMQ 服务端口,默认为 5672
username (str): 登录用户名,默认为 'guest'
password (str): 登录密码,默认为 'guest'
Returns:
pika.BlockingConnection: 成功建立的连接对象,可用于后续通道操作
"""
# Step 2: 构建凭据对象,用于身份验证
credentials = pika.PlainCredentials(username, password)
# Step 3: 构建连接参数对象,包含主机、端口和认证信息
connection_params = pika.ConnectionParameters(
host=host,
port=port,
credentials=credentials,
heartbeat=600, # 设置心跳间隔为600秒,防止连接因空闲断开
blocked_connection_timeout=300 # 设置阻塞超时时间,避免无限等待
)
# Step 4: 尝试建立连接,并处理可能的异常
try:
connection = pika.BlockingConnection(connection_params)
logger.info(f"✅ 成功连接到 RabbitMQ 服务器 {host}:{port}")
return connection
except pika.exceptions.AMQPConnectionError as e:
logger.error(f"❌ 连接失败: {e}")
raise
except Exception as e:
logger.error(f"❌ 未知错误: {e}")
raise
def main():
"""
主函数:演示如何使用 create_rabbitmq_connection 函数建立连接并关闭
"""
# Step 5: 调用连接函数,创建 RabbitMQ 连接
connection = create_rabbitmq_connection()
# Step 6: 检查连接是否打开,确保连接有效
if connection.is_open:
logger.info("🔌 连接状态正常,准备进行后续操作...")
else:
logger.warning("⚠️ 连接未成功打开,请检查配置或网络")
return
# Step 7: 关闭连接(实际项目中通常在程序退出或资源清理阶段执行)
connection.close()
logger.info("🔌 连接已安全关闭")
if __name__ == "__main__":
# Step 8: 执行主函数,启动连接示例
main()OUTPUT
INFO:__main__:✅ 成功连接到 RabbitMQ 服务器 localhost:5672
INFO:__main__:🔌 连接状态正常,准备进行后续操作...
INFO:__main__:🔌 连接已安全关闭该代码示例展示了如何使用 Python 的 Pika 库与 RabbitMQ 建立连接。首先通过配置日志系统提升可调试性,然后封装了一个 create_rabbitmq_connection 函数,支持自定义主机、端口和认证参数。函数内部构建了连接参数对象并设置了心跳和超时机制以增强稳定性,同时通过 try-except 结构捕获连接异常。主函数调用该连接方法后验证连接状态,并最终安全关闭连接。
关键点包括:使用 BlockingConnection 实现同步阻塞式连接、合理设置心跳与超时避免连接中断、结构化异常处理保障程序健壮性。此示例适合作为学习 RabbitMQ 客户端开发的基础模板,便于后续扩展消息发布/订阅功能。
以上代码展示了如何建立到本地RabbitMQ的连接,并打开一个通信通道(Channel)。注意,默认用户名密码均为 guest ------ 这正是Docker镜像预设的凭据。
访问管理控制台验证服务状态
部署完成不代表万事大吉,我们需要可视化手段验证服务是否真正可用。RabbitMQ自带的Web管理控制台就是最佳工具。
打开浏览器,访问 http://localhost:15672,使用用户名 guest、密码 guest 登录。你将看到如下功能模块:
- Overview: 集群概览、消息吞吐统计
- Connections / Channels: 实时查看客户端连接数
- Queues: 创建、删除、清空队列,查看积压消息
- Exchanges: 管理交换机及其绑定关系
消息队列核心流程:生产者发送消息至队列,消费者异步拉取并处理,实现系统解耦
这张架构图清晰展示了消息流转路径:生产者发送消息至Exchange,Exchange根据Routing Key和Binding规则分发到对应Queue,最终由消费者拉取消费。在控制台中,你可以手动创建一个测试队列,然后通过"Publish message"功能发送一条文本消息,观察其是否成功入队------这是最直观的服务健康检查。
至此,你的本地RabbitMQ开发环境已全面就绪。整个过程无需编译、无复杂配置、无版本冲突,真正实现"开箱即用"。更重要的是,这套方法论可迁移至Redis、Kafka、PostgreSQL等其他中间件------掌握Docker+官方镜像+客户端库的组合拳,你就能在任何新技术面前快速建立实验场。
环境是地基,代码是高楼。地基打得快且稳,才能把精力聚焦在真正的业务逻辑与架构设计上。
下一章《动手实战:生产者与消费者代码实现》中,我们将基于当前环境,编写第一个消息收发程序,亲手体验异步解耦的魅力。准备好你的IDE,精彩即将开始!
动手实战:生产者与消费者代码实现
你是否遇到过这样的场景------用户下单后系统卡顿数秒,后台服务因瞬时流量打满CPU,甚至直接崩溃?想象一下,线上促销活动开启的瞬间,成千上万请求如潮水般涌来,你的同步架构毫无招架之力。这时候,消息队列就像一个"缓冲水库",把洪峰削平、把压力延后,让系统从容不迫地逐个处理。而这一切魔法的核心,正是我们本章要亲手实现的"消息收发编程模型"。
一行代码发送,一行代码接收------这就是消息队列的优雅之处。
在上一章中,我们已经搭好了本地RabbitMQ环境和开发工具链,现在是时候让代码动起来了!本章将带你从零构建一个完整的生产者-消费者闭环:生产者负责构造并投递任务,消费者负责监听并执行,中间通过Broker可靠传递。我们将特别关注消息持久化 与ACK确认机制------这是保障业务不丢消息、不错消息的关键防线。
编写生产者:连接MQ、声明队列、发送JSON消息
生产者的职责非常明确:把业务数据封装成消息,安全送达指定队列。整个过程分为三步:
- 建立连接与通道:使用AMQP协议连接到RabbitMQ服务器,并打开一个通信通道;
- 声明队列(Queue):确保目标队列存在,若不存在则自动创建,同时可设置持久化等属性;
- 构造并发送消息 :通常以JSON格式序列化业务对象,通过
basic_publish方法投递。
python
# section_3_code_1 - 生产者连接与发送示例(Python + pika)
import pika
import json
# 1. 建立连接与通道
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost')
)
channel = connection.channel()
# 2. 声明持久化队列(durable=True)
channel.queue_declare(queue='order_queue', durable=True)
# 3. 构造业务消息(如订单信息)
order_data = {
"order_id": "ORD20240520001",
"user_id": 10086,
"amount": 99.9,
"items": ["商品A", "商品B"]
}
# 4. 发送消息:delivery_mode=2 表示消息持久化
channel.basic_publish(
exchange='',
routing_key='order_queue',
body=json.dumps(order_data),
properties=pika.BasicProperties(
delivery_mode=2, # 持久化消息:写入磁盘
content_type='application/json'
)
)
print("✅ 订单消息已发送:", order_data["order_id"])
connection.close()这段代码看似简单,但暗藏玄机:
durable=True表示队列将在Broker重启后依然存在;delivery_mode=2标记消息为"持久化",即使Broker宕机也不会丢失;- 使用JSON是为了跨语言兼容性,也便于后续日志追踪和人工排查。
⚠️ 注意: 生产者不应假设队列已存在,必须主动声明------这是分布式系统的"幂等"思维体现。
💡 原理补充:消息持久化如何工作?
当设置 delivery_mode=2,RabbitMQ 会将消息写入磁盘上的持久化日志文件(位于 /var/lib/rabbitmq/mnesia/.../.vhost/queues/),并在内存中保留一份副本用于快速消费。只有当消息被成功落盘后,Broker才会向生产者返回"发送成功"响应。如果此时Broker崩溃,重启后会从磁盘日志恢复未消费的消息,从而保证"至少一次交付"。
编写消费者:监听队列、处理消息、手动ACK确认
如果说生产者是"投递员",那消费者就是"收件人+处理员"。它需要持续监听队列,取出消息、执行业务逻辑,并在成功后向Broker发送确认(ACK),否则消息会被重新入队或进入死信队列。
关键步骤包括:
- 建立消费通道:同样需先连接MQ,再绑定到目标队列;
- 注册回调函数:每当有新消息到达,触发该函数进行处理;
- 手动ACK机制 :只有在业务逻辑完全执行成功 后,才调用
basic_ack确认消费。
python
# section_3_code_2 - 消费者监听与ACK示例(Python + pika)
import pika
import json
import time
def process_order(body):
"""模拟订单处理业务逻辑"""
order = json.loads(body)
print(f"📦 正在处理订单 {order['order_id']} ...")
# 模拟耗时操作(如调用支付、库存扣减)
time.sleep(2)
# 模拟业务异常(例如库存不足)
if order.get("user_id") == 9999:
raise Exception("❌ 库存不足,订单处理失败")
print(f"✅ 订单 {order['order_id']} 处理成功")
return True
def callback(ch, method, properties, body):
"""消息到达时的回调函数"""
try:
# 执行核心业务逻辑
success = process_order(body)
if success:
# ✅ 业务成功 → 手动ACK确认
ch.basic_ack(delivery_tag=method.delivery_tag)
print("📩 消息已确认消费")
except Exception as e:
print(f"⚠️ 处理失败: {e}")
# ❌ 业务失败 → 不ACK,消息重回队列(或进入DLQ)
ch.basic_nack(delivery_tag=method.delivery_tag, requeue=True)
# 建立连接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 声明队列(确保与生产者一致)
channel.queue_declare(queue='order_queue', durable=True)
# 关闭自动ACK,启用手动确认
channel.basic_consume(
queue='order_queue',
on_message_callback=callback,
auto_ack=False # 关键:关闭自动确认
)
print(' [*] 等待订单消息中。按 CTRL+C 退出')
channel.start_consuming()为什么强调"手动ACK"?因为自动ACK模式下,消息一旦被取出即视为"已消费",哪怕后续处理失败也不会重试------这在金融、订单等场景是灾难性的。手动ACK赋予你对消息生命周期的完全控制权。
消息队列核心流程:生产者发送消息至队列,消费者异步拉取并处理,实现系统解耦
如上图所示,消息从生产者发出,经由Broker暂存,再到消费者拉取并最终ACK,形成一个闭环。任何环节失败,系统都有能力回滚或重试,从而保障"至少一次交付"的语义。
💡 原理补充:ACK在网络中断时如何保证一致性?
RabbitMQ 的 ACK 是基于 TCP 连接的。如果消费者在处理过程中网络断开,Broker 会检测到通道关闭,并将未ACK的消息标记为"未确认",随后根据队列配置决定是否重新入队。消费者重启后,只要重新订阅同一队列,即可继续消费这些"悬而未决"的消息。这种设计确保了即使发生网络分区,也不会丢失消息语义。
演示消息持久化与重试机制配置
光有ACK还不够。现实中,消费者可能因网络抖动、资源不足或程序异常导致处理失败。这时我们需要配置重试策略 和死信队列(DLQ),避免消息无限循环或永久丢失。
典型做法如下:
- 设置
basic_nack(requeue=True):当处理失败时,将消息重新放回原队列; - 配置重试次数上限(如3次),超过后转入死信队列供人工介入;
- 死信队列本身也是普通队列,只是专门用于存放"问题消息"。
python
# section_3_code_3 - 配置重试与死信队列示例(Python + pika)
# 步骤1:声明死信交换机和死信队列
channel.exchange_declare(exchange='dlx.exchange', exchange_type='direct')
channel.queue_declare(queue='order_dlx_queue', durable=True)
channel.queue_bind(exchange='dlx.exchange', queue='order_dlx_queue', routing_key='order.dlx')
# 步骤2:声明主队列,绑定死信策略
args = {
"x-dead-letter-exchange": "dlx.exchange",
"x-dead-letter-routing-key": "order.dlx",
"x-message-ttl": 60000, # 消息最大存活时间 60s
"x-max-length": 1000 # 队列最大长度
}
channel.queue_declare(queue='order_queue', durable=True, arguments=args)
# 步骤3:在消费者回调中实现重试计数(通过消息头记录)
def callback_with_retry(ch, method, properties, body):
headers = properties.headers or {}
retry_count = headers.get('x-retry-count', 0)
try:
success = process_order(body)
if success:
ch.basic_ack(delivery_tag=method.delivery_tag)
except Exception as e:
retry_count += 1
if retry_count >= 3:
print(f"💀 重试{retry_count}次仍失败,转入死信队列")
# 转发到死信交换机(自动路由到DLQ)
ch.basic_publish(
exchange='dlx.exchange',
routing_key='order.dlx',
body=body,
properties=pika.BasicProperties(headers={'original_retry': retry_count})
)
ch.basic_ack(delivery_tag=method.delivery_tag) # 从主队列移除
else:
print(f"🔁 第{retry_count}次重试...")
# 重新入队,并增加重试计数头
new_headers = headers.copy()
new_headers['x-retry-count'] = retry_count
ch.basic_publish(
exchange='',
routing_key=method.routing_key,
body=body,
properties=pika.BasicProperties(
headers=new_headers,
delivery_mode=2
)
)
ch.basic_ack(delivery_tag=method.delivery_tag)配合RabbitMQ的Policy功能,你还可以设置TTL(消息存活时间)、最大重试间隔等精细化策略。例如:
bash
# 通过命令行设置策略:所有order.*开头的队列启用死信
rabbitmqctl set_policy DLX "order\..*" '{"dead-letter-exchange":"dlx.exchange"}' --apply-to queues
# 或通过Web管理界面操作:
# 1. 登录 http://localhost:15672
# 2. 进入 Admin > Policies > Add / update a policy
# 3. Name: "Order-DLX-Policy"
# Pattern: ^order\.
# Apply to: Queues
# Definition: {"dead-letter-exchange": "dlx.exchange"}📊 如何监控死信队列?
- 在 RabbitMQ Web 控制台(http://localhost:15672)中,点击 "Queues" 标签页,查看
order_dlx_queue的消息数量。 - 可编写独立的"死信消费者"监听该队列,记录日志或触发告警:
python
channel.basic_consume(queue='order_dlx_queue', on_message_callback=log_dlq_message, auto_ack=True)- 使用 Prometheus + Grafana 监控队列深度变化,设置阈值告警。
这套组合拳下来,你的消息系统就具备了"故障自愈 + 人工兜底"的双重保障。
消息队列不是银弹,但它是最优雅的异步解耦工具。掌握生产者与消费者的编写范式,等于掌握了现代分布式系统的"任督二脉"。
在下一章《效果验证:测试异步通信与削峰能力》中,我们将模拟高并发场景,实测这套架构如何扛住流量洪峰,并对比同步调用的性能差异------敬请期待!
效果验证:测试异步通信与削峰能力
你是否遇到过系统在流量高峰时突然卡顿、接口超时甚至服务崩溃?想象一下,线上促销活动刚一开始,用户瞬间涌入,订单系统像被洪水冲击的堤坝------同步调用链条层层阻塞,数据库连接池耗尽,最终整个服务雪崩。这不是危言耸听,而是无数团队踩过的坑。好消息是,消息队列提供的"削峰填谷"能力,不是纸上谈兵的架构图,而是你可以亲手搭建、真实验证的系统韧性。
上一章我们完成了生产者与消费者的代码实现,现在,是时候让它们真正跑起来,在实战中检验这套异步通信机制能否扛住压力、缓冲洪峰、保障数据不丢。本章将通过三个关键实验,带你一步步验证消息队列的核心价值:功能正确性、高并发缓冲能力、以及故障恢复可靠性。
实验一:基础功能验证 ------ 100条消息逐条消费
首先,我们从最简单的场景开始:启动消费者进程后,运行生产者快速发送100条消息。观察控制台输出,你会发现消费者并非"瞬间处理完所有消息",而是以稳定节奏逐条拉取、逐条处理。这正是异步通信的本质------生产者发送即返回,无需等待消费者响应;消费者按自身处理能力消费,互不阻塞。
⚠️ 注意: 如果你看到消费者一次性处理了全部100条,请检查是否误用了批量消费或预取(prefetch)设置过高。理想的异步模型应体现"解耦"和"背压"。
这个实验看似简单,实则验证了两个核心机制:
- 消息持久化:消息已成功写入队列,而非内存中一闪而过。
- 消费速率可控:消费者能按设定速率(如每秒5条)稳定处理,避免资源过载。
python
import time
import threading
from queue import Queue
# 模拟消息队列(生产者-消费者模型中的缓冲区)
message_queue = Queue()
def produce_messages(total_messages=100, delay_between_messages=0.01):
"""
生产者函数:快速发送指定数量的消息到队列中
Args:
total_messages (int): 要发送的消息总数,默认100条
delay_between_messages (float): 每条消息发送间隔(秒),默认0.01秒用于模拟真实场景压力
Returns:
None: 无返回值,仅向全局队列推送消息
"""
# Step 1: 遍历生成指定数量的消息
for i in range(1, total_messages + 1):
# Step 2: 构造消息内容(含时间戳和序号)
message = f"Message-{i} @ {time.strftime('%H:%M:%S')}"
# Step 3: 将消息放入共享队列(线程安全)
message_queue.put(message)
# Step 4: 打印发送日志(模拟生产者行为)
print(f"[Producer] Sent: {message}")
# Step 5: 短暂延迟,控制发送速率(避免瞬间压垮系统)
time.sleep(delay_between_messages)
# Step 6: 发送结束标记(可选,用于通知消费者停止)
message_queue.put("END_SIGNAL")
print(f"[Producer] Finished sending {total_messages} messages.")
def consume_messages():
"""
消费者函数:从队列中取出并处理消息(用于验证异步通信效果)
Returns:
None: 无返回值,仅消费队列中的消息并打印
"""
while True:
# Step 1: 从队列阻塞获取消息(线程安全)
message = message_queue.get()
# Step 2: 检查是否为结束信号
if message == "END_SIGNAL":
print("[Consumer] Received END signal. Stopping consumer.")
break
# Step 3: 模拟消息处理延迟(例如写入数据库、调用API等)
time.sleep(0.05) # 消费比生产慢,体现削峰能力
# Step 4: 打印消费日志
print(f"[Consumer] Processed: {message}")
# Step 5: 标记任务完成(Queue要求)
message_queue.task_done()
if __name__ == "__main__":
# Step 1: 启动消费者线程(异步处理消息)
consumer_thread = threading.Thread(target=consume_messages, daemon=True)
consumer_thread.start()
# Step 2: 启动生产者发送100条消息(主程序执行)
print("=== Starting Producer to send 100 messages rapidly ===")
produce_messages(total_messages=100, delay_between_messages=0.01)
# Step 3: 等待队列中所有消息被消费完毕
message_queue.join()
# Step 4: 输出完成信息
print("=== All messages have been processed successfully ===")OUTPUT
[Producer] Sent: Message-1 @ 14:23:05
[Consumer] Processed: Message-1 @ 14:23:05
[Producer] Sent: Message-2 @ 14:23:05
[Producer] Sent: Message-3 @ 14:23:05
[Consumer] Processed: Message-2 @ 14:23:05
[Producer] Sent: Message-4 @ 14:23:05
...
[Producer] Sent: Message-100 @ 14:23:06
[Producer] Finished sending 100 messages.
[Consumer] Processed: Message-99 @ 14:23:11
[Consumer] Processed: Message-100 @ 14:23:11
[Consumer] Received END signal. Stopping consumer.
=== All messages have been processed successfully ===该脚本实现了生产者-消费者模型,用于验证异步通信与削峰填谷的能力。生产者以较高速率(每0.01秒一条)连续发送100条带时间戳的消息,而消费者则以较慢速度(每0.05秒一条)处理消息,从而在队列中形成积压,模拟高并发场景下的缓冲效果。通过使用线程安全的Queue和多线程机制,确保了消息传递的可靠性。
关键设计包括:生产者发送结束后放入'END_SIGNAL'通知消费者终止;消费者在处理每条消息后调用task_done()配合join()实现主线程等待;注释密度高且步骤清晰,便于教学或调试。输出结果展示了消息的异步处理过程,直观体现了系统在面对突发流量时如何平滑消费、避免崩溃。
python
# 示例:快速发送100条测试消息
for i in range(100):
producer.send(f"order_{i}", {"user_id": 1000+i, "amount": 99.9})
time.sleep(0.01) # 模拟快速发送实验二:压力测试 ------ 1秒内灌入1000条消息,看队列如何"削峰"
接下来进入重头戏:模拟突发流量。我们将生产者脚本调整为在1秒内密集发送1000条消息(约每毫秒1条),同时监控消费者处理速度(假设其最大处理能力为每秒100条)。此时,你会观察到:
- 生产者几乎瞬间完成发送(得益于异步非阻塞)
- 消费者依然保持每秒100条的稳定处理速度
- 队列长度(Queue Length)先飙升至900+,然后缓慢下降
消息队列核心流程:生产者发送消息至队列,消费者异步拉取并处理,实现系统解耦
这张图清晰展示了两种架构的差异:
- 同步调用:延迟随并发数指数级增长,1000并发下平均延迟可能超过30秒。
- 消息队列:生产者延迟始终<100ms,消费者延迟稳定在10ms左右,峰值被完美"削平"。
这就是"削峰"的本质------把瞬时不可承受的压力,转化为可平滑消化的"时间差"。系统不再因突发流量崩溃,而是优雅降级、持续服务。
实验三:故障演练 ------ 强制停机再重启,验证消息不丢失
最后,我们模拟最残酷的生产环境场景:在消费者正在处理消息时,强制 kill -9 杀死进程,等待10秒后重新启动。此时,你应该看到:
- 重启后的消费者自动从上次断点继续消费(前提是开启ACK确认机制)
- 所有未确认的消息重新投递,无一遗漏
- 系统整体状态一致,没有重复消费或数据丢失
⚠️ 注意: 此实验依赖消息队列的"持久化 + ACK机制"。若使用内存队列或自动ACK,消息可能丢失。务必确认你的Broker配置了
durable=True和auto_ack=False。
这一实验验证了系统的容错性 和数据可靠性。在真实世界中,服务器重启、网络抖动、进程崩溃是常态。消息队列通过持久化存储和消费确认机制,确保业务数据"至少送达一次",这是构建高可用系统的基石。
削峰填谷不是理论,是你可以亲手验证的系统韧性。
通过这三个层层递进的实验,我们不仅验证了消息队列的功能正确性,更亲眼见证了它在高并发和故障场景下的强大表现。异步通信不是魔法,而是通过解耦、缓冲、重试等机制构建的工程化解决方案。当你下次面对老板"系统能不能扛住双十一流量?"的灵魂拷问时,你可以自信地回答:"不用猜,我已经亲手测过了。"
至此,我们的消息队列实战之旅圆满结束。从概念理解到代码实现,再到效果验证,你已掌握构建弹性系统的钥匙。记住,真正的架构能力,不在画图板上,而在压测报告里。
总结
- 消息队列通过异步通信实现系统解耦与弹性伸缩
- RabbitMQ提供开箱即用的可靠消息传递能力
- 生产者/消费者模式易于实现且具备天然扩展性
延伸阅读
尝试集成死信队列、延时消息,或迁移到Kafka/RocketMQ进行横向对比