什么是死信队列(Dead Letter Queue)?
文章目录
- [什么是死信队列(Dead Letter Queue)?](#什么是死信队列(Dead Letter Queue)?)
-
- 一、什么是死信
- 二、死信队列的工作原理
-
- [2.1 死信的产生条件](#2.1 死信的产生条件)
- [2.2 死信消息的流转过程](#2.2 死信消息的流转过程)
- 三、如何配置死信队列
-
- [3.1 基本步骤](#3.1 基本步骤)
- [3.2 示例(使用 RabbitMQ Java 客户端)](#3.2 示例(使用 RabbitMQ Java 客户端))
- [3.3 死信消息的路由](#3.3 死信消息的路由)
- 四、死信队列的应用场景
- 五、死信队列的注意事项
- 六、总结
死信队列(Dead Letter Queue,DLQ)是消息队列(Message Queue)系统中的一种特殊队列,用于存储那些无法被正常消费的消息。这些消息被称为"死信"(Dead Letter)。死信队列的主要作用是提供一个"隔离区",让开发人员或运维人员可以分析、排查、重新处理或归档这些异常消息,从而保证主业务流程的稳定性和可靠性。
下面我们从多个方面详细介绍死信队列。
一、什么是死信
在消息队列中,消息通常按照正常流程从生产者发送到交换机,然后路由到队列,最后被消费者消费。但在某些情况下,消息可能无法被正常处理,例如:
- 消费者处理失败且设置了重试后仍然失败;
- 消息过期(设置了 TTL 且超时);
- 队列达到最大长度,无法再存储消息;
- 消费者拒绝消息且不重新入队(basic.reject 或 basic.nack 且 requeue=false)。
这些无法被正常消费的消息如果被直接丢弃,可能导致数据丢失或业务异常。因此,消息队列提供了死信机制,将这些消息重新发布到另一个交换机(即死信交换机),再由该交换机路由到一个或多个死信队列中,以便后续处理。
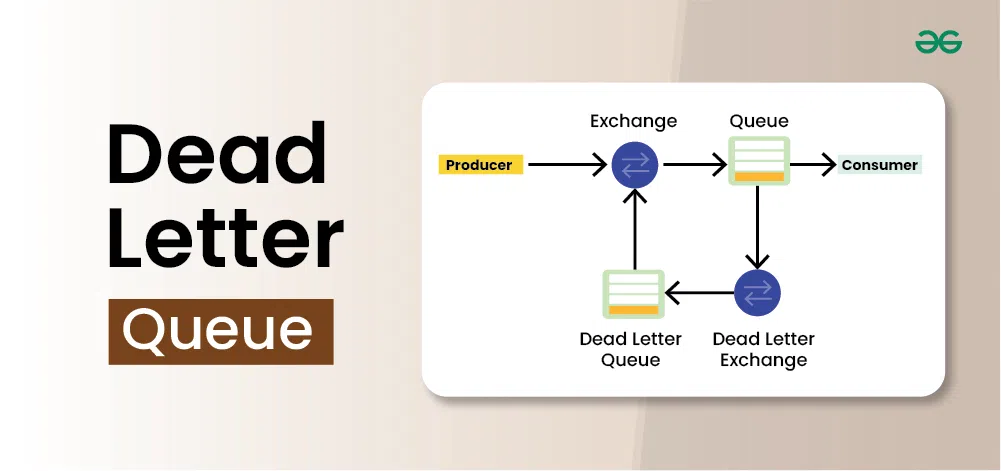
二、死信队列的工作原理
死信队列的核心是死信交换机(Dead Letter Exchange,DLX)。当一个队列被声明时,可以通过设置参数指定该队列的死信交换机。当队列中的消息变成死信时,消息会被重新发布到指定的死信交换机,然后根据死信交换机的路由规则将消息路由到绑定的死信队列中。
2.1 死信的产生条件
消息在以下任一情况下会变成死信:
-
消息被消费者拒绝且不重新入队
消费者使用
basic.reject或basic.nack方法拒绝消息,并且requeue参数设置为false。此时消息不会重新放回原队列,而是成为死信。 -
消息过期
如果消息设置了存活时间(Time To Live,TTL),在队列中等待超过 TTL 后仍未消费,消息会变成死信。TTL 可以在发送消息时设置,也可以在队列级别设置。
-
队列达到最大长度
当队列中的消息数量超过设定的最大长度(
x-max-length)或占用空间超过设定的最大容量(x-max-length-bytes)时,最早的消息可能会被丢弃或变成死信(取决于队列的溢出策略x-overflow配置,默认是drop-head丢弃头部,但如果设置了死信交换机,则会被转发到 DLX)。 -
消息被死信队列再次拒绝或过期
在死信队列中,消息同样可能再次成为死信,形成死信链,但需要避免循环。
2.2 死信消息的流转过程
- 正常流程:生产者 → 交换机(Exchange)→ 绑定 → 队列(Queue)→ 消费者。
- 死信流程 :
- 队列 A 设置了死信交换机 DLX。
- 当队列 A 中的一条消息变成死信时,它会被自动重新发布到 DLX。
- DLX 根据其绑定规则(通常使用消息原来的路由键,或由死信信息指定)将消息路由到死信队列 B。
- 消费者可以监听死信队列 B,对这些死信进行特殊处理(如记录日志、告警、重试、人工介入等)。
注意:死信消息被重新发布到死信交换机时,会保留原有的消息内容和大部分属性(如 headers),但会增加一些与死信相关的系统属性,例如:
x-first-death-reason:第一次成为死信的原因(如 rejected、expired、maxlen)。x-death:记录消息的死信历史,包括被死信的队列、原因、时间等。
三、如何配置死信队列
以 RabbitMQ 为例,配置死信队列需要在声明队列时通过参数指定死信交换机。
3.1 基本步骤
-
创建死信交换机(DLX)
可以是任何类型的交换机(direct、topic、fanout 等),根据业务需要设计路由规则。
-
创建死信队列(DLQ)
与死信交换机绑定,用于接收死信消息。
-
创建业务队列,并为其设置死信交换机参数
在声明业务队列时,添加
x-dead-letter-exchange参数指定 DLX 的名称,还可以使用x-dead-letter-routing-key参数指定发送到 DLX 时使用的路由键(如果不设置,则使用原消息的路由键)。
3.2 示例(使用 RabbitMQ Java 客户端)
java
// 1. 声明死信交换机
channel.exchangeDeclare("dlx.exchange", "direct");
// 2. 声明死信队列并绑定到死信交换机
channel.queueDeclare("dlq.queue", true, false, false, null);
channel.queueBind("dlq.queue", "dlx.exchange", "dlx.routing.key");
// 3. 声明业务队列,并设置死信交换机参数
Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", "dlx.exchange");
args.put("x-dead-letter-routing-key", "dlx.routing.key"); // 可选,默认使用原routing key
// 还可以设置队列的其他属性,如消息TTL、最大长度等
args.put("x-message-ttl", 60000); // 消息存活时间60秒
args.put("x-max-length", 1000); // 队列最大消息数
channel.queueDeclare("business.queue", true, false, false, args);3.3 死信消息的路由
死信消息被重新发布到死信交换机时,其路由键由以下规则决定:
- 如果业务队列设置了
x-dead-letter-routing-key,则使用该值。 - 否则,使用原消息的
routing key(如果原消息是发送到交换机时指定的路由键)。
死信交换机根据这个路由键将消息路由到绑定的死信队列。如果死信交换机没有匹配的队列绑定,消息可能会被丢弃(取决于交换机的配置)。
四、死信队列的应用场景
死信队列在实际开发中有多种用途:
-
异常消息的隔离与处理
当消费者处理消息失败且无法重试时,可以将消息转入死信队列,避免阻塞主队列。后续可以开发专门的消费者对死信进行分析、重试或人工干预。
-
延迟队列的实现
利用消息的 TTL 和死信机制可以模拟延迟队列。例如,发送一条消息到普通队列,设置较长的 TTL(比如 10 分钟),该队列没有消费者,消息过期后进入死信队列,此时死信队列的消费者获取到消息就相当于延迟了 10 分钟执行。RabbitMQ 本身不支持延迟队列,但可以通过这种方式实现。
-
消息重试与错误追踪
结合重试机制,当消息处理失败几次后,可以将其发送到死信队列,同时记录失败原因,便于排查问题。
-
流量控制与降级
如果消息量过大导致队列积压,可以通过设置队列最大长度,使超出部分自动进入死信队列,防止内存溢出,同时保留数据以便后续处理。
-
数据归档与审计
将某些不再需要实时处理但需要保留的消息转入死信队列,再由归档程序定期存储到数据库或文件系统。
五、死信队列的注意事项
- 避免死信循环:如果死信队列本身又设置了死信交换机,并且消息再次成为死信,可能会形成无限循环。通常不建议死信队列再设置死信交换机,或者要设计好终止条件。
- 死信消息的属性 :死信消息会携带一些额外的系统属性(如
x-death),消费者可以利用这些信息了解死信原因和历史,便于决策。 - 性能影响:消息变成死信并重新投递会增加一次额外的路由开销,但在大多数场景下可以接受。
- 死信队列的监控:需要监控死信队列的消息堆积情况,如果堆积过多,说明系统可能存在异常,应及时处理。
- 死信消息的清理:死信队列中的消息也需要设置合理的过期时间或消费策略,避免无限堆积。
六、总结
死信队列是消息队列中一种重要的容错机制,它保证了异常消息不会被直接丢弃,而是转移到专门的队列中,为开发者提供了处理失败消息的机会。通过合理配置死信交换机、死信队列以及相关的参数,可以构建健壮的消息处理系统,实现延迟队列、错误重试、流量控制等功能。
掌握死信队列的原理和使用方法,对于设计和维护可靠的消息驱动架构至关重要。在实际应用中,应结合业务需求合理设置死信条件,并对死信队列进行监控和管理,确保系统的稳定运行。