Pandas 数据清洗详解
数据清洗概述
数据清洗是数据分析过程中至关重要的步骤,主要包括处理缺失值、异常值、重复数据、格式转换等。下面通过具体案例演示常见的数据清洗操作。
一、处理缺失值
Excel(data.xlsx)示例数据:
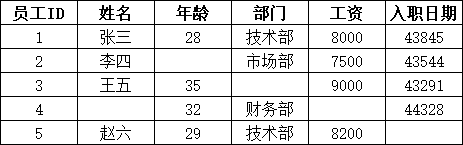
1、查看缺失值情况
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
print("缺失值统计:")
print(df_data.isnull().sum())输出:
python
缺失值统计:
员工ID 0
姓名 1
年龄 1
部门 1
工资 1
入职日期 1
dtype: int642、删除缺失值
2.1 删除所有包含缺失值的行
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df_data_all = df_data.dropna()
print("删除所有含缺失值的行:")
print(df_data_all)输出:
python
删除所有含缺失值的行:
员工ID 姓名 年龄 部门 工资 入职日期
0 1 张三 28.0 技术部 8000.0 43845.02.2 只删除"姓名"列缺失的行
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df1_drop_name = df_data.dropna(subset=['姓名'])
print("只删除'姓名'列缺失的行:")
print(df1_drop_name)输出:
python
只删除'姓名'列缺失的行:
员工ID 姓名 年龄 部门 工资 入职日期
0 1 张三 28.0 技术部 8000.0 43845.0
1 2 李四 NaN 市场部 7500.0 43544.0
2 3 王五 35.0 NaN 9000.0 43291.0
4 5 赵六 29.0 技术部 8200.0 NaN3、填充缺失值
3.1 用指定值填充
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df1_fill = df_data.copy()
# 方法一:直接赋值
df1_fill['部门'] = df1_fill['部门'].fillna('未知部门') # 缺失的部门使用"未知部门"填充
df1_fill['年龄'] = df1_fill['年龄'].fillna(df1_fill['年龄'].mean()) # 用平均值填充年龄
# 方法二:使用 loc 进行明确赋值
# df1_fill.loc[:, '部门'] = df1_fill['部门'].fillna('未知部门')
# df1_fill.loc[:, '年龄'] = df1_fill['年龄'].fillna(df1_fill['年龄'].mean())
# 方法三:批量更新多个列
# df1_fill.update(df1_fill['部门'].fillna('未知部门'))
# df1_fill.update(df1_fill['年龄'].fillna(df1_fill['年龄'].mean()))
# 方法四:一次填充多个列
#df1_fill = df1_fill.fillna({
# '部门': '未知部门',
# '年龄': df1_fill['年龄'].mean()
#})
print("填充后的数据:")
print(df1_fill)输出:
python
填充后的数据:
员工ID 姓名 年龄 部门 工资 入职日期
0 1 张三 28.0 技术部 8000.0 43845.0
1 2 李四 31.0 市场部 7500.0 43544.0
2 3 王五 35.0 未知部门 9000.0 43291.0
3 4 NaN 32.0 财务部 NaN 44328.0
4 5 赵六 29.0 技术部 8200.0 NaN3.2 向前或向后填充
向前填充(ffill) 是指用缺失值前面的最近一个非缺失值来填充当前缺失值。
向后填充(bfill) 是指用缺失值后面的最近一个非缺失值来填充当前缺失值。
例如,要填充"工资"列的缺失值,如果是向前填充,则填充"9000",向后填充则是"8200"。
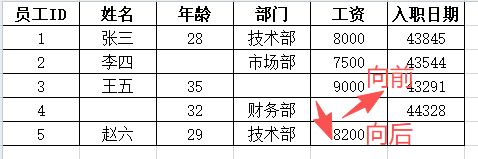
向前填充:
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df1_ffill = df_data.copy()
# 对工资列进行向前填充
df1_ffill['工资'] = df1_ffill['工资'].ffill() # 用前一个值填充
print("向前填充工资列:")
print(df1_ffill)输出:
python
向前填充工资列:
员工ID 姓名 年龄 部门 工资 入职日期
0 1 张三 28.0 技术部 8000.0 43845.0
1 2 李四 NaN 市场部 7500.0 43544.0
2 3 王五 35.0 NaN 9000.0 43291.0
3 4 NaN 32.0 财务部 9000.0 44328.0
4 5 赵六 29.0 技术部 8200.0 NaN向后填充:
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df1_bfill = df_data.copy()
# 对工资列进行向前填充
df1_bfill['工资'] = df1_bfill['工资'].bfill() # 用前一个值填充
print("向前填充工资列:")
print(df1_bfill)输出:
python
向前填充工资列:
员工ID 姓名 年龄 部门 工资 入职日期
0 1 张三 28.0 技术部 8000.0 43845.0
1 2 李四 NaN 市场部 7500.0 43544.0
2 3 王五 35.0 NaN 9000.0 43291.0
3 4 NaN 32.0 财务部 8200.0 44328.0
4 5 赵六 29.0 技术部 8200.0 NaN二、处理重复值
Excel(data.xlsx)示例数据:
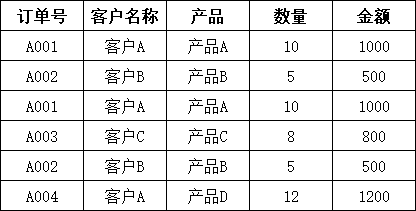
1、检查重复数据
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
print("重复行统计:", df_data.duplicated().sum())
print("重复行详情:")
print(df_data[df_data.duplicated()])输出:
python
重复行统计: 2
重复行详情:
订单号 客户名称 产品 数量 金额
2 A001 客户A 产品A 10 1000
4 A002 客户B 产品B 5 5002、删除完全重复的行
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df2 = df_data.copy()
df2_dedup = df2.drop_duplicates()
print("删除完全重复行后:")
print(df2_dedup)输出:
python
删除完全重复行后:
订单号 客户名称 产品 数量 金额
0 A001 客户A 产品A 10 1000
1 A002 客户B 产品B 5 500
3 A003 客户C 产品C 8 800
5 A004 客户A 产品D 12 12003、根据指定列删除重复行
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df2 = df_data.copy()
df2_dedup_order = df2.drop_duplicates(subset=['订单号'])
print("根据'订单号'删除重复行:")
print(df2_dedup_order)输出:
python
根据'订单号'删除重复行:
订单号 客户名称 产品 数量 金额
0 A001 客户A 产品A 10 1000
1 A002 客户B 产品B 5 500
3 A003 客户C 产品C 8 800
5 A004 客户A 产品D 12 12004、保留重复行中的第一条或最后一条
保留重复行中的最后一条
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df2 = df_data.copy()
df2_keep_last = df2.drop_duplicates(subset=['订单号'], keep='last')
# 保留'订单号'重复的第一条记录
# df2_keep_last = df2.drop_duplicates(subset=['订单号'], keep='first')
print("保留'订单号'重复的最后一条记录:")
print(df2_keep_last)输出:
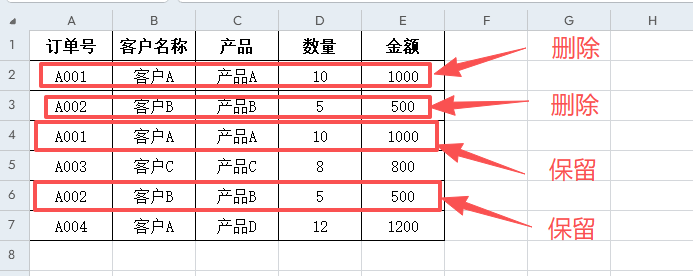
python
保留'订单号'重复的最后一条记录:
订单号 客户名称 产品 数量 金额
2 A001 客户A 产品A 10 1000
3 A003 客户C 产品C 8 800
4 A002 客户B 产品B 5 500
5 A004 客户A 产品D 12 1200三、数据类型转换
Excel(data.xlsx)示例数据:
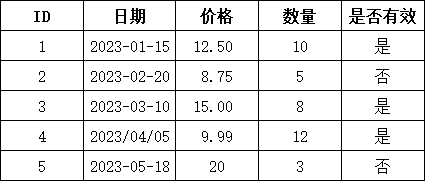
1、日期格式转换
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df3 = df_data.copy()
df3['日期'] = pd.to_datetime(df3['日期'], errors='coerce') # errors='coerce',将错误解析的转换为 NaT (Not a Time)
print("日期转换后:")
print(df3['日期'])输出:
python
日期转换后:
0 2023-01-15
1 2023-02-20
2 2023-03-10
3 2023-04-05
4 2023-05-18
Name: 日期, dtype: datetime64[ns]2、数值类型转换
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df3 = df_data.copy()
# 将 '价格' 和 '数量' 列的数据转换为数值类型(int64或float64)
df3['价格'] = pd.to_numeric(df3['价格'], errors='coerce')
df3['数量'] = pd.to_numeric(df3['数量'], errors='coerce')
print("数值转换后数据类型:")
print(df3.dtypes)输出:
python
数值转换后数据类型:
ID int64
日期 datetime64[ns]
价格 float64
数量 int64
是否有效 object
dtype: object3、布尔值转换
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df3 = df_data.copy()
df3['是否有效'] = df3['是否有效'].map({'是': True, '否': False})
print("布尔值转换后:")
print(df3)输出:
python
布尔值转换后:
ID 日期 价格 数量 是否有效
0 1 2023-01-15 12.50 10 True
1 2 2023-02-20 8.75 5 False
2 3 2023-03-10 15.00 8 True
3 4 2023-04-05 9.99 12 True
4 5 2023-05-18 20.00 3 False4、使用astype转换
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df3 = df_data.copy()
df3['ID'] = df3['ID'].astype('int32')
print("使用astype转换ID列类型:")
print(df3.dtypes)输出:
python
使用astype转换ID列类型:
ID int32
日期 datetime64[ns]
价格 float64
数量 int64
是否有效 object
dtype: object四、字符串处理
Excel(data.xlsx)示例数据:
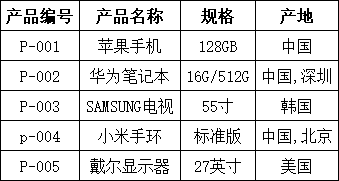
1、字符串大小写转换
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df4 = df_data.copy()
df4['产品编号'] = df4['产品编号'].str.upper()
df4['产品名称'] = df4['产品名称'].str.lower()
print("大小写转换后:")
print(df4[['产品编号', '产品名称']])输出:
python
大小写转换后:
产品编号 产品名称
0 P-001 苹果手机
1 P-002 华为笔记本
2 P-003 samsung电视
3 P-004 小米手环
4 P-005 戴尔显示器2、去除空格
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df4 = df_data.copy()
df4['规格'] = df4['规格'].str.strip()
print("去除空格后:")
print(df4['规格'])输出:
python
去除空格后:
0 128GB
1 16G/512G
2 55寸
3 标准版
4 27英寸
Name: 规格, dtype: object3、字符串替换
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df4 = df_data.copy()
df4['产品名称'] = df4['产品名称'].str.replace('手机', '智能手机')
print("字符串替换后:")
print(df4['产品名称'])输出:
python
字符串替换后:
0 苹果智能手机
1 华为笔记本
2 SAMSUNG电视
3 小米手环
4 戴尔显示器
Name: 产品名称, dtype: object4、字符串分割
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df4 = df_data.copy()
df4['产地_主要'] = df4['产地'].str.split(',').str[0]
print("字符串分割后:")
print(df4[['产地', '产地_主要']])输出:
python
字符串分割后:
产地 产地_主要
0 中国 中国
1 中国,深圳 中国
2 韩国 韩国
3 中国,北京 中国
4 美国 美国5、字符串提取
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df4 = df_data.copy()
df4['规格_数字'] = df4['规格'].str.extract(r'(\d+)')
print("提取数字后:")
print(df4[['规格', '规格_数字']])输出:
python
提取数字后:
规格 规格_数字
0 128GB 128
1 16G/512G 16
2 55寸 55
3 标准版 NaN
4 27英寸 276、字符串包含检查
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df4 = df_data.copy()
df4['是否国产'] = df4['产地'].str.contains('中国')
print("是否国产检查:")
print(df4[['产地', '是否国产']])输出:
python
是否国产检查:
产地 是否国产
0 中国 True
1 中国,深圳 True
2 韩国 False
3 中国,北京 True
4 美国 False五、处理异常值
Excel(data.xlsx)示例数据:
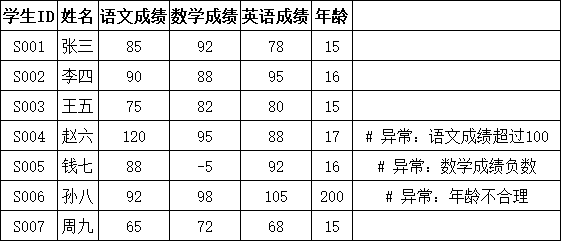
1、描述性统计
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df5 = df_data.copy()
print("描述性统计:")
print(df5.describe())输出:
python
描述性统计:
语文成绩 数学成绩 英语成绩 年龄
count 7.000000 7.000000 7.000000 7.000000
mean 87.857143 74.571429 86.571429 42.000000
std 17.082433 36.156406 12.272695 69.675438
min 65.000000 -5.000000 68.000000 15.000000
25% 80.000000 77.000000 79.000000 15.000000
50% 88.000000 88.000000 88.000000 16.000000
75% 91.000000 93.500000 93.500000 16.500000
max 120.000000 98.000000 105.000000 200.0000002、使用分位数识别异常值
IQR(Interquartile Range)是统计学中检测异常值的常用方法:
Q1(第一四分位数):数据的25%分位点
Q3(第三四分位数):数据的75%分位点
IQR(四分位距):Q3 - Q1,表示中间50%数据的范围
异常值边界计算
下限:Q1 - 1.5 × IQR
上限:Q3 + 1.5 × IQR
任何低于下限或高于上限的值通常被视为异常值。
python
import pandas as pd
# 读取数据
df_data = pd.read_excel('data.xlsx')
# 创建副本,避免修改原始数据
df5 = df_data.copy()
# 1. 计算Q1(第一四分位数)
Q1 = df5[['语文成绩', '数学成绩', '英语成绩']].quantile(0.25)
# 结果:每个科目25%分位点的值
# 2. 计算Q3(第三四分位数)
Q3 = df5[['语文成绩', '数学成绩', '英语成绩']].quantile(0.75)
# 结果:每个科目75%分位点的值
# 3. 计算IQR(四分位距)
IQR = Q3 - Q1
# 结果:每个科目中间50%数据的范围
# 4. 计算异常值边界
lower_bound = Q1 - 1.5 * IQR # 下边界
upper_bound = Q3 + 1.5 * IQR # 上边界
# 5. 打印结果
print("异常值边界:")
print("语文成绩:", (lower_bound['语文成绩'], upper_bound['语文成绩']))
print("数学成绩:", (lower_bound['数学成绩'], upper_bound['数学成绩']))
print("英语成绩:", (lower_bound['英语成绩'], upper_bound['英语成绩']))输出:
python
异常值边界:
语文成绩: (np.float64(63.5), np.float64(107.5))
数学成绩: (np.float64(52.25), np.float64(118.25))
英语成绩: (np.float64(57.25), np.float64(115.25))3、标记异常值
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df5 = df_data.copy()
Q1 = df5[['语文成绩', '数学成绩', '英语成绩']].quantile(0.25)
Q3 = df5[['语文成绩', '数学成绩', '英语成绩']].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
df5['语文异常'] = (df5['语文成绩'] < lower_bound['语文成绩']) | (df5['语文成绩'] > upper_bound['语文成绩'])
df5['数学异常'] = (df5['数学成绩'] < lower_bound['数学成绩']) | (df5['数学成绩'] > upper_bound['数学成绩'])
df5['英语异常'] = (df5['英语成绩'] < lower_bound['英语成绩']) | (df5['英语成绩'] > upper_bound['英语成绩'])
df5['年龄异常'] = (df5['年龄'] < 10) | (df5['年龄'] > 30)
print("异常值标记:")
print(df5[['学生ID', '姓名', '语文异常', '数学异常', '英语异常', '年龄异常']])输出:
python
异常值标记:
学生ID 姓名 语文异常 数学异常 英语异常 年龄异常
0 S001 张三 False False False False
1 S002 李四 False False False False
2 S003 王五 False False False False
3 S004 赵六 True False False False
4 S005 钱七 False True False False
5 S006 孙八 False False False True
6 S007 周九 False False False False4、处理异常值
替换超出边界的成绩 - 替换为边界值
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df5 = df_data.copy()
Q1 = df5[['语文成绩', '数学成绩', '英语成绩']].quantile(0.25)
Q3 = df5[['语文成绩', '数学成绩', '英语成绩']].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
for col in ['语文成绩', '数学成绩', '英语成绩']:
lower = lower_bound[col]
upper = upper_bound[col]
df5[col] = df5[col].clip(lower, upper)
print(df5)输出:
python
学生ID 姓名 语文成绩 数学成绩 英语成绩 年龄 Unnamed: 6
0 S001 张三 85.0 92.00 78 15 NaN
1 S002 李四 90.0 88.00 95 16 NaN
2 S003 王五 75.0 82.00 80 15 NaN
3 S004 赵六 107.5 95.00 88 17 # 异常:语文成绩超过100
4 S005 钱七 88.0 52.25 92 16 # 异常:数学成绩负数
5 S006 孙八 92.0 98.00 105 200 # 异常:年龄不合理
6 S007 周九 65.0 72.00 68 15 NaN替换不合理的年龄 - 替换为平均值
python
import pandas as pd
import numpy as np
df_data = pd.read_excel('data.xlsx')
df5 = df_data.copy()
# 计算30岁及以下学生的平均年龄
age_mean = df5[df5['年龄'] <= 30]['年龄'].mean()
# 四舍五入为整数(或者使用 np.round, np.floor, np.ceil 等)
age_mean_int = int(round(age_mean))
# 将30岁以上学生的年龄替换为整数平均值
df5.loc[df5['年龄'] > 30, '年龄'] = age_mean_int
print("处理异常值后:")
print(df5[['学生ID', '姓名', '语文成绩', '数学成绩', '英语成绩', '年龄']])输出:
python
处理异常值后:
学生ID 姓名 语文成绩 数学成绩 英语成绩 年龄
0 S001 张三 85 92 78 15
1 S002 李四 90 88 95 16
2 S003 王五 75 82 80 15
3 S004 赵六 120 95 88 17
4 S005 钱七 88 -5 92 16
5 S006 孙八 92 98 105 16
6 S007 周九 65 72 68 155、删除异常值
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df5 = df_data.copy()
print("删除年龄异常前:")
print(df5[['学生ID', '姓名', '语文成绩', '数学成绩', '英语成绩', '年龄']])
# 基于原始年龄删除异常
# 1. 先创建副本
df5_drop = df5.copy()
# 2. 添加原始年龄列
df5_drop['原始年龄'] = df5['年龄'].copy()
# 3. 筛选原始年龄≤30的行
df5_drop = df5_drop[df5_drop['原始年龄'] <= 30]
# 4. 删除临时列
df5_drop = df5_drop.drop('原始年龄', axis=1)
print("\n删除年龄异常后:")
print(df5_drop[['学生ID', '姓名', '语文成绩', '数学成绩', '英语成绩', '年龄']])输出:
python
删除年龄异常前:
学生ID 姓名 语文成绩 数学成绩 英语成绩 年龄
0 S001 张三 85 92 78 15
1 S002 李四 90 88 95 16
2 S003 王五 75 82 80 15
3 S004 赵六 120 95 88 17
4 S005 钱七 88 -5 92 16
5 S006 孙八 92 98 105 200
6 S007 周九 65 72 68 15
删除年龄异常后:
学生ID 姓名 语文成绩 数学成绩 英语成绩 年龄
0 S001 张三 85 92 78 15
1 S002 李四 90 88 95 16
2 S003 王五 75 82 80 15
3 S004 赵六 120 95 88 17
4 S005 钱七 88 -5 92 16
6 S007 周九 65 72 68 15六、数据规范化与标准化
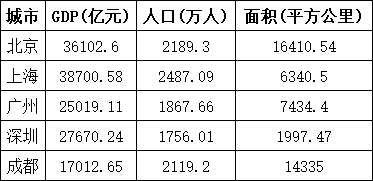
Excel(data.xlsx)示例数据:
1、最小-最大规范化
最小-最大规范化(Min-Max Normalization),也称为离差标准化或线性函数归一化,是一种常用的数据标准化方法。它的核心思想是 将原始数据线性变换到指定的范围内(通常是0, 1区间)。
最小-最大规范化的目的:
- 将不同量纲、不同范围的数据转换到统一的范围
- 消除数据尺度差异,使数据具有可比性
对于将数据规范到 0, 1 区间:
x n o r n = x − x m i n x m a x − x m i n x_{\mathrm{norn}}={\frac{x-x_{\mathrm{min}}}{x_{\mathrm{max}}-x_{\mathrm{min}}}} xnorn=xmax−xminx−xmin
对于将数据规范到 a, b 区间:
x n o r m = a + ( x − x min ) × ( b − a ) x max − x min x_{\mathrm{norm}}=a+{\frac{(x-x_{\operatorname*{min}})\times(b-a)}{x_{\operatorname*{max}}-x_{\operatorname*{min}}}} xnorm=a+xmax−xmin(x−xmin)×(b−a)
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df6_minmax = df_data.copy()
numeric_cols = ['GDP(亿元)', '人口(万人)', '面积(平方公里)']
for col in numeric_cols:
min_val = df6_minmax[col].min()
max_val = df6_minmax[col].max()
df6_minmax[f'{col}_minmax'] = (df6_minmax[col] - min_val) / (max_val - min_val)
print("最小-最大规范化后:")
# 输出城市列和所有规范化后的列
output_cols = ['城市'] + [f'{col}_minmax' for col in numeric_cols]
print(df6_minmax[output_cols])输出:
python
最小-最大规范化后:
城市 GDP(亿元)_minmax 人口(万人)_minmax 面积(平方公里)_minmax
0 北京 0.880894 0.646235 0.568273
1 上海 1.000000 1.000000 0.282303
2 广州 0.369314 0.150532 0.382652
3 深圳 0.491679 0.000000 0.000000
4 成都 0.000000 0.497755 1.000000结果解读:
最小-最大规范化(Min-Max Normalization) 将原始数据线性转换到0,1区间:
- 0 表示该城市在该指标上处于最小值位置
- 1 表示该城市在该指标上处于最大值位置
GDP(亿元)指标:
- 上海(1.0)GDP最高
成都(0.0)GDP最低
北京(0.88)接近最高水平
人口(万人)指标:
- 上海(1.0)人口最多
深圳(0.0)人口最少(但需注意深圳面积也最小)
成都(0.50)人口处于中间位置
面积(平方公里)指标:
- 成都(1.0)面积最大
深圳(0.0)面积最小
上海(0.28)面积较小,但其GDP和人口密度很高
2、Z-score标准化
Z-score标准化(也叫标准差标准化或零-均值标准化)是一种统计方法,用于将数据转换为具有均值为0、标准差为1的标准正态分布。
核心公式为: z = x − μ σ z={\frac{x-\mu}{\sigma}} z=σx−μ
- z:标准化后的值(Z分数) x:原始值 μ:该列的均值 σ:该列的标准差
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df6_zscore = df_data.copy()
# 定义数值列
numeric_cols = ['GDP(亿元)', '人口(万人)', '面积(平方公里)']
for col in numeric_cols:
mean_val = df6_zscore[col].mean()
std_val = df6_zscore[col].std()
df6_zscore[f'{col}_zscore'] = (df6_zscore[col] - mean_val) / std_val
print("Z-score标准化后:")
# 输出城市列和所有标准化后的列
output_cols = ['城市'] + [f'{col}_zscore' for col in numeric_cols]
print(df6_zscore[output_cols])输出:
python
Z-score标准化后:
城市 GDP(亿元)_zscore 人口(万人)_zscore 面积(平方公里)_zscore
0 北京 0.716238 0.328726 0.255240
1 上海 1.288371 1.352782 -0.469163
2 广州 -0.438185 -0.831754 0.003027
3 深圳 0.026692 -1.036339 -1.391226
4 成都 -1.593116 0.186584 1.602122结果解读:
Z-score标准化将数据转换为均值为0,标准差为1的正态分布:
- 正值表示高于平均值
- 负值表示低于平均值
- 数值大小表示距离均值的标准差倍数
GDP(亿元)指标:
- 上海(1.29)最高,比平均GDP高出约1.29个标准差
成都(-1.59)最低,比平均GDP低约1.59个标准差
北京(0.72)明显高于平均值
广州(-0.44)略低于平均值
人口(万人)指标:
- 上海(1.35)人口最多,显著高于平均水平
深圳(-1.04)人口最少,明显低于平均水平
北京(0.33)略高于平均值
成都(0.19)接近平均水平
面积(平方公里)指标:
- 成都(1.60)面积最大,显著大于平均面积
深圳(-1.39)面积最小,显著小于平均面积
上海(-0.47)面积略小于平均值
北京(0.26)面积略大于平均值
3、小数定标规范化
小数定标规范化(Decimal Scaling) 通过移动数据的小数点位置,将数据转换到-1,1或0,1区间:
- 方法:除以10的k次幂,其中k是使所有数据的绝对值都小于1的最小整数 保留了数据的分布形状,只是调整了量级
python
import pandas as pd
df_data = pd.read_excel('data.xlsx')
df6_decimal = df_data.copy()
# 定义数值列
numeric_cols = ['GDP(亿元)', '人口(万人)', '面积(平方公里)']
for col in numeric_cols:
max_abs = abs(df6_decimal[col]).max()
k = len(str(int(max_abs)))
df6_decimal[f'{col}_decimal'] = df6_decimal[col] / (10 ** k)
print("小数定标规范化后:")
# 输出城市列和所有规范化后的列
output_cols = ['城市'] + [f'{col}_decimal' for col in numeric_cols]
print(df6_decimal[output_cols])输出:
python
小数定标规范化后:
城市 GDP(亿元)_decimal 人口(万人)_decimal 面积(平方公里)_decimal
0 北京 0.361026 0.218930 0.164105
1 上海 0.387006 0.248709 0.063405
2 广州 0.250191 0.186766 0.074344
3 深圳 0.276702 0.175601 0.019975
4 成都 0.170127 0.211920 0.143350结果解读:
GDP(亿元)指标:
- 最大值:38700.58(5位数)
k = 5,所以除以10⁵(100,000)
规范化后数值在1.7-3.87之间
人口(万人)指标:
- 最大值:2487.09(4位数)
k = 4,所以除以10⁴(10,000)
规范化后数值在0.175-0.249之间
面积(平方公里)指标:
- 最大值:16410.54(5位数)
k = 5,所以除以10⁵(100,000)
规范化后数值在0.20-1.64之间
所有数据被缩放到相对接近的范围内,不同指标之间可以更直观地比较。
对比不同规范化方法:
- 最小-最大规范化:将数据映射到0,1区间,强调相对位置
- Z-score标准化:以标准差为单位表示距离均值的远近,适合正态分布数据
- 小数定标规范化:通过移动小数点简化数据,适合数据量级差异大的情况