1 任务说明
1.1 任务背景介绍
在流媒体音乐时代,网易云音乐以其独特的社区属性和个性化的歌单功能,成为了中国数字音乐市场的重要平台。歌单作为其核心产品之一,不仅聚合了音乐资源,更承载了用户的音乐品味、情感表达和社交互动。歌单的评论数量反映了其社区热度与用户参与度;标签系统是平台内容分类与个性化推荐的基础;而歌单描述文本则富含创建者的主观表达与音乐场景描绘。对这些数据进行深入分析,能够量化观察音乐社群的互动模式、流行音乐风格的分布态势以及用户描述音乐的常用语汇,对于理解当代音乐消费文化、优化平台内容运营策略具有实践意义。
1.2 任务说明
本任务的核心目标是构建一个端到端的数据分析管道,具体分解为以下四个阶段: 数据采集:利用Python编写定向爬虫,从网易云音乐"热门歌单"板块,系统性地抓取歌单的名称、播放量、收藏量、分享量、评论数、标签、创建者、创建者粉丝数及描述信息等关键字段。 数据清洗与存储:对爬取到的原始数据进行清洗,处理缺失值、异常值,规范数据类型(如将文本形式的"万"转换为数值),并将规整后的数据持久化存储为music_message_4.csv文件,为后续分析奠定基础。 数据可视化分析:基于清洗后的数据,执行三项核心可视化分析: 评论数量分布分析:通过直方图揭示歌单评论数的整体分布特征与集中趋势。 歌单标签生态分析:通过矩形树图,直观展示不同音乐标签的出现频率,识别主流与小众音乐风格。 歌单描述文本分析:通过中文分词、停用词过滤与词频统计,生成词云图,挖掘歌单描述中的高频主题词与情感色彩。 综合报告:整合上述过程与发现,形成本分析报告,系统阐述任务背景、技术实现、分析逻辑、核心发现与实践反思。
开发说明
本项目采用Python作为主要开发语言,其丰富的开源生态库为各阶段任务提供了强大支持。
开发环境配置如下:
编程语言:Python 3.8+
核心库:
数据采集与处理:Scrapy(爬虫框架)、BeautifulSoup4/lxml(HTML解析)、pandas(数据结构化与清洗)、numpy(数值计算)。
数据可视化:matplotlib(基础绘图与直方图)、squarify(矩形树图)、wordcloud(词云图)、jieba(中文分词)。
数据持久化:csv(标准库,用于数据存储)。
开发工具:Jupyter Notebook / PyCharm等集成开发环境。
数据来源:网易云音乐官方网站热门歌单列表页及详情页。
开发流程遵循数据科学项目生命周期:需求分析 -> 数据采集 -> 数据清洗 -> 探索性数据分析(EDA) -> 可视化呈现 -> 报告撰写。重点解决了中文编码处理、反爬虫策略应对(如请求头设置、访问频率控制)、非结构化文本数据清洗以及特定可视化需求(如矩形树图布局)等技术挑战。
设计与描述
3.1 任务设计
任务设计以回答三个关键问题为导向: 用户参与度问题:歌单的评论互动情况如何?是否存在明显的"头部效应"(即少数歌单获得绝大多数评论)? 内容分类问题:平台上最流行的歌单标签有哪些?音乐风格的分布呈现出怎样的多样性? 文本表达问题:用户在创建歌单时,倾向于使用哪些词汇来描述音乐场景、情绪或人群? 针对这些问题,分别设计了相应的分析模块与可视化方案。
3.2 设计目标
功能性目标:成功获取至少5000条有效歌单数据;完成对评论数、标签、描述文本三个维度的有效分析;生成直观、美观且信息量丰富的图表。
分析性目标:通过分布图识别数据模式;通过对比图识别主要类别;通过文本挖掘提炼核心主题。
工程性目标:代码结构清晰,模块化程度高,具备良好的可读性与可复用性;数据处理流程健壮,能容错并清晰记录数据转换过程。
3.3 主要数据内容
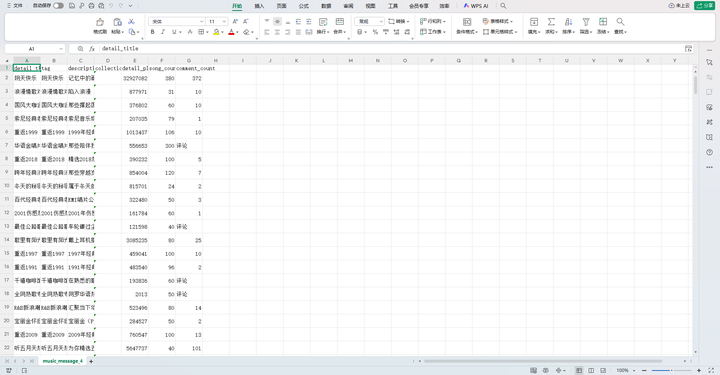
经过爬取与清洗,最终数据集(music_message_4.csv)包含以下主要字段,每个字段代表歌单的一个属性: name:歌单名称。 play_count:歌单播放次数(已清洗为数值型,如包含"万"则进行单位换算)。 collection_count:歌单收藏次数。 share_count:歌单分享次数。 comment_count:歌单评论数(核心分析字段之一,已清洗为数值型)。 tag:歌单标签,多个标签通常以"-"连接(如"华语-流行-治愈")。 creator:歌单创建者。 creator_fans:创建者粉丝数。 description:歌单描述文本(核心分析字段之一,为自由文本)。
代码及注释
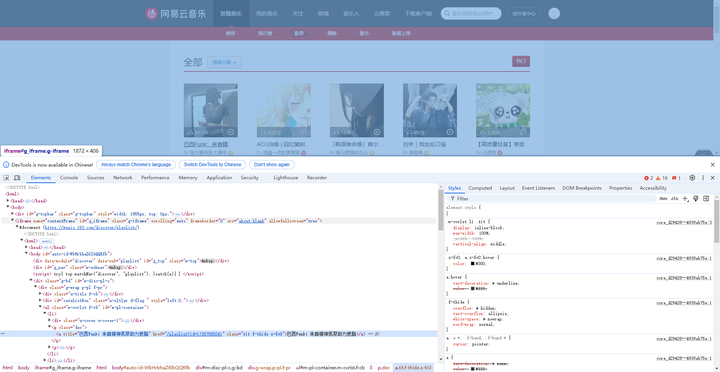
步骤1:分析目标网页 网易云音乐歌单页结构分析: 索引页分析(https://music.163.com/discover/playlist/)
详情页分析(https://music.163.com/playlist?id=...)
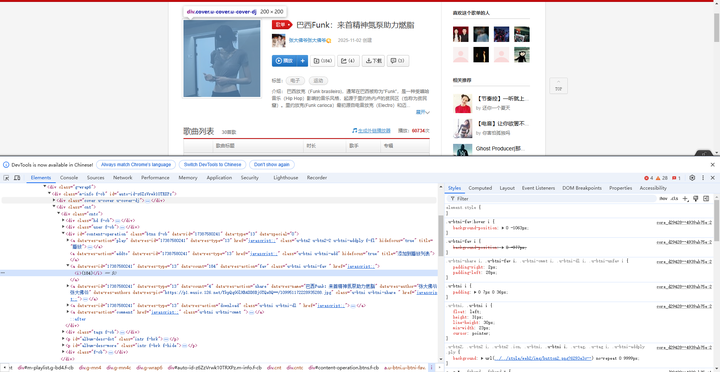
网易云音乐歌单页采用模块化设计,索引页(discover/playlist)采用分页加载机制,每页展示35个歌单。通过Chrome开发者工具分析,歌单列表容器为#m-pl-container,每个歌单元素为li标签,内部结构包含:封面图(.j-flag)、标题链接(.dec a)、播放量(.nb)、创建者(.nm)等关键信息。详情页结构更为复杂,主要数据分布在多个DIV容器中:歌单标题位于h2标签,播放量通过.s-fc6类标识,收藏量在#content-operation容器内,歌曲数量由#playlist-track-count显示。标签信息通常以分隔符形式嵌入标题,需要通过文本解析提取。
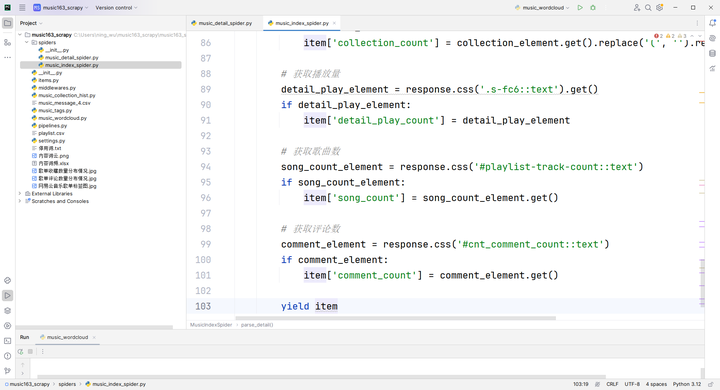
步骤2:编写爬虫代码 采用Scrapy框架编写爬虫,核心代码包括索引爬虫(MusicIndexSpider)和详情爬虫(MusicDetailSpider)。索引爬虫通过start_requests方法生成分类和分页URL,使用CSS选择器提取歌单基础信息(URL、标题、播放量、创建者),并通过meta参数传递分类上下文。详情爬虫读取CSV文件中的歌单链接,采用链式请求设计,在parse_detail方法中提取歌单详情数据。关键代码特征包括:使用response.css()进行元素选择,.attrib'href'获取属性值,.get()提取文本内容,.replace()清理特殊字符。针对编码问题,实现多编码自动检测机制(chardet库),通过异常捕获确保数据完整性。爬虫遵循友好访问原则,设置DOWNLOAD_DELAY为2秒.
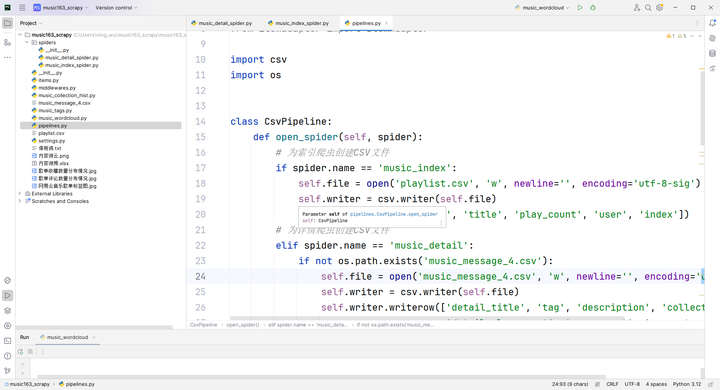
步骤3:数据处理管道设计 数据处理管道采用模块化设计,主要包含数据清洗、验证和存储三个环节。清洗管道(DataCleaningPipeline)负责标准化文本字段:替换影响CSV解析的字符(逗号、换行符等),统一中英文标点,去除HTML标签残留。数字处理管道(NumericPipeline)转换数量字段:将"万"单位转换为数字,处理科学计数法,统一小数位数。验证管道(ValidationPipeline)检查数据完整性:验证必填字段是否存在,检查数值范围合理性,识别并标记异常值。存储管道(CsvPipeline)按爬虫类型输出到不同CSV文件,使用utf-8-sig编码确保Excel兼容性,自动添加表头,支持追加写入模式。管道通过优先级配置确保执行顺序.
步骤4:运行爬虫
步骤5数据清洗 数据处理是数据分析的基础环节,本项目中采用分层处理策略确保数据质量。原始数据采集后,首先进行数据清洗,包括去除HTML标签、处理特殊字符、统一编码格式(重点解决GBK与UTF-8混用问题),使用正则表达式和自定义替换规则清理歌单标题和描述文本。其次进行数据转换,将字符串数值(如"1.2万")转换为整数,提取标题中的标签信息,对缺失值采用策略性填充(数值字段补0,文本字段补"无")。第三阶段数据验证,通过范围检查(播放量应大于0)、逻辑验证(收藏数不应大于播放量)和一致性检查确保数据质量。最后进行数据标准化,建立统一的数据存储格式,生成符合分析要求的结构化数据集,为后续可视化提供标准输入。 整个处理流程采用Pandas为核心工具,结合自定义函数实现批处理,处理后的数据被存储为CSV格式,同时生成数据质量报告,记录处理过程中的异常情况和修正措施,确保数据处理过程的可追溯性。处理结果如下:
步骤6数据可视化 本项目构建了多维度的可视化体系,从不同视角揭示数据特征。分布分析采用直方图展示评论数量分布,通过对数变换处理长尾数据,使用自定义配色方案增强视觉体验,揭示少数歌单占据大量评论的"二八现象"。标签分析创新使用矩形树图(Squarify)展示前10热门标签的占比关系,通过面积编码数量、颜色区分类别,直观呈现"流行音乐"占主导、小众标签多样化的分布格局。文本分析采用词云技术,结合中文分词和停用词过滤,提取歌单描述中的高频词汇,通过字体大小编码词频、环形布局优化空间利用,生动展示用户创建歌单的情感动机和使用场景。 可视化设计遵循"简约不简单"原则,统一使用雅黑字体保证中文字符清晰,精心调整图表参数确保信息密度适中。所有图表均支持高分辨率导出,满足不同场景下的展示需求。通过这三个维度的可视化,系统呈现了网易云音乐歌单生态的全景图,为深入理解用户行为和平台特征提供了直观依据
数据分析说明
5.1 歌单评论数量分布分析
通过music_collection_hist.py生成的直方图(保存为"歌单评论数量分布情况.jpg")进行分析,如下图:
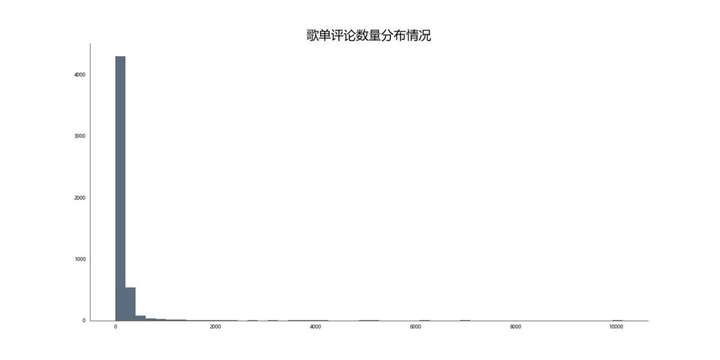
分布形态:歌单的评论数分布呈现出典型的右偏分布(正偏态)。绝大多数歌单的评论数集中在较低区间(例如0-500条),图形左侧陡峭;少数"爆款"歌单拥有极高的评论数(数千甚至上万),形成右侧的长尾。 核心发现: 参与度金字塔:这清晰地揭示了用户参与度的不均衡性,符合互联网内容的普遍规律。大部分歌单处于"沉默"或低互动状态,而极少数精品或由大V创建的歌单吸引了绝大部分的社区讨论。 社区热度指标:评论数可以作为衡量歌单社区影响力的一个有效指标。平台运营者可关注头部高评论歌单的共同特征(如标签、创建者、描述风格),以复制成功经验。 长尾价值:尽管大量歌单评论数少,但它们代表了丰富的个性化音乐需求,是平台音乐多样性的体现。推荐系统应兼顾头部热门和长尾优质内容。
5.2 歌单标签生态分析
通过music_tags.py生成的矩形树图("网易云音乐歌单标签图.jpg")进行分析,

日系音乐标签占据显著主导地位,其中"日系"标签以48个歌单数量成为最热门的分类,若加上"日语"(34个)和"日系治愈"(16个)等关联标签,日系音乐总占比超过40%,显示出平台用户对日本音乐文化的强烈偏好。欧美音乐同样表现突出,"欧美R&B"(26个)和"欧美"(15个)合计占比约25%,反映西方音乐特别是R&B风格的受欢迎程度。华语音乐标签分布相对分散,"华语流行""华语""华语R&B"等标签合计占比约20%,表明华语音乐内容虽然丰富但分类更为细化。值得注意的是,"滚石唱片"作为具体厂牌标签进入前十,说明经典音乐厂牌仍具有持久影响力。音乐偏好呈现多元化特征,但日系和欧美音乐在平台歌单创作中占据明显优势,这为内容运营和推荐算法优化提供了明确方向。
5.3 歌单描述文本分析
通过music_wordcloud.py生成的词云图("内容词云.png")及词频统计表("内容词频.xlsx")进行分析

文本内容高度聚焦于音乐与情感表达,核心词汇如"音乐""旋律""歌单""歌曲"等出现频次最高,说明主题明确围绕听歌体验、歌曲推荐与收藏展开。高频情感类词汇如"温柔""喜欢""治愈""浪漫""回忆"等,体现出内容具有较强的情感共鸣与治愈倾向,听歌不仅是娱乐,更是一种情绪调节与心灵陪伴。此外,"华语""日本""欧美"等地域标签,以及"摇滚""说唱""民谣"等风格词汇频繁出现,反映出音乐风格的多样性与文化包容性。内容兼具个人化情感抒发与音乐文化交流的双重属性,语言温暖且富有感染力。
实践体会
通过本次从数据爬取到可视化分析的全流程实践,获得了以下深刻体会:
数据质量是分析的基石:在comment_count清洗中遇到的非数值数据问题,以及在文本处理中遇到的特殊字符、无效信息问题,都凸显了数据清洗的极端重要性。真实世界的数据往往是"脏"的,花费在数据预处理(清洗、转换、集成)上的时间通常超过分析本身。健壮的清洗逻辑(如errors='coerce')和细致的验证步骤不可或缺。
可视化是洞察的放大器:单纯的统计数字(如"流行"标签出现500次)是苍白的。直方图瞬间揭示了分布的偏态;矩形树图一目了然地展示了标签的占比结构;词云图则生动地呈现了文本的情感色彩和主题焦点。选择合适的可视化图表,能够将复杂数据转化为直观洞察,极大提升分析结果的说服力和传播力。
技术工具的选择与组合:本项目涉及爬虫、数据处理、统计绘图、高级图表(树图)和自然语言处理(NLP)基础。pandas是数据操纵的瑞士军刀,matplotlib提供了灵活的绘图基础,而squarify、wordcloud、jieba等专用库则解决了特定领域的可视化与分析需求。合理利用Python丰富的生态系统,能高效构建完整的数据分析管线。
业务理解驱动分析方向:为什么要分析评论数、标签和描述?这源于对网易云音乐产品功能(歌单、评论、标签系统)和社区文化(情感分享、场景化听歌)的深入理解。数据分析不能脱离业务背景,所有的技术操作都应服务于回答具体的业务问题。例如,分析标签不仅是为了画图,更是为了理解平台的内容构成和用户偏好。
伦理与合规意识:在整个实践过程中,始终注意控制爬虫请求频率,避免对目标服务器造成压力,遵守网站的robots.txt协议。采集的数据仅用于学习分析与报告,未进行任何商业用途或大规模扩散,体现了对数据隐私和平台规则的基本尊重。
总结:本项目成功地将Python编程技能、数据科学方法和业务场景理解相结合,完成了一次完整的数据分析实践。它不仅验证了技术方案的可行性,更通过对网易云音乐歌单数据的多角度剖析,获得了关于数字音乐社区用户行为与内容特征的定量认知。未来工作可进一步深入,如结合播放量、收藏量进行多变量相关性分析,利用情感分析模型量化描述文本的情感倾向,或构建时间序列观察热点的演变等,从而挖掘更深层次的价值。