结构
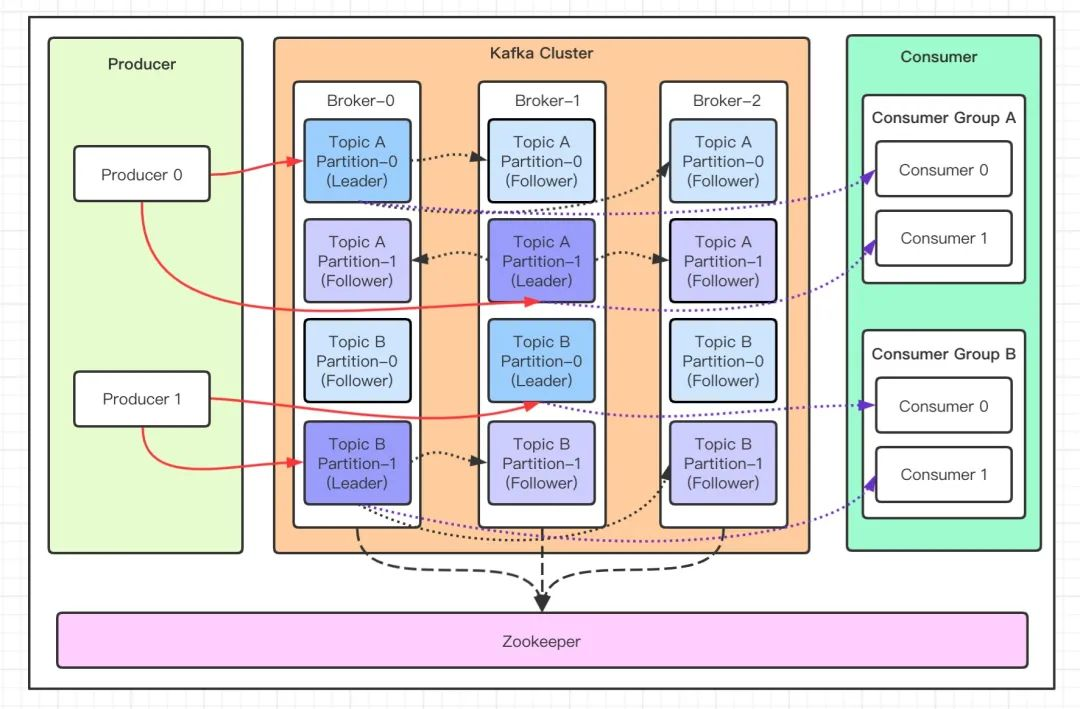
- Message:每一条发送的消息主体。
- Topic:消息的主题,可以理解为消息队列,Kafka的数据就保存在Topic,不同Topic之间相互隔离,互不影响。
- Partition:Topic的分区,每个Topic可以有多个分区,分区的作用是做负载,提高Kafka的吞吐量,实现数据分片。同一个Topic在不同的分区的数据是不重复的。
- Replication:每一个分区都有多个副本,副本的作用是做备胎,主分区(Leader)会将数据同步到从分区(Follower)。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为 Leader。在Kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量。
- 客户端角色:
- Producer:Producer即生产者,消息的产生者,是消息的入口。
- Consumer:消费者,即消息的消费方,是消息的出口。
- Consumer Group:多个消费组组成一个消费者组,同一个分区的数据只能被消费者组中的某一个消费者消费,同一个消费者组的消费者可以消费同一个Topic的不同分区的数据。
- 服务端角色:
- Broker:服务节点,多个Broker节点组成一个Kafka集群。
- Zookeeper:Kafka集群依赖Zookeeper来保存集群的的元信息(Topic信息、分区、Broker、动态配置、用户权限)、依赖Zookeeper实现节点监控和发现、选举中心节点。
计算过程
发送消息
客户端发送
- 获取集群元数据,包括Broker节点、主题、分区(每个分区的副本列表),读取并缓存到本地。
- 为消息指定分区,发送到对应分区的Leader副本。
- RoundRobinPartitioner轮询分区器。
- UniformStickyPartitioner黏性分区器,尽可能填满一个分区之后再切换下一个分区。
- DefaultPartitioner默认分区器,计算消息键Hash后对分区数量取模。
- 消息序列化为字节数组。
- 消息缓存到Accumulator中,分批次发送:当批次已满或者延迟时间已到时,发送该批次。
- Sender线程定时检查Accumulator中的消息批次,并发送已经达到阈值的批次。
- Broker不会将一个批次的消息拆分处理,而是同样以批次为单位存储数据和将数据发送给消费者。
通信协议
RecordBatch
RecordBatch是Kafka消息传输的最小"协议单元",结构如下:(字段长度单位:字节)

| 字段名 | 长度 | 数据类型 | 核心含义 |
|---|---|---|---|
| BaseOffset | 8 | int64 | 该批次第一条消息在Partition中的偏移量(由 Broker 分配,客户端发送时设为 -1,Broker 填充) |
| BatchLength | 4 | int32 | 整个 RecordBatch 的总字节数(含所有字段) |
| PartitionLeaderEpoch | 4 | int32 | 分区 Leader 的版本号,区分不同任期的 Leader。 |
| Magic | 1 | int8 | 消息格式版本(0 = 旧版本,1 = 0.11.0+ 版本,支持事务 / 幂等性) |
| CRC32 | 4 | uint32 | 对 Batch 中 "Magic 之后的所有字段" 的 CRC 校验码(Broker 用于校验数据完整性) |
| Attributes | 2 | int16 | 批次属性:- 0-2 位:压缩算法(0 = 无压缩,1=GZIP,2=Snappy,3=LZ4,4=ZSTD)- 3 位:是否事务消息(1 = 是)- 4 位:是否控制消息(1 = 是,用于事务协调) |
| LastOffsetDelta | 4 | int32 | 该批次最后一条消息与第一条消息的偏移量差值(= 批次内消息数 - 1) |
| FirstTimestamp | 8 | int64 | 批次内第一条消息的时间戳(单位:毫秒) |
| MaxTimestamp | 8 | int64 | 批次内最后一条消息的时间戳 |
| ProducerId | 8 | int64 | 生产者 ID(仅 Magic=1 且开启幂等性 / 事务时有效,由 Broker 分配) |
| ProducerEpoch | 2 | int16 | 生产者版本号 |
| BaseSequence | 4 | int32 | 该批次第一条消息的序列号(生产者发送消息的递增序列,保证幂等性) |
| RecordsCount | 4 | int32 | 该批次内的消息条数(Record 数量) |
| Records | 可变 | 字节数组 | 所有 Record 的二进制数据(按 Record 格式依次拼接) |
PartitionLeaderEpoch用于解决 Leader 切换时数据一致性问题,它是一个单调递增的整数,与分区的 Leader 副本绑定,本质是 Leader 副本的 "版本号"。
生产者从 Broker 获取当前分区的PartitionLeaderEpoch,并将其写入RecordBatch 中,随消息一起发送给 Leader。Leader 校验收到的PartitionLeaderEpoch 是否与自己的当前Epoch一致:一致则正常写入消息,不一致则拒绝写入,返回错误给生产者。
**ProducerEpoch主要用于幂等性和实现事务,**同一个ProducerId对应多个ProducerEpoch,每次生产者重启,Epoch会递增 1。
幂等性:生产者发送的每条消息都会携带ProducerId + ProducerEpoch + SequenceNumber(序列号),Broker 会基于这三个字段做幂等校验:只有相同ProducerId、相同ProducerEpoch、相同SequenceNumber 的消息,才会被判定为重复消息,Broker 会直接丢弃;若Epoch不匹配(比如旧实例的Epoch 小于当前 Broker 记录的Epoch),Broker 会拒绝该消息,防止旧实例的残留请求干扰。
事务:在事务消息中,ProducerEpoch用于标记事务的 "归属实例":事务协调者会记录每个ProducerId对应的最新Epoch;只有携带最新Epoch的生产者实例,才能提交或回滚事务;旧Epoch的实例发起的事务操作,会被直接拒绝,避免事务状态混乱。
Record
每条Record是变长编码:

| 字段名 | 长度 | 数据类型 | 核心含义 |
|---|---|---|---|
| Length | 4 | int32 | 单条 Record 的总字节数(含以下所有字段) |
| Attributes | 1 | int8 | 单条消息属性(目前仅 0-2 位有效,与 RecordBatch 的压缩算法一致,冗余设计) |
| TimestampDelta | 8 | int64 | 消息时间戳与 RecordBatch.FirstTimestamp 的差值(减少重复存储,节省空间) |
| KeyLength | 4 | int32 | 消息 Key 的长度(-1 表示无 Key) |
| Key | 可变 | 字节数组 | 消息 Key(二进制格式,客户端需自行序列化,如 JSON/Protobuf) |
| ValueLength | 4 | int32 | 消息 Value 的长度(-1 表示无 Value,即空消息) |
| Value | 可变 | 字节数组 | 消息体(核心业务数据,二进制格式,序列化方式由客户端决定) |
| HeadersCount | 4 | int32 | 消息头数量(0 表示无自定义头) |
| Headers | 可变 | 键值对数组 | Headers 字段是可选的键值对(Key-Value)集合,用于存储消息的附加元数据,相当于消息的 "标签" 或 "附属信息",不会影响消息体(Value)的业务逻辑,仅用于辅助消息的路由、过滤、追踪等场景。 自定义消息头,每个 Header 格式为:- HeaderKeyLength (4 字节) + HeaderKey (可变) + HeaderValueLength (4 字节) + HeaderValue (可变) |
Broker接收
处理消息
- 对命令请求内容进行验证:检查写入分区是否存在;检查生产者是否有写入权限。
- 将消息保存到本地Log文件中。
- 按请求acks参数返回结果:
- 如果acks参数不为-1,则Broker在消息写入本地后立即给生产者返回成功。
- 如果acks参数为-1,则Broker设置定时任务,等待ISR中所有副本节点都同步该消息后再返回成功。
延迟操作
时间轮
轮盘结构:将时间轴拆分为固定大小的 "时间槽(Bucket)",形成一个环形数组(类似时钟的 12 个刻度);
时间粒度:每个槽对应一个固定的时间间隔(如 1ms、10ms),称为tickMs;
分层设计:单级时间轮容量有限,通过 "秒轮、分轮、时轮" 分层(类似时钟的秒 / 分 / 时),支持超长延迟任务;
任务映射:延迟任务根据 "到期时间" 计算所属的槽位,存入对应槽的任务列表;
驱动机制:一个定时器线程按tickMs间隔遍历槽位,执行该槽中已到期的任务。
Kafka的时间轮
为了避免任务太稀疏导致指针空转,Kafka将存在任务的Bucket槽放入DelayQueue中,再从延迟队列取出到期的Bucket。(Bucket数量是固定的,使用DelayQueue不存在性能问题)
DelayQueue和时间轮的对比
| 对比维度 | 时间轮(TimeWheel) | DelayQueue |
|---|---|---|
| 核心数据结构 | 环形数组 + 链表(哈希映射) | 二叉堆 + 全局 ReentrantLock |
| 插入操作时间复杂度 | O (1)(计算槽位 → 插入链表) | O (logN)(堆结构调整) |
| 删除操作时间复杂度 | O (1)(若记录槽位,直接删除链表节点) | O (N)(遍历找元素)+ O (logN)(堆调整) |
| 执行到期任务复杂度 | O (1)(遍历当前槽位) | O (logN)(堆顶取出 + 堆调整) |
| 并发性能 | 无全局锁(可按槽位加锁),高并发友好 | 全局 ReentrantLock,高并发下锁竞争激烈 |
| 内存占用 | 固定内存(槽数组大小),低占用 | 动态堆结构,内存随任务数增长 |
| 延迟精度 | 由 tickMs 决定(如 10ms),精度可控 | 毫秒级高精度,但性能代价高 |
| 海量任务支持 | 支持(分层时间轮可扩展),百万级任务无压力 | 不支持(O (logN) 开销随任务数指数增长) |
| 典型应用场景 | 高吞吐延迟消息(如 RocketMQ)、定时任务 | 低并发、小批量延迟任务(如单机定时) |
| Kafka/Pulsar 适配性 | 适配(可分布式部署) | 完全不适配(单节点、高锁竞争) |
接收消息
消费者分区
分配器
RangeAssignor:分区和消费者按字典序排序,然后一一对应,按序分配。如果分区数多余消费者数,排在前面的消费者会被多分。
RoundRobinAssigner:所有消费者和该消费者订阅的所有分区按字典序排序,然后逐个分配。如果一个消费者订阅了不同主题,会被多分。
StickyAssigner:机器下线时保留原来消费者的分配方案,把多出来的分区再均匀分配。
CooperativeStickyAssignor:EAGER 在JOIN_GROUP之后取消所有订阅的分区,消费全部暂停;COOPERATIVE 分为两次重平衡,消费者在第一次JOIN_GROUP(见下文)之后取消原消费者部分分区,但不给新消费者分区,第二次平衡时给新消费者分配原消费者取消的分区。
重平衡
- 新消费者发送JOIN_GROUP请求给Broker协调者,要求加入消费组。
- 协调者通过心跳给所有消费者发送REBALANCE_IN_PROGRESS,通知重平衡开始,然后等待所有消费者加入。
- 其他消费者收到REBALANCE_IN_PROGRESS之后,发送JOIN_GROUP请求加入消费。
- 协调者收到所有JOIN_GROUP之后,选择一个leader消费者,将当前消费者和订阅关系发送给leader。
- leader消费者生成分区方案,并将该方案通过SYNC_GROUP发送给协调者。
- 协调者通过SYNC_GROUP把该方案发送给所有消费者。
- 消费者开始消费。
读取消息
- 消费者通过Heartbeat维持和协调者之间的会话,默认每3秒发送一次心跳,45秒无心跳则超时。
- Broker中保存当前分区的ACK偏移量,偏移量之前的消息已经全部消费成功,下一次从偏移量开始拉取数据。
- 消息消费成功后,消费者将ACK偏移量发送给协调者Broker(注意不是分区Broker,分区Broker只支持消息读写)
- Kafka消费者使用纯粹的**"拉"模型**读取消息:如果当前分区有可消费的消息则立即返回,如果没有消息Consumer会在本地最多等待
timeout时间(如 100ms),期间不断尝试拉取,而这个等待是在客户端完成的,不是Broker挂起请求。相比之下,Rocket通过长轮询实现类似于"推消息"的机制,当Consumer 发起拉取时如果Broker没有消息,挂起请求最多 15~30 秒,一旦有新消息到达,立即返回给 Consumer,牺牲部分吞吐换取更低延迟(会消耗更多Broker资源)。
事务消息
幂等消息
保证单生产者的单个分区内发送的消息只会被持久化一次,杜绝重复消息的问题。
实现方式
- Broker为生产者分配身份标识PID,生产者为PID+Partition内的消息分配单调递增的序列号。
- Broker 为每个PID + Partition维护最大已提交序列号,并校验消息是否可接收:
- 新消息序列号 = 最大已提交序列号 + 1 → 合法,写入消息,更新最大已提交序列号;
- 新消息序列号 ≤ 最大已提交序列号 → 重复消息,直接丢弃,返回写入成功给生产者;
- 新消息序列号 > 最大已提交序列号 + 1 → 消息乱序或丢失,拒绝写入,触发生产者重试补齐空缺。
事务消息
目标
- 向多个Topic发送消息,所有分区 / Topic 的消息写入要么全成、要么全败。
- 消费Topic1的消息→业务处理→向Topic2发送结果消息,同样要么全部成功,要么全部失败,避免消费成功但生产失败、生产成功但消费位点未提交。
实现
发送到多个Topic的事务:
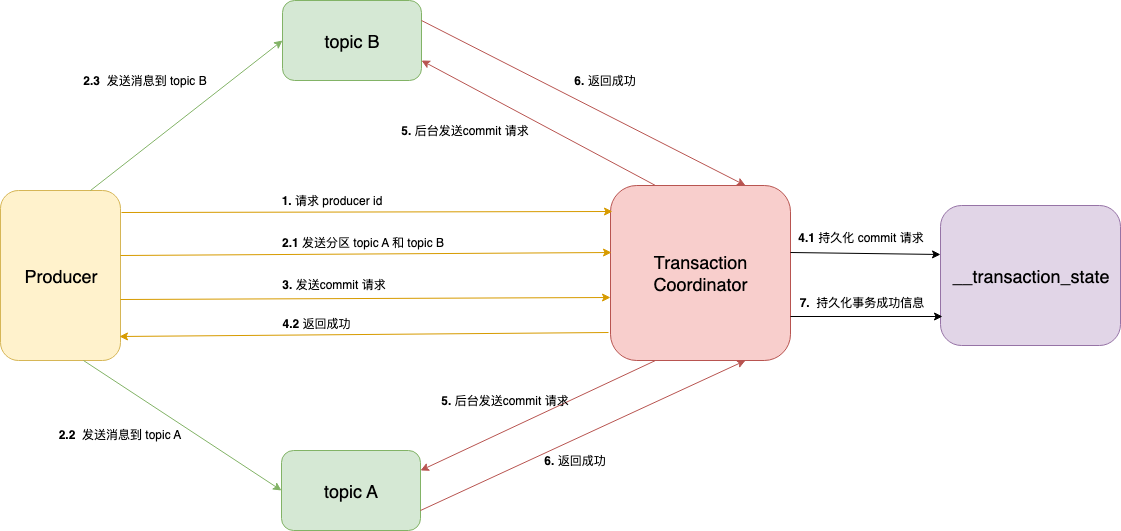
- 初始化生产者,获取PID。
- 生产者发送消息:
- 分区信息给事务协调者,事务协调者保存。
- 分别发送消息给topic A和topic B。
- 生产者发送commit请求。
- 事务协调者持久化commit请求,并返回成功。
- 事务协调者发送commit请求给topic A和topic B。
- 返回给事务协调者commit成功。
- 事务协调者持久化成功的状态。
消费-处理-生产的事务
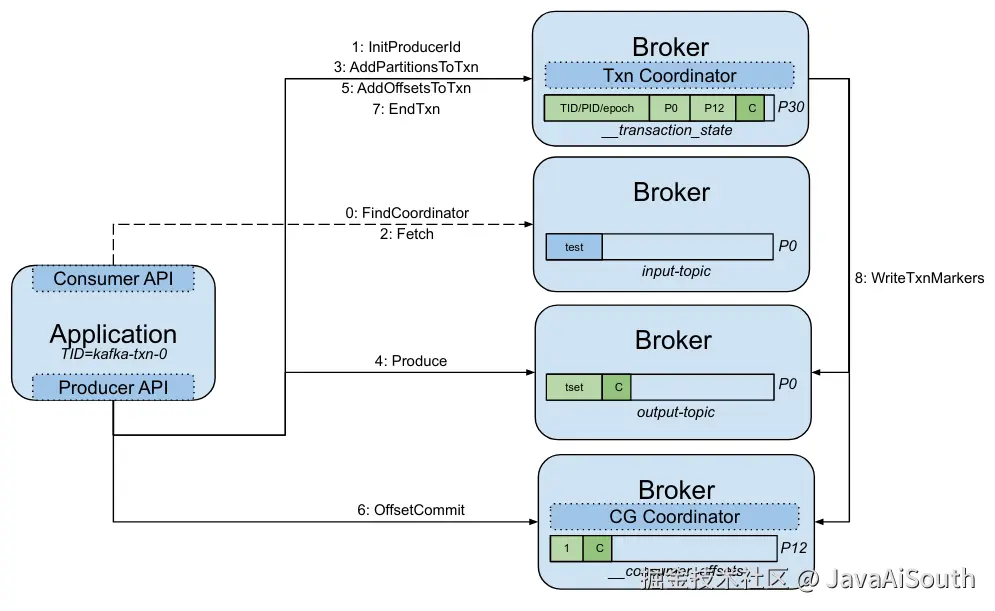
- 初始化生产者,获取PID。
- 拉取消息并消费。
- 生产者发送消息前,先发送AddPartitionsToTxn给事务协调者,事务协调者保存事务分区信息。
- 生产者发送消息,Broker标记为未提交消息。
- 生产者发送AddOffsetsToTxn给事务协调者,事务协调者保存ACK偏移量。
- 生产者发送TxnOffsetCommit给消费组协调者,消费者协调者保存(未提交)ACK偏移量。
- 生产者发送EndTxnRequest给事务协调者,事务协调者修改状态为PREPARE_COMMIT,返回给生产者提交成功。
- 事务协调者发送WriteTxnMarkers给事务分区的leader副本和消费组协调者,分别提交并返回响应给事务协调者,事务协调者把状态修改为COMPLETE_COMMIT。
存储设计
文件结构
Kafka 的存储本质是 "逻辑分类(Topic)→ 物理拆分(Partition)→ 分段存储(Segment)→ 文件组(.log/.index/.timeindex)" 的分层设计,这样做的好处是:
分区拆分:实现存储和读写的水平扩展;
分段存储:避免单个文件过大,提升读写 / 清理效率;
索引文件:通过 .index/.timeindex 实现消息的快速查询,不用全量扫描 .log 文件。
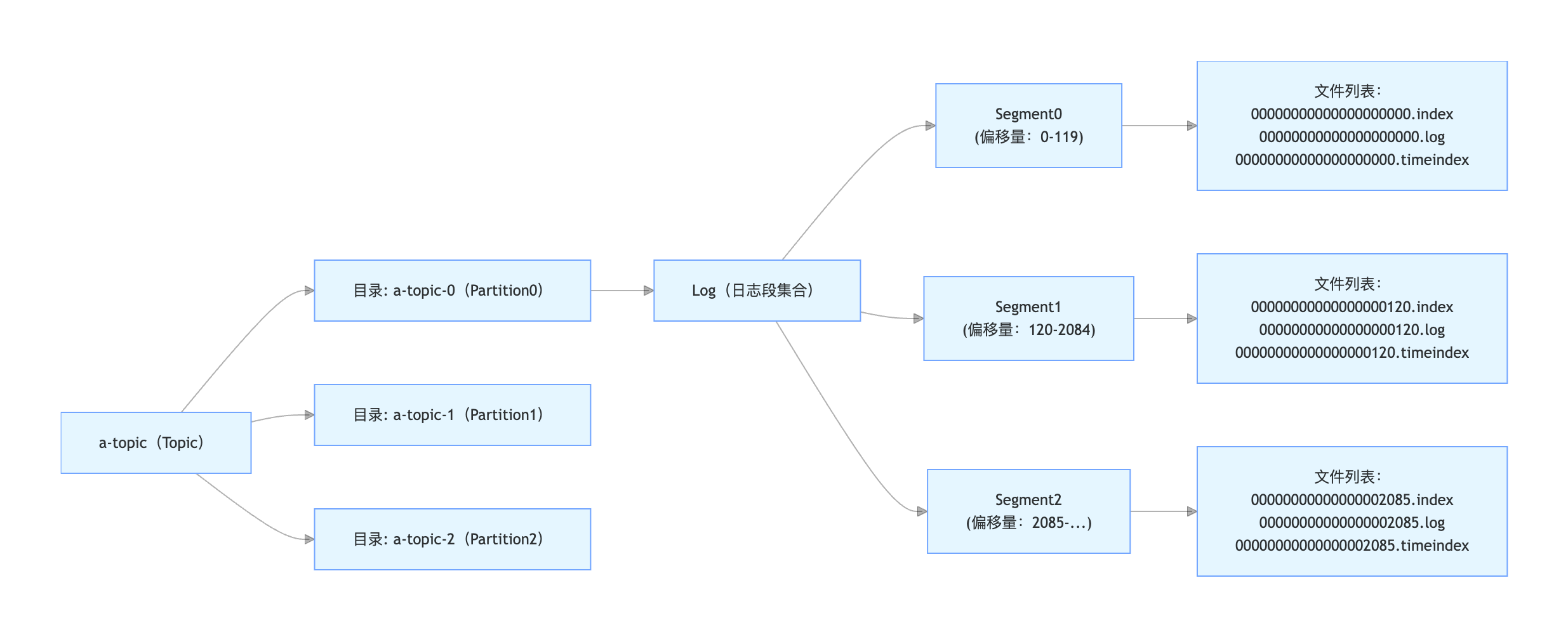
Topic(逻辑消息分类)
本身不存储数据,仅用于区分不同业务的消息。
Partition(物理存储单元)
Topic 会被拆分为多个 Partition(分区)(图中是 a-topic-0/a-topic-1/a-topic-2),每个 Partition 对应磁盘上的一个独立目录。
消息会被分散写入不同 Partition,实现存储和读写的 "水平扩展"(比如 Topic 拆 3 个 Partition,可同时用 3 个 Broker 存储)。
Log(日志段集合)
由多个 Segment(日志段) 组成的 "集合"。避免单个文件过大,Partition 的消息按 "大小 / 时间" 拆分为多个 Segment
Segment(日志分段)
每个 Segment 是 Log 中的一个 "子文件组",对应一批连续偏移量的消息:例如Segment0 对应偏移量 0~119的消息;Segment1 对应偏移量 120~2084的消息;Segment2 对应偏移量 2085 之后的消息。每个 Segment 都有自己的编号(即该段第一条消息的偏移量,比如 Segment0 的编号是 00000000000000000000)。
每个 Segment 对应 3 个文件,共同实现 "消息存储 + 快速查询":.log 文件:存储实际的消息数据(二进制格式),是消息的核心载体;.index 文件:存储消息偏移量 → 文件物理位置的映射(稀疏索引),用于快速定位某个偏移量的消息在 .log 中的位置;.timeindex 文件:存储消息时间戳 → 偏移量的映射,用于按时间范围查询消息。
读写优化
高吞吐量的消息系统一般有追加写入和顺序读取两大特点,Kafka在此基础上通过以下特性提高性能:
顺序读写
生产者将写入的消息聚合为消息批次,然后追加到Log文件中,读取时一次读取一个(或多个)消息批次。
PageCache
操作系统创建内核缓冲区PageCache,提供预读和后写。
预读:一次性读取比请求要求更多的数据并缓存在PageCache中。
后写:写操作仅仅写入PageCache,由操作系统将PageCache中的多个变更合并成一个并刷新到磁盘中。
Kafka没有定义Java进程的内存缓冲区,直接使用PageCache缓存消息内容,省去一份Java进程内部内存消耗,且缓存不受Kafka服务重启影响。
如果生产者的生产速率和消费者的消费速率相差不大,那么生产消费过程只需要在PageCache中同步完成,不需要任何磁盘读写操作。
零拷贝
缓冲IO和直接IO如下图,区别在于应用程序是否在用户空间中使用内核缓冲区。直接IO也可以舍弃PageCache直接和磁盘交互,Linux需要通过系统调用open(O_DIRECT)开启。

包含PageCache的直接IO,一次读或者写需要2次数据复制操作(应用程序和PageCache、PageCache和磁盘)和1次上下文切换操作(用户态与内核态切换)。
缓冲ID,一次读或者写需要3次数据复制操作和1次上下文切换操作。
零拷贝的mmap和sendfile机制减少数据复制和上下文切换操作:
mmap:应用程序的逻辑内存映射到(内核缓冲区)PageCache,应用程序直接读写PageCache。完成一次读或者写只需要1次数据复制操作(内核缓冲区与磁盘)和1次上下文切换。

sendfile:数据不经过用户空间,直接在内核空间中发送给目标存储介质,例如将磁盘数据发送到网络,不需要切换上下文。

读写流程
- 查找Partition:Broker接收到消息之后,根据「生产者指定的分区策略」(或默认策略:轮询 / 按 key 哈希),路由消息到目标 Partition(比如 a-topic-0),确定最终要写入的 Partition 目录。
- 定位Log并追加日志 :需要加锁;根据文件创建时间阈值、文件大小阈值、索引文件大小阈值检查是否需要切换到新的日志段;检查消息是否已存在,处理幂等、事务逻辑;判断是否需要刷盘;通过mmap写入。
- 更新LastEndOffset。
- 定位目标 Segment 文件:接收消费者的拉取请求,找到Partitiono(如果不启动最佳副本读取机制,默认使用leader节点),二分查找,定位Segment文件。
- 定位Log位置:基于.index索引,二分查找+向后遍历找到可以拉取的日志位置。
- 读取日志内容:优先通过PageCache读取;只能消费 HW 之前的消息;通过sendfile发送。
日志管理
清理
去重:基于消息 Key 唯一性去重。
按时间清理:当Segment文件的最后修改时间 ≥ 配置的保留时长,则被标记为过期,由后台线程自动删除(整段删除,包含 .log/.index/.timeindex)。
按大小清理:当单个Partition的所有Segment文件总大小 ≥ 配置的最大保留大小,则从最旧的 Segment 开始,逐个删除,直到总大小低于阈值。
刷盘
写入时刷盘:配置间隔N条消息进行一次刷盘,N为1时则每条消息都刷盘。
定时刷盘:累计写入N条消息,触发一次刷盘;累计N毫秒,触发一次刷盘;默认均为Long.MAX_VALUE。
内核自动刷盘:脏页最长不超过30s刷盘;脏页占内存比超20%触发刷盘。
刷盘机制对性能影响较大,建议通过多副本保证消息可靠。
分布式
主从同步
ISR
In-Sync Replicas,保持基本同步的leader和follow集合。
ISR集合由leader管理,同时保存到Zookeeper中,避免leader副本下线导致ISR信息丢失。
leader节点定时更新ISR集合:把超过N毫秒没有fetch消息的副本剔出ISR集合;把不在ISR集合中但是logEndOffset大于等于HW的副本拉进ISR集合。
follower主动从leader拉取消息并保存到本地。
HW
HighWatermark 高水位,ISR集合中同步进度最落后的副本logEndOffset。
HW只增不减;消费者只能读取HW之前的消息;消费者默认从leader副本读取消息,leader负责处理读写请求,follow负责备份;leader只在ISR中选举。
acks=1(默认,性能优先)时,leader写入消息,更新自身LEO → 立即给Producer返回ACK。
acks=all /acks=-1(生产推荐,可靠性优先)时,leader写入消息并创建延迟操作 + ISR内所有副本同步完成 + leader更新 HW → 才给Producer返回 ACK。
acks=0(极致性能,无可靠性):Producer发送消息后,不等待Broker任何响应,直接返回成功。
日志截断
场景
原leader的LEO已经到100,HW仍为90(F1/F2的LEO仅90),leader宕机后重启,在这个过程中F1被选为新leader且写入90-100的消息(偏移量和原leader重合,但内容完全不同)。
LeaderEpoch**设计**
每个Partition的Leader每一次换届,都会分配一个单调递增的整数任期号(Epoch),比如第一次 Leader是Epoch=0,换届后新Leader是Epoch=1。
为「偏移量 + 任期号」建立唯一绑定关系,新Leader的Epoch一定大于原Leader的Epoch,且每个Leader都会记录「自己任期内写入的消息偏移量范围」(比如 Epoch=1 的 Leader,写入的偏移量是 90~100)。
解决问题
原Leader重启后发现自己成为Follower,立刻向新 Leader 发送fetch请求,并携带元数据:自身宕机时的LeaderEpoch值、自身的LEO=101和HW=90、自身记录的各Epoch对应的偏移量范围。
新Leader收到请求后,执行最严格的一致性校验,给原Follower返回指令:
- 截断边界:原Follower将本地日志截断到「Epoch 切换的临界偏移量 = 90」;
- 同步起点:原Follower从偏移量90开始,重新拉取新Leader Epoch=1 下的90~100消息。
最强一致性
生产者
properties
# 1. 最强可靠性级别:等待所有ISR副本同步完成后再返回
acks=all
# 2. 开启无限重试(生产中建议设为较大值,如10)
retries=10
# 3. 重试间隔(避免短时间重复请求)
retry.backoff.ms=1000
# 4. 开启幂等性(防止重试导致的消息重复)
enable.idempotence=trueBroker
properties
# 1. ISR最小同步副本数,防止单副本故障
min.insync.replicas=2
# 2. 副本同步超时阈值,避免短暂滞后被踢出ISR
replica.lag.time.max.ms=60000
# 3. 日志刷盘兜底
log.flush.interval.ms=500
# 4. 日志保留策略,避免数据提前清理
log.retention.hours=720
# 5. 关闭自动删除
log.retention.enable=false
# 6. 开启Leader Epoch,防止日志截断异常
leader.epoch.replication.checkpoint.interval.ms=10000消费者
properties
# 1. 关闭自动提交,手动控制消费位点
enable.auto.commit=false
# 2. 手动同步提交(消费完成后再提交)
# 代码中调用:consumer.commitSync()
# 3. 消费超时(避免长事务导致的位点过期)
max.poll.interval.ms=300000
# 4. 禁止自动重置位点(避免丢失未消费消息)
auto.offset.reset=none和RMQ的对比
| 对比维度 | Kafka | RocketMQ |
|---|---|---|
| 消费语义 | 最多一次(At most once):生产者ack=0+消费者自动提前提交位点,可能丢消息。 至少一次(At least once):默认配置(ack=1/all+消费后提交位点),不丢但可能重复。 精确一次(Exactly once):生产者开启幂等 / 事务 + 消费者位点绑定事务,支持 Consume-Transform-Produce 端到端精确一次 | 最多一次:消费者同步消费 + 立即提交位点,可能丢消息。 至少一次:默认配置(异步消费 + 消费完成后提交位点),不丢但可能重复。 精确一次:通过 事务消息 + 本地事务表 实现,支持分布式事务场景。 |
| 是否幂等 | 支持。 通过PID+Partition+序列号实现,但是仅单生产者单分区生效。 | 支持。 生产者+消息唯一Key,Broker 基于 Key 去重,支持跨分区 / 跨生产者,需手动设置消息 Key。 |
| 事务消息 | 支持。 实现原理:基于 两阶段提交(2PC)+ 事务协调器 + 内部主题__transaction_state 核心能力:支持多 Topic / 多 Partition 原子写入,支持 消费 - 生产 | 支持。 实现原理:半消息机制 + 事务反查,分为「发送半消息→执行本地事务→提交 / 回滚」三步,无需依赖协调器。 核心能力:支持 分布式事务(本地事务表 + 消息事务),适合订单支付等场景 |
| 重复消费 | 存在重复可能。 重复原因:网络重试、Broker 故障恢复、消费者位点回滚 解决方式:单分区开启幂等性;多分区开启事务消息;业务层基于唯一键去重 | 存在重复可能。 重复原因:半消息提交重试、消费者重平衡 解决方式:消费者基于业务唯一键去重。 |
| 推还是拉 | 拉。 消费者主动拉取,Broker 无主动推送能力,消费者可以设置长轮询参数。 | 拉。 同样也有长轮询。 |
| 顺序消费 | 单Partition是顺序消费。 | 单Partition是顺序消费。 |
| 广播消费 | 支持。 | 支持。 |
参考
1 深入理解Kafka与Pulsar。