4.1 高可用性的全景图
高可用性(High Availability)不是某个开关或某个功能,而是一种从物理硬件贯穿到应用逻辑的系统性设计哲学。它如同为一座现代化城市构建的防灾体系:从建筑的抗震结构(硬件冗余),到市政的应急响应(平台服务集群),再到每个家庭的应急包(应用多活),共同组成一个纵深防御网络。本章,我们将全景式扫描这座"云城市"的每一道防线,并通过"压力测试"来验证其可靠性。
一、纵深防御体系:构建云平台的"马其诺防线"
云平台的高可用性设计遵循"不将鸡蛋放在同一个篮子"的原则,并在每一层都设立冗余和自动故障转移机制。
第一道防线:硬件层的物理冗余------城市的"坚固地基"
这是所有高可用性的物质基础,也是最直观的一层。
- 服务器级 :双电源 接入不同PDU、RAID 1的系统盘,确保单路市电或单块系统盘故障不影响服务器运行。
- 网络接入级 :每台服务器配置多块网卡 ,并通过 LACP/ 绑定模式 上联到MLAG配对的叶交换机。这消除了网卡、线缆、交换机端口乃至整台交换机的单点故障,提供了无中断的网络路径。
- 存储硬件级:在分布式存储架构下,单块硬盘以JBOD模式使用,其冗余由软件层保障,但服务器整体的风扇、电源等冗余设计,仍是节点稳定服役的前提。
第二道防线:平台服务层的集群化------城市的"应急指挥中心"
云平台自身的核心管理服务绝不能是单点。XX云通过 " 管理节点集群" 实现这一目标。
- 多活集群 :关键的API服务、认证服务、数据库服务等,均以多节点集群 方式部署。例如,三个管理节点同时运行关键服务,通过负载均衡器对外提供统一入口。任何单个节点宕机,流量被自动导向其余健康节点,用户无感知。
- 分布式存储集群 :这是我们数据高可用的核心。以Ceph为例,数据被划分为PG(归置组),每个PG默认维护3个副本 ,并分布在不同的服务器、甚至不同的机架。Ceph的"自我修复"能力是这层的灵魂:当监测到某个OSD(磁盘)或节点下线,集群会自动在剩余的健康磁盘上开始重建缺失的副本,直至恢复完整的冗余状态。
- 网络控制层:SDN控制器、DHCP服务等同样以集群模式运行,确保虚拟网络策略的下发和IP地址的分配永不中断。
第三道防线:应用层的多活与优雅降级------家庭的"应急自救"
这是最能体现业务架构师智慧的一层。基础设施提供了高可用的"舞台",应用需要设计出能在舞台上持续表演的"剧本"。
- 无状态应用 :Web服务、API服务等应设计为无状态。通过云平台的负载均衡器 和弹性伸缩组,将实例分布在多个可用区(故障域)。任何实例故障,被自动移出并替换,实现水平扩展与高可用。
- 有状态应用(以DolphinDB为例) :这是我们案例中的典范。
- 数据副本:DolphinDB的分布式表本身支持多副本。每个分区的数据会在多个数据节点上存在副本。当某个数据节点故障时,查询和写入会自动路由到拥有健康副本的其他节点。
- 控制器高可用 :部署多个控制节点,并通过冗余的链路接入网络。控制节点负责元数据管理和协调,其高可用确保了整个数据库集群的管理面不会瘫痪。
- 客户端重试与连接池:应用端配置重试机制和连接多个控制节点地址,确保单点故障时能自动重连。
- 与云平台协同 :当监测到某DolphinDB节点所在物理机发生不可恢复故障时,云平台调度器可结合反亲和性规则,在另一台健康物理机上快速重构一个全新的虚拟机或容器,并挂载原分布式存储卷,实现跨主机的高可用恢复。
二、故障模拟与演练:真正的信心源于"炮火检验"
纸上谈兵终觉浅。一个真正健壮的系统,必须经过精心设计的故障演练。我们模拟三个经典场景,观察系统的反应。
场景一:暴力美学------拔掉一块数据盘(NVMe SSD)
- 预期现象 :
- 服务器操作系统或硬件RAID卡(如果配置了)会立刻告警。
- 对于分布式存储(Ceph),该盘对应的 OSD 状态会迅速变为 down, 随后 out 。监控大盘上该服务器存储利用率骤降,集群整体存储利用率不变但出现"降级"PG。
- 系统自愈过程 :
- Ceph的Monitor检测到OSD下线,经过预设的超时窗口后,开始重新计算受影响PG的数据分布。
- 集群中所有其他健康OSD开始协作,自动重建原丢失盘上所有数据的副本,并将其写入到其他节点的空闲空间。网络流量和磁盘IO会显著上升。
- 待所有PG恢复为 active+clean 状态,数据恢复完整的三副本,告警自动清除。
- 业务影响 :零影响。对于上层的虚拟机、DolphinDB数据库,整个数据重建过程是完全透明的。I/O请求略有波动但持续可用,无需人工干预。
场景二:节点级灾难------宕掉一台块存储服务器
- 预期现象 :
- 监控中该服务器所有指标(Ping、SSH、服务端口)中断。
- 分布式存储集群中,该服务器上所有OSD(可能8个HDD+2个SSD对应的OSD)集体标记为 down 和 out。大量PG进入降级状态,但取决于副本分布,多数应仍可读写。
- 运行在该物理机上的所有虚拟机、容器会瞬间失联。
- 系统自愈与恢复过程 :
- 存储层:Ceph触发大规模但有序的数据重建,将丢失节点的所有数据副本,在其他幸存节点的磁盘上重建。
- 计算层 :XX云调度器检测到宿主机故障,会将其标记为"不可用",并自动在其管理的其他健康宿主机上,按原有规格重新启动那些设置了"高可用"策略的虚拟机。虚拟机重启后,因其系统盘和数据盘均为分布式存储卷,数据完好无损,业务恢复。
- 网络层:由于虚拟机在新宿主机上重启,SDN控制器会自动将其虚拟网卡重新接入对应的VXLAN网络,IP/MAC地址不变。
- 业务影响 :业务中断时间 = 虚拟机检测故障时间 + 重启时间 (通常为分钟级)。对于无状态应用,恢复后业务连续;对于有状态应用(如未集群化的单点服务),会有分钟级中断。这凸显了应用层自身高可用设计(如DolphinDB多副本) 的重要性。
场景三:网络风暴------关闭一台核心叶交换机(MLAG成员之一)
- 预期现象 :
- 网络监控告警该交换机离线。
- 所有双上联至此MLAG对的服务器,其网络流量在毫秒内无缝切换至幸存的那台叶交换机。通过 ip a 命令查看服务器网卡绑定状态,可能显示一条链路 down,但聚合接口依然 up。
- 服务器与外部通信会有瞬间的丢包或微秒级延迟波动,TCP会话快速重传恢复。
- 系统自愈过程 :
- 对服务器和上层业务,此过程是自动、瞬间的,没有"恢复"等待期。MLAG协议已预先同步了状态,故障发生时,备交换机立即接管所有MAC地址和流量。
- 管理员需物理更换或修复故障交换机。修复后重新上电,MLAG协议会重新协商,流量逐步均衡回两条链路,期间同样无感知。
- 业务影响 :近乎无影响。这是对我们网络高可用设计的终极验证。EPICS数据流、DolphinDB集群同步、虚拟机迁移等关键流量均不受影响,云平台服务的连续性得到保障。
总结:高可用性的真谛
通过这场从微观到宏观的"压力测试",我们可以清晰地看到,现代云平台的高可用性不是一个点,而是一个立体的、协同工作的生态系统。
- 硬件冗余 提供了故障的容身之所,让单点故障被隔离。
- 平台服务集群 提供了自动化的应急响应,在故障发生时快速重组资源。
- 应用多活设计 则实现了业务的优雅接续,将基础设施的韧性最终转化为业务的不间断服务。
真正的信心,不来自于未曾发生故障,而来自于确信当故障必然发生时,系统拥有一套成熟、自动、经过验证的机制去应对它。 这就是我们为云平台构建纵深防御体系的意义所在。在终篇,我们将站在更高的视角,复盘整个架构的设计得失,并展望未来演进的方向。
4.2 可观测性与运维体系
构建一个稳定运行的云平台只是起点,而看清其每一处脉搏、预见潜在风险、并自动化应对日常与异常,才是保障其长期健康运营的关键。可观测性(Observability)是我们的"透视眼",运维自动化则是我们的"手术机器人"。本章将揭示如何为这个复杂的有机体建立完整的生命体征监控系统,并将运维经验固化为可重复、可审计的自动化代码。
一、监控什么?构建分层递进的"生命体征监测网"
有效的监控绝非指标的简单堆砌。我们遵循 " 从基础设施到业务价值" 的黄金法则,构建一个分层、聚焦的监控体系。下图展示了这个分层监控金字塔,以及核心的监控数据流:
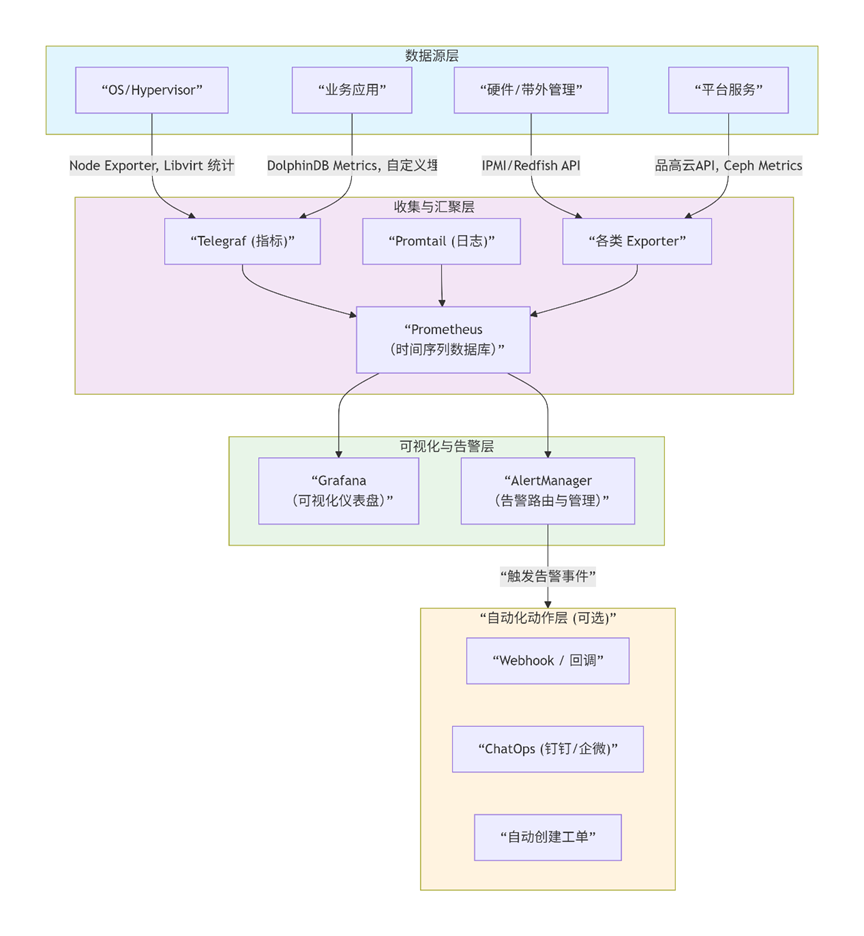
第一层:基础设施健康度------系统的"筋骨"
这是稳定性的根基,必须实现主动式、预测性监控。
- 硬件健康 :
- 服务器 :通过IPMI或Redfish API采集电源状态、风扇转速、CPU/内存温度。温度持续升高是冷却系统故障的早期信号。
- 磁盘 :通过smartctl或硬件管理口,监控RAID卡状态、BBU(电池)健康度、磁盘SMART信息 (重分配扇区计数、读写错误率)。预测性故障分析(PFA) 能让我们在磁盘彻底宕掉前更换它。
- 网络 :监控网卡链路状态、错包/丢包率、带宽利用率。MLAG配对交换机的状态同步是否正常是关键。
- 虚拟化层 :
- 宿主机:CPU/内存/swap使用率、网络吞吐、存储IOPS和延迟(通过node_exporter、libvirt exporter)。
- 关键进程:libvirtd、ovs-vswitchd、ceph-osd等核心服务的存活状态。
第二层:平台服务SLA------系统的"器官"
这是云平台自身服务能力的直接体现。
- XX云管理面 :
- API健康 :关键管理API(如计算、网络、镜像服务)的请求成功率、平均/分位延迟。API 5xx错误率飙升往往意味着平台内部出现严重问题。
- 服务组件:keystone(认证)、nova-scheduler(调度)、neutron-server(网络)等核心服务的进程状态和日志错误。
- 存储服务 :
- Ceph集群 :集群状态(ceph health detail)、存储池使用率 (超过80%需告警)、数据重新平衡/恢复的进度与速度 、各OSD的写入/读取延迟和IOPS。监控PG的状态是核心中的核心。
- 对象存储S3:PUT/GET请求的成功率、延迟、带宽消耗。
第三层:业务与应用指标------系统的"价值输出"
这是监控的终极目的,直接关联业务连续性。
- 数据流水线健康 :
- EPICS Archiver:数据点采集成功率、归档延迟、与IOC的通道连接状态。
- 数据摄入层 :消息队列(如Kafka)的积压量(Lag) 。消费程序处理消息的速率和错误计数 。数据从产生到入库DolphinDB的端到端延迟(最关键的SLO之一)。
- DolphinDB集群 :
- 数据库层面:查询QPS、查询平均响应时间、慢查询数量、连接数。
- 资源层面:各节点内存使用率、流表数据积压、分布式表副本同步状态。
- 租户业务视角 :通过云平台监控API,汇总展示租户虚拟机/容器的整体健康度、资源使用趋势,为其提供运维视图。
二、运维自动化:将经验固化为代码
当监控发现问题或需要执行常规任务时,自动化是唯一能实现规模、速度和一致性保障的途径。XX云等现代云平台提供的丰富API,是我们实现运维自动化的"万能遥控器"。
场景一:容量不足?触发自动扩容流程
当监控检测到存储池使用率 > 85%时,触发自动化流水线。
下载
# 伪代码示例:基于XX云API的自动化扩容
def auto_expand_storage_pool(alert):
pool_name = alert.annotations.get('pool')
# 1. 调用XX云API,在预置的"待添加"主机列表中,选择一台,并将其硬盘添加到对应存储池
target_host = select_host_from_inventory()
add_osd_to_pool(pool_name, target_host)
# 2. 等待并验证OSD加入成功,集群状态恢复健康
wait_for_ceph_healthy()
# 3. 发送扩容完成通知,并更新CMDB
send_notification(f"存储池 {pool_name} 已成功扩容,新增主机 {target_host}")
update_cmdb(pool_name, new_capacity)
场景二:每日/每周自动巡检,生成健康报告
将过去需要手动执行的检查点全部代码化,定时运行。
#!/bin/bash
# 自动化巡检脚本核心逻辑
run_check "硬件健康" "ipmitool sel list"
run_check "Ceph状态" "ceph -s"
run_check "云平台服务" "openstack compute service list"
run_check "磁盘预测故障" "check_smartctl --all-drives"
# 生成JSON或Markdown格式报告,发送至运维频道
generate_report > daily_health_check_$(date +%Y%m%d).md
场景三:从告警到自愈------自动化故障修复
对于已知的、有标准处理流程的故障,实现"告警即修复"。
# 伪代码:自动处理僵尸虚拟机实例
def auto_remediate_stuck_vm(alert):
vm_id = alert.labels.get('instance_id')
# 1. 确认状态:调用XX云API,确认虚拟机状态确为"错误"且超时
vm_status = get_vm_status(vm_id)
if vm_status == 'ERROR' and time_exceeded(alert):
# 2. 安全强制删除:先尝试优雅删除,失败后强制删除
force_delete_vm(vm_id)
# 3. 基于原镜像和配置自动重建(如需)
if need_rebuild(vm_id):
rebuild_vm_from_template(vm_id)
# 4. 记录审计日志并通知
log_audit_event(vm_id, "auto_remediated")
自动化运维的价值升华:
- 一致性:无论谁执行、在何时执行,结果都相同,杜绝人工失误。
- 可审计:所有操作通过API执行,有完整的日志记录,满足合规要求。
- 效率革命:将运维人员从重复性劳动中解放出来,专注于架构优化和解决更复杂的问题。
- 持续演进:自动化脚本和流水线本身可以作为知识库,沉淀和传承团队的最佳实践。
总结:从"救火队"到"预言家"与"建筑师"
通过构建贯穿硬件、平台、业务三层的可观测性体系,我们让云平台从"黑盒"变为"白盒",甚至成为能"开口说话"、主动报告问题的有机体。而通过将运维操作全面API化、代码化、流水线化,我们则实现了从被动"救火"到主动"规划"与"自愈"的范式转移。
优秀的云平台运维,不再是24小时待命的抢险队,而是编写精密自动化程序的"系统架构师"和基于数据决策的"数据分析师" 。这套体系,不仅保障了EPICS数据流水线与DolphinDB分析服务的稳定高效,更是整个云平台得以持续、稳健承载企业核心业务的终极守护者。