关键词:淘宝爬虫、sign签名、数据加密、反爬突破、电商数据抓取
一、引言:淘宝数据爬取的难点
在进行电商数据采集时,淘宝平台因其强大的反爬机制而成为许多爬虫开发者的"硬骨头"。不同于简单的静态网站,淘宝采用了多重防护措施:
-
动态签名机制 :每个请求都需要计算sign签名
-
Cookie验证 :多个加密Cookie字段缺一不可
-
请求参数加密 :data参数需要特定格式编码
-
用户行为模拟 :需要模拟真实用户请求模式
本文将详细解析如何突破这些防护,实现稳定的淘宝商品数据抓取 建议登录一下网页版本的淘宝获取的数据更全一些
二、环境准备与工具
1. 所需Python库
python
import pandas as pd # 数据处理与存储
import requests # HTTP请求库
import re # 正则表达式
import json # JSON数据处理
import time # 时间处理
import hashlib # MD5加密2. 关键工具
-
Chrome开发者工具(分析网络请求)
-
淘宝账号(获取有效Cookie)
-
代码编辑器(PyCharm/VSCode)我这里用的是Pycharm
F12 or 右击检查 之后Ctrl+R 刷新当前页面 因为只加载开发者工具打开之后数据包
然后点击网络 or Network Ctrl+F 搜索页面中我们需要的数据
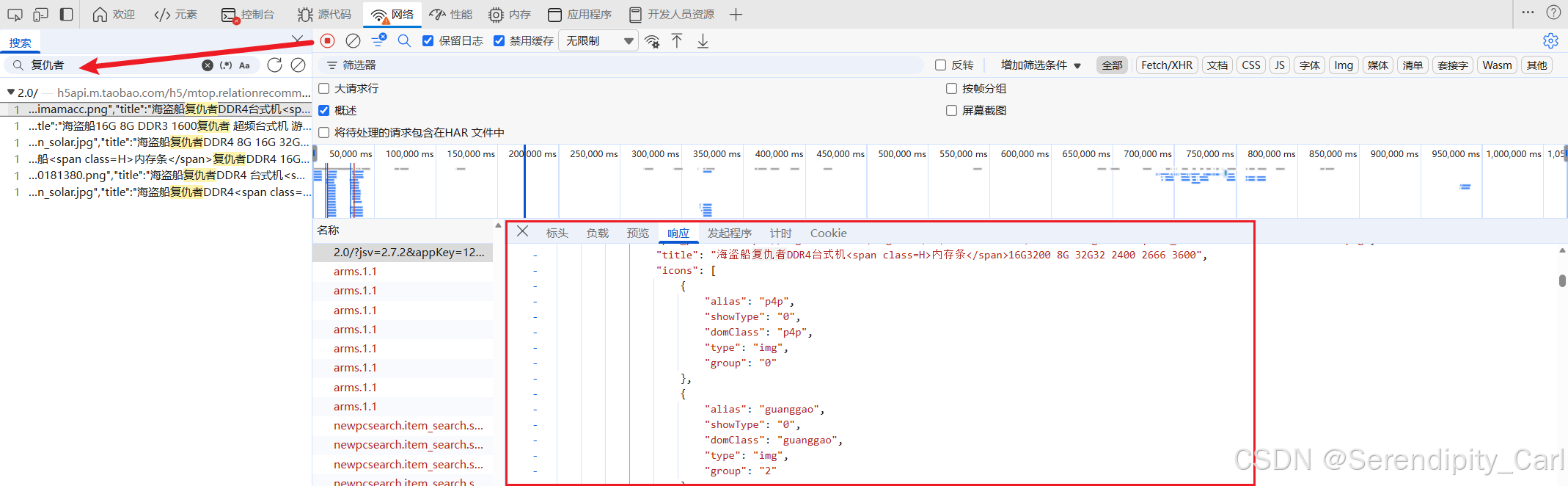
这个数据包即为所需要的 OK 我们查看详细的信息
比如负载 GET or POST 请求方式 返回的数据类型等
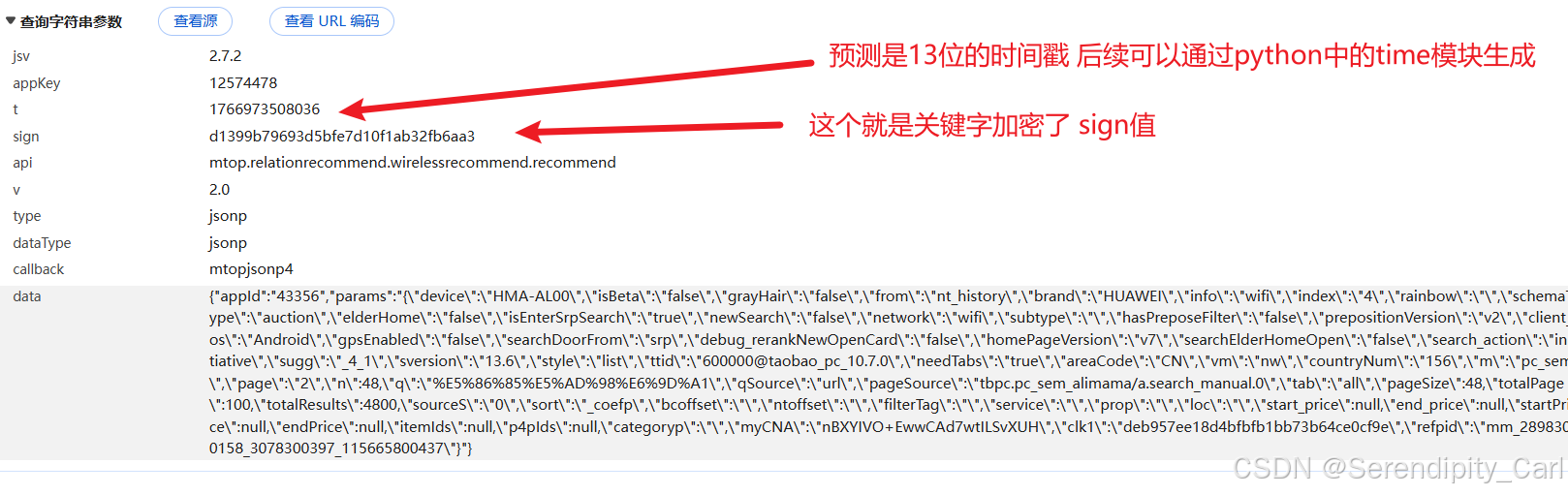
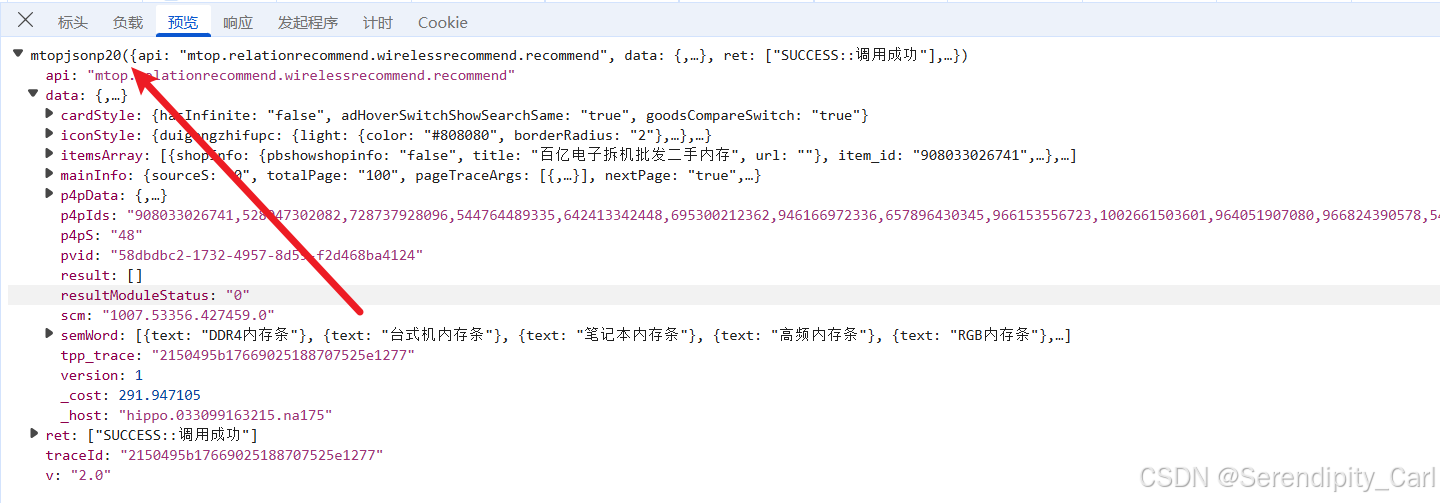
发现 返回的数据并不是完整的Json格式 前面还有别的字符串
后续可以通过正则匹配筛选我们想要的数据 再用json模块 将字符串转换成Json格式
三、请求头与Cookie分析
1. 请求头设置
python
headers = {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9", # 语言偏好
"cache-control": "no-cache", # 禁用缓存
"referer": "https://uland.taobao.com/...", # 来源页面
"sec-ch-ua": "\"Microsoft Edge\";v=\"143\"", # 浏览器标识
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)...", # 用户代理
}2. Cookie关键字段分析
淘宝的Cookie包含多个加密字段,每个都有特定作用:
python
cookies = {
"cookie2": "1e61048cce806ae369596766e305f384", # 用户会话标识
"_m_h5_tk": "daf111231dd543b04d94caa5fb6d3bbe_1766982105727", # token+时间戳
"_m_h5_tk_enc": "26900b8c4d72144bafdc8092cf9dfab6", # 加密token
"cna": "nBXYIVO+EwwCAd7wtILSvXUH", # 用户设备标识
"tfstk": "gaYjexYhI-2XdGhxB-lzFEWUqZ_sTbuEG519tCU46ZQYWf9wUFSOQmv1fdJlXE72...", # 反爬token
}
可以将此请求头的信息复制到Pycharm 构建请求头
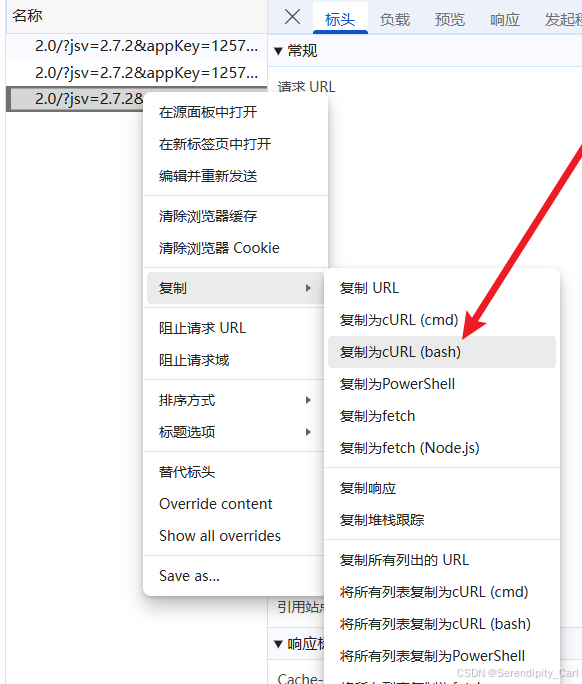
还有就是 通过工具来生成 爬虫工具库-spidertools.cn
右击数据包复制其Curl(bash) 然后到这个工具中 将返回的请求体复制到Pycharm即可

重点说明 :_m_h5_tk字段是sign计算的关键,格式为token_时间戳,例如:
daf111231dd543b04d94caa5fb6d3bbe_1766982105727
前面部分(下划线前)是token,后面部分是生成时间戳
四、Sign签名生成机制解析
1. Sign生成公式分析
Ctrl+shift+F 调出搜索框 输入sign: 一般关键字加密就搜 关键字带= : 这是前端JS语法的特性
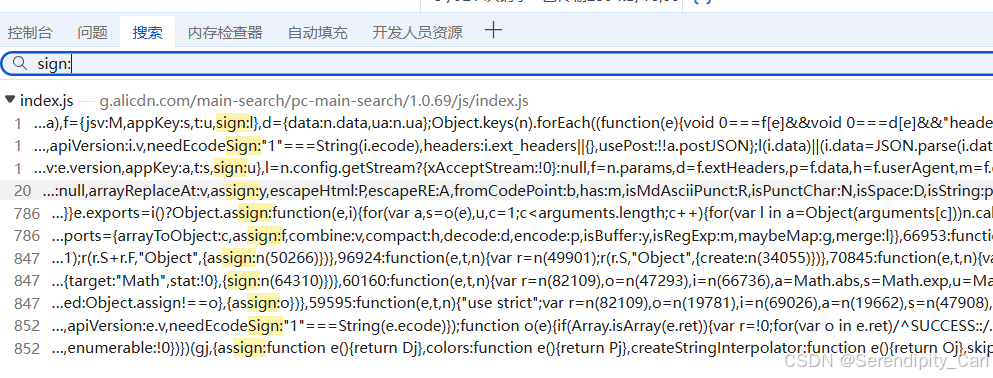
然后从返回的Js文件中查找 可以在疑似加密的位置打断点(在代码对应的行数前面左击即可)
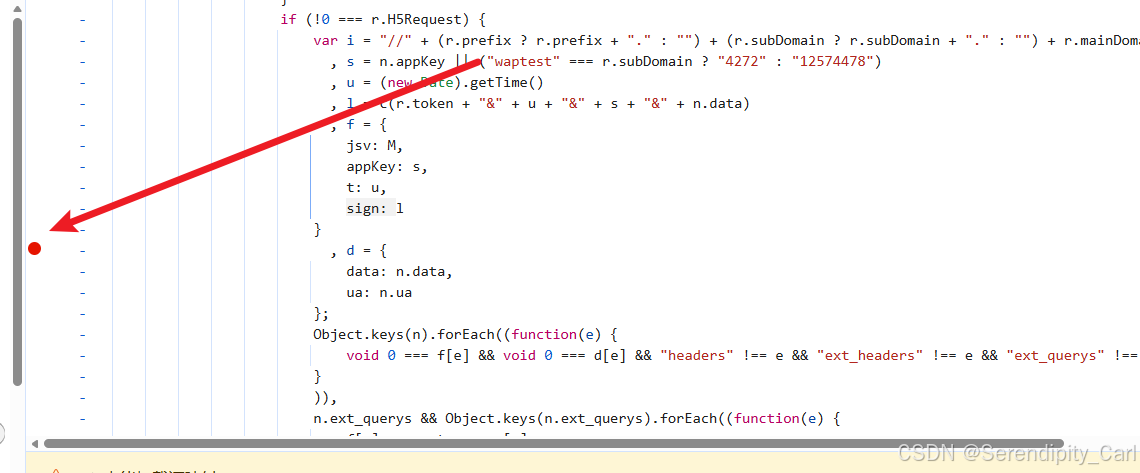
然后刷新当前页面 看程序停留在哪个位置就是数据的加密位置
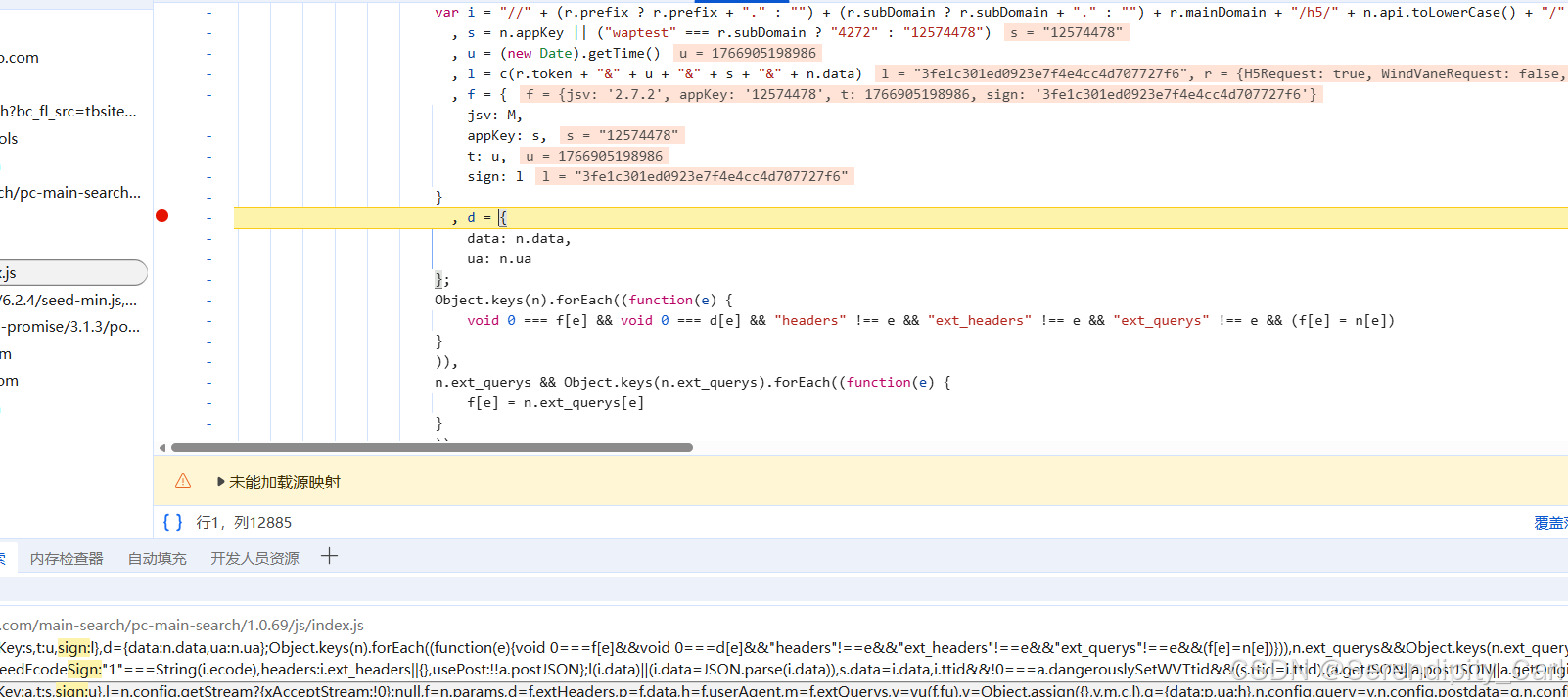
注意此时我们要找符合之前我们找到数据返回的那个接口 是V2.0的
将现在的断点过掉 直到出现V2.0的接口

OK 此时我们查看加密的位置 分析参数
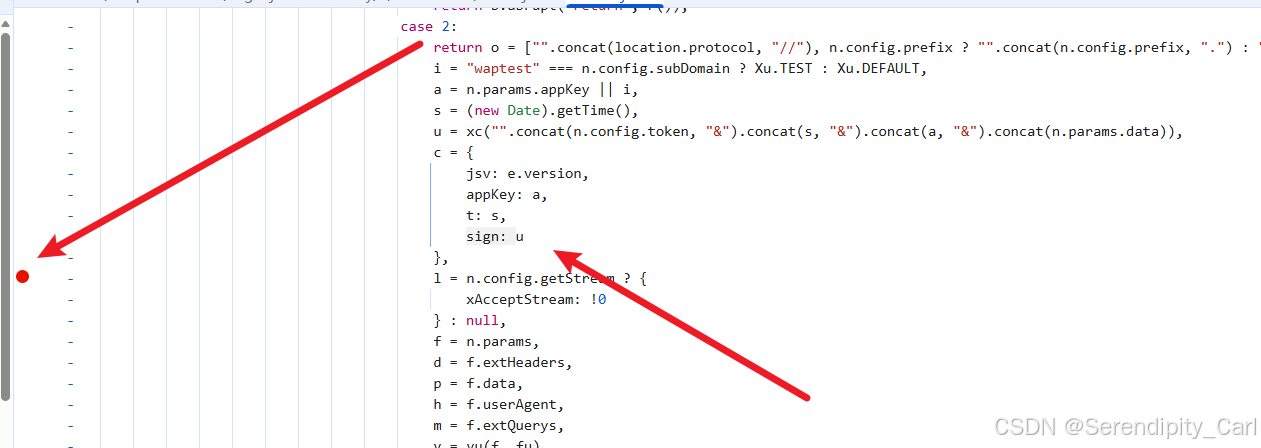
通过分析JavaScript代码,我们发现sign的生成逻辑:
从代码可以看出sign的计算方式:
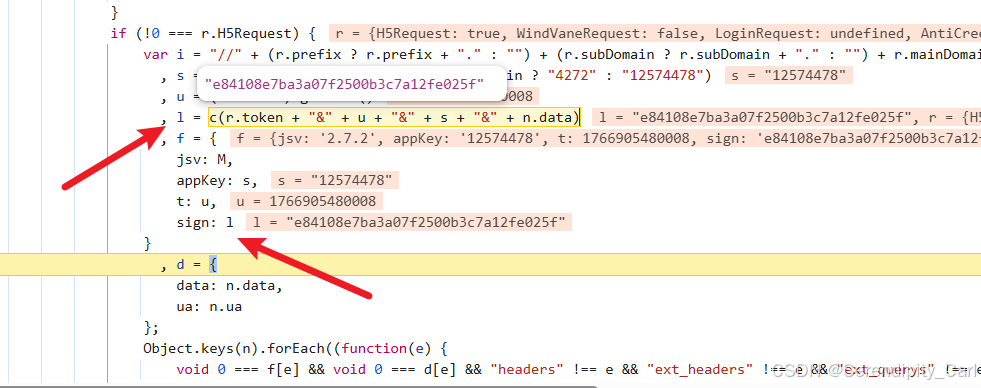
c是个函数 里面传入的是参数 最终构建成一串字符串 通过这个函数生成加密的sign值
可以将里面的参数复制到控制台输出打印看看是什么 或者鼠标选中 上面会显示
第一个c.token 截取了一段token值 前面有说 后续通过正则 提取即可
u是时间戳
s看上面一行 三元运算符 是固定的 直接拿过来即可
n.data 就是这个接口请求携带的参数里面的 后续拿到即可
最后我们看这个加密参数的长度 是32位 大概率是md5加密算法 或者点进这个函数中查看源码
还有就是传入123456 看返回的值是否是 e10a......83e
这里以经确认是md5加密 后续通过第三方库实现 加密函数 hashilib
2. Python实现Sign计算
python
def get_sign():
"""生成淘宝请求所需的sign签名"""
# 获取当前时间戳(毫秒级)
time_temp = int(time.time() * 1000)
# 固定appKey,淘宝PC端通常使用12574478
s = "12574478"
# 从cookie中提取token(_m_h5_tk字段下划线前的部分)
u = re.findall(r'(.*?)_', cookies['_m_h5_tk'])[0]
# 构建签名字符串:token + "&" + 时间戳 + "&" + appKey + "&" + 请求数据
# 转换成字符串类型 相加
sign_str = u + "&" + str(time_temp) + "&" + s + "&" + ddd
# MD5加密生成sign 导包 传入参数 要加密的格式 哈希计算
final_sign = hashlib.md5(sign_str.encode('utf-8')).hexdigest()
return time_temp, final_sign关键点说明:
-
时间戳精度:必须使用毫秒级时间戳
-
token提取:从
_m_h5_tkCookie中提取下划线前的部分 -
字符串顺序:必须严格按照
token×tamp&appKey&data的顺序拼接 -
MD5加密:对拼接后的字符串进行MD5计算,得到32位小写十六进制字符串
五、请求参数构造详解
1. 基础参数设置
python
def get_content(time_temp, final_sign):
"""发送请求获取商品数据"""
url = "https://h5api.m.taobao.com/h5/mtop.relationrecommend.wirelessrecommend.recommend/2.0/"
params = {
"jsv": "2.7.2", # JavaScript版本
"appKey": "12574478", # 应用密钥
"t": f"{time_temp}", # 时间戳
"sign": f"{final_sign}", # 签名
"api": "mtop.relationrecommend.wirelessrecommend.recommend", # API接口
"v": "2.0", # API版本
"type": "jsonp", # 返回类型
"dataType": "jsonp", # 数据类型
"callback": "mtopjsonp20", # JSONP回调函数名
"data": f'{ddd}' # 请求数据
}2. 请求数据(data)格式分析
data参数是一个嵌套的JSON字符串,结构复杂:
我这里写的是变量 之后实现分页的采集
python
ddd = f'''
{{
"appId":"43356",
"params":"{{
\\"device\\":\\"HMA-AL00\\",
\\"page\\":\\"{i}\\",
\\"n\\":48,
\\"q\\":\\"%E5%86%85%E5%AD%98%E6%9D%A1\\",
\\"pageSize\\":48,
\\"totalPage\\":100,
\\"totalResults\\":{page},
... # 其他参数
}}"
}}
'''参数说明:
-
appId:应用ID,固定为43356 -
device:设备型号,模拟华为手机 -
page:当前页码 -
q:搜索关键词(URL编码),示例为"内存条" 可以使用urllib -
pageSize:每页商品数量 -
totalResults:总结果数,动态更新
六、数据处理与解析
1. 响应数据提取
淘宝返回的是JSONP格式数据,需要提取JSON部分:
python
# 发送请求
response = requests.get(url, headers=headers, cookies=cookies, params=params)
# 使用正则提取JSON数据(去除JSONP包装)
# 响应格式:mtopjsonp20({...json数据...})
content = re.findall(r' mtopjsonp20\((.*)\)', response.text)[0]
# 转换为Python字典
json_data = json.loads(content)2. 商品信息解析
从响应数据中提取关键商品信息:

拿到数据之后需要对数据做一些处理 比如删除这个title里面的span标签 后续用字符串的替换
有的数据没有城市名只有省份 需要做个判断
python
# 获取商品列表
data = json_data['data']['itemsArray']
# 获取总结果数(用于动态更新totalResults)
# 和分页的参数有关
page_number = json_data['data']['mainInfo']['totalResults']
all_data = []
for item in data:
try:
# 清理商品标题中的HTML标签
title = item['title'].replace('<span class=H>', '').replace('</span>', '')
# 价格信息
price = item['price']
# 处理地理位置信息
if ' ' in item['procity']:
province = item['procity'].split(' ')[0]
city = item['procity'].split(' ')[1]
else:
province = item['procity']
city = '未知'
# 销量数据
purchase_number = item['realSales']
# 店铺信息
shop_name = item['shopInfo']['title']
# 商品ID
item_id = item['item_id']
# 图片链接
img_url = item['pic_path']
# 存储到字典中
dit = {
'title': title,
'price': price,
'province': province,
'city': city,
'purchase_number': purchase_number,
'shop_name': shop_name,
'item_id': item_id,
'img_url': img_url
}
# 将字典数据添加到列表中
all_data.append(dit)
except Exception as e:
print(f"解析商品信息出错: {e}")
continue七、完整爬虫实现
1. 主程序逻辑
python
if __name__ == '__main__':
page = 4800 # 初始总结果数
lis = [] # 存储所有商品数据
# 循环抓取多页数据
for i in range(1, 16): # 抓取1-15页
# 构造请求数据,动态更新页码和总结果数
ddd = f'''{{"appId":"43356","params":"{{\\"device\\":\\"HMA-AL00\\",\\"page\\":\\"{i}\\",\\"n\\":48,\\"q\\":\\"%E5%86%85%E5%AD%98%E6%9D%A1\\",\\"pageSize\\":48,\\"totalPage\\":100,\\"totalResults\\":{page},\\"sort\\":\\"_coefp\\"}}"}}'''
# 生成签名
timestamp, sign = get_sign()
# 获取数据
total_results, page_data = get_content(timestamp, sign)
# 更新总结果数
page = total_results
# 合并数据
lis += page_data
# 防止请求过快
time.sleep(1)
# 保存到Excel
pd.DataFrame(lis).to_excel('内存条.xlsx', index=False)
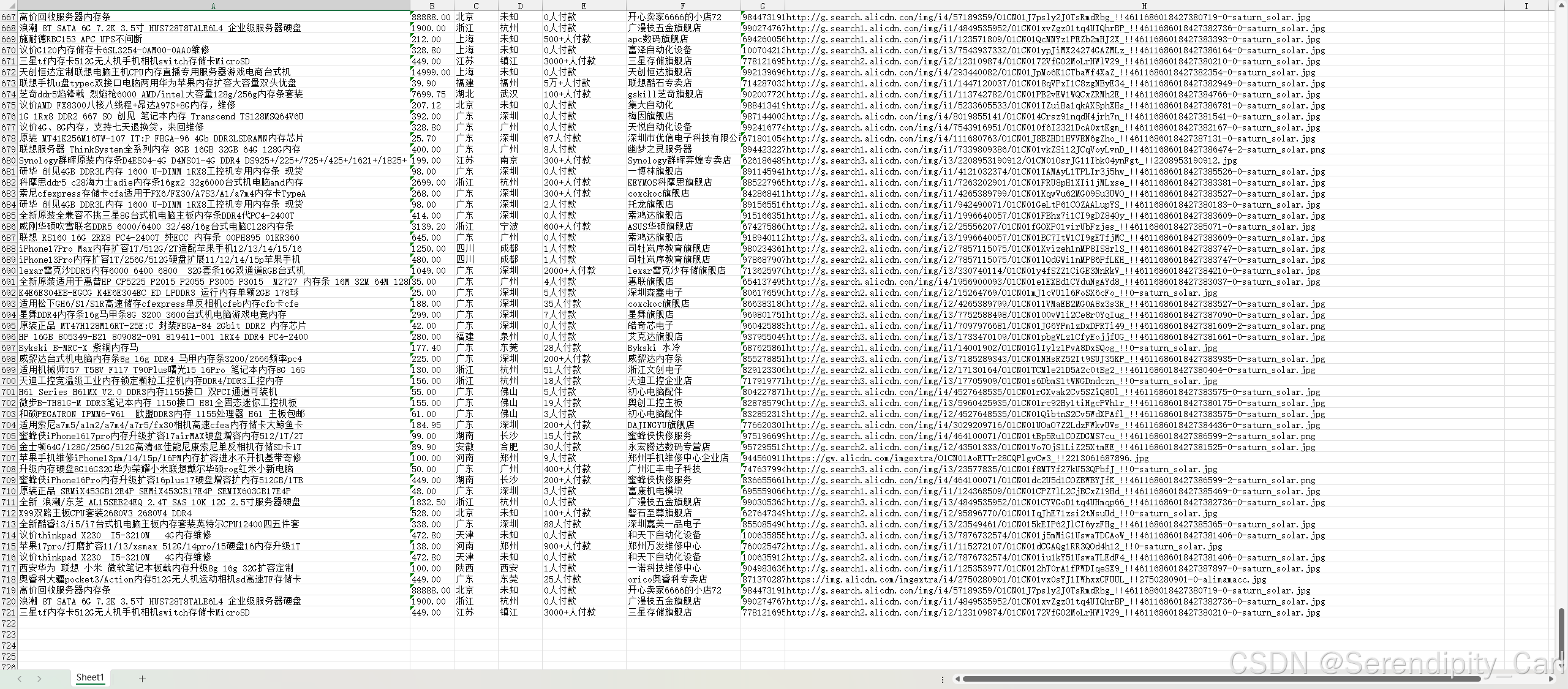
print(f"数据抓取完成,共{len(lis)}条记录")2. 运行结果
九、完整代码
以下是本次案例的源代码 我的代码还需要很多的优化 需自己更新cookie
python
import pandas as pd
import requests
import re
import json
import time
import re, hashlib
headers = {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6", # 语言偏好
"cache-control": "no-cache", # 禁用缓存
"pragma": "no-cache",
"referer": "https://uland.taobao.com/sem/tbsearch?bc_fl_src=tbsite_T9W2LtnM&channelSrp=bingSomama&clk1=deb957ee18d4bfbfb1bb73b64ce0cf9e&commend=all&ie=utf8&initiative_id=tbindexz_20170306&keyword=%E9%92%88%E7%BB%87%E5%B8%BD%E7%94%B7&localImgKey=&msclkid=e19204980fde19ef77af6dc8c844be77&page=1&preLoadOrigin=https%3A%2F%2Fwww.taobao.com&q=%E9%92%88%E7%BB%87%E5%B8%BD%E7%94%B7&refpid=mm_2898300158_3078300397_115665800437&search_type=item&sourceId=tb.index&spm=tbpc.pc_sem_alimama%2Fa.search_manual.0&ssid=s5-e&tab=all",
"sec-ch-ua": "\"Microsoft Edge\";v=\"143\", \"Chromium\";v=\"143\", \"Not A(Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "script",
"sec-fetch-mode": "no-cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36 Edg/143.0.0.0"
}
cookies = {
# 用户会话标识
"cookie2": "1e61048cce806ae369596766e305f384",
"t": "0b06444da070067d7a5fb8dbd19e0a5b",
"_tb_token_": "4f93933383b1",
"thw": "cn",
"xlly_s": "1",
"_samesite_flag_": "true",
"3PcFlag": "1766904851330",
"wk_cookie2": "12514281f2a259d69f093abd4604b2b5",
"wk_unb": "UUpgRsRuesoID0DB4A%3D%3D",
"sdkSilent": "1766933700074",
"havana_sdkSilent": "1766933700074",
"sgcookie": "E100h0lY%2FAMtbG9Vmpe5tWRjllVcES7n68c3Xea5HfsbSFYT1xaA9M%2Brn92sPLNNzBomBeG7MFLoCOPot%2BQ0n33FaqrEEP90MEi5iSu4K%2FCMxdE%3D",
"mt": "ci=0_0",
"tracknick": "",
"cna": "nBXYIVO+EwwCAd7wtILSvXUH",
"mtop_partitioned_detect": "1",
# tooken+时间戳
"_m_h5_tk": "daf111231dd543b04d94caa5fb6d3bbe_1766982105727",
# 加密cookie
"_m_h5_tk_enc": "26900b8c4d72144bafdc8092cf9dfab6",
# 反爬token
"tfstk": "gaYjexYhI-2XdGhxB-lzFEWUqZ_sTbuEG519tCU46ZQYWf9wUFSOQmv1fdJlXE72gL69LL6Y7cX45NO6IdJ6sjfOBdp1Qnor8IAcSNHeC2uei5ZFG-TfWRRRo1PqvTKi8IA0wSwtT33E5ayM5rEOBdQRe1f1WSCODb_Ri1bTkGUY28Bl6NQODsCJw6CbksQO6bORE1QTDdIxNaBl6NB9BNHGa41rMTAjTvAdo127bIW7WPL5wAXpGR4RsU1bvtdAFvH6PPIfpIB75xI7aXX1EeHrVQveDK5kC2M5JHvW5MQslJfX2B_R3w3bi9LV1B-6OvwNZnpXyGTrsmAW5tspkgNjMI_O6dI6qvaFGZ-5AEtms8dvLttdoCPI3QsBVMfR25ZAuHReSMLxlJXPx195YnMQlpIytyWIYdE_NM41N9lSNlqG3Pv-_h-ar0IAZ_yENbZe_J4T7ohSN-r1D_fr_bG7YB5..",
"isg": "BOnpzBe-pElXHpj8PCz3vL7f-JVDtt3odVZQ6IveZVAPUglk0wbtuNdEEPbkSnUg"
}
def get_sign():
time_temp = int(time.time() * 1000)
s = "12574478"
u = re.findall(r'(.*?)_', cookies['_m_h5_tk'])[0]
# r.token + "&" + u + "&" + s + "&" + n.data
sign_str = u + "&" + str(time_temp) + "&" + s + "&" + ddd
final_sign = hashlib.md5(sign_str.encode('utf-8')).hexdigest()
return time_temp, final_sign
def get_content(time_temp, final_sign):
url = "https://h5api.m.taobao.com/h5/mtop.relationrecommend.wirelessrecommend.recommend/2.0/"
params = {
"jsv": "2.7.2",
"appKey": "12574478",
"t": f"{time_temp}",
"sign": f"{final_sign}",
"api": "mtop.relationrecommend.wirelessrecommend.recommend",
"v": "2.0",
"type": "jsonp",
"dataType": "jsonp",
"callback": "mtopjsonp20",
"data": f'{ddd}'
}
response = requests.get(url, headers=headers, cookies=cookies, params=params)
# 采用正则将响应数据进行提取 符合json格式的数据 使用\转义调括号
# re.findall() 这个方法会找到所有符合正则表达式的内容 返回一个列表
content = re.findall(r' mtopjsonp20\((.*)\)', response.text)[0]
# 现在我们转换成json格式的数据
json_data = json.loads(content)
# 后面就是通过键值对取值了
data = json_data['data']['itemsArray']
page_number = json_data['data']['mainInfo']['totalResults']
all_data = []
for i in data:
try:
title = i['title'].replace('<span class=H>', '').replace('</span>', '')
price = i['price']
if ' ' in i['procity']:
province = i['procity'].split(' ')[0]
city = i['procity'].split(' ')[1]
else:
province = i['procity']
city = '未知'
purchase_number = i['realSales']
shop_name = i['shopInfo']['title']
item_id = i['item_id']
img_url = i['pic_path']
dit = {
'title': title,
'price': price,
'province': province,
'city': city,
'purchase_number': purchase_number,
'shop_name': shop_name,
'item_id': item_id,
'img_url': img_url
}
all_data.append(dit)
except Exception as e:
print(e)
pass
return page_number, all_data
if __name__ == '__main__':
page = 4800
lis = []
for i in range(1, 16):
ddd = f'{{"appId":"43356","params":"{{\\"device\\":\\"HMA-AL00\\",\\"isBeta\\":\\"false\\",\\"grayHair\\":\\"false\\",\\"from\\":\\"nt_history\\",\\"brand\\":\\"HUAWEI\\",\\"info\\":\\"wifi\\",\\"index\\":\\"4\\",\\"rainbow\\":\\"\\",\\"schemaType\\":\\"auction\\",\\"elderHome\\":\\"false\\",\\"isEnterSrpSearch\\":\\"true\\",\\"newSearch\\":\\"false\\",\\"network\\":\\"wifi\\",\\"subtype\\":\\"\\",\\"hasPreposeFilter\\":\\"false\\",\\"prepositionVersion\\":\\"v2\\",\\"client_os\\":\\"Android\\",\\"gpsEnabled\\":\\"false\\",\\"searchDoorFrom\\":\\"srp\\",\\"debug_rerankNewOpenCard\\":\\"false\\",\\"homePageVersion\\":\\"v7\\",\\"searchElderHomeOpen\\":\\"false\\",\\"search_action\\":\\"initiative\\",\\"sugg\\":\\"_4_1\\",\\"sversion\\":\\"13.6\\",\\"style\\":\\"list\\",\\"ttid\\":\\"600000@taobao_pc_10.7.0\\",\\"needTabs\\":\\"true\\",\\"areaCode\\":\\"CN\\",\\"vm\\":\\"nw\\",\\"countryNum\\":\\"156\\",\\"m\\":\\"pc_sem\\",\\"page\\":\\"{i}\\",\\"n\\":48,\\"q\\":\\"%E5%86%85%E5%AD%98%E6%9D%A1\\",\\"qSource\\":\\"url\\",\\"pageSource\\":\\"tbpc.pc_sem_alimama/a.search_manual.0\\",\\"tab\\":\\"all\\",\\"pageSize\\":48,\\"totalPage\\":100,\\"totalResults\\":{page},\\"sourceS\\":\\"0\\",\\"sort\\":\\"_coefp\\",\\"bcoffset\\":\\"\\",\\"ntoffset\\":\\"\\",\\"filterTag\\":\\"\\",\\"service\\":\\"\\",\\"prop\\":\\"\\",\\"loc\\":\\"\\",\\"start_price\\":null,\\"end_price\\":null,\\"startPrice\\":null,\\"endPrice\\":null,\\"itemIds\\":null,\\"p4pIds\\":null,\\"categoryp\\":\\"\\",\\"myCNA\\":\\"nBXYIVO+EwwCAd7wtILSvXUH\\",\\"clk1\\":\\"deb957ee18d4bfbfb1bb73b64ce0cf9e\\",\\"refpid\\":\\"mm_2898300158_3078300397_115665800437\\"}}"}}'
a, b = get_sign()
number, all_data = get_content(a, b)
page = number
lis += all_data
pd.DataFrame(lis).to_excel('内存条.xlsx', index=False)八、常见问题与解决方案
1. Cookie失效问题
症状 :返回"非法请求"或"签名错误"
解决方案:
-
重新登录淘宝账号获取新Cookie
-
检查
_m_h5_tk和_m_h5_tk_enc是否匹配 -
确保Cookie中的所有字段完整
2. Sign验证失败
症状 :返回"签名验证失败"
解决方案:
-
检查token提取是否正确(
_m_h5_tk下划线前的部分) -
验证时间戳是否为毫秒级
-
确认字符串拼接顺序:token×tamp&appKey&data
-
检查data参数是否与生成sign时使用的完全一致
3. 请求频率限制
症状:IP被限制访问
解决方案:
-
添加随机延迟:
time.sleep(random.uniform(1, 3)) -
使用代理IP池
-
降低请求频率,模拟真实用户行为
十、总结
本次淘宝商品数据爬取实战涉及多个关键技术点:
-
签名机制突破:理解并实现了淘宝的sign签名算法
-
Cookie管理:处理多个加密Cookie字段的获取与维护
-
参数构造:正确构造包含嵌套JSON的请求参数
-
数据解析:从JSONP响应中提取并清洗商品信息
-
反爬策略:通过合理的延迟和错误处理避免被封
重要提示:
-
本代码仅供学习交流使用
-
请遵守淘宝的robots.txt协议
-
不要用于商业用途或大规模抓取
-
尊重数据所有者的合法权益
通过掌握这些技术,你不仅可以爬取淘宝数据,还可以将类似的方法应用到其他有签名验证的电商平台。记住,爬虫技术的核心是理解目标网站的工作原理,而不是盲目地复制代码
技术发展的同时,请务必遵守法律法规和道德规范!