目录
[XPath 是什么?](#XPath 是什么?)
[XPath 基础语法:从 "找节点" 开始](#XPath 基础语法:从 “找节点” 开始)
[1. 选取节点的基本表达式](#1. 选取节点的基本表达式)
[2. 带条件的节点选取(属性匹配)](#2. 带条件的节点选取(属性匹配))
[3. 实战:用 XPath 定位百度热搜条目](#3. 实战:用 XPath 定位百度热搜条目)
[XPath vs CSS Selector:为什么自动化要学两种定位方式?](#XPath vs CSS Selector:为什么自动化要学两种定位方式?)
[XPath 的学习建议](#XPath 的学习建议)
元素定位
cssSelector
在 Web 自动化测试中,操作页面前必须先定位到目标元素------ 这是自动化的核心逻辑。而定位元素后,我们需要根据 "找一个元素" 或 "找多个元素" 的场景,选择对应的查找方法。
元素查找的两个核心方法
在 Python+Selenium 的自动化脚本中,元素查找主要依赖两个方法:
-
find_element(定位方式, "元素表达式")- 作用:查找单个元素(若匹配到多个元素,仅返回第一个);
- 适用场景:目标元素在页面中唯一(如百度的搜索框、"百度一下" 按钮)。
-
find_elements(定位方式, "元素表达式")- 作用:查找多个元素(返回所有匹配的元素列表);
- 适用场景:页面中存在多个相同特征的元素(如百度热搜的多条条目)。
find_element:定位单个元素(以百度搜索为例)
以 "打开百度→输入关键词→点击搜索" 的自动化流程为例,演示find_element的使用:

1. 操作步骤与代码实现
python
# 1. 驱动管理与浏览器初始化
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
import time
# 自动安装Chrome驱动并创建浏览器对象
chrome_service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=chrome_service)
time.sleep(2)
# 2. 访问百度首页(注意:网址需带完整协议头"https://")
driver.get("https://www.baidu.com")
time.sleep(2)
# 3. 定位搜索框(通过CSS选择器定位,#kw对应搜索框的id属性)
driver.find_element(By.CSS_SELECTOR, "#kw").send_keys("迪丽热巴")
time.sleep(2)
# 4. 定位"百度一下"按钮(通过CSS选择器定位,#su对应按钮的id属性)
driver.find_element(By.CSS_SELECTOR, "#su").click()
time.sleep(2)
# 5. 关闭浏览器
driver.quit()2. 定位逻辑说明
- 百度搜索框的 HTML 属性为
id="kw",因此用 CSS 选择器#kw即可唯一定位; - "百度一下" 按钮的 HTML 属性为
id="su",同理用#su定位(CSS 选择器中#代表匹配id)。
find_elements:定位多个元素(以百度热搜为例)
百度首页的 "百度热搜" 区域包含多条条目,这些条目具有相同的元素特征,需用find_elements批量定位。
如图所示在百度热搜中存在多个相同元素

在浏览器控制页面CTRL+shift+i进行选择器的查找工作显示该元素在当前页面一共存在六处,我们想要进行查找此时需要用到find_elements。
1. 元素特征与定位方式
在浏览器控制台(按Ctrl+Shift+I打开)中,可看到百度热搜条目的 CSS 选择器为#hotsearch-content-wrapper > li,且该选择器匹配6 个元素(对应 6 条热搜)。
2. 代码实现与效果
python
# 1. 初始化浏览器(步骤同前)
chrome_service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=chrome_service)
driver.get("https://www.baidu.com")
time.sleep(2)
# 2. 定位所有热搜条目(返回元素列表)
hot_search_list = driver.find_elements(By.CSS_SELECTOR, "#hotsearch-content-wrapper > li")
# 3. 遍历列表,打印每条热搜的文本内容
for item in hot_search_list:
print(item.text) # 输出每条热搜的文字内容
# 4. 关闭浏览器
driver.quit()3. 执行结果
运行代码后,会输出百度热搜的所有条目(如:
 补充:常见元素定位方式
补充:常见元素定位方式
Web 自动化中,元素定位的常用方式有 5 种:
| 定位方式 | 说明 | 示例(CSS 选择器 /xpath) |
|---|---|---|
| id | 匹配元素的id属性(唯一) |
#kw(CSS)///*[@id="kw"](xpath) |
| classname | 匹配元素的class属性 |
.s_ipt(CSS)///*[@class="s_ipt"](xpath) |
| tagname | 匹配 HTML 标签名 | input(CSS)///input(xpath) |
| cssSelector | CSS 选择器(灵活通用) | #hotsearch-content-wrapper > li |
| xpath | 路径表达式(适配复杂场景) | //div[@class="hotsearch-item"] |
其中,cssSelector 和 xpath 是实际自动化中最常用的定位方式(适配绝大多数元素场景)。
xpath
在 Web 自动化测试中,XPath 是最灵活的元素定位方式之一 ------ 它不仅能通过id/class定位元素,还能基于元素的层级、属性、文本等复杂特征精准匹配,甚至可以在 HTML 结构动态变化时 "灵活应变"。今天我们就从 XPath 的基础语法入手,结合实战案例聊聊它的使用逻辑。
XPath 是什么?
XPath(XML Path Language)原本是用于在 XML 文档中查找节点的语言,但在 Web 自动化中,我们可以把 HTML 页面当作 "类 XML 结构",用 XPath 定位页面元素。
它的核心优势是不受限于元素的id/class:哪怕元素没有唯一标识,只要能描述它在页面中的 "位置" 或 "特征",就能用 XPath 找到它。
XPath 基础语法:从 "找节点" 开始
XPath 的语法围绕 "节点关系" 展开,我们先从最基础的节点定位学起:
1. 选取节点的基本表达式
| 表达式 | 说明 | 示例 |
|---|---|---|
nodename |
选取该节点的所有子节点 | //div:选取页面中所有div标签 |
/ |
从根节点开始选取(绝对路径) | /html/body/div:从html根节点找body下的div |
// |
从任意位置选取(相对路径,最常用) | //input:选取页面中所有input标签 |
. |
选取当前节点 | ./li:选取当前节点下的li标签 |
.. |
选取当前节点的父节点 | //input/..:选取input的父节点 |
2. 带条件的节点选取(属性匹配)
实际自动化中,我们通常会给 XPath 加 "条件",精准定位目标元素:
- 匹配
id属性://*[@id="kw"](选取id="kw"的任意标签,对应百度搜索框) - 匹配
class属性://*[@class="s_ipt"](选取class="s_ipt"的任意标签) - 匹配其他属性:
//input[@type="submit"](选取type="submit"的input标签)
3. 实战:用 XPath 定位百度热搜条目
以百度热搜为例,假设我们要定位 "热搜列表中的第 3 个条目",可以这样写 XPath:
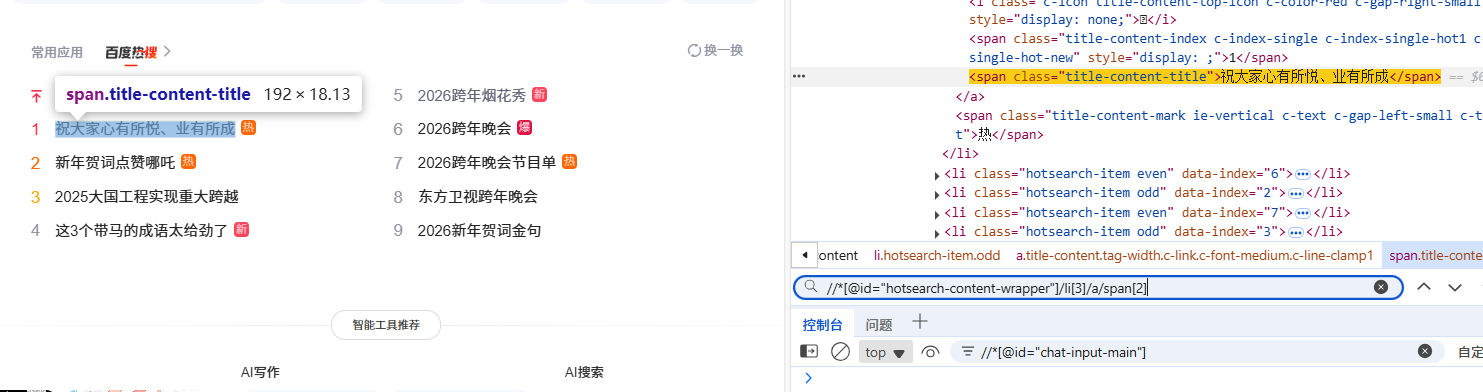
//div[@id="hotsearch-content-wrapper"]/li[3]//div[@id="hotsearch-content-wrapper"]:先找到热搜列表的父容器(id唯一)/li[3]:选取该容器下的第 3 个li标签(对应第 3 条热搜)
XPath vs CSS Selector:为什么自动化要学两种定位方式?
很多同学会问:已经学了 CSS 选择器,为什么还要学 XPath?
其实两者各有优势:
- CSS 选择器 :语法更简洁,执行效率更高(适合简单场景),比如定位
id用#kw、定位class用.s_ipt; - XPath :支持文本匹配 (
//*[text()="百度一下"])、模糊匹配 (//*[contains(@class, "btn")]),还能定位父节点 / 兄弟节点(CSS 做不到)。
举个例子:如果要定位 "文本为'百度一下'的按钮",XPath 可以直接写:
//*[text()="百度一下"]而 CSS 选择器无法直接匹配元素文本,必须结合其他属性。
XPath 的学习建议
- 先掌握基础语法:从 "绝对路径 / 相对路径""属性匹配" 开始,熟练后再学文本匹配、模糊匹配;
- 结合浏览器工具:在 Chrome 开发者工具的 "Elements" 面板中,右键元素→"Copy"→"Copy XPath",可以快速生成基础 XPath(但注意:自动生成的 XPath 可能冗余,需要手动优化);
- 灵活搭配 CSS 选择器:简单场景用 CSS(高效),复杂场景用 XPath(灵活),两者结合覆盖 99% 的定位需求。
最后提醒:无论用哪种定位方式,优先选 "稳定的特征" (比如id、唯一属性),避免依赖 "页面层级"(比如/html/body/div[2]/div[3])------ 因为页面结构一旦变化,这类定位就会失效。