一.分类
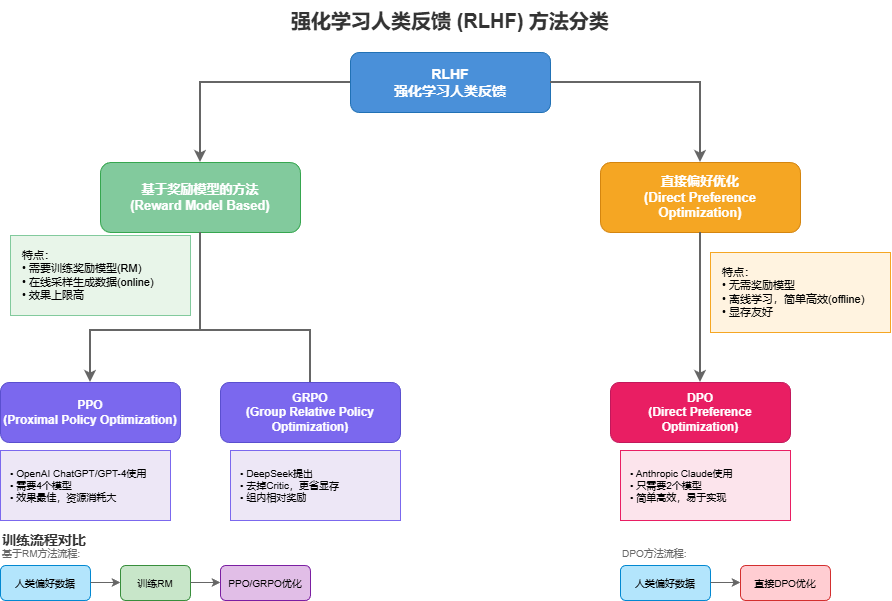
Reward Model Based方法:
- PPO, TRPO, GRPO, A2C等
- 需要每次用当前模型重新生成输出
- 然后基于生成结果更新模型
Direct Preference Optimization方法 (偏好式):
- DPO, IPO, KTO等
- 直接从偏好数据学习
- 不需要重新生成
混合方法:
- Constitutional AI等
二.Reward Model Based
PPO:TRPO的优化,CLIP截断梯度策略替代KL散度
KL散度:
计算公式:
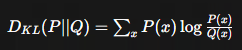

kl越小说明两个策略越接近
TRPO目标:更新策略时,新策略不能和旧策略差太多
实际计算过程:
在KL散度不超过δ的前提下,找到让目标函数最大的参数更新
三种理解方式
python
# 伪代码
1. 计算策略梯度方向 g
2. 计算Fisher信息矩阵 F(KL散度的二阶近似)
3. 用共轭梯度法求解:F * step = g
4. 计算最大步长 α,使得 KL ≤ δ
5. 更新:θ_new = θ_old + α * stepClip截断梯度替代KL
python
# 伪代码
def clip(ratio, lower, upper):
if ratio < lower:
return lower # 太小了,裁剪到下界
elif ratio > upper:
return upper # 太大了,裁剪到上界
else:
return ratio # 在范围内,保持不变PPO每步更新很小,但通过K轮迭代累积,不同的动作各自逼近自己的clip边界,最终实现了和TRPO类似的稳定训练效果,而实现只需要一个简单的clamp操作。
标准PPO: 2 模型 + 3 loss 游戏RL:环境自带reward
RLHF PPO: 4模型 + 2loss
trl框架ppo源码:https://github.com/huggingface/trl/blob/main/trl/experimental/ppo/ppo_trainer.py
verl框架ppo源码:https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py
内容基本一致,但verl框架适合大规模参数模型的训练
标准PPO : loss计算:
python
total_loss = policy_loss + c1 * value_loss - c2 * entropy_loss
# (Actor更新) (Critic更新) (鼓励探索)
# 其中:
policy_loss = -min(ratio × advantage, clip(ratio) × advantage)
value_loss = MSE(critic_output, returns)
entropy_loss = -mean(π * log(π)) # 策略的熵policy_loss
- 重要性采样ratio:ratio = π_new(a|s) / π_old(a|s) ratio > 1: 新策略比老策略更喜欢这个动作
- Clipping机制:防止ratio极端值。clip(ratio, 1-ε, 1+ε) 设定ε = 0.2,那么:
clip(ratio, 0.8, 1.2)
ratio = 100 → 被clip到1.2
ratio = 0.01 → 被clip到0.8
- 完整Loss:policy_loss = -min(ratio × A, clip(ratio, 1-ε, 1+ε) × A)
- 负号:loss最小化,正向A,负数优化越负;负向A,loss要变小-> ratio变小 -> 减小负向A的概率
value_loss
critic的作用学会预测真实的答案,指导A的方向,是防止方差过大,偏离标准实际答案太远,可以认为是加速收敛的
python
# 基础版
returns = advantage + old_critic_output
value_loss = MSE(critic_output, returns)
带Clip版本:
# Clip限制critic输出的变化
critic_output_clipped = clamp(critic_output,
old_critic_output - ε,
old_critic_output + ε)
# 两种loss
loss1 = (critic_output - returns)²
loss2 = (critic_output_clipped - returns)²
# 取更大的
value_loss = 0.5 * max(loss1, loss2)
#取max是为了惩罚Critic的剧烈变化,让它稳步逼近目标,而不是一步到位。entropy_loss 类似于惩罚,保持一定的随机性,防止一直命中一个答案
要最小化loss,因为是 - c2 * entropy_loss ,也就是最大化 entropy_loss ,而entropy_loss 越大代表动作A分布越平均,即随机性也强
python
entropy_loss = -mean(π * log(π))RLHF PPO:
四模型: Actor,Critic,Reward Model,Reference Model
python
loss = policy_loss + 从* value_loss
# Actor(更新) + Critic (更新)Actor 和 Critic 与标准版一致
Reward Model(奖励模型):给回答打分 冻结
python
score = reward_model(response) # 给Actor生成的回答打分Reference model(参考/惩罚模型):提供KL惩罚的锚点,防止Actor跑偏 SFT后的原始模型的拷贝,冻结
python
kl = actor_log_probs - ref_log_probs # Actor和Reference的差异
reward = RM_score - β * kl # KL惩罚融入reward
# β 限制可变化的安全范围
#不参与loss,参与advantage的计算
advantage = GAE(reward, values)不直接参与到loss的变化,但是由于reward结合了reference模型,如果答案偏离太远会导致rewad过小,此时advantage变小/变负,loss不往这个方向优化
GRPO
GRPO = PPO - Critic 采用了组内平均的计算方式,所以不需要Critic模型
python
total_loss = policy_loss + β * kl_loss
# Actor更新 防止偏离Reference
#与ppo的actor一致(A的计算方式不同)
policy_loss = -min(ratio * A, clip(ratio) * A)Reward模型仍旧在外部进行计算,同时参与到A的计算。但是reference model直接参与到loss的计算
本质上与ppo的算法是一致的,通过kl计算sft之后模型的输出与现在模型输出的差距,越大说明差距越大。
三。Direct Preference Optimization方法
DPO
传统的dpo是offline的,但是其实也有很多online的做法
输入本就具备好了打分的内容:
python
{
"prompt": "什么是机器学习?",
"chosen": "机器学习是一种人工智能方法...", # 人类偏好的回答
"rejected": "机器学习就是让机器学习。" # 人类不偏好的回答
}
#loss计算也只有一个 atcor(更新)和reference
# 输入:一批偏好对数据
for batch in dataloader:
prompt = batch["prompt"]
chosen = batch["chosen"]
rejected = batch["rejected"]
# 1. Actor计算log概率
chosen_logps = actor(prompt + chosen)
rejected_logps = actor(prompt + rejected)
# 2. Reference计算log概率(不更新)
with torch.no_grad():
ref_chosen_logps = reference(prompt + chosen)
ref_rejected_logps = reference(prompt + rejected)
# 3. 计算logits
logits = (chosen_logps - rejected_logps) - (ref_chosen_logps - ref_rejected_logps)
# 4. DPO Loss
loss = -F.logsigmoid(beta * logits).mean()
# 5. 更新Actor
loss.backward()
optimizer.step()online版本:https://github.com/volcengine/verl/blob/main/docs/advance/dpo_extension.rst
Online DPO就是在Actor计算logps之前,用RM或规则自动生成(chosen, rejected)对,替代人类标注。后面的DPO Loss计算完全一样。