使用 Table Exporter方法
第一步:
通过在本地终端(请确保你的机器上安装了dx-toolkit)或ttyd终端,执行以下命令,获取包含你数据集中所有可用数据字段的文件:
dx extract_dataset project-xxxx:record-yyyy -ddd --delimiter ","
where project-xxxx:record-yyyy is ID of your Dataset【安装dx-toolkit】打开本地电脑中的Anaconda Prompt
【安装dx-toolkit】在Anaconda Prompt中输入
pip install dxpy系统会进行自动安装。
假如出现类似以下报错:
WARNING: The scripts dx, dx-app-wizard, dx-build-app and dx-build-applet are installed in
'/Users/user-amy/Library/Python/3.9/bin' which is not on PATH.
Consider adding this directory to PATH 说明需要更新电脑的PATH环境变量配置,以包括pip安装新命令的路径(具体解决方案自行百度)。
【CLI登录】在Anaconda Prompt中输入
dx login服务器连接成功后按提示输入RAP的用户名和密码即可
现在输入:
dx extract_dataset project-xxxx:record-yyyy -ddd --delimiter ","注意!
project-xxxx:record-yyyy为你的数据库
例如xxxxx.dataset完成后有三个文件

上述命令将生成3个*.csv文件,其中*.dataset.data_dictionary.csv文件包含所有可用数据字段的完整信息(字段名称位于称为 的第二列name)。
where project-xxxx:record-yyyy is ID of your Dataset【登出/注销CLI】使用完毕养成好习惯需要登出/注销,在Anaconda Prompt中输入:
dx logout第二步:
接下来使用Table Exporter
收集所有感兴趣的数据字段名称,并写入field_name.txt文件。文件应有1列,每行只有1个数据字段名称。上述文件应仅包含同一实体中的数据字段(例如"参与者"、"olink_instance_0"等)。不同实体中的数据字段应写入独立文件。用于的值可以在.dataset.data_dictionary.csv文件的第一列中找到(注:这与entity_dictionary.csv文件中的不同)
注意这一步:
可以在自己电脑上新建txt,
但是!
需要用Visual Studio Code软件将txt转化为unix格式的txt !!!
也可,自行百度查看其他方法windows的txt转unix的txt.
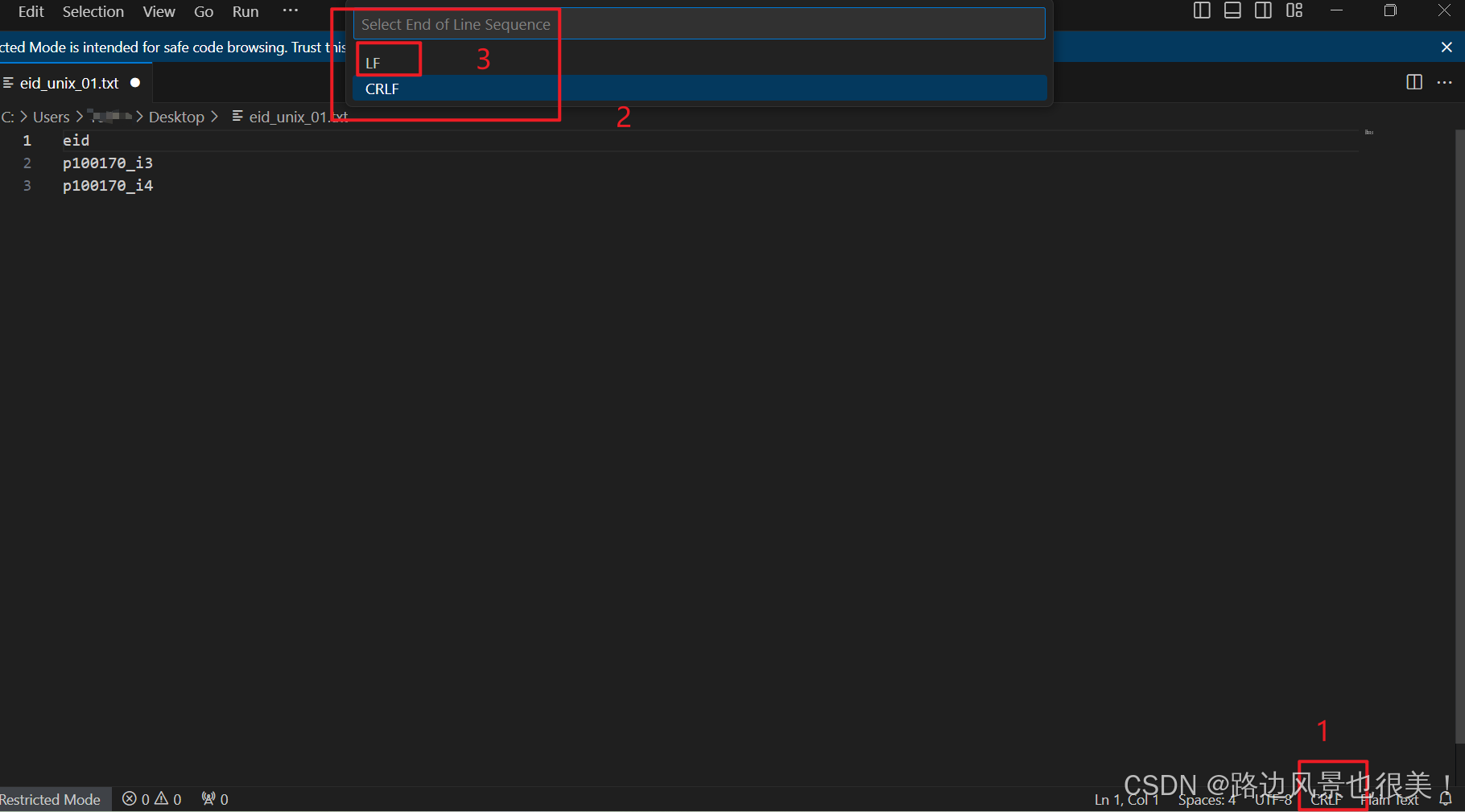
用 VS Code 打开文件
查看右下角状态栏,会显示 "CRLF" 或 "LF"
点击 "CRLF" 或 "LF",选择 "LF"
保存文件
第三步
将field_name.txt文件上传到RAP项目
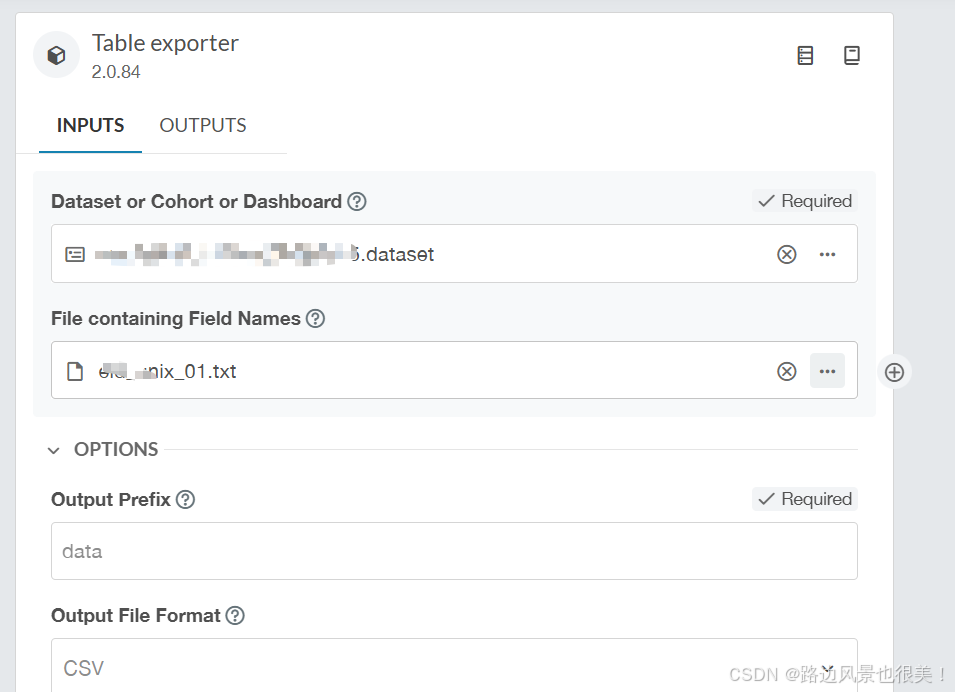
根据需要,
我用这个
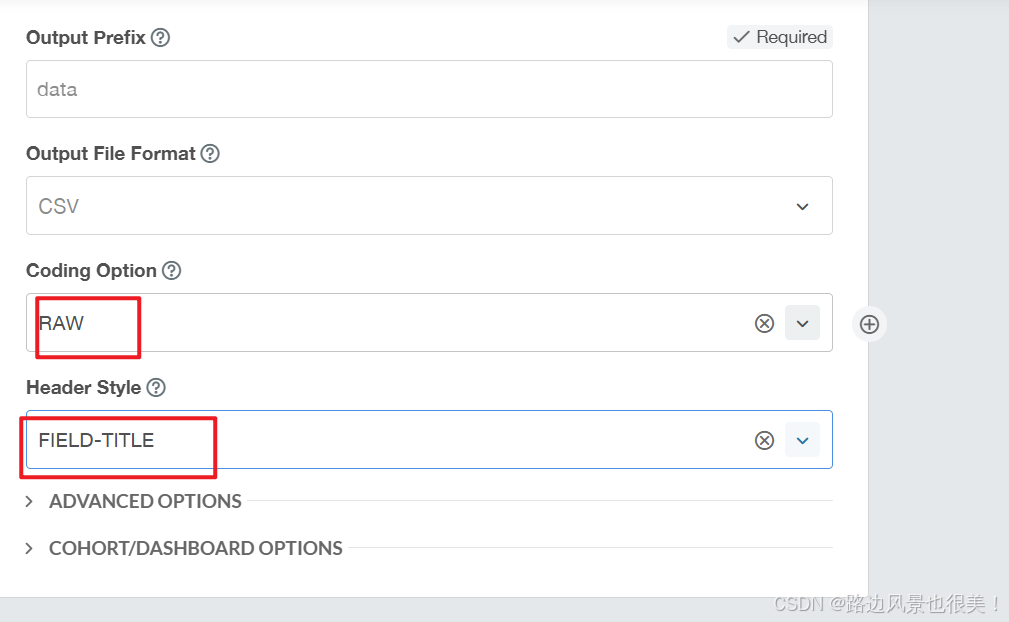
注意:指定实体会快更多!
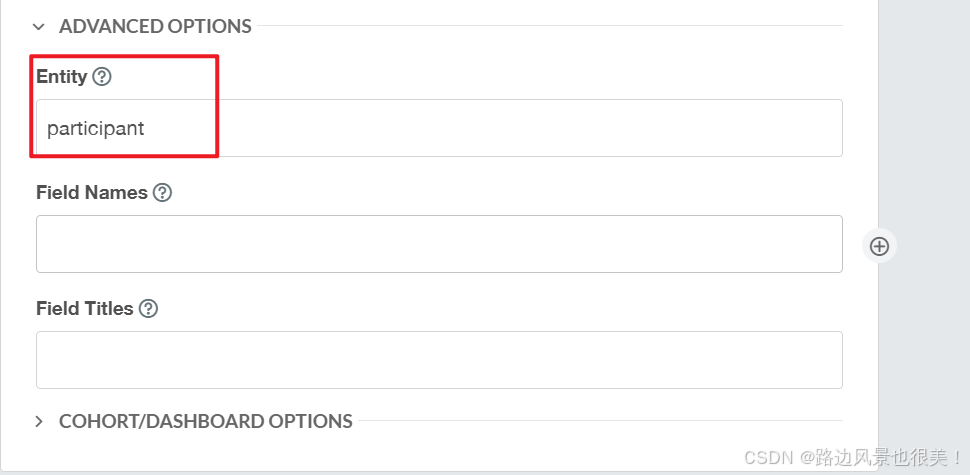


到这个就批量下载完成!
RAP官网下载教程如下:
https://dnanexus.gitbook.io/uk-biobank-rap/working-on-the-research-analysis-platform/accessing-data/accessing-phenotypic-data
https://documentation.dnanexus.com/developer/apps/developing-spark-apps/table-exporter-application可进行进一步参考!