01 隐形的安全漏洞:当敏感数据"穿上马甲"
在数字化转型的当下,绝大多数企业都已经建立了基础的数据安全意识。对于数据库中的核心表(如 t_users),我们通常会对"手机号"、"身份证"、"银行卡号"等字段打上 "PII(个人敏感信息)" 标签,并配置严格的访问控制或静态脱敏策略。
看起来固若金汤?但现实往往是"防不胜防"。
在实际的数据流转和开发过程中,数据从来不是静止的。它会被查询、被重命名、被聚合、被封装。
试想这样一个常见的场景:
-
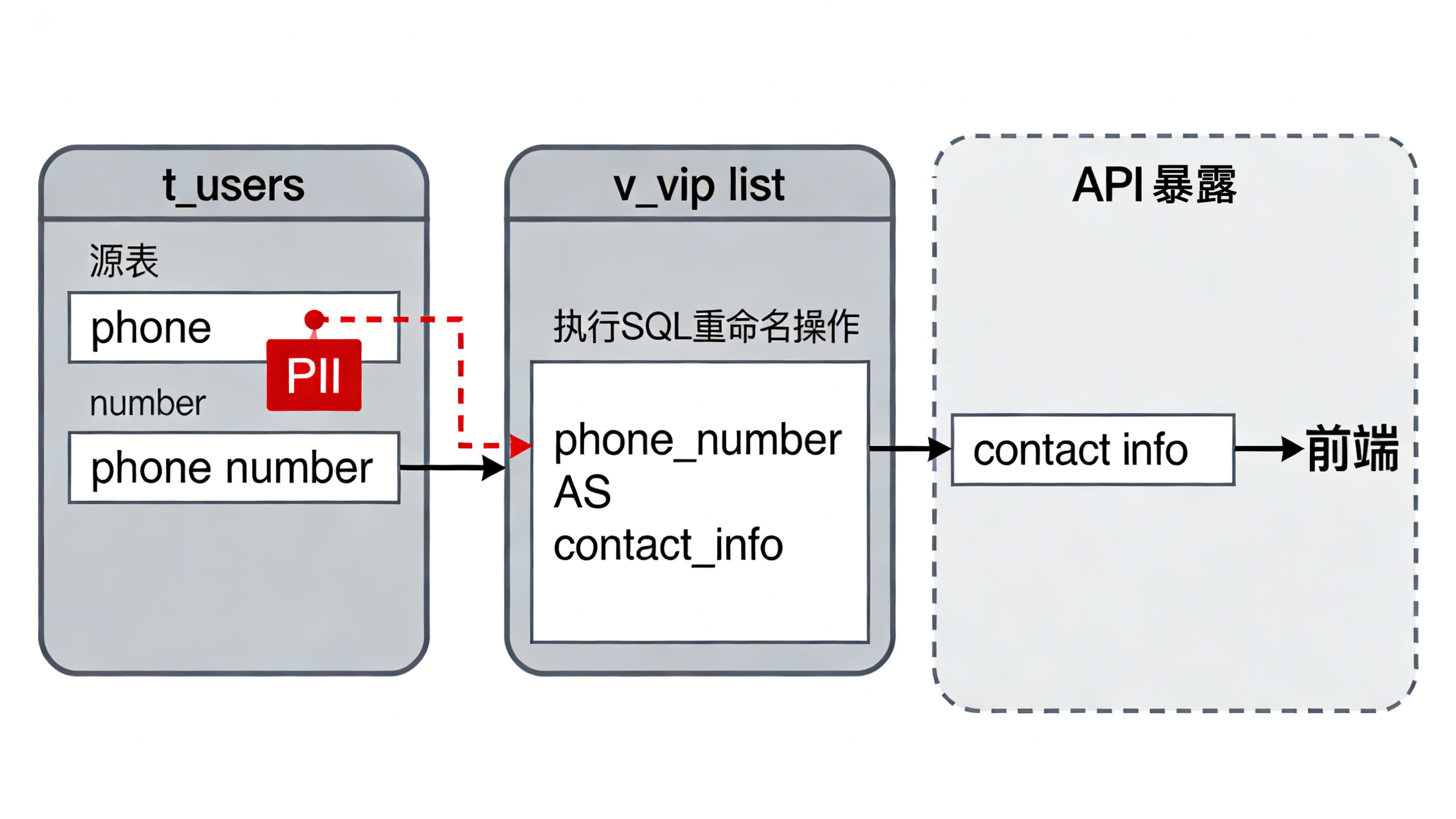
源端: 表
t_users里的phone_number字段被标记为敏感。 -
加工: 业务人员为了方便,创建了一个视图
v_vip_list,执行了 SQL:SELECT phone_number AS contact_info FROM t_users。 -
泄露: 传统的安全策略只盯着
phone_number,却不认识contact_info。结果,这个"穿了马甲"的敏感字段,就这样大摇大摆地绕过了脱敏规则,直接暴露在前端或 API 接口中。
这就是数据治理中的"标签断层"。数据的形态发生了变化,原有的安全属性往往就会丢失。
02 核心解法:基于血缘的"标签自动继承"
要解决这个问题,靠人工去梳理每一个视图、每一个报表是不可能的。我们需要引入"字段级数据血缘" 技术。
血缘不仅仅是用来查看"数据从哪里来",在安全领域,它更重要的作用是实现安全标签的自动继承。
可以概括为:
-
源端定义: 在源头定义
phone为敏感字段。 -
路径解析: 系统通过解析数据加工过程中的 SQL 语句,构建字段之间的依赖关系图。
-
自动打标: 无论数据经过了多少层
AS重命名、CONCAT拼接或JOIN关联,系统顺着血缘关系,自动将下游的所有派生字段(如contact_info,user_mobile)全部打上"敏感"标签。
这种机制确保了安全策略具有动态穿透力,无论数据变形多少次,其"敏感属性"永不丢失。
03 为什么传统的"事后扫描"行不通?
既然血缘这么重要,为什么很多企业的效果依然不理想?核心原因在于架构模式的落后。
传统的数据治理工具大多采用"事后元数据采集"模式------即每天凌晨去扫描一次数据库日志,或者定期抓取元数据。
但在敏捷开发时代,这种模式存在致命缺陷:
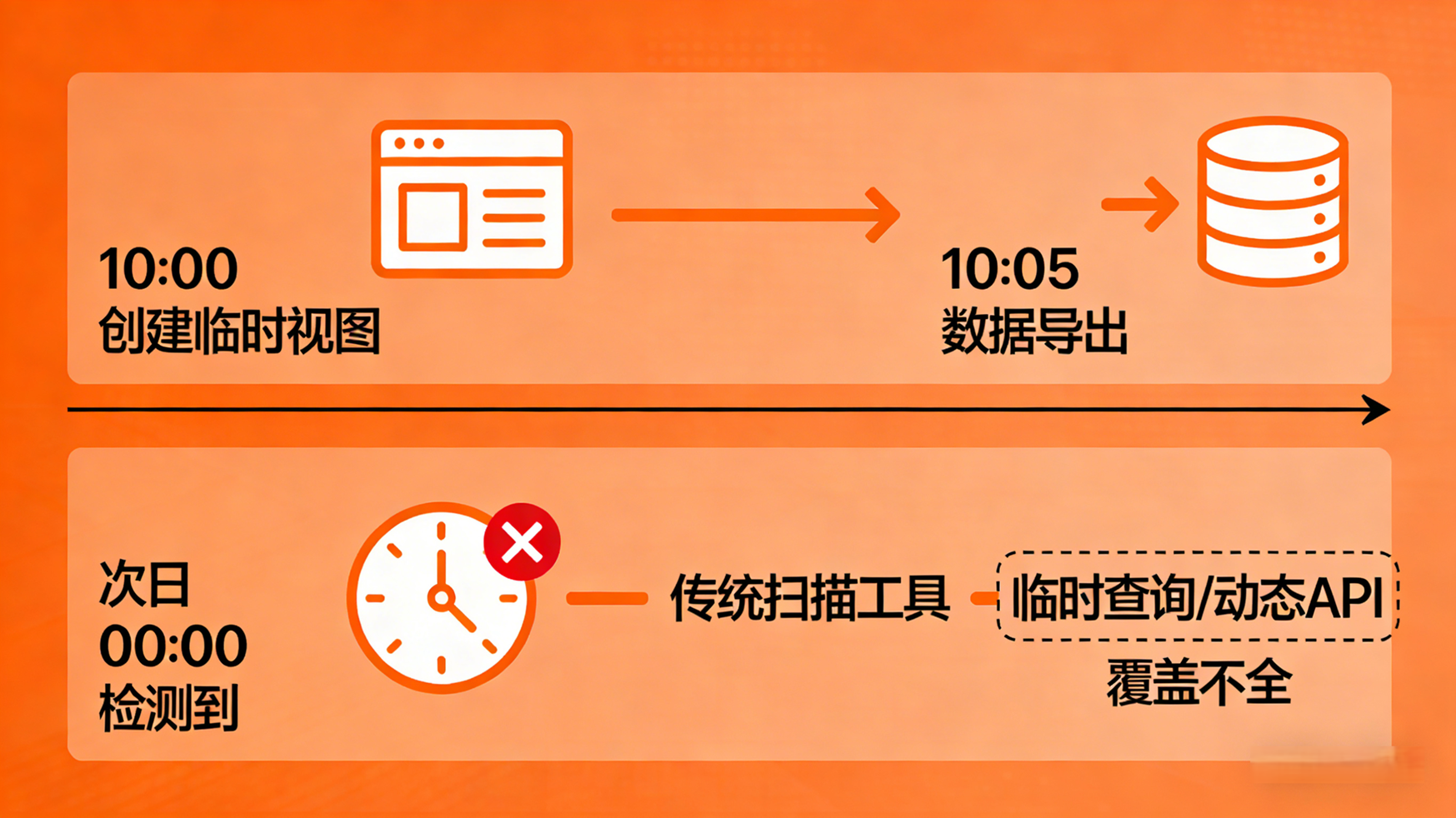
-
时效性差: 开发人员上午 10 点创建了一个临时视图并导出了数据,安全工具有可能要在第二天凌晨才能扫描到这个视图。此时,数据早已泄露。
-
覆盖不全: 很多临时性的查询或动态生成的 API,并不一定会持久化为数据库对象,传统扫描工具根本捕捉不到。
未来的趋势必然是"实时解析"与"统一入口"。
企业需要构建统一的数据管理与服务平台。当 SQL 语句在平台上执行的那一毫秒,后端的 SQL 引擎就应当实时生成 AST(抽象语法树),即时计算出血缘关系,并立即判断是否存在敏感数据泄露风险。
只有将安全检查从"事后审计"前置到"运行时管控",才能真正实现主动防御。
04 最后一公里:从 SQL 到 API 的安全闭环
在现代微服务架构中,数据的终点往往不是数据库,而是 API 接口。
很多时候,数据库层面的防护做得很好,但最后封装成 RESTful API 对外提供服务时,又成了盲区。后端开发在写 API 代码时,可能无意中将一个敏感字段直接 return 给了前端。
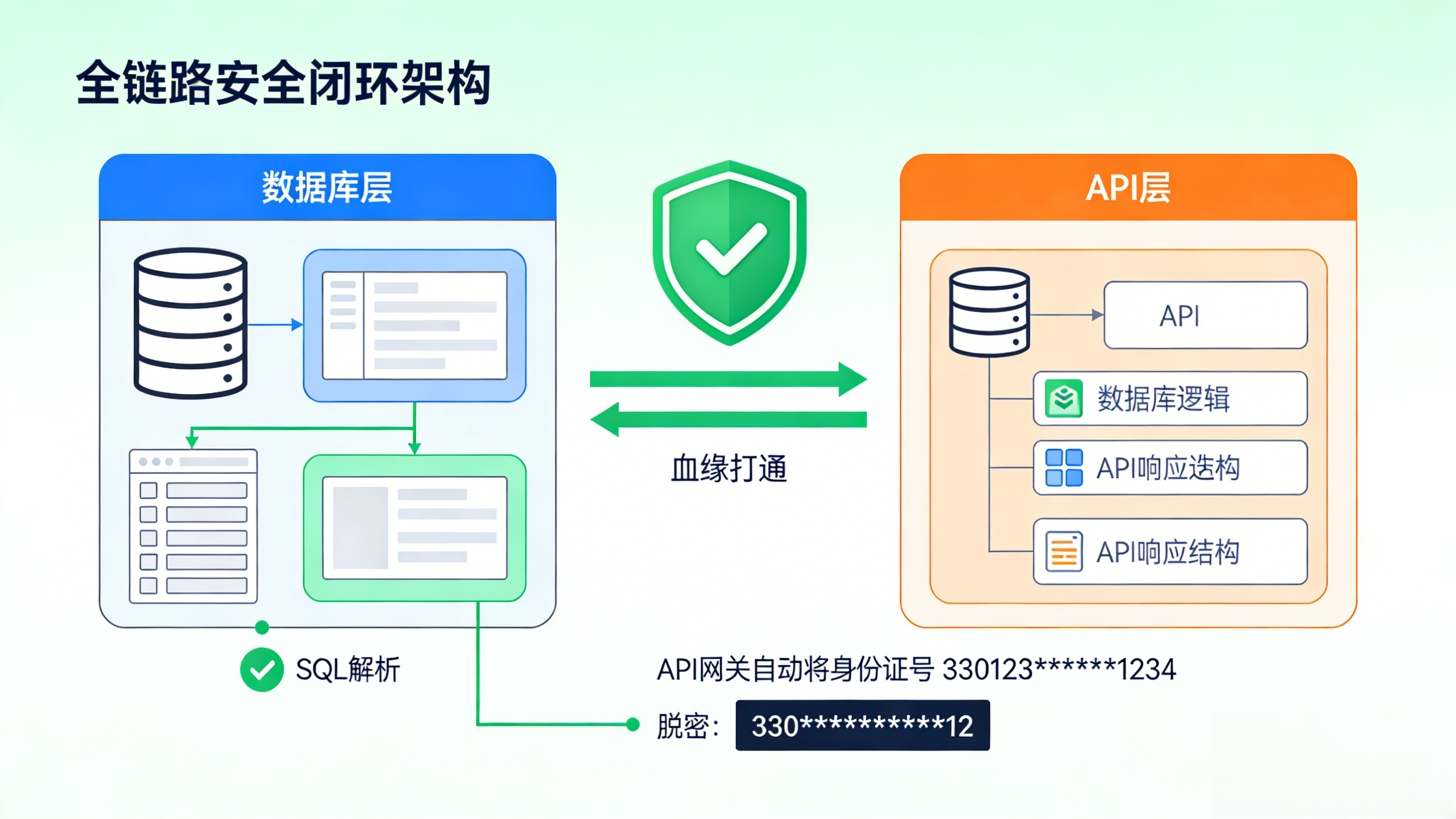
完整的全链路血缘,须跨越"数据库"与"应用"的边界:
-
Layer 1: 数据库表 -> 数据库视图/中间表(SQL 解析)
-
Layer 2: 数据库逻辑 -> API 响应结构(服务封装)
当血缘打通了这"最后一公里",我们就能实现真正的智能脱敏:
系统根据血缘关系,自动识别出某个 API 的返回值中包含源端的"身份证号",从而在 API 网关层自动触发动态脱敏策略(如变为 330***********12),而无需开发人员手动编写脱敏代码。
05 结语
数据安全治理正在经历从"基于规则"向"基于血缘"的进阶。
面对日益复杂的异构数据环境和合规要求,我们不能再依赖人工去维护静态的敏感数据目录。通过构建全链路、实时更新的字段级血缘体系,让安全标签随着数据流动而"自动流转",是企业构建零信任数据安全底座的必由之路。