目录
[一. BIO(Blocking I/O 同步阻塞) 详解](#一. BIO(Blocking I/O 同步阻塞) 详解)
[1.1 BIO 基本介绍,工作机制](#1.1 BIO 基本介绍,工作机制)
[1.2 Java 实现 BIO](#1.2 Java 实现 BIO)
[1.3 总结概括](#1.3 总结概括)
[二. NIO(Non-blocking I/O 同步非阻塞) 详解](#二. NIO(Non-blocking I/O 同步非阻塞) 详解)
[2.1 老调重弹](#2.1 老调重弹)
[2.2 逐步推演NIO的工作机制](#2.2 逐步推演NIO的工作机制)
[2.2.1 有缺陷的方案一](#2.2.1 有缺陷的方案一)
[2.2.2 有缺陷的方案二](#2.2.2 有缺陷的方案二)
[2.2.3 NIO 基本工作过机制解析,最终实现方案](#2.2.3 NIO 基本工作过机制解析,最终实现方案)
[2.2.4 深入探究(Select,poll,epoll 操作系统函数简介)](#2.2.4 深入探究(Select,poll,epoll 操作系统函数简介))
[2.2.5 NIO 客户端实现,模拟真实访问状况](#2.2.5 NIO 客户端实现,模拟真实访问状况)
[三. AIO 详解](#三. AIO 详解)
[3.1 AIO 基本介绍](#3.1 AIO 基本介绍)
[3.2 Java 实现 AIO](#3.2 Java 实现 AIO)
[四. BIO,NIO,AIO 总结对比](#四. BIO,NIO,AIO 总结对比)
[五. 市场现有的成熟解决方案介绍------Netty、MINA、Grizzly](#五. 市场现有的成熟解决方案介绍——Netty、MINA、Grizzly)
一. BIO**(Blocking I/O** 同步阻塞**)** 详解
1.1 BIO 基本介绍,工作机制
同步阻塞BIO,就是传统的 Java IO 编程,其相关的类和接口再 java.io 包下;BIO模型是"一个连接一个线程 ",工作模式为:"当一个连接建立后,服务器端会分配一个独立的线程来为该连接服务,所有操作(读取、写入)都是阻塞的"。并且会一直阻塞直到数据完成传输,通常适用于低并发、连接数少的场景,使用频率相对较低。其优点就是比较稳定,编程模型简单易上手;但设计模型也决定了缺点可扩展性较差,受限于线程数量,还会导致资源利用率较低。
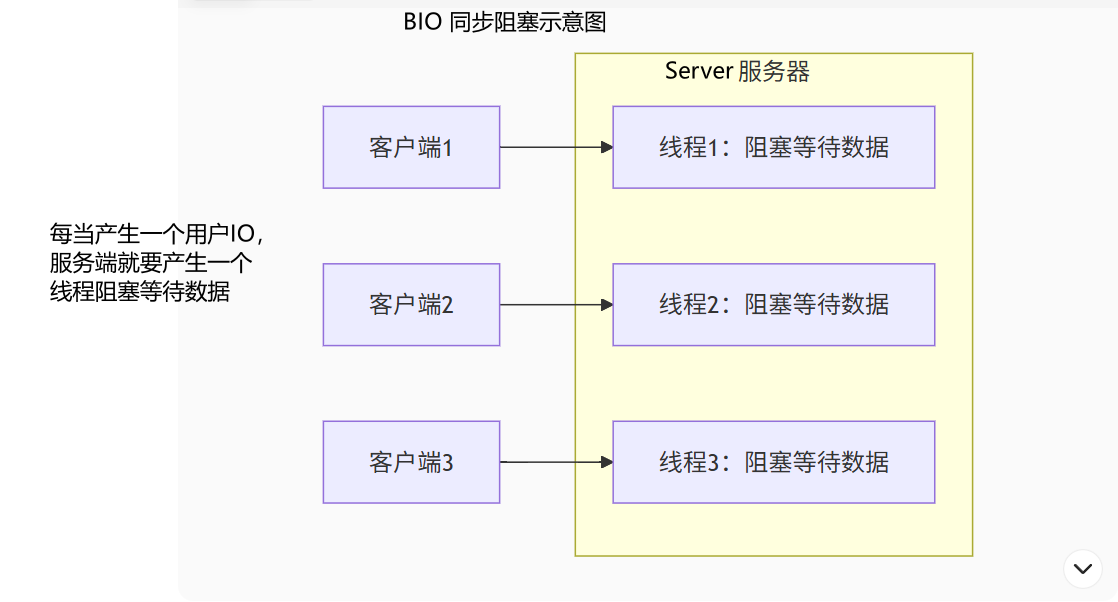
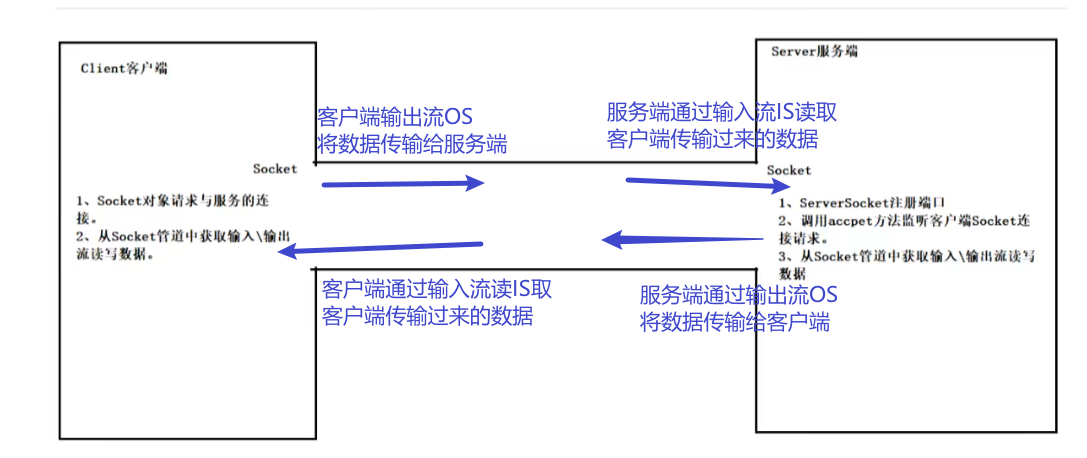
我们那其中一个客户端服务端的交互为例,客户端与服务端的大致交流过程如下图所示;
1.2 Java 实现 BIO
为了便于同学们好理解,我们先以一个单线程BIO为例,模拟一下 BIO 的数据传递过程;
**a.**首先创建一个 Server 服务端;
java
public class BIOServer {
public static void main(String[] args) {
byte[] buffer = new byte[1024];
try {
// 创建一个ServerSocket,绑定到8080端口,监听客户端连接
ServerSocket serverSocket = new ServerSocket(8080);
System.out.println("服务器已监听8080端口");
while (true){
System.out.println("服务器正在等待连接");
// 阻塞(1):阻塞等待连接请求
Socket socket = serverSocket.accept();
System.out.println("服务器已接收到连接请求");
System.out.println("服务器正在等待数据源");
// 阻塞(2):连接成功后,仍然阻塞,等待数据传输
socket.getInputStream().read(buffer);
String content = new String(buffer);
System.out.println("服务器已接收到数据:" + content);
}
}catch (IOException e){
e.printStackTrace();
}
}
}**b.**再创建一个客户端
java
public class BIOClient {
public static void main(String[] args) {
try {
Socket socket = new Socket("localhost", 8080);
String message = null;
// 创建键盘录入
Scanner scanner = new Scanner(System.in);
// 获取键盘录入
message = scanner.next();
socket.getOutputStream().write(message.getBytes());
socket.getOutputStream().flush();
socket.close();
scanner.close();
} catch (Exception e) {
e.printStackTrace();
}
}
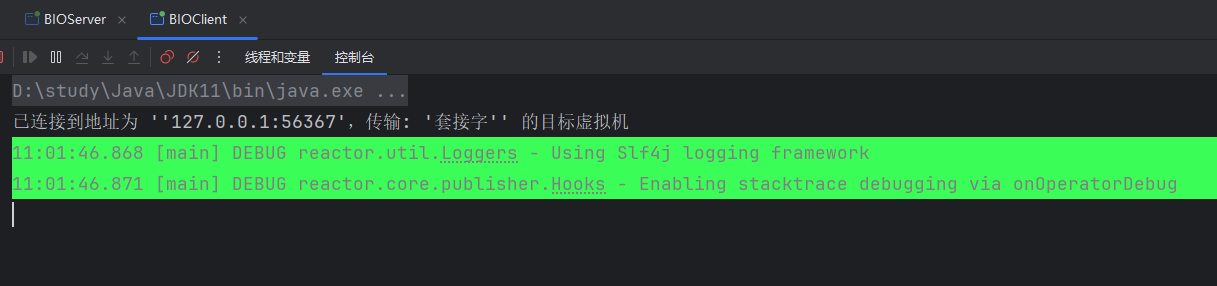
}**c.**启动客户端,控制台打印如下,服务端阻塞等待客户端连接请求

**d.**然后启动客户端,可以看到此时可以键盘录入,我们暂时先不录入,再回到客户端线程,
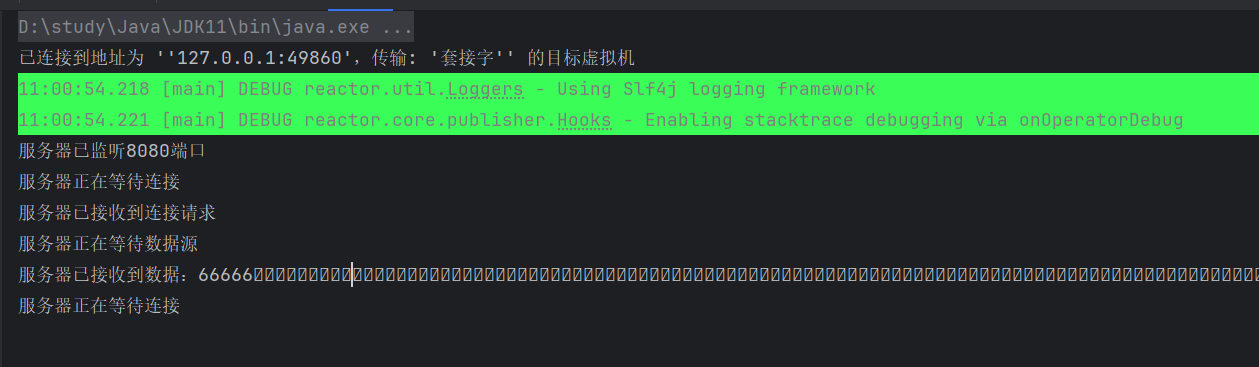
**e.**如下图,此时客户端已经监听到了连接请求并连接成功,等待客户端发送数据;

**f.**回到客户端,随便输入数据,回车发送,数据传输成功,客户端线程中断

**g.**切换回服务端线程,可以看到,客户端传输的数据"66666"已经被接收处理,处理完毕,重新进入 while 循环等待新的连接请求
1.3 总结概括
通过上面的单线程BIO示例代码可以得出如下结论
(1) 客户端再启动运行后,首先会经历第一次阻塞(等待客户端请求连接),如果没有客户端请求连接,就会一直处理阻塞;
(2) 如果接收到了请求连接并连接成功,则会进入第二次阻塞(等待客户端发送数据),如果客户端一直不发送数据,则会一直处于阻塞状态;
(3) 这是其中一个线程的处理总体程序逻辑,那么在实际BIO中,while 循环通常是来一个请求,就创建一个新的线程去处理,我这里为了便于大家理解并没有展示,实际逻辑如下所示,来一个请求,就 new Thread 一个新的线程去处理,实际业务逻辑定义在了 "handleClient" 方法中;总之大家只要明白,BIO 在处理请求时会阻塞两次 ,并且为每个请求都创建一个线程,这是BIO最重要的两个特点;
java
public static void testBio() throws IOException {
// 创建一个ServerSocket,绑定到8080端口,监听客户端连接
ServerSocket serverSocket = new ServerSocket(8080);
System.out.println("BIO Server started");
// 无限循环,持续监听接收客户端连接
while (true) {
// accept()方法会阻塞当前线程,直到有客户端连接;当客户端连接时,返回该链接的Socket对象
Socket clientSocket = serverSocket.accept();
System.out.println("BIO Client connected");
// 为每个客户端连接创建并启动新线程
new Thread(() ->
// 在新线程中处理客户端连接,这里我们单独定义为一个方法
handleClient(clientSocket)
).start();
}
}(4) 那么我们进一步简单分析(3) 中的逻辑不难发现,我们为每一个到来请求连接都创建了一个线程去处理,又已知,如果请求不发送数据,则线程会一直阻塞等待,如果请求访问数量较少时尚可接收,但倘若有成千上万的线程都是连接成功但是却不向服务器发送数据,造成大量的线程干等的,服务器资源被极大的浪费,这便是BIO的最大弊端------"容易造成服务器资源的浪费";
二. NIO**(Non-blocking I/O** 同步非阻塞**)** 详解
2.1 老调重弹
通过上面对BIO的学习了解,我们知道了BIO的最大通电就是连接阻塞和等待数据阻塞;
如果单线程BIO,虽然不浪费服务器资源,但是由于等待阻塞,每次只能处理一个线程,程序的运行处理效率极低 ,但如果使用多线程,虽然可以同时并行处理大量请求访问,但是大量的线程创建或阻塞又被导致服务器资源被极大的浪费;两次阻塞极大地降低了BIO的效率,这似乎是一个无解的问题?怎样解决解决这一问题?
此时不难发现,我们的问题焦点就转移到了,"如何让单线程或少量线程在的服务器在等待客户数据到来或客户请求连接时不处于阻塞状态,可以去处理其它用户数据或用户请求?"
所以,下面我们要讲到的 NIO ,说白了就是在解决这一问题。
2.2 逐步推演NIO的工作机制
2.2.1 有缺陷的方案一
上面我们说到了,如果让服务器线程在处理客户请求数据或连接时,不处于阻塞状态,就可以提高效率,下面就是一个简单的示例代码,我们将它简单运行一下;
java
/**
* 基础NIO版本:单线程轮询
* 问题:会错过数据,因为只能处理当前连接
*/
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
try {
// 使用非阻塞的类型的ServerSocketChannel
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(8080));
// 设置为非阻塞
serverSocketChannel.configureBlocking(false);
while (true) {
SocketChannel socketChannel = serverSocketChannel.accept();
// 为空表示无人连接
if (socketChannel == null) {
System.out.println("正在等待客户端请求...");
Thread.sleep(5000);
} else {
System.out.println("当前接受客户端请求连接...");
}
if (socketChannel != null){
socketChannel.configureBlocking(false);
buffer.flip(); // 切换模式:写------>读
int effect = socketChannel.read(buffer);
if (effect > 0){
String message = Charset.forName("UTF-8").decode(buffer).toString();
System.out.println("接收到数据:" + message);
} else {
System.out.println("没有数据可读");
}
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
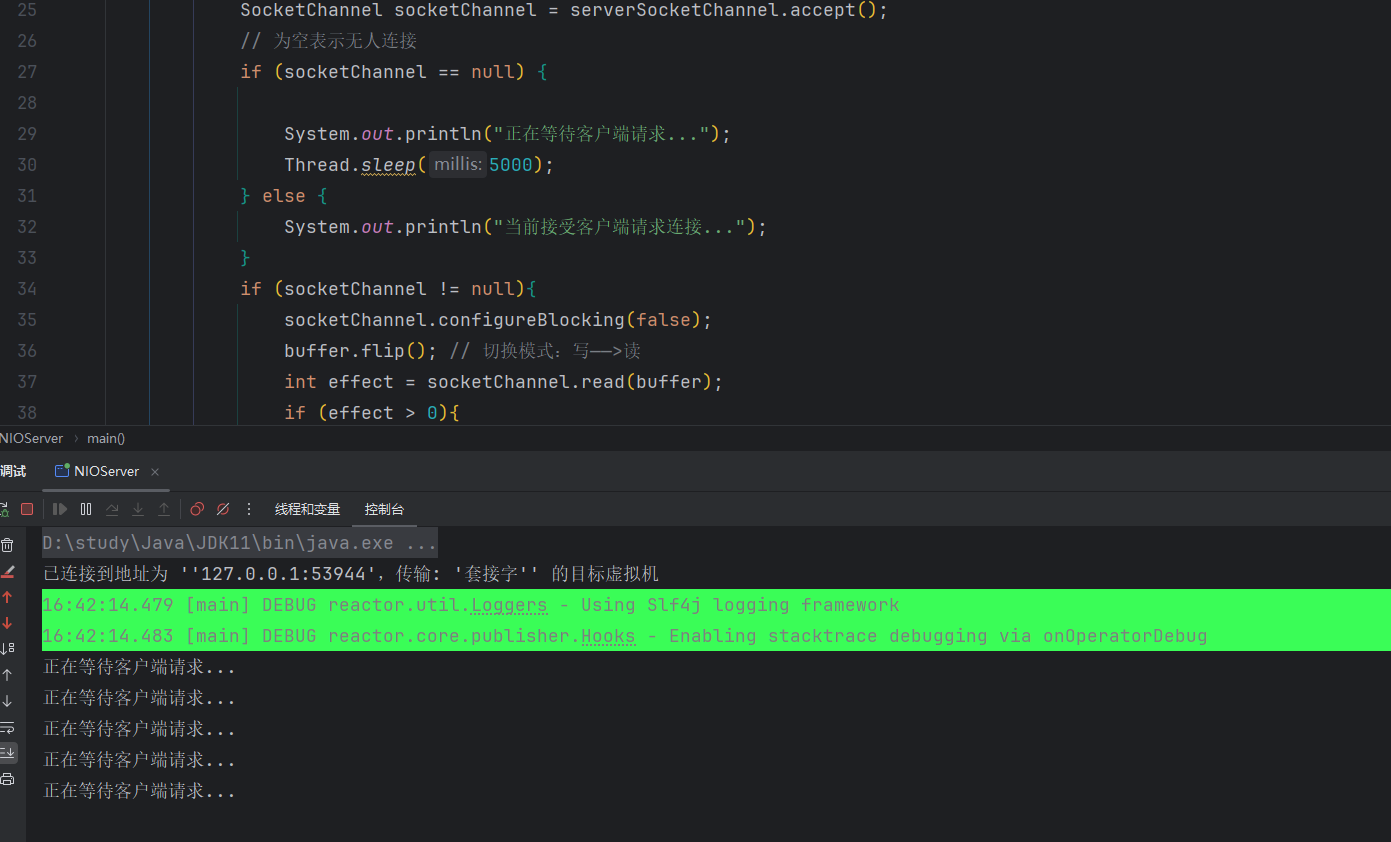
}如下图所示,可以看到,控制台每隔五秒打印一次日志,标识等待客户端请求连接。
现在我们现在思考一个问题,如果不设置时间,那就是什么时候有连接,什么时候出处理。
此时,又会衍生出另外一个问题,假设我用户A正在向服务器传输数据,服务器正在正常接收并处理,同一时刻用户B也向服务器发送了请求连接,那么服务器就会去处理用户B的请求连接,我用户A请求访问,导致服务器并没有接收到用户A传输的数据,处理数据失败。所以显而易见,下面这种做法明显是不妥当的,因为会导致在处理请求时,会导致其它连接传递的数据未能接收。
换言之,这种方法的解决思路总体是没错的,但是可能会导致数据丢失,所以说,如果我们能在此基础上,找到一种不让数据丢失的解决办法,不就可以了吗?
此时,聪明的你大概已经想到了,我可以将每个请求连接发送的数据存储或缓存起来,每个请求连接要做的请求操作或数据处理操作,都可以视为一个单独的任务,我们将所有的任务统一放一起或者放集合中,总之只要可以让服务器线程可以去遍历处理每个任务就可以了,这样一来,我的服务器线程及没有空闲下来造成阻塞,也没有导致请求访问或数据传输的丢失,一举两得!!!
2.2.2 有缺陷的方案二
上面我们分析出,可以使用集合将所有请求访问进行存储,然后遍历所有请求连接判断是否传输了数据,如果有数据则读取数据,下面我们就针对上面的代码做进一步的演化,如下所示
java
/**
* NIO服务端 V2.0(集合版本)
* 改进:用集合存储所有连接,不会错过数据
* 问题:需要遍历所有连接,效率较低
*/
public static void main(String[] args) {
try {
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
// 创建一个集合,用于存储 SocketChannel 任务列表
List socketList = new ArrayList();
// 使用非阻塞的类型的ServerSocketChannel
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(8080));
// 设置为非阻塞
serverSocketChannel.configureBlocking(false);
while (true) {
SocketChannel socketChannel = serverSocketChannel.accept();
if (socketChannel == null) {
// 表示无人连接
Thread.sleep(5000);
} else {
// 当前收到客户端请求连接,添加到任务列表...
socketList.add(socketChannel);
}
for (SocketChannel socket : socketList){
socket.configureBlocking(false);
int effect = socket.read(byteBuffer);
if (effect > 0){
byteBuffer.flip(); // 切换模式:写------>读
String message = Charset.forName("UTF-8").decode(byteBuffer).toString();
System.out.println("接收到数据:" + message);
byteBuffer.clear();
} else {
System.out.println("没有数据可读");
}
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}分析上面的代码,我们现在已经将所有的请求连接作为一个待处理任务添加到了集合中,现在我们只需要遍历集合中所有请求连接处理数据即可啦。
OK,到了这里,其实我们已经基本实现了NIO的工作原理了。现在,我们认真分析上面的方案二代码,是否还可以进一步优化???
答案是显而易见的,可以进行优化,重点优化就在任务集合 List 。
同学们试想一下,现在将所有的请求连接全部放入集合,然后让服务器线程遍历集合即可,虽然不会再次造成数据丢失,但有一个比较严重的问题我们或许没有注意到,就是数量,什么数量呢?当然是集合中的任务数量。
现在我们编写的示例代码,假设只有三个请求过来,集合中就只有三个任务,循环效率较快,我们没有什么实际感知;
但是!在实际生产项目或网络环境下,会有数千数万数十万的用户请求访问连接,或许只有其中的几十个或数百个有进行数据传输,但是我们让然遍历所有整个 List 任务集合,很显然做了很多的无用功。所以,如果我们能够在此基础上再进一步,将所有可被处理的请求连接放在任务集合中,这样一来遍历到了每个请求都是可被处理的任务,进一步提高了程序的处理效率。由此,我们便正式推断出了 NIO 网络编程的基本工作机制。
2.2.3 NIO 基本工作过机制解析,最终实现方案
NIO 的工作机制流程,大致如下图所示;
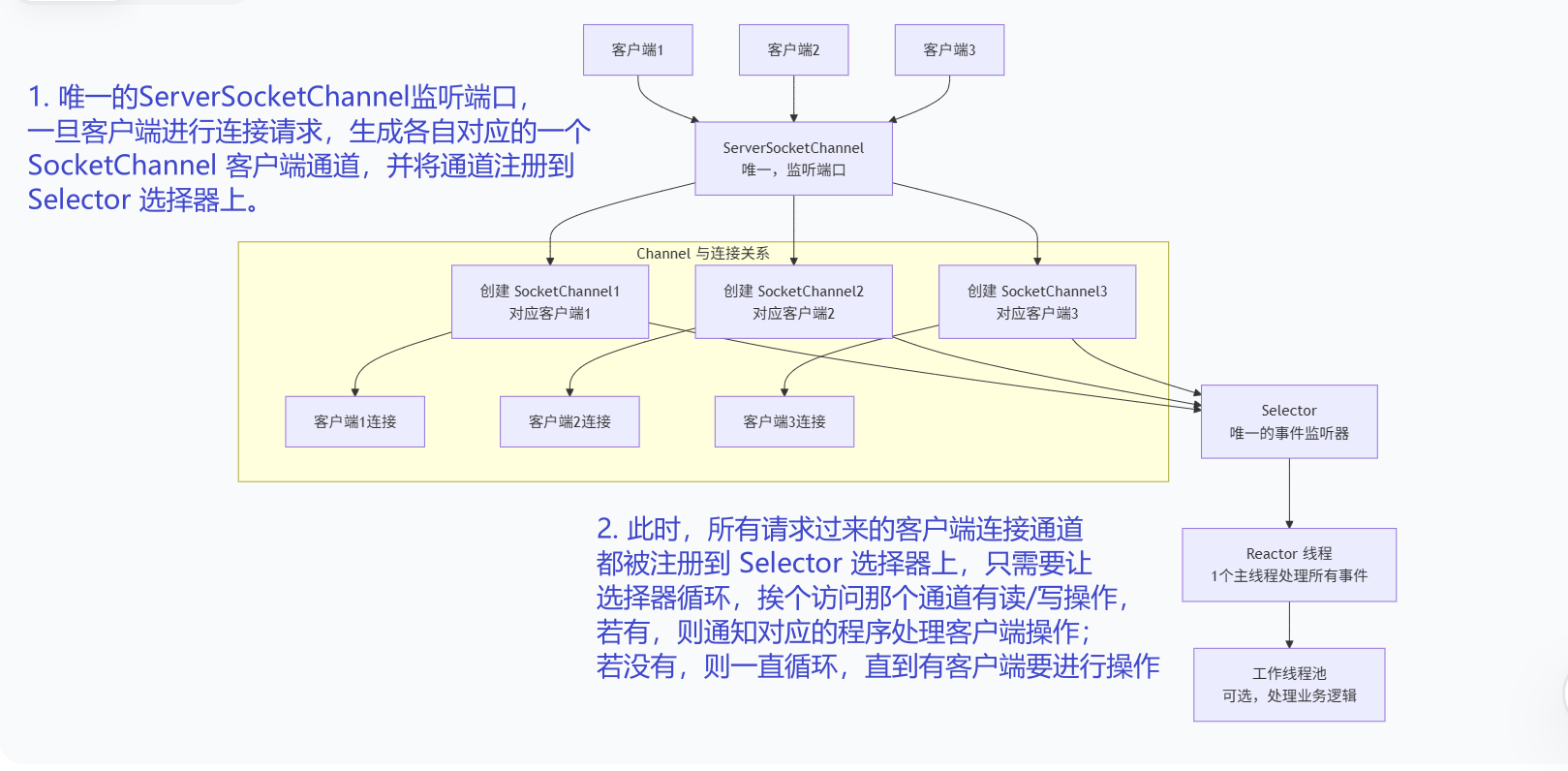
我们简单介绍一下图中的对象,其实大部分都是我们上面已经用过或者见到过的事物了。a
ServerSocketChannel:整个服务器只有一个,负责接收连接,如图中所示的 ServerSocketChannel ;
Channel(通道):类似于流,但可以同时进行读写,主要类型有 SocketChannel(TCP客户端),ServerSocketChannel(TCP服务端)和 DatagramChannel(UDP),如图中所示的SockerChannel1、SocketChannel2、SocketChannel3;
Buffer(缓冲区):一个容器,所有数据的读写都通过 Buffer。核心属性有 capacity,position,limit;
Selector(选择器):NIO的灵魂,一个 Selector(选择器) 可以轮询多个 Channel(通道),当一个 Channel 上有事件(如新连接到来,数据可读,数据可写)发生时,Selector 会通知应用程序,然后应用程序再处理这些事件;
Reactor 线程:一个主线程,处理所有的网络IO,可选工作线程池处理业务逻辑,可以类似理解为服务器线程;
下面就是一个比较完整的 NIO 服务器实现方案
java
public class NIOServer {
// main 方法测试启动
public static void main(String[] args) {
try {
new NIOServer().start(8085);
} catch (IOException e) {
e.printStackTrace();
}
}
// ========================== 服务端部分 ==========================
private Selector selector;
public void start(int port) throws IOException {
System.out.println("=== NIO服务端启动 ===");
// 1. 创建Selector(事件监听器)
selector = Selector.open();
// 2. 创建ServerSocketChannel
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.bind(new InetSocketAddress(port));
serverChannel.configureBlocking(false);
// 3. 注册ACCEPT事件
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("服务器监听端口: " + port);
System.out.println("等待客户端连接...\n");
// 4. 事件循环
while (true) {
// 阻塞等待事件
int readyChannels = selector.select();
if (readyChannels == 0) continue;
// 处理就绪的事件
Set<SelectionKey> readyKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = readyKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
keyIterator.remove();
try {
if (!key.isValid()) continue;
if (key.isAcceptable()) {
// 处理新的连接
handleAccept(key);
} else if (key.isReadable()) {
// 处理读取事件
handleRead(key);
} else if (key.isWritable()) {
// 处理写入事件
handleWrite(key);
}
} catch (Exception e) {
key.cancel();
try {
key.channel().close();
} catch (IOException ex) {
e.printStackTrace();
}
}
}
}
}
// 处理连接方法
private void handleAccept(SelectionKey key) throws IOException {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel client = server.accept();
client.configureBlocking(false);
System.out.println("✅ 新客户端连接: " + client.getRemoteAddress());
// 注册READ事件,并附加缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
client.register(selector, SelectionKey.OP_READ, buffer);
}
// 处理读取事件方法
private void handleRead(SelectionKey key) throws IOException {
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer buffer = (ByteBuffer) key.attachment();
buffer.clear();
int bytesRead = client.read(buffer);
if (bytesRead > 0) {
buffer.flip();
String message = StandardCharsets.UTF_8.decode(buffer).toString().trim();
System.out.println("📨 收到来自 " + client.getRemoteAddress() + " 的消息: " + message);
// 准备回复
String response = "Server reply: " + message;
ByteBuffer responseBuffer = ByteBuffer.wrap(response.getBytes(StandardCharsets.UTF_8));
// 改为关注WRITE事件
key.interestOps(SelectionKey.OP_WRITE);
key.attach(responseBuffer);
} else if (bytesRead == -1) {
System.out.println("❌ 客户端断开: " + client.getRemoteAddress());
client.close();
key.cancel();
}
}
// 处理写入事件方法
private void handleWrite(SelectionKey key) throws IOException {
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer buffer = (ByteBuffer) key.attachment();
if (buffer.hasRemaining()) {
client.write(buffer);
}
if (!buffer.hasRemaining()) {
// 发送完成,重新关注READ事件
ByteBuffer newBuffer = ByteBuffer.allocate(1024);
key.interestOps(SelectionKey.OP_READ);
key.attach(newBuffer);
System.out.println("📤 回复已发送到 " + client.getRemoteAddress());
}
}
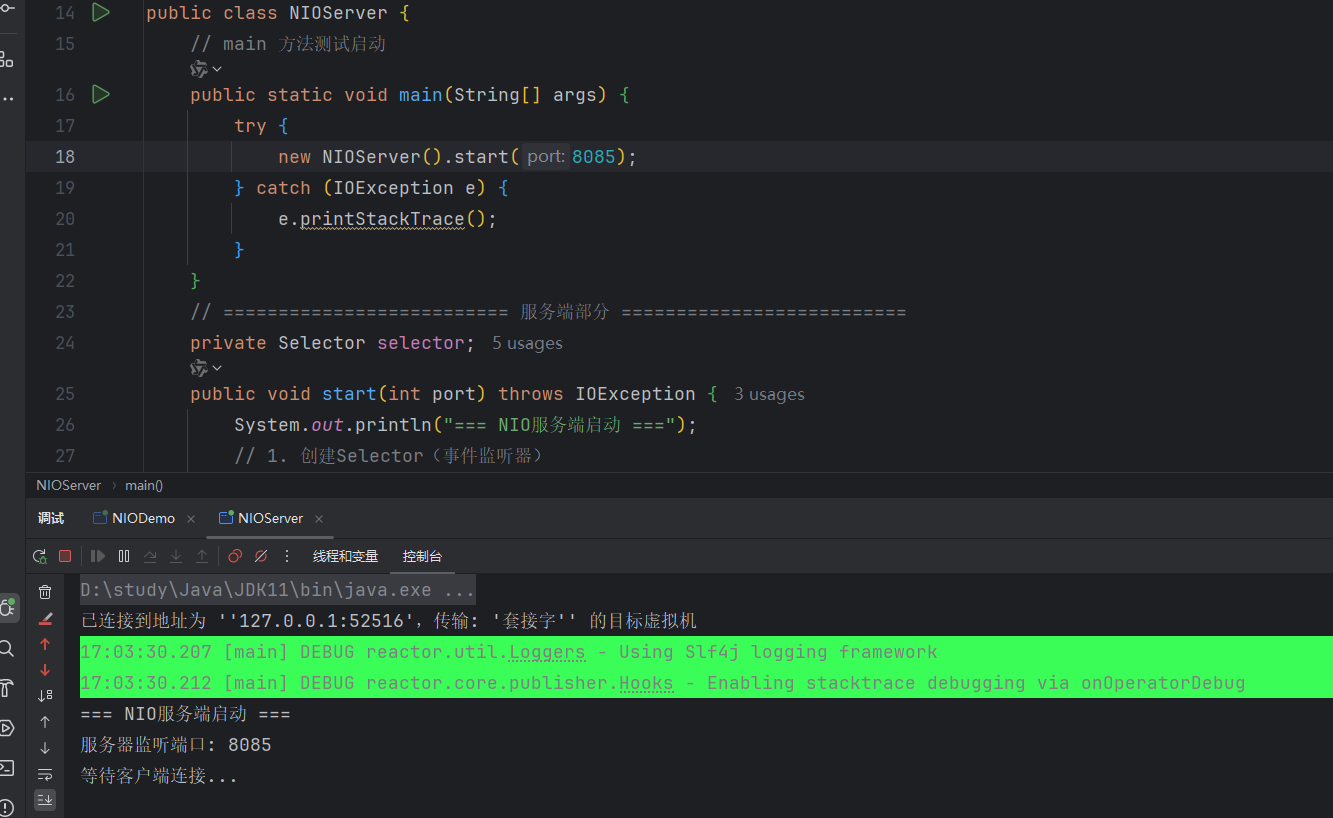
}运行上述代码,如下图所示,模拟 NIO 服务器启动成功!
2.2.4 深入探究(Select,poll,epoll 操作系统函数简介)
通过上面的解释,我们不难发现,在NIO中,资源关系为 1:1:1:N (1个ServerSocketChannel:1个Selector:1个Rector线程:N个SocketChannel);
它的工作模式也常被称为 Reactor 模式 。实现了用少数线程管理大量的连接,只有当某个连接真正有读/写事件的时候,才会分配资源进行处理,这也是NIO支持高并发的核心原因!
这个时候小伙伴们可以能会有一些疑问?
(1)怎样判断"某个连接真正有读/写事件?"。
答:这一步操作并不是在 Java 代码层面实现的,而是将这个轮询的步骤交给了操作系统来进行,底层将轮询的那部分代码该做系统级别的系统调用(Select 函数,在 Linux 系统中为 epoll ),通过操作系统的函数调用,主动感知有数据的 Socket ,然后放入 channel 通道中再由 Java 代码进行循环遍历。
(2)既然应用层也是去进行循环遍历感知,为什么我们不能在代码应用层实现呢?
答:最主要的原因是,我们所写的 Java 程序,每次在轮询 Socket 时也需要去调用系统函数,每次轮询每次都调用,会造成不必要的性能开销;而如果我们使用系统函数库 Select,它会直接全量复制所有请求到系统内核空间,在内核空间判断每个请求是否已经准备好,这样一来还规避了频繁的上下文切换,所以使用系统函数轮询是要比在Java代码层面实现轮询效率要高的!
原本应该直接说明 NIO 的实现模式,但这里我们插上一小节,专门来讲解一下操作系统底层的相关 IO 函数;
这三个函数都是 Linux 系统下的 IO 多路复用机制,其发展顺序为 select------>poll------>epoll,但在其它系统也有类似的功能(如 macOS,FreeBSD)中也有类似的实现,下面简述它们的区别,同学们可以混个眼熟大概了解一下;
Select 函数
是一个阻塞函数,如果一个或多个请求已经准备好了数据,那么 Select 会先将有数据的文件描述符置位,然后 Select 返回,返回后通过遍历查看那个请求有数据。
但是,任何事物总归都是有两面性的,我们不能只看好处不看缺点,同样 Select 也是存在缺点的。
- 底层存储依赖 bitmap,处理是有内存上限的,为 1024,即最大连接数为1024;
- 文件描述是会置位的,如果当被置位文件描述符需要重新使用时,则需要重新赋空值;
- fd(文件描述符)从用户态拷贝到内核态仍然有一笔开销;
- select 返回后还要再进行遍历,来获悉是哪个请求有数据,事件复杂度O(n);
poll 函数
由于其底层设计为链表,所以相比 Select 函数,他没有文件描述符数量的限制,并使用了 pollfd 结构体,可以更精细的监控事件(如ROLLRDHUP);所以 poll 解决了上述 Select 函数的缺点1和缺点2;
但是,它仍然存在和 Select 函数一样的缺陷,即 每次调用仍然是复制全部 fd 到内核;返回后仍然需要遍历所有 fd 检查就绪状态,时间复杂度O(n)
epoll 函数
因为 epoll 它的 fd 是共享在用户态和内核态之间的,所以不需要像 select,poll 那样将数据进行拷贝,节省了系统资源;
此外,当 epoll 发现某个请求数据已经准备好时,首先会进行一个重新排序操作,将所有有 fd 的数据放在最前面,然后返回值,返回值是存在的数据请求个数 N,也就是说,epoll 只会返回存在数据的请求(或者说请求个数),那么我们的上层应用,就不需要像 select,poll 那样对所有请求都进行轮询,而是直接遍历 epoll 返回的前 N 个请求,这些都是有效的有数据的请求。
所以它相较于前两者,做出了较大的改进,
- 无需每次复制 fd,而是通过 epoll_ctrl 注册一次,后续直接复用;
- 只返回就绪的 fd,epoll_wait 直接返回就绪状态的事件列表,无需再向前两者一样遍历所有 fd,时间复杂度由 O(n)直接降低为O(1);
- 支持边缘触发(ET)和水平出发(LT)两种模式;
- 底层使用红黑树管理 fd,高效支持大规模连接;
性能对比
| 特性 | select | poll | epoll |
|---|---|---|---|
| 最大连接数 | FD_SETSIZE(1024) | 无限制(系统限制) | 无限制(系统限制) |
| 时间复杂度 | O(n) 需要遍历数组 | O(n) 需要遍历链表 | O(1)(就绪 fd 数) |
| 内存拷贝 | 每次复制全部 fd | 每次复制全部 fd | 注册一次,无需重复 |
| 触发模式 | 水平触发 | 水平触发 | 边缘触发(ET)/水平触发(LT) 可选 |
| 内核实现 | 线性遍历 | 线性遍历 | 红黑树+就绪链表 |
| 底层数据结构 | 数组 | 链表 | 红黑树 |
适用场景
select/poll:适用于fd 数量少,跨平台需求或者兼容旧系统的场景;
epoll:适用于 Linux 高并发的场景(如万级连接),尤其是长连接服务(Web服务器,即时通讯);
2.2.5 NIO 客户端实现,模拟真实访问状况
经过上面的层层推演,我们现在已经了解了 NIO 服务器的基本原理了,现在再编写一个客户端的方法逻辑,这个就比较简单了,我直接展示代码
java
public class NIOClient {
public static void main(String[] args) {
try {
new NIOClient().start("localhost", 8085);
} catch (IOException e) {
e.printStackTrace();
}
}
public void start(String host, int port) throws IOException {
System.out.println("=== NIO客户端启动 ===");
// 1. 创建SocketChannel
SocketChannel client = SocketChannel.open();
client.configureBlocking(false);
// 2. 连接服务器
System.out.println("正在连接服务器 " + host + ":" + port + "...");
client.connect(new InetSocketAddress(host, port));
// 等待连接完成
while (!client.finishConnect()) {
System.out.println("连接中...");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return;
}
}
System.out.println("✅ 连接服务器成功!");
System.out.println("请输入消息(输入 'exit' 退出):\n");
Scanner scanner = new Scanner(System.in);
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (true) {
System.out.print(">>> ");
String input = scanner.nextLine();
if ("exit".equalsIgnoreCase(input.trim())) {
break;
}
// 发送消息
buffer.clear();
buffer.put(input.getBytes(StandardCharsets.UTF_8));
buffer.flip();
while (buffer.hasRemaining()) {
client.write(buffer);
}
System.out.println("消息已发送: " + input);
// 接收回复
buffer.clear();
int bytesRead = client.read(buffer);
if (bytesRead > 0) {
buffer.flip();
String response = StandardCharsets.UTF_8.decode(buffer).toString();
System.out.println("服务器回复: " + response);
}
try {
Thread.sleep(100); // 避免过快发送
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
System.out.println("客户端退出");
client.close();
scanner.close();
}
}运行代码,如下所示,输入任意数据,回车发送,可以看到数据已经发送成功!
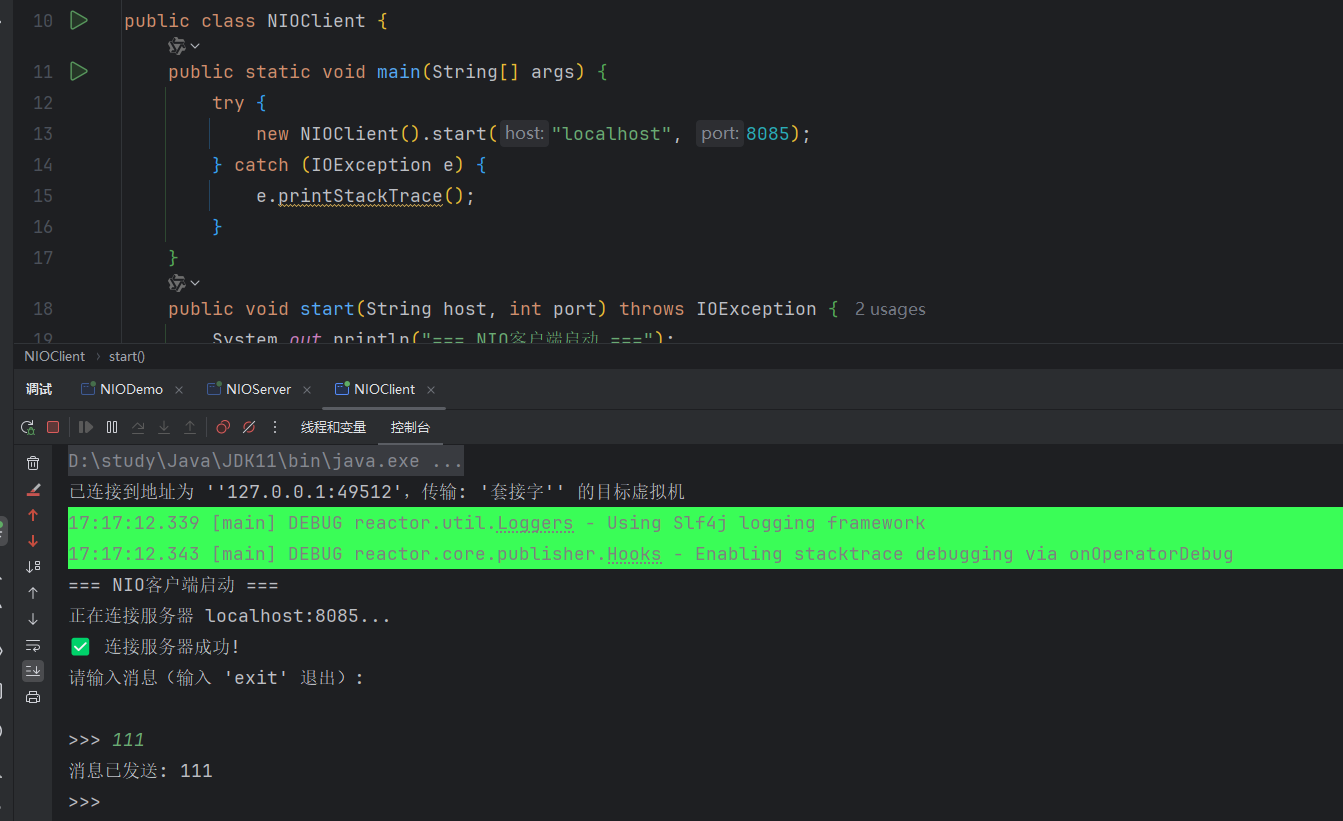
此时我们再回到服务端窗口,可以看到刚才发送的"111"已经接收到,我们再给客户端返回数据
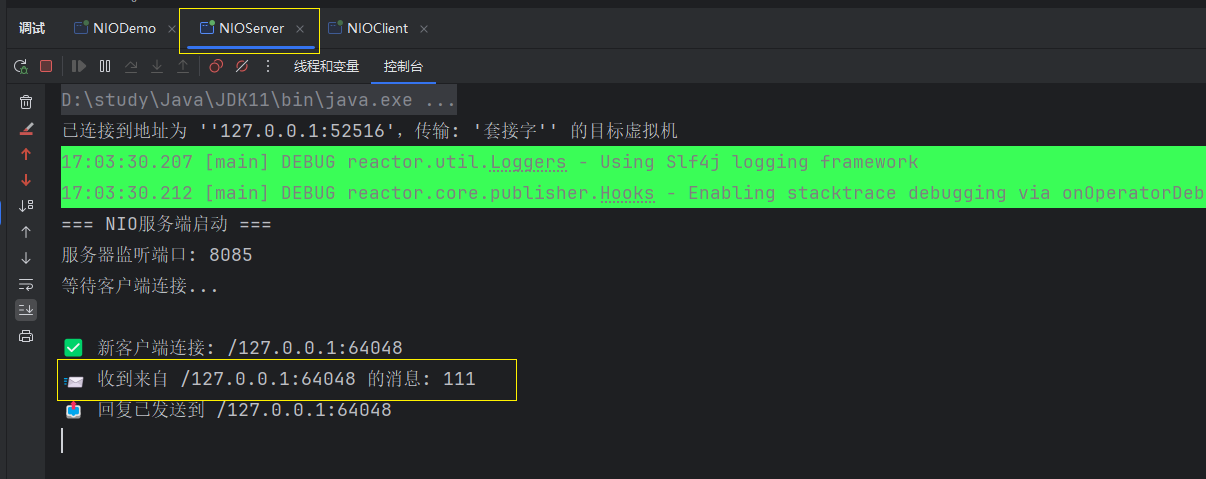
三. AIO 详解
3.1 AIO 基本介绍
由于 Linux 系统对 AIO 支持不完善(底层仍然采用 epoll 模拟),且几乎所有项目都是部署在 Linux 操作系统,所以就目前来说,并不要求开发人员对 AIO 有多么深入地掌握运用,这里小编不再做详尽的描述,主要说一说基本实现,思路原理等,简单理解熟悉即可。
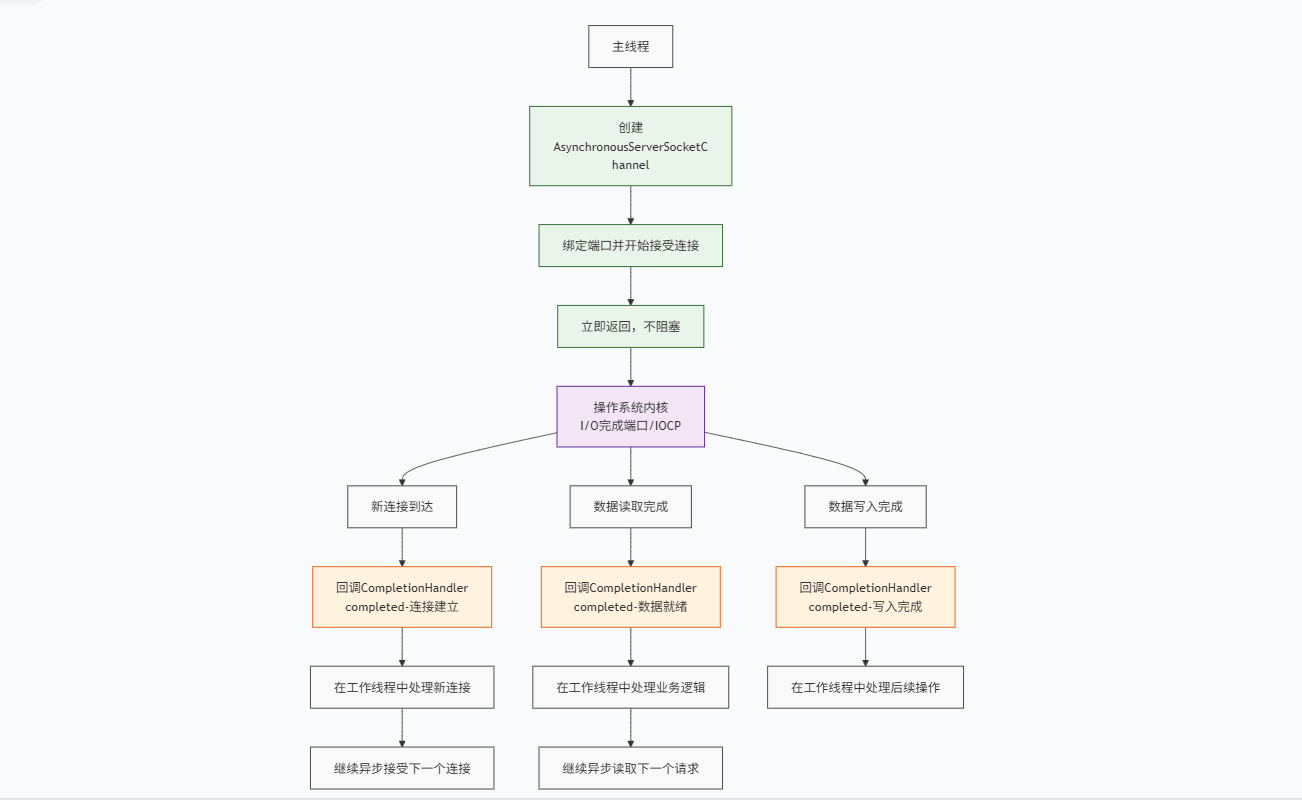
异步非阻塞也常称之为NIO2.0版本,IO操作都是异步的,这也是AIO的核心原理。当应用程序发起一个IO操作(如读、写)时,会立即返回,不会阻塞当前线程。操作系统会完成整个IO操作(包括将数据从内核空间拷贝到用户空间),完成之后,会主动回调应用程序提供的回调函数。
AIO的工作模式被称为 Proactor 模式。它与 Reactor 的关键区别在于
Reactor:通知你"何时可以开始"一个IO操作(例如数据可读了),但实际的IO操作(读数据)还是要自己来做;
Proactor:通知你"IO操作已经完成了"(例如数据已经读到你提供的 Buffer 里了)
AIO用途:AIO一般适用于连接数较多并且连接较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂。
3.2 Java 实现 AIO
以下是使用 Java 代码实现 AIO 编程示例
java
public static void main(String[] args) {
try {
testAio();
} catch (IOException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
/**
* AIO服务器核心实现
* @throws IOException 可能抛出网络I/O异常
* @throws InterruptedException 可能抛出线程中断异常
*/
public static void testAio() throws IOException, InterruptedException {
// 创建异步服务器套接字通道
// open():打开异步服务器通道
// bind():绑定到8080端口
AsynchronousServerSocketChannel server =
AsynchronousServerSocketChannel.open().bind(new InetSocketAddress(8080));
System.out.println("AIO Server started");
// 定义连接完成回调
server.accept(null, new CompletionHandler<AsynchronousSocketChannel, Void>() {
@Override
public void completed(AsynchronousSocketChannel client, Void attachment) {
// 继续接收新连接(递归调用)
server.accept(null, this);
// 处理新连接的客户端
handleClient(client);
}
@Override
public void failed(Throwable exc, Void attachment) {
// 处理连接失败异常
exc.printStackTrace();
}
});
// 防止主线程退出(AIO是异步的,需要保持主线程运行)
Thread.currentThread().join();
}
/**
* 处理客户端连接
* @param client 客户端异步通道
*/
private static void handleClient(AsynchronousSocketChannel client) {
// 创建1024字节容量的缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 定义读操作完成回调处理器
client.read(buffer, null, new CompletionHandler<Integer, Void>() {
@Override
public void completed(Integer bytesRead, Void attachment) {
// 检查客户端是否断开连接
if (bytesRead == -1) {
try {
// 关闭通道
client.close();
System.out.println("Client disconnected");
} catch (Exception e) {
e.printStackTrace();
}
return;
}
// 切换为读模式
buffer.flip();
// 创建字节数组存储数据
byte[] data = new byte[buffer.remaining()];
// 从缓冲区复制数据
buffer.get(data);
// 将字节数据转换为字符串
// 注意:实际应用应指定字符集(如StandardCharsets.UTF_8)
String request = new String(data);
System.out.println("Received: " + request);
// 准备响应数据
ByteBuffer response = ByteBuffer.wrap(("Echo: " + request).getBytes());
// 发起写操作(发送响应给客户端)
client.write(response, null, new CompletionHandler<Integer, Void>() {
@Override
public void completed(Integer bytesWritten, Void attachment) {
// 清空缓冲区准备下一次读取
buffer.clear();
// 继续发起读操作(形成读取循环)
client.read(buffer, null, this);
}
@Override
public void failed(Throwable exc, Void attachment) {
// 处理写操作失败
exc.printStackTrace();
}
});
}
@Override
public void failed(Throwable exc, Void attachment) {
exc.printStackTrace();
}
});
}四. BIO,NIO,AIO 总结对比
| 特性 | BIO | NIO | AIO |
|---|---|---|---|
| 模型 | 同步阻塞 | 同步非阻塞(多路复用) | 异步非阻塞 |
| 线程要求 | 1连接 = 1线程 | 多连接共享少量线程 | 回调驱动,线程利用率最高 |
| 编程复杂度 | 简单 | 复杂(需管理Selector) | 中等(回调嵌套) |
| 吞吐量 | 低(线程限制) | 高 | 极高 |
| 底层机制 | 传统Socket | epoll/kqueue(系统调用) | 内核级异步支持 |
| 适用场景 | 低并发(<1000连接) | 高并发(如即时通讯) | 超大规模并发(如云存储) |
| 资源利用率 | 低 | 比较高 | 最高 |
| 核心实现思想 | 线性流程 | 状态机 + 事件驱动 | 回调驱动 |
五. 市场现有的成熟解决方案介绍------Netty、MINA、Grizzly
由于原生 API 复杂且容易出错,所以在实际开发过程中,我们通常不会直接进行编写,而是公司内部通常会进行封装调用,亦或者直接采用市场现有的主流封装框架。大家或许听说过 Netty,它的底层框架模型采用的就是 NIO。此外还有 MINA 和 Grizzly。三者的简要信息如下表格
| 框架 | 底层模型 | 适用场景 |
|---|---|---|
| Netty | NIO | 高并发、自定义协议(如游戏) |
| MINA | NIO | 轻量级TCP/UDP应用 |
| Grizzly | NIO/AIO混合 | 嵌入式服务器(如REST服务) |
在现有常见的 Spring Boot 项目中,几乎大多都选择使用 Netty 框架,Netty 的 EventLoopGroup 可以减少线程切换,还有零拷贝技术(ByteBuf 池化)带来的内存上的优势,从而使得 Netty 具有比后两者更高的性能。大家熟知的 RocketMQ、Dubbo 底层均使用了 Netty 框架。
XML
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.86.Final</version>
</dependency>