来源:程序员老廖
1. 背景与目标
1.1 为什么要做高性能日志
日志是所有线上系统的"黑匣子",但日志写入如果阻塞业务线程,会把 I/O 延迟 直接放大到业务请求上。
高并发下,同步写日志常见问题:
-
频繁系统调用(write/flush/open/close)
-
锁竞争(多线程写同一输出)
-
格式化开销(时间戳/字符串拼接/数字转字符串)
-
缓存失效(小块写、跨核争用)
1.2 本项目的设计目标
-
吞吐优先:尽可能将业务线程的日志开销降低到"内存追加 + 少量同步开销"。
-
异步落盘:将 I/O 操作从业务线程剥离到后台线程。
-
可控刷盘与回滚:支持按大小滚动文件,按时间 flush(语义清晰)。
-
可观测与可压测:提供压测程序(main_log_test.cc)用于对照实验。
1.3 非目标(边界)
-
不保证多线程场景下"严格按真实时间的全局顺序"(通常代价很高)。
-
不做网络日志/远端日志传输(仅本地文件写入)。
-
不做复杂的日志索引/结构化存储(以 plain text 为主)。
视频讲解与源码领取:C++高性能日志库开发实践
2. 总体架构(同步 vs 异步)
2.0 整体架构图
线程局部存储(Thread Local Storage, TLS)是一种机制,用于为每个线程提供独立的变量副本。这些变量存储在每个线程的局部存储区中,而不是全局存储区,从而避免线程之间的数据竞争和共享问题。
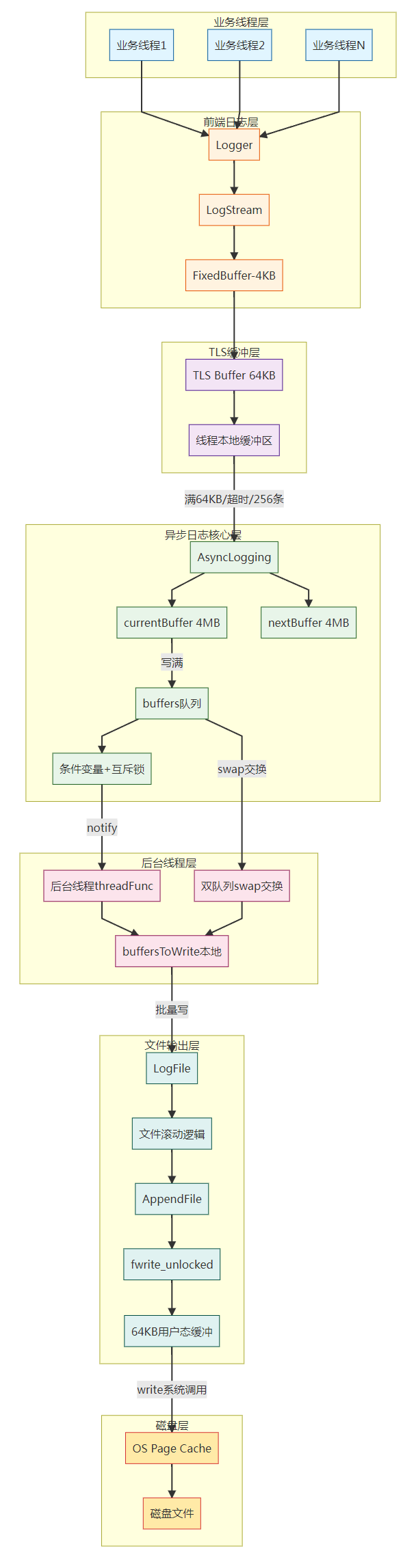
2. 总体架构(同步 vs 异步)
2.1 同步日志(对比基线)
同步日志通常意味着:业务线程在写日志时完成:
-
日志格式化(时间戳、线程 id、级别、文件行号等)
-
写文件/写 stdout
-
flush(可能每条或高频)
缺点:任何 I/O 抖动会直接影响业务线程;并发时锁竞争严重。
2.2 异步日志(本项目核心优化)
核心思想:业务线程只负责"产生日志并写入内存缓冲",后台线程负责"批量写入磁盘"。
数据流(简化):
业务线程: Logger -> g_output(asyncOutput) -> AsyncLogging::append()
|
v
内存缓冲(currentBuffer_/TLS buffer)
|
v
后台线程: AsyncLogging::threadFunc() -> LogFile -> FileUtil::AppendFile -> fwrite_unlocked -> OS page cache -> 磁盘收益:
-
业务线程避免磁盘 I/O
-
批量写提高吞吐,减少系统调用频率
-
锁粒度可进一步优化(双缓冲/线程本地缓冲)
2.3 类关系图(UML)
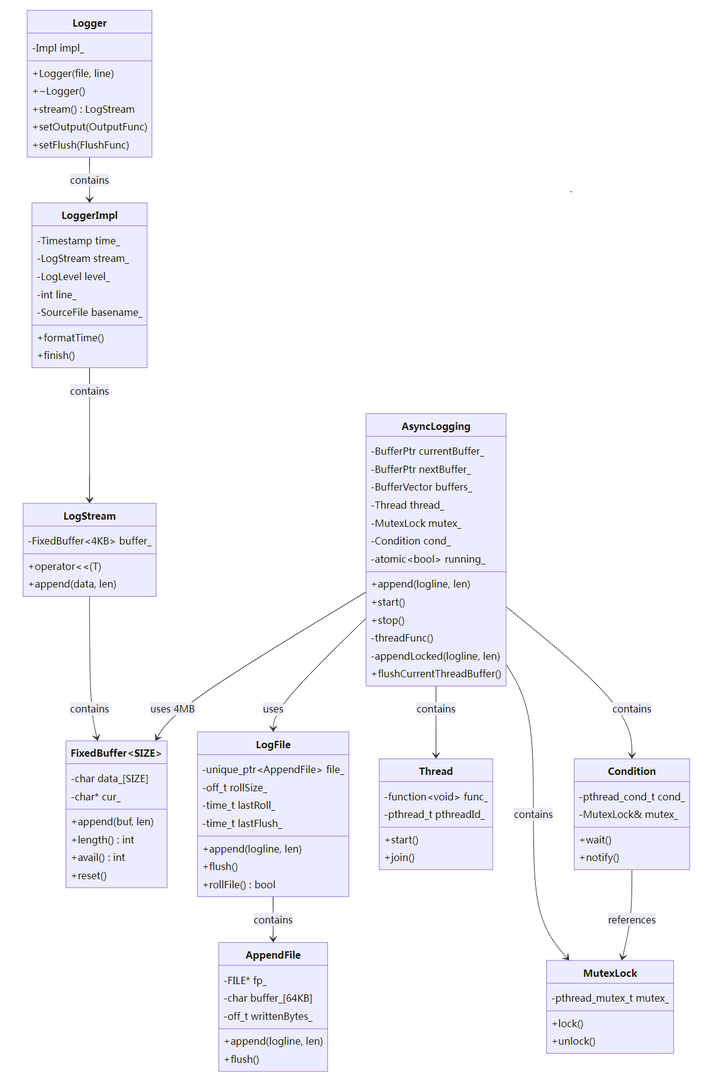
3. 模块拆解与职责
3.1 Logger / Logging.*:日志格式化与输出回调
-
负责拼接日志头部:时间戳、线程 id、级别、错误码等。
-
最终在 Logger::~Logger() 中把 LogStream 缓冲区交给 g_output。
-
g_output 默认输出到 stdout,可被替换为 asyncOutput(异步输出)。
关键点:
-
使用线程局部缓存 t_time/t_lastSecond:只在"秒变化"时格式化日期时间,降低成本。
-
我们新增优化:微秒部分从 snprintf 改为 手写固定 6 位拼接,减少热路径开销。
3.1.1 时间戳缓存的具体实现(降低 gmtime_r 调用频率)
代码逻辑(Logging.cc::Logger::Impl::formatTime()):
__thread char t_time[64]; // 缓存 "YYYYMMDD HH:MM:SS" 部分
__thread time_t t_lastSecond; // 上次格式化的秒数
void Logger::Impl::formatTime() {
int64_t microSecondsSinceEpoch = time_.microSecondsSinceEpoch();
time_t seconds = microSecondsSinceEpoch / 1000000;
int microseconds = microSecondsSinceEpoch % 1000000;
if (seconds != t_lastSecond) { // 只在"秒变化"时才调用 gmtime_r + snprintf
t_lastSecond = seconds;
struct tm tm_time;
::gmtime_r(&seconds, &tm_time);
snprintf(t_time, sizeof(t_time), "%4d%02d%02d %02d:%02d:%02d", ...);
}
// 微秒部分:每条日志都要拼,但我们已优化为手写 6 位数字(不再 snprintf)
formatMicroseconds(microseconds, ...); // 固定 6 位数字拼接
stream_ << T(t_time, 17) << ".XXXXXX " << ...;
}收益量化:
-
gmtime_r + snprintf 日期时间:约 100~200 ns(取决于 CPU)
-
缓存后:同一秒内后续日志只需读 t_time(几 ns)
-
在高 QPS 场景下(单秒百万条),节省 ~100M ns = 0.1 秒 CPU 时间
3.2 LogStream.*:高性能字符串拼接(小对象、固定缓冲)
-
LogStream 内部用 FixedBuffer<kSmallBuffer>(默认 4KB)保存一条日志的拼接结果。
-
使用自实现 convert() 做整数转字符串(减少 sprintf)。
-
我们新增优化:增加 operator<<(const char (&)N),对 字符串字面量 避免 strlen。
3.3 AsyncLogging.*:异步日志核心(缓冲、队列、后台线程)
AsyncLogging 的核心是"缓冲 + 线程同步 + 批量写":
-
业务线程调用 append() 把日志追加到内存缓冲。
-
缓冲满则把当前缓冲移入队列 buffers_,并唤醒后台线程。
-
后台线程把 buffers_ 交换到本地 buffersToWrite(缩短持锁时间),然后批量写入文件。
3.3.1 缓冲区大小选择的依据(为什么 4MB/64KB)
后台大 buffer(4MB):kLargeBuffer = 4000*1000
-
目的:减少系统调用频率;一次 fwrite 可以写入更大块
-
trade-off:太大会导致内存占用高、单次拷贝延迟增加;太小会频繁 swap/notify
-
经验值:4MB 在多数场景下能让"批量写"收益最大化,同时内存可控(预留 16 个 buffer 也只约 64MB)
TLS staging buffer(64KB):
-
目的:降低每条日志加锁频率;典型日志 100~200 字节,64KB 可攒 300~600 条
-
trade-off:太小会让"降锁"效果不明显;太大会在线程退出时残留更多数据(需要显式 flush)
-
实现:FixedBuffer<64*1024>,与后台大 buffer 解耦
3.3.2 项目自带的关键优化
-
双缓冲:currentBuffer_ + nextBuffer_,减少频繁 new。
-
双队列交换:buffers_.swap(buffersToWrite),让"落盘写文件"在无锁状态执行。
-
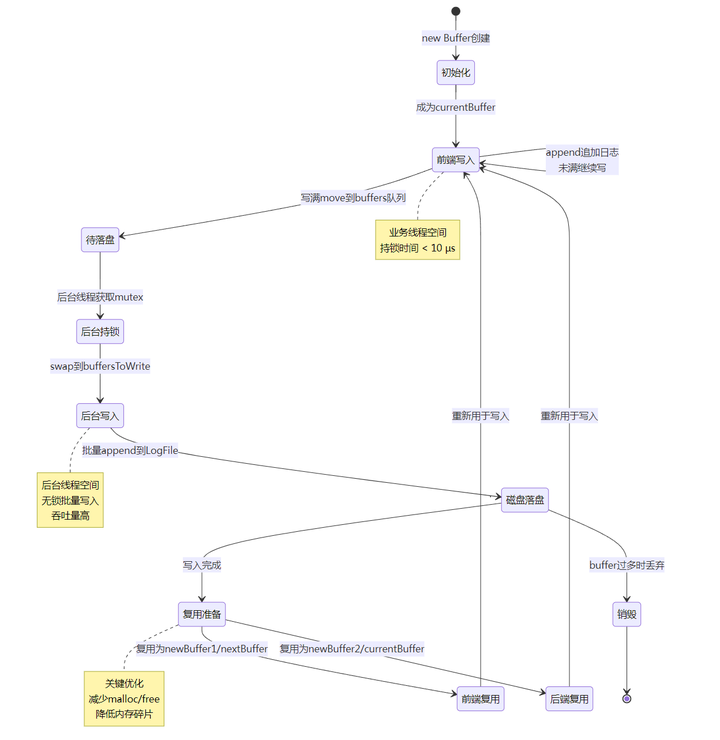
buffer 复用:后台线程把写完的 buffer 复用回 newBuffer1/newBuffer2,减少 malloc/free。
-
丢弃策略:当积压 buffer 过多(>25)时丢弃并写入告警(防止内存无限增长)。
3.3.3 我们新增/修正的关键优化
flush 语义修正:后台线程不再"每批写完都 flush",改为按 flushInterval 时间间隔 flush。
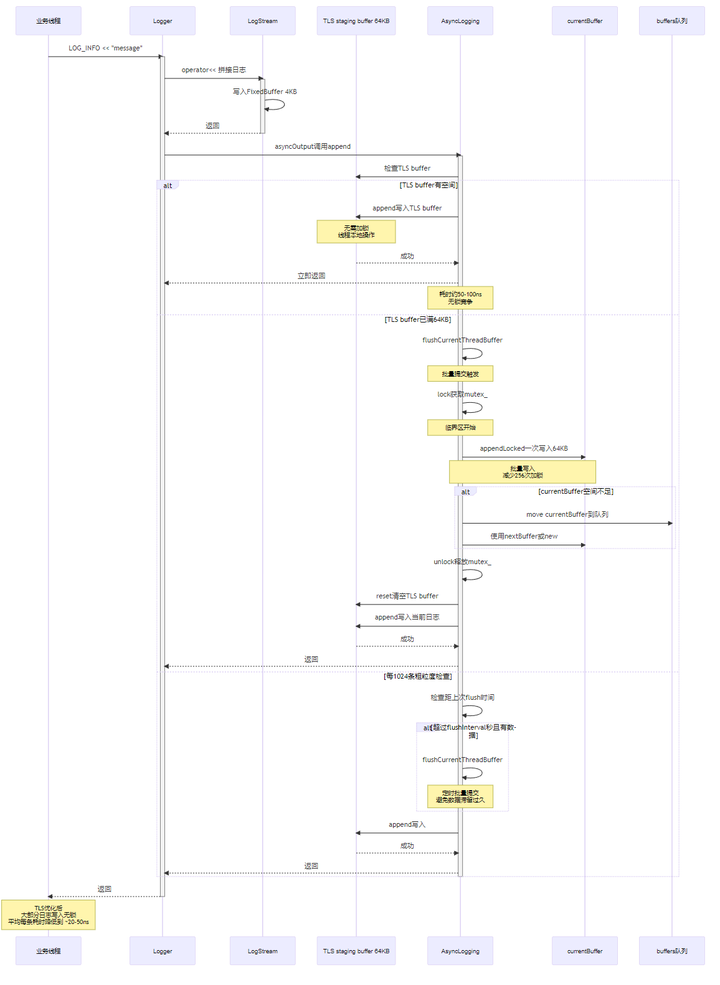
thread-local 前端缓冲(降锁):业务线程先写入 64KB TLS staging buffer,满了/到时间再一次性提交,减少每条日志的 mutex 开销。
注意:TLS 方案保持"同线程内顺序",不保证跨线程严格全局顺序(并发下本就难保证)。
TLS buffer 生命周期:
-
创建:首次 append 时 thread_local 自动构造
-
提交:满 64KB / 累计 256 条 / 距上次提交超过粗粒度时间阈值
-
清理:主线程 stop() 会调用 flushCurrentThreadBuffer() 尝试提交当前线程残留
3.4 LogFile.* / FileUtil.*:文件滚动与落盘实现
LogFile 负责:
-
根据 rollSize 判断是否需要滚动文件
-
按天/按时间窗口组织文件名
FileUtil::AppendFile 负责实际写入:
-
fopen(...,"ae")(close-on-exec)
-
setbuffer 设置用户态缓冲(默认 64KB)
-
fwrite_unlocked 加速写入(单写线程场景适用)
3.4.1 为什么用 fwrite_unlocked + setbuffer(组合原理)
setbuffer(用户态缓冲):
-
默认情况:fwrite 会用 stdio 内部的小缓冲(通常 8KB),写满才调用 write 系统调用
-
setbuffer(fp, buffer, 64KB):把用户态缓冲扩大到 64KB,减少系统调用频率
-
收益:减少用户态 → 内核态切换次数;提升吞吐
fwrite_unlocked(无锁 stdio):
-
标准 fwrite 内部会加锁(支持多线程并发写同一 FILE*)
-
本项目只有后台单线程写文件,不需要这个锁
-
fwrite_unlocked:跳过 FILE* 内部的 flockfile/funlockfile,降低开销
-
收益:每次写少 ~10~20 ns(高吞吐时累积可观)
注意:fwrite_unlocked 只能在"确定单线程写"时用,否则会数据竞争。
4. 关键设计:双缓冲、批量写、缩短锁粒度
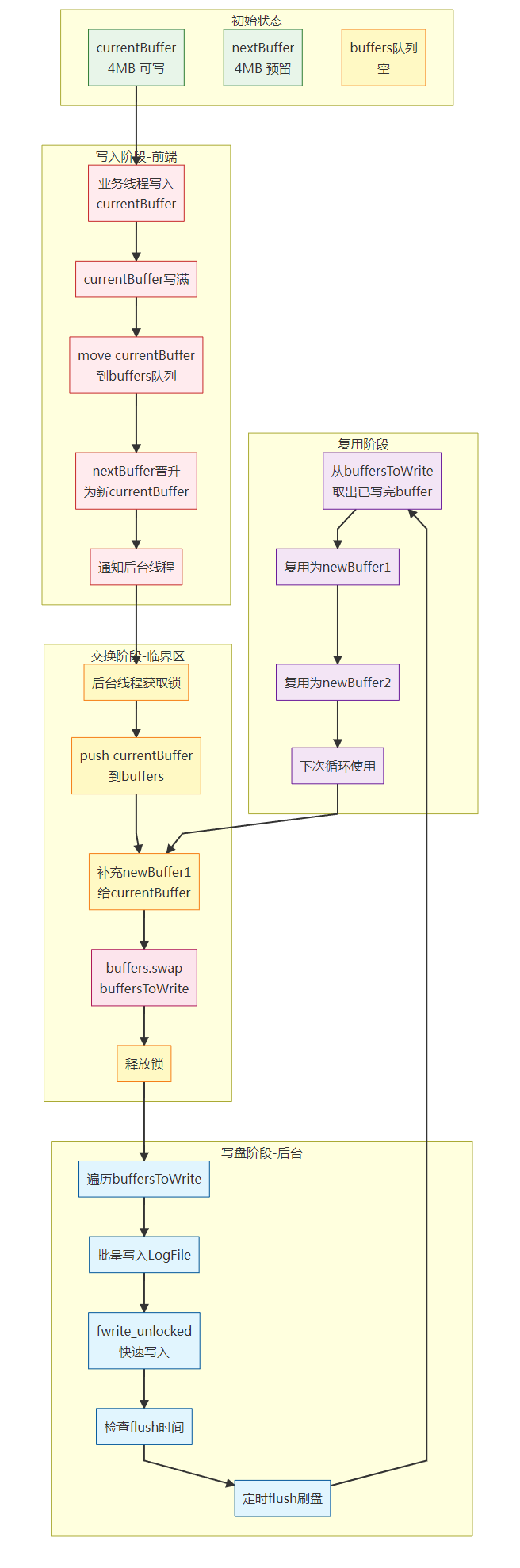
4.1 双缓冲(currentBuffer_ / nextBuffer_)
目的:减少内存分配。
正常写入:业务线程向 currentBuffer_ append
写满:把 currentBuffer_ move 到 buffers_
-
优先复用 nextBuffer_ 作为新的 currentBuffer_
-
nextBuffer_ 为空才 new(Rarely happens)
4.2 双队列 swap(前端队列 → 后端本地队列)
目的:让"写磁盘"阶段不持锁。
后台线程拿锁做很短的事情:
-
等待条件变量或超时
-
把 currentBuffer_ 推入 buffers_
-
buffers_.swap(buffersToWrite) 把所有待写数据移动到本地变量
释放锁后:
- 遍历 buffersToWrite,批量 output.append(...)
4.2.1 为什么 swap 能显著缩短临界区(持锁时间对比)
如果不用双队列 swap(伪代码):
lock(mutex);
for (auto& buf : buffers_) {
output.append(buf->data(), buf->length()); // 持锁写文件,阻塞前端 append
}
buffers_.clear();
unlock(mutex);持锁时间 = 遍历 + 写文件 + 清理,可能数百 ms(取决于磁盘 I/O)
用双队列 swap(实际代码):
lock(mutex);
buffers_.swap(buffersToWrite); // O(1),只交换两个 vector 的内部指针
unlock(mutex); // 持锁时间降到 < 1 µs
// 释放锁后批量写(不影响前端 append)
for (auto& buf : buffersToWrite) {
output.append(buf->data(), buf->length());
}持锁时间 = swap(几条指令)+ 其他准备,通常 < 10 µs
收益量化:
-
临界区从"毫秒级"降到"微秒级",锁竞争显著降低
-
前端业务线程 append() 几乎不会因为"后台正在写文件"而被阻塞
4.3 批量写入
目的:减少系统调用次数,提高吞吐。
-
output.append(buffer->data(), buffer->length()) 以"块"为单位写入
-
FileUtil::AppendFile 使用 fwrite_unlocked + setbuffer,进一步降低开销
4.4 核心流程伪代码
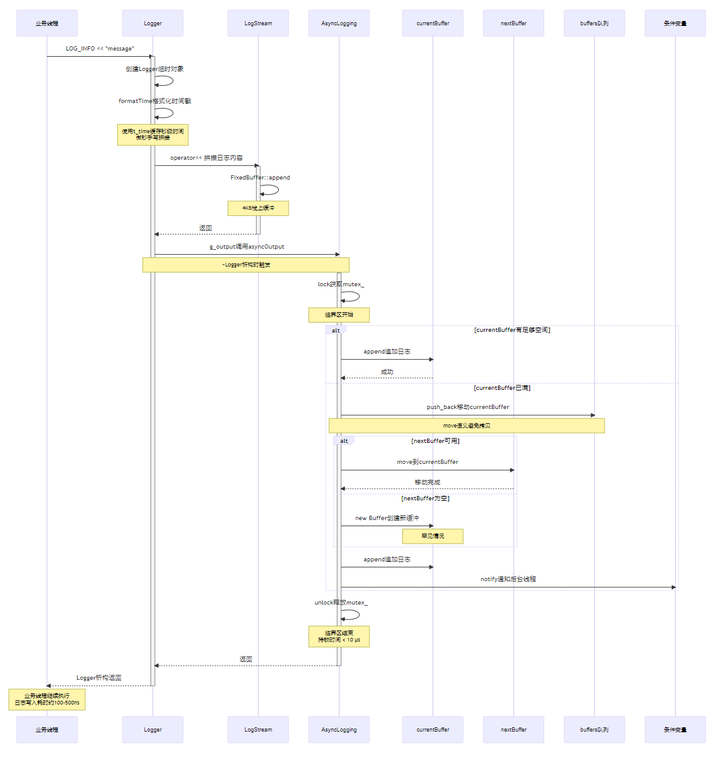
4.4.0 业务线程写日志完整时序图(无 TLS 优化版本)
4.4.1 业务线程写日志完整时序图(TLS 优化版本)
4.4.2 业务线程 append(双缓冲版本)
append(logline):
lock(mutex)
if currentBuffer 有空间:
currentBuffer.append(logline)
else:
buffers.push_back(move(currentBuffer))
currentBuffer = nextBuffer ? move(nextBuffer) : new Buffer
currentBuffer.append(logline)
notify(cond)
unlock(mutex)4.4.3 后台线程批量落盘完整时序图
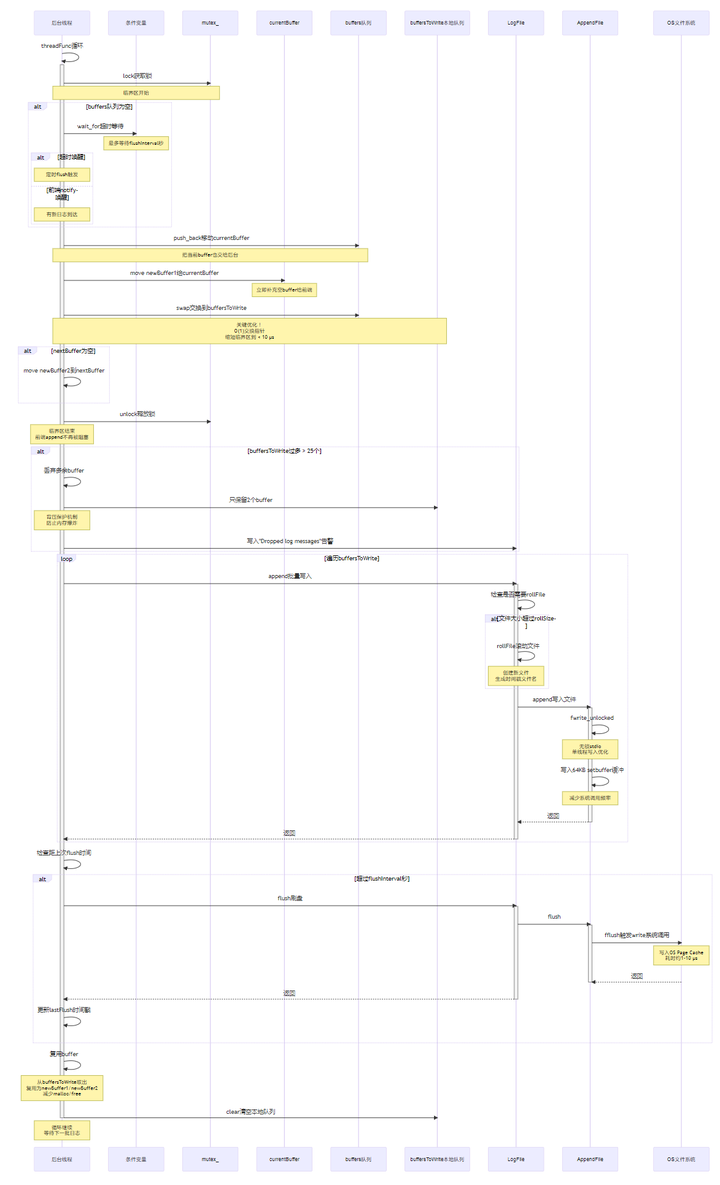
4.4.4 后台线程 threadFunc(双队列 swap + 批量写)
threadFunc():
while running:
lock(mutex)
if buffers empty:
wait(cond, flushInterval)
buffers.push_back(move(currentBuffer)) // 把当前 buffer 也交给后台写
currentBuffer = move(newBuffer1) // 立刻补一个空 buffer 给前端
buffersToWrite.swap(buffers) // 关键:缩短临界区
if nextBuffer empty:
nextBuffer = move(newBuffer2)
unlock(mutex)
for b in buffersToWrite:
output.append(b.data, b.len) // 无锁批量写
if 到了 flushInterval:
output.flush()
回收 buffersToWrite 的部分 buffer 复用为 newBuffer1/newBuffer2
buffersToWrite.clear()4.4.5 Buffer 状态转换图
4.4.6 双缓冲机制详细图
4.4.7 TLS staging buffer(降锁)版本(业务线程)
append(logline):
写入 thread_local tlsBuffer
如果 tlsBuffer 满了 / 到时间:
lock(mutex)
appendLocked(tlsBuffer.data, tlsBuffer.len) // 一次提交一大块
tlsBuffer.reset()
notify(cond)
unlock(mutex)4.5 TLS Buffer 优化对比图
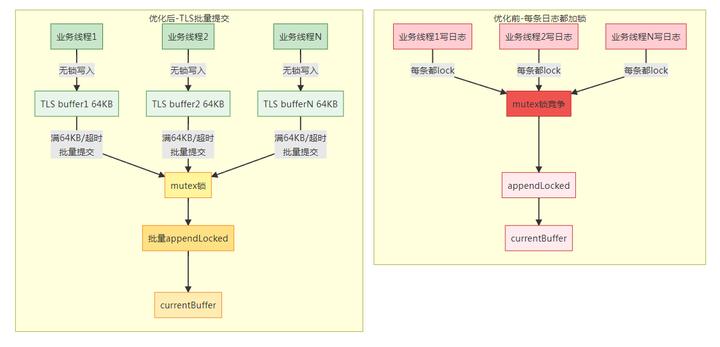
性能对比量化:
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 每条日志加锁次数 | 1 次 | 约 1/256 次 | 降低 98.6% |
| 单次 lock/unlock 开销 | 20-30 ns | 20-30 ns | 不变 |
| 平均每条锁开销 | 20-30 ns | ~0.1 ns | 降低 99%+ |
| 锁竞争概率 | 高(每条都竞争) | 极低(批量提交) | 显著降低 |
| 单线程 500 万条日志锁开销 | ~100-150 ms | ~0.5 ms | 节省约 100ms |
4.6 时间戳格式化优化流程图

优化效果:
gmtime_r + snprintf:约 100-200 ns(仅在秒变化时调用)
缓存命中(同一秒内):约 2-5 ns(直接读 t_time)
微秒拼接(每条必做):从 30-50 ns(snprintf)降到 5-10 ns(手写)
单秒百万日志场景:
-
优化前:1 次秒格式化(200ns) + 100 万次微秒 snprintf(30-50 ms)= ~50 ms
-
优化后:1 次秒格式化(200ns) + 100 万次手写拼接(5-10 ms)= ~10 ms
-
节省约 40 ms CPU 时间
4.7 文件滚动与 Flush 策略图
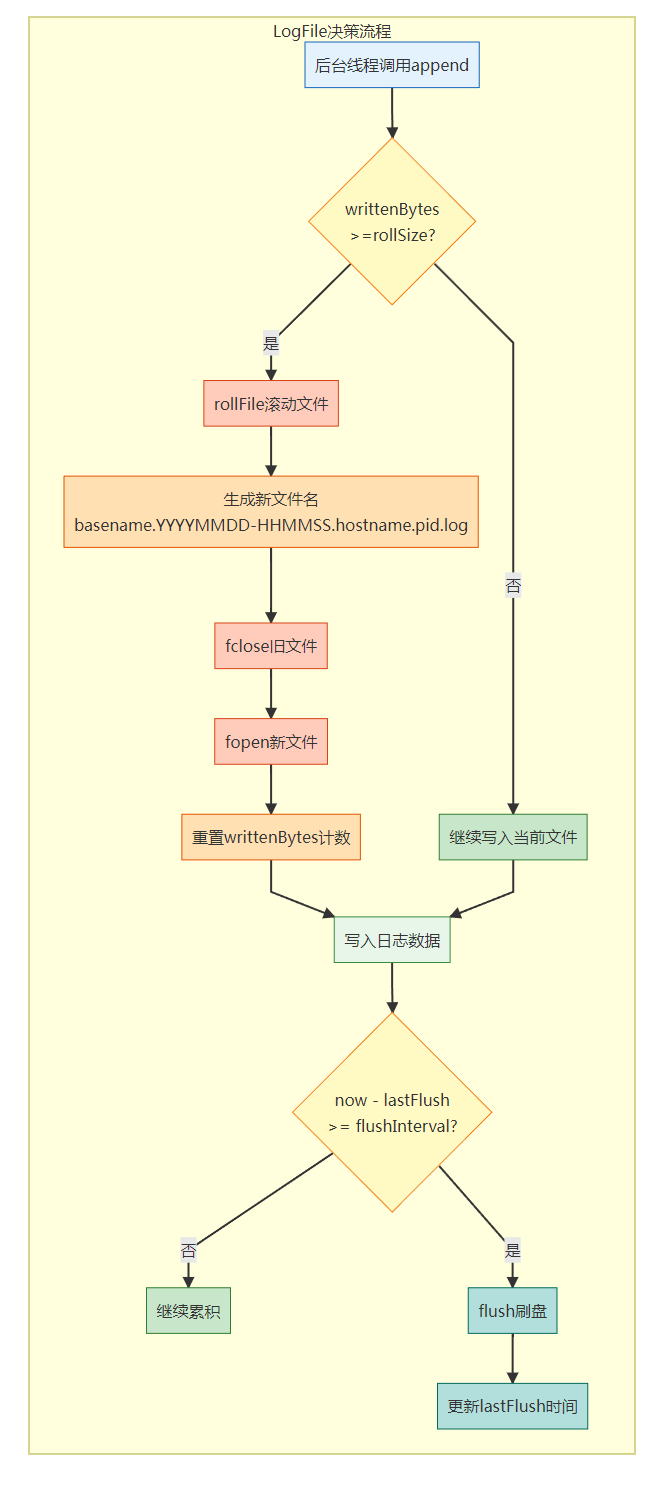
参数选择依据:
rollSize = 100MB ~ 1GB:
-
太小(1MB):频繁 rollFile 导致 fopen/fclose 开销大
-
太大(>10GB):单文件过大不便传输、分析
-
推荐:100MB-1GB,平衡滚动频率与文件大小
flushInterval = 1 ~ 3 秒:
-
太小(每批 flush):吞吐降低,fflush 开销累积
-
太大(>10 秒):进程异常退出时日志滞留风险高
-
推荐:1-3 秒,平衡可靠性与性能
5. 我们做过的优化清单(按"影响路径"分层)
把优化分层是面试的关键:能说明你不是"乱改",而是按热路径定位与成本模型做工程取舍。
5.1 压测参数层(让测试更接近真实瓶颈)
-
rollSize 过小会掩盖真实吞吐上限:频繁 rollFile()/fopen 会显著拖慢 QPS。
-
已支持通过 main_log_test 参数设置:
--roll=100M、--flush=1、--num=...
5.2 I/O 策略层(flush/roll)
-
flush 过频:会把用户态缓冲优势打掉 → QPS 下降
-
修正:AsyncLogging 按 flushInterval 时间间隔 flush,而不是每批 flush
5.3 并发同步层(锁竞争)
-
原始:每条日志进 AsyncLogging::append() 都要加锁
-
优化:TLS staging buffer(64KB)攒一批再提交,显著减少 lock/unlock 次数
5.4 CPU 热路径层(格式化与字符串处理)
-
微秒格式化去 snprintf:固定 6 位数字手写拼接
-
字面量避免 strlen:operator<<(const char(&)N)
5.4.1 为什么微秒拼接要去 snprintf(成本对比)
优化前(使用 Fmt 内部 snprintf):
Fmt us(".%06dZ ", microseconds); // 内部:snprintf(buf, 32, ".%06dZ ", microseconds);
stream_ << T(us.data(), us.length());- snprintf 格式化 6 位数字:约 30~50 ns(需要解析格式串、填充、判断宽度等)
优化后(手写固定 6 位拼接):
char buf[10];
buf[0] = '.';
buf[1] = '0' + (microseconds / 100000) % 10;
buf[2] = '0' + (microseconds / 10000) % 10;
buf[3] = '0' + (microseconds / 1000) % 10;
buf[4] = '0' + (microseconds / 100) % 10;
buf[5] = '0' + (microseconds / 10) % 10;
buf[6] = '0' + microseconds % 10;
buf[7] = 'Z';
buf[8] = ' ';
stream_.append(buf, 9);- 固定 6 位数字拼接:约 5~10 ns(几次除法/取模,全部内联)
收益量化:每条日志节省 ~20~40 ns;100 万条日志累计节省 ~20~40 ms CPU 时间。
5.4.2 为什么字面量要避免 strlen(成本对比)
优化前:
LogStream& operator<<(const char* str) {
buffer_.append(str, strlen(str)); // strlen 需要遍历到 '\0'
}- strlen("Root Error Message!"):约 5~10 ns(19 字符,简单但热路径累积)
优化后:
template <int N>
LogStream& operator<<(const char (&arr)[N]) {
buffer_.append(arr, N - 1); // N 编译期已知,不需要 strlen
}- 编译期常量 N-1:0 ns 运行时开销
收益量化:典型一条日志有 3~5 个字面量片段,累计节省 15~50 ns/条。
6. 本项目体现的 C++11/11+ 特性清单
6.1 语言特性
-
nullptr:更安全的空指针语义(如 t_tlsOwner = nullptr、NULL 旧写法的替代)
-
auto / 范围 for:更简洁的遍历与类型推导(如后台线程遍历 buffersToWrite)
-
右值引用与移动语义(std::move):避免深拷贝,尤其在 buffer 转移/队列 swap 中关键
-
thread_local(C++11 起):线程本地缓存/缓冲(我们用它做 staging buffer;项目也大量使用 __thread)
-
static_assert:编译期约束(如 Timestamp 大小校验)
-
enum/强类型设计:测试模式等(建议面试时可讲成 enum class 更安全)
6.2 标准库特性
-
std::atomic:无锁状态标志(running_)
-
std::unique_ptr:RAII 管理 buffer/file 指针,避免泄漏(BufferPtr、file_)
-
std::function / std::bind:线程入口绑定成员函数(thread_(bind(&AsyncLogging::threadFunc,...)))
-
std::vector + reserve:减少扩容与拷贝(buffers_.reserve(16))
6.3 关键 C++ 特性应用图解
6.3.1 移动语义与零拷贝传递
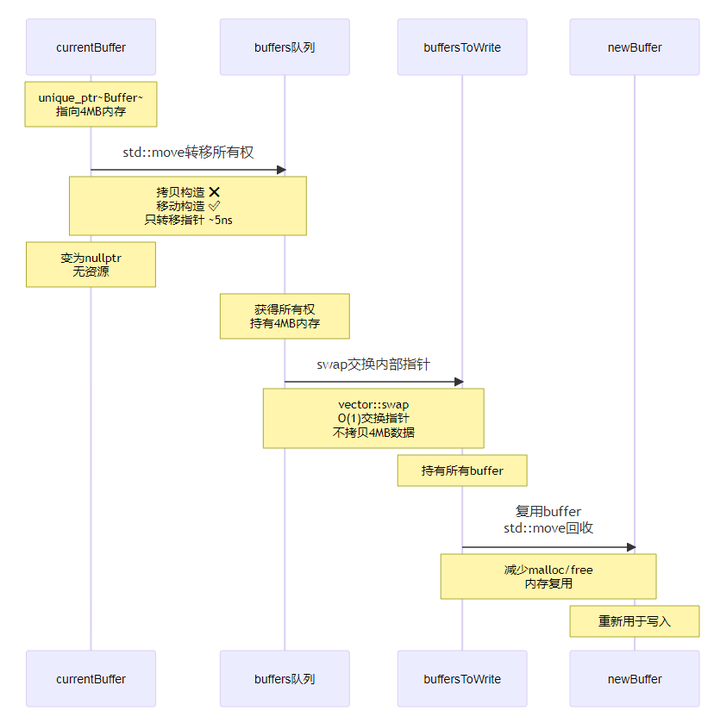
性能对比:
| 操作 | 拷贝方式 | 移动方式 | 差异 |
|---|---|---|---|
| 转移4MB buffer | memcpy 4MB ~1-2 ms | 交换指针 ~5 ns | 快 20万倍 |
| 内存分配 | new + delete ~100-500 ns | 复用 ~0 ns | 节省分配开销 |
| 异常安全 | 可能泄漏 | unique_ptr自动释放 | RAII保证 |
6.3.2 RAII资源管理模式
6.3.3 thread_local 线程本地存储原理
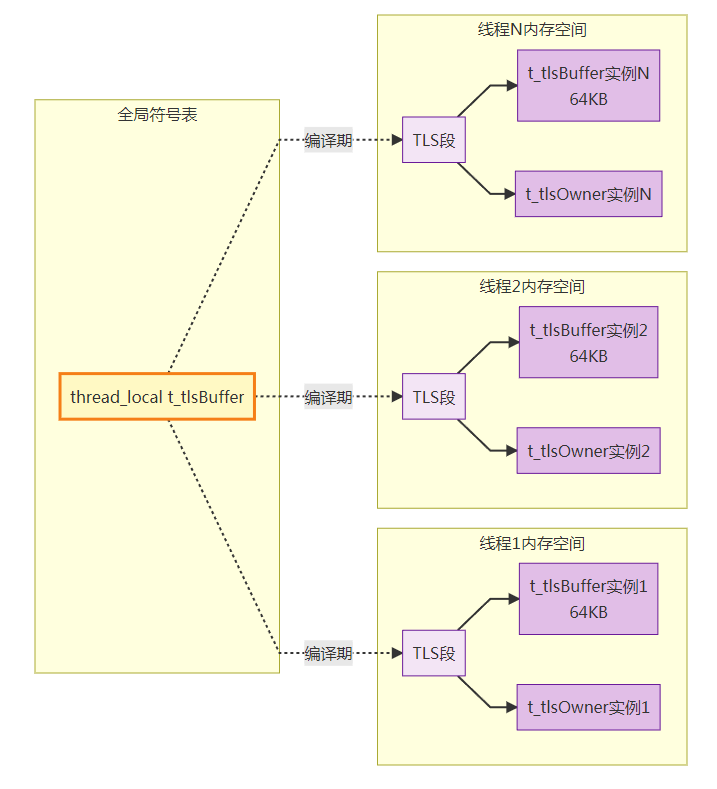
访问过程:
-
编译期:thread_local 变量放入特殊的 TLS 段(.tdata/.tbss)
-
线程创建时:为每个线程分配独立的 TLS 副本
-
运行时访问:通过 fs 寄存器(x86-64)或平台相关机制快速索引
-
性能:比 pthread_getspecific 快(直接寄存器偏移 vs 哈希查找)
6.3.4 atomic 无锁同步
为什么用 atomic:
-
✅ 无锁读取:多个线程读 running_ 不需要加锁
-
✅ 跨核可见:保证内存序,修改立即对其他核可见
-
✅ 避免编译器优化:防止编译器把循环中的 running_ 优化到寄存器
-
❌ 如果用普通 bool:可能被缓存在寄存器,后台线程看不到修改,永不退出
6.3 工程化技巧
-
RAII:MutexLockGuard 确保锁释放
-
缩短临界区:swap 双队列
-
热路径避免系统调用:批量写 + 缓存时间戳
6.4 C++11/11+ 特性 → 代码位置 → 面试话术
| 特性 | 代码位置(示例) | 解决的问题 | 面试一句话 |
|---|---|---|---|
| std::atomic<bool> | AsyncLogging.h:running_ | 状态跨线程可见,避免数据竞争 | "用 atomic 管理线程生命周期状态,保证可见性与无数据竞争。" |
| std::unique_ptr | AsyncLogging.h:BufferPtr;LogFile.h:file_ | 自动资源管理,避免泄漏 | "用 unique_ptr 做 RAII,异常/早返回也不会泄漏资源。" |
| std::move | AsyncLogging.cc:buffer 转移/复用 | 避免深拷贝,降低开销 | "高吞吐路径只移动所有权,不做拷贝。" |
| std::function/std::bind | AsyncLogging.cc:线程入口绑定成员函数 | 更易组合与复用 | "线程函数用 bind 绑定成员函数,结构更清晰。" |
| thread_local | AsyncLogging.cc:TLS staging buffer | 降锁、缓存热数据 | "把高频写先落到线程本地,批量提交减少锁竞争。" |
| static_assert | TimeStamp.cc:类型/大小校验 | 编译期约束 | "用 static_assert 把假设写进编译期,防止平台差异。" |
| range-for | AsyncLogging.cc:遍历 buffersToWrite | 少写错、更简洁 | "遍历容器用 range-for,减少手写迭代器错误。" |
| nullptr | AsyncLogging.cc:TLS owner 等 | 安全空指针 | "用 nullptr 代替 NULL,避免重载歧义。" |