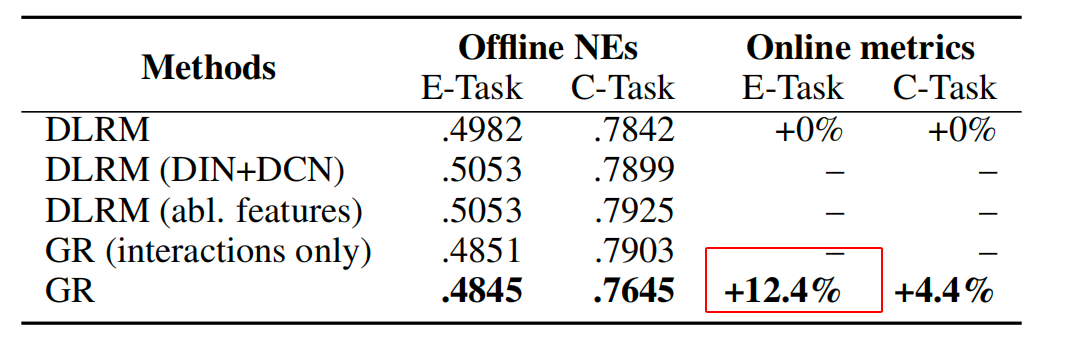
Meta 24年release的工作,属于LLM对于推荐的颠覆性创新工作,End-To-End推荐的第一篇工作,效果也是惊人,在Meta业务下有12%的业务指标提升!
下面从几个方面进行该工作的记录:
一 创新缘起
先说DLRMs的缺点,特征异质结构(features in recommendation systems lack explicit structures),没有 NLP/CV 那种自然结构,使得深度模型无法从结构中自动学习规律,导致 scaling 受限,不符合Scaling Law规律。
推荐系统的输入长这样:用户年龄、用户星级、设备型号、过去 7 天点击次数、过去 30 天浏览 CTR、用户行为序列(但很短)
这些特征特点是:
a 异构的(heterogeneous)
每个特征类型完全不同:有些是 float,有些是类别 embedding,有些是计数统计,有些是序列,有些是罕见高维 id(用户 id/商品 id)
不像 NLP:所有 token 都是同一类型
b 没有固定的顺序位置
语言模型的 token 是:x1, x2, x3, ... 按句子顺序排列;推荐模型的特征却是:性别, 年龄, 星级, 城市, 设备型号, 7天CTR, 30天ratio, 商品品类, 标签...
这些特征之间没有天然顺序,也没有上下文关系。
c 没有空间邻接关系
在图像中:(x,y) 像素和旁边像素关系固定,卷积核可以移动;而推荐中的特征:年龄和城市之间没有空间关系,CTR 和 用户 id 之间也没有"邻居",模型不能像 CNN 那样共享 pattern。
d 没有统一 token 表示
NLP → 全是 tokens
CV → 全是 pixels
推荐 → 每个特征意义完全独立,没有 "word-like token" 可以堆叠大模型去捕捉模式
二 实现细节
作为一个全新的生成式推荐架构,架构图如下:
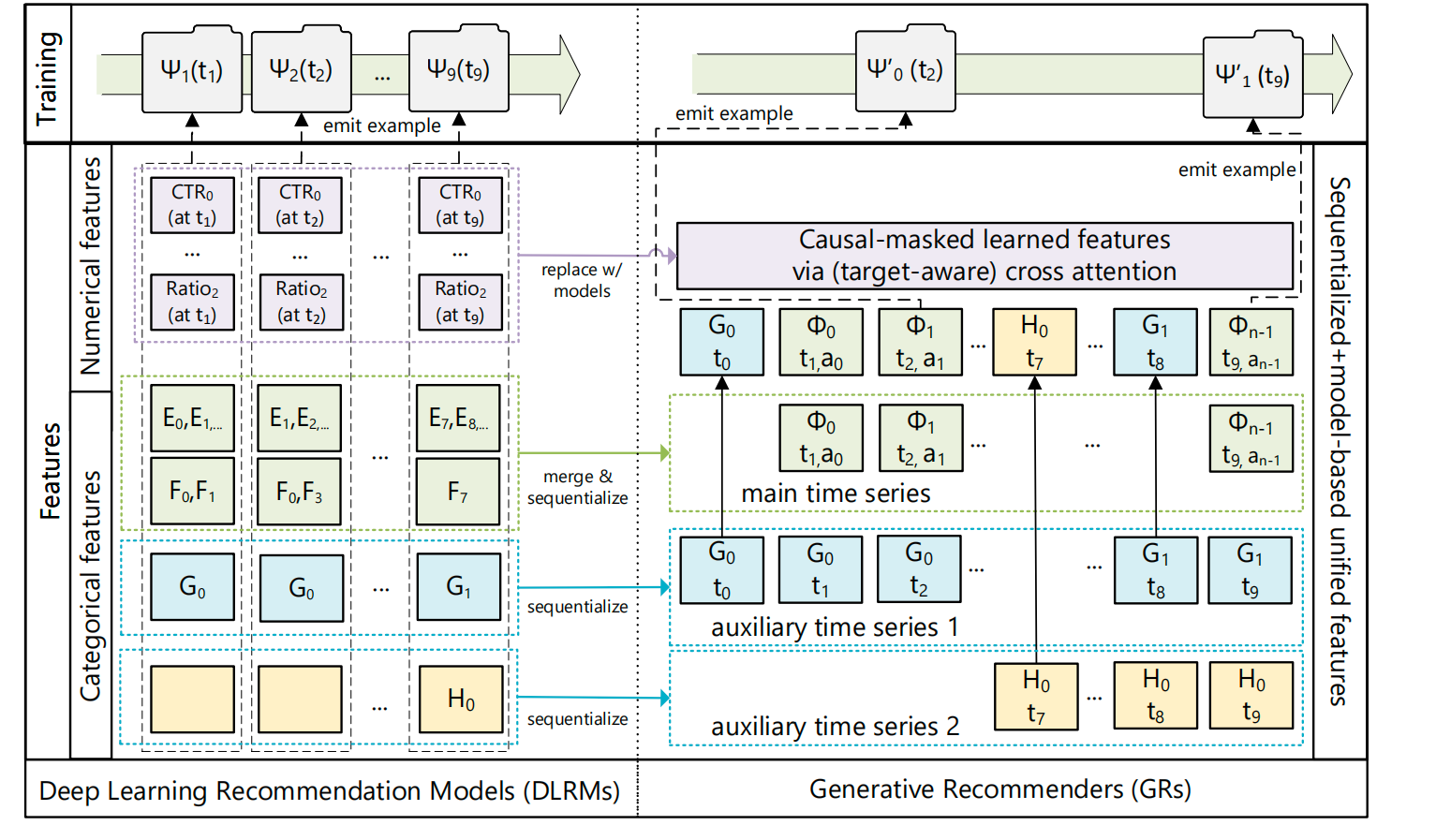
2.1 Input
先梳理下DLRMs的输入,一版有三类,类别特征(Sparse)/数值特征(Dense or Numberical)/序列特征(varlen sparse or sequence)。
这里的输入把类别特征和序列特征融合到了一起,至于数值特征则直接摒弃。GR 把所有特征变成一个长序列,让模型直接"自己学"这些统计特征。当序列足够长时,GR 能表达的特征空间 ≈ DLRM 全部特征,甚至更强。(We sequentialize and unify the heterogeneous feature space in DLRMs, with the new approach approximating the full DLRM feature space as sequence length tends to infinity )
分为主序列和辅助序列(We first select the longest time series ... as the main time series/
The remaining features are generally time series that slowly change over time)
2.1.1 主时间序列(main time series)
首先出场的是一个统一的主时间序列(main time series),把所有 "用户 × item 的交互行为(及 item 的属性)",按时间合并起来形成的最长行为序列,是 GR 序列化的骨架,对应架构图里的E/F,形成 ϕ i \phi_i ϕi 序列。
a 用户原始行为日志
假设这是一个短视频+权益+套餐混合推荐场景,某个用户过去的行为日志如下(按时间):
| 时间 | 行为类型 | item_id | item类型 | 主题/标签 |
|---|---|---|---|---|
| t1 | 展示曝光 | 990027088 | 流量包 | 「省内流量」「5G」 |
| t2 | 点击 | 990027088 | 流量包 | 「省内流量」「5G」 |
| t3 | 展示曝光 | 3700066543 | 宽带升级 | 「千兆宽带」「家庭」 |
| t4 | 浏览详情 | 3700066543 | 宽带升级 | 「千兆宽带」「家庭」 |
| t5 | 点击 | 37100001862 | 短期流量包 | 「叠加包」「短期」 |
| t6 | 订购成功 | 37100001862 | 短期流量包 | 「叠加包」「短期」 |
| t7 | 展示曝光 | 990024443 | 视频会员权益 | 「视频」「会员」「权益」 |
| t8 | 点击 | 990024443 | 视频会员权益 | 「视频」「会员」「权益」 |
这是典型的:
"items user engaged with" = 用户与具体产品(item)的交互行为序列
b 把行为序列当作 main time series
在 GR 里,这些会先被视为一条主时间线:
t1: 展示 item 990027088
t2: 点击 item 990027088
t3: 展示 item 3700066543
t4: 浏览 item 3700066543
t5: 点击 item 37100001862
t6: 订购 item 37100001862
t7: 展示 item 990024443
t8: 点击 item 990024443此时:
- 只关心"用户 × item × 行为 × 时间"
- 还没合并城市/套餐/星级等慢特征
- 这条就是 GR 所说的 "最长的时间序列",用来当作 main series
c main series 在 GR 里的 token 形式
模型不会直接看到 "点击 流量包" 这种中文,而是拆成一串 token;
一个时间步(比如 t5)可能被编码成:
[TS=t5]
[ACTION=click]
[ITEM_ID=37100001862]
[ITEM_TYPE=short_data_pack]
[ITEM_TAG=叠加包]
[ITEM_TAG=短期]
[SURFACE=homepage] # 来自哪个入口那么整条 main time series 就会变成类似:
# t1
[TS=t1] [ACTION=impression] [ITEM_ID=990027088] [ITEM_TYPE=data_pack] [TAG=省内流量] [TAG=5G]
# t2
[TS=t2] [ACTION=click] [ITEM_ID=990027088] [ITEM_TYPE=data_pack] [TAG=省内流量] [TAG=5G]
# t3
[TS=t3] [ACTION=impression] [ITEM_ID=3700066543] [ITEM_TYPE=broadband] [TAG=千兆宽带] [TAG=家庭]
# t4
[TS=t4] [ACTION=view_detail] [ITEM_ID=3700066543] [ITEM_TYPE=broadband] [TAG=千兆宽带] [TAG=家庭]
# t5
[TS=t5] [ACTION=click] [ITEM_ID=37100001862] [ITEM_TYPE=short_data_pack] [TAG=叠加包] [TAG=短期]
# t6
[TS=t6] [ACTION=purchase] [ITEM_ID=37100001862] [ITEM_TYPE=short_data_pack] [TAG=叠加包] [TAG=短期]
# t7
[TS=t7] [ACTION=impression] [ITEM_ID=990024443] [ITEM_TYPE=video_privilege] [TAG=视频] [TAG=会员] [TAG=权益]
# t8
[TS=t8] [ACTION=click] [ITEM_ID=990024443] [ITEM_TYPE=video_privilege] [TAG=视频] [TAG=会员] [TAG=权益]这串就是 纯粹的 main time series:
- 每个 step 都是 "用户对某个 item 的一次 engagement + item 自身属性"
- 全部按时间排序
- 不含城市、套餐、星级等慢特征(那些之后再 merge)
2.1.2 辅助时间序列(auxiliary time series)
定义:那些不是行为,但也带时间属性、且变化速度比行为慢很多的特征序列。
换句话说:"所有除了主行为序列之外的、随时间缓慢变化的特征,都叫 auxiliary time series。"
一般有用户人口属性(demographics)、用户户长期偏好特征(interests)、用户设备/系统属性(device)等内容。对应架构图里,G 和 H 都是 auxiliary time series,但它们代表的是不同的"缓变特征类型"
进一步的举个例子
Auxiliary 1:套餐(main_plan_in_use)
真实时间序列例子:
t1: 套餐 = 99元全国通用
t300: 套餐 = 99元全国通用
t500: 套餐 = 129元5G融合
t900: 套餐 = 129元5G融合→ Segment 压缩:
t1: plan=99元
t500: plan=129元Auxiliary 2:城市(u_city)
真实城市变化日志:
t1: city=济南
t200: city=济南
t400: city=青岛
t800: city=青岛→ Segment 压缩后:
t1: city=济南
t400: city=青岛b 创建 auxiliary feature tokens
转换成 token 形式:
套餐 tokens(G 系列):
[TS=t1] [FEAT:plan=99]
[TS=t500] [FEAT:plan=129]城市 tokens(H 系列)
[TS=t1] [FEAT:city=济南]
[TS=t400] [FEAT:city=青岛]c 按时间戳 merge 到 main time series**
合并规则:
按真实时间顺序,将所有 auxiliary tokens 插入 main sequence。
(同时间戳可并列插入)
最终 Unified GR 序列(合并后的完整序列)
🔹 t1 时刻发生了 3 件事:城市、套餐变化、行为
[TS=t1] [FEAT:city=济南]
[TS=t1] [FEAT:plan=99]
[TS=t1] [ACTION=impression] [ITEM_ID=990027088] [ITEM_TYPE=data_pack] [TAG=省内流量] [TAG=5G]🔹 t2~t6:正常行为事件(没有辅特征变化)
[TS=t2] [ACTION=click] [ITEM_ID=990027088] [ITEM_TYPE=data_pack] [TAG=省内流量] [TAG=5G]
[TS=t3] [ACTION=impression] [ITEM_ID=3700066543] [ITEM_TYPE=broadband] [TAG=千兆宽带] [TAG=家庭]
[TS=t4] [ACTION=view_detail] [ITEM_ID=3700066543] [ITEM_TYPE=broadband] [TAG=千兆宽带] [TAG=家庭]
[TS=t5] [ACTION=click] [ITEM_ID=37100001862] [ITEM_TYPE=short_data_pack] [TAG=叠加包] [TAG=短期]
[TS=t6] [ACTION=purchase] [ITEM_ID=37100001862] [ITEM_TYPE=short_data_pack] [TAG=叠加包] [TAG=短期]🔹 t7~t8:继续行为事件
[TS=t7] [ACTION=impression] [ITEM_ID=990024443] [ITEM_TYPE=video_privilege] [TAG=视频][TAG=会员][TAG=权益]
[TS=t8] [ACTION=click] [ITEM_ID=990024443] [ITEM_TYPE=video_privilege] [TAG=视频][TAG=会员][TAG=权益]🔹 t400:城市变成青岛 → 插入 auxiliary token
[TS=t400] [FEAT:city=青岛](此时 main series 可能没有行为,但 auxiliary token 一样会出现在序列里)
🔹 t500:套餐升级 → 插入 auxiliary token
[TS=t500] [FEAT:plan=129]⭐ 最终 unified sequence(整合后序列完整版)
# 序列开始
[TS=t1] [FEAT:city=济南]
[TS=t1] [FEAT:plan=99]
[TS=t1] [ACTION=impression] [ITEM_ID=990027088] [ITEM_TYPE=data_pack] [TAG=省内流量] [TAG=5G]
[TS=t2] [ACTION=click] [ITEM_ID=990027088] [ITEM_TYPE=data_pack] [TAG=省内流量] [TAG=5G]
[TS=t3] [ACTION=impression] [ITEM_ID=3700066543] [ITEM_TYPE=broadband] [TAG=千兆宽带] [TAG=家庭]
[TS=t4] [ACTION=view_detail] [ITEM_ID=3700066543] [ITEM_TYPE=broadband] [TAG=千兆宽带] [TAG=家庭]
[TS=t5] [ACTION=click] [ITEM_ID=37100001862] [ITEM_TYPE=short_data_pack] [TAG=叠加包] [TAG=短期]
[TS=t6] [ACTION=purchase] [ITEM_ID=37100001862] [ITEM_TYPE=short_data_pack] [TAG=叠加包] [TAG=短期]
[TS=t7] [ACTION=impression] [ITEM_ID=990024443] [ITEM_TYPE=video_privilege] [TAG=视频] [TAG=会员] [TAG=权益]
[TS=t8] [ACTION=click] [ITEM_ID=990024443] [ITEM_TYPE=video_privilege] [TAG=视频] [TAG=会员] [TAG=权益]
# 缓变特征变化点
[TS=t400] [FEAT:city=青岛]
[TS=t500] [FEAT:plan=129]🎯 这就是 GR 中 "序列化 + auxiliary merge" 的完整过程
2. Output
传统推荐系统中,召回和排序通常是两个独立阶段;而 GR 通过将 item 与用户 action 交错编码进同一序列,使"推荐什么"和"这个推荐是否会被点击"都成为生成式模型的一部分,从而在统一的序列建模框架下同时支持召回和排序。

召回(Retrieval) 阶段输出
In recommendation system's retrieval stage, we learn a distribution
p ( Φ i + 1 ∣ u i ) p(\Phi_{i+1}\mid u_i) p(Φi+1∣ui) over Φ i + 1 ∈ X c \Phi_{i+1}\in \mathcal{X}_c Φi+1∈Xc, where u i u_i ui is the user's representation at token i. 学习的是给定当前用户状态,对所有候选 item 打分/建模偏好分布
Φi+1 表示"下一个候选 item 的特征表示"(不是 token id,而是 item 的语义特征)
与语言模型不同的是,推荐序列中的下一个 token 并不一定是正样本,且序列中还包含大量没有 engagement 语义的特征 token,因此 retrieval 的监督是稀疏且不连续的。
排序(Ranking) 阶段输出
ranking task to be formulated as p ( a i + 1 ∣ Φ 0 , a 0 , Φ 1 , a 1 , ... , Φ i + 1 ) p(a_{i+1} \mid Φ_0, a_0, Φ_1, a_1, \ldots, Φ_{i+1}) p(ai+1∣Φ0,a0,Φ1,a1,...,Φi+1)
简单来说,就是在看到目标 item Φᵢ₊₁ 的前提下,预测用户会采取什么行为
二. 模型细节:
整体是一个Encoder结构,如下图所示,多层堆叠,每一层为定制化的单元结构,叫Hierarchical Sequential Transduction Unit (HSTU) ,在图里是用一种颜色表示(蓝色/紫色/黄色都是一个Unit). 每个单元结构一共有三个子层:1)Pointwise Projection 2)Spatial Aggregation 3)Pointwise Transformation。
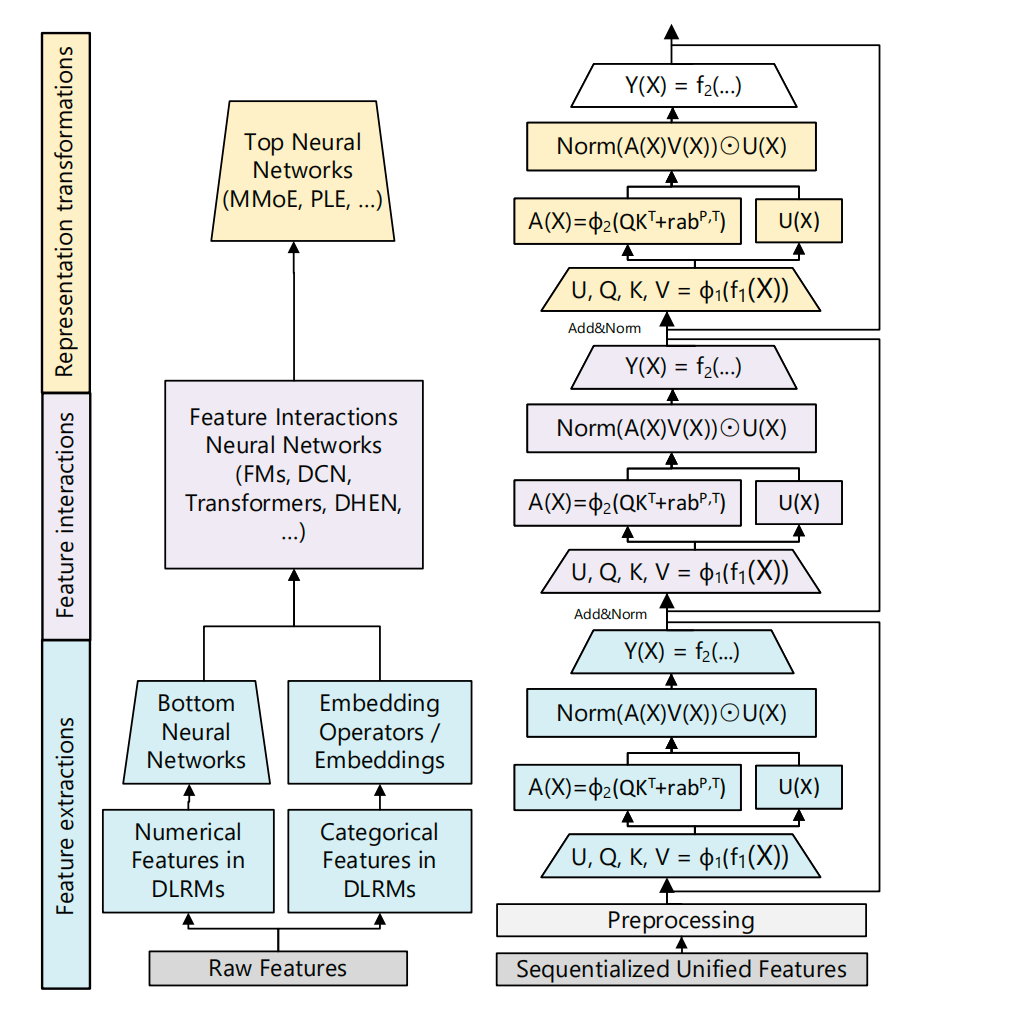
1 Pointwise Projection
投影层,如下公式所示
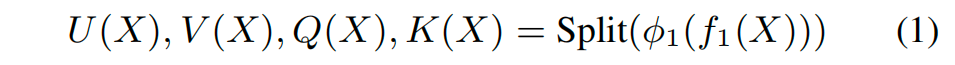
X ∈ ℝ^{L × d}, L为token数量,d是hidden dim, f i ( X ) f_i(X) fi(X) 是个MLP, ϕ 1 \phi_1 ϕ1 是SiLU非线性变换,这里和经典的Transformer的结构有两点明显的差异:
1) 首先是引入了一个U,在标准 Transformer 中,attention 的输出是通过
Attention ( Q , K , V ) + X \text{Attention}(Q,K,V) + X Attention(Q,K,V)+X
的 residual 方式回到主干;而在 HSTU 中,额外引入了一条并行的 用户状态流 U U U ,并在后续通过逐点乘(gating)的方式对 attention 结果进行调制。 也就是说, U U U 并不是一个简单的 residual,而是一个可学习、可调节强度的控制信号 ,用于在不使用 softmax 的前提下稳定 attention 的输出并保留偏好强度信息。
2) 其次 操作上存在差异 ,在标准 Transformer 里,我们通常会说 Q、K、V 各自有一套线性映射 ,每个 head 都对应一组 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV。HSTU 这里做的事情,其实不是换了一种能力更弱的做法,而是换了一种更工程友好的实现方式 :它直接用一个大的线性层,一次性把需要的表示全算出来: W = W U ∣ W Q ∣ W K ∣ W V W = \\, W_U \\mid W_Q \\mid W_K \\mid W_V \\, W=WU∣WQ∣WK∣WV
也就是说,一次线性变换得到一个 4 d 4d 4d 维的结果,然后再按通道把它拆成 U , Q , K , V U, Q, K, V U,Q,K,V。
从表达能力上讲,这和"每个分支单独一个 W W W"是完全等价的 ,并没有少学任何东西;差别主要体现在工程和结构设计上:
a 算得更省:一次大矩阵乘就能搞定,比反复对同一个输入做多次小矩阵乘更省访存,也更容易做 kernel fusion,在 GPU 上跑得更快;
b 数值更稳: U U U 在 HSTU 里不是普通的 residual,而是后面要用来做 gating 的用户状态流。让 U U U 和 Q K V QKV QKV 都来自同一个变换,能保证它们在尺度和分布上是一致的,训练起来更稳定。
c 语义更清楚:这种写法在结构上明确表达了一点------U U U 和 Q K V QKV QKV 本质上是同一份表示的不同"用途",而不是额外拼出来的一条旁路
2 Spatial Aggregation
Attention计算方式和Transformer的也有差别,经典的Transformer如下公式:

本文无softmax,第一项是QK的乘积,第二项为bias项,p,t分别为positional(位置)和temporal(时间)的信息。 ϕ 2 \phi_2 ϕ2还是SiLU函数。
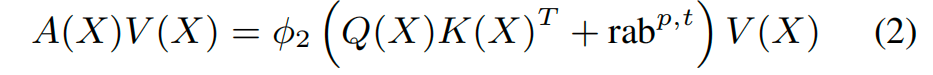
1)对于bias项目,论文中没有给出公式,扒了下代码,attention里面没有这一项,其实这个bias是加在input embedding的。
Step 1:把每个 token 的"位置 id"算出来(pos_inds)
pos_inds 是一个 [B, max_seq_len] 的整数矩阵,每个整数表示"这个位置用第几个 position embedding"。
- 越靠近序列结尾(越新)→ position id 越小
- 越靠前(越旧)→ position id 越大
** Step 2:把每个 token 的"时间差桶 id"算出来(ts)**
它会先找到每个序列的 query_time = 最后一个 token 的 timestamp
然后对每个位置算:
Δ t = q u e r y _ t i m e − t i m e s t a m p t o k e n \Delta t = query\_time - timestamptoken Δt=query_time−timestamptoken
再除以 60(大概按分钟尺度),再做sqrt或log压缩,最后取整 → 得到 bucket id。 - 离最后一个 token 越近(越新)→ bucket id 越小
- 越久远 → bucket id 越大
Step 3:查表拿到两个 embedding position_embeddings = pos_embeddings[pos_inds]time_embeddings = ts_embeddings[ts]
它们都是[B, max_seq_len, d]的张量。
Step 4:加到 token embedding 上
对每个 token:
x ′ = x + p o s _ e m b + t i m e _ e m b x' = x + pos\_emb + time\_emb x′=x+pos_emb+time_emb
2) 本文的工作抛弃了softmax的归一化,原因在3.1Pointwise aggregated attention部分进行了阐述:
- 推荐里面除了排序还需要有强度信息,softmax只能做相对排序,不能兼顾intensity信息
- softmax适合固定类别集合,但是推荐是流式场景,items的数量经常变化,导致softmax分母一
直在变化,历史分数不再有意义。
本工作中放弃了概率分布,直接建模"可加的强度",通过 pointwise aggregated attention 将 attention 从"概率分布建模"转为"强度建模":历史交互的贡献以可加形式累积,从而保留偏好强度;同时,由于不再依赖全局归一化分母,attention 分数不受候选 item 集合变化的影响,更适合推荐系统中的流式、非平稳场景。
对于无归一化后延伸数值稳定性问题,则通过 U-gating 与 LayerNorm 共同保证。

除了理论验证,文章也做了对应的实验,没有softmax的HR@10/50指标都有不同程度的提升。
3 Pointwise Transformation
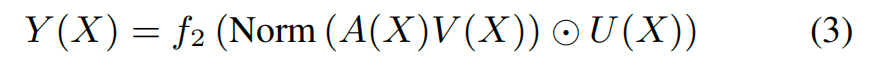
这里的设计实际上是对 3.1 中 softmax attention 缺乏强度建模能力这一问题的直接改进。由于 softmax 只能刻画相对重要性而无法表达偏好强度,HSTU 引入了显式的 U-gating 机制。U 在功能上类似于 MoE 中的 gate,作为一个强度缩放器,对 pointwise aggregated attention 的结果进行逐点调制,从而补足了 softmax 在强度建模上的不足。
Ref:
Transformer解读
论文地址
git地址
知乎解读