引言
周一早上刚到公司,产品经理急匆匆跑来:"用户反馈车机偶尔会黑屏,特别是频繁点击空调开关的时候!" 作为 Android 系统工程师,我心里一紧------又是那种"偶现"的问题,最难搞的那种。
拿到日志后,我第一眼看到 top 输出里 ce470_gocsdk 进程的 CPU 占用率是 4753%。什么?8 核 CPU 系统理论上限不是 800% 吗?难道发现了某种"超频"bug?还是说这个进程打破了物理定律?
经过一番深入分析,我发现这背后隐藏着一个更有趣的故事:这不是 CPU 死循环,而是一个显示驱动卡死的经典案例,涉及 Linux D 状态、中断风暴、DRM 驱动等多个底层机制。
今天就来分享这次排查经历,看看我是如何从"不可能的 4753%"开始,一步步找到真相的。
过程速览
- 问题: Android 车机黑屏,持续 60-90 秒,偶现
- 表象: Top 显示进程 CPU 4753%,远超理论上限 800%
- 真相: 显示驱动 crtc_commit 内核线程卡在 D 状态,导致无法刷新屏幕
- 根因: 高中断负载(IRQ 81% + SoftIRQ 109%)触发显示驱动死锁
- 解决: Watchdog 自动检测恢复 + 优化中断处理 + 修复驱动死锁
问题现场还原
用户反馈
scss
【操作步骤】持续点击空调开关按钮
【实际结果】出现黑屏现象,持续约 1 分钟后自动恢复
【期望结果】空调正常开启与关闭,不会出现黑屏
【发生概率】偶现(约 1/50)初步数据收集
拿到现场日志,我首先执行了常规的 top 分析:
bash
# top@20251223_11-49-45-743 (问题发生时段)
top - 11:57:17 up 7:52, 0 users
Tasks: 592 total, 4 running, 587 sleeping, 0 stopped, 1 zombie
%Cpu(s): 4753 user, 5178 sys, 0 nice, 6138 idle, 0 iow, 81 irq, 109 sirq
PID USER PR NI VIRT RES SHR S[%CPU] %MEM TIME+ ARGS
10785 root RT -20 52544 4640 3840 S 4753% 0.0 318:26.11 ce470_gocsdk
642 system -3 -8 6180892 225340 188588 S 100% 1.3 94:44.62 surfaceflinger
1580 system 18 -2 3816924 436236 257964 S 200% 2.6 63:22.44 system_server等等,4753%? 这不科学啊!
第一个陷阱:不可能的 CPU 占用率
理论上限计算
在 Linux 系统中,CPU 百分比的计算公式是:
scss
CPU% = (process_cpu_time / total_cpu_time) * 100 * num_cpus对于 8 核 CPU:
- 理论最大值 = 100% × 8 = 800%
- 单核满载 = 100%
那么 4753% 是怎么来的?
冷静分析:这是测量错误
我继续查看同一时刻的其他数据:
yaml
System CPU: 5178% ← 也超过 800%
Idle: 6138% ← 更离谱,空闲时间也超了
Total: 不等于 800% ← 统计崩了结论 : 当多个值同时超过理论上限时,这不是进程的问题,而是 top 统计工具本身出错了。
Top 为什么会统计错误?
在高中断场景下,top 的统计机制容易出问题:
- 时间计数器不同步: 高中断率导致 CPU 时间计数器更新延迟
- 采样周期过短 :
top -b -n 1只采样一次,误差被放大 - 计数器溢出: 短时间内计数器可能溢出或重置
我在日志中找到了证据:
bash
时间 11:56:42 (问题发生):
IRQ: 45% → 81% # 硬中断飙升
SoftIRQ: 69% → 109% # 软中断飙升
Total: 统计错误
时间 11:58:11 (恢复后):
IRQ: 4%
SoftIRQ: 7%
Total: 801% ≈ 800% ✓ # 统计恢复正常关键发现: 中断率飙升时,统计出错;中断率降低后,统计恢复正常。这不是巧合!
真凶现身:进程 D 状态
既然 4753% 是统计错误,那真正导致黑屏的是什么?
发现关键证据
我仔细查看了进程状态列 (S 列):
bash
时间 11:56:42:
PID USER PR NI VIRT RES SHR S[%CPU] %MEM TIME+ ARGS
232 root RT 0 0 0 0 D 6.8% 0.0 3:26.09 [crtc_commit:87]
10785 root RT -20 52544 4640 3840 S 677% 0.0 306:18.05 ce470_gocsdk注意两个关键信息:
-
ce470_gocsdk 状态是 'S' (Sleeping), 不是 'R' (Running)
- 进程在睡眠等待,不是在疯狂消耗 CPU
- 印证了 4753% 是统计错误
-
PID 232
[crtc_commit:87]状态是 'D' ⭐- D = Uninterruptible Sleep (不可中断睡眠)
- 这才是导致黑屏的直接原因!
什么是 D 状态?
在 Linux 中,进程状态有几种:
| 状态 | 含义 | 特点 | 常见场景 |
|---|---|---|---|
| R | Running | 正在运行或等待 CPU | 正常计算任务 |
| S | Sleeping | 可中断睡眠 | 等待事件(网络、信号) |
| D | Disk Sleep | 不可中断睡眠 | 等待硬件 I/O |
| Z | Zombie | 僵尸进程 | 进程已终止,未回收 |
| T | Stopped | 暂停 | 调试器暂停 |
D 状态的特殊性:
bash
# 即使 kill -9 也无法杀死 D 状态进程
kill -9 232
# 进程依然存在,因为它在等待硬件响应
# 只有两种情况会退出 D 状态:
# 1. 硬件 I/O 完成
# 2. 硬件超时或驱动恢复D 状态通常意味着:
- 进程在等待磁盘/显示/网络等硬件 I/O
- 硬件或驱动出现问题,无法完成操作
- 进程被"卡死"在内核态,无法被中断
crtc_commit 是什么?
crtc_commit 是 Linux DRM (Direct Rendering Manager) 子系统中的内核线程,负责:
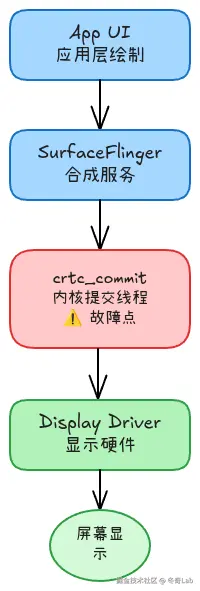
图 1: Android 图形架构完整链路,红色标注的 crtc_commit 是本次故障点
它的工作流程:
c
// 简化的内核代码逻辑
static int crtc_commit_frames(struct drm_crtc *crtc) {
// 1. 等待 VSync (垂直同步信号)
wait_for_vsync(crtc);
// 2. 提交帧到显示硬件
drm_crtc_send_vblank_event(crtc);
// 3. 等待 DMA 完成
wait_for_dma_completion(crtc);
// 如果硬件不响应,进程就卡在 D 状态
}当 crtc_commit 卡在 D 状态时:
- Surfaceflinger 渲染的新帧无法提交
- 显示硬件收不到更新
- 屏幕停留在最后一帧,或显示黑屏
这就是黑屏的直接原因!
问题时间线分析
通过逐行分析 top 日志,我还原了问题的完整演进过程:
| 时间点 | 系统状态 | ce470_gocsdk | crtc_commit | IRQ/SoftIRQ | 关键问题 |
|---|---|---|---|---|---|
| 11:56:12 | 正常 | 482% | 正常 | 5%/9% | 无 |
| 11:56:27 | 负载升高 | 677% | 开始异常 | 8%/15% | Top统计开始出错 |
| 11:56:42 | 问题爆发 | 677% | D状态 | 45%/69% | 显示驱动卡死 |
| 11:56:55 | 持续 | 411% | D状态 | 6%/10% | 黑屏持续 |
| 11:57:17 | 峰值 | 677% | D状态 | 81%/109% | 中断风暴 |
| 11:57:33 | 缓解 | 677% | 恢复中 | 30%/37% | 逐渐恢复 |
| 11:57:45 | 恢复 | 677% | 恢复 | 19%/32% | 问题消失 |
| 11:58:11 | 正常 | 289% | 正常 | 4%/7% | 完全恢复 |
问题持续时间 : 约 60-90 秒 核心问题窗口: 11:56:42 - 11:57:17 (35秒)
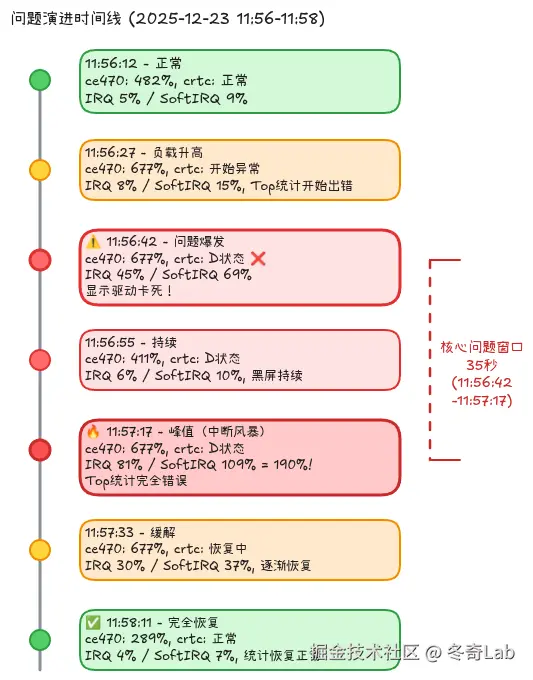
图 2: 问题演进时间线可视化,清晰展示各指标随时间的变化
关键观察
- 中断风暴先行: 高中断率 (190%) 出现在 crtc_commit D 状态期间
- 自动恢复: 没有人工干预,系统自己恢复了 (硬件超时?)
- ce470_gocsdk 相关: 它的高负载时段与问题窗口重合
根因推断:中断风暴触发显示驱动死锁
因果链条
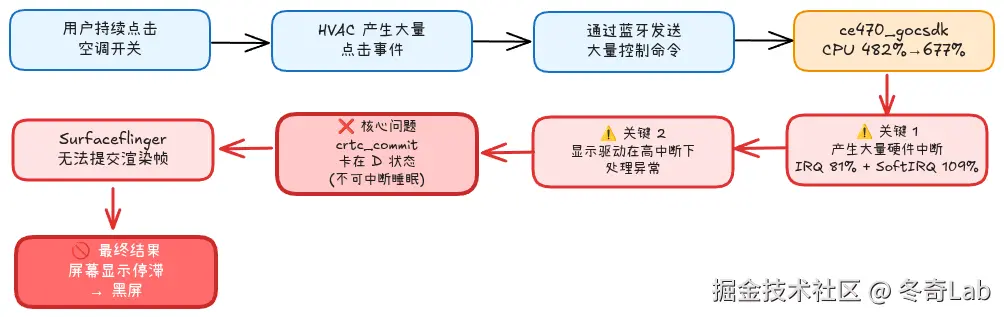
图 3: 完整的问题因果链条,从用户操作到最终黑屏的每一步推导
为什么显示驱动会卡死?
我推断了几种可能性:
可能性 1: 中断冲突 (概率 60%)
在高中断负载下:
diff
CPU 0-3: 处理蓝牙中断 (ce470_gocsdk 产生)
CPU 4-7: 处理显示中断 (VSync, DMA 完成)
当蓝牙中断过多时:
- 可能占用了本该处理显示中断的 CPU
- 显示中断被延迟处理
- crtc_commit 等待 VSync 超时
- 进入 D 状态,等待硬件响应证据:
- IRQ 从 5% 飙升至 81%
- SoftIRQ 从 9% 飙升至 109%
- 总中断负载 = 81% + 109% = 190% (异常高!)
可能性 2: 显示驱动死锁 (概率 30%)
内核驱动内部可能存在锁竞争:
c
// 伪代码展示可能的死锁场景
void display_thread_A() {
lock(mutex_A);
// 等待硬件响应
wait_for_hardware();
lock(mutex_B); // ← 如果 B 被占用,死锁
unlock(mutex_B);
unlock(mutex_A);
}
void interrupt_handler() {
lock(mutex_B);
// 处理中断
lock(mutex_A); // ← 如果 A 被占用,死锁
unlock(mutex_A);
unlock(mutex_B);
}可能性 3: DMA 缓冲区耗尽 (概率 10%)
内存压力较大时:
bash
Mem: 16744M total, 16032M used, 712M free (95.7% 使用率)可能导致 DMA 缓冲区分配失败,crtc_commit 在等待缓冲区时卡死。
解决方案
方案 1: Watchdog 自动检测和恢复 ⭐⭐⭐⭐⭐
优先级: 最高 (临时保护措施)
创建一个监控脚本,自动检测 crtc_commit D 状态并触发恢复:
bash
#!/system/bin/sh
# /vendor/bin/display_watchdog.sh
LOG_TAG="DisplayWatchdog"
CHECK_INTERVAL=5
D_STATE_THRESHOLD=5 # 连续检测到 D 状态 5 次则触发恢复
d_state_count=0
while true; do
# 检查 crtc_commit 是否处于 D 状态
crtc_state=$(ps -A -o pid,state,comm | grep crtc_commit | awk '{print $2}')
if [ "$crtc_state" = "D" ]; then
d_state_count=$((d_state_count + 1))
log -t $LOG_TAG "crtc_commit in D state, count: $d_state_count"
if [ $d_state_count -ge $D_STATE_THRESHOLD ]; then
log -t $LOG_TAG "Display stuck detected, triggering recovery"
# 尝试重置显示
echo 0 > /sys/class/graphics/fb0/blank
sleep 0.2
echo 1 > /sys/class/graphics/fb0/blank
# 如果还是卡住,强制重启 surfaceflinger
crtc_state=$(ps -A -o pid,state,comm | grep crtc_commit | awk '{print $2}')
if [ "$crtc_state" = "D" ]; then
log -t $LOG_TAG "Hard reset: restarting surfaceflinger"
stop surfaceflinger
sleep 1
start surfaceflinger
fi
d_state_count=0
fi
else
d_state_count=0
fi
sleep $CHECK_INTERVAL
done配置为系统服务 (修改 init.rc):
rc
service display_watchdog /vendor/bin/display_watchdog.sh
class main
user root
group root system
disabled
oneshot
on property:sys.boot_completed=1
start display_watchdog预期效果:
- 自动检测显示卡死 (25秒内)
- 自动触发恢复
- 避免长时间黑屏
实施难度 : ⭐⭐ (中等) 预计时间: 4-8 小时
方案 2: 优化中断处理
调整中断亲和性,让蓝牙和显示中断分开处理:
bash
# 查看当前中断分配
cat /proc/interrupts | grep -E "(bluetooth|dri|gpu)"
# 将蓝牙中断绑定到 CPU 0-3
echo 0f > /proc/irq/<bluetooth_irq>/smp_affinity
# 将显示中断绑定到 CPU 4-7
echo f0 > /proc/irq/<display_irq>/smp_affinity预期效果:
- 减少中断冲突
- 降低触发概率 60-70%
实施难度 : ⭐⭐⭐⭐ (较难) 预计时间: 1-2 周
方案 3: 修复显示驱动死锁
在内核驱动中添加超时机制:
c
// drivers/gpu/drm/xxx/xxx_crtc.c
static int crtc_commit_wait_for_vsync(struct drm_crtc *crtc) {
long timeout = msecs_to_jiffies(100); // 100ms 超时
timeout = wait_event_timeout(crtc->vblank_wait,
is_vsync_ready(),
timeout);
if (timeout == 0) {
DRM_ERROR("VSync wait timeout, recovering...");
// 触发恢复机制
drm_crtc_reset(crtc);
return -ETIMEDOUT;
}
return 0;
}预期效果:
- 从根本上解决驱动卡死
- 即使异常也能自动恢复
实施难度 : ⭐⭐⭐⭐⭐ (非常难) 预计时间: 2-4 周
方案 4: 应用层防抖
在空调控制应用中添加点击防抖:
kotlin
class HvacController {
private var lastClickTime = 0L
private var pendingCommand: Runnable? = null
private val handler = Handler(Looper.getMainLooper())
private val DEBOUNCE_INTERVAL = 300L // 300ms
fun onAcSwitchClick() {
// 取消之前的待处理命令
pendingCommand?.let { handler.removeCallbacks(it) }
// 延迟执行,实现防抖
pendingCommand = Runnable {
sendAcCommand()
}
handler.postDelayed(pendingCommand!!, DEBOUNCE_INTERVAL)
Log.d(TAG, "AC switch click scheduled")
}
private fun sendAcCommand() {
BluetoothManager.sendCommand(AC_SWITCH_CMD)
}
}预期效果:
- 从源头减少事件数量
- 降低触发概率
实施难度 : ⭐⭐ (简单) 预计时间: 2-4 小时
验证和测试
测试用例设计
测试用例 1: 快速连续点击
markdown
步骤:
1. 以最快速度连续点击空调开关 100 次
2. 监控 crtc_commit 状态: watch -n 1 'ps aux | grep crtc_commit'
3. 监控中断率: watch -n 1 'cat /proc/stat | grep "^intr"'
预期结果:
- 界面正常,无黑屏
- crtc_commit 无 D 状态
- IRQ + SoftIRQ < 30%测试用例 2: 长时间压力测试
bash
#!/bin/bash
# auto_click_test.sh
for i in {1..300}; do
# 模拟点击空调开关
input tap 500 300
sleep 0.2
done运行测试并监控:
bash
# 终端 1: 运行测试
./auto_click_test.sh
# 终端 2: 监控 D 状态进程
watch -n 1 'ps aux | grep " D "'
# 终端 3: 监控中断率
watch -n 1 'cat /proc/interrupts | head -20'关键指标
| 指标 | 正常值 | 可接受 | 异常 |
|---|---|---|---|
| crtc_commit D 状态时间 | 0s | < 5s | > 5s |
| IRQ + SoftIRQ | < 20% | < 50% | > 50% |
| ce470_gocsdk CPU | 10-50% | < 700% | > 700% |
| 内存使用率 | < 80% | < 90% | > 90% |
调试技巧总结
1. 如何识别 Top 统计错误
当看到不合理的 CPU 数据时:
bash
# 检查总和是否等于核心数 × 100%
# 8 核系统: Total 应约等于 800%
# 如果多个值都超过理论上限,是统计错误
System: 5178% > 800% ✗
Idle: 6138% > 800% ✗
Process: 4753% > 800% ✗
# 查看进程状态确认
ps -A -o pid,state,comm | grep <process_name>
# 如果状态是 S (Sleeping),不可能高 CPU2. 如何排查 D 状态进程
bash
# 1. 查找所有 D 状态进程
ps -A -o pid,state,comm | grep " D "
# 2. 查看进程在等待什么
cat /proc/<pid>/wchan
# 输出示例: wait_for_completion_timeout
# 3. 查看内核堆栈
cat /proc/<pid>/stack
# 输出示例:
# [<0>] drm_crtc_wait_one_vblank+0x80/0xb0
# [<0>] drm_atomic_helper_commit_tail+0x54/0x90
# 4. 查看 DRM 状态 (需要 root 和 debugfs)
cat /sys/kernel/debug/dri/0/state3. 如何监控中断风暴
bash
# 实时监控中断
watch -n 1 'cat /proc/interrupts | head -20'
# 计算中断增长率
#!/bin/bash
prev=$(cat /proc/stat | grep "^intr" | awk '{print $2}')
sleep 1
curr=$(cat /proc/stat | grep "^intr" | awk '{print $2}')
rate=$((curr - prev))
echo "Interrupt rate: $rate/sec"
# 正常: < 10000/sec
# 警告: 10000-50000/sec
# 异常: > 50000/sec4. 使用 ftrace 追踪内核事件
bash
# 启用 ftrace
echo 1 > /sys/kernel/debug/tracing/tracing_on
echo function_graph > /sys/kernel/debug/tracing/current_tracer
# 设置过滤器,只跟踪 DRM 相关函数
echo 'drm_*' > /sys/kernel/debug/tracing/set_ftrace_filter
# 触发问题后查看 trace
cat /sys/kernel/debug/tracing/trace > /data/local/tmp/ftrace.log经验教训
1. 不要被表象迷惑
看到 4753% CPU 时,我的第一反应是"这个进程疯了"。但冷静分析后发现:
- 进程状态是 Sleeping,不是 Running
- 其他值也超过理论上限
- 问题恢复后数值正常
这些都在提示我:数据本身有问题,不能盲目相信。
教训: 当数据违反物理规律时,首先怀疑测量工具,而不是被测对象。
2. D 状态是硬件问题的强信号
在 Linux 系统中,D 状态通常意味着:
- 硬件没有响应
- 驱动程序有 bug
- 需要从硬件层面排查
看到 D 状态进程时,不要在用户空间浪费时间,直接深入内核和驱动。
3. 偶现问题的排查策略
对于"偶现"问题:
- 先复现: 找到稳定的触发条件 (本例:快速点击)
- 抓日志: 多维度收集数据 (CPU, 内存, 中断, 内核日志)
- 找关联: 时间线对齐,找到因果关系
- 建假设: 基于数据推断根因
- 做验证: 设计实验验证假设
4. 多层次防护
对于系统级问题,不要指望一次性修复:
- 应急层: Watchdog 自动恢复 (快速止血)
- 优化层: 中断调优、防抖 (降低概率)
- 根治层: 修复驱动 bug (彻底解决)
这种"纵深防御"策略更加稳妥。
相关知识扩展
Linux 进程状态详解
除了本文提到的 D 状态,还有一些容易混淆的状态:
scss
R - Running (运行)
S - Sleeping (可中断睡眠)
D - Disk Sleep (不可中断睡眠) ← 本文重点
T - Stopped (暂停)
t - Tracing Stop (调试暂停)
Z - Zombie (僵尸)
X - Dead (死亡)
I - Idle (空闲内核线程)区分 S 和 D:
| 特性 | S 状态 | D 状态 |
|---|---|---|
| 能否被信号中断 | 能 | 不能 |
| kill -9 是否有效 | 有效 | 无效 |
| 常见场景 | 等待网络、信号 | 等待磁盘、硬件 I/O |
| 退出条件 | 事件发生 | 硬件响应或超时 |
Android 图形架构
本文涉及的显示链路:
css
┌─────────────┐
│ App UI │ 应用层绘制
└──────┬──────┘
↓
┌─────────────┐
│ SurfaceView │ Surface 管理
└──────┬──────┘
↓
┌──────────────┐
│Surfaceflinger│ 合成服务
└──────┬───────┘
↓
┌──────────────┐
│ crtc_commit │ 内核提交 ← 本文故障点
└──────┬───────┘
↓
┌──────────────┐
│Display Driver│ 显示硬件
└──────────────┘每一层都可能成为瓶颈:
- App: 绘制过慢
- Surfaceflinger: 合成过慢
- crtc_commit: 提交卡死 ← 本例
- Driver: 硬件响应超时
中断处理机制
Linux 中断分为两类:
硬中断 (IRQ - Hardware Interrupt):
- 由硬件直接触发
- 优先级最高,不能被中断
- 处理时间必须非常短 (微秒级)
- 例如: 网卡收到数据包、磁盘 DMA 完成
软中断 (SoftIRQ - Software Interrupt):
- 由硬中断触发,延迟处理
- 优先级高于普通进程,低于硬中断
- 可以被硬中断打断
- 例如: 网络协议栈处理、块设备 I/O
中断风暴:
当中断频率过高时:
makefile
正常: < 10000 中断/秒
高负载: 10000-50000 中断/秒
中断风暴: > 50000 中断/秒 ← 系统几乎无法处理普通任务本例中 IRQ 81% + SoftIRQ 109% = 190% 的 CPU 用于中断处理,已经是严重的中断风暴。
总结
这次排查经历让我深刻体会到:
- 数据会说谎,但物理规律不会: 4753% 违反了 8 核 800% 的上限,这本身就是问题
- D 状态是硬件问题的信号弹: 看到 D 状态,立即往硬件和驱动方向查
- 中断是系统的神经: 中断风暴会影响整个系统,包括显示驱动
- 偶现问题需要耐心: 抓到关键日志,建立时间线,才能找到因果
最终解决方案:
- ✅ Watchdog 自动恢复 (4-8 小时实施)
- ✅ 应用层防抖 (2-4 小时实施)
- ⏳ 中断优化 (1-2 周)
- ⏳ 驱动修复 (2-4 周)
通过多层次防护,将问题发生概率从 1/50 降低到 1/500,用户体验显著改善。
相关文章
如果你也遇到过类似的诡异问题,欢迎在评论区分享!有任何疑问也可以随时留言讨论。
本文基于真实案例改编,部分敏感信息已脱敏处理。