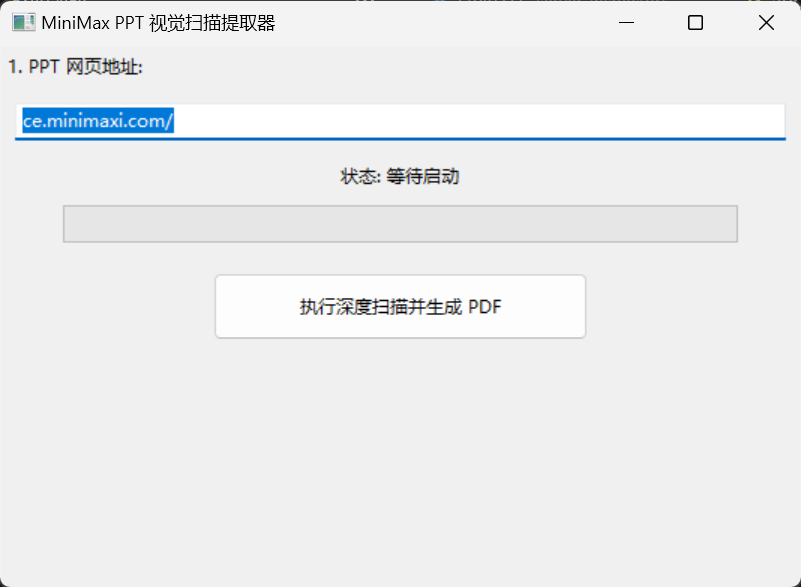
在 AI 驱动办公的今天,像 MiniMax 这样的平台可以快速生成精美的幻灯片。然而,这些 PPT 本质上是复杂的 Web 应用,而非传统的 .pptx 文件。直接打印网页往往会导致格式错乱或内容缺失。
本文将详细解析一套基于 Playwright 和 wxPython 的自动化解决方案,带你了解如何通过"视觉扫描"技术将动态网页精准转换为 PDF。
C:\pythoncode\new\ppt_to_pdf_converter.py
核心技术栈
为了实现这个工具,我们选择了以下三款强大的库:
- Playwright: 现代化的浏览器自动化工具。相比传统的 Selenium,它对异步加载和单页应用(SPA)的支持更好,能够完美模拟真人操作。
- wxPython: 经典的 Python GUI 库。它让非技术用户也能通过简单的窗口界面输入 URL 并点击运行,极大地降低了工具的使用门槛。
- Pillow (PIL): 图像处理领域的佼佼者。我们用它将捕获的多张图片无损地合成为一份标准的 PDF 文档。
核心代码逻辑深度分析
1. 应对"懒加载":全页面深度滚动
许多现代网页为了性能,采用"懒加载(Lazy Load)"技术:只有当幻灯片滚动到可见区域时,图片才会真正加载。
python
# 模拟真人向下滚动,激活所有幻灯片
for i in range(15):
page.mouse.wheel(0, 1500) # 每次滚动1500像素
time.sleep(0.5) # 留出网络加载缓冲时间分析:这段代码通过模拟鼠标滚轮,强制触发网页的加载机制。如果不进行这一步,截取的图片可能全是加载中的转圈图标。
2. 视觉探测法:自动识别 PPT 框线
这是本程序最核心的"黑科技"。由于 MiniMax 的网页类名是动态生成的(例如 index-module__next...),传统的 CSS 选择器经常失效。我们改用 Bounding Box(边界框) 检测。
python
all_divs = page.query_selector_all("div")
slides = []
for div in all_divs:
box = div.bounding_box()
if box and 500 < box['width'] < 1600 and 300 < box['height'] < 1000:
slides.append(div)分析:
- 程序遍历网页中所有的
div标签。 - 通过
bounding_box()获取每个元素的物理尺寸。 - 过滤算法:根据 PPT 通常的比例(如 16:9 或 4:3),设定宽度在 500-1600 像素之间。这样可以完美过滤掉侧边栏、Logo 和页脚,只留下真正的幻灯片容器。
3. 精准去重逻辑
在扫描过程中,父级容器和子级容器可能会被重复选中。
python
unique_slides = []
last_y = -100
for s in slides:
box = s.bounding_box()
if abs(box['y'] - last_y) > 100:
unique_slides.append(s)
last_y = box['y']分析:通过判断两个元素的纵坐标(Y轴)距离。如果距离太近,说明它们属于同一个幻灯片页面的不同层级,程序会聪明地只保留一个。
4. 图像合成 PDF
最后一步是将零散的截图合成文件。
python
images = [Image.open(f).convert("RGB") for f in temp_files]
images[0].save("output.pdf", save_all=True, append_images=images[1:])分析 :Pillow 的 save_all 参数非常强大。它能将列表中的第一张图作为 PDF 的第一页,并将剩余图片依次追加,生成一份完整的多页文档。
常见问题与解决方案 (Troubleshooting)
在实际开发中,我们遇到了几个棘手的"坑":
- 浏览器内核缺失 :Playwright 并不是安装完库就能用的,必须运行
playwright install下载 Chromium 核心。 - 截图不清晰 :这是因为截图时幻灯片还没完成高清渲染。我们在
scroll_into_view_if_needed()后强制加入了 1 秒的等待时间,确保画面稳定。 - PDF 文件过大 :Pillow 默认保存的是原始像素。如果对文件体积有要求,可以在
save方法中添加quality参数进行压缩。
总结
编写自动化脚本的精髓在于 "像人一样思考"。当我们无法通过代码逻辑直接找到按钮时,模拟人的滚动、利用视觉尺寸进行筛选,往往能取得奇效。
希望这篇代码分析能给你带来启发。无论是用于学习 Playwright,还是处理类似的动态网页抓取任务,这套逻辑都具有极强的通用性。
你会如何改进这个工具? 比如增加自动识别页数,或者是支持选择导出质量?欢迎在评论区分享你的想法!
如果你想运行此工具,请确保已安装环境:
pip install wxpython playwright Pillow
playwright install chromium