在 MySQL 高可用架构中,Group Replication(MGR)凭借其分布式一致性能力成为热门方案。它通过多节点协同实现数据同步,同时提供灵活的一致性配置,可根据业务需求平衡数据可靠性与性能。本文将从 MGR 的事务执行流程、冲突检测机制、一致性选项选择及实操配置四个维度,拆解其核心特性。
一、事务在 MGR 中的完整执行流程
MGR 的事务处理需经过 "本地执行 - 集群同步 - 全局确认 - 异步应用" 多个阶段,确保集群内数据最终一致。具体流程如下:

- 本地事务执行阶段
客户端在某一节点发起事务后,在执行commit前,事务仅在该节点本地处理(包括 SQL 解析、执行、事务日志写入),不涉及其他节点,避免过早的集群交互消耗。 - 提交与二阶段日志写入
当客户端发起commit请求,事务进入提交流程:- 事务修改的内容先写入节点的Binlog Cache(内存缓存);
- 随后准备将 Binlog 日志持久化到本地binlog文件,完成日志层面的 "预提交"。
- 事务打包与集群发送
事务在本地提交后,MGR 的主复制插件会将事务相关元数据(含 Binlog、Write Set 等)打包,通过 P2P 协议发送至集群内其他所有节点,实现事务信息的分布式同步。 - 全局排序与冲突检测
这是 MGR 保证一致性的关键环节,分两种场景处理:- 单机模式(单主):仅主节点接受写操作,无需多节点排序,冲突检测简化;
- 多主模式:所有节点可接受写操作,需通过集群协商为事务分配全局唯一序号(确保执行顺序一致),同时触发冲突检测(下文详细解析),若检测到冲突,事务将直接回滚。
- 多数节点确认(法定数量校验)
事务信息发送后,需等待集群内多数节点(超过半数)确认接收并通过冲突检测。当达到法定数量时,发起事务的节点会将该事务标记为 "已提交",确保集群层面的强一致性基础。 - 其他节点异步应用事务
已确认提交的事务,不会阻塞发起节点的后续操作 ------ 其他节点会独立、异步地从集群接收事务数据,并在本地应用(执行 Binlog、更新数据)。此过程不影响发起节点的事务吞吐量。 - 事务完成(提交 / 回滚)
- 若所有节点成功应用事务,整个事务流程完成;
- 若某节点应用时遇到无法解决的冲突(如数据格式异常),则在所有节点触发事务回滚,确保集群数据无脏写。
二、MGR 冲突检测机制:双重校验防 "脏写"
MGR 的核心目标之一是防止多节点并发修改同一条记录,其冲突检测机制通过 "Write Set 指纹 + GTID 集合" 双重校验实现,流程如图所示:
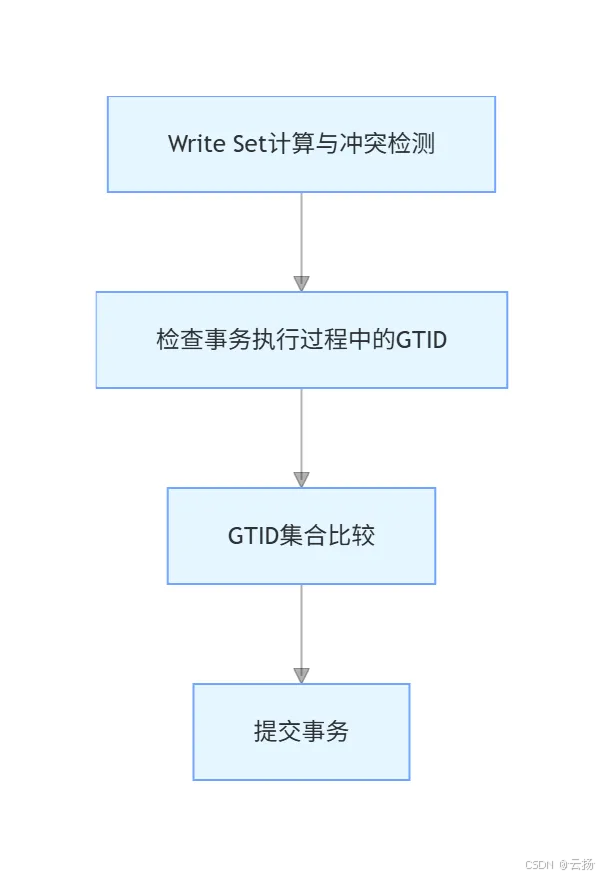
1. 第一步:生成事务 "指纹"------Write Set
针对每个写事务,MGR 会为其修改的记录生成唯一标识(Write Set),构成如下:
- 基础信息:索引名、数据库名(及长度)、表名(及长度);
- 核心标识:构成索引唯一性的列值(及长度,如主键值);
- 哈希转换:将上述信息通过哈希算法生成固定长度的哈希值,作为事务修改内容的 "指纹",便于快速比对。
2. 第二步:Write Set 冲突校验
集群内每个节点维护一份certification info(认证信息表),记录所有已通过校验的事务 Write Set:
- 若当前事务的 Write Set 已存在于
certification info,说明其他节点已修改过同一条记录,当前事务存在冲突,直接回滚; - 若不存在,则将当前 Write Set 写入
certification info,进入下一重校验。
3. 第三步:GTID 集合兼容性校验
GTID(全局事务 ID)是 MGR 中事务的全局唯一标识,每个节点维护GTID executed集合(本地已执行的事务 ID):
- 对比当前节点的
GTID executed与certification info中其他节点的 GTID 集合; - 若当前节点的
GTID executed是其他节点集合的子集 ,说明当前节点 "数据落后"(未执行其他节点已完成的事务),可能存在数据不一致风险,事务回滚; - 若不是子集,说明节点数据状态兼容,事务通过校验,可正常提交。
简言之,MGR 通过 "Write Set 防同记录并发修改 + GTID 防数据状态落后",从根本上避免集群脏写问题。
三、MGR 一致性选项:5 种配置平衡 "一致性" 与 "性能"
MGR 通过group_replication_consistency参数提供 5 种一致性级别,不同配置对应不同的业务场景,核心区别如下表所示:
| 配置值 | 一致性级别 | 核心逻辑 | 适用场景 | 性能影响 |
|---|---|---|---|---|
EVENTUAL |
最终一致性 | 事务本地提交后广播,其他节点异步处理,短时间可能读旧数据,最终同步 | 对实时一致性要求低(如非核心日志查询) | 性能最优 |
BEFORE_ON_PRIMARY_FAILOVER |
故障转移一致性 | 仅主节点故障时生效:新主需处理完所有未完成事务,再响应读写请求 | 需避免故障切换后读旧数据(如支付订单系统) | 故障恢复延迟增加 |
BEFORE |
读操作强一致性 | 事务执行前,等待所有已提交事务在本地应用,确保读最新数据 | 写密集、读少,且不敏感于读过期数据 | 写事务等待时间增加 |
AFTER |
写操作强一致性 | 写事务提交前,等待修改在所有节点应用,确保后续读必见最新值(只读事务无影响) | 无(通常不建议使用) | 写延迟显著增加 |
BEFORE_AND_AFTER |
全强一致性 | 结合 BEFORE(等前置事务)与 AFTER(等全节点应用),读写均获最新数据 | 读频繁、写少,需即时数据可见(如库存查询) | 性能开销最大 |
关键结论:
-
从
EVENTUAL到BEFORE_AND_AFTER,一致性强度递增,但集群延迟与性能消耗也同步递增; -
多数业务优先选择
EVENTUAL(性能最优)或BEFORE(读强一致),AFTER因严重影响写性能,通常不建议使用。
四、实操:MGR 事务一致性级别的查看与修改
在实际运维中,需根据业务变化调整 MGR 一致性级别,以下是常用 SQL 命令(基于 MySQL 8.0+):
1. 查看一致性级别
- 查看当前会话级别(仅对当前数据库连接有效):
bash
select @@session.group_replication_consistency;- 查看全局级别(对所有新创建的会话有效):
bash
select @@global.group_replication_consistency;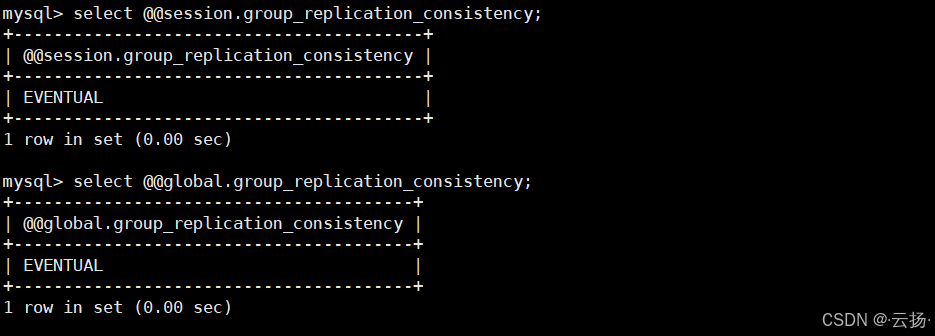
2. 修改一致性级别
- 修改当前会话级别(示例:改为 BEFORE,读强一致):
bash
set @@session.group_replication_consistency = 'BEFORE';- 修改全局级别(示例:改为 BEFORE,需注意对所有新会话的影响):
bash
set @@global.group_replication_consistency = 'BEFORE';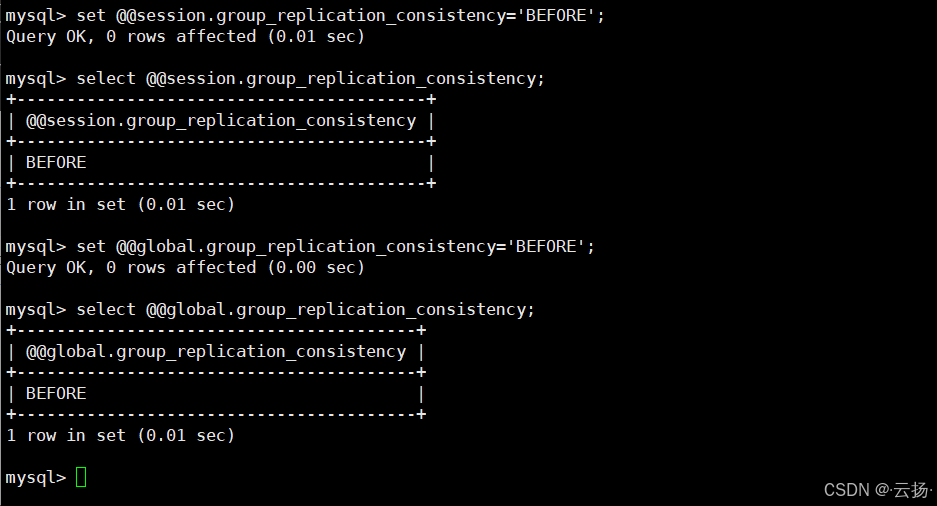
3. 运维建议
-
测试或临时调整时,优先修改 "会话级别",避免影响全局业务;
-
若仅为验证功能修改全局级别,实验完成后建议改回默认的
EVENTUAL(性能最优):
bash
set @@global.group_replication_consistency = 'EVENTUAL';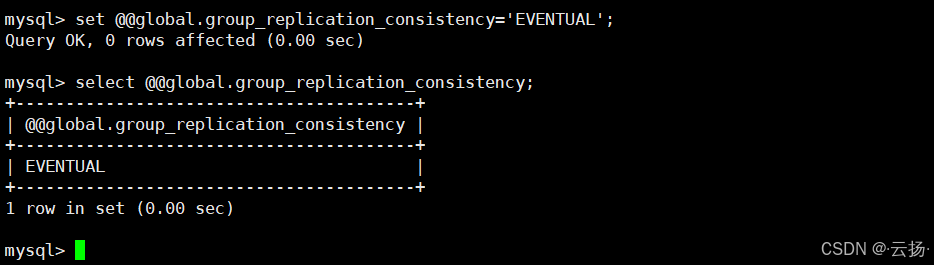
总结:MGR 的核心价值与实践原则
MGR 作为 MySQL 官方分布式集群方案,其核心优势在于:
-
通过 "Write Set+GTID" 双重校验,彻底解决多节点并发冲突问题;
-
提供 5 种一致性配置,可灵活平衡 "数据可靠性" 与 "集群性能";
-
事务异步应用机制降低集群交互延迟,保障高吞吐量。
在实践中,需牢记 "业务驱动配置" 原则:
-
非核心查询选
EVENTUAL,优先保性能; -
写密集业务选
BEFORE,兼顾写效率与读一致性; -
读敏感且写少的场景选
BEFORE_AND_AFTER,确保数据即时可见; -
避免使用
AFTER,防止写性能大幅下降。
掌握 MGR 的事务流程与一致性配置,是构建高可用、高可靠 MySQL 集群的关键一步。