Stability AI:开源图像生成的破局者,如何重塑全球AI创作生态?
作者:Weisian
科技观察者 · 开源社区践行者 · AIGC实践者 · 相信技术应该像空气一样自由流动

哈喽,各位关注AI与创意交汇的朋友!
如果你在过去两年里接触过AI绘画、图像生成或视觉内容创作,几乎不可能没听过 Stability AI 的名字。
它不像 Midjourney 那样神秘封闭,也不像 DALL·E 那样依附于商业巨头;相反,它从诞生之初就高举"开源、免费、可商用"的大旗,把顶级文生图模型的钥匙,亲手交到了每一位普通创作者手中。
更令人震撼的是------这家成立于2021年的公司,在短短几年内不仅推出了 Stable Diffusion 系列模型(彻底引爆全球AI艺术浪潮),还构建起覆盖文本、音频、3D、视频的多模态开源生态,并吸引了包括 Runway、Hugging Face、Replicate 在内的数千家开发者和平台共建生态。
那么,Stability AI 到底是谁?它的崛起背后有哪些不为人知的故事?
更重要的是------作为设计师、开发者、内容创作者甚至普通用户,我们该如何真正用好 Stable Diffusion?
今天,我将以一个长期追踪AIGC生态的实践者身份,带你全面、深入、人性化地了解 Stability AI 的全貌:从创始人初心、技术演进、产品矩阵,到本地部署、商业应用、伦理争议,再到中国用户的实操指南------一文讲透。
无论你是想用AI画插画、做电商素材、训练专属风格模型,还是好奇"开源能否对抗闭源垄断",这篇内容都值得你耐心读完。
一、Stability AI:开源图像生成的"扛旗者"
1.1 起源故事:从学术合作到全球现象
Stability AI 并非传统意义上的初创公司。它的核心并非由工程师单打独斗打造,而是源于一场跨国学术协作:
- 2022年8月 ,德国慕尼黑大学的 CompVis 实验室 (计算机视觉团队)与 Runway ML (创意AI工具平台)联合开发了一款名为 Latent Diffusion Model(LDM) 的图像生成架构;
- Stability AI 的创始人 Emad Mostaque (前对冲基金经理、技术理想主义者)敏锐意识到其潜力,主动提供算力与资金支持,并推动该项目以 Stable Diffusion 之名开源发布;
- 模型权重、代码、训练方法全部公开,且采用 Creative ML OpenRAIL-M 许可证------允许商用、允许修改、仅限制滥用(如生成暴力、违法内容)。
这一举动如同在平静湖面投下巨石:
不到一周,GitHub 星标破万;一个月内,全球数百万开发者、艺术家、学生开始本地运行 Stable Diffusion。
从此,AI图像生成不再是硅谷巨头的专利,而成为人人可参与的"全民创作运动"。
1.2 创始人 Emad Mostaque:理想主义与争议并存
如果 Stability AI 是一部电影,那么创始人 Emad Mostaque 就是最不像 CEO 的主角。这位牛津数学与计算机科学毕业生,曾在对冲基金工作,却在2020年疫情封锁期间,做出了改变AI历史的决定。
几个关键特质让你了解他:
- 非典型技术领袖:不穿连帽衫,喜欢讨论哲学和社会影响;
- 务实理想主义者:相信AI应该属于每个人,而不是大公司;
- 开源原教旨主义者:"如果AI是新时代的火,那么我们要让每个人都能取暖。"

有趣的时间线:
- 2019年:开始投资开源AI项目
- 2020年:正式创立Stability AI
- 2022年8月:发布Stable Diffusion 1.0,世界为之改变
- 2023年至今:从图像扩展到代码、音频、视频、3D的全面AI套件
Emad Mostaque 并非技术出身,但他坚信:"AI 应该属于人类,而不是被少数公司控制。"
他将 Stability AI 定位为"赋能型基础设施公司",目标不是卖 API 或订阅服务,而是通过开源模型+社区生态,让每个人都能掌控自己的创作工具。
但他的激进言论(如"AI将取代90%程序员")和管理风格也引发内部动荡------2023年,多位核心科学家离职,CompVis 实验室宣布不再参与后续开发。
尽管如此,Stability AI 仍坚持开源路线,并逐步建立起自己的研发团队,推出 SDXL、Stable Video Diffusion、Stable Audio 等新模型,证明其具备独立创新能力。
1.3 核心理念:开源即正义,去中心化即未来
Stability AI 的信条可概括为三点:
- 模型必须开源:只有透明,才能被信任、被改进、被审计;
- 工具必须免费:降低创作门槛,让非洲学生和纽约设计师站在同一起跑线;
- 生态必须开放:鼓励第三方开发插件、微调模型、搭建平台,形成"百花齐放"的AIGC宇宙。
这种理念,使其在全球开源社区中赢得了极高声誉,也被誉为"AI时代的Linux"。

二、核心哲学:为什么开源不是策略,而是信仰
2.1 "人人可用"的真正含义
在Stability AI的世界观里,开源不是营销话术,而是核心DNA:
| 维度 | 传统AI公司 | Stability AI |
|---|---|---|
| 模型发布 | API访问,闭源 | 完全开源,权重公开下载 |
| 商业限制 | 严格的使用条款 | 宽松的CreativeML Open RAIL-M许可证 |
| 本地运行 | 不允许或有限制 | 鼓励且提供优化工具 |
| 社区角色 | 被动使用者 | 主动贡献者,共同创造者 |
Emad Mostaque的经典语录:
"我们不是在建造围墙花园,我们是在播种。每一颗种子都能长成一片森林。"
2.2 开源生态的乘法效应
Stable Diffusion的开源效应:
- 发布后24小时:GitHub仓库获得1万+星星
- 第一周:出现了50多个衍生工具
- 第一个月:社区贡献了数百个微调模型
- 现在:整个生态系统估值可能超过Stability AI本身
社区创造的奇迹:
- DreamBooth:个人风格微调技术,让任何人都能训练自己的风格
- ControlNet:精确控制生成过程,解决了AI绘画的"随机性"问题
- LoRA:轻量级微调,用少量数据定制模型
- AUTOMATIC1111 WebUI:图形界面,让非程序员也能使用

这就是开源的魔法:公司提供了一个基础模型,社区让它强大100倍。
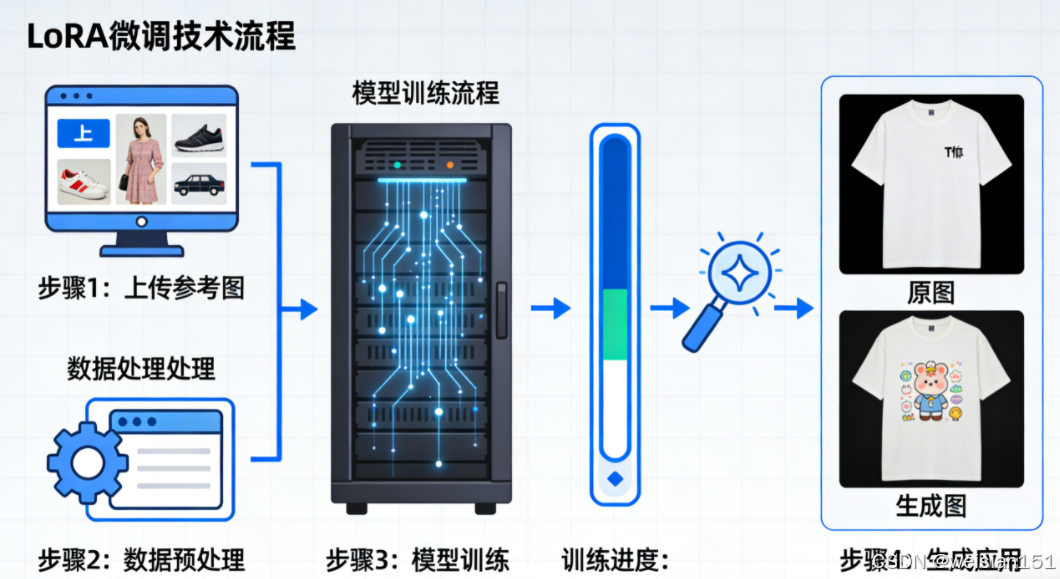
三、技术演进:从 Stable Diffusion 到多模态帝国
Stability AI 的技术路线清晰而激进:以图像为起点,向全模态扩展。
3.1 Stable Diffusion 系列:图像生成的"开源基石"
技术突破的核心:
-
潜在扩散模型(Latent Diffusion)
- 传统扩散:在像素空间操作,计算成本极高
- 潜在扩散:在压缩的潜在空间操作,效率提升10倍
- 结果:消费级GPU也能运行高质量的图像生成
-
CLIP引导的文本理解
- CLIP模型理解文本和图像的关联
- 将文字描述映射到图像特征
- 让"用文字画画"成为现实
版本演进史:
| 版本 | 发布时间 | 关键进步 | 我的使用感受 |
|---|---|---|---|
| SD 1.4 | 2022年8月 | 基本可用,细节一般 | "Wow,真的能用!" |
| SD 1.5 | 2022年10月 | 质量显著提升 | "这已经比很多人类画师好了" |
| SD 2.0 | 2022年11月 | 更强的写实能力,但艺术性下降 | "技术上进步,但失去了灵魂" |
| SD 2.1 | 2022年12月 | 平衡了质量和艺术性 | "找到了正确的方向" |
| SD XL 0.9 | 2023年6月 | 质的飞跃,真正专业级 | "这可以用于商业项目了" |
| SD XL 1.0 | 2023年7月 | 稳定商用版本 | "我的首选工具" |
SD XL的真正突破:
- 参数:从9.9亿 → 35亿
- 训练数据:更干净,更高质量
- 架构:双CLIP编码器(OpenCLIP ViT-G + CLIP ViT-L)
- 结果:理解复杂提示词的能力提升300%
特别说明 :Stable Diffusion 3(2024.06)虽未完全开源权重,但提供了 推理代码 + 微调框架,并承诺未来开放基础版本,延续"有限开源"策略。
3.2 视频与3D:拓展创作维度
Stable Video Diffusion(SVD)(2023.11):
- 输入一张图,生成25帧短视频(576x1024),支持相机运动控制
- 虽不如 Pika 或 Runway 流畅,但首个开源视频生成模型,意义重大
Stable Zero123 / Depth:
- 从单张图生成3D视角或深度图,为游戏、AR/VR 提供低成本资产生成方案

3.3 音频与语言:悄然布局多模态
Stable Audio(2023.09):
-
文本生成音乐/音效,支持时长、风格、乐器描述
-
可用于短视频配乐、游戏音效
-
我的音乐创作实验 :
提示词:"电子音乐,80年代合成器风格,欢快节奏,有空间感,专业制作质量" 生成结果:30秒片段,听起来像真正的电子音乐,自动添加了合适的音效过渡
Stable Code / Beluga / FreeWilly 系列:
- 开源大语言模型(基于 Llama 微调)
- 支持30+编程语言,可在消费级硬件运行
- 表明 Stability AI 正构建全栈AIGC能力,不局限于视觉
四、产品矩阵:从模型到工具,覆盖创作全链路
Stability AI 不只是一家模型公司,更是一个创作者基础设施提供商。
4.1 核心开源模型(免费 + 可商用)
所有模型均托管于 Hugging Face 和 Stability 官网,支持主流框架(Diffusers、ComfyUI、InvokeAI):
- Stable Diffusion XL (SDXL):当前最强开源图像模型,适合高质量商业输出;
- SDXL Turbo / Lightning:追求速度的轻量选择,适合实时交互场景;
- Stable Video Diffusion (SVD):开源视频生成首选;
- Stable Audio:文本生成音乐/环境音;
- Stable Diffusion 3 (SD3):最新多模态架构,支持复杂提示词理解。
许可证说明 :大部分模型采用 CreativeML OpenRAIL-M,允许商用,但禁止生成违法、有害、侵犯隐私的内容。
4.2 官方工具与平台
-
DreamStudio (https://dreamstudio.ai):
Stability 官方Web界面,提供API调用、批量生成、高清修复等功能,按积分计费(新用户送免费额度)。
-
Stability Matrix (开发者平台):
提供模型微调、部署、监控一体化服务,面向企业客户。
-
Clipdrop by Stability AI (收购而来):
一系列实用AI图像工具,如背景移除、图像增强、文字擦除等,部分功能免费。
五、实操指南:普通人如何用好 Stable Diffusion?
5.1 零代码入门:用 WebUI 一键生成
推荐使用 AUTOMATIC1111 WebUI(最流行的本地部署方案):
- 下载整合包(如秋叶、Fooocus):国内有大量优化版,内置中文、模型管理、插件;
- 放入模型文件 :将
sd_xl_base_1.0.safetensors等模型放入models/Stable-diffusion文件夹; - 启动程序 :双击运行,浏览器打开
http://127.0.0.1:7860; - 输入提示词(Prompt),点击生成!
提示词技巧:
- 正向提示:
masterpiece, best quality, 1girl, cyberpunk city, neon lights- 负向提示:
lowres, bad anatomy, blurry, text

5.2 进阶玩法:微调专属风格
- LoRA 微调:用几十张图训练专属风格(如"宫崎骏风""赛博朋克logo"),仅需 4GB 显存;
- Textual Inversion:学习新概念(如你的宠物、产品logo),嵌入到提示词中;
- ControlNet:通过边缘图、深度图、姿态图精确控制构图。
这些技术已在 Hugging Face 和 Civitai 上形成庞大生态,数万个免费模型任你调用。
5.3 商业应用案例
- 电商:自动生成商品场景图、模特试穿效果;
- 游戏:批量生成角色立绘、场景贴图;
- 出版:为小说绘制插图,成本降低90%;
- 教育:制作历史场景复原图、科学示意图。
案例:某淘宝店主用 SDXL + LoRA 微调自家服装风格,日均生成500+商品图,人力成本归零。
六、商业模型:开源公司如何生存?
6.1 多元化的收入来源
Stability AI的商业模式:
| 收入来源 | 具体形式 | 目标客户 | 我的观察 |
|---|---|---|---|
| 企业API | Stability AI API | 需要稳定服务的企业 | 与开源版本形成互补 |
| 定制开发 | 行业定制模型 | 特定行业客户(医疗、设计等) | 利用开源模型作为基础 |
| 硬件合作 | 与硬件厂商合作 | 硬件公司优化AI性能 | 生态系统的自然延伸 |
| 创作者计划 | 优质模型市场 | 专业创作者 | 正在探索的方向 |
| 投资与融资 | 风险投资 | 长期发展资金 | 已融资超过1亿美元 |
API服务的差异化:
- 优势:更稳定的服务,更好的SLA
- 功能:比开源版本更多的功能
- 合规:企业级的数据处理协议
- 价格:比Midjourney等更灵活
6.2 开源与商业的平衡艺术
独特的"分层开源"策略:
- 完全开源层:Stable Diffusion基础模型
- 限制开源层:某些版本有使用限制
- 商业专属层:企业版工具和模型

这种策略的智慧:
- 社区获得了强大的基础工具
- 企业获得了需要的稳定性和支持
- 公司获得了可持续发展资金
- 生态获得了多样性
实际案例:Clipdrop产品线:
- 背景:2023年收购的AI工具套件
- 模式:免费基础功能 + 付费高级功能
- 产品:去背景、图像放大、重照明等
- 成功 :证明了"免费增值"模式在AI工具上的可行性
七、争议与挑战:光环下的阴影
7.1 数据版权问题
Stable Diffusion 训练数据来自 LAION-5B (网络爬取的图文对),包含大量未授权艺术家作品。
多起诉讼(如 Getty Images 起诉 Stability AI)仍在进行中。
Stability 的回应:
"我们训练的是'概念',而非复制作品。且用户生成内容版权归用户所有。"
7.2 滥用风险:生成虚假信息、色情内容
尽管有安全过滤器,但开源模型可被绕过。
社区自发开发 NSFW 检测插件 、内容水印工具,试图建立自律机制。
7.3 深度伪造与艺术家权益
Stability AI的立场:
- 技术措施:在模型中加入隐形水印
- 使用政策:禁止生成误导性内容
- 教育倡导:推广媒体素养教育
- 技术方案:开发深度伪造检测工具
艺术家的担忧:
- 风格被模仿而无补偿
- 作品被用于训练数据而无告知
- 市场被AI生成内容冲击
Stability AI的应对:
- Opt-out机制:艺术家可以要求从训练数据中移除作品
- 风格保护:避免直接模仿特定艺术家
- 合作计划:与艺术家合作开发工具
- 教育:帮助艺术家学习使用AI工具
我的观点:AI不是艺术的敌人,而是新的工具。就像摄影没有消灭绘画,数字绘画没有消灭传统艺术一样,AI艺术将找到自己的位置,与人类艺术共存。
八、中国用户指南:如何高效使用 Stability AI?
8.1 模型下载加速
- 魔搭(ModelScope):阿里云已同步 SDXL、SVD 等模型;
- HF Mirror :设置
HF_ENDPOINT=https://hf-mirror.com; - Civitai 镜像站:国内有多个镜像(如 liblib.ai、fooocus.cn)提供 LoRA/Checkpoint 下载。
8.2 本地部署优化
- 使用 秋叶整合包:一键安装 WebUI,内置中文、插件、模型管理;
- 显存不足?启用
--medvram或使用 TensorRT 加速; - Mac 用户可用 Draw Things(App Store 应用)运行量化版模型。
8.3 替代方案参考
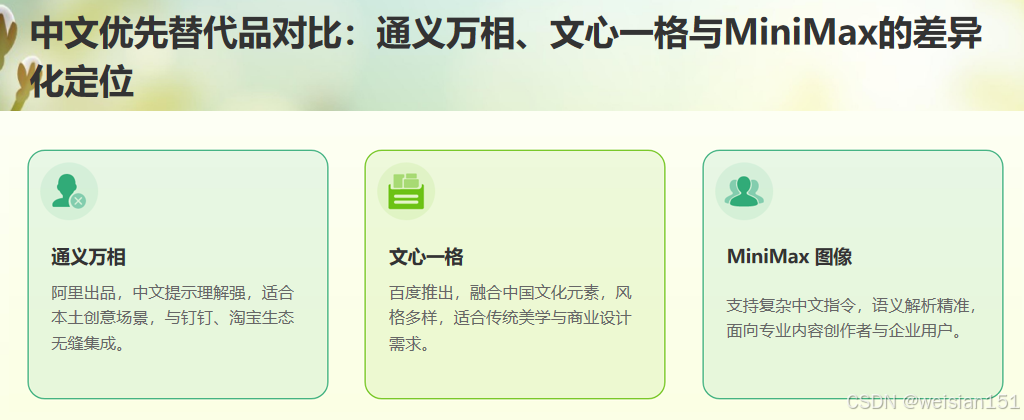
若追求中文优化,可关注:
- 通义万相(阿里):中文提示理解强;
- 文心一格(百度):本土化风格丰富;
- MiniMax 图像生成:支持复杂中文指令。
但若要自由度、生态、可定制性,Stable Diffusion 仍是首选。
九、未来展望:Stability AI 想走向何方?
根据官方路线图,Stability AI 正聚焦三大方向:
- 实时多模态生成:文本→图像→视频→音频无缝衔接;
- 个人AI代理:每个创作者拥有专属"AI助手",理解其风格、偏好、项目历史;
- 去中心化训练:利用全球闲置算力,构建"AI合作社"模式。
"我们的目标不是成为下一个 Adobe,而是让 Adobe 成为过去。"
------ Emad Mostaque
十、给不同读者的建议
10.1 如果你是创作者或艺术家
开始的最佳路径:
- 从WebUI开始:不需要编程,图形界面操作
- 学习提示词工程:掌握"用文字画画"的语言
- 探索社区模型:在CivitAI上找到你喜欢的风格
- 尝试微调:用少量作品训练自己的风格
心态调整:
- AI不是替代,而是增强
- 你的审美和创意指导才是核心
- 学习新技术不是背叛传统,而是扩展工具箱
10.2 如果你是开发者
技术学习路径:
bash
# 1. 基础使用
pip install diffusers transformers torch
# 2. 深入研究
git clone https://github.com/CompVis/stable-diffusion
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
# 3. 贡献社区
# - 提交PR修复bug
# - 开发扩展插件
# - 分享训练的技术洞见项目想法:
- 工具开发:让SD更容易使用的工具
- 垂直应用:针对特定行业的解决方案
- 效率优化:让SD在低端硬件上运行得更好
10.3 如果你是企业家或企业决策者
评估Stability AI技术:
- 成本效益分析:与传统创作方式对比
- 技术可行性:你的团队是否有能力实施
- 合规性检查:确保符合行业规定
试点项目建议:
- 营销内容生成:社交媒体图片、广告素材
- 产品设计辅助:概念图生成、风格探索
- 培训材料制作:教育插图、演示素材
风险控制:
- 从小项目开始,验证效果
- 建立内容审核流程
- 保持人类在关键决策中的角色
结语:开源的魔法与创造者的未来
让我以两个故事结束这篇深度解析。
第一个故事关于一位印度乡村教师 :
她不懂英文,不会编程,但通过翻译工具和Stable Diffusion WebUI,她为自己的学生制作了本地语言的教育插图。这些孩子第一次有了色彩丰富的学习材料。她说:"我以前只能描述世界,现在我可以用图片展示它。"
第二个故事关于一位退休的日本画家 :
他因手抖无法继续作画,几乎陷入抑郁。他的孙子教他使用ControlNet和Stable Diffusion。现在,他先画出简单的草图,AI帮他完善,他再用手绘板添加细节。他说:"AI没有取代我的手,它成为了我新的手。"
这两个故事揭示了一个核心真相:技术本身没有意义,是人们如何使用它才赋予了意义。
Stability AI的价值不在于创造了多么先进的算法,而在于将这些算法交到了普通人手中。这不仅仅是技术开源,这是创造力的民主化。
我们正处在一个转折点:创造工具正在从专业软件变成通用基础设施。就像电力、互联网一样,AI生成能力正在成为每个人都可以使用的基础资源。
Stability AI提醒我们:在未来,最重要的可能不是你拥有什么技术,而是你选择如何使用它;不是你有多强的计算能力,而是你有多丰富的想象力。
创造力不再是少数人的专业,而是每个人的权利。
我是 Weisian,一个相信技术应该服务于人的博主。在这个AI快速变化的时代,我很庆幸有像Stability AI这样的存在,提醒我们技术可以既强大又普惠,既先进又开放。
无论你是艺术家、开发者、教育者,还是只是一个好奇的探索者,现在都是参与这场创造革命的最佳时机。因为这一次,画笔在每个人手中。
资源附录:开始你的创造之旅
- 零代码起点 :automatic1111.github.io(WebUI教程)
- 模型宝库 :civitai.com(社区训练的各种模型)
- 学习提示词 :lexica.art(提示词灵感库)
- 本地运行指南 :github.com/AUTOMATIC1111/stable-diffusion-webui/wiki
- 我的个人推荐 :从 Stable Diffusion XL 1.0 + AUTOMATIC1111 WebUI 开始,这是最佳平衡点
作者后记
上周,我教70岁的母亲用 Stable Diffusion 画她童年记忆中的老屋。
当那幅带着青瓦白墙、桂花树和石阶的画面出现在屏幕上时,她轻轻摸了摸屏幕,说:
"原来,回忆也可以被重新看见。"
那一刻我明白:
技术的伟大,不在于它多先进,
而在于它能让普通人,温柔地触碰自己的梦。