Ad Hoc Query:
Ad-hoc查询(即席查询)是一种允许用户根据临时需求灵活定义查询条件并实时获取结果的技术,无需预先开发固定功能模块。1
**核心特性与技术实现:** 其核心特性包括查询条件的自定义、对多数据源(如结构化与非结构化数据)的接入支持,以及实时响应能力,以满足交互式分析需求。
Presto:
是由Facebook开发的分布式SQL查询引擎,支持交互式分析超过250PB规模的数据。该项目始于2012年秋季,2013年正式开源,采用MPP架构实现跨数据源查询,可对接MySQL、Hive、Cassandra等多种异构数据源。
Presto和Apache Calcite的关系?
Presto和Apache Calcite都是大数据生态系统中用于SQL查询处理的关键组件,但它们在架构中的角色和关系有所不同。Presto是一个分布式SQL查询引擎,专注于大规模数据分析,而Calcite是一个动态数据管理框架,提供SQL解析、查询优化和数据源适配功能。12
**Presto使用Calcite作为其查询优化器的核心组件。** 具体来说,Presto在查询处理流程中依赖Calcite来处理SQL解析、查询优化和逻辑计划生成,Calcite的优化器基于Volcano或HepPlanner实现基于规则(RBO)或基于成本(CBO)的优化策略,例如应用谓词下推、常量折叠等规则来提升查询效率;这种集成使Presto能够支持多数据源查询和高效执行计划生成。12
**两者在架构中的定位不同:** Calcite作为一个独立的框架,设计为可嵌入其他系统,提供通用的查询优化能力,而Presto则是一个完整的查询引擎,包含协调器、工作节点和MPP架构,直接处理分布式查询执行。34
**在实际应用中,Presto通过集成Calcite实现了灵活性和高性能。** 例如,在数据联邦场景中,Presto利用Calcite的优化规则来处理跨数据源查询,同时通过自定义配置(如内存和并行度调整)进一步提升性能。4
跨库联合查询性能优化:数据联邦工具配置、查询下推策略及结果集合并的实操方法
trino和presto的区别???
Trino和Presto均是分布式SQL查询引擎,专为跨异构数据源的高效查询设计,但Trino作为Presto的开源分支,在架构、功能和社区发展上已形成显著差异。12
**起源与社区发展:** Presto最初由Facebook开发并于2013年开源,后由社区维护;Trino于2020年由原Presto核心团队成员发起,旨在解决Presto的架构局限性并加速创新迭代,目前已成为独立项目,社区活跃度持续提升。12
**架构设计:** Presto采用经典的Master-Worker架构,包括Coordinator节点(负责查询解析与任务分发)和Worker节点(负责计算),而Trino在架构上进行了多项改进,例如引入可插拔的Session Property Managers、动态过滤机制以增强查询优化器的自适应能力,并通过故障容错执行提升大规模集群的稳定性。2
**功能与性能:** Trino在Presto基础上扩展了对更多数据源和文件格式的支持,同时加强了安全性、稳定性和易用性;两者在查询性能上相近,但Trino的优化更适合复杂场景,例如在云原生环境中表现更优。12
**生态系统与兼容性:** Trino与Presto保持较高的语法兼容性,部分SQL查询可互通,但存在差异;Trino的生态系统通过插件机制持续扩展,支持更广泛的数据集成需求。23
**适用场景建议:** 对于需要快速查询、实时分析和跨数据源整合的场景(如大数据仓库、数据湖),两者均适用,但Trino因架构优化更适合云原生、高并发环境,而Presto在传统分布式系统中仍有应用。12
Apache Doris 简介
Apache Doris 是一款基于 MPP 架构的高性能、实时分析型数据库。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris 既能支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
基于这些优势,Apache Doris 非常适合用于报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等场景。用户可以基于 Doris 构建大屏看板、用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
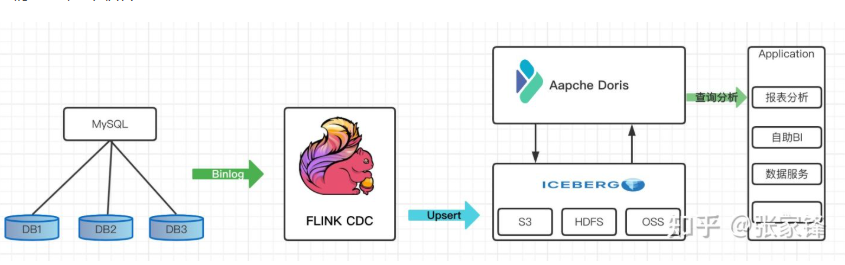
首先我们从Mysql数据中使用Flink 通过 Binlog完成数据的实时采集
然后再Flink 中创建 Iceberg 表,Iceberg的元数据保存在hive里
最后我们在Doris中创建Iceberg外表
在通过Doris 统一查询入口完成对Iceberg里的数据进行查询分析,供前端应用调用,这里iceberg外表的数据可以和Doris内部数据或者Doris其他外部数据源的数据进行关联查询分析
Doris湖仓一体的联邦查询架构如下:

- Doris 通过 ODBC 方式支持:MySQL,Postgresql,Oracle ,SQLServer
- 同时支持 Elasticsearch 外表
- 1.0版本支持Hive外表
- 1.1版本支持Iceberg外表
- 1.2版本支持Hudi 外表