TL;DR
- 场景:基于 Flume、HDFS、Hive 验证离线数仓链路,完成会员活跃、新增、留存指标跑通。
- 结论:该链路适合教学和离线验证,但文中存在命名、路径、日志参数与时间口径不一致的问题。
- 产出:给出可用于技术博客发布的 SEO 摘要、版本矩阵、错误速查卡,便于读者快速定位和复现。

版本矩阵
| 项 | 已验证 | 说明 |
|---|---|---|
| 数仓分层链路(ODS→DWD→DWS→ADS) | 是 | 文章结构完整,分层目标明确,符合典型离线数仓教学路径 |
| Flume Taildir 采集本地日志 | 是 | 配置包含 source/channel/sink,具备基础可运行形态 |
| HDFS 按日志类型+日期分区落盘 | 是 | /%{logtype}/dt=%{logtime}/ 具备分区设计思路 |
| Hive ODS 外部表挂载 | 是 | 有加载脚本与查询示例,说明链路已打通到 ODS |
| Hive DWD 明细层清洗 | 是 | 有 DWD 加载脚本与查询结果,具备验证闭环 |
| 活跃会员指标链路 | 是 | 提供了 DWS/ADS 脚本顺序,链路定义清楚 |
| 新增会员指标链路 | 是 | 提供对应脚本,但正文未展示执行结果 |
| 明细会员留存指标链路 | 是 | 提供对应脚本,但正文未展示结果表结构与样例 |
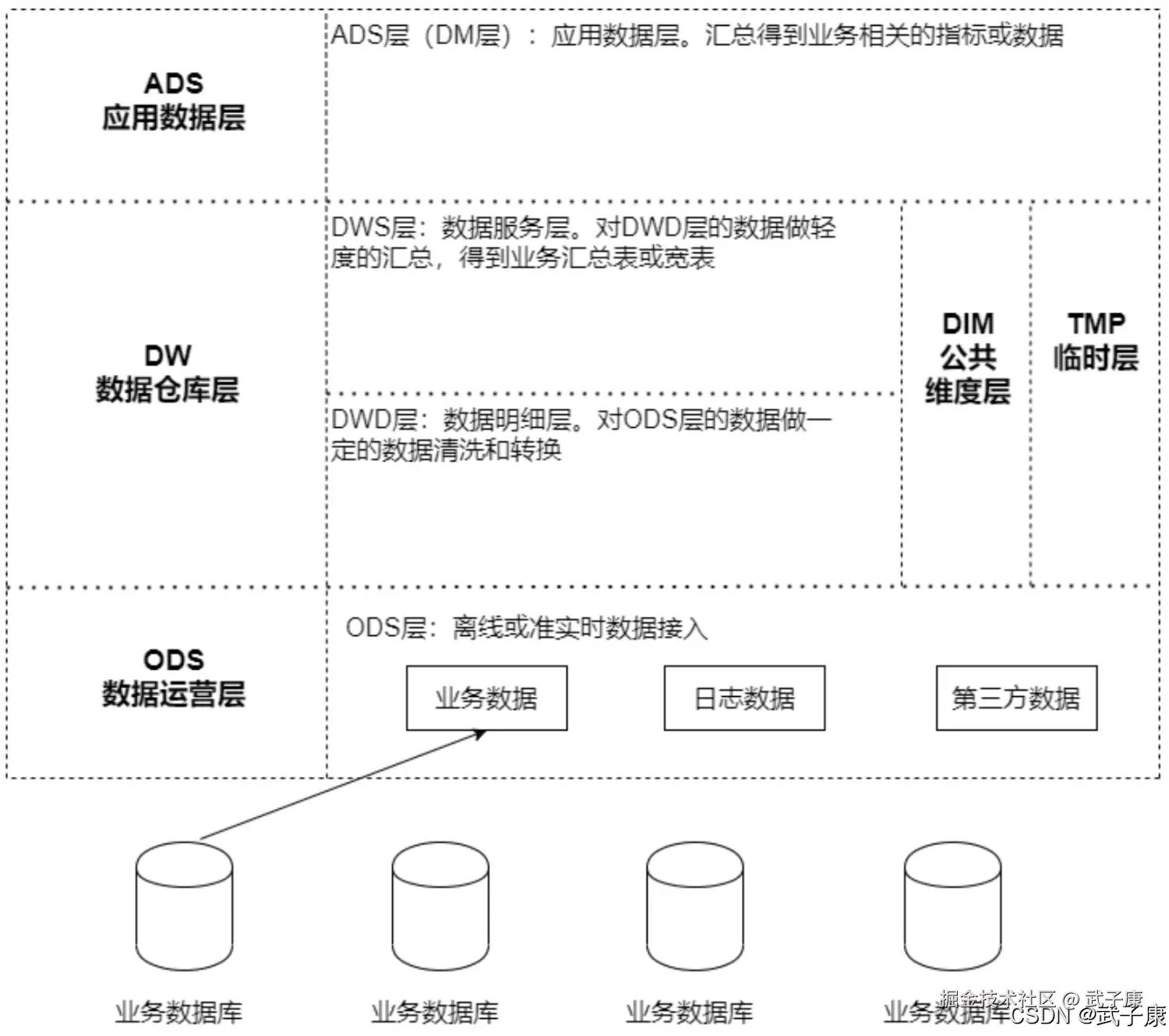
数据测试
数据采集 => ODS => DWD => DWS => ADS => MySQL 活跃会员、新增会员、会员留存
- DAU:Daily Active User(日活跃用户)
- MAU:Monthly Active User(月活跃用户)
- 假设App的DAU在1000W左右,日启动数据大概1000W条
查看脚本
脚本调用次序:(名字可能有几个不完全能对上,如果名字不对,也不会差太多,修改一下成下面对应的,方便后续的执行)
shell
# 加载ODS / DWD 层采集
ods_load_startlog.sh
dwd_load_startlog.sh
# 活跃会员
dws_load_member_start.sh
ads_load_member_active.sh
# 新增会员
dws_load_member_add_day.sh
ads_load_member_add.sh
# 会员留存
dws_load_member_retention_day.sh
ads_load_member_retention.sh我们之前编写的好的脚本如下所示: 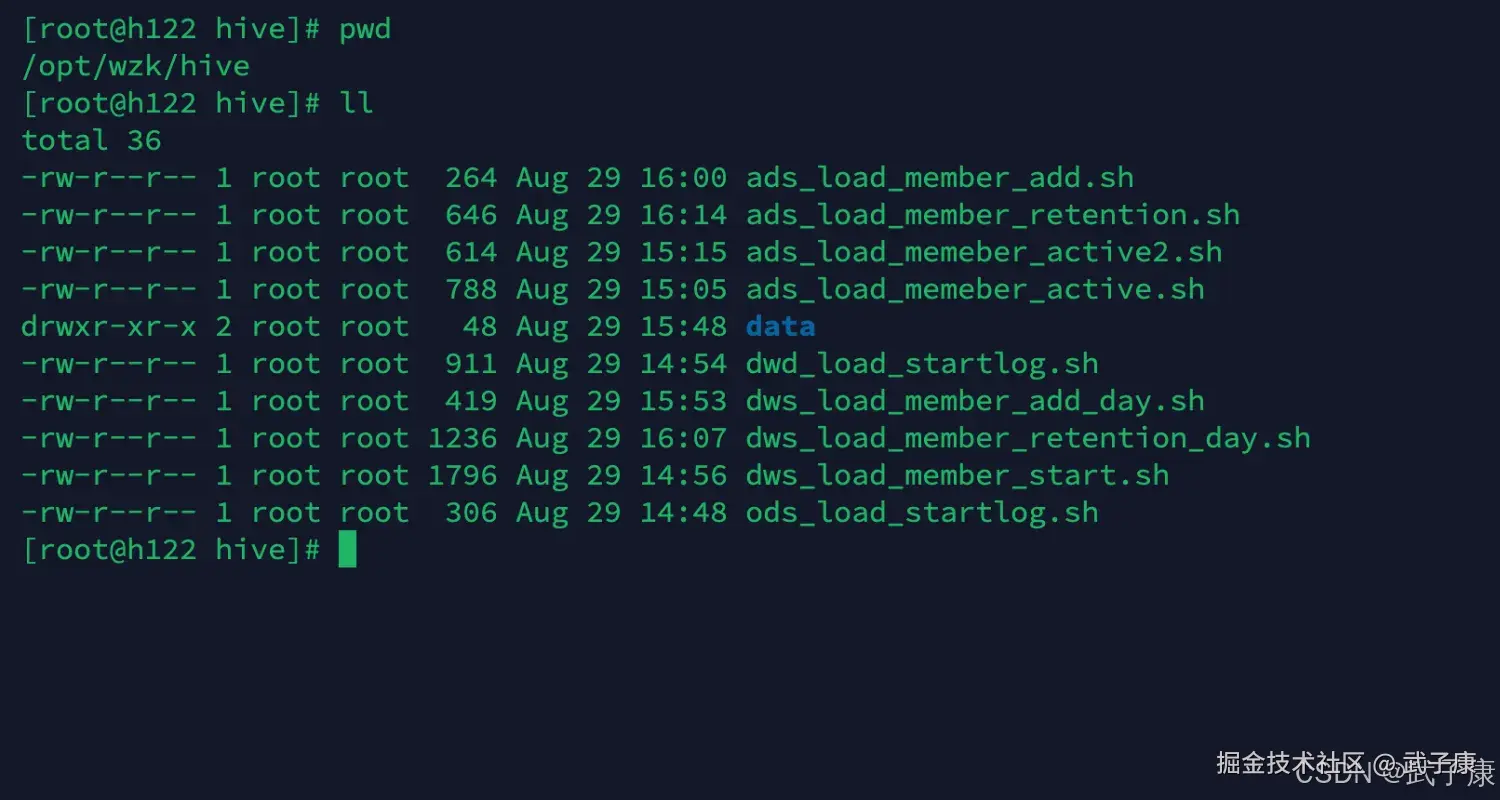
清理数据
将之前测试的数据清理掉,主要是HDFS上数据,避免对后续的操作产生错误的影响:
shell
hadoop fs -rm -r /user/data/logs/start/
hadoop fs -rm -r /user/data/logs/enent/
hadoop fs -mkdir /user/data/logs/start
hadoop fs -mkdir /user/data/logs/event加载数据
我们需要启动Flume,将数据写入,这里准备了几个 log 文件,4MB大小的数据文件。我们将模拟这个文件是程序产生的日志文件,然后Flume采集日志文件后,写入到HDFS中,重新回顾我们的配置文件(flume-log2hdfs2.conf):
shell
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# taildir source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/wzk/conf/startlog_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /opt/wzk/logs/start/.*log
a1.sources.r1.headers.f1.logtype = start
a1.sources.r1.filegroups.f2 = /opt/wzk/logs/event/.*log
a1.sources.r1.headers.f2.logtype = event
# 自定义拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = icu.wzk.LogTypeInterceptor$Builder
# memorychannel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 2000
# hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/data/logs/%{logtype}/dt=%{logtime}/
a1.sinks.k1.hdfs.filePrefix = startlog.
a1.sinks.k1.hdfs.fileType = DataStream
# 配置文件滚动方式(文件大小32M)
a1.sinks.k1.hdfs.rollSize = 33554432
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 向hdfs上刷新的event的个数
a1.sinks.k1.hdfs.batchSize = 1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1- 监听的日志目录是:/opt/wzk/logs/start/.*log,一会儿我们将把文件放到这个目录下
- 写入的HDFS目录是:/user/data/logs/start 下
我们先启动Flume,然后将对应的日志放入到监听的目录下。
shell
flume-ng agent --conf-file /opt/wzk/flume-conf/flume-log2hdfs2.conf -name a1 -Dflume.roog.logger=INFO,console我的数据如下图所示:
shell
2021-09-16 16:55:01.744 [main] INFO icu.wzk.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"2","action":"0","error_code":"0"},"time":1595260800000},"attr":{"area":"洛阳","uid":"2F1009对应的就截图如下所示: 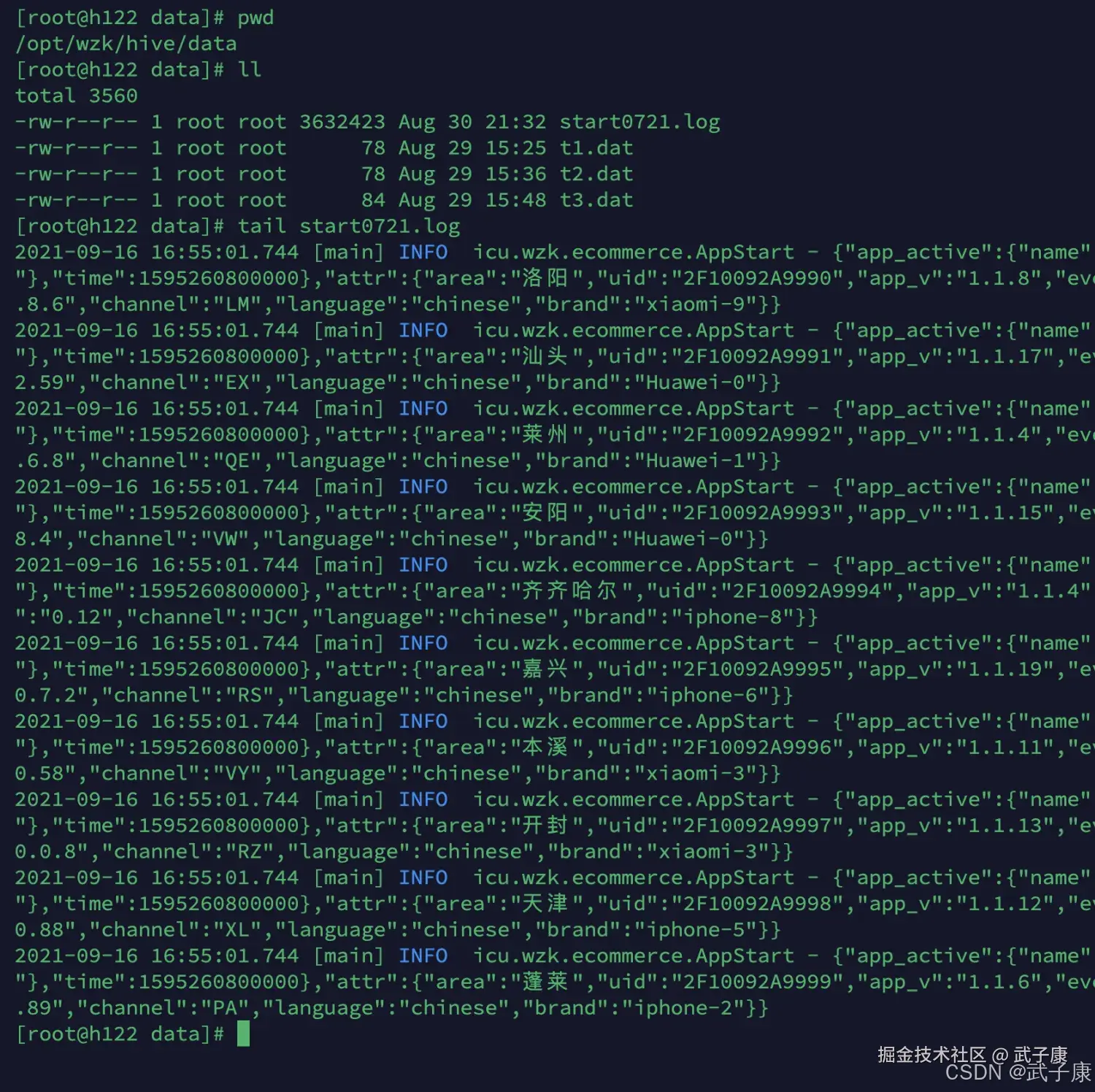 把这个数据移动到监控目录下:
把这个数据移动到监控目录下:
shell
cp /opt/wzk/hive/data/start0721.log /opt/wzk/logs/start/start0721.log我们观察到flume的程序日志如下:
shell
24/08/31 01:59:19 INFO taildir.ReliableTaildirEventReader: headerTable: {}
24/08/31 01:59:19 INFO taildir.ReliableTaildirEventReader: Updating position from position file: /opt/wzk/conf...对应的截图如下所示: 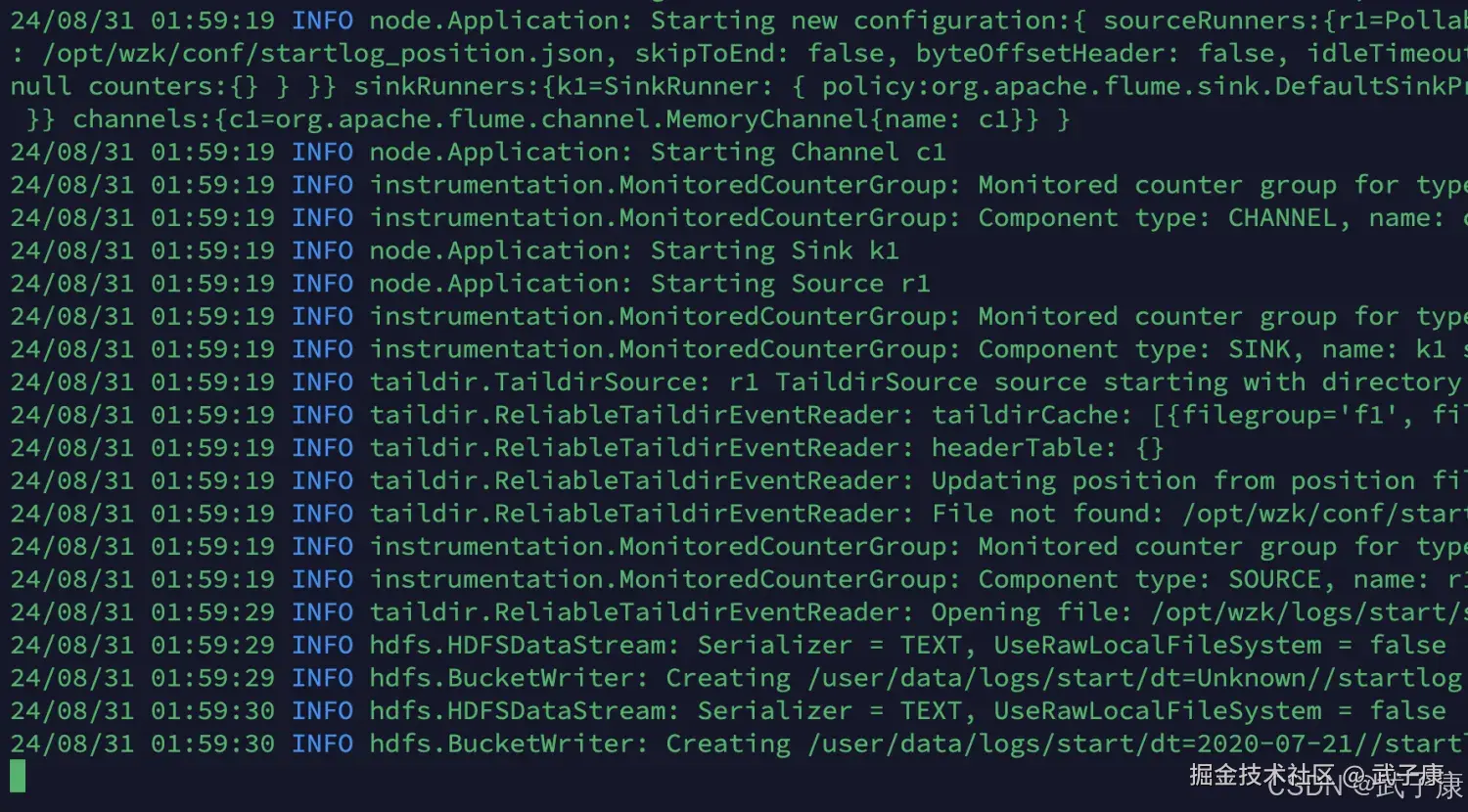 HDFS状态如下:
HDFS状态如下: 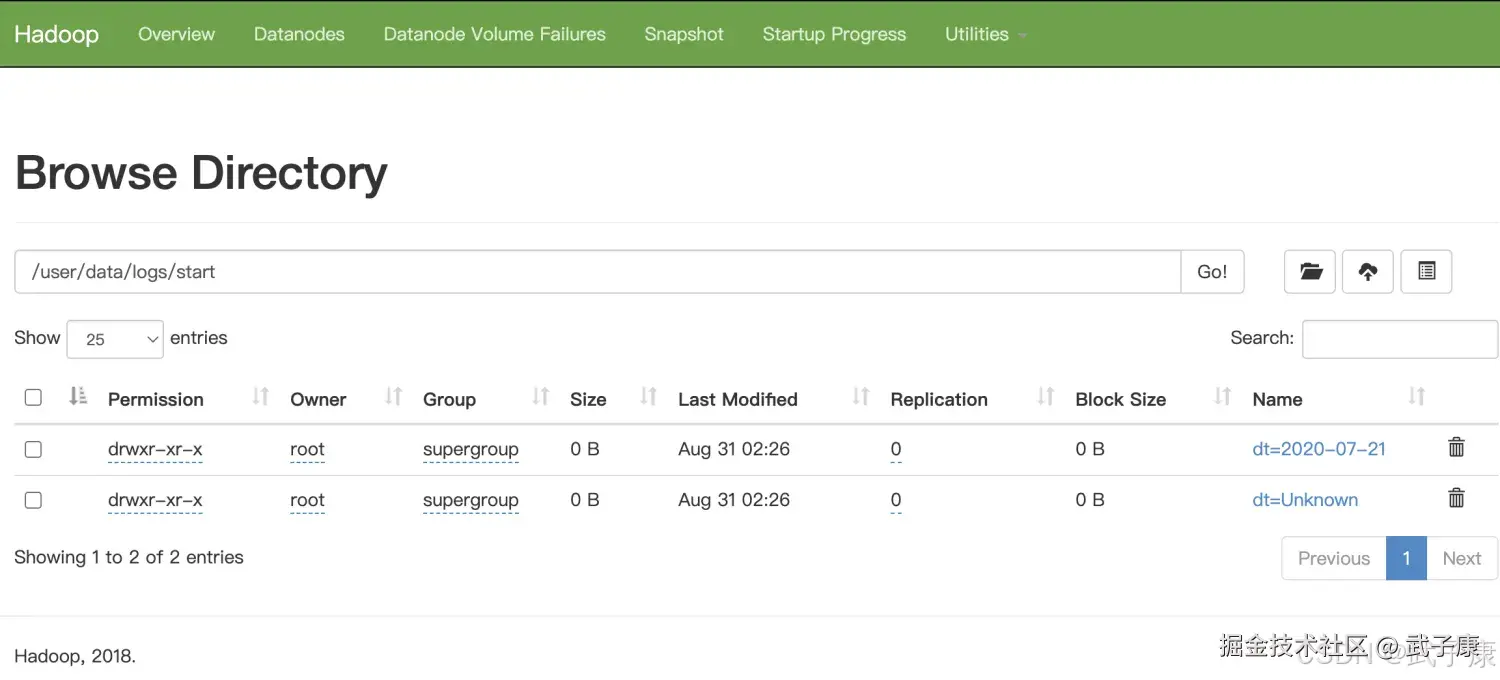
ODS
定义
ODS 是操作型数据存储层,主要用于存放从业务系统中抽取的原始数据。 数据通常以 业务系统的原始格式 或经过少量标准化处理的形式存储。 是数仓的"数据输入口",负责承接来自业务系统的数据。
功能
数据完整存储:保持数据原始性,便于追溯问题。 解耦:实现业务系统与数据仓库之间的隔离。 实时性支持:如果数据需要实时分析,ODS 可以支持数据的近实时同步。
数据处理
轻度清洗:
- 去除重复数据。
- 标准化时间字段、日期字段格式。
- 增加一些必要的标识字段(如抽取时间、源系统等)。
轻量变换:
- 数据结构与源系统保持一致,尽量避免复杂的转换。
存储特点
- 全量存储:ODS 通常存储的是全量数据(包括历史快照)。
- 分区设计:按时间分区(如按天、小时),以便数据管理和性能优化。
- 高吞吐:支持高并发写入和抽取。
加载ODS
shell
sh ods_load_startlog.sh 2020-07-21执行结果如小图所示:  我们查看Hive中的数据:
我们查看Hive中的数据:
shell
hive
-- 执行SQL
use ods;
select * from ods_start_log limit 3;这里可以看到,外部表已经把数据挂载上了:
加载ODS其他数据
由于数据很多,这里重复上述的日期步骤,把其他数据加载进来,总共的数据如下图所示:  对应的Flume的结果:
对应的Flume的结果:  对应的HDFS的结果:
对应的HDFS的结果:
DWD
定义
DWD 是明细数据层,存储的是经过清洗和轻度处理的宽表数据。 DWD 数据是细粒度的、面向分析的明细数据,数据通常已经具备一定的 业务逻辑处理 和 质量保证。
功能
数据细化:清洗、标准化后的数据,供后续主题建模使用。 性能优化:减少后续查询时的数据清洗和转换开销。 维度宽表化:对多表进行宽表关联,便于业务分析。
数据处理
数据清洗:
- 去除脏数据,如无效值、空值处理。
- 格式统一,如日期格式、金额精度。
数据整合:
- 按照业务逻辑关联多张表(如订单表和用户表)。
- 增加计算字段或衍生字段(如消费总金额)。
去重与规范化:
- 去重是 DWD 层的常见操作,保证数据唯一性。
- 统一编码、统一时间维度等。
存储特点
- 宽表存储:尽可能将相关的明细数据组织成宽表,减少关联操作。
- 分区设计:根据业务需求设计分区,通常也以时间为主要分区键。
加载DWD
shell
sh dwd_load_startlog.sh 2020-07-21
# 后续加载了 21-31的数据 重复性高就略过了执行之后的结果如下图所示: 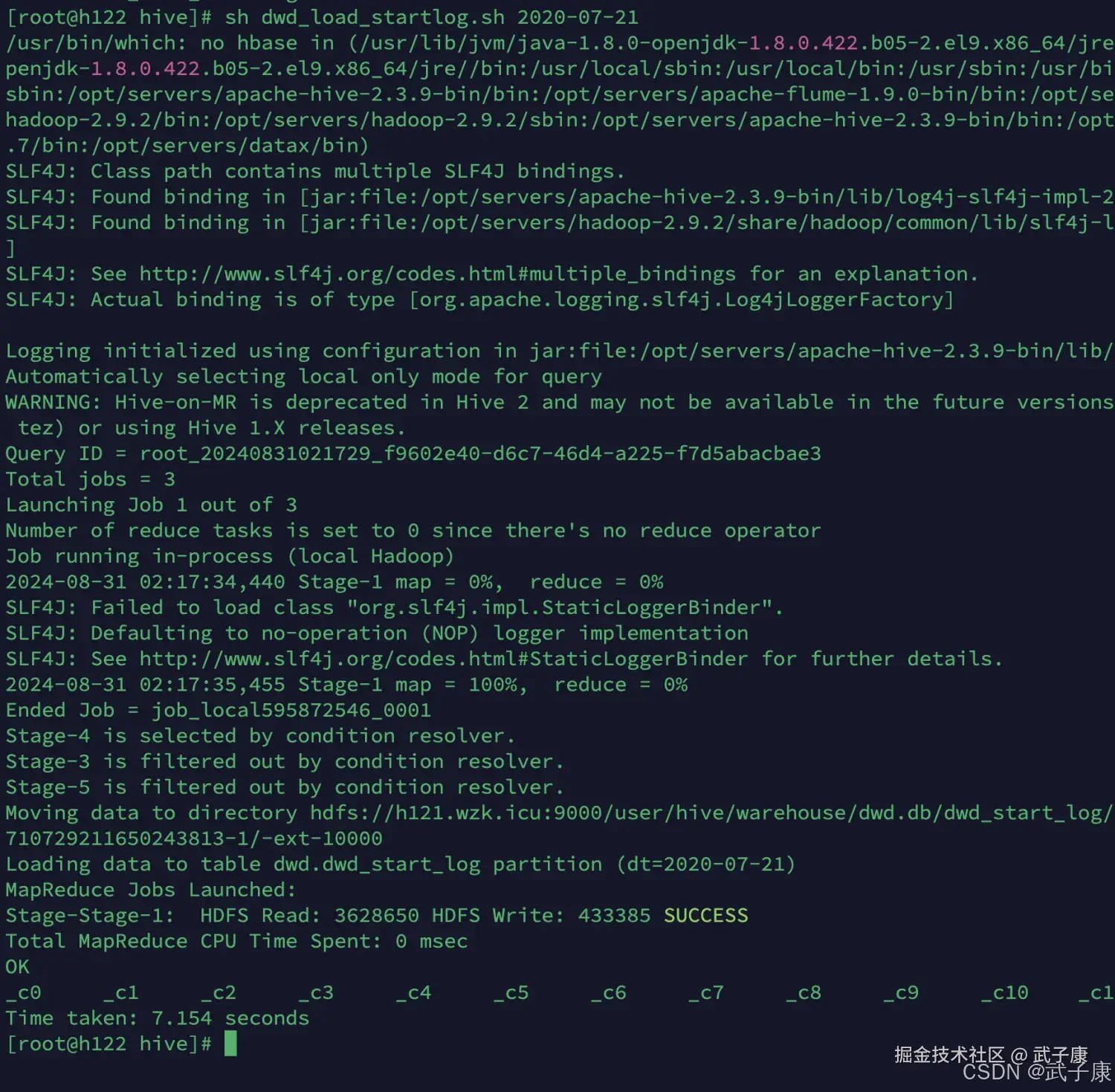 数据将会写入到:dwd.dwd_start_log 我们查看数据的情况:
数据将会写入到:dwd.dwd_start_log 我们查看数据的情况:
shell
hive
-- 查看数据
use dwd;
select * from dwd.dwd_start_log limit 3;可以看到数据已经加载出来了:
shell
1FB872-9A1001 连云港 2F10092A1 1.1.8 common 0.43 PN chinese iphone对应的截图如下所示:
加载DWD其他数据
由于数据很多,这里就都加载了,都是重复步骤,就省略了。 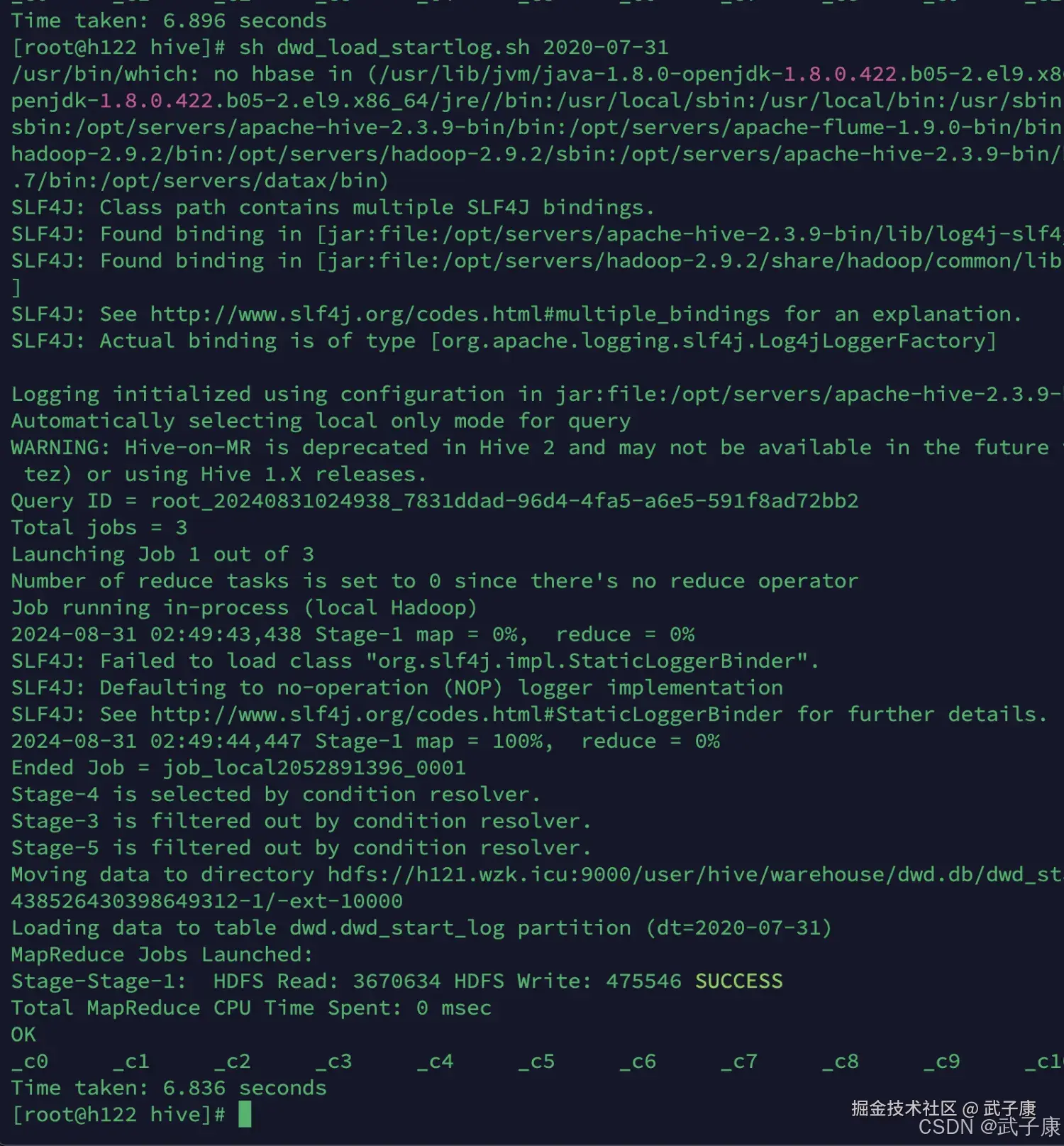
错误速查
| 症状 | 根因 | 定位修复 |
|---|---|---|
| Flume 启动后无预期日志输出 | 启动参数拼写错误 | 检查 -Dflume.roog.logger 改为标准 logger 参数,确保 root logger 拼写正确 |
| HDFS 清理后后续采集目录异常 | enent 与 event 拼写不一致 | 对比删除命令与创建命令统一为 event,避免删错目录或遗漏旧数据 |
| Flume 监听不到文件 | 监听目录与复制目录不一致或文件名不匹配 | 检查 filegroups 正则与 cp 目标目录确认 /opt/wzk/logs/start/.*log 与实际文件路径、扩展名一致 |
| HDFS 有目录但 Hive 查不到数据 | 分区目录日期字段依赖拦截器,未正确写入 logtime | 检查自定义拦截器 LogTypeInterceptor 输出 header 确保拦截器正确注入 logtype/logtime,并与 Hive 分区字段一致 |
| ODS 可查但 DWD 无数据 | DWD 脚本日期参数与 ODS 实际分区不匹配 | 核对 sh dwd_load_startlog.sh 2020-07-21 与 ODS 分区统一业务日期口径,确认源分区存在后再跑 DWD |
| 日志文件复制后无新增消费 | Taildir positionFile 记录了旧偏移 | 检查 /opt/wzk/conf/startlog_position.json 测试前清理或重置 positionFile,避免 Flume 认为已消费 |
| HDFS 文件滚动异常或文件长期不关闭 | rollCount/rollInterval/idleTimeout 均设为 0 | 检查 sink 滚动参数按测试场景设置合理滚动阈值,避免小样本测试不落稳态文件 |
| 文章中的日期看起来混乱 | 样例日志时间、执行日期、日志截图时间跨 2020/2021/2024 | 核对正文中的日期片段发布前统一演示日期,避免读者误判数据链路有问题 |
| 脚本执行顺序理解成本高 | 只给脚本名,未明确"依赖关系/输入输出表" | 检查"查看脚本"章节增加每个脚本对应的输入层、输出层、目标表说明 |
| 读者能跑通 ODS/DWD,但无法验证 ADS 指标正确性 | 缺少 ADS 结果查询示例 | 检查 DWS/ADS 段落内容补充至少一条活跃/新增/留存的 SQL 查询结果示例 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解