近期,猪猪侠(GG Bond)的声音模型在各大视频平台广受欢迎。作为00后的"童年男神",许多人喜欢这个红胖子的形象和他那极具辨识度的声音。
那么,如何制作出这样一个逼真的AI声音模型呢?接下来,我将为您详细解答。
一、 数据集准备(最重要的一步)
为了训练出高质量的AI猪猪侠声音模型,我们需要收集大量的猪猪侠声音样本。
- 样本要求:这些样本应涵盖猪猪侠在不同情绪下的语音,比如变身时的热血呐喊、平时说话的幽默调侃、或者尴尬时的低语等。
- 获取途径:我们可以从《猪猪侠》的历代动画、大电影或官方视频中截取这些声音。
注意:这是不可或缺且最重要的一步,数据的纯净度直接决定了最终模型像不像。
二、 技术原理(RVC)
接下来,我们需要使用深度学习框架。目前最主流的是 RVC模型(Retrieval-based Voice Conversion)。 简单来说,这是一项基于深度学习的语音处理技术。其核心原理是将输入的"源声音"(比如你自己的声音)与"目标声音"(猪猪侠的声音)进行对齐和映射,从而实现变声效果。
三、 制作流程拆解
听不懂专业术语没关系,做AI翻唱其实就分四步:
- 提取声音(准备干声数据集)
- 训练模型(让AI学习GG Bond的声线)
- 推理歌曲(用模型进行转换)
- 合成歌曲(后期混音)
四、 如何提取声音?
提取声音主要有两种方式:手动提取和自动提取。
- 手动提取(推荐,更精准) : 使用音频编辑软件(如Audition)或简单的剪辑软件,把动画里猪猪侠说的话录屏或剪辑下来。你需要人工剔除背景音乐、打斗音效,只保留人声,然后导出成单独的WAV音频文件。 优点 :质量高,没有杂音干扰;缺点:非常耗时,但为了"男神"的效果,这是值得的。
- 自动提取: 利用信号处理方法(如UVR5等伴奏分离工具),通过算法把音频信号分成不同的频段,自动将人声和背景音分离。适合处理大量的音频素材。
常用工具下载
音频分离工具
UVR 5.6 免费软件 最佳歌曲分离 音频去噪优化 - 模型工坊 (mxgf.cc)
B站视频下载工具
链接:https://pan.baidu.com/s/1Y1zGf6Zl8er6tV0Su_Tivg?pwd=83e7
提取码:83e7
模型训练
RVC介绍
Retrieval-based-Voice-Conversion-WebUI 简称 RVC
一个基于VITS的简单易用的语音转换(变声器)框架
N卡下载
链接:https://pan.baidu.com/s/1Vzvpq_D-NFLL-IpvQtzPlA?pwd=mxgf
提取码:mxgf
--来自百度网盘超级会员V7的分享
A卡下载
https://pan.baidu.com/s/1XDp0dzvDpgqGgHT1r15b2A?pwd=z3oo
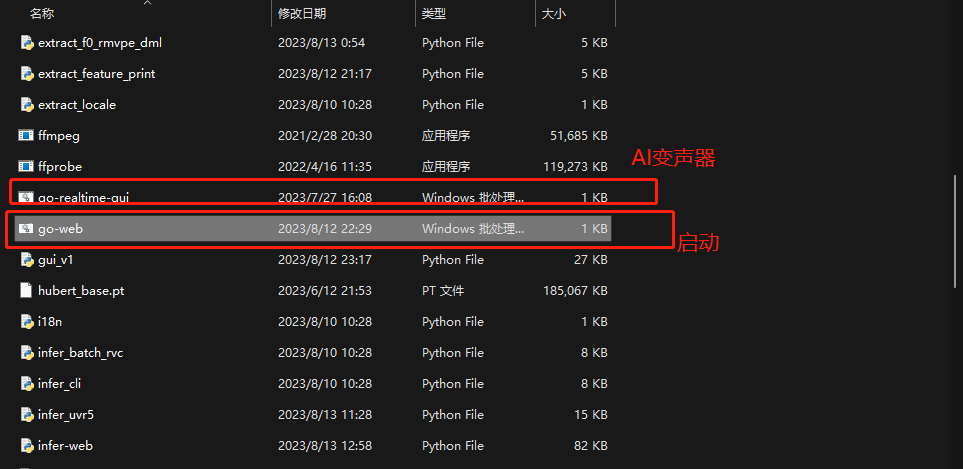
将整合包下载并解压,启动go-web.bat 等待运行
会跳转到浏览器,本地内网地址

进入训练界面,默认的参数默认就行,不用动
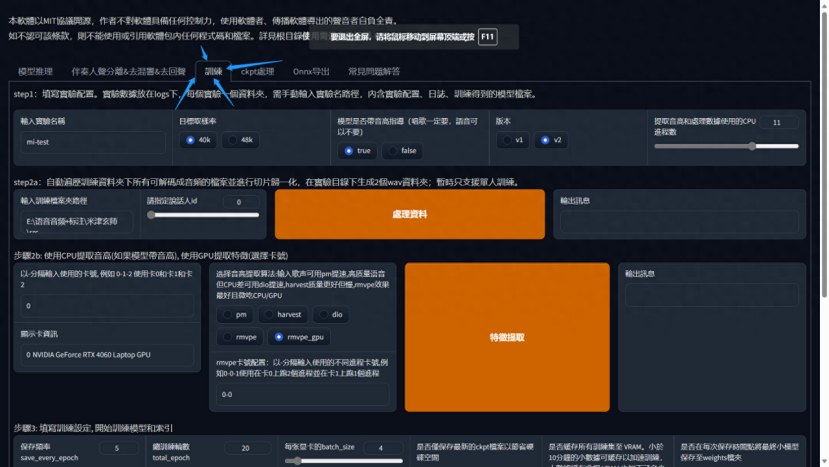
3,输入音频文件夹路径,处理数据
将要训练的的干声数据集放到本地任意英文路径文件夹内复,点击处理数据
处理数据
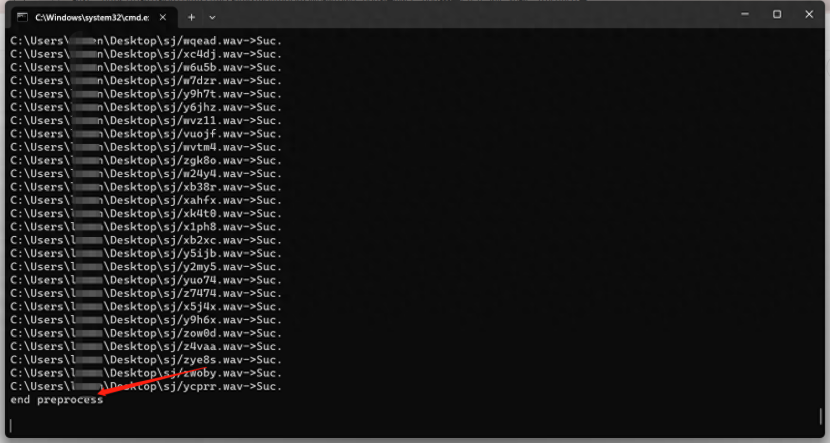
出现 end preprocess 表示处理完毕
特征提取
(特征提取是从声音信号中提取有用信息的过程,这些信息可以被用于训练模型进行分类或识别)
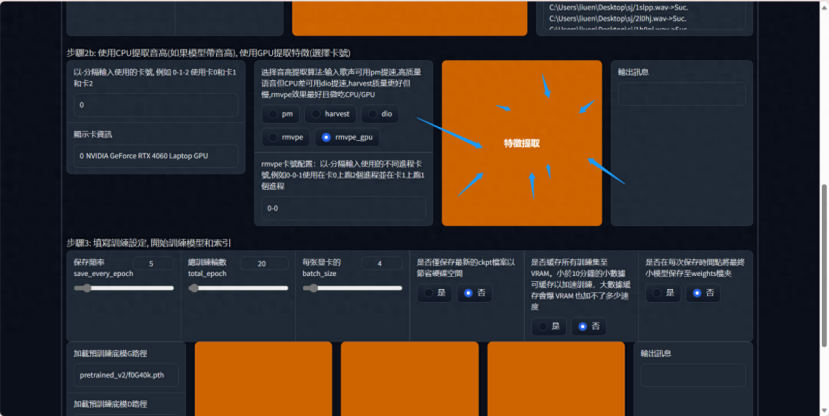

出现 all-feature-done 表示已经处理完毕,可以进行最后一步处理了
开始训练,设置训练的步数和保存频率
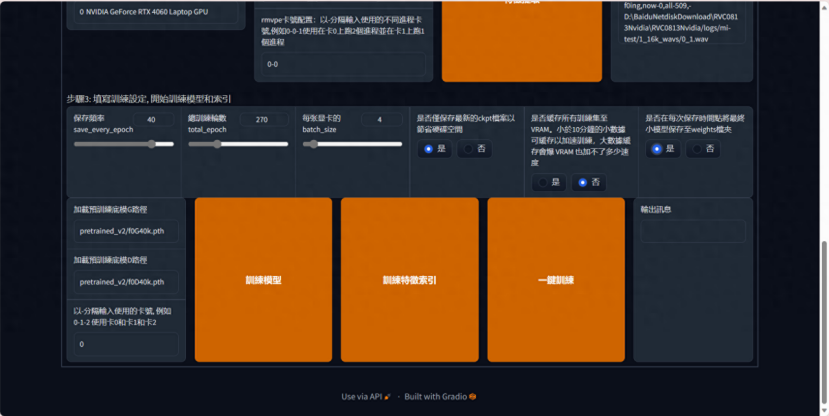
保存頻率 这个数值表示多少轮保存一次模型,如果你的电脑很牛很稳定 50轮也是可以的,不然就推荐 20-40轮保存一次模型
總訓練輪數一般 300轮,模型就可以出炉了
每张显卡的batch_size 如果你的显存是8则填8,显存多少,填多少数值。
点击一键训练

终端显示Epoch: 1字符,表示第一轮,正在训练了

等待几个小时后,就训练结束了,就可以进行下一步,对声音模型进行推理试音了。
三、 歌曲分离/推理
1,歌曲分离
1,准备好歌曲文件,格式包括AAC,FLAC等主流声音格式,但不包括加密格式,比如网易云加密歌曲,酷狗,qq音乐。
2,将歌曲文件放到UVR 5,进行分离,分离的目的是 把伴奏和人声抽离出来

处理完成之后会得到两个音频文件
1_陈雪凝 - 绿色_(Instrumental) 伴奏
1_陈雪凝 - 绿色_(Vocals) 人声
等下推理时候会用到 这个 _(Vocals) 人声部分

注:
- 模型要记得选择 MDX-NET UVR-MDX-NET Main
处理模型下载
https://pan.baidu.com/s/1QgjSllWUCoTNEYkzgMMMjA?pwd=yvkv
将下载好的模型,放到UVR根目录下面的models文件夹下
- 如果分离过程中出现报错,可能原因是显存或内存不足,尝试重启电脑
2,歌曲推理
- 打开整合包
RVC0813 整合包下载(整合包 包含 运行环境 启动器)
https://pan.baidu.com/share/init?surl=mEs9Jmi2tBot4AgH6ZWp-w&pwd=eqea
下载之后,解压
版本说明
下载RVC0813AMD_Intel包可解锁A卡I卡
(1)双击go-realtime-gui-dml.bat使用实时变声,A卡大概能压到300ms左右,以下有压力
(2)双击go-web-dml.bat使用训练推理(CPU训练)
N卡用户下载RVC0813Nvidia
(1)双击go-realtime-gui.bat使用实时变声,N卡大概能压到100ms左右,以下有压力
- 双击go-web.bat使用训练推理
选择合适自己的显卡下载
- 等待启动,出现地址,表示启动成功
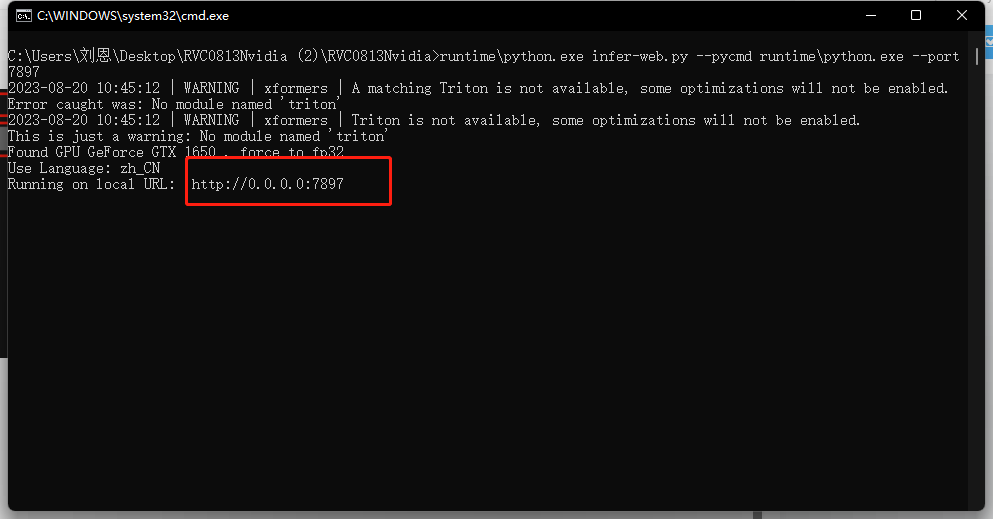
启动成功会自动跳转WEBUI
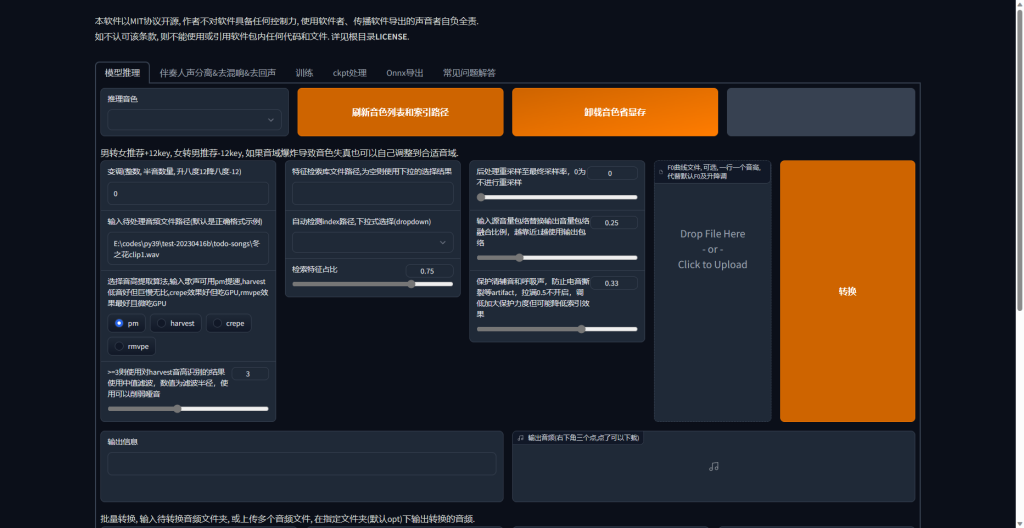
将模型放置到目录(训练好的,忽略这一步)

刷新音色,然后按顺序进行推理
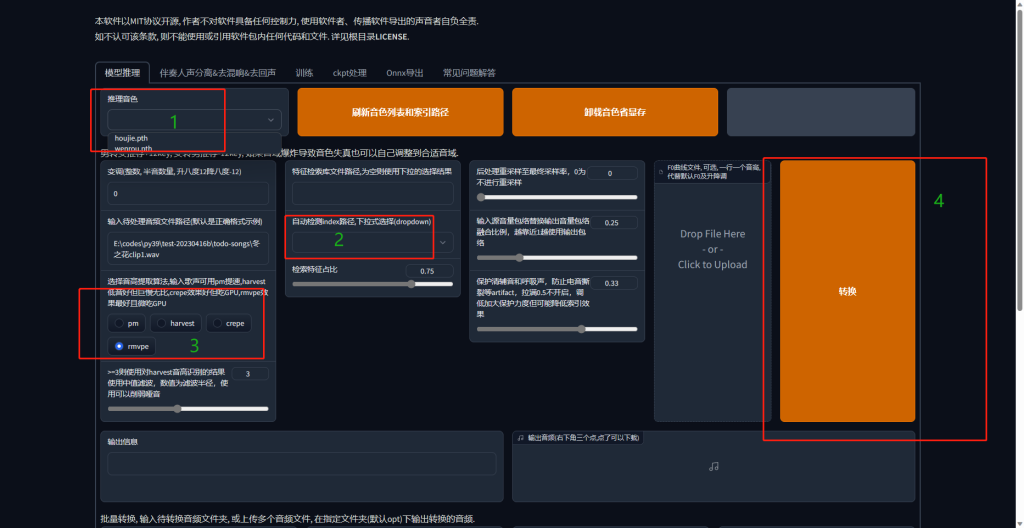
解疑
音频地址
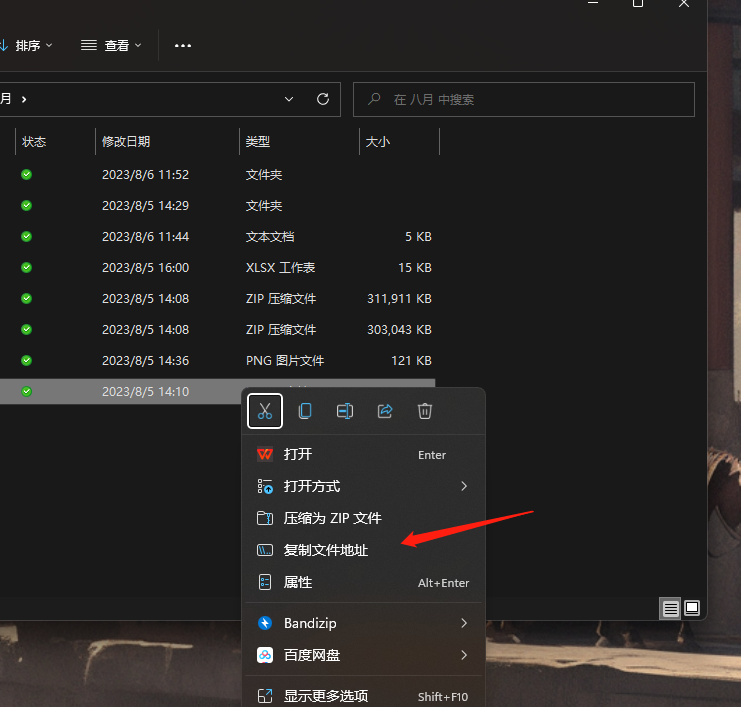
WIN11 鼠标右击可以快速复制地址,复制的地址前后如果带有双引号记得删除""
WIN10 需要将声音文件放到 任意文件夹内,按shift+鼠标右键 选择复制路径
四、歌曲合成
所需工具 AU 链接:https://pan.baidu.com/s/107cWfLF6ftdxxfVLipfnfw?pwd=mxgf
解压密码 @vposy
1,转换后的歌曲人声下载到桌面
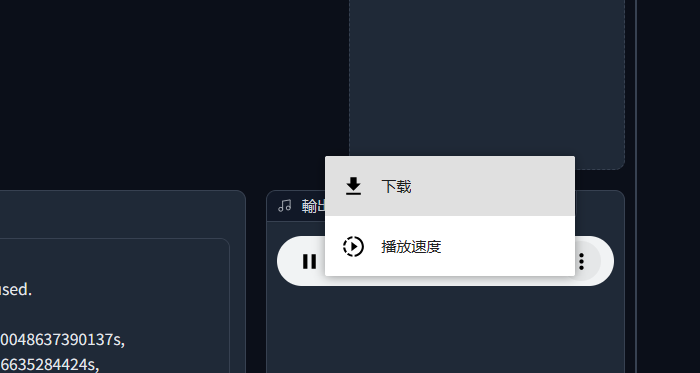
2,使用AU将伴奏和转换后的人声合并

首先新建多轨会话,将转换的人声和伴奏拉进AU
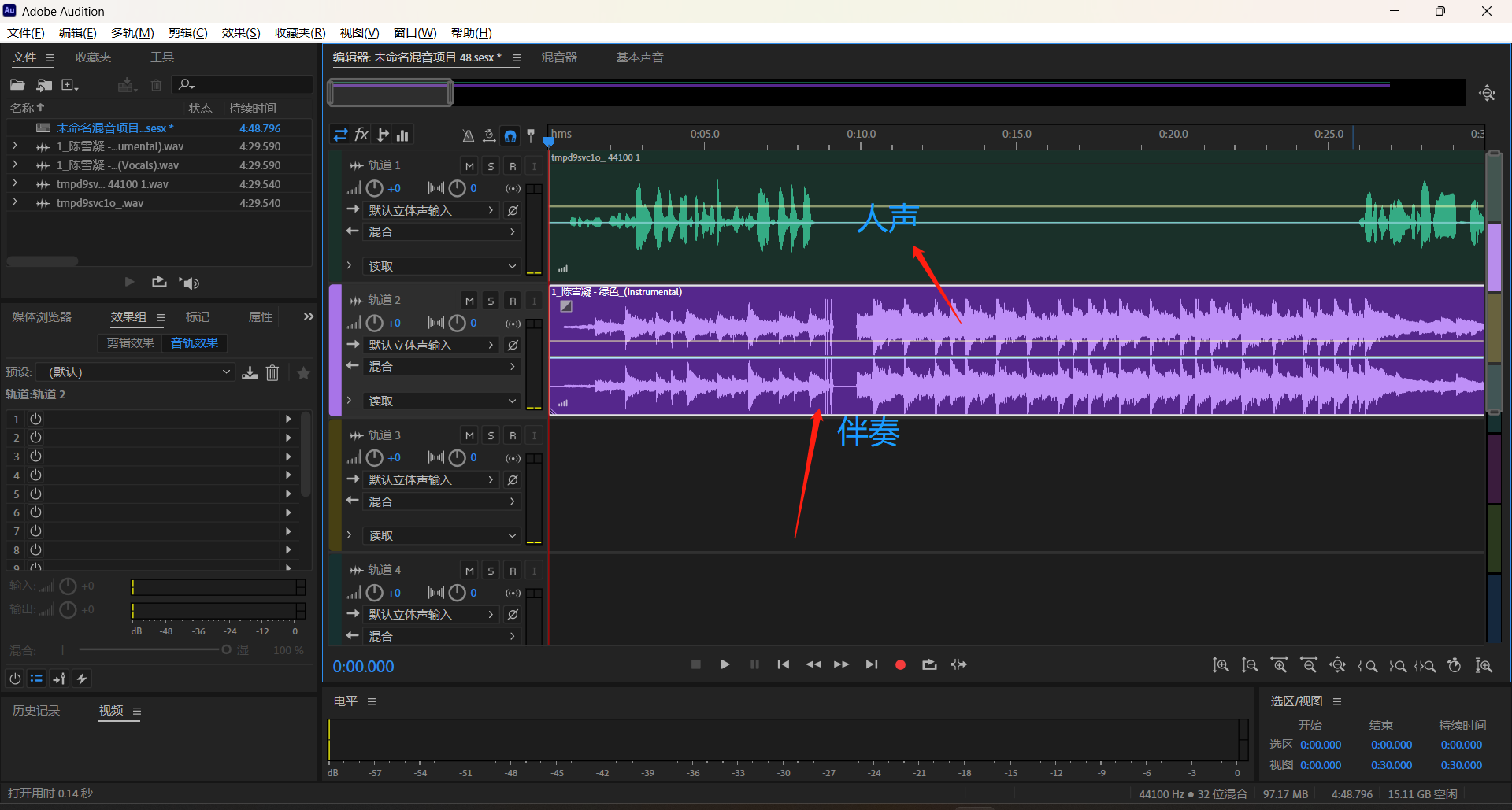
导出
