1. LeNet-5
1. LeNet-5网络诞生背景
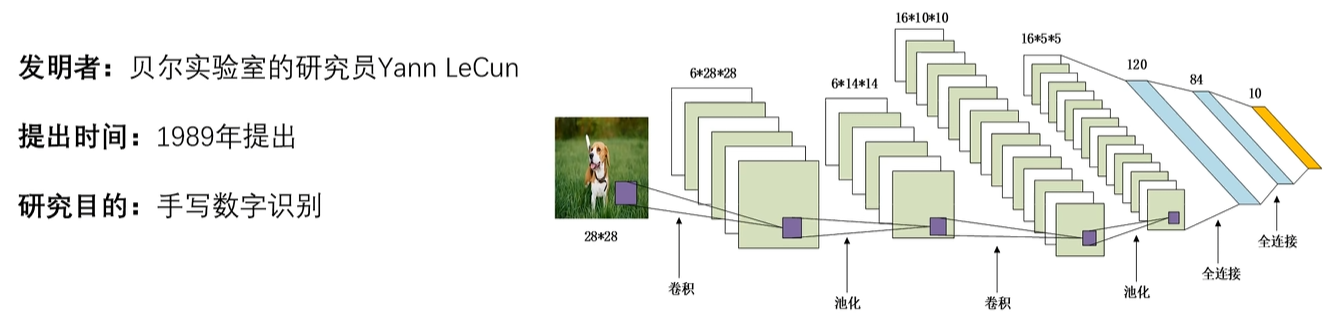
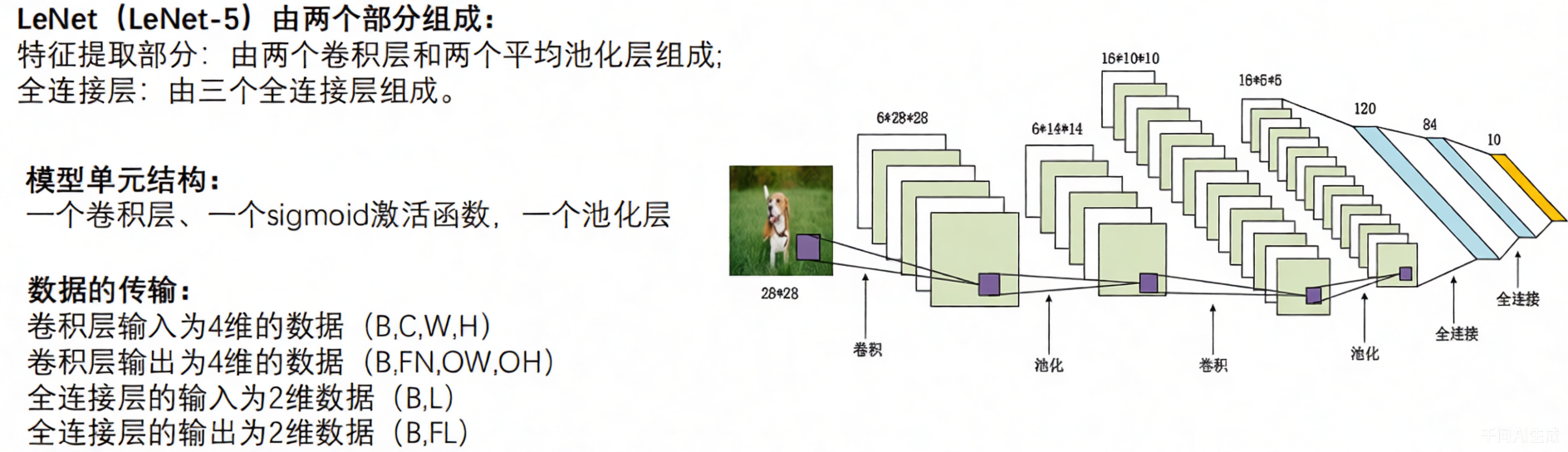
LeNet-5,5的意思就是,这个网络有5层隐藏层,如图,池化运算只是一种操作,卷积核里面才有参数(w,b),所以是两次卷积+三次全连接,一共是5层
在目标检测 里面,都喜欢叫特征提取主干,就是这个model模型专门做提取的。这里是一张狗的图片,我们最希望的是,就把这只狗的信息提取出来,比如草啊之类是无关信息不需要,然后放入卷积池化中(就简单叫 任务层),然后把提取到的信息,经过卷积运算之后,放入全连接中进行分类(到底是狗还是猫)。
因此目标检测就是 回归 + 分类 。首先我们要知道狗在哪里,这张图片狗的区域在哪里,在哪里就是一个坐标,左边就是一个连续值。
所以特征提取主干是由:两个卷积和两个平均池化层组成(因为在那个时代,1987,最大池化还没有发明出来)
整个过程是:
X------>卷积------>Sigmoid------>池化------>卷积------>Sigmoid------>池化------>全连接------>全连接------>全连接
在神经网络当中,我们输入数据肯定不是一张一张的输入,肯定是一批次**一批次(Batch Size)**的输入。比如说我们有1000张数据,每一批次都设置为100张,也就是总共有10批次。然后每批次100张一起输入到模型当中,去批量的更新w和b,这样就比较快。
所以一次100张,只用CPU去运算就很慢了,所以才需要GPU,所以学习深度学习一定要有GPU,特别是计算机视觉,一定要有个GPU,便宜点的也没问题。
因此我们输入的数据一般是4维的:
**B:**100张(一批次)
**C:**3(通道数,彩色图)
**W,H:**28 * 28(图片的宽高)
因此经过卷积核计算之后,输出的数据也是4维的:
**B:**100张(一批次)
**FN:**卷积核的个数
**FW:**输出的宽
**FH:**输出的高
那么全连接的输入:
**B:**100张(一批次)
**L:**FN * OW * OH(展平,保留卷积的空间信息,变成长条状的参数放入全连接中)
**FL:**如图,120,84,10是每一层全连接的神经元(这个具体个数是人为来定的)然后每一层全连接的输出就是下一层的输入
2. LeNet-5网络参数详解
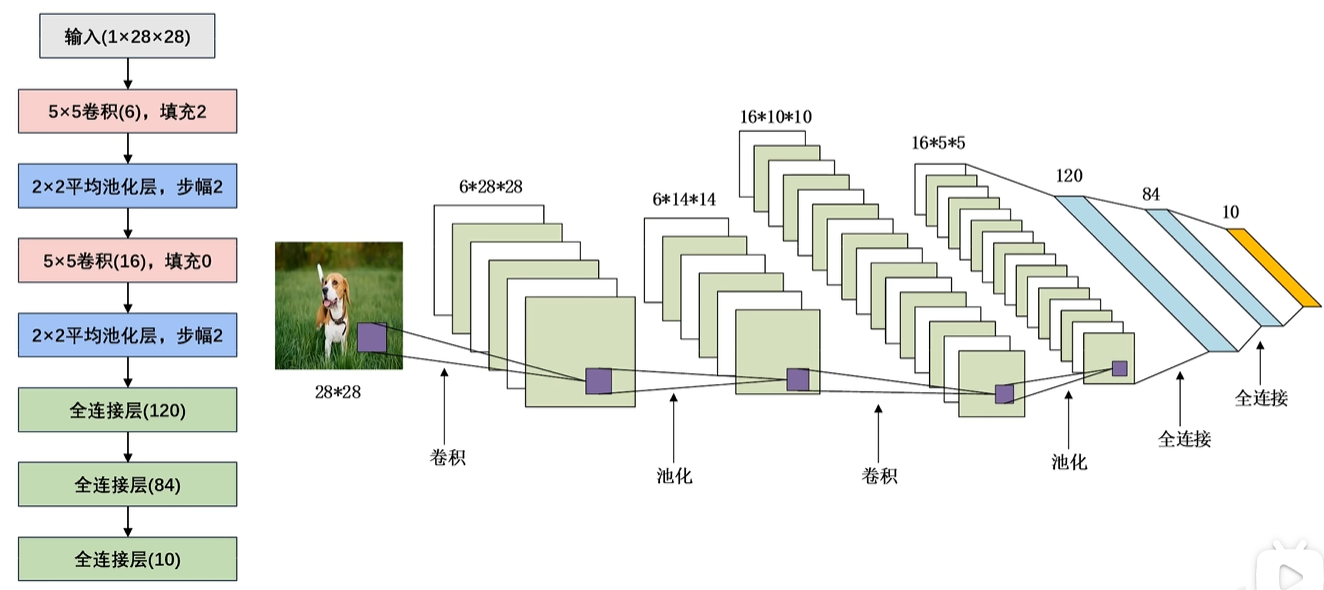
上面是LeNet具体的初始网络参数,整个运算都是使用这些参数

我们可以发现,在卷积神经网络中,卷积运算都是在增加通道数,池化运算都是在使特征图变小,后面的AlexNet和VGG,Goodlenet,RestNet都是这样的。
卷积是用来增多特征的,卷积每一个通道都用于独立描述一个特征
池化是用来修改特征表现的,如平滑或者突出
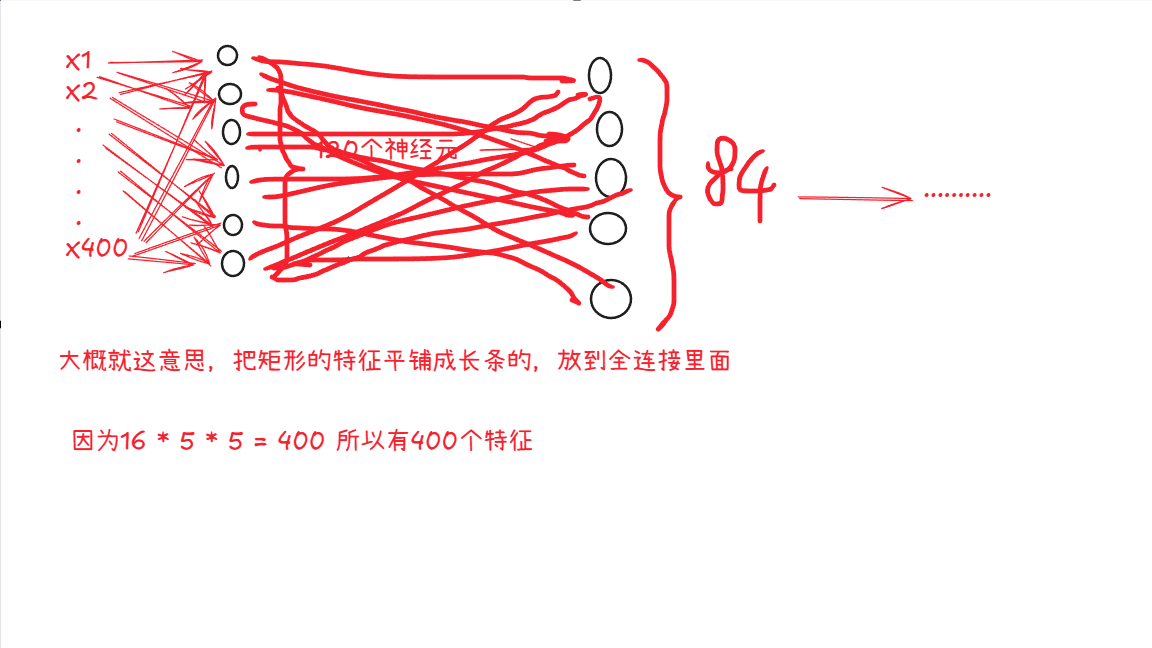
第五层结束之后,进行展平操作,得到400个数据和全连接相连
3. LeNet-5总结

只要是使用卷积运算的就是卷积神经网络,池化层有没有不重要,有卷积层就算卷积神经网络的一种。
卷积运算通常增加通道数,这样就能把特征提取出来,每一个特征都都用一个独立的通道数来表示。
在LeNet之前,我们都是用机器学习来做分类任务的,所以LeNet具有开创意义
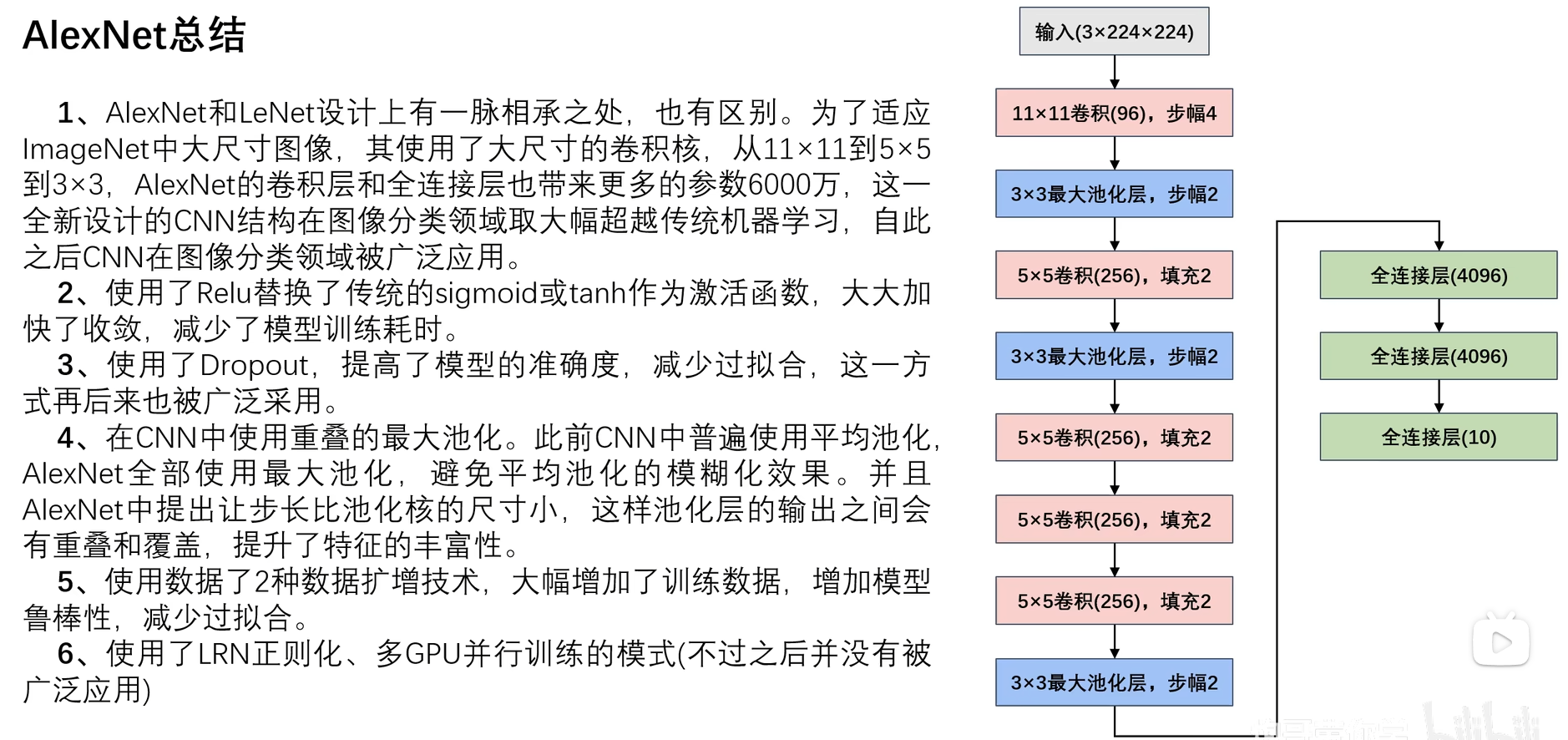
2. AlexNet
1. AlexNet诞生背景

在1987年LeNet出现之后,2012年AlexNet才出世,主要是因为,当时那个年代卷积操作太消耗资源了,计算很慢,那个时候计算机硬件跟不上。然后慢慢的被其他机器学习方法超越,因为机器学习有很强的理论支持(比如说为什么二次函数的最小值是这个点取到),而深度学习解释性比较差,基本都是先拿到一个好的结果,然后拿结果去解释为什么这么设计,只能等科学家们研究明白神经网络到底是怎么运行的,才能解释了。
可以理解为,数据本身所存在的维度无法被人类察觉,这样就不会被严谨性支配了。
2. AlexNet网络结构

其实最主要的差别就是,比起LeNet,AlexNet多了两次卷积层,然后激活函数使用的是ReLU。
3. AlexNet网络参数详解
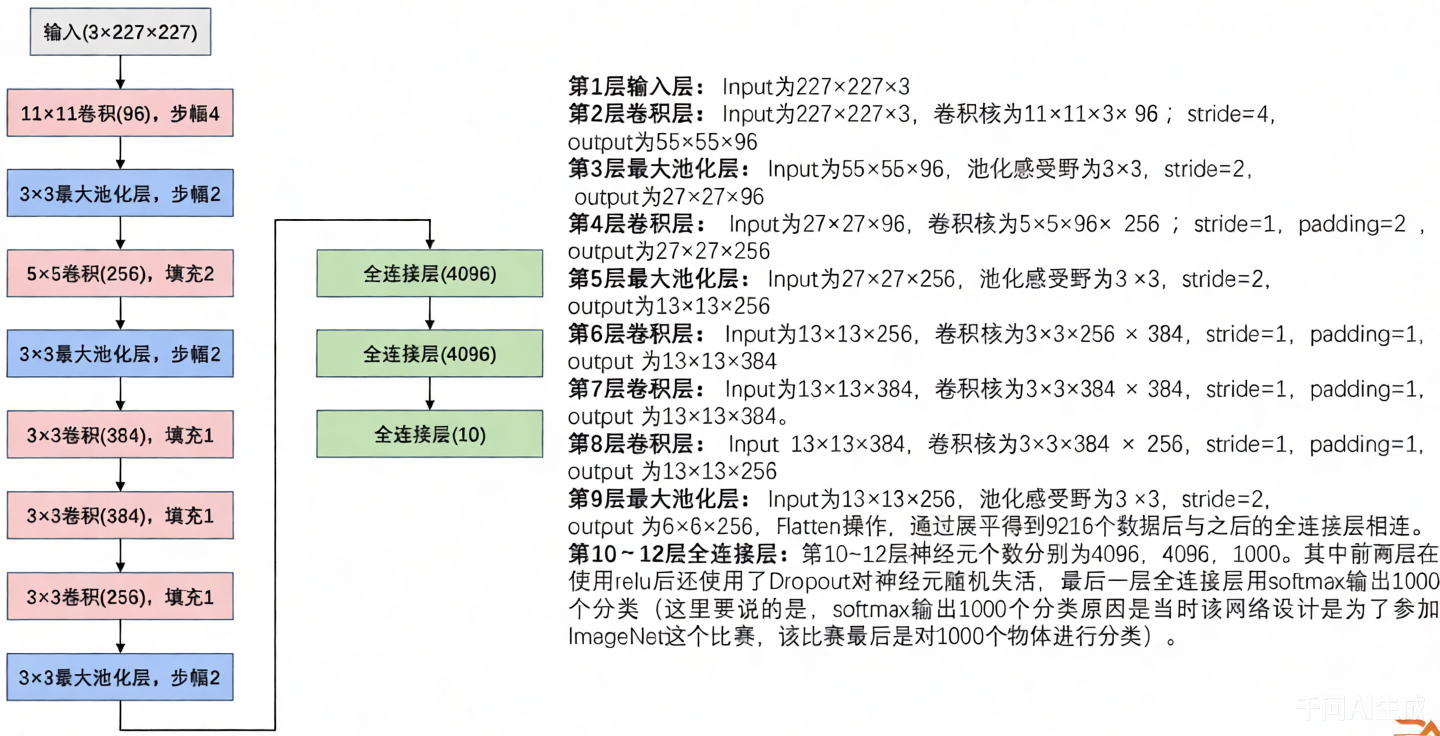
其实和LeNet过程差不多,值得一提的是,这里池化层用的是最大池化的算法,不过总之也不会改变通道数。
通过ReLU激活函数之后,还是用了Dropout操作,使一些神经元失效, 可以在一定程度上防止过拟合。
4. Dropout操作
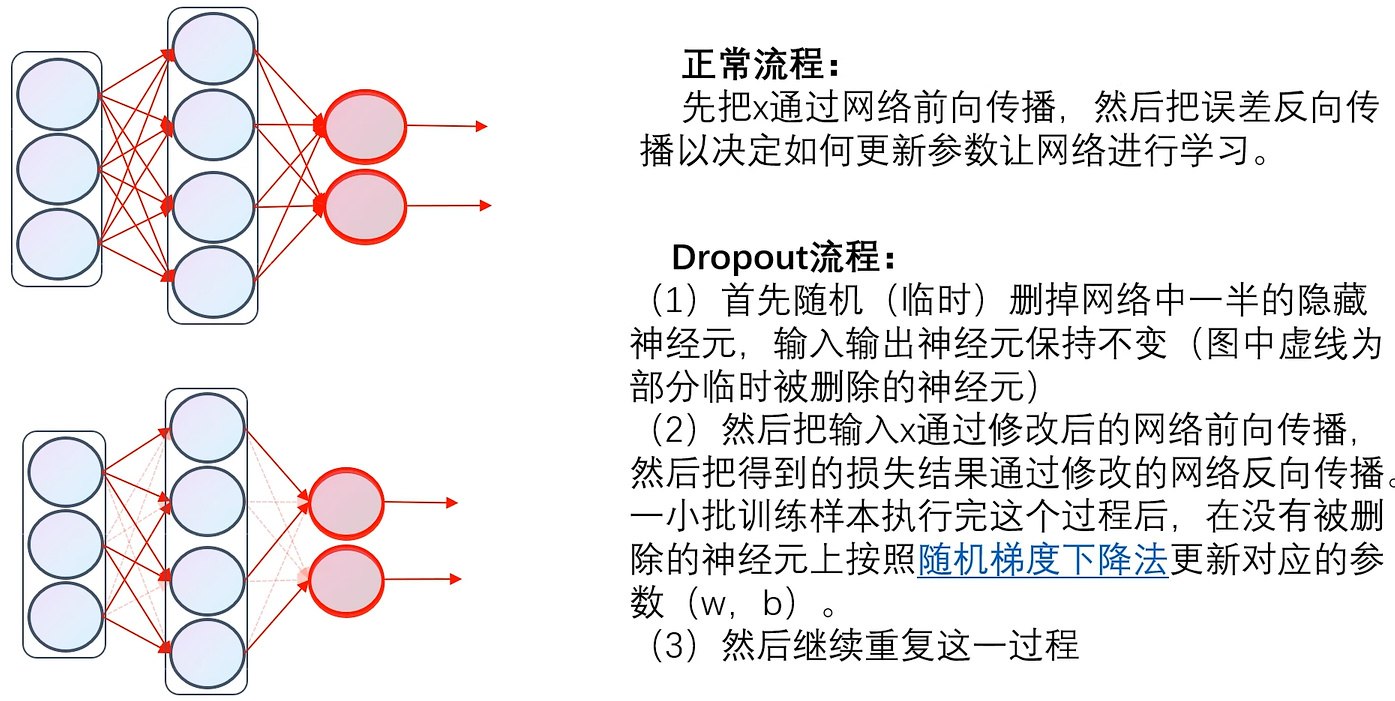
比如说把dropout设置为0.2,也就是每次反向传播的时候20%神经元随机失活,相当于就是,这一次这些神经元不更新w、b,不是死亡,下一轮更新还会继续更新的,这样就一定程度的避免了过拟合频繁的更新某个参数,并且可以加速训练。
可以理解为:让一部分神经元失活,来防止最后预测的时候只有一部分权重占主导地位,导致预测错误,而使用dropout就会使得每个权重都会承担一些特征,防止某些个别特征影响过大。
5. 图像增强
在我们项目当中,最困难的就是数据集,因为获得数据集需要成本,有数据才能训练,有数据才能测试,而且你数据不够,也没办法去验证不同网络之间的区别,所以有一些图像增强 的操作帮助我们扩增数据集
扩增数据集有两个好处:增加训练数据集,防止过拟合
1. 水平翻转
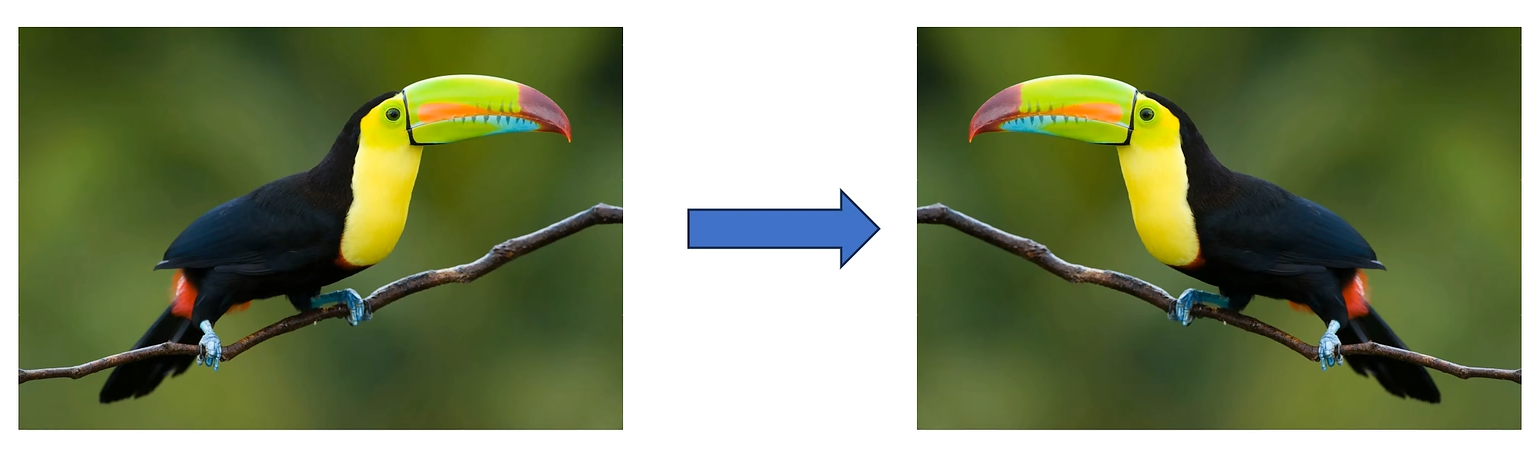
将图片水平翻转,使得我们的数据集直接增加了一倍,因为明显两张图片对于计算机来说是完全不一样的,但是输出的结果都应该是鸟
2. 随机裁剪
很明显,随机裁剪能产生更多数据集,比如说你裁剪就留下了一个鸟头,也应该识别出这是鸟
3. PCA

就是类似于对图片加了滤镜、饱和度调整等等操作,但是不管怎么样,还是应该很容易看出来这是鸟才对
抖动系数是人为设置的,通过设置抖动系数,也就是说,其实你想输出几张图像增强的图片都可以
4. 总结
其实就是:由于网络只对一种鸟进行一次识别是学不好的,所以不得不进行多层次的学习,得以学习到其本质,而图像扩增就是对这种数据进行多次利用的一种手段。通过不同的角度(翻转、裁剪、滤镜等改变)都可以识别出这是哪一张鸟。
但是这一系列操作只能增强网络对这一种鸟的识别准确率,不可能说,你把这种鸟研究透了,其他种类的鸟你也都认识了。因此本质上,想要增强网络,还是得依靠大量的初始数据集,图像增强操作只能让网络更好一点,属于是锦上添花的东西。
6. LRN正则化
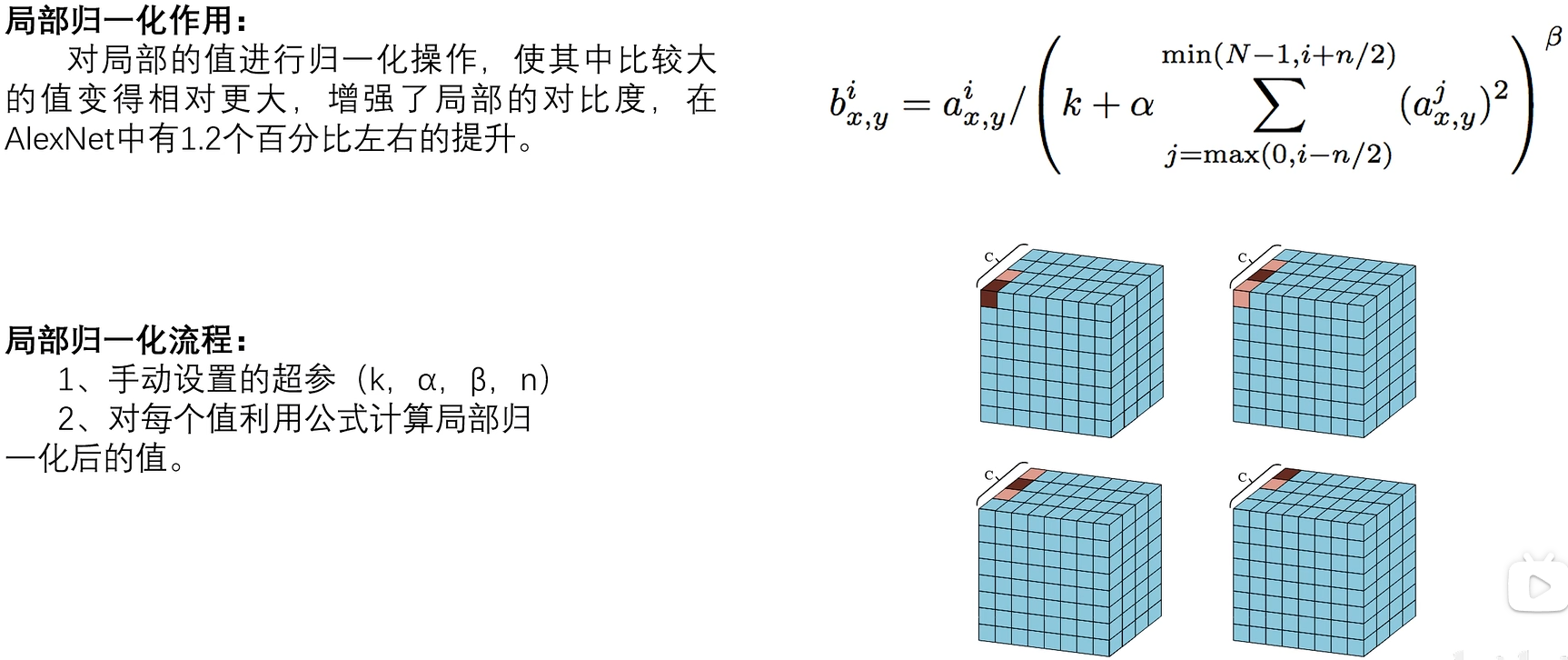
LRN正则化,全称为Local Response Normalization(局部响应归一化),是一种在深度学习,特别是在卷积神经网络(CNN)中常用的正则化技术

比如说:你有 10 个通道,在某个像素位置 (x,y) 上,每个通道都有一个激活值。LRN 会看这个位置在"附近几个通道"的激活强度平方和,如果这个和很大,说明很多通道都很活跃,那么当前通道的激活就会被"压低";反之,如果只有当前通道活跃,它就会被相对放大。
想象一个班级考试的场景
假设你们班有 30 个同学(这就像神经网络里的 30 个通道 )。
老师出了一道题,每个同学都写了一个答案,分数从 0 到 100 不等。
现在,老师想"调整"一下大家的分数,不是为了公平,而是为了突出真正答得好的人 ,同时压一压那些只是凑热闹、分数虚高的人。
于是老师定了一个规则:
"每个人的最终得分 = 原始分 ÷(他和他前后 2 个同学的分数平方和 的某个根)"
比如:
- 小明考了 90 分
- 他前面两个同学考了 85 和 88,后面两个考了 87 和 92
- 那么小明的新分数就会被"除以一个比较大的数",因为周围人都很强 → 说明这个题大家都答得好,小明不算特别突出
- 但如果小明考了 90,而周围同学都只考了 30、40,那他的新分数就会相对更高,因为他"鹤立鸡群"
这就是 LRN 的核心思想 :
不让一个人(或一个通道)轻易冒尖,除非他真的比"邻居"强很多。
回到神经网络
在 CNN 里:
- 每个"通道"就像一个同学,负责检测某种特征(比如边缘、颜色、纹理)
- 在图像的某个位置(比如左上角),每个通道都会输出一个"激活值"(可以理解为"这个位置有多像我负责的特征")
- 如果很多通道在这个位置都输出很高的值,说明这里很"热闹",但可能没啥特别意义
- LRN 就会把所有人的值都"压一压"
- 但如果只有一个通道特别高,其他都很低,那它就值得被保留甚至放大
目的:让网络更关注"独特"的特征,而不是一堆通道一起瞎喊。
这就是"局部响应归一化"------"局部"指附近的通道,"归一化"就是重新调整大小。
6. 总结