GBDT 是 Gradient Boosting Decision Tree 的缩写,中文名为梯度提升决策树 ,是一种经典的集成学习算法 ,核心逻辑是 串行生成多棵 CART 回归树 ,每一棵新树都用来拟合前一轮模型的预测残差,最终将所有树的预测结果累加,得到最终模型。
关键前提:GBDT 中所有的基学习器都是 CART 回归树 ,无论任务是分类还是回归。分类任务会通过损失函数的负梯度将标签转换为连续的 "伪残差",再用回归树拟合。
一、GBDT 核心思想
Boosting 算法的本质是 "知错就改":
- 先训练一棵基础树,用它做预测会产生误差(真实值 - 预测值 = 残差);
- 再训练一棵新树,专门拟合这个残差,让新树的预测值尽可能抵消前一轮的误差;
- 重复上述过程,生成多棵树;
- 最终预测结果 = 所有树的预测结果之和。
类比:你估算一个苹果的重量,第一次猜 200g,实际是 250g → 残差 50g;第二次专门猜这个残差 50g;最终结果 = 200g + 50g = 250g。
用 5 个房屋价格预测的样本 来完整演示第 m 棵树的「计算残差→训练回归树→更新模型」全过程,所有步骤都附带具体数值计算。
GBDT 回归任务生成过程(逐步计算演示)
前置准备
-
回归数据集 (特征:房屋面积 x,单位:㎡;标签:房价 y,单位:万元)
样本编号 1 2 3 4 5 面积 x 50 60 70 80 90 房价 y 15 18 22 25 30 -
超参数:树的数量 M=2(演示 2 轮迭代),学习率 η=0.1
-
初始模型 :回归任务的初始模型 f0(x) 是所有样本标签的均值
-

第 1 轮迭代:生成第 1 棵树 h1(x)
步骤 1:计算第 1 轮残差 r1i
残差的定义是 真实值 - 前一轮模型预测值,
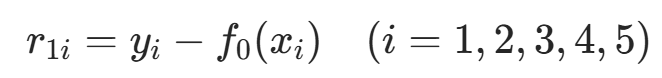
逐个样本计算残差:
| 样本编号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 真实房价 yi | 15 | 18 | 22 | 25 | 30 |
| 前一轮预测值 f0(xi) | 22 | 22 | 22 | 22 | 22 |
| 残差 r1i | 15−22=−7 | 18−22=−4 | 22−22=0 | 25−22=3 | 30−22=8 |
得到第 1 轮残差集合:r1=−7,−4,0,3,8
步骤 2:训练第 1 棵 CART 回归树 h1(x)
核心目标 :用「面积 x」作为特征,「残差 r1i」作为新标签,训练一棵 CART 回归树,划分准则是 平方误差最小化。
子步骤 2.1:生成候选阈值

子步骤 2.2:逐个阈值计算平方误差,选最优划分

我们逐个计算候选阈值的平方误差:
| 候选阈值 | 划分规则 | 左子集 S1(残差 / 均值) | 右子集 S2(残差 / 均值) | 总平方误差 L |
|---|---|---|---|---|
| 55 | x≤55 / x>55 | 样本 1(-7)→ rˉ1=−7 | 样本 2-5(-4,0,3,8)→ rˉ2=1.75 | (−7+7)2+(−4−1.75)2+(0−1.75)2+(3−1.75)2+(8−1.75)2=0+74.75=74.75 |
| 65 | x≤65 / x>65 | 样本 1-2(-7,-4)→ rˉ1=−5.5 | 样本 3-5(0,3,8)→ rˉ2=3.67 | (−7+5.5)2+(−4+5.5)2+(0−3.67)2+(3−3.67)2+(8−3.67)2=4.5+33.34=37.84 |
| 75 | x≤75 / x>75 | 样本 1-3(-7,-4,0)→ rˉ1=−3.67 | 样本 4-5(3,8)→ rˉ2=5.5 | (−7+3.67)2+(−4+3.67)2+(0+3.67)2+(3−5.5)2+(8−5.5)2=24.67+12.5=37.17 |
| 85 | x≤85 / x>85 | 样本 1-4(-7,-4,0,3)→ rˉ1=−2 | 样本 5(8)→ rˉ2=8 | (−7+2)2+(−4+2)2+(0+2)2+(3+2)2+(8−8)2=58+0=58 |
最优划分选择:阈值 = 75 时总平方误差最小(37.17),因此第 1 棵树的划分规则为:
- 若 x≤75 → 叶子节点 1,预测值 =rˉ1=−3.67
- 若 x>75 → 叶子节点 2,预测值 =rˉ2=5.5
得到第 1 棵树对 5 个样本的预测值 h1(xi):
| 样本编号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 面积 x | 50≤75 | 60≤75 | 70≤75 | 80>75 | 90>75 |
| h1(xi) | -3.67 | -3.67 | -3.67 | 5.5 | 5.5 |
步骤 3:更新模型,得到 f1(x)

逐个样本计算更新后的预测值:
| 样本编号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| f0(xi) | 22 | 22 | 22 | 22 | 22 |
| 0.1⋅h1(xi) | 0.1×(−3.67)=−0.37 | −0.37 | −0.37 | 0.1×5.5=0.55 | 0.55 |
| f1(xi) | 22−0.37=21.63 | 21.63 | 21.63 | 22+0.55=22.55 | 22.55 |
此时模型的预测值已经比初始模型更接近真实房价。
第 2 轮迭代:生成第 2 棵树 h2(x)
步骤 1:计算第 2 轮残差 r2i
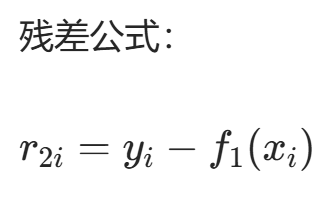
逐个样本计算残差:
| 样本编号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 真实房价 yi | 15 | 18 | 22 | 25 | 30 |
| 前一轮预测值 f1(xi) | 21.63 | 21.63 | 21.63 | 22.55 | 22.55 |
| 残差 r2i | 15−21.63=−6.63 | 18−21.63=−3.63 | 22−21.63=0.37 | 25−22.55=2.45 | 30−22.55=7.45 |
残差集合:r2=−6.63,−3.63,0.37,2.45,7.45
步骤 2:训练第 2 棵 CART 回归树 h2(x)
同样以「面积 x」为特征、「残差 r2i」为新标签,重复平方误差最小化的划分过程,最终得到第 2 棵树的划分规则和预测值 h2(xi)(计算过程同第 1 棵树,此处省略阈值筛选步骤)。
假设第 2 棵树的最优划分阈值还是 75,得到预测值:
| 样本编号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| h2(xi) | -3.4 | -3.4 | -3.4 | 4.95 | 4.95 |
步骤 3:更新模型,得到最终模型 f2(x)
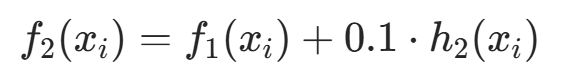
计算最终预测值:
| 样本编号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| f1(xi) | 21.63 | 21.63 | 21.63 | 22.55 | 22.55 |
| 0.1⋅h2(xi) | −0.34 | −0.34 | −0.34 | 0.50 | 0.50 |
| f2(xi) | 21.29 | 21.29 | 21.29 | 23.05 | 23.05 |
核心结论
- 残差的作用 :每一轮的残差都是「模型当前预测的误差」,训练新树的目标就是尽可能拟合这个误差。
- 模型更新逻辑:每一轮都用学习率控制新树的贡献,逐步修正预测值,让模型越来越准。
- 迭代终止条件:当树的数量达到预设值 M,或残差的均值小于阈值时,停止迭代。