在数据库运维场景中,高可用性是保障业务连续性的核心诉求。MySQL InnoDB Cluster作为官方推荐的高可用解决方案,通过集成MySQL Shell、MySQL Router和Group Replication,实现了集群的自动故障检测与主从切换能力。本文基于实际测试环境,详细记录InnoDB Cluster高可用测试的完整流程,验证集群在节点故障、机器宕机等场景下的自愈能力与数据一致性保障效果。
一、测试环境与前置准备
1. 集群拓扑
本次测试基于3节点InnoDB Cluster,节点信息如下,所有节点均部署MySQL 8.0版本,已通过Group Replication完成集群初始化:
| 节点名称 | IP地址 | 端口 | 初始角色 |
|---|---|---|---|
| maria-01 | 192.168.184.151 | 6446 | Primary |
| maria-02 | 192.168.184.152 | 6446 | Secondary |
| maria-03 | 192.168.184.153 | 6446 | Secondary |
2. 测试工具与账号
- 管理工具:MySQL Shell(用于集群状态查询与管理)、Go语言(编写数据写入脚本)
- 测试账号:
mgr_user(具备集群管理与数据读写权限,密码:BgIka^123) - 核心目标:验证集群在Primary节点故障 、Primary节点所在机器宕机场景下的自动切换能力,以及故障节点恢复后的集群重整合效果。
二、测试步骤1:搭建数据写入与监控环境
为模拟真实业务压力,需先构建持续数据写入场景,通过观察写入中断与恢复情况,直观判断集群高可用能力。
1. 登录Primary节点并创建测试数据
首先登录初始Primary节点(192.168.184.151),创建测试库、测试表,为后续数据写入做准备:
bash
# 登录MySQL(通过Group Replication端口6446)
mysql -umgr_user -p'BgIka^123' -P6446 -h192.168.184.151
# 创建测试库maria
create database maria;
use maria;
# 创建测试表user_info(含自增ID、姓名、年龄、创建时间)
CREATE TABLE user_info (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
age INT,
created_at datetime NOT NULL DEFAULT CURRENT_TIMESTAMP
);2. 编写Go语言数据写入脚本
通过Go语言编写定时写入脚本,实现每秒向user_info表插入1条数据,脚本会打印写入时间与错误信息,便于观察故障时的写入状态:
go
package main
import (
"database/sql"
"fmt"
"time"
_ "github.com/go-sql-driver/mysql" // MySQL驱动
)
func main() {
// 数据库连接配置(指向初始Primary节点)
dbUser := "mgr_user"
dbPass := "BgIka^123"
dbIP := "192.168.184.151"
dbPort := "6446"
dbName := "maria"
// 构建DSN(数据源名称)
dsn := fmt.Sprintf("%s:%s@tcp(%s:%s)/%s", dbUser, dbPass, dbIP, dbPort, dbName)
fmt.Printf("连接信息:%s\n", dsn)
// 建立数据库连接(defer确保程序退出时关闭连接)
db, err := sql.Open("mysql", dsn)
if err != nil {
panic("数据库连接失败:" + err.Error())
}
defer db.Close()
// 定时任务:每秒插入1条数据
ticker := time.NewTicker(1 * time.Second)
defer ticker.Stop()
for range ticker.C {
// 插入数据(姓名固定为John Doe,年龄固定为30)
insertQuery := "INSERT INTO user_info (name, age) VALUES (?, ?)"
_, err := db.Exec(insertQuery, "John Doe", 30)
if err != nil {
fmt.Printf("[%s] 写入失败:%s\n", time.Now().Format("2006-01-02 15:04:05"), err.Error())
continue
}
fmt.Printf("[%s] 数据写入成功\n", time.Now().Format("2006-01-02 15:04:05"))
}
}3. 运行脚本并验证数据写入
将脚本在测试机上编译运行,同时在Primary节点查询数据,确认写入正常:
bash
# 运行Go脚本(需提前安装Go环境与MySQL驱动)
go run insert_data.go
# 在Primary节点查询数据
mysql -umgr_user -p'BgIka^123' -P6446 -h192.168.184.151 -e "use maria; select count(*) from user_info;"正常情况下,脚本会每秒打印"数据写入成功",查询结果显示user_info表数据量持续增长。
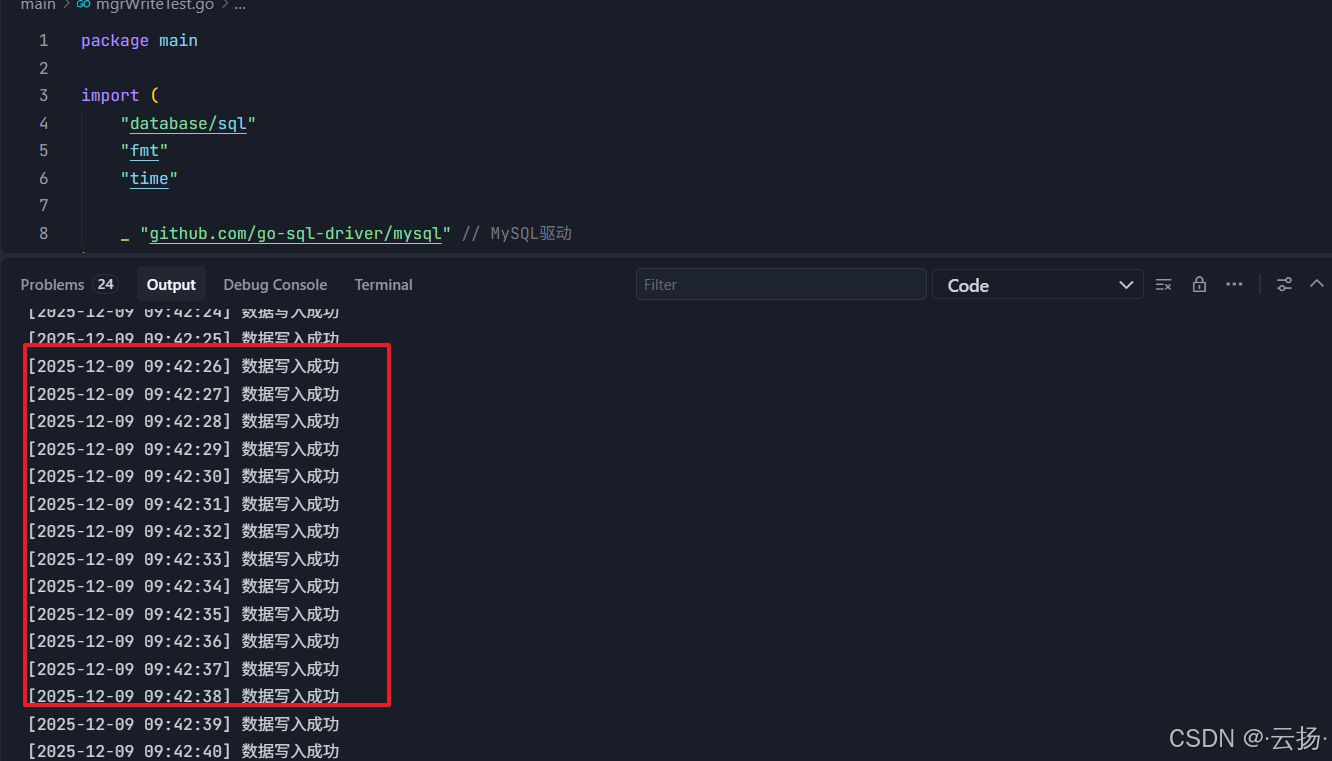
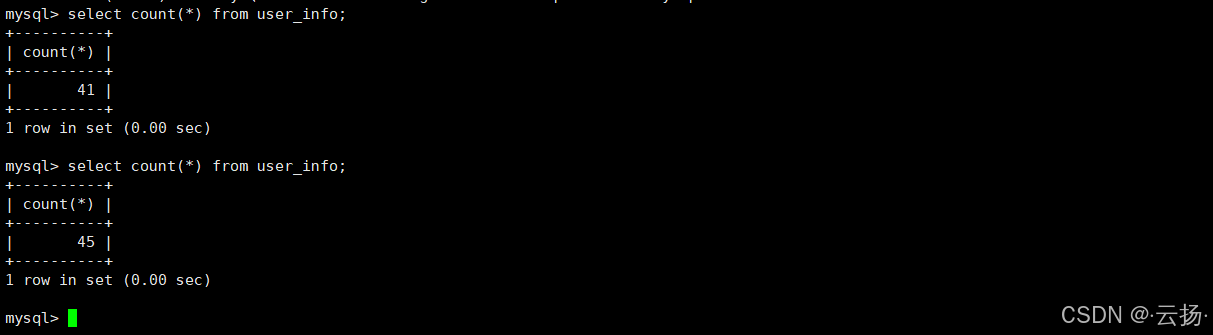
三、测试步骤2:Primary节点故障场景验证
1. 查看初始集群状态
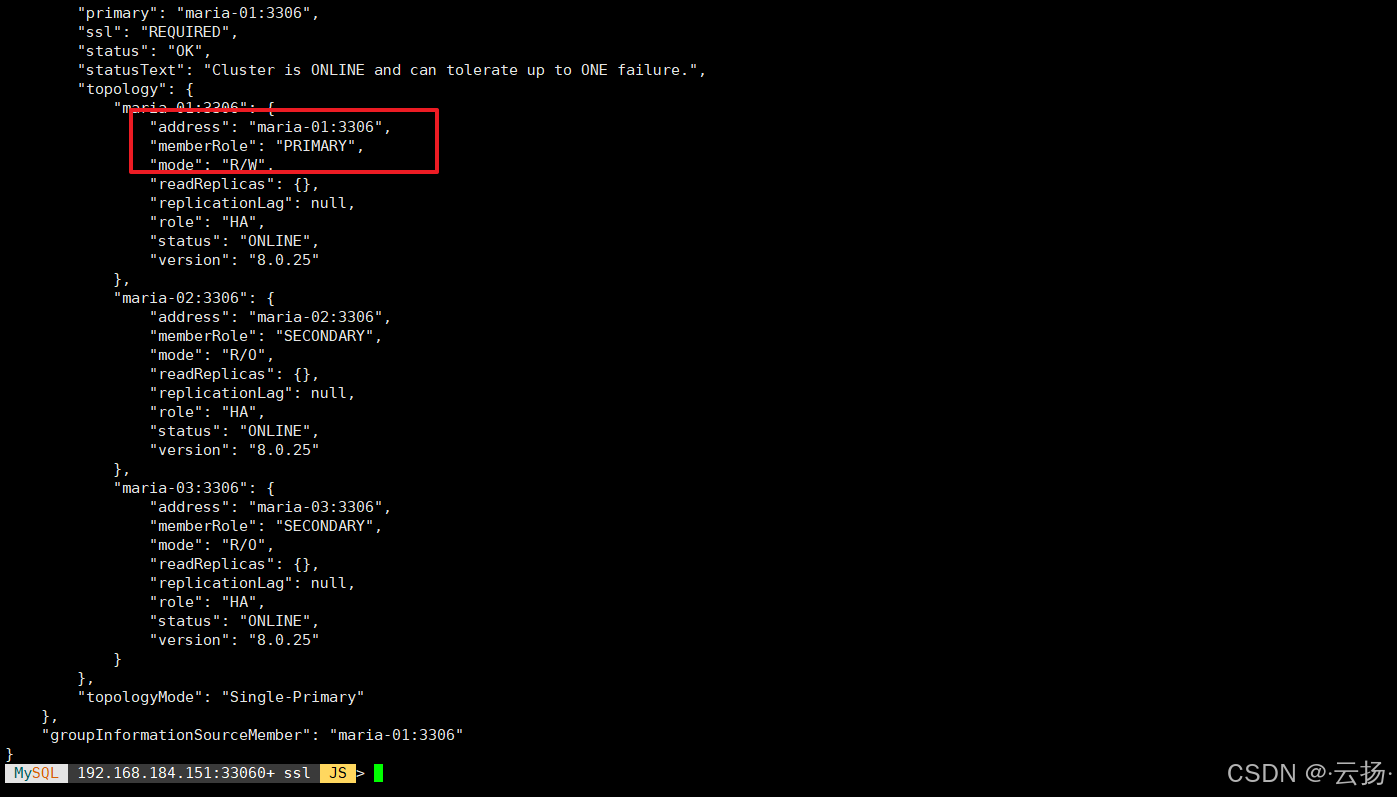
通过MySQL Shell连接集群,确认初始Primary节点为maria-01(192.168.184.151):
bash
# 登录MySQL Shell
mysqlsh -umgr_user -p'BgIka^123' -h192.168.184.151
# 获取集群对象并查询状态
var cluster = dba.getCluster('Cluster01')
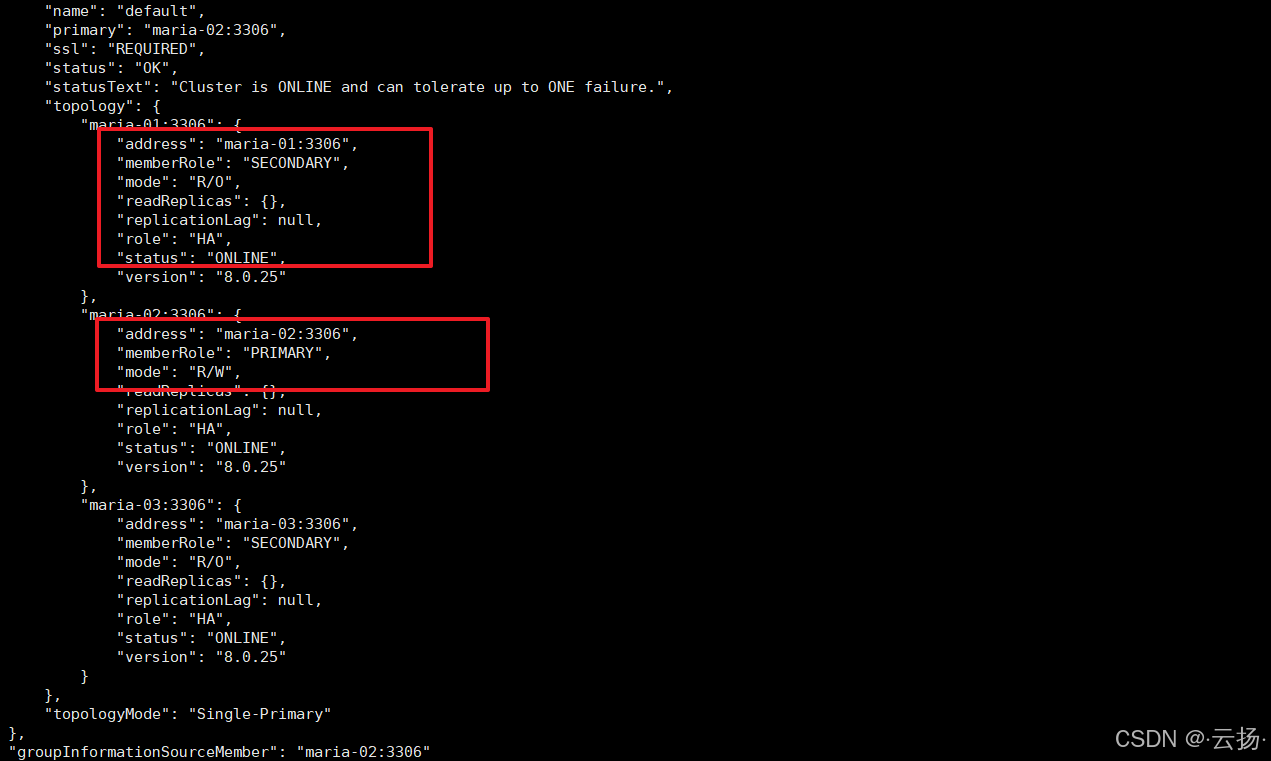
cluster.status();输出结果中,maria-01的role字段为PRIMARY,maria-02与maria-03为SECONDARY,集群状态为OK。
2. 停止Primary节点MySQL服务
在192.168.184.151节点上停止MySQL服务,模拟Primary节点故障:
bash
# 停止MySQL服务(基于初始化脚本的启停命令)
/etc/init.d/mysql.server stop3. 观察数据写入与集群切换
-
数据写入状态 :观察Go脚本输出,会短暂打印"写入失败"(约1-2秒),随后自动恢复正常写入------这是因为InnoDB Cluster检测到Primary故障后,会自动从Secondary节点中选举新的Primary。

-
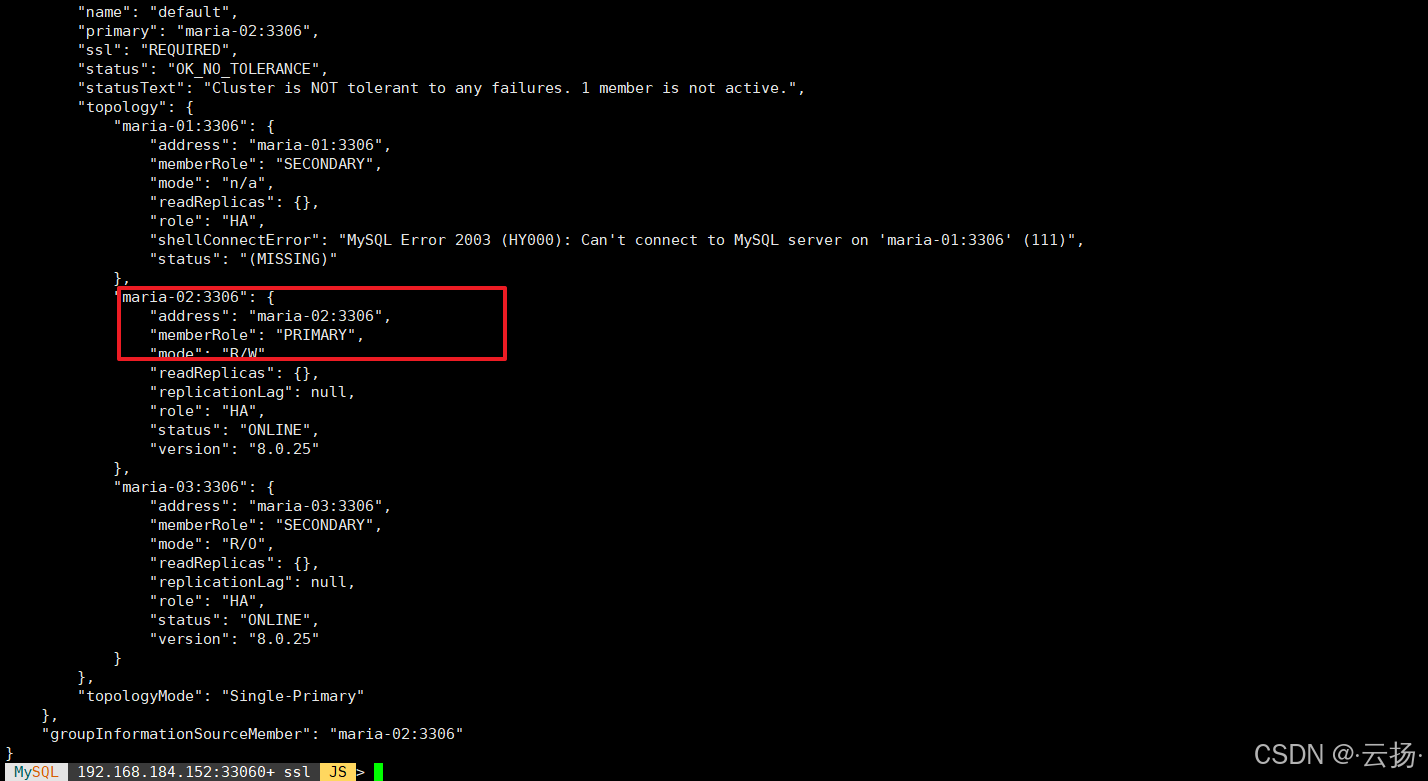
验证新Primary节点:重新通过MySQL Shell连接集群(需连接其他正常节点,如192.168.184.152),查询集群状态:
bash# 连接到maria-02节点 mysqlsh -umgr_user -p'BgIka^123' -h192.168.184.152 # 查看集群状态 var cluster = dba.getCluster('Cluster01') cluster.status();输出显示:
maria-02已切换为新的Primary节点,maria-01状态变为MISSING。
4. 恢复故障节点并验证重整合
在192.168.184.151节点上重启MySQL服务,观察集群是否自动将其重整合为Secondary节点:
bash
# 重启MySQL服务
/etc/init.d/mysql.server start
# 再次查询集群状态
cluster.status();结果显示:maria-01已恢复为Secondary节点,集群状态回到OK,数据写入持续正常(无丢失)。
四、测试步骤3:Primary节点所在机器宕机场景验证
1. 确认当前Primary节点
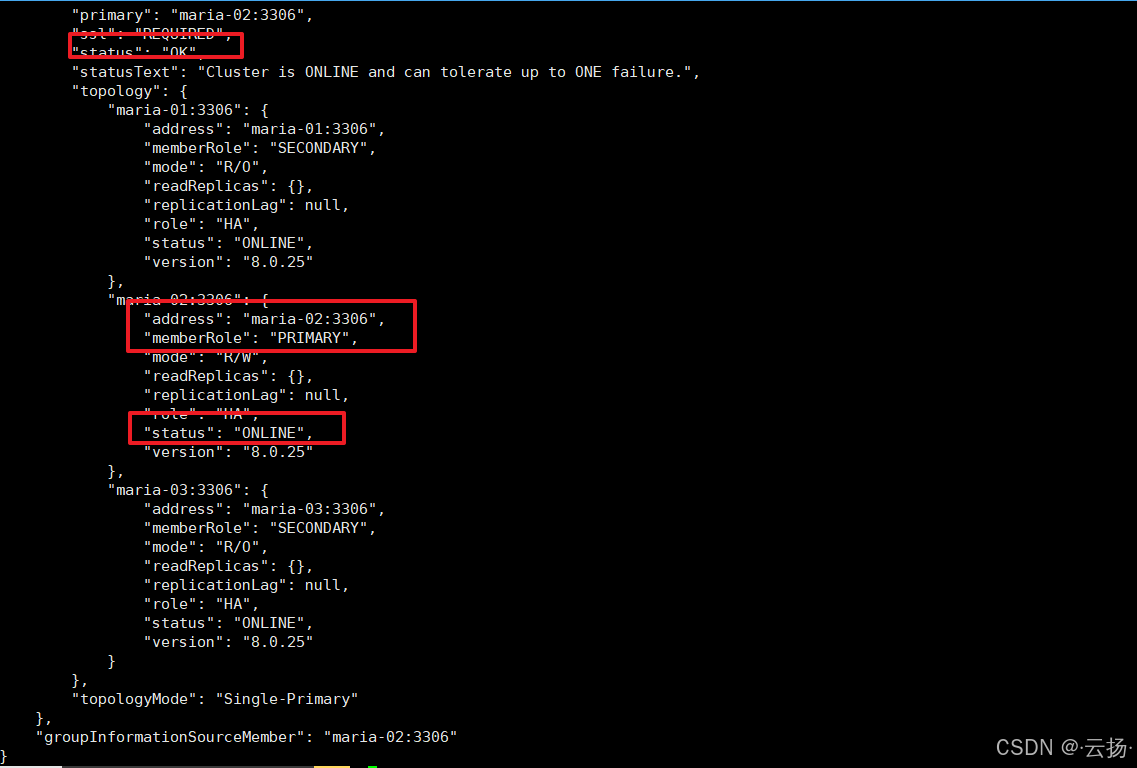
延续上一步测试结果,当前Primary节点为maria-02(192.168.184.152),先通过cluster.status()确认节点状态正常。
2. 关闭Primary节点所在机器
在192.168.184.152节点上执行关机命令,模拟更极端的"机器宕机"故障:
bash
# 关闭机器(需谨慎操作,仅测试环境执行)
shutdown -h now3. 观察故障切换与数据一致性
-
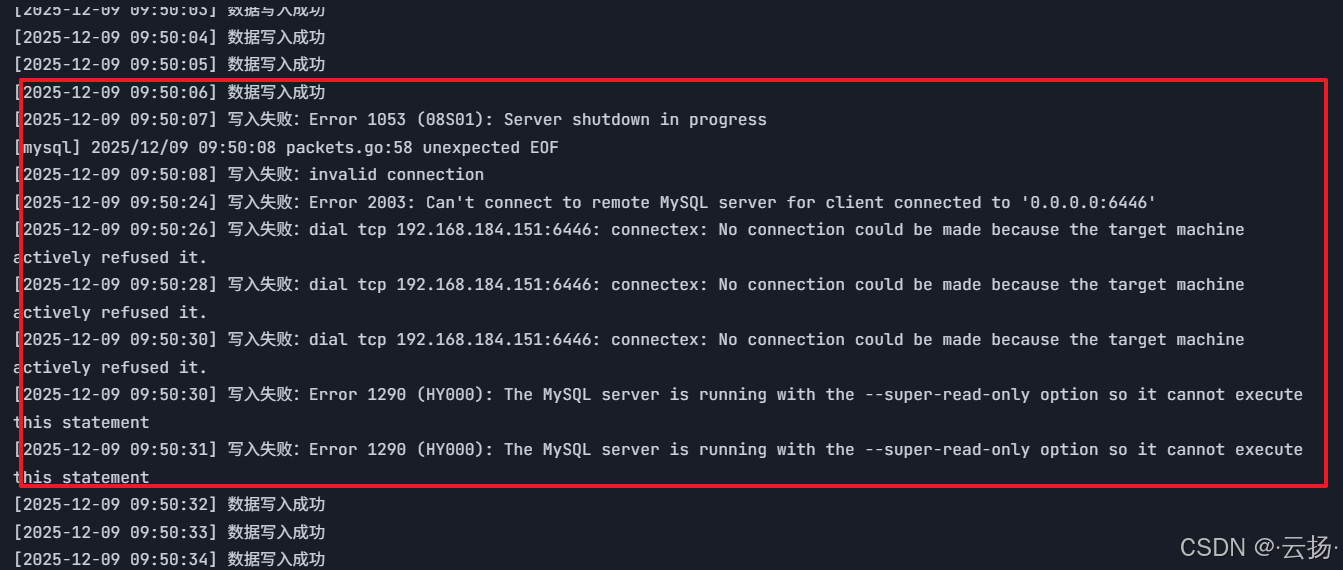
数据写入状态 :Go脚本会短暂中断(约2-3秒),随后恢复正常写入------证明集群在"机器宕机"场景下仍能完成故障检测与切换。
-
验证新Primary节点 :连接到
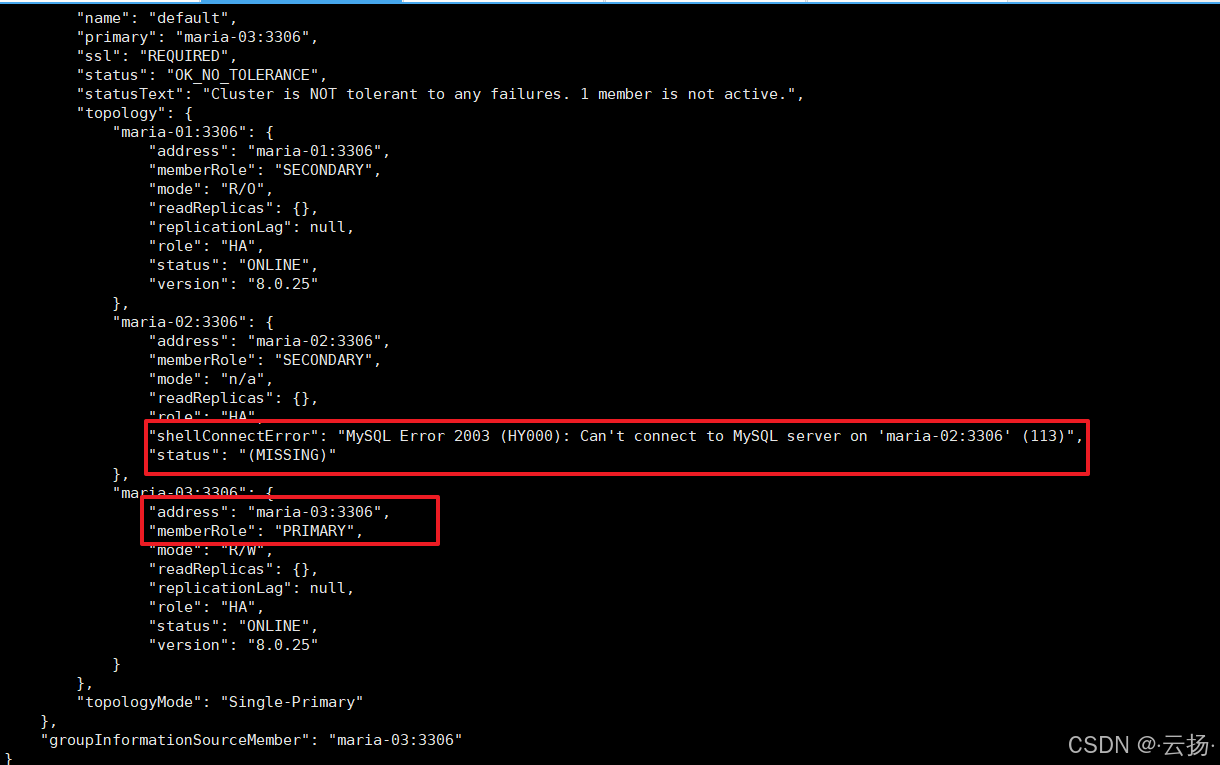
maria-01(192.168.184.151),查询集群状态:bashmysqlsh -umgr_user -p'BgIka^123' -h192.168.184.151 var cluster = dba.getCluster('Cluster01') cluster.status();输出显示:
maria-03已成为新的Primary节点,maria-02状态为MISSING。
4. 恢复宕机机器并验证集群状态
启动192.168.184.152节点,待机器正常启动后,查看集群是否自动将其重整合:
bash
# 机器启动后,查询集群状态
cluster.status();结果显示:maria-02已恢复为Secondary节点,集群重新回到3节点正常状态,user_info表数据无丢失(通过select count(*)对比故障前后数据量可验证)。
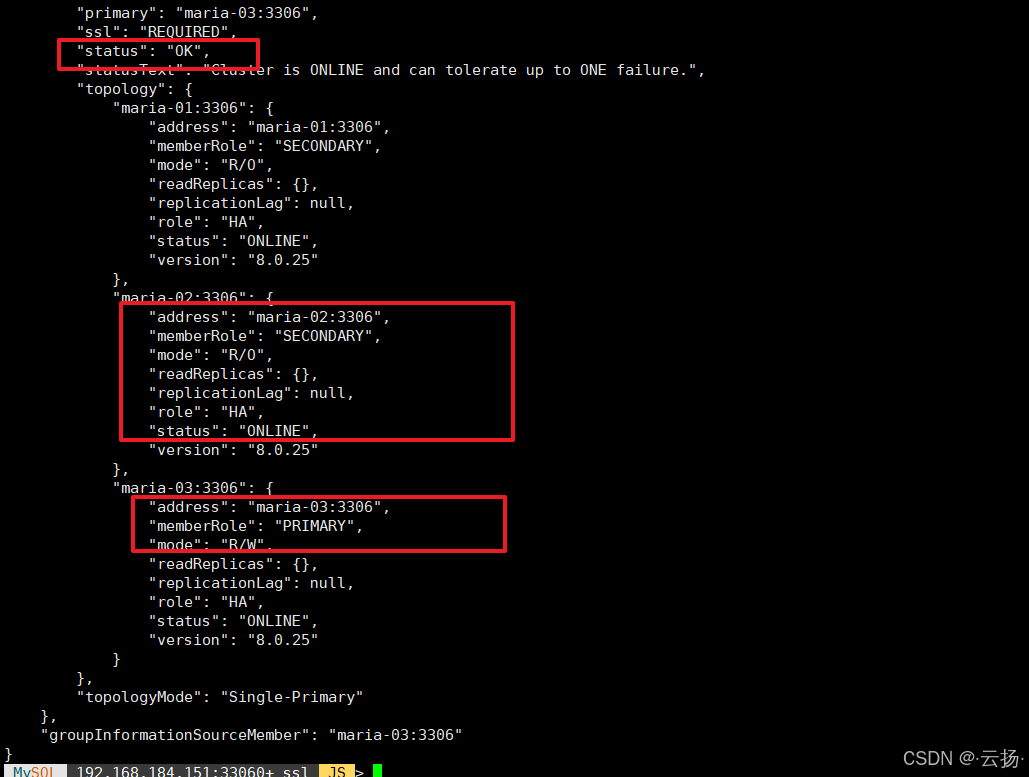

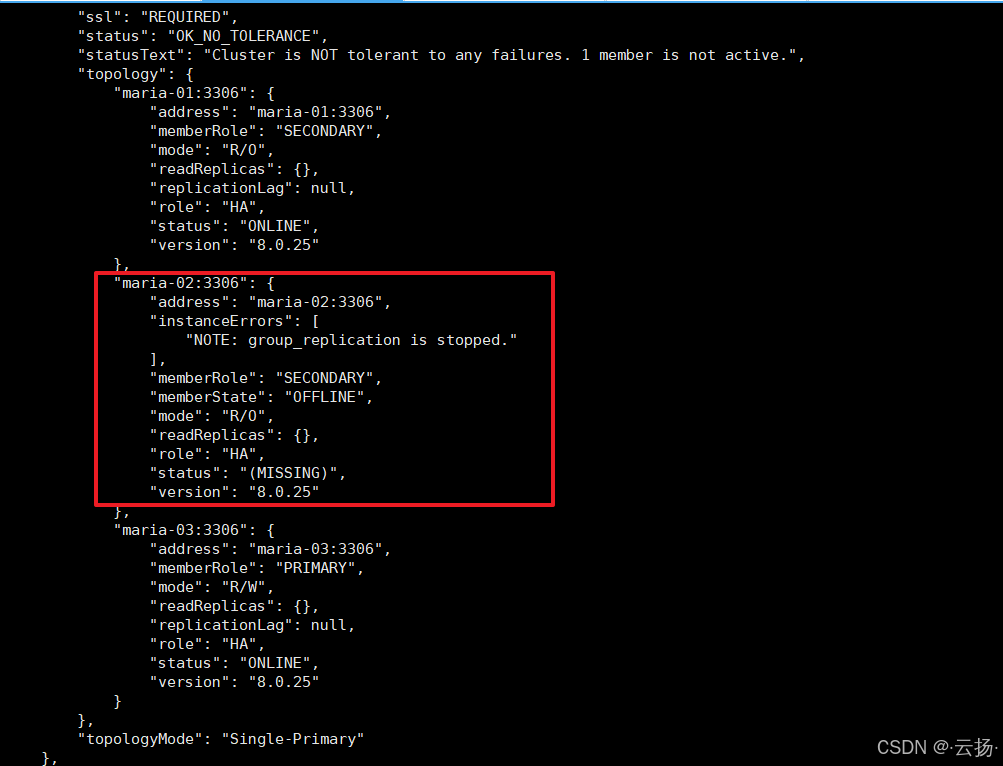
注:若maria-02重启后,查看集群状态出现如下情况,可以登录maria-02的MySQL,然后执行start group_replication;命令开启组复制,从而使得maria-02在集群内正常运行。
五、测试结论与核心发现
- 高可用能力验证通过 :InnoDB Cluster在"Primary节点服务停止"和"Primary节点机器宕机"两种场景下,均能在3秒内完成故障检测与自动切换,数据写入仅短暂中断,无数据丢失,满足业务连续性要求。
- 故障节点自动重整合:故障节点(或机器)恢复后,集群会自动将其重整合为Secondary节点,无需人工干预,降低运维成本。
- 角色选举逻辑稳定:集群始终从健康的Secondary节点中选举新Primary,选举结果符合Group Replication的"多数派存活"原则(3节点集群需至少2个节点健康)。
六、注意事项与优化建议
- 生产环境需配置MySQL Router:本次测试直接连接节点IP,生产环境建议部署MySQL Router作为入口,实现"读写分离"与"自动路由到新Primary",避免客户端直接感知节点变化。
- 监控集群状态 :需通过Prometheus+Grafana等工具监控集群状态(如
cluster.status()、节点存活状态、复制延迟),及时发现潜在故障。 - 测试频率:建议每季度执行一次高可用测试,验证集群配置未因版本更新、参数调整而失效。
通过本次测试,充分验证了InnoDB Cluster在关键故障场景下的高可用能力,为生产环境部署提供了实践依据。