人工智能学习-AI-MIT公开课11. 学习:识别树、无序
- 1-前言
- 2-课程链接
- 3-具体内容解释说明
-
- 一、这节课在整个课程里的位置
- 二、前半部分:识别树(=决策树)
-
- [1️⃣ 什么是识别树?](#1️⃣ 什么是识别树?)
- [2️⃣ 决策树是怎么"学"的?](#2️⃣ 决策树是怎么“学”的?)
- [3️⃣ 决策树的优缺点(必考)](#3️⃣ 决策树的优缺点(必考))
- 三、后半部分:无序(=无监督学习)
-
- [1️⃣ 什么是"无序学习"?](#1️⃣ 什么是“无序学习”?)
- [2️⃣ 典型无监督学习任务](#2️⃣ 典型无监督学习任务)
-
- [🔹 聚类(Clustering)](#🔹 聚类(Clustering))
- [🔹 降维(Dimensionality Reduction)](#🔹 降维(Dimensionality Reduction))
- [3️⃣ 无监督学习的特点(考试重点)](#3️⃣ 无监督学习的特点(考试重点))
- 四、这节课的"入试视角总结"
- 4-课后练习(日语版本)
- 5-课后答案解析(日语版本)
-
- 問題1(識別木の性質)
- 問題2(分割基準)
- 問題3(無教師学習)
- [問題4(教師あり vs 無教師あり)](#問題4(教師あり vs 無教師あり))
- [📊 总结成绩(按真实入试标准)](#📊 总结成绩(按真实入试标准))
- [🎯 出题人对你的评价(实话)](#🎯 出题人对你的评价(实话))
- [🔑 给你一个"不会再错"的一句话规则](#🔑 给你一个“不会再错”的一句话规则)
- 6-总结
1-前言
为了应对大学院考试,我们来学习相关人工智能相关知识,并且是基于相关课程。使用课程为MIT的公开课。
通过学习,也算是做笔记,让自己更理解些。
2-课程链接
是在B站看的视频,链接如下:
https://www.bilibili.com/video/BV1dM411U7qK?spm_id_from=333.788.videopod.episodes&vd_source=631b10b31b63df323bac39281ed4aff3&p=11
3-具体内容解释说明
一、这节课在整个课程里的位置
从目录可以看出顺序是:
- 10:学习介绍、最近邻(k-NN)
- 11:识别树、无序
- 12:神经网络、反向传播
- 13:遗传算法
👉 说明这是传统机器学习 → 深度学习 之间的过渡章节 。
不讲工程实现,重在"思想与原理"。
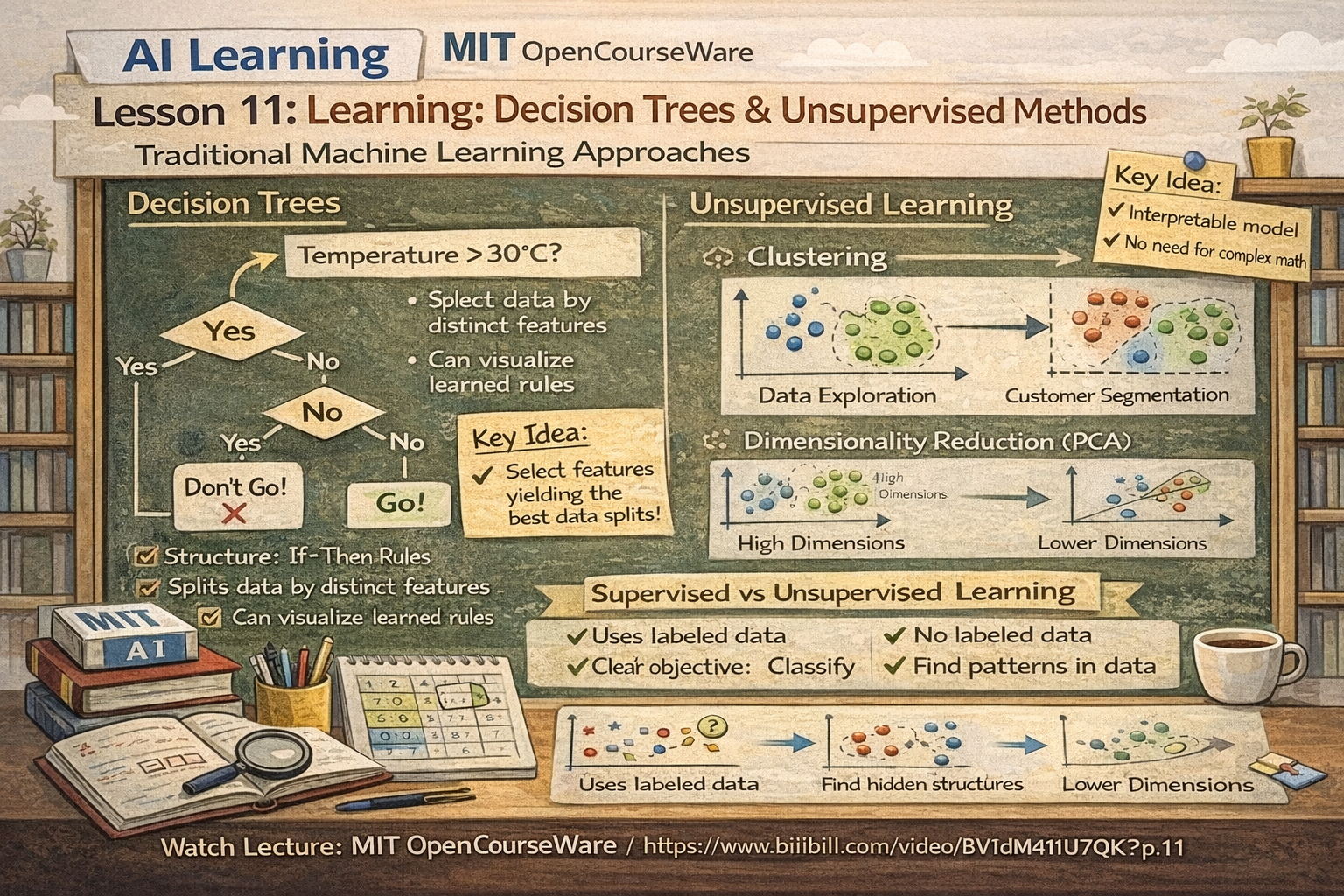
二、前半部分:识别树(=决策树)
1️⃣ 什么是识别树?
一句话:
通过一连串"如果...那么..."的判断来进行分类或预测
例如:
- 如果「温度 > 30℃」?
- 如果「下雨 = 是」?
- 最终得到「去 / 不去」
👉 本质:树结构的分类模型
2️⃣ 决策树是怎么"学"的?
核心思想只有一个:
每一步选"最能区分数据"的特征
常见指标(知道名字即可):
- 信息增益(Information Gain)
- 熵(Entropy)
- 基尼指数(Gini)
入试不会让你算公式,但会问:
- 为什么要选"信息增益最大"的特征?
- 这样做有什么好处?
3️⃣ 决策树的优缺点(必考)
优点
- 结构直观,可解释性强
- 不需要复杂数学
- 适合规则清晰的问题
缺点
- 容易过拟合
- 对噪声敏感
- 树太深会泛化差
👉 很常见的考法:
「以下哪一项是决策树的特点?」
三、后半部分:无序(=无监督学习)
1️⃣ 什么是"无序学习"?
日文里的「無序」= 没有正确答案标签
一句话:
只有数据,没有老师
与前面学过的「教师あり学習(监督学习)」形成对比。
2️⃣ 典型无监督学习任务
🔹 聚类(Clustering)
- 把相似的数据分到一组
- 代表方法:k-means
例如:
- 自动把顾客分群
- 把相似图片聚在一起
🔹 降维(Dimensionality Reduction)
- 用更少的变量表示数据
- 代表方法:PCA
3️⃣ 无监督学习的特点(考试重点)
-
没有"正确答案"
-
结果的好坏依赖评价方法
-
常用于:
- 数据探索
- 特征预处理
- 发现隐藏结构
👉 很爱考这种对比题:
「监督学习 与 无监督学习 的区别是?」
四、这节课的"入试视角总结"
如果这是日本大学院 AI 入试,这节课在考什么?
✅ 不会考代码
✅ 不会考复杂公式
✅ 会考概念理解 + 区别 + 适用场景
重点记住三组对比:
1️⃣ 决策树 vs 最近邻
2️⃣ 监督学习 vs 无监督学习
3️⃣ 可解释性强 vs 表达能力强(为神经网络铺垫)
4-课后练习(日语版本)
問題1(識別木:基本性質)
識別木(決定木)に関する説明として、最も適切なものを一つ選べ。
A.識別木は常に最短の分類規則を生成する。
B.識別木は学習データに対して過学習を起こしにくい。
C.識別木は分類規則を木構造として表現し、可読性が高い。
D.識別木は教師なし学習の代表的手法である。
問題2(識別木:分割基準)
識別木において、分割に用いられる評価基準として一般的でないものを一つ選べ。
A.情報利得
B.エントロピー
C.ジニ係数
D.ユークリッド距離
問題3(無教師学習:特徴)
無教師学習に関する説明として、正しいものを一つ選べ。
A.正解ラベルを用いてモデルを学習する。
B.分類精度を用いて結果の良否を直接評価できる。
C.データの潜在的な構造や類似性を発見する目的で用いられる。
D.誤差逆伝播法を用いて学習を行う。
問題4(学習方法の比較)
教師あり学習と無教師学習の違いに関する説明として、最も適切なものを一つ選べ。
A.教師あり学習では、常に分類問題のみを扱う。
B.無教師学習では、入力データと正解ラベルの対応が与えられる。
C.教師あり学習では、目的変数が与えられる。
D.無教師学習は、識別木によってのみ実現される。
做题建议(重要)
- 不要靠「感觉」
- 每个选项都问自己一句:
👉 "这是不是定义层面的事实?"
你可以直接回复我:
1: ?
2: ?
3: ?
4: ?5-课后答案解析(日语版本)
問題1(識別木の性質)
你的答案:C
識別木は分類規則を木構造として表現し、可読性が高い。
✅ 正确
- 决策树最大的特点就是 可解释性强
- 这是教科书级正确描述
- A、B 都是常见陷阱("常に""起こしにくい")
👉 这一题你是标准满分答案
問題2(分割基準)
你的答案:A(情報利得)
❌ 这一题错了
题目问的是:
一般的でないもの(不常用的)
- 情報利得 ✔ 常用
- エントロピー ✔ 常用
- ジニ係数 ✔ 常用
- ユークリッド距離 ❌(这是 k-means 等聚类用的)
✅ 正确答案是:D
問題3(無教師学習)
你的答案:C
データの潜在的な構造や類似性を発見する目的で用いられる。
✅ 完全正确
- 这是无监督学习的标准定义句
- A、B、D 都是典型"监督学习/深度学习混入陷阱"
問題4(教師あり vs 無教師あり)
你的答案:C
教師あり学習では、目的変数が与えられる。
✅ 正确
- 这是区分监督/无监督的核心一句话
- 表述精准,没有多余限定词
📊 总结成绩(按真实入试标准)
| 题号 | 结果 | 评价 |
|---|---|---|
| 1 | ✅ | 教科书级理解 |
| 2 | ❌ | 典型混淆点 |
| 3 | ✅ | 概念非常稳 |
| 4 | ✅ | 入试标准答案 |
👉 正确率:3 / 4(合格线以上)
🎯 出题人对你的评价(实话)
-
你 概念掌握是对的
-
错的不是"不会",而是:
- 没有抓住"这个指标是给谁用的"
这正是日本大学院入试想筛的点。
🔑 给你一个"不会再错"的一句话规则
"凡是'距离'相关的,多半不是决策树的分割指标。"
6-总结
知识一点点记录吧,最后应对考试,打下基础