之前发现不同框架的性能差异有出入,当时并没有太在意。最近,对社区开源的LLM性能压测工具做了一个深度体验。发现各个框架对于各指标(如:ILT/TPOT)的定义真的是五花八门,稍微不注意可能就会用错里面的指标。本文梳理了各性能压测工具的计算公式,试图对齐各压测工具的性能指标。
我撰写的大模型相关的博客及配套代码 均整理放置在Github:llm-action,有需要的朋友自取。
各框架概述
GuideLLM
GuideLLM 是一个用于评估语言模型在真实工作负载和配置下性能表现的平台。它模拟与 OpenAI 和 vLLM 原生服务兼容的端到端交互,生成反映生产使用情况的工作负载模式,并生成详细报告,帮助团队理解系统行为、资源需求和运营限制。GuideLLM 支持真实和合成数据集、多模态输入以及灵活的执行配置文件,为工程师和机器学习团队提供了一个一致的框架,用于评估模型行为、调整部署和规划容量,以应对系统演进。

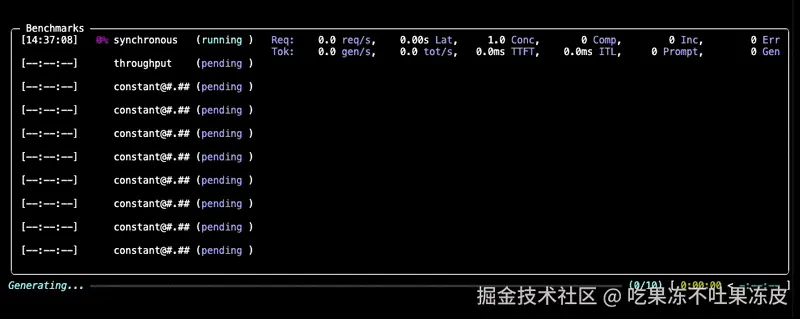
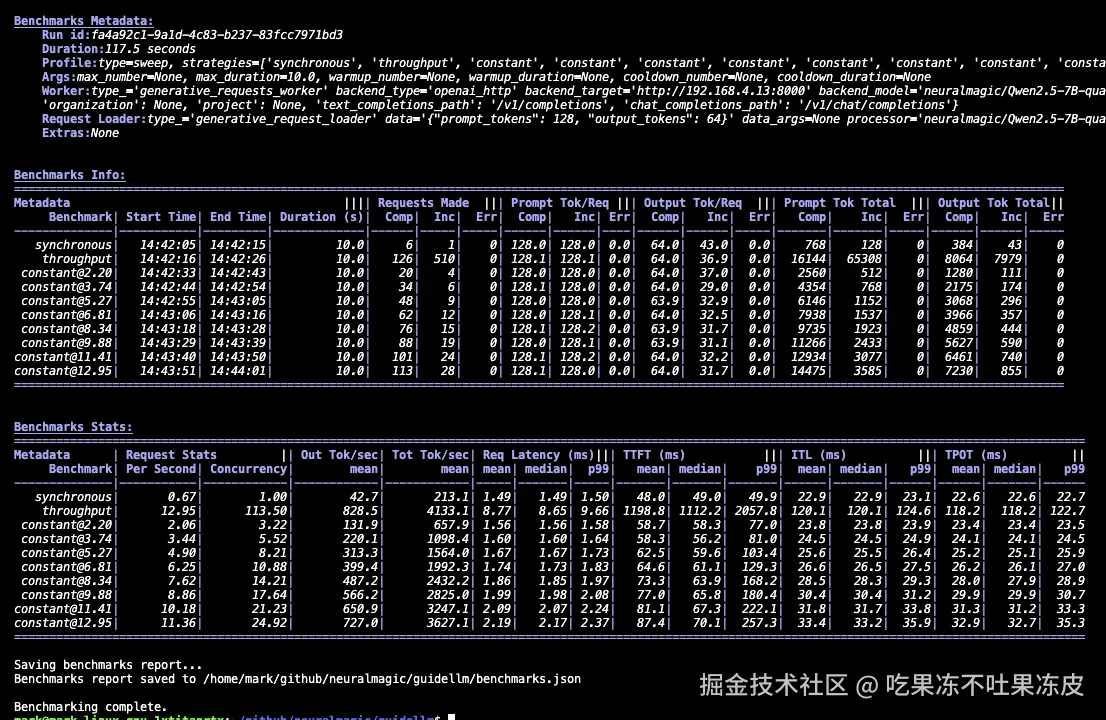
GuideLLM特性:
GuideLLM 为团队在类生产环境中部署 LLM 时,清晰地展示了性能、效率和可靠性。
- 捕捉完整的延迟和token级统计数据,用于 SLO 驱动的评估 ,包括 TTFT、ITL 和端到端行为的完整分布。
- 生成跨同步、并发和基于速率模式的真实、可配置的流量模式 ,包括可重复的扫描以识别安全运行范围。
- 支持真实和合成多模态数据集 ,支持一个框架内的受控实验和生产式评估。
- 生成标准化、可导出的报告,用于仪表盘、分析和回归跟踪 ,确保团队和工作流程间的一致性。
- 提供高吞吐量、可扩展的基准测试,支持多处理、线程、异步执行,以及灵活的 CLI/API用于支持自定义或快速启动。
安装:
pip install guidellm或者直接使用镜像:
sql
docker run -dt --name guidellm-lgd \
--gpus all \
--network=host \
--shm-size=256g \
--env LANG=C.UTF-8 \
-v /share/global:/global \
--entrypoint /bin/bash \
ghcr.io/vllm-project/guidellm:latest
docker exec -it guidellm-lgd /bin/bash示例:
diff
BASE_PATH=/workspace/outputs/genai-bench-eval
NAME=qwen3-8b-bf16-parallel20
rm -rf $BASE_PATH/$NAME
genai-bench benchmark \
--api-backend sglang \
--api-base "http://localhost:8000" \
--api-model-name "Qwen3-8B" \
--api-key "xxx" \
--model-tokenizer "/global/models/Qwen3-8B" \
--server-engine "SGLang" \
--server-gpu-type "H200" \
--server-version "v0.5.6" \
--server-gpu-count 1 \
--task text-to-text \
--max-time-per-run 10 \
--max-requests-per-run 500 \
--num-concurrency 20 \
--traffic-scenario "D(1024,128)" \
--experiment-base-dir $BASE_PATH \
--experiment-folder-name $NAME关键参数:
- --profile:定义流量模式,选项包括 synchronous (顺序请求)、 concurrent (并行用户)、 throughput(最大容量)、 constant(每秒固定请求数)、 poisson(每秒随机请求数)或 sweep(自动速率探索)。
- --rate:速率值,其含义取决于
--profile,sweep 时是基准测试数量,concurrent 时是同时请求, constant / poisson 时是每秒请求数。 - --max-seconds:每次基准测试的最大持续时间(秒数)(也可以用 --max-requests 来限制请求数)。
常用指标计算公式:
- 平均ITL = (last_token - first_token) / (output_tokens - 1) , 不包括第一个token
- 平均TPOT = (last_token - request_start) / output_tokens , 包括第一个token
- e2e latency = request_end - request_start
- 输出吞吐量 = output_tokens / e2e latency
参考:
Genai-Bench
Genai-bench 是一款强大的基准工具,旨在全面评估大语言模型服务系统的token级性能评估。它提供了模型服务性能的详细洞察,还有用户友好的 CLI 和实时进度监控的实时 UI。
特征:
- 🛠️ CLI 工具 :无缝验证用户输入并启动基准测试。
- 📊 实时界面仪表盘 :显示当前进度、日志和实时指标。
- 📝 丰富的日志 :实验完成后自动写入终端和文件。
- 📈 实验分析器 :生成包含原始指标数据的全面 Excel 报告,以及灵活的图表配置(默认 2x4 网格),可视化关键性能指标,包括吞吐量、延迟(TTFT、端对端、TPOT)、错误率和 RPS,适用于不同流量场景和并发水平。支持自定义绘制布局和多行比较。

安装:
pip install genai-bench示例:
diff
BASE_PATH=/workspace/outputs/genai-bench-eval
NAME=qwen3-8b-bf16-parallel20
rm -rf $BASE_PATH/$NAME
genai-bench benchmark \
--api-backend sglang \
--api-base "http://localhost:8000" \
--api-model-name "Qwen3-8B" \
--api-key "xxx" \
--model-tokenizer "/global/models/Qwen3-8B" \
--server-engine "SGLang" \
--server-gpu-type "H200" \
--server-version "v0.5.6" \
--server-gpu-count 1 \
--task text-to-text \
--max-time-per-run 10 \
--max-requests-per-run 500 \
--num-concurrency 20 \
--traffic-scenario "D(1024,128)" \
--experiment-base-dir $BASE_PATH \
--experiment-folder-name $NAME参数说明:
- --task:指定任务类型,支持文本生成、文生图、文本嵌入、图像嵌入。
- --traffic-scenario:接受一种或多种场景。每次运行都会迭代所提供的场景和所选迭代参数(并发或批处理大小)。文本分布类型:
- 确定性输入输出:
D(num_input_tokens,num_output_tokens),比如:D(100,1000) - 正态分布:
N(mean_input_tokens,stddev_input_tokens)/(mean_output_tokens,stddev_output_tokens),例如:N(480,240)/(300,150) - 均匀分布:
U(min_input_tokens,max_input_tokens)/(min_output_tokens,max_output_tokens),例如:U(50,100)/(200,250)
- 确定性输入输出:
从结果生成 Excel 报告:
ini
BASE_PATH=/workspace/outputs/genai-bench-eval
NAME=qwen3-8b-bf16-parallel20
genai-bench excel --experiment-folder $BASE_PATH/$NAME \
--excel-name results \
--metric-percentile mean常见指标计算公式:
- metrics.e2e_latency = response.end_time - response.start_time
- metrics.num_input_tokens = response.num_prefill_tokens
- metrics.total_tokens = metrics.num_input_tokens
- metrics.num_output_tokens = response.tokens_received
- metrics.total_tokens += metrics.num_output_tokens
- metrics.ttft = response.time_at_first_token - response.start_time
- metrics.output_latency = metrics.e2e_latency - metrics.ttft
- metrics.tpot = metrics.output_latency / (metrics.num_output_tokens - 1),相当于GuideLLM中的ITL
- metrics.output_throughput = metrics.num_output_tokens - 1) / metrics.output_latency
参考:
AIPerf
AIPerf 是一款全面的基准测试工具,用于衡量生成式 AI 模型的性能。它通过命令行展示详细的指标以及详尽的基准性能报告。
AIPerf 之前,英伟达开源的大模型性能工具为GenAI-Perf,目前已经逐步淘汰。
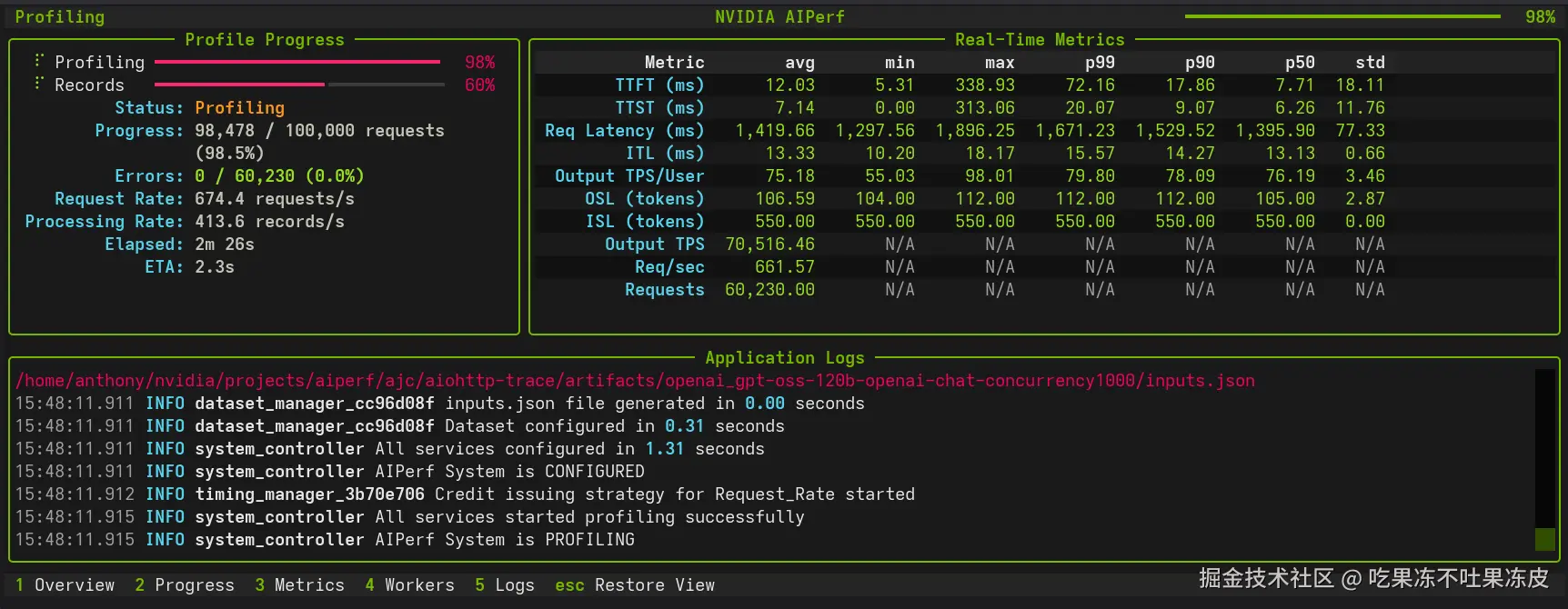
特性:
- 通过多进程支持可扩展
- 模块化设计便于用户修改
- 支持多种基准测试模式:
- 并发
- 请求率
- 最大并发量的请求率
- 追踪回放用于重现性能基准测试结果
- 支持公开数据集
支持的 API:
- OpenAI chat completions
- OpenAI completions
- OpenAI embeddings
- OpenAI audio: request throughput and latency
- OpenAI images: request throughput and latency
- NIM rankings
安装:
pip install aiperf示例:
diff
aiperf profile \
--model qwen3 \
--tokenizer /global/models/Qwen3-8B \
--url localhost:8000 \
--endpoint-type chat \
--endpoint /v1/chat/completions \
--streaming \
--synthetic-input-tokens-mean 1024 \
--synthetic-input-tokens-stddev 0 \
--output-tokens-mean 128 \
--output-tokens-stddev 0 \
--extra-inputs ignore_eos:true \
--concurrency 20 \
--request-count 500 \
--warmup-request-count 0 \
--num-dataset-entries 1000 \
--random-seed 100 生成基准测试结果:

常用指标计算公式:
- TTFT = First Response Timestamp - Request Start Timestamp
- TTST = Second Response Timestamp - First Response Timestamp
- Inter Token Latency(ITL) = (Request Latency - Time to First Token) / (Output Sequence Length - 1)
- ICL =
[timestamps[i] - timestamps[i-1] for i in range(1, len(timestamps))],比如:对于块在 100ms, 150ms, 210ms 时间到达的流响应。ICL = 50ms, 60ms(连续时间戳之间的差异)
参考:
EvalScope
EvalScope 是魔搭社区倾力打造的模型评测与性能基准测试框架,为您的模型评估需求提供一站式解决方案。支持的模型类型如下:
- 🧠 大语言模型
- 🎨 多模态模型
- 🔍 Embedding 模型
- 🏆 Reranker 模型
- 🖼️ CLIP 模型
- 🎭 AIGC模型(图生文/视频)
EvalScope 不仅仅是一个评测工具,它还内置多个业界认可的测试基准和评测指标:MMLU、CMMLU、C-Eval、GSM8K 等。同时,支持模型推理性能压测,确保您的模型在实际应用中表现出色。
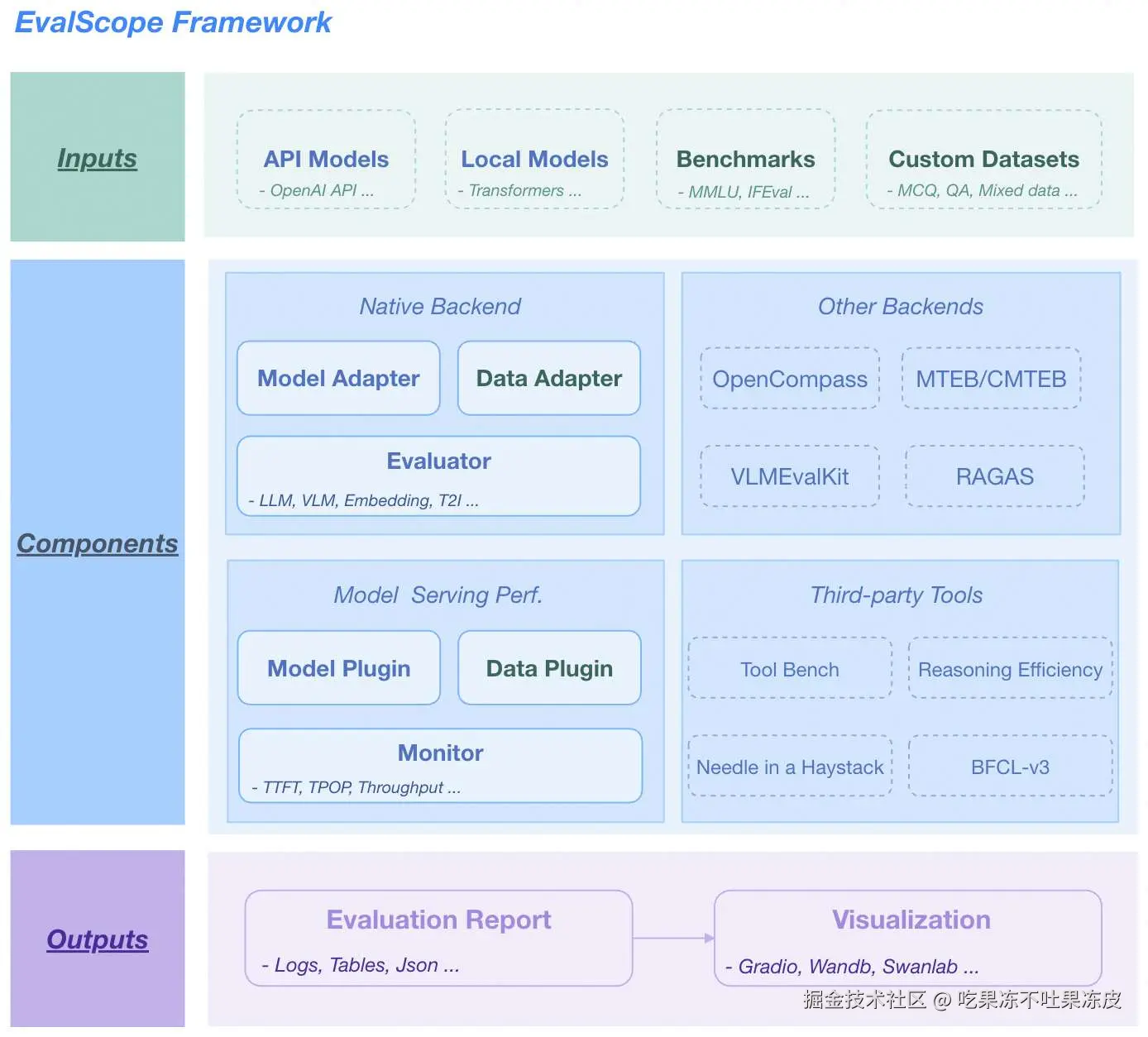
EvalScope 整体架构如下图所示,包括以下模块:
- 输入层
- 模型来源:API模型(OpenAI API)、本地模型(ModelScope)
- 数据集:标准评测基准(MMLU/GSM8k等)、自定义数据(MCQ/QA)
- 核心功能
多后端评估
- 原生后端:LLM/VLM/Embedding/T2I模型统一评估
- 集成框架:OpenCompass/MTEB/VLMEvalKit/RAGAS
性能监控
- 模型插件:支持多种模型服务API
- 数据插件:支持多种数据格式
- 指标追踪:TTFT/TPOP/稳定性 等指标
工具扩展
- 集成:Tool-Bench/Needle-in-a-Haystack/BFCL-v3
- 输出层
- 结构化报告: 支持JSON/Table/Logs
- 可视化平台:支持Gradio/Wandb/SwanLab
框架特点:
- 基准数据集:预置了多个常用测试基准,包括:MMLU、CMMLU、C-Eval、GSM8K、ARC、HellaSwag、TruthfulQA、MATH、HumanEval等。
- 评测指标:实现了多种常用评测指标。
- 模型接入:统一的模型接入机制,兼容多个系列模型的Generate、Chat接口。
- 自动评测:包括客观题自动评测和使用专家模型进行的复杂任务评测。
- 评测报告:自动生成评测报告。
- 竞技场(Arena)模式:用于模型间的比较以及模型的客观评测,支持多种评测模式,包括:
- Single mode:对单个模型进行评分。
- Pairwise-baseline mode:与基线模型进行对比。
- Pairwise (all) mode:所有模型间的两两对比。
- 可视化工具:提供直观的评测结果展示。
- 模型性能评测:提供模型推理服务压测工具和详细统计。
- OpenCompass集成:支持OpenCompass作为评测后端,对其进行了高级封装和任务简化,您可以更轻松地提交任务进行评测。
- VLMEvalKit集成:支持VLMEvalKit作为评测后端,轻松发起多模态评测任务,支持多种多模态模型和数据集。
- 全链路支持:通过与ms-swift训练框架的无缝集成,实现模型训练、模型部署、模型评测、评测报告查看的一站式开发流程,提升用户的开发效率。
EvalScope 支持OpenAI API格式模型服务以及多种数据集格式,方便用户进行性能评测。具体使用如下:
安装:
css
pip install evalscope[perf] -U示例:
lua
evalscope perf \
--parallel 20 \
--number 500 \
--model Qwen-bf16-isl1k-osl128-056post1 \
--url http://localhost:8000/v1/chat/completions \
--api openai \
--dataset random \
--max-tokens 128 \
--min-tokens 128 \
--prefix-length 0 \
--min-prompt-length 1024 \
--max-prompt-length 1024 \
--tokenizer-path /global/models/Qwen3-8B \
--extra-args '{"ignore_eos": true}' \
--outputs-dir /workspace/outputs/evalscope-perf-qwen3-8b参数说明:
- parallel: 请求的并发数,可以传入多个值,用空格隔开
- number: 发出的请求的总数量,可以传入多个值,用空格隔开(与parallel一一对应)
- url: 请求的URL地址
- model: 使用的模型名称
- api: 使用的API服务,默认为openai
- dataset: 数据集名称,此处为random,表示随机生成数据集。
- tokenizer-path: 模型的tokenizer路径,用于计算token数量(在random数据集中是必须的)
- extra-args: 请求中的额外的参数,传入json格式的字符串,例如:{"ignore_eos": true} 表示忽略结束token
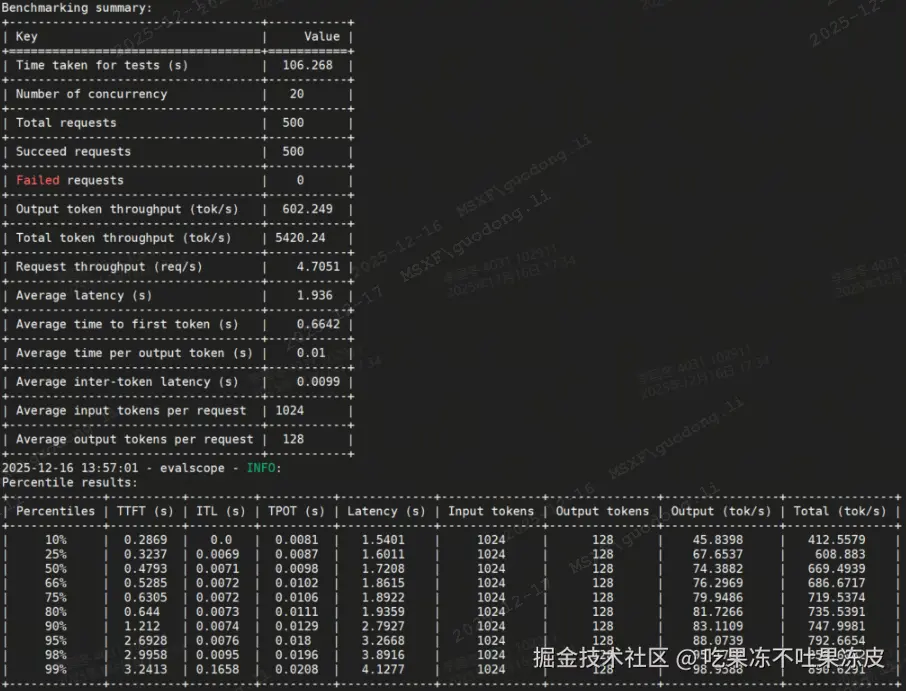
常见指标计算公式:
- time_per_output_token (TPOT) = (query_latency - first_chunk_latency) / (completion_tokens - 1),注意:AIPerf和GuideLLM中的itl实际上和EvalsSope的计算公式一致。
- n_time_per_output_token += benchmark_data.time_per_output_token
- avg_time_per_token (平均TPOT) = n_time_per_output_token / n_succeed_queries
- total_first_chunk_latency += benchmark_data.first_chunk_latency
- avg_first_chunk_latency(平均TTFT) = total_first_chunk_latency / n_succeed_queries
- inter_chunk_latency =
[t2 - t1 for t1, t2 in zip(chunk_times[:-1], chunk_times[1:])] - n_total_inter_token_latency += benchmark_data.inter_chunk_latency
- avg_inter_token_latency(平均ITL) = sum(n_total_inter_token_latency) / len(n_total_inter_token_latency)
- qps = n_succeed_queries / total_time
- avg_output_token_per_seconds(输出token吞吐量) = n_total_completion_tokens / total_time
参考:
Inference Perf
Inference Perf 是一款生成式 AI 推理性能基准工具,允许您对部署的推理模型的性能进行基准测试和分析。它不受模型服务影响,可用于性能测量 和对不同系统进行全面比较。它是推理基准测试和指标标准化工作的一部分,旨在标准化 Kubernetes 和模型服务社区中用于衡量推理性能的基准工具和指标 。
架构:
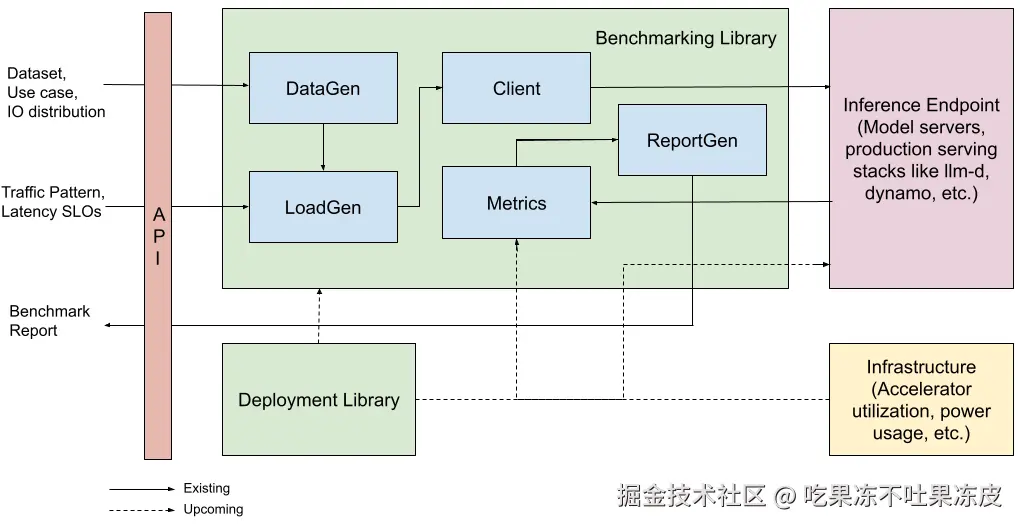
主要特点:
- 高度可扩展,并支持大规模模型推理生产部署的基准测试。
- 报告衡量 LLM 性能的关键指标。
- 支持不同的真实世界和合成数据集。
- 支持不同的 API,并支持多个具增强指标的模型服务,如 vLLM、SGLang 和 TGI。
- 支持使用 LLM-d、Dynamo 和 Inference Gateway 等框架进行大型部署基准测试。
- 支持指定精确的输入和输出分布以模拟不同场景------支持高斯分布、固定长度、最小最大场景。
- 生成不同的负载模式,并能对特定场景进行基准测试,如突发流量、扩展至饱和以及其他自动扩展/路由场景。
- 支持多轮聊天对话,可以保持一系列消息的上下文,模拟对话。每轮聊天中的请求将保留前置消息作为前缀。
安装:
pip install inference-perf示例:
arduino
inference-perf --config_file config.yml其中,config.yml内容如下所示:
yaml
load:
type: constant
interval: 15
stages:
- rate: 1
duration: 30
- rate: 2
duration: 30
api:
type: completion
server:
type: sglang
model_name: HuggingFaceTB/SmolLM2-135M-Instruct
base_url: http://0.0.0.0:8000
tokenizer:
pretrained_model_name_or_path: HuggingFaceTB/SmolLM2-135M-Instruct
data:
type: synthetic
input_distribution:
min: 10 # min length of the synthetic prompts
max: 100 # max length of the synthetic prompts
mean: 50 # mean length of the synthetic prompts
std: 10 # standard deviation of the length of the synthetic prompts
output_distribution:
min: 10 # min length of the output to be generated
max: 100 # max length of the output to be generated
mean: 50 # mean length of the output to be generated
std: 10 # standard deviation of the length of the output to be generated
metrics:
type: prometheus
prometheus:
url: http://localhost:9090
scrape_interval: 15
report:
request_lifecycle:
summary: true
per_stage: true
per_request: true常见指标计算公式:
- time_per_output_token (TPOT)=
(x.info.output_token_times[-1] - x.info.output_token_times[0]) / (len(x.info.output_token_times) - 1),该指标相当于GuideLLM的ITL - normalized_time_per_output_token(标准TPOT) = (metric.end_time - metric.start_time) / metric.info.output_tokens ,该指标相当于GuideLLM的TPOT
- TTFT = x.info.output_token_times0 - x.start_time
- 平均ITL =
mean([t2 - t1 for x in streamable for t1, t2 in zip(x.info.output_token_times, x.info.output_token_times[1:], strict=False)]) - total_time = max(x.end_time for x in metrics) - min(x.start_time for x in metrics)` ,相当于AIPerf中的ICL求平均。
- output_tokens_per_sec (输出token吞吐量) = sum(x.info.output_tokens for x in all_successful) / total_time
- requests_per_sec(RPS) = len(all_successful) / total_time
参考:
LLMPerf
LLMPerf 是一个用于评估 LLM API 性能的工具。目前已停止更新。实现了两种评估大型语言模型的测试:一个是用于测试性能的负载测试,另一个是用于检测正确性的正确性测试。
安装:
bash
git clone https://github.com/ray-project/llmperf.git
cd llmperf
pip install -e .负载测试:
负载测试会向 LLM API 生成多个并发请求,并测量tiken间延迟和每次请求及跨并发请求的生成吞吐量。每个请求中发送的提示词格式如下:
vbnet
Randomly stream lines from the following text. Don't generate eos tokens:
LINE 1,
LINE 2,
LINE 3,
...诗句是从莎士比亚十四行诗中的一组诗句中随机抽取的。无论测试的是哪个 LLM API,LlamaTokenizer 都会统计 token 数。这是为了确保提示在不同 LLM API 上保持一致。
OpenAI Compatible APIs 示例如下:
dart
export OPENAI_API_KEY=secret_abcdefg
export OPENAI_API_BASE=https://console.endpoints.anyscale.com/m/v1
python llm_correctness.py \
--model "meta-llama/Llama-2-7b-chat-hf" \
--max-num-completed-requests 150 \
--timeout 600 \
--num-concurrent-requests 10 \
--results-dir "result_outputs"注意事项与免责声明:
- 终端提供商的后端可能差异很大,因此这并不代表软件在特定硬件上的运行方式。
- 结果可能会因一天中的时间而异。
- 结果可能会因负载不同而有所变化。
- 结果可能与用户的工作量不相关。
正确性测试:
正确性测试会以以下格式向 LLM API 生成多个并发请求:
sql
Convert the following sequence of words into a number: {random_number_in_word_format}. Output just your final answer.其中:random_number_in_word_format 可以是 "one hundred and twenty three"。测试检查回答中是否包含该数字格式,在此例中为 123。
该检验对随机生成的数字进行此操作,并报告包含不匹配的回答数量。
OpenAI Compatible APIs 示例:
dart
export OPENAI_API_KEY=secret_abcdefg
export OPENAI_API_BASE=https://console.endpoints.anyscale.com/m/v1
python llm_correctness.py \
--model "meta-llama/Llama-2-7b-chat-hf" \
--max-num-completed-requests 150 \
--timeout 600 \
--num-concurrent-requests 10 \
--results-dir "result_outputs"参考:
llm-benchmark
llm-benchmark 通过 Ollama 进行本地 LLM 吞吐量基准测试。
llm-benchmark 在 Windows、Linux 和 macOS 上,它会检测内存大小以优先下载所需的 LLM 模型。
当内存内存大小大于或等于 4GB 但小于 7GB 时,它会检查是否存在 gemma:2b。程序隐式地拉取这些模型。
ollama pull deepseek-r1:1.5b
ollama pull gemma:2b
ollama pull phi:2.7b
ollama pull phi3:3.8b
安装:
pip install llm-benchmark运行:
#1 将系统信息和基准测试结果发送到远程服务器
arduino
llm_benchmark run#2 不要将系统信息和基准测试结果发送到远程服务器
arduino
llm_benchmark run --no-sendinfo#3 明确指定 ollama 可执行文件路径时运行(当你构建了自己的 ollama 开发者版本时)
css
llm_benchmark run --ollamabin=~/code/ollama/ollama#4 运行自定义基准模型
css
llm_benchmark run --custombenchmark=path/to/custombenchmarkmodels.yml其中,custombenchmarkmodels.yml文件内容如下:
vbnet
file_name: "custombenchmarkmodels.yml"
version: 2.0.custom
models:
- model: "deepseek-r1:1.5b"
- model: "qwen:0.5b"参考:
常见的性能延迟指标
上面在各框架概述,我梳理了各框架的性能压测指标,但是有一些指标在各框架里面计算方式不一,下面我综合主流的大模型框架的评估指标的计算方式,根据自己的主观判断给一点标准定义,以便使用各框架进行性能压测时能够对齐。:
- 首Token生成时间 (Time To First Token,简称TTFT):即用户输入提示后,模型生成第一个输出词元(Token)所需的时间。在实时交互中,低时延获取响应非常重要,但在离线工作任务中则不太重要。此指标受处理提示信息并生成首个输出词元所需的时间所驱动。通常,不仅对平均TTFT感兴趣,还包括其分布,如P50、P90、P95和P99等。计算公式为:
ttft = first_token_time - request_start_time。 - Token间延迟 (Inter Token Latency,简称ITL):计算公式:
ITL = (last_token_time - first_token_time) / (output_tokens - 1) , 不包括第一个token。 - 块间延迟 (Inter Chunk Latency,简称ICL):特指在流式传输场景 下,模型服务器返回的两个连续数据块(Chunk)之间的时间间隔。在流式传输中,LLM生成的文本不是一次性全部返回,而是以"块"为单位逐步返回。一个"块"通常包含若干个Token。因此,它衡量的是客户端接收到第N个数据块与接收到第N+1个数据块之间的时间差。它主要出现在服务器以 "text/event-stream" 等流式协议返回数据的场景中,是评估流式响应流畅度的核心指标。计算公式:
Inter Chunk Latency (Chunk_N) = Timestamp(收到 Chunk_{N+1}) - Timestamp(收到 Chunk_N)。 - 每个输出Token的生成时间 (Time Per Output Token,简称TPOT):即为每个用户的查询生成一个输出词元所需的时间。这一指标与每个用户对模型"速度"的感知相关。例如,TPOT为100ms/token表示每个用户每秒可处理10个token,或者每分钟处理约450个token,那么这一速度远超普通人的阅读速度。计算公式:
TPOT = (last_token_time - request_start_time) / output_tokens , 包括第一个token。 - 端到端时延(E2E) :模型为用户生成完整响应所需的总时间。整体响应时延可使用前两个指标计算得出:
e2e latency = request_end_time - request_start_time。 - 每分钟完成的请求数(RPS):通常情况下,我们都希望系统能够处理并发请求。可能是因为你正在处理来自多个用户的输入或者可能有一个批量推理任务。
- 生成Token吞吐量 :推理服务在所有用户请求中每秒可生成的输出词元(Token)数。考虑到无法测量预加载时间,并且总推理时延所花时间更多地取决于生成的Token数量,而不是输入的Token数量,因此,将注意力集中在输出Token上通常是正确的抉择。计算公式:
输出Token吞吐量 = output_tokens / e2e latency - 总吞吐量:包括输入的Token和生成的Token。
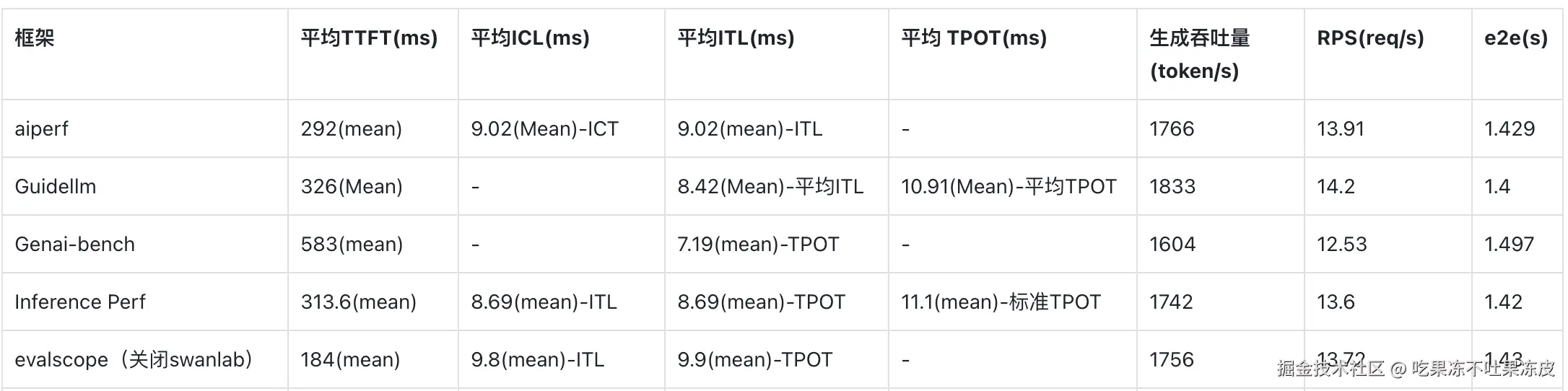
各框架之间的指标差异
下面是针对qwen3-8b在h200上进行各框架性能指标对齐的结果(主要是ICL/ITL/TPOT指标差异较大)。即针对上面汇总之后定义的指标,在各个框架中的对应值。
结语
最后,在GuideLLM针对各LLM性能压测进行综合对比的基础上,下表进一步汇总了各个LLM性能压测框架的特性差异,大家在选择性能测试工具时可以根据自己的偏好进行选择。如果需要对比各种框架和特性的性能,最好统一使用同一个工具进行比较,以免出现结论性错误。
| 工具 | CLI | API | High Perf | Full Metrics | 数据模态 | 数据源 | Profiles | Backends | Endpoints | 输出类型 |
|---|---|---|---|---|---|---|---|---|---|---|
| GuideLLM | ✅ | ✅ | ✅ | ✅ | 文本, 图像, 音频, 视频 | HuggingFace, Files, 合成, 自定义数据集 | Synchronous, Concurrent, Throughput, Constant, Poisson, Sweep | OpenAI-compatible | /completions, /chat/completions, /audio/translation, /audio/transcription | console, json, csv, html |
| inference-perf | ✅ | ❌ | ✅ | ❌ | 文本 | 合成, 指定数据集 | Concurrent, Constant, Poisson, Sweep | OpenAI-compatible | /completions, /chat/completions | json, png |
| genai-bench | ✅ | ❌ | ❌ | ❌ | 文本, 图像, Embedding, ReRank | 合成, File | Concurrent | OpenAI-compatible, Hosted Cloud | /chat/completions, /embeddings | console, xlsx, png |
| llm-perf | ❌ | ❌ | ✅ | ❌ | 文本 | 合成 | Concurrent | OpenAI-compatible, Hosted Cloud | /chat/completions | json |
| ollama-benchmark | ✅ | ❌ | ❌ | ❌ | 文本 | 合成 | 同步 | Ollama | /completions | console, json |
| vllm/benchmarks | ✅ | ❌ | ❌ | ❌ | 文本 | 合成, 指定数据集 | Synchronous, Throughput, Constant, Sweep | OpenAI-compatible, vLLM API | /completions, /chat/completions | console, png |
| AIPerf | ✅ | - | - | - | 文本、图像、视频 | 合成、自定义以及公开数据集 | Concurrent | OpenAI-compatible | /completions, /chat/completions | console, json, csv |
| EvalScope Perf | ✅ | - | - | ❌ | 文本、图像 | 合成、自定义以及公开数据集 | Concurrent | OpenAI-compatible | /completions, /chat/completions | console, json |