赋值
python
# 例1:if 基本用法
flag = False
name = 'luren'
if name == 'python': # 判断变量是否为 python
flag = True # 条件成立时设置标志为真
print 'welcome boss' # 并输出欢迎信息
else:
print name # 条件不成立时输出变量名称输出结果: luren
python
a = 3
b = 2
print(a+b) #5
print(a-b) #1
print(a*b) #6
print(a/b) #1.5
print(a//b) #地板除 1
print(a**b) #3的2次 = 9函数
python
#返回A的平方
def myfun(A):
C = A**2
return C
#返回A的B次方
def myfun(A, B):
return A**B
#如果传入B,就返回A的B次方, 如果没传入B,返回A的平方
def myfun(A, B=2):
return A**B
print(myfun(3)) #3的2次=9def print_hi(name):
print(f'Hi, {name}')
if __name__ == '__main__':
print_hi('PyCharm') 交换a和b
python
a = 3
b = 4
print(a, b) #3 4
a, b = b, a #交换a和b
print(a, b) #4 3字符串
python
name = "ligekaoyan"
print(name) #ligekaoyan
print(name[2]) #返回name字符串中下标为2的值 g列表
python
list1 = [1, 2, 3, 4, 5]
print(list1) #[1, 2, 3, 4, 5]
print(list1[2]) #返回下表为2的值 3
print(list1[-1]) #返回列表最后一个元素 5 列表的循环
python
dict1 = {"name": "ligekaoyan", "age": 28, 20: 80}
list2 = [1, "art", dict1]
for each in list2:
print(each)列表的删除、移除
python
list1 = [1, 2, 3, 10, 5, 6]
list1.remove(10) #移除10
print(list1) #[1, 2, 3, 5, 6]
del list1[3] #删除下标为3的值,即删除5
print(list1) #[1, 2, 3, 6]列表的插入
list1 = [1, 2, 3, 10, 5, 6]
list1.append(7) #列表最后加入7
print(list1) #[1, 2, 3, 10, 5, 6, 7]
list1.extend([8,9]) #列表最后加入89
print(list1) #[1, 2, 3, 10, 5, 6, 7, 8, 9]列表另类初始化
list2 = [i for i in range(1, 10, 2)]
print(list2) #[1, 3, 5, 7, 9]
list3 = []
for i in range(10):
list3.append(i)
print(list3) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]切片
python
list1 = [0,1, 2, 3, 4, 5]
#切片\左闭右开
print(list1[1:4]) #[1, 2, 3]
print(list1[0:4]) #[0,1, 2, 3]
print(list1[1:-1]) #[1, 2, 3,4]
print(list1[1:]) #从下标1开始,到最后 [1, 2, 3, 4, 5]
print(list1[:]) #全部[0, 1, 2, 3, 4, 5] 字典
python
dict = {"name": "ligekaoyan", "age": 28, 20: 80}
#键:name 值ligekaoyan
#键:age 值28
#键:20 值80
print(dict["name"]) #根据name键,找到值 ligekaoyan
print(dict["age"]) #28
print(dict[20]) #80
#字典可以放到列表中
list = [1, "art", dict]
print(list) #[1, 'art', {'name': 'ligekaoyan', 'age': 28, 20: 80}]字典的循环
python
dict1 = {"name": "ligekaoyan", "age": 28, 20: 80}
for each in dict1:
print(each) #each是键 ,打印name,age,20
print(dict1[each]) #dict1[each]是值 ,打印ligekaoyan,28,80循环
python
# for i in 范围
list1 = [1,2,3,4,5]
for i in list1:
print(i)
#遍历list1,打印结果为12345range
生成一个不可变的数字序列
python
for i in range(10): #[0, 10)
print(i) #打印0123456789
for i in range(1, 10): #[1, 10)
print(i) #打印123456789
for i in range(1, 10, 2): #[1, 10),2是步长
print(i) #打印13579while
python
i = 0
while i < 10 :
i += 1
print(i) #0123456789判断
python
a = 4
if a == 3:
print("a == 3")
elif a == 4:
print("a == 4")
python
a = 3
b = 4
if a == 3:
if b > 3:
print("b大于a")
else:
print("b不大于a")yield
yield 是 Python 中用于创建生成器的关键字,它使得函数可以"暂停"和"恢复"执行。
常见的return,运行一次,程序就结束了
如何实现多次的return?
# 普通函数
def normal_function(n):
result = []
for i in range(n):
result.append(i * i)
return result # 一次性返回所有结果
# 生成器函数
def generator_function(n):
for i in range(n):
yield i * i # 每次产生一个结果类
定义类
class person(): # 定义名为person的类
def __init__(self, name, age): # 构造方法/初始化方法
self.name = name # 实例属性:姓名
self.age = age # 实例属性:年龄
def print_name(self): # 实例方法:打印姓名
print(self.name)
def print_age(self): # 实例方法:打印年龄
print(self.age)使用类
# 创建对象/实例
p1 = person("张三", 25)
# 调用方法
p1.print_name() # 输出: 张三
p1.print_age() # 输出: 25 类的继承
class superman(person): # 继承person类
def __init__(self, name, age):
super(superman, self).__init__(name, age) # 调用父类的构造方法
self.fly_ = True # 新增属性:是否能飞
def fly(self): # 新增方法:飞行能力
if self.fly_ == True:
print("我会飞!")
# 创建超人对象
superman1 = superman("克拉克", 30)
# 调用继承自父类的方法
superman1.print_name() # 输出: 克拉克
superman1.print_age() # 输出: 30
# 调用子类新增的方法
superman1.fly() # 输出: 我会飞!
# 访问属性
print(superman1.name) # 输出: 克拉克(继承自父类)
print(superman1.fly_) # 输出: True(子类新增)矩阵
NumPy (Numerical Python)是 Python 中最重要的科学计算库之一,主要用于高效处理大型多维数组和矩阵。
list1 = [
[1,2,3,4,5],
[6,7,8,9,10],
[11,12,13,14,15]
]
print(list1)
# Python列表输出------打印时保持原始格式
[[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]]
#---------------------------------------------------------------
array = np.array(list1)
print(array)
# NumPy数组输出
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]])
#------------------------------------------------------------------------------
tensor1 = torch.tensor(list1)
print(tensor1)
# PyTorch张量输出------类似NumPy数组,但支持GPU加速
tensor([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]])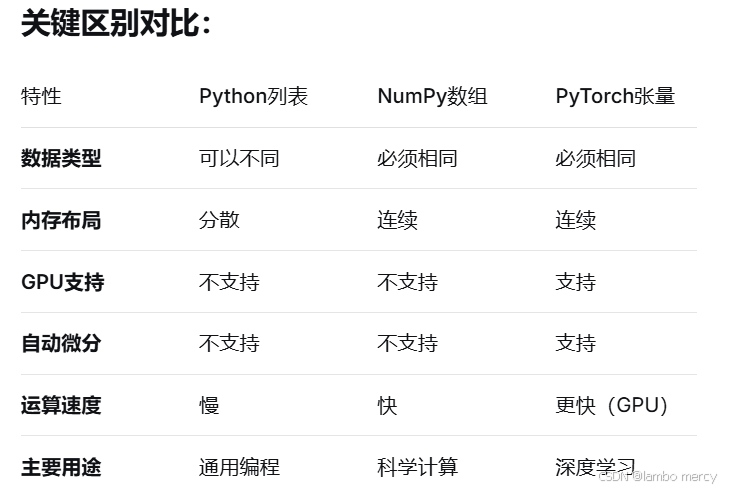
张量梯度
# 1. 创建一个标量张量
x = torch.tensor(3.0) # tensor(3.)
# x = torch.tensor(3.0, requires_grad=True) # 等价写法
# 2. 启用梯度跟踪
x.requires_grad_(True) # 原地修改,添加梯度跟踪
# 3. 定义计算图:y = x²
y = x**2 # y = 3² = 9
# 4. 反向传播,计算梯度
y.backward() # 计算 dy/dx
# 5. 查看梯度
print(x.grad) # tensor(6.)创建张量
torch.ones((100,4)):
相当于创建一个 100行 × 4列 的矩阵(张量)
所有元素的值都初始化为 1
# 创建张量
tensor1 = torch.ones((100,4))
print(tensor1)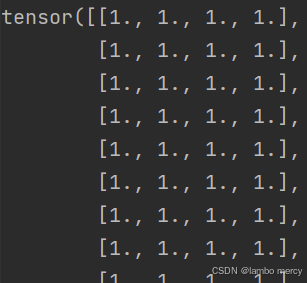
#创建一个10行4列的矩阵,初始化全为0
tensor2 = torch.zeros((10,4))
print(tensor2)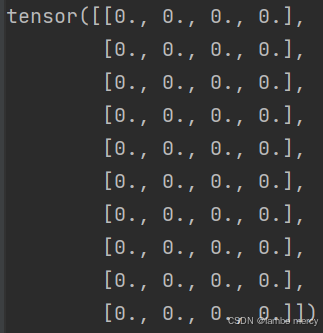
tensor3 = torch.normal(10, 1, (3,10, 4))
print(tensor3)创建正态张量------normal
生成服从正态分布(高斯分布)的随机张量的函数。
torch.normal(10, 1, (3,10,4)):
- mean=10:均值为10
- std=1:标准差为1
- size=(3,10,4):张量形状
创建一个形状为 (3, 10, 4) 的张量(三维张量) 元素值服从正态分布
输出结构: 这是一个 3维张量,可以理解为:
- 3个矩阵(第1维) 每个矩阵有10行(第2维) 每行有4列(第3维)
总元素数量:3 × 10 × 4 = 120

张量求和
tensor1 = torch.ones((10,4))
sum1 = torch.sum(tensor1, dim=1, keepdim=True)
print(sum1) dim=1:沿着第1维度求和(列方向,对每行求和)
【注意:PyTorch中维度从0开始计数 】
- dim=0:按列求和(压缩行)
- dim=1:按行求和(压缩列)
keepdim=True:保持维度不变
原始形状:(10, 4) 沿dim=1求和后,
如果没有keepdim,会变成:(10,)
使用keepdim=True后,形状变为:(10, 1)
计算过程
对于全1的 tensor1:
每一行:[1, 1, 1, 1]
按行求和:1+1+1+1 = 4
10行的结果都是4运行结果
# 输出 sum1
tensor([[4.],
[4.],
[4.],
[4.],
[4.],
[4.],
[4.],
[4.],
[4.],
[4.]])#如果把keepdim改为False
sum1 = torch.sum(tensor1, dim=1, keepdim=False)#结果:tensor([4., 4., 4., 4., 4., 4., 4., 4., 4., 4.])#如果把dim改为0,求一列的和
sum1 = torch.sum(tensor1, dim=0, keepdim=True)#结果: tensor(\[10., 10., 10., 10.])
张量的形状、类型、总数
tensor1 = torch.ones((100,4))
print(f"张量形状: {tensor1.shape}") # 输出: torch.Size([100, 4])
print(f"数据类型: {tensor1.dtype}") # 输出: torch.float32
print(f"总元素数量: {tensor1.numel()}") # 输出: 400张量的合并连接
list1 = [[1,2,3,4,5],
[6,7,8,9,10],
[11,12,13,14,15]]
array = np.array(list1)
array2 = np.array(list1)
array3 = np.concatenate((array, array2), axis=1)
print(array3)
#打印结果:
# [[ 1 2 3 4 5 1 2 3 4 5]
# [ 6 7 8 9 10 6 7 8 9 10]
# [11 12 13 14 15 11 12 13 14 15]]np.concatenate(): 沿着指定轴连接数组
-
axis=1: 沿着第1轴(列方向)连接 (水平堆叠)
-
axis=0: 行方向(垂直堆叠)
#修改axis的值
array3 = np.concatenate((array, array2), axis=0)#打印结果:
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]
[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]]
张量的切片
print(array[:, :]) # 获取array所有行所有列
# 执行会输出:
# [[ 1 2 3 4 5]
# [ 6 7 8 9 10]
# [11 12 13 14 15]]
idx = [1, 3]
print(array[:, idx]) # 获取所有行的第1列和第3列
# 执行会输出:
# [[ 2 4]
# [ 7 9]
# [12 14]]张量梯度
# 原始张量,
# 直接写 x = torch.tensor(3.0)会报错,因为要申明我需要求梯度
x = torch.tensor(3.0, requires_grad=True)
# 先进行一次计算
y1 = x**2
y1.backward()
print("初始梯度:", x.grad) # tensor(6.)
# 梯度会累积在 x.grad 中
# 再进行一次计算
y2 = x**2
y2.backward()
print("梯度:", x.grad) # tensor(12.)
# 梯度会累积在 x.grad 中 ,导致6+6 = 12重置张量
上面提到,梯度如果不进行分离,会累加,这不是我们想要看到的结果,如何重置张量
#重置张量的梯度
x.grad = torch.tensor(0.0)
# 再进行一次计算
y2 = x**2
y2.backward()
print("梯度:", x.grad)
# tensor(6.) 分离张量
如果我们不想要计算梯度,如何把x从向量网上摘下来
# 分离张量
x_detached = x.detach() # 创建不需要梯度的副本
# 如果要让分离后的张量能计算梯度,需要重新设置
# 重新启用梯度跟踪
x_detached.requires_grad_(True)
# 现在可以计算
y2 = x_detached**2
y2.backward()
print("y2:", y2) # tensor(9., grad_fn=<PowBackward0>)
print("分离后x_detached的梯度:", x_detached.grad) # tensor(6.)
print("原始x的梯度:", x.grad) # 还是 tensor(6.),不受影响