VLN-MME: Diagnosing MLLMs as Language-guided Visual Navigation agents
Authors: Xunyi Zhao, Gengze Zhou, Qi Wu
Deep-Dive Summary:
以下是论文的中文摘要:
# 摘要
多模态大语言模型(MLLMs)在各种视觉-语言任务中展现出卓越能力。然而,它们作为具身智能体(需要多轮对话空间推理和顺序动作预测)的性能仍需深入探索。本研究通过引入一个统一且可扩展的评估框架------VLN-MME,将传统导航数据集整合为一个标准化基准,旨在探索MLLMs在零样本(zero-shot)具身智能体方面的潜力。VLN-MME以高度模块化和易于访问的设计简化了评估过程。这种灵活性简化了实验,使得能够对不同的MLLM架构、智能体设计和导航任务进行结构化比较和组件级消融研究。值得注意的是,通过我们的框架,我们观察到用思维链(CoT)推理和自反思增强基线智能体反而导致性能意外下降。这表明MLLMs在具身导航任务中上下文感知能力较差;尽管它们能遵循指令并结构化输出,但其3D空间推理的准确性较低。VLN-MME为具身导航环境中通用MLLMs的系统评估奠定了基础,并揭示了它们在顺序决策能力上的局限性。我们相信这些发现为MLLM作为具身智能体的后训练提供了关键指导。
# 1 引言
具身导航通常依赖于高保真模拟器,如Matterport3D(Chang et al., 2017)或Habitat(Savva et al., 2019)。当在这些多轮、交互式环境中部署大型MLLMs时,计算成本急剧增加。由于跨各种基准测试(Anderson et al., 2018; Qi et al., 2020; Ku et al., 2020)的大量轨迹,这个问题变得更加复杂,使得全面测试变得耗时过长。因此,详尽评估的计算负担促使以前的研究主要采用以指标驱动的方法,优先考虑端到端成功率而非诊断清晰度。这种缺乏原则性错误分析的方法模糊了底层模型行为,使得难以评估关键能力,例如泛化性、鲁棒性,或视觉感知与指令遵循之间的具体对齐。
更关键的是,尽管近期像NavBench(Qiao et al., 2025)这样的评估套件试图标准化这个过程并成功统一不同任务和模型的评估,但它们通常局限于单一的智能体设计。这种限制是实质性的:通过不系统地改变智能体设计,就无法将MLLM的内在能力与特定提示或规划策略的效率分离开来。结果,社区缺乏对失败是源于模型推理限制还是次优智能体工程的细粒度理解。
为了应对这些挑战,我们提出了视觉语言导航多模型评估(VLN-MME),一个旨在解决这些局限性的新颖框架。我们的方法采用模块化、无模拟器的架构,保留了导航语义,同时消除了传统流程的设置复杂性和计算开销。与之前的基准测试不同,VLN-MME旨在评估模型、任务和智能体三者的协同作用。至关重要的是,我们超越了高层成功指标,提供了详细的错误分析,剖析智能体性能以诊断指令遵循、空间理解和历史顺序推理中的核心能力。
我们的贡献总结如下:
- 我们引入了VLN-MME,一个统一且模块化的框架,系统地评估模型、智能体和任务之间的相互作用,解决了以往基准测试中固定智能体设计的局限性。
- 我们设计了一个无模拟器评估流程,它保留了必要的导航语义,同时大幅降低了计算开销和设置复杂性,增强了可访问性。
- 我们提供了一个全面的诊断分析,超越了成功指标,对细粒度故障模式进行分类,以揭示MLLM空间推理和指令遵循中的具体缺陷。
- 我们发布了一套标准化的处理数据集和环境工件,以促进可复现研究并简化基准测试流程。
# 2 相关工作
在空间和具身环境中评估MLLMs 已经出现了全面的基准测试,以测试MLLMs的广泛能力(Chaoyou et al., 2023; Liu et al., 2024; Li et al., 2024c; Yue et al., 2024; Yu et al., 2024; Lu et al., 2023; Fei et al., 2025),范围从基本感知到复杂认知。在此背景下,一些特定的工作专注于评估3D空间推理(Yang et al., 2025b; Daxberger et al., 2025; Xu et al., 2025; Liao et al., 2024; Li et al., 2024b)。然而,大多数这些基准测试依赖于静态QA格式,模型对固定的视觉输入提供单一响应,而不是用于连续状态跟踪。
为了评估顺序推理,一些基准测试侧重于长周期任务;然而,这些任务主要局限于数字领域,如网页浏览和应用程序使用(Deng et al., 2023; Trivedi et al., 2024; Tao et al., 2025; Wang et al., 2025)。最近的具身基准测试试图弥合这一差距,但面临明显的局限性。一些工作,如3DMEM-Bench(Hu et al., 2025),主要侧重于高层规划。虽然这些方法对于评估抽象推理有效,但它们通常忽略了现实智能体执行所需的细粒度环境交互。相反,像(Yang et al., 2025c; Cheng et al., 2025)这样的基准测试在低保真、合成环境中运行。尽管它们包含了操作任务,但这些设置通常缺乏逼真的视觉复杂性,并且不涉及大规模导航固有的巨大3D环境状态变化。因此,这些任务很少需要长期空间记忆或在动态、逼真空间中操作所需的严格顺序推理。
用于视觉和语言导航的MLLMs MLLMs与机器人的整合为VLN带来了新的范式。早期的工作利用LLMs作为副驾驶来指导专业智能体(Qiao et al., 2023),而最近的工作则通过精巧的提示将现成的MLLMs用作零样本智能体(Zhou et al., 2024; Long et al., 2023; Chen et al., 2024; Dong et al., 2025)。同时,其他研究探索了直接在导航数据上微调MLLMs(Zhou et al., 2025a; Lin et al., 2024; Pan et al., 2023; Zheng et al., 2023)或调整预训练视频模型(Zhang et al., 2024b; a; Cheng et al., 2024)。
尽管取得了这些进展,但由于依赖模拟器,评估仍然碎片化且成本高昂。虽然像SAME(Zhou et al., 2025b)和NavBench(Qiao et al., 2025)这样的最新努力试图标准化任务评估,但它们面临明显的局限性:前者没有专门针对MLLM智能体,而后者仅限于固定的智能体设计。因此,现有框架通常侧重于聚合指标,缺乏理解特定故障模式所需的细粒度诊断。我们通过一个统一的、无模拟器框架弥补了这一差距,该框架共同评估MLLMs、智能体设计和多样化任务。
# 3 方法
# 3.1 模块化VLN评估框架
为了系统评估MLLMs在具身环境中的空间推理、长周期规划和顺序决策能力,我们设计了一个模块化软件堆栈,它清晰地分离了三个核心组件:模型(Model)、智能体(Agent)和任务(Task)(图1和图2)。这种模块化使我们能够无缝地独立互换每个组件,从而实现结构化比较和组件级消融,以隔离成功或失败的来源。我们的框架建立在三个主要抽象之上:
模型(Model) 此组件作为各种MLLMs的统一接口,处理模型特定的API调用。它允许用户集成从开源模型到专有API,而无需修改智能体逻辑或评估协议。
任务(Task) 此组件封装了特定的导航挑战并管理数据集划分。通过将任务作为模块化输入处理,我们的框架在一个统一的评估协议中支持多样化的导航任务。
智能体(Agent) 智能体作为决策模块,调解MLLM与任务之间的交互。其作用是将环境观测嵌入结构化提示中,并将模型的文本输出解析为可执行动作。为了严格测试不同的认知能力,我们实现了在记忆和推理方面各异的模块化智能体设计。我们比较了使用文本摘要动作历史(Zhou et al., 2024)的智能体与构建拓扑文本地图(Chen et al., 2024)的智能体,以测试长期空间基础。类似地,为了探究规划深度,我们评估了从直接预测到采用思维链(CoT)(Wei et al., 2022)和自反思(Yao et al., 2022)的基线。详细的智能体工作流程和提示模板在附录D中提供。

图1:基准测试的高层结构,以任务、智能体和模型之间的相互作用为中心。
可扩展性和编排(Extensibility and Orchestration) 为确保模块化,我们采用统一的工厂模式来实例化所有三种组件类型。通过为每个组件注册一个在运行时解析的唯一标识符,这种设计实现了真正的"即插即用"可扩展性:集成新的智能体或模型只需简单的注册,即可保持核心评估逻辑的完整性。
评估生命周期由中央运行器(Runner)模块协调,该模块通过轻量级配置系统确保可复现性。运行器管理无模拟器环境的初始化(第3.3节)和数据集的动态加载(第3.2节)。在执行期间,它充当中间人,促进智能体与环境之间的观察和动作交换,同时记录交互以进行细粒度的事后分析。这种架构严格分离了高层推理能力与低层执行细节,增强了框架的模块化。
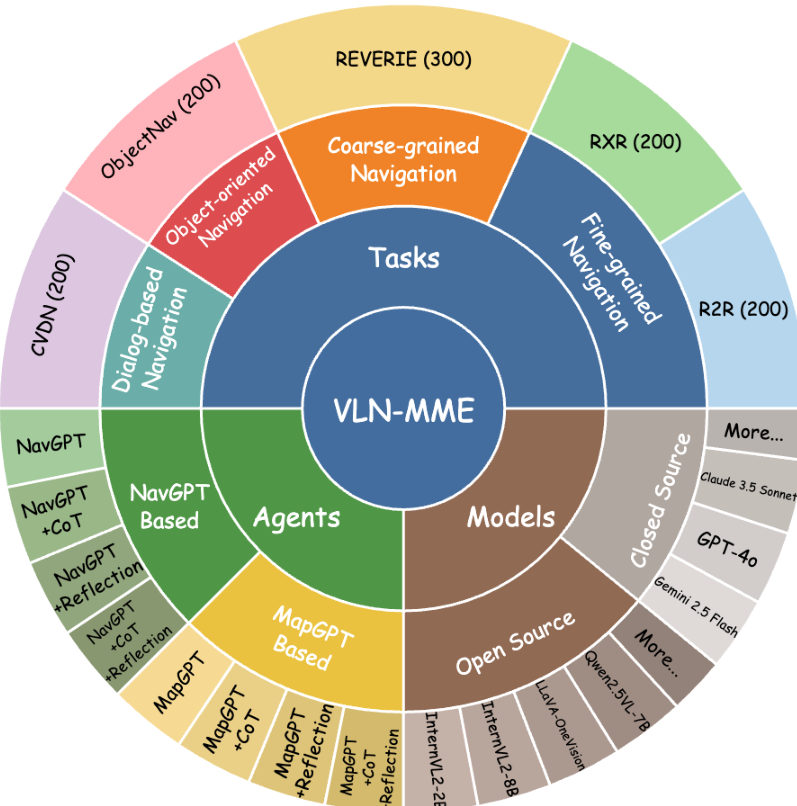
图2:VLN-MME的组成。
# 3.2 用于高效评估的数据集构建
为了解决在现有大规模VLN数据集上评估大型模型的计算挑战并促进快速实验,我们构建了一个精选基准,以实现高效且具有代表性的评估。遵循VLN的更广泛定义(Zheng et al., 2023; Zhou et al., 2025b),我们的基准由从R2R(Anderson et al., 2018)、REVERIE(Qi et al., 2020)和ObjectNav(Batra et al., 2020)三个主要数据集的验证集(val_unseen splits)中精心抽取的样本组成。这些数据集的详细描述及其选择理由在附录A中提供。
我们的构建采用分层抽样,以在三个关键维度上保持多样性:场景复杂性、路径难度和语言丰富度。例如,在R2R和REVERIE中,我们通过Matterport3D扫描ID对情节进行分层,以捕捉环境变化,然后按路径长度区间按比例抽样,以保持难度分布。通过随机选择每条轨迹的三个可用自然语言指令之一,确保了语言多样性。对于ObjectNav,我们还强制要求目标对象类别分布平衡。这个过程产生了一个紧凑的基准,它在统计上反映了原始数据集的特征。为了进一步验证我们构建的基准的保真度,我们评估了从VLN专家到微调MLLM的几种先前方法,在R2R和REVERIE的完整val_unseen划分和我们精选的基准上(所有详细信息在附录C中提供)。结果显示性能之间存在很强的相关性。我们基准上的成功率(SR)和路径长度加权成功率(SPL)等关键指标与完整划分上的性能密切相关,偏差通常在2-3个百分点以内。这种紧密对齐证实了我们的分层抽样方法成功捕获了原始数据集的内在难度和多样性,将我们的基准建立为大规模MLLM评估的可靠且高效的替代方案。
# 3.3 无模拟器环境设计
虽然高保真模拟器对于渲染至关重要,但其计算开销成为实时评估的瓶颈。为了解决这个问题,我们引入了一种无模拟器模式,通过用高效的磁盘I/O替换昂贵的GPU操作,实现了战略性的"空间换时间"权衡,将评估与渲染引擎解耦。如表1所示,这种方法大幅降低了硬件门槛:通过加载预缓存图像而非完整的3D场景几何和纹理,我们将VRAM使用量从约 10 G B ~10\mathrm{GB} 10GB 降低到约 1.7 G B ~1.7\mathrm{GB} 1.7GB (降低了 6 6 6 倍),使得在消费级硬件上进行研究成为可能。此外,用直接图像检索取代即时渲染,将观察访问速度提高了近 9 × 9 \times 9× (从 0.14 s 0.14\mathrm{s} 0.14s 到 0.016 s 0.016\mathrm{s} 0.016s),使总的片段持续时间缩短了20-30秒。这种效率通过我们的离散导航图得到加强,该导航图消除了VLN-CE中典型的连续航点预测的需要,从而简化了评估循环,而不会牺牲3D空间评估。
表1:效率比较。我们的无模拟器、预渲染方法与Habitat的资源使用和运行时比较,显示内存消耗显著降低,评估速度更快。
|----------------|----------|----------|--------------|
| Metric | Ours | Habitat | Delta |
| VRAM Usage | ~1.7 GB | ~10 GB | 5.9× Lower |
| Obs. Access | ~0.016s | ~0.14s | 8.8× Faster |
| Time / Step | t | t + 1.5s | 1.5s Faster |
| Time / Episode | T | T + 25s | ~25s Faster |
这种设计的核心是为MLLM感知优化的标准化视觉表示。我们不使用扭曲的等距柱状投影,而是将全景上下文捕获为四幅不重叠的透视图像,每幅图像具有 90 ∘ 90^\circ 90∘ 的视场角(Field of View)。这种格式保留了视觉保真度,并与标准视觉编码器的预训练分布更好地对齐。这种特定投影策略的原理在附录C中进一步详细说明。在这些视图中,可导航方向用源自底层连接图的独特数字标记进行注释,通过其全局航向对候选方向进行排序,以提供一致的空间参考。
为了弥合视觉特征和符号推理之间的差距,我们用语义元数据增强了环境。我们使用GPT-5为一般场景和特定的导航候选对象生成描述性标题。这些描述作为依赖语义记忆的智能体的辅助输入;这些标题的生成提示和验证在附录B中有记录。最后,为确保即时可访问性,我们将所有预渲染资产托管在开源平台上。我们的框架管理这些工件的自动检索,使用户无需复杂的模拟器安装即可进行评估。
# 4 实验
# 4.1 设置
评估指标。 在这项工作中,我们专注于所有任务的导航组件,不考虑REVERIE中的对象定位。我们采用一套标准的导航指标来评估智能体性能:(1) 轨迹长度(TL) ,测量平均路径长度(米);(2) 导航误差(NE) ,代理最终位置与目标位置之间的平均距离;(3) 成功率(SR) ,最终位置在目标3米范围内的情节百分比;(4) Oracle成功率(OSR) ,假设最优停止策略的成功率;(5) 路径长度加权成功率(SPL) (Jain et al., 2019),结合了成功率和路径效率;(6) 归一化动态时间规整(nDTW) (Ilharco et al., 2019),测量轨迹与真实路径的相似度;以及(7) 归一化DTW加权成功率(SDTW),一个结合了到达目标和轨迹保真度的综合指标。
实现细节。 我们在零样本设置中评估了两个专有和四个开源MLLMs:GPT5、Gemini2.5 Pro、Qwen2.5-VL7B(Bai et al., 2025)、InternVL3-2/8B(Zhu et al., 2025)、LLaVA-One-Vision-7B(Li et al., 2024a)。这些模型被集成到八种不同的智能体配置中,分为两大类:使用文本摘要和文本地图作为记忆的智能体。每个类别包含四种变体:基线、带思维链(CoT)提示的变体、带反思推理的变体以及同时具有CoT和反思的变体。所有开源MLLMs都使用vLLM后端(Kwon et al., 2023)提供服务,以确保高效的推理和内存管理。我们在基准测试中的所有任务上评估了它们的性能。此外,我们将这些零样本智能体与先前在R2R和REVERIE任务上微调过的VLN专业智能体和微调过的MLLM智能体进行了比较,评估了它们在之前评估方法的完整数据集和我们基准测试上的性能。所有实验均在一块40GB VRAM的NVIDIA A100 GPU上进行。
4.2 性能分析
我们评估了基于零样本MLLM的智能体与现有最先进方法相比的性能,分析了不同模型架构、推理策略和导航任务的表现。
模型能力。 我们的结果,如表2所示,表明GPT-5和Gemini-2.5 Pro等专有模型目前设定了零样本导航的性能上限。然而,在开源模型中,Qwen2.5-VL-7B表现出卓越的鲁棒性,持续优于LLaVA-OneVision和InternVL3-2B等同类模型。例如,在Fine-Grained任务的基线NavGPT配置中,Qwen2.5-VL-7B的成功率(SR)达到 27.5 % 27.5\% 27.5%,显著超过LLaVA-OneVision ( 11.5 % 11.5\% 11.5%)和InternVL3-2B ( 13.5 % 13.5\% 13.5%)。这使得Qwen2.5-VL成为开源具身社区一个强大而有能力的基线。
智能体架构和推理策略。 与直觉相反,集成CoT或Reflection等高级提示策略并未持续带来性能提升,反而常常有害。如表2所示,在Fine-Grained任务中对Qwen2.5-VL-7B应用CoT,其SR从 27.5 % 27.5\% 27.5%下降到 21 % 21\% 21%。同样,文本摘要(Text Summarization)和文本地图(Text Map)记忆架构之间的区别也比预期的小。性能差异通常很小,尽管一些较小的特定模型(如InternVL3-2B)确实获得了显著的提升。
|----------------|-------|------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|------|-------|-------|-------|-------|-------|-------|
| Agent / MLLM | Fine-Grained Navigation |||| Coarse-grained Navigation |||| Object-Oriented Navigation ||||
| Agent / MLLM | TL | NE | SR | OSR | SPL | nDTW | SDTW | CLS | TL | NE | SR | OSR | SPL | nDTW | SDTW | CLS | TL | NE | SR | OSR | SPL | nDTW | SDTW | CLS |
| Text Summarization Memory Agents |||||||||||||||
| NavGPT |||||||||||||||
| GPT-5 | 9.12 | 6.28 | 38.50 | 57.50 | 29.23 | 37.96 | 22.02 | 34.11 | 9.37 | 8.03 | 30.00 | 49.50 | 20.76 | 27.11 | 14.88 | 21.05 | 9.63 | 4.41 | 48.00 | 79.00 | 23.84 | 26.52 | 16.33 | 20.13 |
| Gemini-2.5 Pro | 8.94 | 6.17 | 41.00 | 60.50 | 32.67 | 38.07 | 22.43 | 34.62 | 9.21 | 7.89 | 33.50 | 52.00 | 24.38 | 27.47 | 15.13 | 21.38 | 9.48 | 4.34 | 51.50 | 79.00 | 27.19 | 26.78 | 16.54 | 20.43 |
| InternVL3-2B | 9.89 | 8.56 | 13.50 | 27.00 | 5.46 | 21.25 | 5.75 | 21.59 | 10.13 | 10.18 | 7.33 | 16.33 | 2.50 | 15.30 | 2.97 | 17.17 | 10.35 | 6.27 | 21.50 | 40.50 | 3.57 | 13.67 | 2.55 | 15.57 |
| InternVL3-8B | 11.74 | 7.55 | 28.00 | 50.50 | 12.61 | 25.28 | 13.38 | 26.22 | 11.90 | 9.25 | 20.00 | 30.67 | 7.18 | 17.32 | 8.18 | 18.84 | 11.55 | 4.63 | 39.00 | 56.00 | 7.69 | 14.51 | 5.09 | 17.36 |
| LLaVA-OV-7B | 8.04 | 8.40 | 11.50 | 20.50 | 4.94 | 26.34 | 5.70 | 25.53 | 9.85 | 9.35 | 14.67 | 20.00 | 5.19 | 19.27 | 6.09 | 18.39 | 9.52 | 5.93 | 27.50 | 41.00 | 4.51 | 16.54 | 5.11 | 14.71 |
| Qwen2.5-VL-7B | 8.54 | 6.99 | 27.50 | 44.00 | 17.11 | 35.97 | 18.88 | 34.85 | 8.94 | 8.55 | 18.67 | 27.33 | 9.00 | 23.79 | 9.88 | 23.55 | 9.07 | 4.65 | 37.50 | 56.50 | 13.18 | 21.83 | 10.63 | 23.52 |
| NavGPT w/ CoT ||||||||||||||| | | | | | | | | |
| GPT-5 | 9.47 | 6.42 | 36.00 | 54.50 | 27.31 | 39.17 | 18.89 | 32.54 | 9.71 | 8.24 | 28.50 | 46.00 | 20.42 | 32.53 | 12.04 | 26.82 | 9.92 | 4.58 | 46.50 | 70.00 | 23.67 | 31.06 | 14.03 | 25.07 |
| Gemini-2.5 Pro | 9.31 | 6.29 | 32.50 | 50.00 | 23.88 | 39.64 | 19.12 | 32.86 | 9.56 | 8.11 | 24.00 | 41.50 | 16.93 | 32.83 | 12.22 | 27.14 | 9.76 | 4.49 | 42.00 | 65.50 | 19.27 | 31.38 | 14.24 | 25.31 |
| InternVL3-2B | 6.21 | 8.84 | 8.00 | 14.50 | 4.47 | 26.15 | 4.28 | 27.45 | 4.98 | 9.87 | 5.33 | 9.00 | 3.24 | 23.39 | 3.11 | 25.09 | 6.78 | 5.56 | 25.00 | 41.00 | 6.66 | 25.51 | 5.34 | 23.98 |
| InternVL3-8B | 9.07 | 7.56 | 19.00 | 35.50 | 10.95 | 29.22 | 10.90 | 29.59 | 7.96 | 9.39 | 15.33 | 22.00 | 9.31 | 24.93 | 9.14 | 26.40 | 6.43 | 5.31 | 34.50 | 43.50 | 12.67 | 27.22 | 10.30 | 27.35 |
| LLaVA-OV-7B | 7.97 | 8.85 | 12.50 | 22.50 | 5.41 | 23.20 | 5.60 | 24.43 | 8.43 | 9.47 | 14.00 | 20.33 | 5.90 | 21.09 | 7.13 | 21.38 | 9.69 | 5.66 | 33.50 | 47.50 | 7.31 | 15.90 | 6.24 | 17.92 |
| Qwen2.5-VL-7B | 9.04 | 7.97 | 21.00 | 37.50 | 11.41 | 30.23 | 11.56 | 31.36 | 8.29 | 9.85 | 15.67 | 24.33 | 8.10 | 24.02 | 8.82 | 25.59 | 6.86 | 5.13 | 33.00 | 44.50 | 13.25 | 28.63 | 12.54 | 28.32 |
| NavGPT w/ Reflection ||||||||||||||| | | | | | | | | |
| GPT-5 | 9.61 | 6.37 | 33.00 | 50.50 | 24.18 | 40.04 | 19.53 | 33.14 | 9.82 | 8.13 | 25.00 | 43.00 | 17.34 | 33.03 | 12.51 | 27.08 | 10.03 | 4.47 | 43.00 | 68.00 | 20.62 | 30.02 | 15.06 | 24.09 |
| Gemini-2.5 Pro | 9.44 | 6.23 | 37.50 | 55.00 | 28.73 | 40.39 | 19.71 | 33.47 | 9.67 | 7.98 | 29.00 | 47.50 | 21.68 | 33.34 | 12.72 | 27.33 | 9.88 | 4.38 | 47.50 | 72.50 | 25.14 | 30.27 | 15.21 | 24.34 |
| InternVL3-2B | 6.50 | 8.94 | 8.00 | 16.00 | 5.20 | 29.91 | 5.00 | 30.13 | 7.20 | 9.41 | 8.50 | 15.00 | 4.80 | 25.49 | 4.60 | 24.93 | 6.43 | 5.56 | 28.00 | 43.00 | 7.83 | 26.53 | 6.14 | 25.28 |
| InternVL3-8B | 4.54 | 7.99 | 12.00 | 19.00 | 9.53 | 34.25 | 8.89 | 34.44 | 6.82 | 10.20 | 11.00 | 17.33 | 5.97 | 23.58 | 6.04 | 27.79 | 8.35 | 5.02 | 32.50 | 51.00 | 9.12 | 18.79 | 6.68 | 22.14 |
| LLaVA-OV-7B | 2.81 | 8.01 | 10.50 | 11.00 | 9.44 | 38.17 | 8.43 | 38.39 | 5.15 | 9.34 | 9.33 | 14.67 | 5.82 | 28.04 | 5.91 | 30.22 | 9.35 | 5.58 | 34.00 | 47.50 | 7.90 | 15.48 | 6.11 | 17.05 |
| Qwen2.5-VL-7B | 6.93 | 7.17 | 24.00 | 32.50 | 14.95 | 36.51 | 16.44 | 33.59 | 6.96 | 8.76 | 12.00 | 18.00 | 7.97 | 26.88 | 7.97 | 25.78 | 7.55 | 5.06 | 35.50 | 50.50 | 14.67 | 23.33 | 11.04 | 25.23 |
| NavGPT w/ CoT & Reflection ||||||||||||||| | | | | | | | | |
| GPT-5 | 9.52 | 6.31 | 38.50 | 56.50 | 29.81 | 39.56 | 20.08 | 33.02 | 9.77 | 8.18 | 30.00 | 48.50 | 22.17 | 32.04 | 13.07 | 26.03 | 9.97 | 4.36 | 48.50 | 73.50 | 25.92 | 29.08 | 15.51 | 23.06 |
| Gemini-2.5 Pro | 9.36 | 6.19 | 34.00 | 52.00 | 25.74 | 39.83 | 20.24 | 33.27 | 9.61 | 8.04 | 25.50 | 43.50 | 18.36 | 32.32 | 13.21 | 26.24 | 9.81 | 4.27 | 43.50 | 68.00 | 21.28 | 29.33 | 15.66 | 23.22 |
| InternVL3-2B | 7.15 | 9.24 | 4.50 | 15.00 | 1.70 | 22.45 | 2.05 | 23.47 | 7.30 | 9.78 | 9.33 | 15.00 | 4.63 | 22.33 | 5.30 | 24.07 | 6.94 | 6.25 | 24.50 | 37.50 | 7.26 | 21.29 | 6.11 | 21.47 |
| InternVL3-8B | 7.22 | 7.47 | 22.00 | 32.50 | 15.33 | 36.62 | 16.18 | 35.98 | 8.95 | 9.07 | 17.33 | 28.67 | 10.07 | 24.11 | 10.24 | 25.78 | 9.18 | 5.30 | 32.50 | 51.50 | 8.14 | 18.59 | 5.99 | 21.45 |
| LLaVA-OV-7B | 7.61 | 8.48 | 10.00 | 22.00 | 5.81 | 28.01 | 6.31 | 26.32 | 8.44 | 8.68 | 14.00 | 22.00 | 6.78 | 24.73 | 8.37 | 22.60 | 8.55 | 5.66 | 28.50 | 44.00 | 7.25 | 21.26 | 6.74 | 19.69 |
| Qwen2.5-VL-7B | 7.82 | 7.53 | 25.50 | 38.50 | 17.68 | 34.86 | 17.65 | 34.80 | 7.19 | 9.48 | 11.67 | 18.00 | 7.89 | 27.07 | 7.81 | 28.22 | 7.60 | 5.39 | 36.00 | 47.00 | 13.67 | 26.52 | 11.49 | 26.98 |
| Text Map Memory Agents ||||||||||||||| | | | | | | | | |
| MapGPT ||||||||||||||| | | | | | | | | |
| GPT-5 | 9.32 | 6.21 | 34.00 | 52.50 | 25.83 | 39.03 | 21.08 | 33.05 | 9.53 | 7.94 | 26.00 | 45.00 | 18.29 | 29.07 | 13.02 | 23.04 | 9.73 | 4.33 | 44.00 | 74.00 | 20.91 | 28.06 | 16.08 | 22.01 |
| Gemini-2.5 Pro | 9.17 | 6.09 | 39.50 | 57.50 | 30.72 | 39.34 | 21.22 | 33.23 | 9.38 | 7.81 | 31.50 | 50.00 | 23.16 | 29.26 | 13.17 | 23.21 | 9.58 | 4.26 | 49.50 | 79.50 | 26.24 | 28.24 | 16.19 | 22.13 |
| InternVL3-2B | 9.84 | 8.61 | 11.00 | 22.50 | 3.71 | 20.18 | 3.85 | 21.89 | 10.19 | 9.59 | 12.00 | 19.00 | 4.41 | 18.10 | 5.24 | 19.97 | 10.35 | 5.93 | 27.50 | 46.50 | 4.41 | 13.59 | 3.69 | 15.57 |
| InternVL3-8B | 6.78 | 7.70 | 18.00 | 32.00 | 12.46 | 34.34 | 13.06 | 33.78 | 7.26 | 9.16 | 13.67 | 22.33 | 7.87 | 26.63 | 8.04 | 27.62 | 5.95 | 5.26 | 31.50 | 44.50 | 11.61 | 28.03 | 8.98 | 27.39 |
| LLaVA-OV-7B | 4.97 | 8.44 | 8.50 | 15.50 | 5.59 | 31.70 | 5.29 | 32.62 | 8.58 | 8.96 | 14.67 | 22.00 | 6.48 | 23.33 | 7.33 | 22.39 | 7.92 | 5.86 | 22.50 | 35.50 | 4.28 | 20.66 | 4.63 | 18.34 |
| Qwen2.5-VL-7B | 8.16 | 7.13 | 26.00 | 38.00 | 17.31 | 34.31 | 17.39 | 33.37 | 10.52 | 8.53 | 21.67 | 32.33 | 8.96 | 21.27 | 10.85 | 20.78 | 9.77 | 4.82 | 36.50 | 52.50 | 11.05 | 20.06 | 9.06 | 22.13 |
| MapGPT w/ CoT ||||||||||||||| | | | | | | | | |
| GPT-5 | 9.62 | 6.51 | 32.50 | 50.00 | 27.14 | 40.09 | 17.04 | 32.08 | 9.83 | 8.31 | 24.50 | 42.50 | 19.68 | 34.05 | 10.06 | 28.03 | 9.93 | 4.67 | 44.50 | 68.50 | 23.21 | 32.08 | 13.01 | 26.02 |
| Gemini-2.5 Pro | 9.46 | 6.38 | 31.00 | 48.50 | 23.37 | 40.36 | 17.17 | 32.24 | 9.68 | 8.19 | 23.00 | 40.00 | 15.84 | 34.23 | 10.14 | 28.22 | 9.78 | 4.59 | 39.50 | 62.50 | 18.76 | 32.27 | 13.16 | 26.21 |
| InternVL3-2B | 5.09 | 8.99 | 6.50 | 14.00 | 4.12 | 26.43 | 3.94 | 27.62 | 5.22 | 9.88 | 4.00 | 8.00 | 1.58 | 23.01 | 1.77 | 24.48 | 6.66 | 6.31 | 20.00 | 35.50 | 4.76 | 21.14 | 4.69 | 21.05 |
| InternVL3-8B | 5.96 | 8.79 | 12.00 | 22.50 | 9.66 | 31.15 | 8.64 | 33.11 | 5.82 | 9.07 | 13.33 | 17.33 | 8.77 | 30.01 | 9.09 | 30.77 | 6.55 | 5.34 | 34.00 | 46.50 | 12.33 | 26.74 | 9.38 | 27.22 |
| LLaVA-OV-7B | 8.34 | 8.96 | 8.50 | 13.50 | 2.83 | 19.61 | 2.84 | 19.10 | 7.82 | 9.63 | 8.67 | 13.00 | 3.38 | 20.22 | 4.10 | 21.21 | 7.64 | 6.43 | 16.00 | 31.00 | 4.14 | 19.11 | 3.21 | 18.63 |
| Qwen2.5-VL-7B | 7.45 | 7.78 | 17.00 | 28.50 | 10.47 | 30.38 | 10.86 | 29.67 | 6.48 | 8.49 | 16.33 | 21.00 | 10.61 | 30.81 | 11.11 | 31.34 | 9.51 | 4.78 | 32.00 | 54.00 | 9.95 | 22.14 | 8.65 | 23.29 |
| MapGPT w/ Reflection ||||||||||||||| | | | | | | | | |
| GPT-5 | 9.72 | 6.41 | 36.50 | 54.00 | 28.19 | 41.02 | 18.09 | 33.03 | 9.91 | 8.26 | 25.50 | 42.50 | 20.73 | 35.06 | 11.04 | 29.07 | 10.02 | 4.62 | 45.50 | 69.50 | 23.65 | 31.09 | 14.05 | 25.08 |
| Gemini-2.5 Pro | 9.57 | 6.28 | 32.00 | 49.50 | 24.31 | 41.28 | 18.16 | 33.21 | 9.77 | 8.14 | 24.00 | 41.50 | 16.88 | 35.27 | 11.13 | 29.25 | 9.87 | 4.54 | 41.00 | 64.00 | 19.94 | 31.24 | 14.17 | 25.23 |
| InternVL3-2B | 2.37 | 8.55 | 4.00 | 6.00 | 3.26 | 32.83 | 2.97 | 33.54 | 2.45 | 9.58 | 3.67 | 5.00 | 3.31 | 27.97 | 2.81 | 31.14 | 9.72 | 5.85 | 25.00 | 44.00 | 4.50 | 15.52 | 3.04 | 17.39 |
| InternVL3-8B | 5.85 | 7.80 | 16.50 | 28.50 | 10.89 | 36.05 | 11.48 | 35.18 | 6.49 | 8.80 | 12.67 | 19.33 | 6.64 | 27.19 | 6.91 | 28.24 | 6.23 | 5.50 | 30.00 | 40.50 | 10.36 | 26.92 | 8.12 | 25.74 |
| LLaVA-OV-7B | 8.35 | 8.50 | 10.00 | 20.00 | 5.50 | 26.62 | 5.50 | 23.33 | 8.20 | 9.47 | 11.00 | 19.00 | 6.00 | 25.84 | 6.00 | 25.16 | 9.46 | 6.11 | 15.50 | 33.50 | 2.02 | 15.90 | 2.53 | 15.57 |
| Qwen2.5-VL-7B | 10.41 | 7.12 | 26.50 | 41.00 | 10.12 | 27.97 | 12.88 | 25.38 | 9.60 | 8.67 | 15.67 | 23.67 | 6.00 | 23.29 | 7.62 | 20.63 | 10.15 | 4.90 | 33.50 | 46.00 | 7.41 | 17.18 | 6.33 | 17.34 |
| MapGPT w/ CoT & Reflection ||||||||||||||| | | | | | | | | | |
| GPT-5 | 9.82 | 6.59 | 34.50 | 52.00 | 26.13 | 42.07 | 16.04 | 34.09 | 10.03 | 8.39 | 24.50 | 40.50 | 18.67 | 36.05 | 9.03 | 30.02 | 10.11 | 4.76 | 42.50 | 66.50 | 21.79 | 33.08 | 12.07 | 27.03 |
| Gemini-2.5 Pro | 9.66 | 6.46 | 30.00 | 47.50 | 22.28 | 42.26 | 16.11 | 34.24 | 9.88 | 8.27 | 22.00 | 39.50 | 15.41 | 36.28 | 9.16 | 30.17 | 9.96 | 4.68 | 38.00 | 61.00 | 17.86 | 33.27 | 12.12 | 27.16 |
| InternVL3-2B | 7.52 | 8.82 | 9.00 | 20.00 | 4.88 | 23.45 | 4.98 | 24.08 | 7.35 | 9.95 | 4.67 | 12.67 | 1.61 | 19.60 | 2.02 | 21.94 | 7.26 | 6.15 | 18.00 | 35.50 | 4.74 | 22.73 | 3.77 | 22.14 |
| InternVL3-8B | 8.54 | 8.42 | 18.00 | 34.50 | 10.84 | 28.16 | 10.84 | 29.42 | 9.64 | 9.76 | 13.00 | 24.00 | 6.06 | 20.36 | 6.75 | 22.16 | 8.95 | 5.38 | 33.50 | 53.50 | 8.01 | 16.44 | 5.85 | 19.04 |
| LLaVA-OV-7B | 8.35 | 8.50 | 13.00 | 23.00 | 5.81 | 25.55 | 6.04 | 25.47 | 8.14 | 9.56 | 9.00 | 17.67 | 4.53 | 21.74 | 4.86 | 21.98 | 8.53 | 5.74 | 24.50 | 37.00 | 5.45 | 21.01 | 4.35 | 20.49 |
| Qwen2.5-VL-7B | 6.29 | 9.07 | 14.00 | 20.50 | 7.12 | 25.82 | 7.03 | 25.41 | 7.09 | 8.94 | 10.67 | 18.67 | 6.68 | 25.66 | 7.27 | 25.81 | 7.45 | 5.90 | 25.50 | 36.50 | 6.78 | 22.67 | 5.23 | 21.56 |
表2:基于MLLM的智能体在VLN-MME上的性能比较。智能体按其主要架构类型分组。每组最佳性能以粗体标示。
任务难度层级。 最后,结果揭示了不同导航类别之间清晰的难度层级。面向对象导航(Object-Oriented Navigation)被证明是最容易处理的,智能体持续获得更高的成功率。精细粒度导航(Fine-Grained Navigation)难度适中,而粗粒度导航(Coarse-Grained Navigation)则成为MLLM最具挑战性的任务。这表明,将高级指令转化为导航到不太精确定义位置的能力,仍然是当前零样本推理的一个重大障碍。
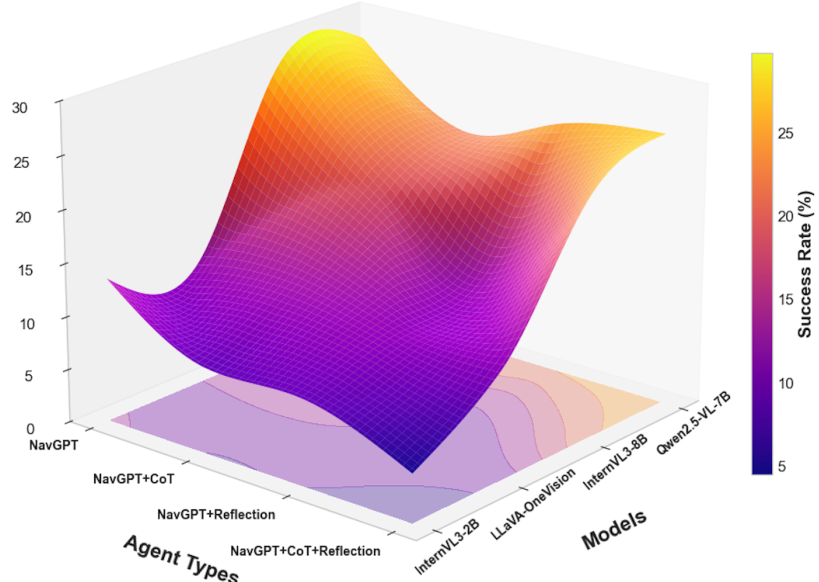
图3:在使用文本摘要记忆的智能体中,不同推理策略在多个骨干MLLM上的性能比较。
4.3 讨论
如4.2节所讨论,我们揭示了MLLM在具身导航中表现出的一些反直觉行为。我们进一步进行了错误分析,以了解其错误模式,发现它们在几个认知维度上受到根本性限制(更多详情见附录E)。有趣的是,我们发现高导航失败率主要由循环行为主导,如图4所示。这并非表面问题,而是指令保真度、空间推理、历史上下文利用以及多模态感知到行动的落地等深层挑战的体现。我们将在下面讨论这三个相互关联的方面。

图4:使用文本地图记忆的智能体,Qwen2.5-VL-7B模型的成功和失败模式的高级分析。
空间和环境理解。 我们的精细错误分析表明,空间理解的深刻弱点是大多数导航失败的根本原因。在分析的131个错误中,高达106个是由于持续循环造成的,这是模型无法将指令与3D环境联系起来的直接后果。这表现在具体的、重复出现的问题上,如区域识别能力差、未能对楼梯上的垂直性进行推理以及基本的方向混淆。提供明确的拓扑地图未能带来显著的收益,这突显了一个更深层的问题:智能体无法将其抽象空间知识与其视觉感知和行动联系起来。此外,智能体在顺序决策方面严重失败,而这对于导航至关重要。普遍存在的循环行为清楚地表明,智能体没有从其轨迹中学习以避免重复错误。这不是记忆容量问题,因为历史记录很少超出模型的上下文窗口,而是记忆利用问题。模型可以访问其过去的行动,但无法将当前决策与该历史联系起来进行自我纠正。事实上,观察到简单的历史格式可以胜过复杂的格式,这表明过多的历史信息会造成认知负荷,使智能体感到困惑而不是引导。
感知-行动落地。 最后,我们观察到多模态感知与具身行动之间存在关键差距。MLLM的视觉落地在识别层面上是功能性的;例如,它通常可以在其文本推理轨迹中正确识别"楼梯"或目标"椅子"。这表明视觉和语言模态是相互关联的。然而,这种识别始终未能转化为正确的行动。智能体看到了楼梯,但却绕过它们循环。它甚至可能非常接近目标,表明它已经成功地在视觉上确定了目标对象,但却未能执行最终的"停止"动作。我们对成功案例的分析有力地说明了这一点,其中大多数成功案例都涉及到在目标附近进行效率低下的循环后才停止。这种"感知-行动差距"表明,MLLM在VLN中面临的最大挑战不仅仅是看到和描述世界,而是在其中有效地行动。
4.4 诊断案例研究
为了展示我们基准测试作为揭示MLLM能力的科学工具的效用,我们对"硬负样本(Hard Negatives)"的一个特定子集进行了深入调查。这个子集包含来自精细粒度任务的25条轨迹,所有开源模型在使用标准文本摘要记忆智能体时都持续失败。我们以Qwen2.5VL-7B作为主要导航器,重新审视了这些失败案例,并设计了两种实验设置来隔离失败的来源:
(1) 神谕引导导航(Oracle-Guided Navigation)。 为了测试失败是否是由于缺乏视觉理解或缺乏高级推理,我们引入了一个更强大的模型(Qwen3VL-4B (Yang et al., 2025a))作为神谕助手。当导航器遇到困难时(例如,循环、方向严重错误或进入错误区域),它被允许查询神谕。神谕提供了高级推理指导并建议了潜在的计划和行动。如表3所示,通过这种推理支持,导航器取得了显著的成功率,这表明基础模型拥有基本的导航能力,但缺乏解决这些困难案例所需的高级规划或错误纠正逻辑。
表3:神谕辅助对硬负样本的影响。
|------------------------------|-------|-------|-------|
| Method | SR ↑ | OSR ↑ | SPL ↑ |
| Baseline (Qwen2.5VL-7B) | 0.00 | 0.00 | 0.00 |
| + Oracle Assistant (Qwen3VL) | 52.00 | 68.00 | 34.00 |
(2) 失败感知语境学习(Failure-Aware In-Context Learning)。 为了测试模型在了解常见陷阱的情况下是否能够自我纠正,我们用少样本设置取代了零样本评估。我们向模型提供了在我们错误分析中识别出的 N N N个潜在失败案例( N = { 1 , 2 , 3 } N = \{1,2,3\} N={1,2,3})。如表4所示,在提示中提供这些"负面"示例带来了性能提升。然而,与神谕干预相比,这些提升是微小的,这表明虽然对失败模式的了解有所帮助,但主动推理支持对于解决复杂的导航挑战更为关键。
表4:失败感知少样本提示对硬负样本的影响。
|-------------------------|-------|-------|-------|
| Method | SR ↑ | OSR ↑ | SPL ↑ |
| Zero-shot (Baseline) | 0.00 | 0.00 | 0.00 |
| 1-shot Failure Example | 12.00 | 24.00 | 9.00 |
| 2-shot Failure Examples | 16.00 | 28.00 | 11.00 |
| 3-shot Failure Examples | 16.00 | 32.00 | 14.00 |
5 结论
在这项工作中,我们以视觉-语言导航(VLN)作为一个具有挑战性的下游任务,评估MLLM作为零样本智能体的核心代理能力。我们引入了VLN-MME,一个统一、模块化、无模拟器的评估框架,旨在探究MLLM的空间推理、行动后果理解和长程序列决策能力,而非建立一个新的VLN基准。我们的结果表明,当前的MLLM在将感知转化为行动方面存在严重局限性,导致零样本性能不佳。通过细粒度的、步骤级的错误分析,VLN-MME揭示了系统的失败模式,并为以思维链(CoT)为导向的数据生成和具身视觉-语言模型的后训练提供了具体指导。
Original Abstract: Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across a wide range of vision-language tasks. However, their performance as embodied agents, which requires multi-round dialogue spatial reasoning and sequential action prediction, needs further exploration. Our work investigates this potential in the context of Vision-and-Language Navigation (VLN) by introducing a unified and extensible evaluation framework to probe MLLMs as zero-shot agents by bridging traditional navigation datasets into a standardized benchmark, named VLN-MME. We simplify the evaluation with a highly modular and accessible design. This flexibility streamlines experiments, enabling structured comparisons and component-level ablations across diverse MLLM architectures, agent designs, and navigation tasks. Crucially, enabled by our framework, we observe that enhancing our baseline agent with Chain-of-Thought (CoT) reasoning and self-reflection leads to an unexpected performance decrease. This suggests MLLMs exhibit poor context awareness in embodied navigation tasks; although they can follow instructions and structure their output, their 3D spatial reasoning fidelity is low. VLN-MME lays the groundwork for systematic evaluation of general-purpose MLLMs in embodied navigation settings and reveals limitations in their sequential decision-making capabilities. We believe these findings offer crucial guidance for MLLM post-training as embodied agents.
PDF Link: 2512.24851v1
部分平台可能图片显示异常,请以我的博客内容为准
