💎 本文价值提示
你将获得什么?
- 从零构建:不再是写脚本,而是构建一个可扩展的微服务架构。
- 企业级思维:掌握限流、熔断、流式传输等生产环境必备技能。
- 代码即资产:一套可直接复用的 LLM Gateway 核心代码骨架。
- 转型视角:看懂大数据高吞吐思维如何映射到 AI 高并发架构。
👋 大家好,我是你们的老朋友,那个正在从大数据转型 AI 架构的"老司机"。
在前三篇文章中,我们已经完成了 Python 的"脱胎换骨":
- 第一篇 :我们用 Type Hints 和 Pydantic 戒掉了"弱类型"的随意,像写 Java 一样严谨;
- 第二篇 :我们用 Asyncio 征服了高并发 I/O,不再让 CPU 傻等;
- 第三篇 :我们用 Generator 和 Decorator 搞定了流式输出和 AOP 切面编程。
今天,是时候把这些散落的珍珠串成项链了!我们将进入 Phase 4:工程化落地与架构设计。
我们要一起做一个 Capstone Project(毕业设计) ------ 企业级 LLM Gateway(大模型网关)。
🏗️ 为什么要造一个 LLM Gateway?
在企业里,直接让业务代码调用 OpenAI 或 DeepSeek 的 API 是非常危险的。这就好比让公司的每辆车都自己去海关报关,效率低且无法管控。
我们需要一个 "海关总署" (Gateway) :
- 统一计费:谁用了多少 Token,得算清楚。
- 流量控制:防止某个业务线把 API Rate Limit 刷爆。
- 协议转换:前端要 SSE 流式,后端要统一接口。
- 安全审计:敏感词过滤,防止数据泄露。
技术栈选型:
- 框架 :
FastAPI(Python 界的最强黑马,性能直逼 Go)。 - 校验 :
Pydantic V2(数据契约的守护神)。 - 并发 :
Asyncio(高并发的核心引擎)。
🧩 架构蓝图:数据是如何流动的?
在我们开始写代码之前,先像设计 Flink 拓扑图一样,画出我们的架构流向。
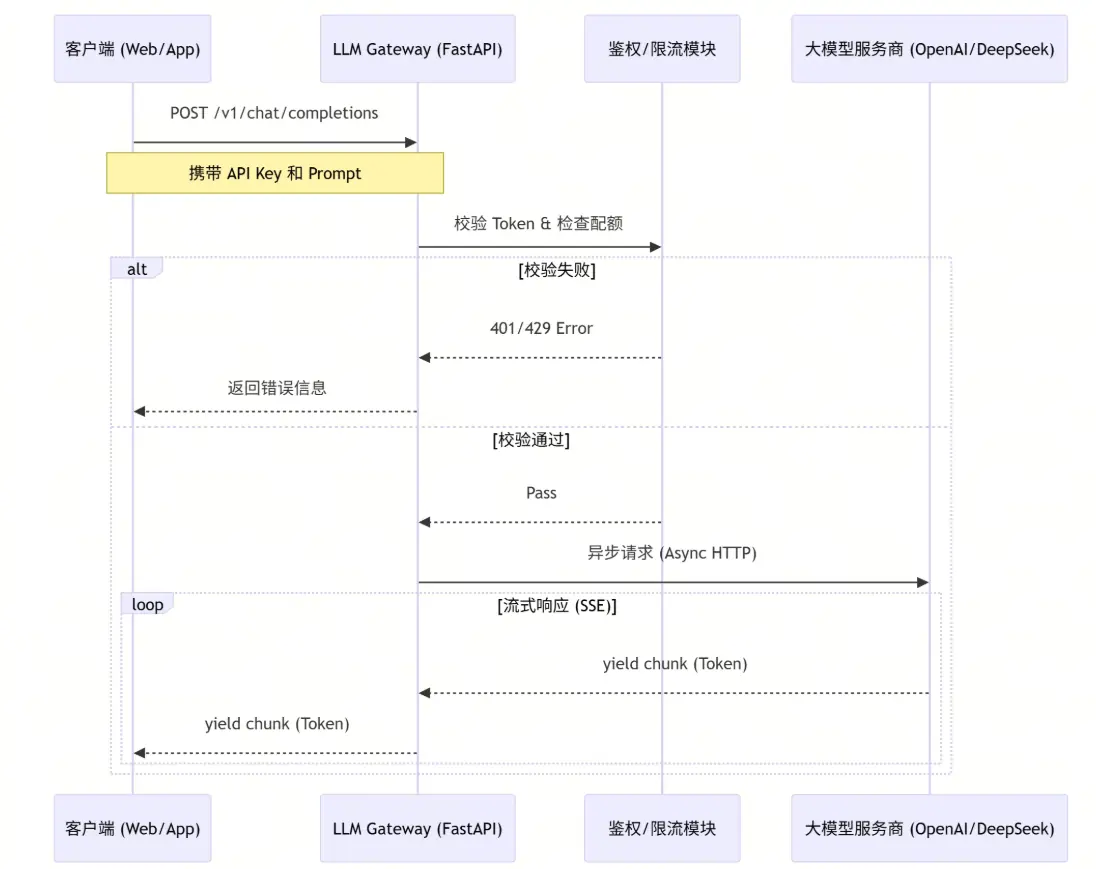
🛠️ 第一步:立规矩 ------ 定义数据契约 (Pydantic)
做大数据出身的我们,最怕数据格式乱七八糟。在 AI 架构中,Prompt 就是 SQL,Schema 就是 Table Schema。
我们需要定义"输入"和"输出"的严格标准。
python
from pydantic import BaseModel, Field, field_validator
from typing import List, Optional, Literal
# 1. 定义消息体
class Message(BaseModel):
role: Literal["system", "user", "assistant"]
content: str
# 2. 定义请求契约 (Request Contract)
class ChatCompletionRequest(BaseModel):
model: str = Field(..., description="模型名称,如 gpt-4, deepseek-chat")
messages: List[Message]
temperature: float = Field(0.7, ge=0.0, le=2.0)
stream: bool = False
# 💡 亮点:自定义校验,防止恶意注入过长文本
@field_validator('messages')
def validate_message_length(cls, v):
total_len = sum(len(m.content) for m in v)
if total_len > 10000:
raise ValueError("Prompt 内容过长,请精简后重试")
return v
# 3. 定义响应契约 (Response Contract)
# 这里我们模拟 OpenAI 的标准返回格式
class ChatCompletionResponse(BaseModel):
id: str
object: str = "chat.completion"
created: int
choices: List[dict]👨💻 架构师旁白 : 这不仅仅是代码,这是协议。有了它,前端开发和后端开发就有了"法律依据",不再需要口头对齐字段。
🚀 第二步:高并发引擎 ------ 异步请求 (Asyncio)
LLM 的响应通常很慢(几秒到几十秒)。如果用传统的同步代码(像 JDBC 那样),一个请求卡住,整个服务就挂了。
我们要用 Asyncio + httpx,实现非阻塞调用。这就像 Node.js 的事件循环,或者 Netty 的 IO 线程。
python
import httpx
import os
from fastapi import HTTPException
# 模拟从环境变量获取 Key
LLM_API_KEY = os.getenv("LLM_API_KEY")
LLM_BASE_URL = "https://api.deepseek.com/v1"
async def call_llm_api(request: ChatCompletionRequest):
"""
异步调用上游大模型接口
"""
headers = {
"Authorization": f"Bearer {LLM_API_KEY}",
"Content-Type": "application/json"
}
# 💡 亮点:使用异步上下文管理器,自动释放连接
async with httpx.AsyncClient(timeout=60.0) as client:
try:
response = await client.post(
f"{LLM_BASE_URL}/chat/completions",
json=request.model_dump(), # Pydantic V2 序列化
headers=headers
)
response.raise_for_status()
return response.json()
except httpx.HTTPStatusError as e:
# 记录日志...
raise HTTPException(status_code=e.response.status_code, detail="上游服务报错")🌊 第三步:极致体验 ------ 流式透传 (Generator)
用户不想盯着空白屏幕等 10 秒。他们想要 ChatGPT 那种"打字机"效果。 这就需要用到 Python 的 Generator (生成器) ,配合 FastAPI 的 StreamingResponse。
这在大数据领域,就是 Spark Streaming 或 Flink DataStream ------ 数据来一条,处理一条,发走一条。
python
import json
from typing import AsyncGenerator
async def stream_llm_api(request: ChatCompletionRequest) -> AsyncGenerator[str, None]:
"""
流式生成器:像水管一样接通上游和下游
"""
headers = {
"Authorization": f"Bearer {LLM_API_KEY}",
"Content-Type": "application/json"
}
async with httpx.AsyncClient() as client:
# 开启流式请求
async with client.stream(
"POST",
f"{LLM_BASE_URL}/chat/completions",
json=request.model_dump(),
headers=headers
) as response:
# 💡 亮点:逐行读取上游数据,并实时 yield 给前端
async for line in response.aiter_lines():
if line:
# 这里可以做数据清洗、计费统计等中间处理
yield f"{line}\n\n" # 符合 SSE 格式🛡️ 第四步:稳定性保障 ------ 熔断器 (Decorator)
如果上游 DeepSeek 挂了,或者网络抖动,我们不能让请求堆积把自己的网关压垮。我们需要一个 熔断器 (Circuit Breaker) 。
利用 Python 的 Decorator (装饰器) ,我们可以优雅地实现 AOP(面向切面编程)。
python
import time
from functools import wraps
# 简单的熔断器状态
CIRCUIT_OPEN = False
ERROR_COUNT = 0
LAST_ERROR_TIME = 0
def circuit_breaker(threshold=5, recovery_time=60):
"""
装饰器:当错误次数超过 threshold 时,暂停服务 recovery_time 秒
"""
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
global CIRCUIT_OPEN, ERROR_COUNT, LAST_ERROR_TIME
# 1. 检查是否熔断
if CIRCUIT_OPEN:
if time.time() - LAST_ERROR_TIME > recovery_time:
# 尝试恢复
CIRCUIT_OPEN = False
ERROR_COUNT = 0
else:
raise HTTPException(status_code=503, detail="服务熔断中,请稍后重试")
# 2. 尝试执行
try:
return await func(*args, **kwargs)
except Exception as e:
ERROR_COUNT += 1
LAST_ERROR_TIME = time.time()
if ERROR_COUNT >= threshold:
CIRCUIT_OPEN = True
print("⚠️ 触发熔断保护!")
raise e
return wrapper
return decorator🏰 第五步:集大成 ------ FastAPI 入口
最后,我们将所有组件组装到 main.py 中。
python
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
app = FastAPI(title="Enterprise LLM Gateway")
@app.post("/v1/chat/completions")
@circuit_breaker() # 挂载熔断器
async def chat_completions(request: ChatCompletionRequest):
"""
网关核心接口
"""
# 1. 打印日志 (实际项目中应使用 logging 模块)
print(f"收到请求: {request.model} - {len(request.messages)} msgs")
# 2. 判断是否流式
if request.stream:
# 返回流式响应 (SSE)
return StreamingResponse(
stream_llm_api(request),
media_type="text/event-stream"
)
else:
# 返回普通 JSON
return await call_llm_api(request)
# 启动命令: uvicorn main:app --reload📝 总结与回顾
恭喜你!你已经从一个写 ETL 脚本的大数据工程师,成功蜕变为能手写 高并发微服务 的 AI 架构师。
让我们回顾一下这个 LLM Gateway 涉及的核心能力:
- Pydantic: 你的"数据安检员",确保进来的数据都是合规的。
- Asyncio: 你的"交通指挥官",让单线程也能处理成千上万的并发请求。
- Generator: 你的"流水线",实现数据的实时流转,降低内存压力。
- Decorator: 你的"保镖",在不侵入业务逻辑的情况下,提供熔断和重试保护。
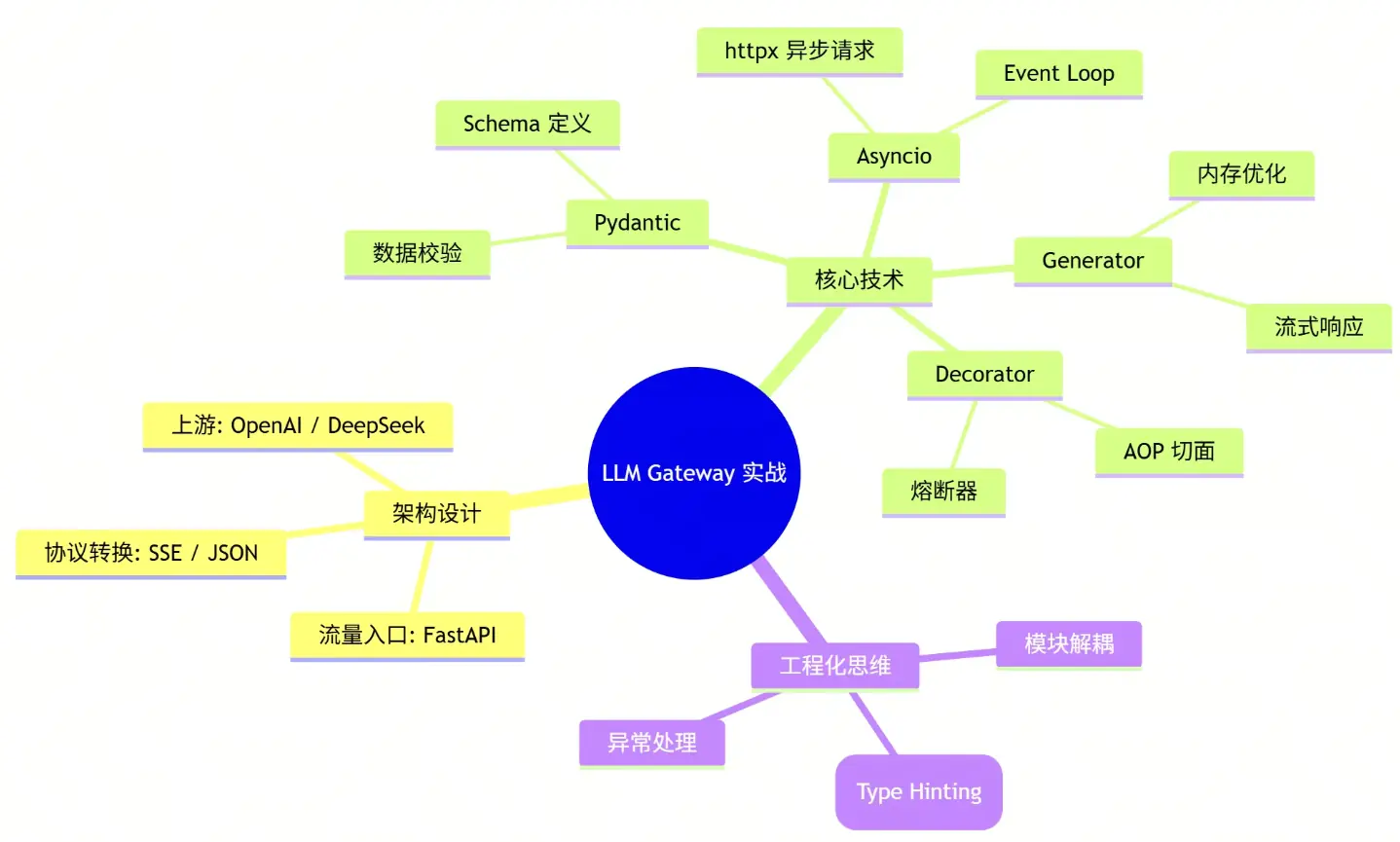
🧠 本文思维导图
🗣️ 互动话题
你在转型 AI 开发的过程中,遇到的最大"坑"是什么?
- A. 习惯了 Java 的强类型,受不了 Python 的动态类型?
- B. 搞不懂
async/await,代码经常卡死? - C. 流式输出 (Streaming) 总是断断续续?
- D. 依赖管理太乱,
pip和conda打架?
👇 在评论区告诉我你的答案,或者输入关键词【网关源码】,获取本文完整的项目代码包!