背景
因为在测试环境中数据量往往是比较小的,在数据接口调用方面速度的差异研发同学是很难感知到的,基本上的开发原则就是:程序员和代码一个能跑就行。导致在后续生产环境时常会中出现接口响应速度慢的问题。
思路分析
当一个慢接口问题进来后,我们不能一上来就怀疑是慢sql的问题,有时你甚至会发现我问题排查着排查着就恢复正常了,可能时远程调用口的负载下来的了最终导致口调用正常了。我们的排查顺序应该时由上至下。从业务接口调用再到底层的sql执行。
1.通过arthas, 执行接口对应的trace指令,查看接口各个子接口的执行时间(当然目前主流的skywalking也可以看子接口的执行时间,效果都是位慢的子接口),如果发现不是因为远程调用的接口(grpc、openfeign),通过华为云日志抓取慢sql,使用explain分析慢sql进行优化。
explain解析
例子为下:
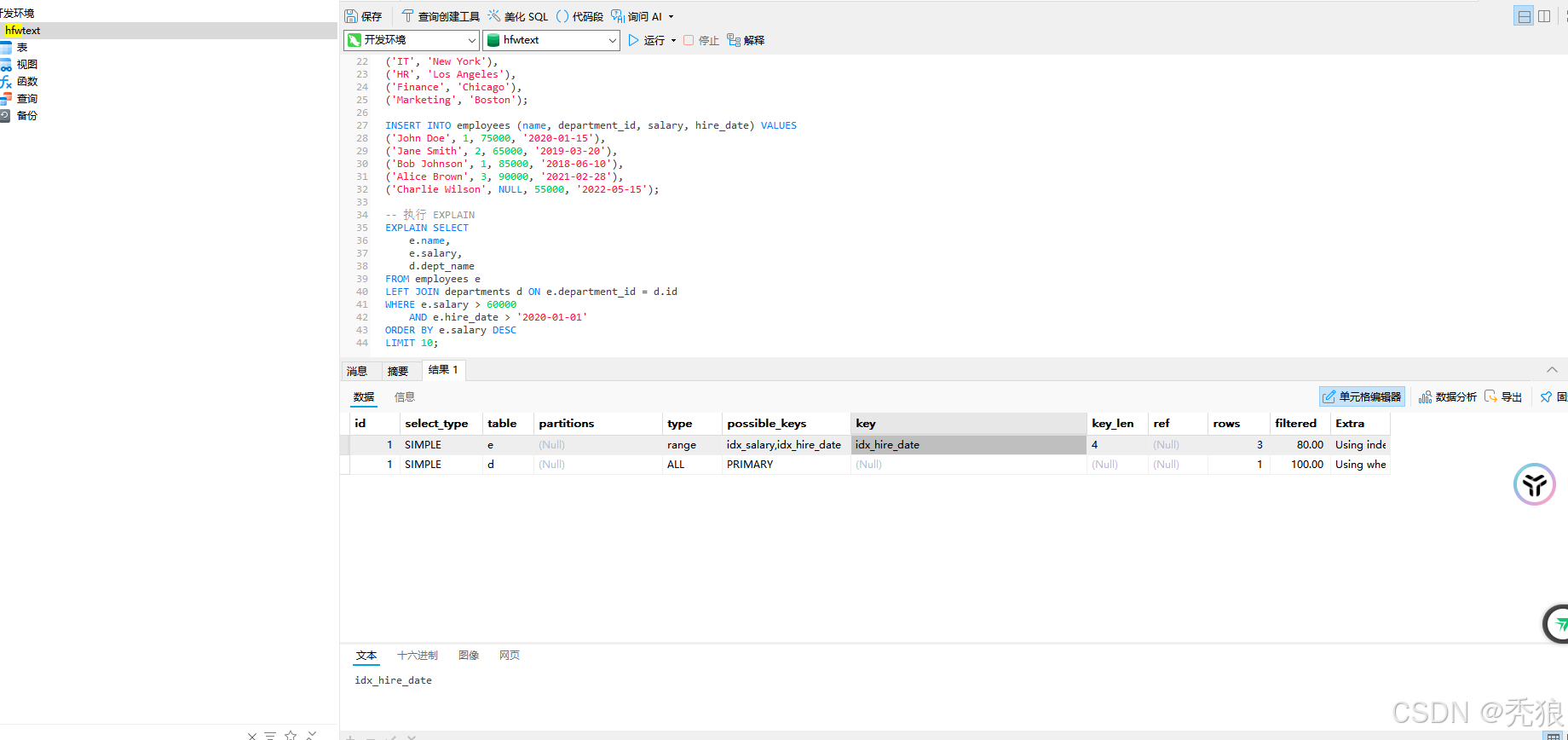
1.id:每一个select 都有一个唯一的Id,其中如果时union的id为null,如果是相同select中的子查询这此时id是一样的。id越大优先级越高。
2.select_type:
- SIMPLE(不存在子查询)。
- PRIMARY(当前查询为最外层的查询)。
- SUBQUERY(当前查询为子查询并且为子查询中的第一个)。
- DERIVED(查询条件中的查询)。
- UNION (联合查询中的第二个子查询)。
- UNION RESULT (联合查询中的结果)。
3.table:当前查询涉及的表。
4.partitions:当前select查询的分区。
5.type(链接类型):
- system:表中只有一行数据。
- const:通过索引一次找到。
- eq_ref:通过唯一索引进行关联。
- ref:通过非唯一索引进行关联。
- range:范围扫描索引。(性能一般)
- index:全索引查询。(效率极差)
- all:全表扫描。(废了)
6.possible_keys:查询可能使用到的索引。为null则说明不会使用到索引。
7.key:实际使用的索引,为null则说明没有走索引。
8.key_len :索引到索引的字节长度。用来判断索引是否存在失效。
9.ref:与索引比较的列。
10.rows: 预估扫描行数,扫描的越少效率就越好。
- filtered: 过滤比例。
12.extra:扩展信息,
- Using index:使用了覆盖索引,不会做回表操作。
- Using where:在存储引擎检索后过滤。
- Using temporary:使用到临时表做查询。
- Using filesort:在查询是做了额外的排序操作。
- Using join buffer:使用连接缓冲区。
- Impossible WHERE:查询条件设置为false。