文章目录
- 前言
- [1. MySQL安装](#1. MySQL安装)
- [2. 什么是数据库,为什么需要数据库?](#2. 什么是数据库,为什么需要数据库?)
- [3. 见一见数据库](#3. 见一见数据库)
- [4. 主流数据库](#4. 主流数据库)
- [5. 服务器、数据库和表之间的关系](#5. 服务器、数据库和表之间的关系)
- [6. MySQL架构](#6. MySQL架构)
- [7. SQL分类](#7. SQL分类)
- [8. 存储引擎](#8. 存储引擎)
前言
安装与卸载中,用户全部切换成为root,⼀旦安装,普通用户均能使用
初期练习,mysql不进行用户管理,全部使用root进行,尽快适应mysql语句,后面学了用户管理后,再考虑新建普通用户
1. MySQL安装
环境:Linux云服务器(Ubuntu)
- 更新系统的软件包列表
powershell
sudo apt-get update- 安装MySQL服务器
powershell
sudo apt install mysql-server- 检查MySQL服务是否启动,若没有启动手动启动
powershell
ps aux | grep mysql
若没有启动执行:
powershell
sudo service mysql start- 登录MySQL(默认安装之后不需要密码就可登录)
登录(连接MySQL服务器)的时候有一些选项,我们来简单介绍一下
powershell
mysql -h 127.0.0.1 -P 3306 -u root -p
-h:指明要连接的服务器地址,即客户端要连接到哪台计算机上的 MySQL 服务器。
这里127.0.0.1 是本地环回地址,代表本机。我们后面会学到MySQL本质是一种网络服务(基于客户端/服务端架构),对应的服务一定回部署到某台特定的主机上,而我们这里是单机测试,所以指明IP为本地环回。
如果要连接远程服务器,这里应该是服务器的IP地址或域名
-P:指明要连接的端口号
3306 是MySQL服务器的默认监听端口,mysqld (MySQL服务器)就在这个端口上等待连接
-u:指明我们想要以哪个用户的身份登录(连接到MySQL服务器)
-p:提示需要输入密码
执行命令后会提示你输入对应用户的密码
目前是免密码登录的,后面必须设置密码(输入密码时不会回显)。
2. 什么是数据库,为什么需要数据库?
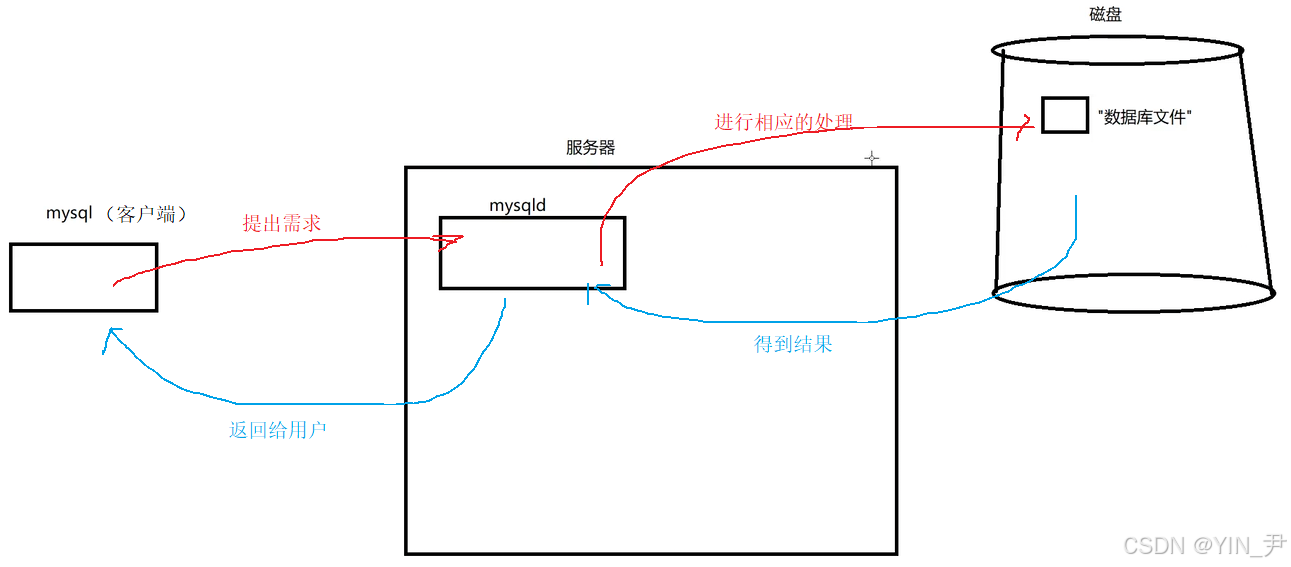
我们上文已经简单提到过,MySQL是一种网络服务:
MySQL 严格遵循客户端/服务器架构,那在我们当前的云服务器上,这两个角色分别是谁呢?
就是这里的mysql和mysqld。
mysql就是我们当前环境的数据库服务客户端,mysqld即为数据库服务的服务端。
但是要注意,MySQL 的客户端不仅只有 mysql 命令行工具,mysql 是 MySQL 自带的一个命令行客户端工具(客户端之一),还有其他形式的客户端。
比如:
图形化客户端(如 MySQL Workbench、phpMyAdmin 等)、各种编程语言提供的 MySQL 连接库

那MySQL到底是做什么的网络服务呢?
MySQL是一套给我们提供数据存取服务 的网络程序。
而我们日常口语中经常提到的数据库,其实是存储在磁盘(或内存)上的、按照特定格式组织起来的数据文件集合。
而如果提到数据库服务,那就是我们上面提到的mysqld(数据库服务器)。
现在如果大家感觉不怎么理解也没关系,后面我们还会不断加深对这些概念的理解。
那么下面问题来了:存储数据用文件就可以了,为什么还要弄个数据库?
是的,文件当然可以存数据,一般的文件确实提供了数据的存储功能,但是站在用户的角度,文件并没有提供非常好的数据管理能力。
什么意思呢?举个栗子:
比如现在有一个大文件,里面有10万个IP地址,如果我现在想统计一下文件里面以120开头的IP地址有多少个,分别是哪些?怎么做呢?
那我们可以借助我们的编程语言比如C语言打开这个文件,然后边读边判断边统计。那这个工作就需要我们自己去做,文件只是提供了基本的存储能力。而对内容的各种统计,各种增删查改等对内容的管理工作,就全部需要我们自己做。这就是我们上面所说的文件没有提供比较好的对数据内容的管理能力。
于是:
就产生了数据库,数据库系统可以提供高效、可靠的数据管理能力,用户指明对应的需求,数据库就可以快速的返回对应的结果。
这是原始文件系统无法比拟的。
一个生动的比喻:
用文件存数据 就像把一堆纸质文件散乱地堆在一个大仓库里。要找一份文件,你得自己进去翻;要更新文件,很容易弄乱或弄丢;多人同时来找文件,会乱作一团。
用数据库存数据就像把文件分门别类地放在一个智能图书馆里。每份文件都有编号和索引卡(索引),有专门的图书管理员(数据库引擎)帮你快速查找。图书馆有严格的借阅和归还规则(事务和并发控制),保证书籍不会丢失或混乱。
简单总结一下:
文件保存数据有以下几个缺点:
文件的安全性问题
文件不利于数据查询和管理
文件不利于存储海量数据
文件在程序中控制不方便
为了解决上述问题,专家们设计出更加利于管理数据的东西------数据库,它能更有效的管理数据。数据
库的水平是衡量一个程序员水平的重要指标。
宏观上,我们可以认为这一套的数据存取的解决方案就是数据库。
3. 见一见数据库
下面我们来做这样一件事情:
下面我们就登录mysql,然后建一个数据库,在这个数据库里面建一张表,插入一些数据,并且带大家看一下这些对应的操作在Linux上是如何表现的(用到的sql语句后面的文章都会讲到,大家先看我操作就好,见一见)
开始了:
登陆上mysql
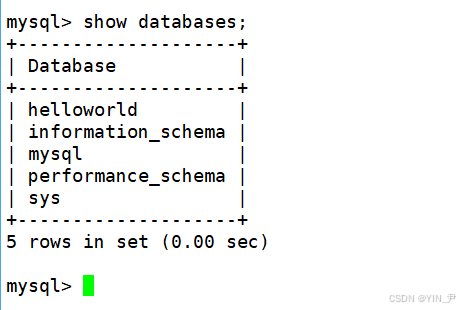
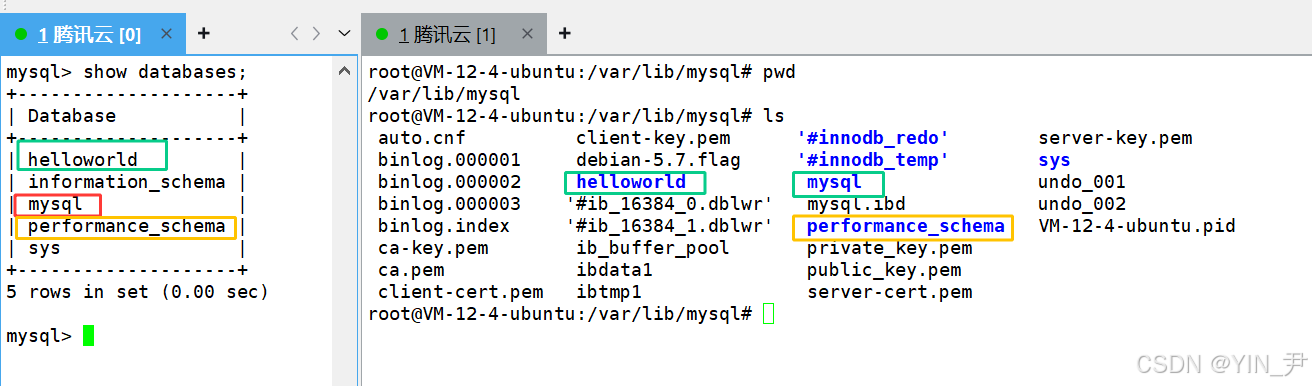
show databases可以查看有哪些数据库
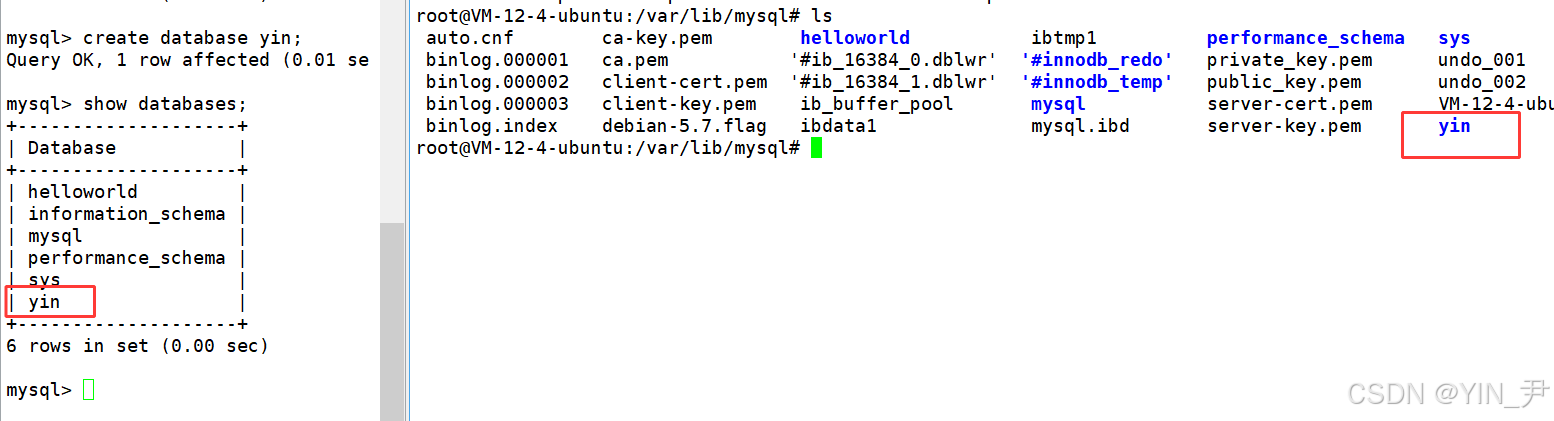
那这些数据库在哪呢?
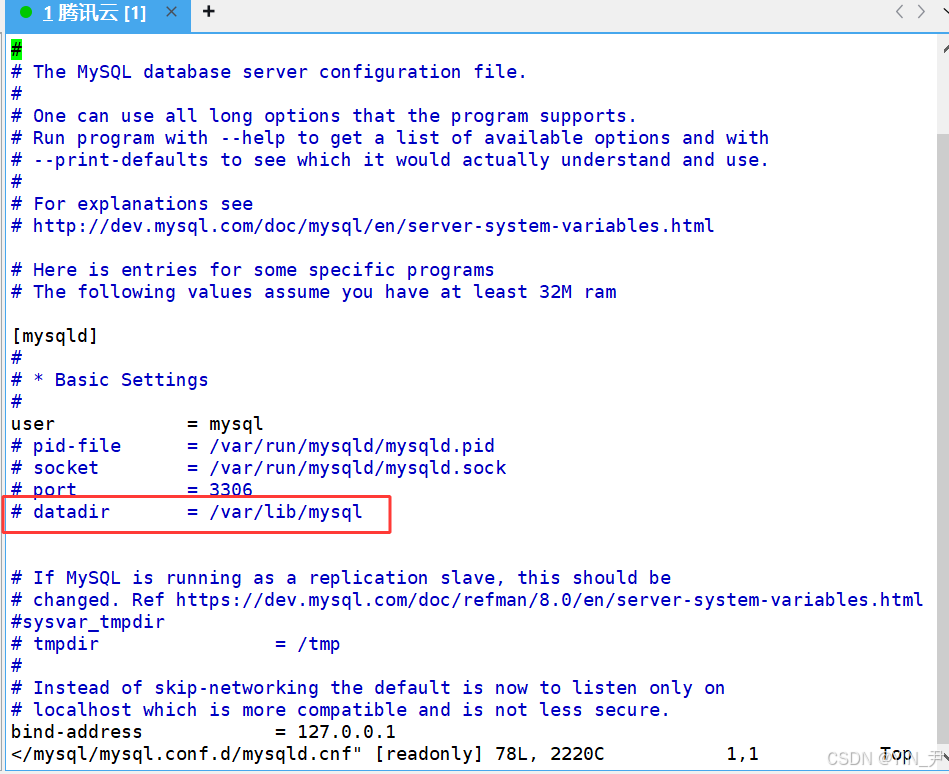
vim /etc/mysql/mysql.conf.d/mysqld.cnf打开我当前这个环境下MySQL的配置文件
看到红色圈出的这一行,这里的datadir就是我们mysql服务对应的数据的一个存放路径
然后我们进入到这个目录下(要root用户才可以进)
现在就进入到这个目录下了,我们来看一下该目录下都有啥
对比一下
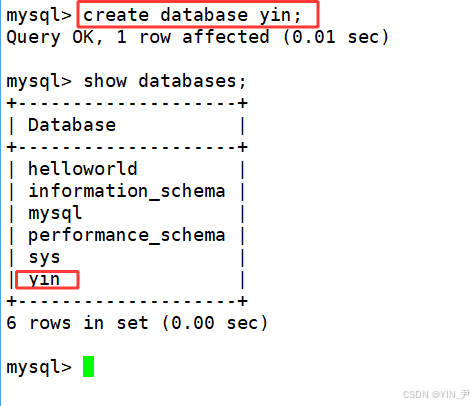
然后我再来创建一个数据库
create database yin;(执行这个sql语句,其实就是向mysql服务器下达一个创建数据库的请求,然后mysqld就帮我们完成该数据库的创建)
然后我们再来对比一下
我们创建了一个名为yin的数据库,在datadir目录下就多了一个名为yin的目录。
所以,创建的数据库,本质就是Linux下的一个目录
接着,我们再在这个数据库下创建一张表
use yin;指明我们是要在yin这个数据库下创建表
create table student( -> id int, -> name varchar(32), -> gender varchar(2) -> );这里建表的语法我们后面会讲(这里就是创建一个表,表名为student,有3列,分别是id、name和gender
然后我们进入到yin目录下
我们发现对应的目录下也新建了一些文件。
所以,在数据库里面建表,其实就是在对应的目录下创建文件即可! (当然这些具体的工作都是mysql服务器即mysqld帮我们做的)
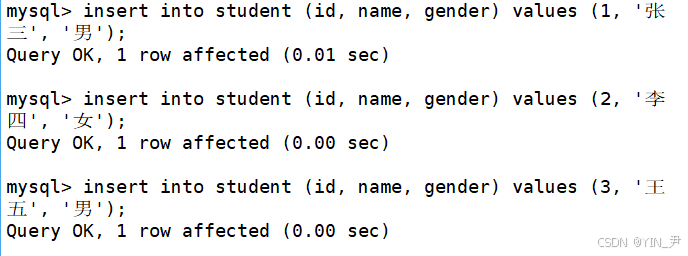
接下来我们来往表里面插入一些数据
然后来查询一下表中的数据
我们看到,它就以一张表格的形式把数据展示给了我们。
当然这里我们看到的是数据的逻辑存储,底层不是真的这样存的。
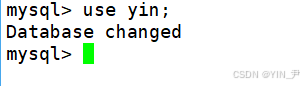



所以,数据库是什么?
数据库本质其实也是文件,只不过这些文件不由我们程序员直接操作,而是由数据库服务器帮我们创建和管理(我们只需执行相应的sql语句即可)
4. 主流数据库
SQL Sever: 微软的产品,.Net程序员的最爱,适合中大型项目。
Oracle: 甲骨文产品,适合大型项目,复杂的业务逻辑,并发一般来说不如MySQL。
MySQL:世界上最受欢迎的数据库 ,属于甲骨文,并发性好,不适合做复杂的业务。主要用在电商,SNS,论坛。对简单的SQL处理效果好。
PostgreSQL :加州大学伯克利分校计算机系开发的关系型数据库,不管是私用,商用,还是学术研究均可使用,可以免费使用,修改和分发。
SQLite: 是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。
H2: 是一个用Java开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中。
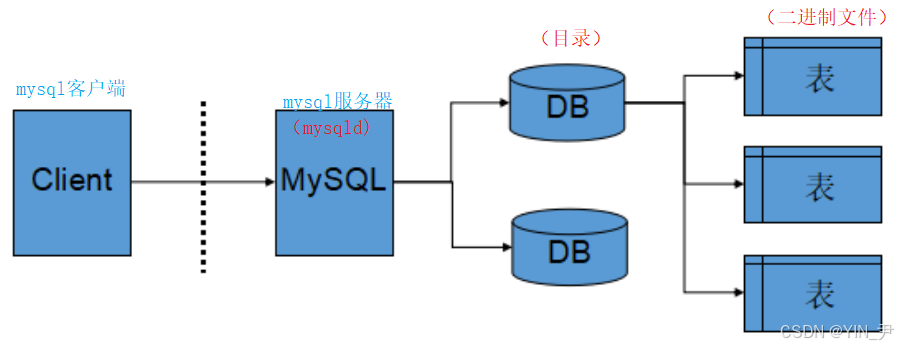
5. 服务器、数据库和表之间的关系
所谓安装数据库服务器(mysqld),只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。
为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
数据库服务器、数据库和表的关系如下:
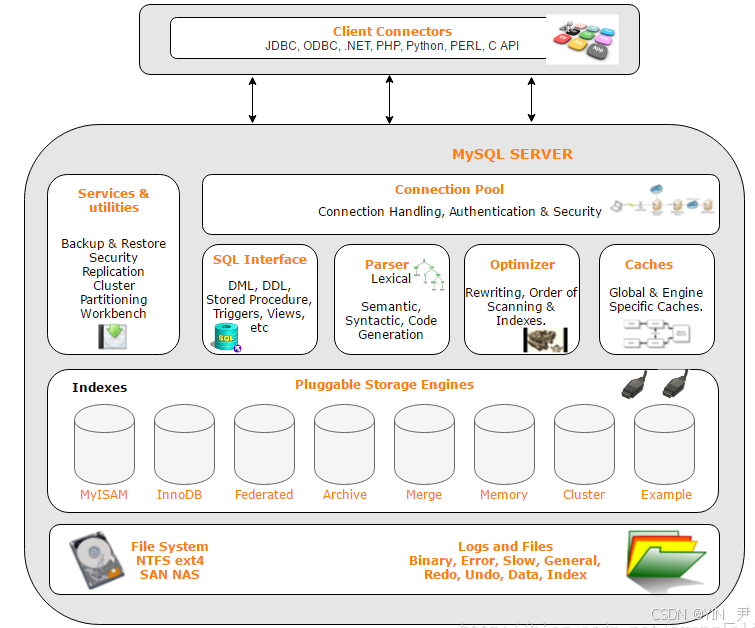
6. MySQL架构
MySQL 是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如 Unix/Linux、Windows、Mac 和 Solaris。各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性。
下面我们重点来看这张图
首先,最上面的就是mysql客户端,我们看到有很多种,这个我们上面也提到过,我们当前用到就是命令行的mysql客户端,除此之外还有一些图形化的客户端和各种编程语言提供的 MySQL 连接库。
然后我们来看下面的mysql sever,即mysql服务器。
主要可以分为三层:
第一层连接池,主要做连接管理、权限认证和一些安全相关的工作。
第二层,主要就是对客户端下达的各种sql语句进行词法分析、语法分析以及做一些sql优化,然后再下达给下一层。
第三层存储引擎层,就是各种的存储引擎。存储引擎接收上层传达下来的经过词法分析、语法分析和优化之后的sql语句,根据指令执行数据操作 。
那我们看到存储引擎的种类有很多,为什么要有这么多呢?
核心原因是 "没有一种存储方案能完美适应所有场景"。
MySQL是帮我们做数据存取服务的,但是数据的类型、使用场景和访问模式 各种各样,不同类型的数据可能需要采用不同的存储方案,所以就有了各种各样的存储引擎,根据数据的访问模式、一致性要求、并发要求等来选择合适的存储引擎。
那最下面的一层即物理存储层,对应具体的文件系统,存储实际的数据。
7. SQL分类
SQL,即Structured Query Language 的缩写,直译为 "结构化查询语言"。
具体可分为:
DDL【data definition language】 数据定义语言 ,用来维护存储数据的结构
代表指令: create(创建表), drop(删除表), alter(修改表结构)
DML【data manipulation language】 数据操纵语言 ,用来对数据进行操作
代表指令: insert,delete,update
DML中又单独分了一个DQL,数据查询语言 ,代表指令: select
DCL【Data Control Language】 数据控制语言 ,主要负责权限管理和事务
代表指令: grant,revoke,commit
8. 存储引擎
存储引擎是:
数据库管理系统如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。
MySQL的核心就是插件式存储引擎,支持多种存储引擎。
查看存储引擎:
sql
show engines;//查看当前环境下所支持的存储引擎
存储引擎对比:
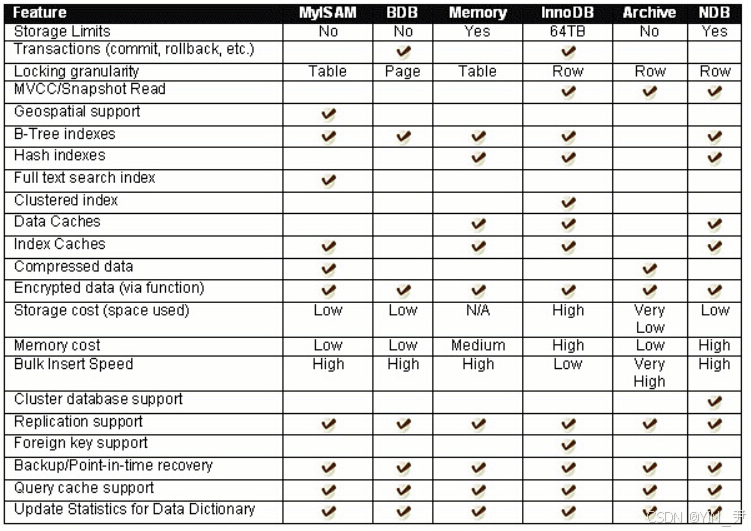
虽然这么多,但是MySQL存储引擎最常用的只有两种------InnoDB和MyISAM。这两个相比的话,80%都是InnoDB。