介绍
文本嵌入模型是自然语言处理的核心,它能将文本转换为数值向量,使机器能够捕捉和处理语义信息 。LangChain框架通过Embeddings类为众多嵌入模型提供商(如OpenAI、Cohere、Hugging Face等)提供了一个标准的交互接口 。
嵌入模型就像是语言的翻译官 ,它们能够将人类可读的文本 转换成计算机可理解的数字向量 ,让AI能够理解和处理文本的语义信息
为什么需要嵌入模型
文本处理问题 = '''
❌ 计算机无法直接理解文本: 只能处理数字
❌ 文本相似度难以计算: "猫"和"狗"的相似性?
❌ 语义信息丢失: 同义词无法识别
❌ 高维稀疏数据: 传统编码效率低
❌ 上下文理解缺失: 词语含义随语境变化
'''
嵌入模型解决方案 = '''
✅ 文本向量化: 将文本转换为密集向量
✅ 语义相似度: 通过向量距离计算语义相似性
✅ 同义词识别: 相似词语具有相近向量
✅ 降维高效: 密集向量表示更高效
✅ 上下文感知: 考虑词语使用环境
'''
嵌入模型工作原理
1. 文本到向量的转换过程
嵌入转换过程 = '''
输入文本: "人工智能改变世界"
↓
分词处理: ["人工", "智能", "改变", "世界"]
↓
语义编码: 神经网络处理
↓
向量生成: [0.33, -0.64, 0.81, ..., 0.35]
↓
输出结果: 769维向量(示例)
'''
向量空间概念 = '''
想象一个多维空间:
- 每个词语是一个点
- 相似词语距离近
- 不同词语距离远
- 语义关系 = 空间关系
'''2. 嵌入模型的核心特性
嵌入模型特性 = {
'语义保持性': {
'定义': '相似文本有相似向量',
'例子': '猫和狗的向量距离 < 猫和汽车的向量距离',
'应用': '文本相似度计算、推荐系统'
},
'上下文敏感性': {
'定义': '同一词语在不同语境有不同向量',
'例子': '苹果(水果) vs 苹果(公司) 有不同向量',
'应用': '消歧义、语义理解'
},
'维度高效性': {
'定义': '用低维向量表示高维语义',
'例子': '100维向量 vs 10万维词袋模型',
'应用': '存储优化、计算加速'
},
'可计算性': {
'定义': '支持向量运算和相似度计算',
'例子': '国王 - 男人 + 女人 ≈ 女王',
'应用': '类比推理、语义运算'
}
}3.词Embedding

那我们假设我们有三个维度,那这个三个维度呢,其实可以对应于这个词的三种意思的考量的不同的方向。那比如说呢我们三个维度的第一个维度呢是它的可爱程度。那第二个维度呢是它体型的大小。第三个维度呢是它的权力等级。那比如说我们以小猫为例,那小猫的话它的可爱程度呢是非常高的。我们打0点9分,那满分是一分啊,那体型的大小呢它是比较小的,我们打0点2分,权利呢我们打0.1分。那这样呢它的向量呢就是0.9、0.20.1。那这样的一个向量,我们用中括号括起来表示一个向量。那同理呢小狗是这个可爱程度0.7,体型0.5,权力等级是0.1,那它就是0.70.50.1这样的一个向量。国王呢它的可爱程度呢就比较低是0.1。那它的体型呢是比较大的,是0.6。那它的权力等级呢是0.9。那它的向量就是0.1,0.6,0.9
那同样这样的话,我们就根据三个维度。把一个词分成了不同维度的打分,那就构成了一个向量。
4.向量画图工具的使用
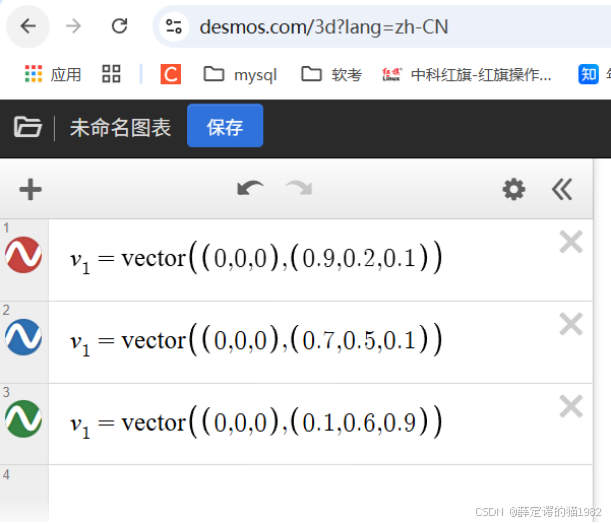
https://www.desmos.com/3d?lang=zh-CN
那接下来呢我们把这个不同的向量呢在一个坐标系里边去显示。那其实这些所有的这个向量呢,它其实是有三个维度。那三个评分决定了。那这个三个评分呢,其实正好对应到我们空间坐标系里边的一个点。那我们呢就可以建立一个向量。那这个向量呢就是从00点,然后指向它最终的一个终止点。那这样的话,它就对应了第一个就是小猫就是。从00点一直到0呃0.90.20.1,它的这个维度点。然后第二个呢也是同理的,这个是小狗的一个向量。然后第三个呢就是国王的一个向量了。那我们把这个这张图放大,我们看一下之后呢,这张图其实是能能滑动的那我们能看出来这个这个 是小猫小狗,然后这个是国王。
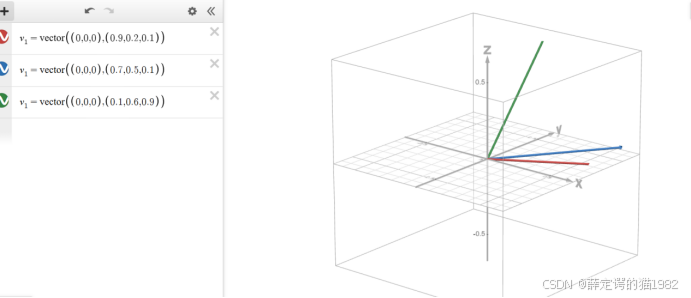
那我们把这张图放大了,它有一些共同的特点可以看到,就比如说小猫和小狗的话,那他们两个其实对于我们理解来讲,他们是比较接近的那对于国王来讲的话,国王应该是离小猫 小。狗的话会比较远的。那通过这张图呢,我们能看出来,就是当两个向量 的话比较相似,比较接近的时候,那它们中间的夹角会比较小。
比如说小猫 和小狗,那他们的夹角呢就比较小。那如果是国王和小猫或者国王和小狗呢,那他们的夹角呢就比小 猫和小狗的话就比较大。那所以呢我们就推断出来了,那一个向量。他嗯他的相似度就这个两个向量,它是否相似,这个词是否相似,就是以以他们的这个夹角来确定的。那接下来我们就找数学公式里边的夹角公式,然后去计算 一下他们的夹角就可以了。
那通过夹角呢,我们就可以判断出。不同向量之间的相似度了。那这个是在线计算 向量夹角的一个一个平台。在线的一个计算平台。那我们看到下边呢,它对于这个向量的空间计算呢,它下边有不同的值。那有这种各种计算的那其实我们用 到的它叫余弦相似度。在线的一个计算平台。那我们看到下边呢,它对于这个向量的空间计算呢,它下边有不同的值。那有这种各种计算的那其实我们用 到的它叫余弦相似度。
5.向量角度计算

那它其实计算的就是夹角的大小。那我们用这个公式,不用关注它底下是如何去去计算的这个公式,因为有现成的工具 包给我们去使用。
我们就知道夹角的大小是决定向向量之间相似度的一个关系就可以了。那这样的话,我们把小猫和小狗的向量都放在这儿,然后我们点击计算。啊,我们就能看出来它的相似度呢就是0.92,那一分是满分,0.92是非常高了。那如果呢我们把刚才的这个国王的。向量拿出来呢,我们放到这儿用小猫去跟国王去对比,然后我们点击计算,那它相似度呢就是0.2。所以我们从直觉上看的话,这个国王和小猫小狗他们的这个相似度就不是很高了。而小猫小狗它们相似度是很高的。那通过这个方式呢,我们就可以看出这个不同词之间的相似度。那刚才我们看到啊所有的 这个向量,那这些指标呢,其实都是我们人工给他设定的。
比如说按照这个三个固定的维度去设定的那如果在真实情况下的话,我们不太可能把所有的词的指标每一个都去设定出来。那怎么办呢?那我们呢其实是把这些所有出现的句子,然后都给到embedding训练模型,让他把相关的词向量给我们计算出来。

那这样的话,它就有一个假设它的假设就是出现在相。4上下文中的词往往具有相似的语义性。那我们举个例子,比如说下边呢有三个句子,小猫喜欢玩毛绒玩具,小狗喜欢玩皮球,国王喜欢发号施令。那这边小猫和小狗呢,那他们呢就在类似的结构中 中经常出现。
比如说叉叉喜欢玩叉叉。那它就表明了小猫小狗呢,它是某一种动物或者某种行为行行为是相似的,行为模式是相似的。所以呢在模型不断调整的过程中呢,小猫和小狗的词向量呢就是处于一个比较接近的位置。也就是说我们刚才说到这个这个向量化的几个数值,那它的夹角呢是非常小的。那其实国王也是类似。那国王的话,它也是根据句子的结构是呃就有所不同的。比如说它的结构是叉叉,喜欢发号施令。那这就表明了国王可能是一个人,然后并且呢他拥有权利。那他的行为模式和小猫小狗是完全不一样的。所以一个词的话,它的词向量的大小其实是根据它所处句子中的位置的语义关系决定的。那通过这样的计算,因为它是一个机器形式的 计算,所以呢我们就可以把它的维度调的更高一些。
那就不限于我们刚才说的固定的 三三个维度。
那我们呢可能给它调了一个更高的一个维度,因为去让机器去算嘛。所以比如说786维,然后1024维,就是相当于一个坐标点呢,一共有呃需要填786个或者是1024个,那它每一个值代表呃究竟代表什么呢?那其实在维度分的很多的时候。其实我们是说不清楚的,所以我们也不需要说清楚。我们只需要把维度确定好之后,把这些相关的足够的语料提供给他,我们的词项量就出来了。那这样的话我们就可以用词项量去判断相似度了。那词向量呢是由它所处的句 子的上下文决定的那我们把词向量呢进行一个扩展。
百炼平台查看词向量
示例1
import os
from langchain_community.embeddings import DashScopeEmbeddings
from dotenv import load_dotenv
load_dotenv()
# 初始化阿里百炼Embeddings(LangChain封装版)
embeddings = DashScopeEmbeddings(
model="text-embedding-v1", # 阿里百炼嵌入模型默认值,也可使用其他嵌入模型
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
# ==================== 1. 单段文本生成向量 ====================
single_text = "大模型"
doc_embdding_data = embeddings.embed_documents(single_text);
print("=== 输出文本对应的向量数字 ===")
print(doc_embdding_data);
single_vector = embeddings.embed_query(single_text) # 单文本嵌入(query场景)
print("=== 根据文本查询到的向量结果 ===")
print(single_vector)示例2
from openai import OpenAI
import os
# 初始化客户端(推荐从环境变量读取API Key,避免硬编码)
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 替换为你的百炼API Key,或直接写字符串(不推荐)
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
try:
# 调用Embeddings接口生成文本向量
response = client.embeddings.create(
model="text-embedding-v4", # 阿里云百炼Embedding模型名
input="测试文本", # 待生成向量的文本
encoding_format="float" # 指定输出格式为浮点型(可选:float/base64)
)
# 1. 输出完整响应结果(查看所有返回字段)
print("=== 完整响应结果 ===")
print(response)
# 2. 提取核心向量数据(实际开发中常用)
embedding = response.data[0].embedding
print("\n=== 提取的文本向量 ===")
print(f"向量长度:{len(embedding)}") # text-embedding-v4默认输出1024维向量
print(f"向量前10位值:{embedding[:10]}") # 打印前10位,避免输出过长
# 3. 提取其他关键信息
print("\n=== 其他关键信息 ===")
print(f"模型:{response.model}")
print(f"消耗Token数:{response.usage.total_tokens}")
except Exception as e:W
print(f"调用失败:{e}")实例3
豆包火山引擎接入
安装OpenAI Python SDK
pip install --upgrade "openai>=1.0"
import os
import os
from openai import OpenAI
# gets API Key from environment variable OPENAI_API_KEY
client = OpenAI(
api_key="key",
base_url="https://ark.cn-beijing.volces.com/api/v3",
)
print("----- embeddings request -----")
resp = client.embeddings.create(
model="doubao-embedding-text-240715",
input=["花椰菜又称菜花、花菜,是一种常见的蔬菜。"],
encoding_format="float"
)
print(resp)实例四
import os
from openai import OpenAI
input_text = "衣服的质量杠杠的"
client = OpenAI(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx",
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key="key",
# 以下是北京地域base-url,如果使用新加坡地域的模型,需要将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
completion = client.embeddings.create(
model="text-embedding-v4",
input=input_text
)
print(completion.model_dump_json())