【前沿技术】构建你的 AI 数字孪生体:基于 RAG 的个人知识库(第二大脑)深度解析
引言:信息爆炸时代的"记忆危机"
作为一名技术人,你是否也面临过这样的窘境:
- 半年前费尽心机解决的复杂 Bug,今天再次遇到时,大脑却一片空白,只记得"我好像解决过"。
- 在 Obsidian、Notion 里囤积了海量的技术笔记、生活感悟,但真正需要时,关键词搜索却总是找不到想要的那一条。
- 我们每天都在产生数据------代码、日记、甚至基因检测报告,但这些数据是沉睡的"死数据",无法为你提供决策支持。
在 AI 时代,我们不应再满足于做一个"只会写笔记 "的人。AI 技术的发展,特别是 LLM(大语言模型)与 RAG技术的成熟,让我们有机会构建一个真正"懂你"的数字化第二大脑 ,或者用更前沿的术语来说------一个个人数字孪生体 (Personal Digital Twin)。
本文将探讨如何利用 AI 技术,将我们的技术积累与生活记忆数字化,构建一个量身定制的智能体。
一、 核心概念:从"死笔记"到"活大脑"
要实现这个愿景,我们需要明确几个核心概念的演进:
1.1 第二大脑 (Second Brain) 的进化:AI-PKM
传统的个人知识管理 (PKM) 是静态的存储。而 AI 加持下的 PKM (AI-PKM) 是动态的。它不仅帮你存,更重要的是当你提问时,它能主动关联、总结并输出答案。
1.2 终极形态:个人数字孪生 (Personal Digital Twin)
这不仅仅是知识库。当你将长期的生活日记、情绪记录、甚至生物数据(如基因代谢特征、体检报告)喂给 AI,它不仅记得你做过什么,还能模拟你的思维方式和生理特征,给出高度个性化的建议。
愿景:未来的 AI 助手不是给你通用的 Stack Overflow 答案,而是说:"参考你 2024 年 5 月处理类似数据库迁移问题的经验,建议你使用当时编写的 Python 脚本,路径在..."
二、 技术底座深度解析:RAG 架构
如何让通用的 LLM(如 ChatGPT)变成你的私人专家?我们不能把私有数据拿去训练(Fine-tuning 成本高且有隐私风险)。
最成熟的解决方案是 RAG(检索增强生成,Retrieval-Augmented Generation)。
简单来说,RAG 就是给"博学但健忘"的大模型教授,配备了一个属于你的"私人图书馆"和一名高效的"图书管理员"。
2.1 RAG 核心架构图
下图展示了一个典型的个人 AI 记忆体的数据流转过程:
(注:请在此处插入展示 RAG 流程的架构图,即包含 Input -> Embedding -> Vector DB -> Retrieval -> Generation 的图示)
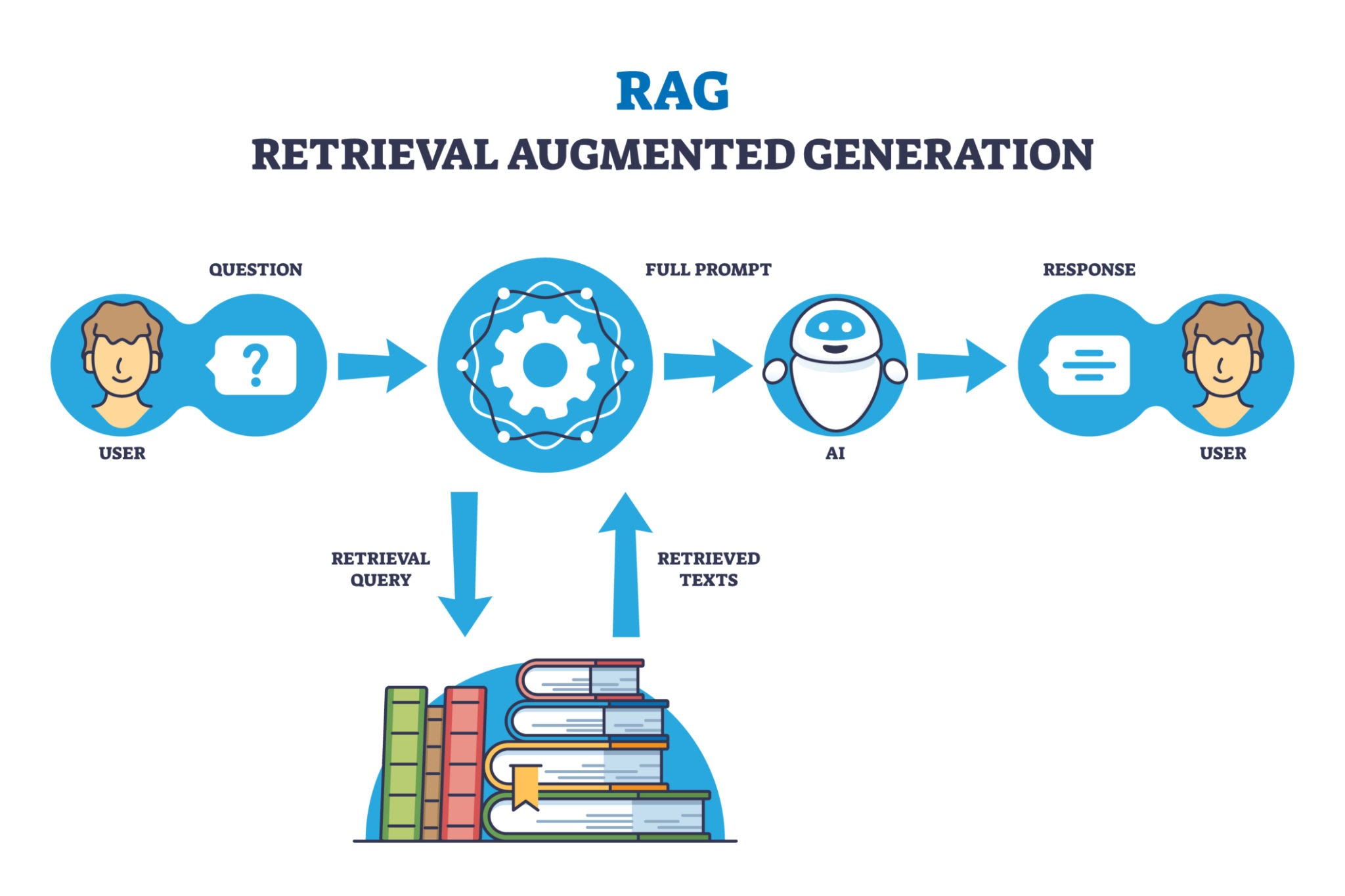
2.2 架构详细说明
我们按步骤拆解这个系统是如何工作的:
第一步:数据输入与切片 (Input & Chunking)
- 你的记忆源:这是系统的养料。包括你的 Markdown 技术笔记、TXT 日记、PDF 文档、甚至 JSON 格式的基因数据。
- 切片 (Chunking):大模型一次吃不下太长的文本。系统需要将这些长文档切割成一个个语义完整的小段落(Chunk),例如每 500 个 Token 为一段。
第二步:向量化 (Embedding) ------ 核心魔法
这是机器理解人类语言的关键一步。
- 原理 :通过 Embedding 模型(如 OpenAI 的
text-embedding-3或本地的 BERT 模型),将每一个文本切片转换成一个高维向量(一串长长的数字数组)。 - 意义:在这个高维空间中,语义相似的内容距离更近。"苹果"和"水果"的向量距离很近,而"苹果"和"手机"的距离就比较远。
第三步:存储入库 (Vector Database)
- 这些转化好的向量,需要存储在专门的向量数据库中。这就像是你的"记忆仓库"。
- 常见选择包括云端的 Pinecone,或者适合个人本地部署的 Chroma、Milvus 等。
第四步:语义检索 (Retrieval) ------ "图书管理员"上线
当你在前端向 AI 提问时(Prompt):
- 系统首先将你的问题也进行向量化。
- 拿着这个"问题向量",去向量数据库里计算相似度(通常用余弦相似度),找出距离最近的 Top-K 个记忆切片。
- 关键点:这不再是僵硬的关键词匹配,而是基于意图的语义搜索。即使你的笔记里没有"解决方案"这四个字,只要内容相关,也能被找出来。
第五步:增强生成 (Generation)
这是最后一步。系统将检索到的"记忆切片"作为上下文 (Context),连同你的原始问题,一起打包发给大模型 (LLM)。
AI 收到的指令实际上是这样的:
"你是一个我的私人助手。请严格根据以下我提供的背景知识(检索到的笔记片段),回答我的问题:我的问题。"
最终,LLM 结合它的逻辑推理能力和你的私有数据,生成了一个既准确又个性化的回答。
三、 双重维度的构建实践
基于 RAG 架构,我们可以构建两个维度的"大脑":
3.1 🛠️ 技术大脑:代码库与 Debug 助手
- 目标:结构化、准确性、复用性。
- 实践 :
- 养成记录习惯:遵循"现象 -> 尝试过的方案 -> 最终解法 -> 关键代码片段"的格式记录 Markdown 笔记。
- 效果:遇到报错时,直接问 AI,它会优先检索你自己的知识库,实现经验的高效复用,避免重复造轮子。
3.2 🌿 生活大脑:数字化记忆与自我认知
- 目标 :关联性、时间轴、情绪感知。
- 实践:记录关键事件、决策动机和当时的情绪,而非流水账。尝试整合结构化数据(如健康体检指标、基因代谢倾向)。
- 效果:实现跨时间维度的自我洞察。
- 示例:AI 可能会分析提示:"根据你上周的日记和基因数据,你在高强度工作后更容易出现偏头痛,建议今晚减少咖啡因摄入。"
四、 结语:AI 时代的进阶玩法
AI 时代的顶级玩家,不再止于调教提示词 (Prompt Engineering),而是致力于构建数字化记忆体。
通过将技术沉淀与生活点滴向量化,我们正亲手终结信息的散乱碎片,利用 RAG 技术让 AI 进化为拥有个人灵魂的"第二大脑",实现跨越时空的自我认知增强。
这不仅是工具的升级,更是对自己人生经历的一次深度"版本管理"。
参考资料与推荐工具:
- 入门体验:Google NotebookLM(最接近成品体验)
- 开源框架:Dify, LangChain, LlamaIndex
- 本地笔记增强:Obsidian + Smart Connections 插件
- 向量数据库:Chroma (本地), Pinecone (云端)