NCCL(NVIDIA Collective Communication Library,pronounced "Nickel")库主要用于GPU集群通信,写一点基础C++ API库调用相关内容供学习参考。NCCL doc文档的API介绍写得比较丰富,但介绍中逻辑穿插了各种操作的说明,对初学者来说有点绕,比如介绍communicator时会讲解comm的split操作。
官方用例(Examples - NCCL 2.22.3 documentation)在初学者看来可能有点不完整。而另一个库(GitHub - NVIDIA/nccl-tests: NCCL Tests)又不够简单,需要全篇阅读。为了帮助对NCCL API内容有个初步理解,本文先介绍API使用基本步骤,然后解释几个常见场景示例,并给出编译运行方法。必要名词解释:
- Node:节点,服务器设备/运行机器;
- Rank:GPU设备/线程的一个标记,通信时用于设备管理。
- Comm:NCCL通信的一个识别标记,认为是一种handle。
1 基本步骤
NCCL API使用过程如下图所示,主要是根据场景初始化communicator,然后用它进行集群通信,最后销毁释放。
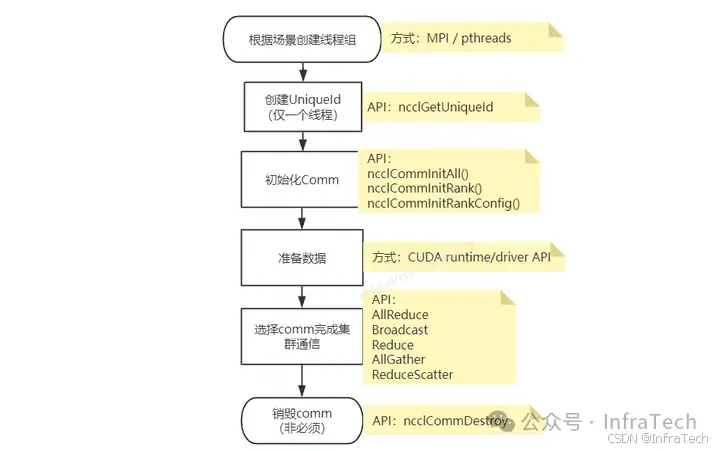
步骤1 :根据场景创建线程组。 因为GPU是独立的设备,需要用CPU线程下发CUDA指令控制其工作。特定是:不同GPU可以由相同或者不同CPU线程控制,计算开始前需要先构建好CPU线程组 ,以及建立线程与GPU之间的控制关系 。 线程的创建/管理可以用openMPI或者其它(比如pthread)。
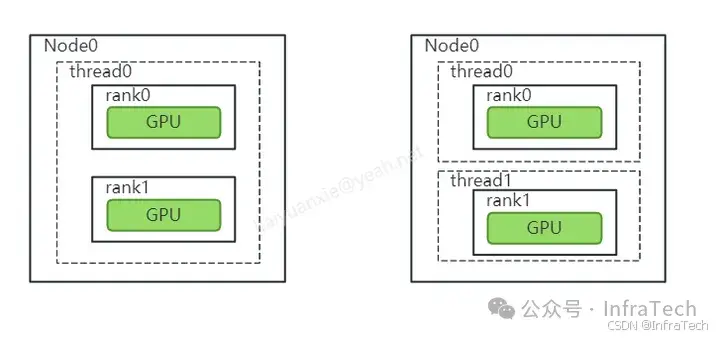
一个线程管理多个设备(左),一个线程管理一个设备(右)
步骤2:
创建一个uniqueID。这个uniqueID仅由一个CPU线程创建,并且需要传递给其它线程,它是通信组初始化的一个标识。
步骤3:
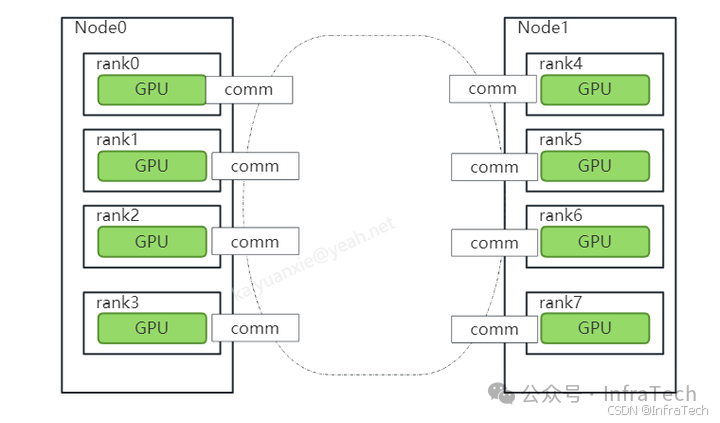
初始化communicator(简写成comm)。主要是建立一个通信组,通信组里面参与进来的GPU可以是全部或者部分,参与通信的GPU有个唯一的rank标号,每个rank拥有自己的comm实例。如下图所示,是一个rank数量为8的通信组的建立。通信组可以由多个,所以一个GPU设备可以被不同comm控制。
步骤4:
准备通信数据。这里调用cuda API将数据准备好。
步骤5:
用创建好的comm进行集群通信。
步骤6:
销毁comm。由于comm占用了一定量的资源,所以可以销毁comm。
2 用例场景
官方文档用例(docs/examples.html)中给了几个基础例子,初步看可能不理解什么意思,这里用图带文字解释几个。 场景比较常见的是示例2。
示例1:单(主)线程管理全部设备(Single Process, Single Thread, Multiple Devices)
主进程启动后管理所有设备,是指主程序不创建子进程,自己管理所有的GPU通信。如图所示有4个GPU,主进程通过创建一个comms数组,每个GPU分配一个comm进行通信。
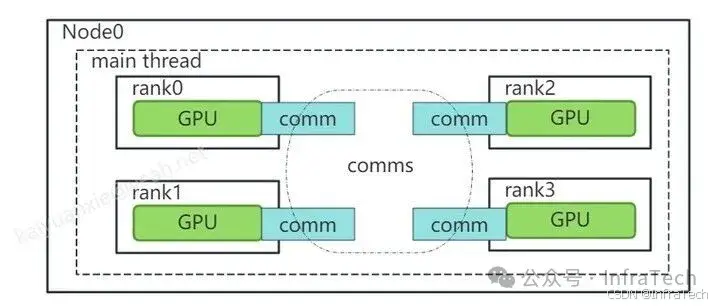
代码实现参考(nccl/multi_devices_per_thread.cu),这里主要需要留意的是初始化函数用了ncclCommInitAll,以及group函数的调用。
//initializing NCCL 用了一个comm组
NCCLCHECK(ncclCommInitAll(comms, nDev, devs));
//calling NCCL communication API. Group API is required when using
//multiple devices per thread
NCCLCHECK(ncclGroupStart()); // Group 是保证ncclAllReduce指令在CPU端非阻塞运行。
for (int i = 0; i < nDev; ++i)
NCCLCHECK(ncclAllReduce((const void*)sendbuff[i], (void*)recvbuff[i], size, ncclFloat, ncclSum,
comms[i], s[i]));
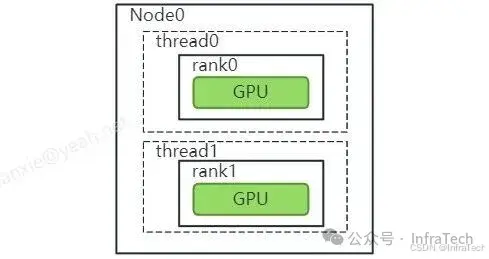
NCCLCHECK(ncclGroupEnd()); // 此处是要让集合通信完成执行等待。示例2:单线程管理单个设备(One Device per Process or Thread)
单个线程管理单个设备比较好理解,也是应用最为普遍的场景。即创建多线程,让每个线程管理一个GPU设备。如下图所示,两个设备分别交由两个不同的线程管理。
示例3:单线程多个设备(Multiple Devices per Thread)
单个线程管理多个设备跟示例1有所不同,示例1中是利用主进程/线程管理,这里是指创建多个线程组合多个设备。 这里主要是区分一下nccl rank与MPI的rank。MPI的rank是线程的数量,而nccl的rank指GPU在comm中的标识。在一些应用中(如pytorch)还会采用global rank和local rank来标识机器内与机器间的线程数量,示例可以参看:PyTorch分布式训练基础--DDP使用。
如下所示是一个双线程示例,每个线程管理两个GPU:
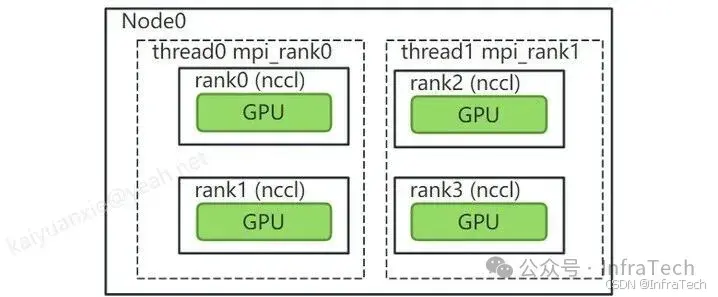
示例代码主函数如下所示。注意这个例子中每个线程占用了两个GPU,所以用mpirun启动的时候需要保证线程数n=GPU数量/2的关系。代码中localRank是指MPI在本节点线程标记,nRanks是指MPI全局的线程总数。
假设有8个GPU,启动方式示例:mpirun -n 4 --allow-run-as-root ./nccl_demo
// 主函数:
int main(int argc, char* argv[])
{
int size = 32*1024*1024;
int myRank, nRanks, localRank = 0;
//initializing MPI
MPICHECK(MPI_Init(&argc, &argv));
MPICHECK(MPI_Comm_rank(MPI_COMM_WORLD, &myRank));
MPICHECK(MPI_Comm_size(MPI_COMM_WORLD, &nRanks));
//calculating localRank which is used in selecting a GPU
uint64_t hostHashs[nRanks];
char hostname[1024];
getHostName(hostname, 1024);
hostHashs[myRank] = getHostHash(hostname);
MPICHECK(MPI_Allgather(MPI_IN_PLACE, 0, MPI_DATATYPE_NULL, hostHashs, sizeof(uint64_t), MPI_BYTE, MPI_COMM_WORLD));
for (int p=0; p<nRanks; p++) {
if (p == myRank) break;
if (hostHashs[p] == hostHashs[myRank]) localRank++;
}
//each process is using two GPUs
int nDev = 2;
float** sendbuff = (float**)malloc(nDev * sizeof(float*));
float** recvbuff = (float**)malloc(nDev * sizeof(float*));
cudaStream_t* s = (cudaStream_t*)malloc(sizeof(cudaStream_t)*nDev);
//picking GPUs based on localRank
for (int i = 0; i < nDev; ++i) {
CUDACHECK(cudaSetDevice(localRank*nDev + i));
CUDACHECK(cudaMalloc(sendbuff + i, size * sizeof(float)));
CUDACHECK(cudaMalloc(recvbuff + i, size * sizeof(float)));
CUDACHECK(cudaMemset(sendbuff[i], 1, size * sizeof(float)));
CUDACHECK(cudaMemset(recvbuff[i], 0, size * sizeof(float)));
CUDACHECK(cudaStreamCreate(s+i));
}
ncclUniqueId id;
ncclComm_t comms[nDev];
//generating NCCL unique ID at one process and broadcasting it to all
if (myRank == 0) ncclGetUniqueId(&id);
MPICHECK(MPI_Bcast((void *)&id, sizeof(id), MPI_BYTE, 0, MPI_COMM_WORLD));
//initializing NCCL, group API is required around ncclCommInitRank as it is
//called across multiple GPUs in each thread/process
NCCLCHECK(ncclGroupStart());
for (int i=0; i<nDev; i++) {
CUDACHECK(cudaSetDevice(localRank*nDev + i));
NCCLCHECK(ncclCommInitRank(comms+i, nRanks*nDev, id, myRank*nDev + i)); // world size = nRanks*nDev
}
NCCLCHECK(ncclGroupEnd());
//calling NCCL communication API. Group API is required when using
//multiple devices per thread/process
NCCLCHECK(ncclGroupStart());
for (int i=0; i<nDev; i++)
NCCLCHECK(ncclAllReduce((const void*)sendbuff[i], (void*)recvbuff[i], size, ncclFloat, ncclSum,
comms[i], s[i]));
NCCLCHECK(ncclGroupEnd());
//synchronizing on CUDA stream to complete NCCL communication
for (int i=0; i<nDev; i++)
CUDACHECK(cudaStreamSynchronize(s[i]));
//freeing device memory
for (int i=0; i<nDev; i++) {
CUDACHECK(cudaFree(sendbuff[i]));
CUDACHECK(cudaFree(recvbuff[i]));
}
//finalizing NCCL
for (int i=0; i<nDev; i++) {
ncclCommDestroy(comms[i]);
}
//finalizing MPI
MPICHECK(MPI_Finalize());
printf("[MPI Rank %d] Success \n", myRank);
return 0;
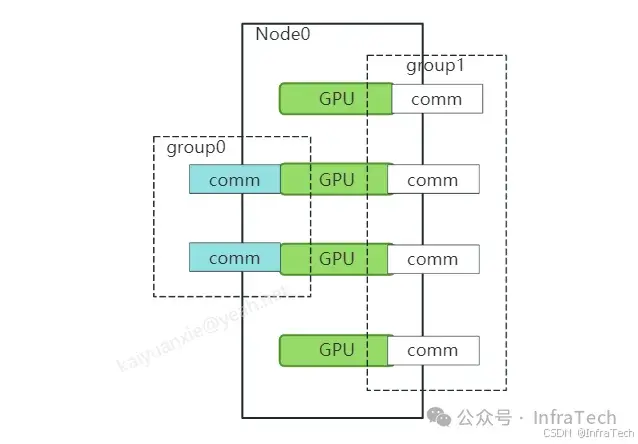
}示例4:设备参与不同通信组(Multiple communicators per device)
本例讲述的是一个设备被不同通信组调用方法。因为有些场景下需要通信组内的部分/全部GPU设备参与集群通信。如下所示,是一个有4卡的节点机器,创建了两个通信组。通信组0包含两个设备,通信组1包含四个设备。当然rank的索引在每个通信组内都会重新标记。通信组0(rank0、rank1)、通信组1(rank0、rank1、rank2、rank3)。
3 编译与运行
- 示例1:单线程操作多个设备,代码:nccl/multi_devices_per_thread.cu
- 示例2:单线程管理单个设备,代码:
nccl/one_device_per_thread.cu - 示例3:用MPI创建线程管理设备,代码:nccl/nccl_with_mpi.cu
官方用例中并未给出编译的示例,编译需要安装一些依赖包:
CUDA
NVIDIA NCCL (optimized for NVLink)
Open-MPI (option)这里我采用了nvidia的pytorch镜像(pytorch非必须)ngc-pytorch。里面包含所需依赖包,拉取镜像:
docker pull nvcr.io/nvidia/pytorch:24.07-py3运行容器:
sudo docker run --net=host --gpus=all -it -e UID=root --ipc host --shm-size="32g" \
-v /home/xky/:/home/xky \
-u 0 \
--name=nccl2 nvcr.io/nvidia/pytorch:24.07-py3 bash编译指令示例:
nvcc -lnccl -ccbin g++ -std=c++11 -O3 -g multi_devices_per_thread.cu -o multi_devices_per_thread用makefile可以同时编译多个文件,同时带上不同GPU架构标记,这里写了一个示例:nccl/Makefile
可以用如下指令完成编译:
make
# 支持MPI需要带个mpi参数,单独编译。
make mpi 运行:
./multi_devices_per_thread
./one_devices_per_thread如果使用MPI运行指令:
mpirun -n 6 --allow-run-as-root ./nccl_with_mpi参考:
- 本文代码:https://github.com/CalvinXKY/BasicCUDA/tree/master/nccl
- NCCL用例:https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/examples.html
- NCCLtest:https://github.com/NVIDIA/nccl-tests
InfraTech申明:未经允许不得转载!