第一章 PostgreSQL 概述
一、PostgreSQL 简介
1.1 PostgreSQL 介绍
PostgreSQL(通常简称为 Postgres)是一个功能强大的开源对象-关系型数据库系统,以其稳定性、标准兼容性、可扩展性和丰富的功能而广受开发者和企业的青睐。
核心特性:
- 开源免费:遵循 PostgreSQL 许可证(类似 MIT),可用于商业项目。
- ACID 兼容:支持事务的原子性、一致性、隔离性和持久性。
- SQL 标准兼容:高度兼容 ANSI/ISO SQL 标准,支持复杂查询、子查询、CTE、窗口函数等。
- 扩展性强:支持自定义数据类型、函数、操作符、索引方法(如 GiST、GIN、BRIN),可通过扩展(如 postgis、pg_trgm、uuid-ossp)增强功能。
- 多版本并发控制(MVCC):读写不阻塞,提高并发性能。
JSON/JSONB 支持:原生支持半结构化数据存储与查询,适合现代应用。 - 复制与高可用:支持流复制(Streaming Replication)、逻辑复制、WAL 归档、自动故障转移(配合 Patroni、repmgr 等工具)。
- 安全性:支持 SSL 连接、行级安全(RLS)、角色权限管理、审计日志等。
1.2 PostgreSQL 安装
1.2.1 下载
进入 PostgreSQL 官网:https://www.postgresql.org/,如下:
点击 Download 进入下载界面:
选择对应的平台,点击进入下载版本的选择:
下载可以使用 EDB(EnterpriseDB) 下载安装包,也可以下载压缩包免安装使用。使用 EDB 如下:

在 EDB 下载界面选择对应的版本和终端,点击下载即可
1.2.2 Windows 安装
点击已经下载完成的 Windows 平台安装包,进入安装界面:

点击 Next,进入修改安装路径:
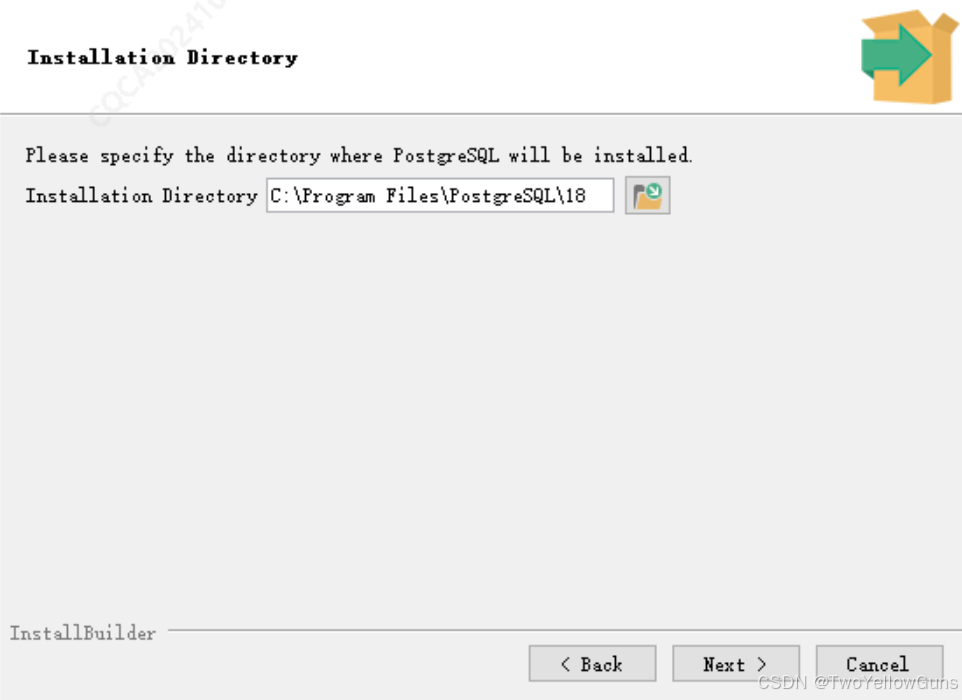
选择需要安装的组件:
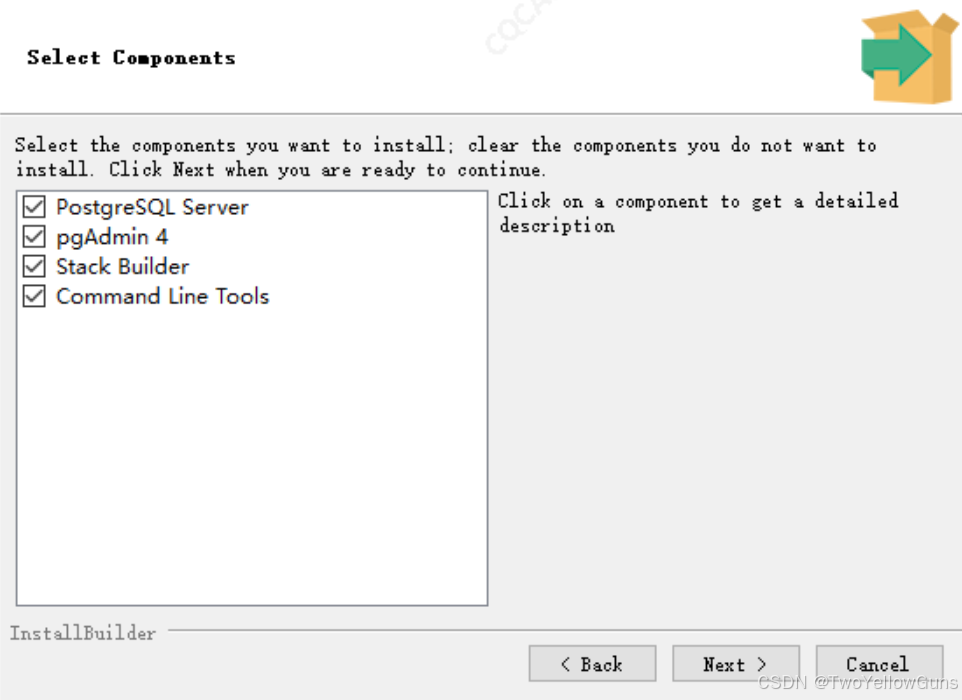
设置数据库的数据存储路径:
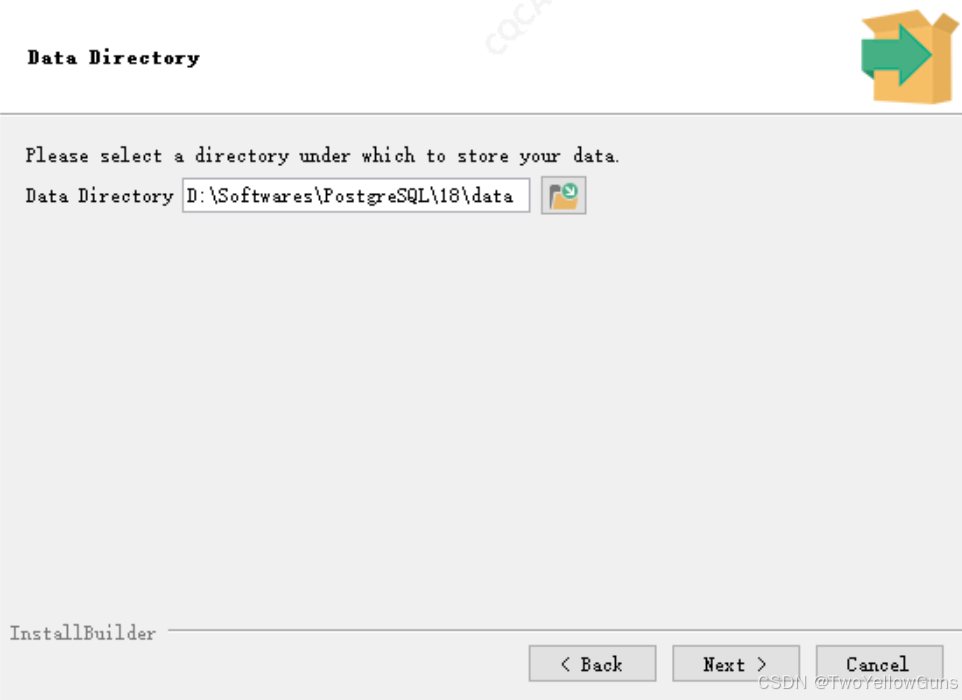
设置超级用户的密码:
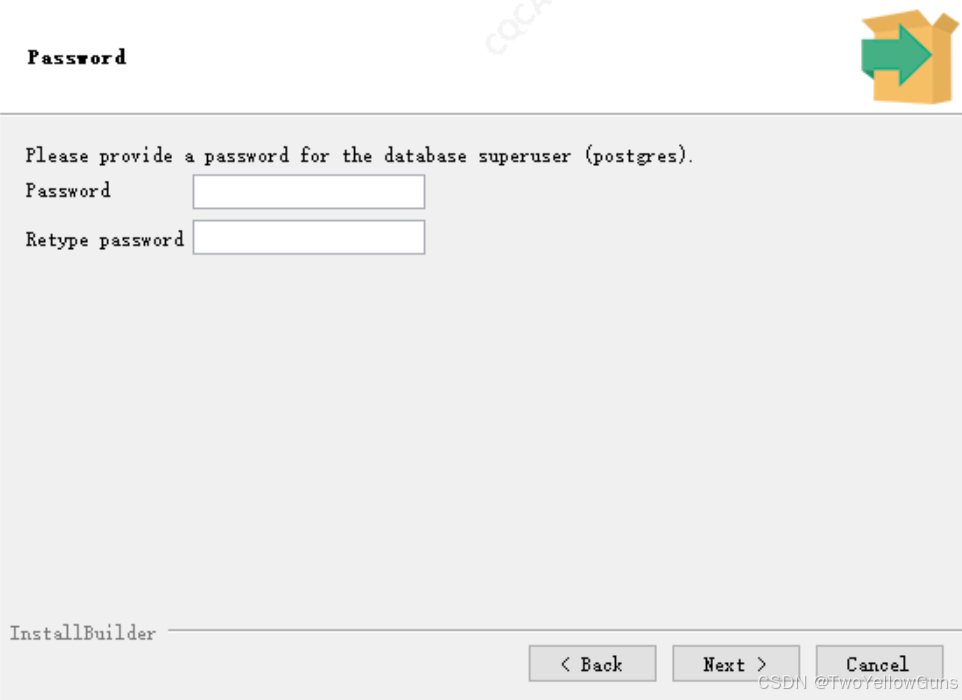
设置端口:
选择时区:
安装信息汇总预览:
准备安装确认:
进入实际安装过程:
安装完成:
安装成功之后,在应用程序内有如下信息:
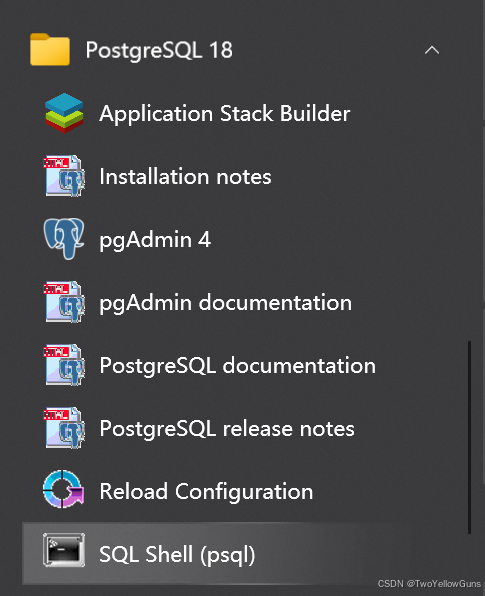
Application Stack Builder:一个图形化安装工具,用于安装 PostgreSQL 的附加组件(如扩展、驱动、客户端工具等)。它不是数据库本身,而是用来"构建"应用栈,比如通过它安装 pgAdmin、PostGIS、ODBC 驱动 等,类似于一个"软件包管理器"界面。Installation notes:查看 PostgreSQL 安装的详细信息。pgAdmin 4:PostgreSQL 的官方图形化管理工具(GUI)。pgAdmin documentation:pgAdmin 4 的官方帮助文档。PostgreSQL documentation:PostgreSQL 官方手册PostgreSQL release notes:查看 PostgreSQL 当前版本的新特性、修复内容和已知问题。Reload Configuration:重新加载 PostgreSQL 的配置文件(postgresql.conf和pg_hba.conf)。SQL Shell (psql):PostgreSQL 的命令行客户端工具(CLI)。
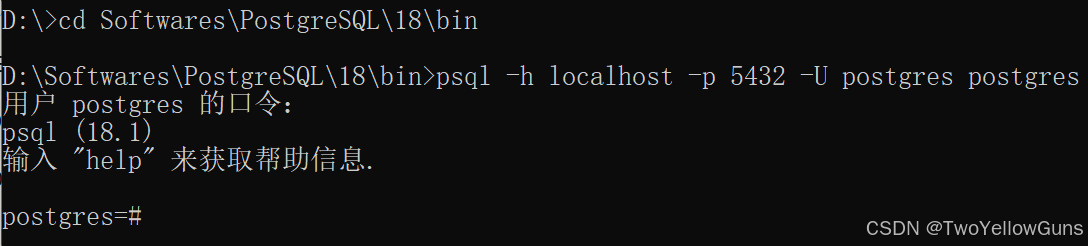
系统命令行连接数据库:
语法:
sql
psql -h [ip] -p 5432 -U [用户名] [数据库名]示例:
1.2.3 pgAdmin 工具
打开 pgAdmin 4,进入官方图形化管理工具,如下:

创建 Postgre SQL 连接:点击左侧的 Servers > Postgre SQL 10,输入超级用户密码
连接成功,界面如下:
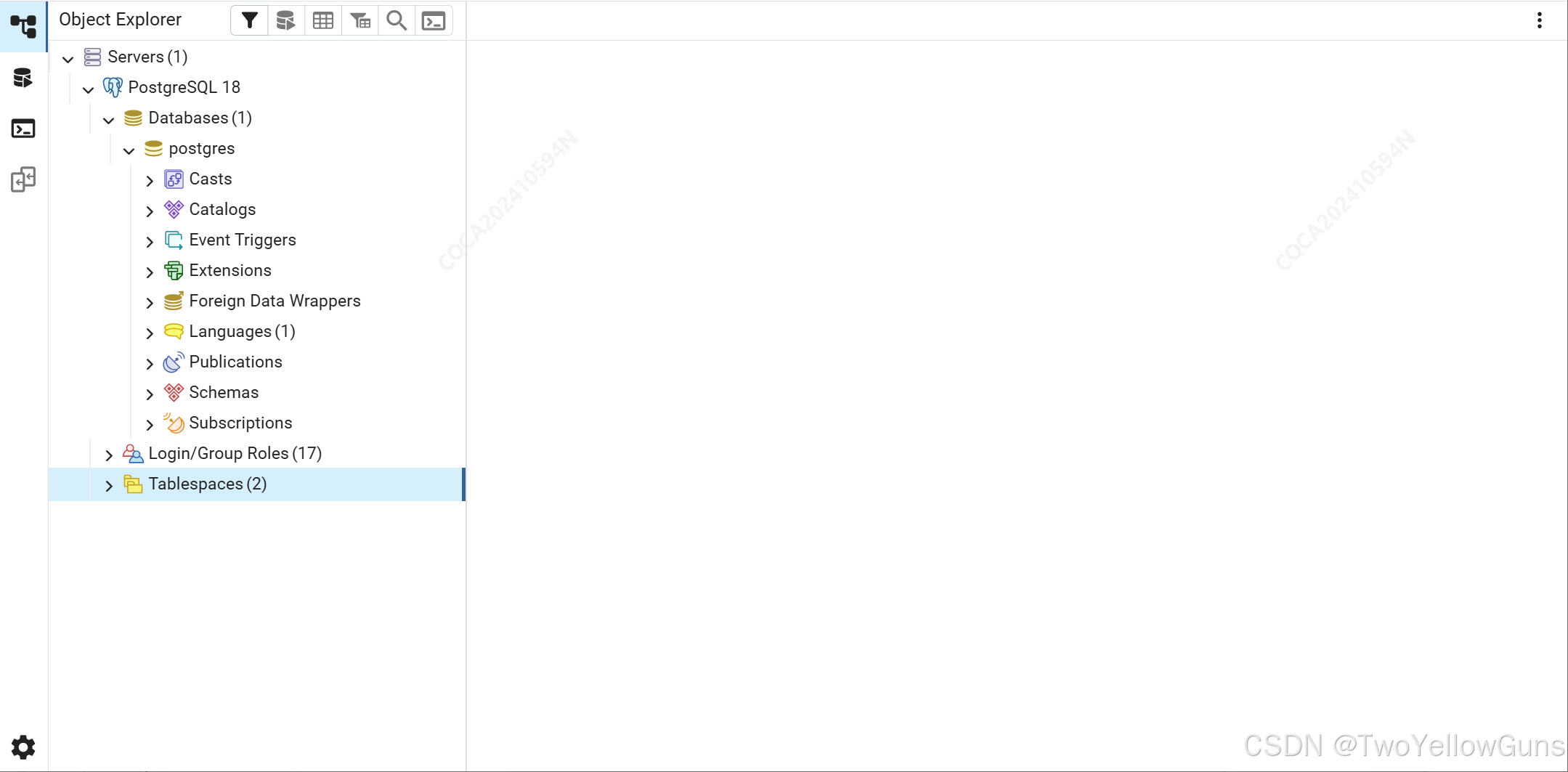
界面功能说明:
-
Servers (1):表示你当前连接了 1 个服务器实例,每个 Server 对应一个运行中的 PostgreSQL 服务进程(通常在本地或远程主机上)。 -
PostgreSQL 18:安装的 PostgreSQL 版本(这里是 18)。它是一个"服务器"节点,代表整个数据库系统,右键可执行操作:重启、停止、重新加载配置等。 -
Databases (1):当前服务器上的数据库个数,这里是一个。默认创建的是名为postgres的数据库(这是系统默认数据库),可以右键新建其他数据库。
postgres:这是 PostgreSQL 自动创建的默认数据库。Casts:类型转换规则,定义如何在不同数据类型之间自动转换(如 text → int)。通常不需要手动管理。Catalogs:系统表集合,包含所有系统表(如 pg_class, pg_attribute),记录数据库的元数据。普通用户很少直接操作。Event Triggers:事件触发器,在特定系统事件发生时执行函数(如 CREATE DATABASE、DROP TABLE)。高级功能,常用于审计。Extensions:扩展插件,已安装的扩展(如 postgis, uuid-ossp, hstore)。可通过右键添加新扩展。Foreign Data Wrappers (FDW):外部数据包装器,允许访问外部数据源(如 MySQL、CSV 文件、其他数据库)。适合跨系统集成。Languages (1):存储过程语言,支持的编程语言(如 PL/pgSQL, PL/Python, PL/Perl)。用于编写自定义函数。Publications:发布(复制源,逻辑复制中的"发布"端,指定哪些表要被复制出去。配合 Subscriptions 使用。Schemas:架构(命名空间,数据库内的逻辑分组,类似文件夹。默认有 public schema。可用于隔离不同模块的数据。Subscriptions:订阅(复制目标),逻辑复制中的"订阅"端,从其他数据库拉取数据。常用于主从同步或数据迁移。
-
Login/Group Roles (17):用户与角色,包括数据库用户(登录角色)、组角色及权限设置,初始会有 postgres 用户和其他系统角色。 -
Tablespaces (2):表空间,控制数据文件的物理存储位置。可用于将大表放在高速磁盘上。
二、PostgreSQL 数据类型
2.1 数值类型
PostgreSQL 中的数值类型如下:
| 名称 | 存储长度 | 描述 | 范围 | 别名 | 是否自增 |
|---|---|---|---|---|---|
smallint |
2 字节 | 小范围整数 | -32,768 到 +32,767 | int2 |
否 |
integer |
4 字节 | 常用整数(最通用) | -2,147,483,648 到 +2,147,483,647 | int, int4 |
否 |
bigint |
8 字节 | 大范围整数 | -9,223,372,036,854,775,808 到 +9,223,372,036,854,775,807 | int8 |
否 |
decimal |
可变长 | 用户指定精度,精确(金融推荐) | 最多 131,072 位数字(整数部分),小数最多 16,383 位 | 同 numeric |
否 |
numeric |
可变长 | 同 decimal,完全等价 |
同上 | 同 decimal |
否 |
real |
4 字节 | 单精度浮点,不精确 | 约 ±1.2×10⁻³⁸ 到 ±3.4×10³⁸ | float4 |
否 |
double precision |
8 字节 | 双精度浮点,不精确 | 约 ±2.2×10⁻³⁰⁸ 到 ±1.8×10³⁰⁸ | float8 |
否 |
smallserial |
2 字节 | 自增小整数(自动创建序列) | 1 到 32,767 | --- | 是 |
serial |
4 字节 | 自增整数(最常用主键) | 1 到 2,147,483,647 | --- | 是 |
bigserial |
8 字节 | 自增大整数(大数据量主键) | 1 到 9,223,372,036,854,775,807 | --- | 是 |
说明:
-
性能对比:整数运算最快 →
INT>BIGINT>NUMERIC>FLOAT -
NUMERIC的精度:NUMERIC(precision, scale)precision:总位数(整数+小数)scale:小数位数NUMERIC(5,2)表示最大 999.99,最小 -999.99,NUMERIC表示无限制(最大 131072 位)
-
类型选择:
- 金额、价格、税率推荐用
NUMERIC(p,s) - 科学计算、传感器数据推荐用
REAL/DOUBLE PRECISION - 计数、ID、索引推荐用整数类型(
INT,BIGINT) - 普通 ID 主键用
SERIAL(够用且节省空间),超大系统(如社交平台用BIGSERIAL,状态码、枚举值等小范围用SMALLINT节省空间
- 金额、价格、税率推荐用
2.2 货币类型
money 类型是 PostgreSQL 提供的一个专为存储货币金额而设计数据类型,但是不推荐使用。
numeric、int 和 bigint 类型的值可以转换为 money。
| 名字 | 存储容量 | 描述 | 范围 |
|---|---|---|---|
| money | 8 字节 | 货币金额 | -92233720368547758.08 到 +92233720368547758.07 |
money 类型在显示时会根据当前 lc_monetary(区域货币设置)自动格式化,lc_monetary 的设置如下:
sql
-- 设置区域(可选)
SET lc_monetary = 'en_US.UTF-8'; -- 美元格式,显示如$1,234.56
-- 或
SET lc_monetary = 'zh_CN.UTF-8'; -- 人民币格式(部分系统支持)money 为什么不推荐使用:
-
依赖操作系统
locale:显示和解析行为由lc_monetary决定,在不同服务器(开发/测试/生产)上可能表现不一致,若locale不支持,可能报错或显示乱码。 -
精度固定,无法适应所有货币:强制 2 位小数,无法表示日元(无小数)、科威特第纳尔(3 位小数)等,无法动态适配多币种系统。
-
应用层兼容性差:应用程序(如
Python、Node.js、Java)读取 money 字段时,常返回带格式的字符串(如$1,234.56),而非数值,需额外解析,容易出错。
2.3 字符类型
PostgreSQL 支持的字符类型如下:
| 类型 | 全称 / 别名 | 长度限制 | 存储方式 | 是否补空格 | 推荐使用场景 |
|---|---|---|---|---|---|
CHAR(n) |
CHARACTER(n) |
固定长度 n(1 ≤ n ≤ 10,737,41823) |
不足补空格至 n 字节 |
是 | 极少使用(如固定编码) |
VARCHAR(n) |
CHARACTER VARYING(n) |
最多 n 个字符 |
按实际内容存储 | 否 | 需要明确长度限制时 |
TEXT |
--- | 无限制(最大约 1 GB) | 按实际内容存储 | 否 | 绝大多数场景首选 |
说明:
-
CHAR(n):固定长度字符串,如果输入字符串长度 < n,自动在右侧填充空格。查询时,尾部空格会被忽略。 -
VARCHAR(n):可变长度带上限,最多存储 n 个字符(不是字节!UTF-8 下一个汉字 = 1 字符),超长会报错。 -
TEXT:无长度限制的字符串- PostgreSQL 中
TEXT和VARCHAR在内部使用完全相同的存储结构,性能与VARCHAR几乎无差别。 - PostgreSQL 对
TEXT做了高度优化:小字符串直接内联存储,大字符串自动压缩并移出主行(TOAST 技术)。 VARCHAR不加长度时(即VARCHAR)等价于TEXT。
- PostgreSQL 中
扩展:特殊字符类型
| 类型 | 说明 |
|---|---|
NAME |
系统内部使用(最长 64 字节),不建议用户使用 |
CITEXT |
大小写不敏感的 TEXT(需安装 citext 扩展,例:'Alice' = 'alice' → true |
2.4 日期/时间类型
PostgreSQL 支持的日期/时间类型如下:
| 类型 | 全称 | 存储大小 | 精度 | 是否含时区 | 范围 |
|---|---|---|---|---|---|
DATE |
--- | 4 字节 | 日 | 否 | 4713 BC ~ 5874897 AD |
TIME [WITHOUT TIME ZONE] |
--- | 8 字节 | 1 微秒 | 否 | 00:00:00 ~ 24:00:00 |
TIME WITH TIME ZONE |
TIMETZ |
12 字节 | 1 微秒 | 是 | 同上 |
TIMESTAMP [WITHOUT TIME ZONE] |
--- | 8 字节 | 1 微秒 | 否 | 4713 BC ~ 294276 AD |
TIMESTAMP WITH TIME ZONE |
TIMESTAMPTZ |
8 字节 | 1 微秒 | 是 | 同上 |
INTERVAL |
--- | 16 字节 | 1 微秒 | - | ±178,000,000 年 |
说明:
-
PostgreSQL 除
DATE类型外的其他日期/时间类型均支持微秒(1 μs = 0.000001秒)精度。 -
DATE:仅包含日期,格式为YYYY-MM-DD,且不包含时区信息。 -
TIME [WITHOUT TIME ZONE]:不带时区的时间,格式为HH:MI:SS[.US]。 -
TIME WITH TIME ZONE(TIMETZ:带时区的时间,格式为HH:MI:SS±TZ。 -
TIMESTAMP [WITHOUT TIME ZONE]:不带时区的日期+时间,格式为YYYY-MM-DD HH:MI:SS[.US]。如果应用部署在不同时区,同一时刻会存成不同值! -
TIMESTAMP WITH TIME ZONE:带时区的日期+时间,格式为YYYY-MM-DD HH:MI:SS±TZ,存储时全部转为UTC时间戳,查询时自动按当前会话时区转换显示。 -
INTERVAL:时间间隔,表示一段时间长度
常用函数与表达式
| 功能 | 表达式 |
|---|---|
| 当前时间(带时区) | NOW() 或 CURRENT_TIMESTAMP |
| 当前日期 | CURRENT_DATE |
| 当前时间(无日期) | CURRENT_TIME |
| 转换时区 | occurred_at AT TIME ZONE 'UTC' |
| 提取部分 | EXTRACT(HOUR FROM ts), DATE(ts) |
| 日期加减 | ts + INTERVAL '1 day' |
2.5 布尔类型
PostgreSQL 的 布尔类型(BOOLEAN) 用于表示逻辑真(True)/假值(False)。
| 名称 | 存储格式 | 描述 |
|---|---|---|
boolean |
1 字节 | true/false |
PostgreSQL 接受多种字符串或数值作为布尔值的输入:
表示 TRUE 的输入 |
表示 FALSE 的输入 |
|---|---|
'true', 't' |
'false', 'f' |
'yes', 'y' |
'no', 'n' |
'on' |
'off' |
1 |
0 |
所有输入不区分大小写(如 'True', 'YES', 'F' 均有效)。
2.6 枚举类型
PostgreSQL 的枚举类型(Enumerated Types,简称 ENUM) 是一种用户自定义的数据类型,用于定义一个固定、有序的字符串值集合。
枚举类型内部以整数形式高效存储(节省空间),但对外表现为字符串。
枚举类型支持排序(按定义顺序,不是字母顺序)。
与其他类型不同的是枚举类型需要使用 CREATE TYPE 命令创建,语法如下:
sql
-- 创建一个订单状态枚举
CREATE TYPE [enum_name] AS ENUM ([val1], [val2],[val3]);示例:
sql
CREATE TYPE week AS ENUM ('Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun');在数据表中使用枚举:
sql
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
week_day week NOT NULL DEFAULT 'Mon'
);枚举值的约束与安全:
- 只能插入定义过的值,插入其他的值会报错
ERROR: invalid input value for enum [enum_name]: [value]。 - 类型安全:不同枚举类型即使值相同也不能互换。
- PostgreSQL 不允许删除或修改已有枚举值,但可以从
v9.1+开始添加新值。
2.7 几何类型
2.7.1 几何类型介绍
PostgreSQL 的几何类型(Geometric Types) 是一组用于表示二维平面空间对象的内置数据类型。几何类型适用于简单的图形、坐标或区域表示,但不适用于专业的地理信息系统(GIS)应用------这类需求应使用 PostGIS 扩展。
PostgreSQL 支持的几何类型如下:
| 类型 | 描述 | 示例 |
|---|---|---|
POINT |
平面上的一个点 | (1.5, 2.0) |
LINE |
无限长的直线(较少用) | {(0,0),(1,1)} |
LSEG |
有限线段(Line Segment) | [(1,2),(3,4)] |
BOX |
矩形(由两个对角点定义) | (1,2),(3,4) |
PATH |
开放或闭合的路径(点序列) | [(0,0),(1,1),(2,2)] |
POLYGON |
封闭多边形 | ((0,0),(1,0),(1,1),(0,1)) |
CIRCLE |
圆(圆心 + 半径) | <(1,2),3> |
说明:
-
POINT表示点。 -
LSEG表示线段。 -
BOX表示矩形,由左下角和右上角(或任意两个对角点)定义。 -
PATH表示路径,分为开放路径和闭合路径:- 开放路径:首尾不相连,用
[...]表示 - 闭合路径:首尾相连,用
(...)表示
- 开放路径:首尾不相连,用
-
POLYGON表示多边形,必须是闭合的(首尾点可相同或不同,系统自动闭合)。 -
CIRCLE表示圆,由圆心和半径构成,格式为<(x,y),r>。
2.7.2 常用操作符
| 操作 | 说明 | 示例 |
|---|---|---|
<< |
||
&< |
||
&& |
相交(重叠) | box1 && box2 |
&> |
||
>> |
||
@> |
包含 | circle @> point |
<@ |
被包含 | point <@ circle |
~= |
||
+ / - |
平移 | point + point |
| ` | ` | |
area() |
面积 | area(box '(0,0),(2,2)') → 4 |
center() |
中心点 | center(circle '<(1,1),2>') → (1,1) |
2.7.3 索引支持
可对几何列创建 GiST 索引,加速空间查询
2.7.5 注意事项
-
仅限二维平面
- 不支持 3D(如高程)、球面(地球曲率)计算。
- 坐标只是数字,无单位、无投影、无地理意义。
-
精度有限
- 使用 double precision 存储坐标,适合工程/图形,不适合高精度测绘。
-
功能远弱于 PostGIS:
- 简单图形、游戏地图、CAD 草图可用内置几何类型
- 地图、LBS、导航、地理分析必须用 PostGIS
| 功能 | 几何类型 | PostGIS |
|---|---|---|
| 地理坐标(WGS84) | 不支持 | 支持 |
| 距离(米/千米) | 不支持(返回欧氏距离) | 支持(大圆距离) |
| 投影变换 | 不支持 | 支持 |
| 复杂空间关系(相接、包含等) | 基础支持 | 完整支持(DE-9IM) |
| GeoJSON 导入导出 | 不支持 | 支持 |
2.8 网络地址类型
2.8.1 网络地址类型介绍
网络地址类型专门用于存储和操作 IP 地址、子网和 MAC 地址,这些类型不仅节省空间,还支持丰富的操作符和函数,非常适合网络管理、安全审计、日志分析等场景。
PostgreSQL 支持的网络地址类型如下:
| 类型 | 描述 | 存储大小 | 示例 |
|---|---|---|---|
inet |
IPv4 或 IPv6 主机地址(可带 CIDR 掩码) | 7--19 字节 | '192.168.1.5', '2001:db8::1/64' |
cidr |
IPv4 或 IPv6 网络块(子网) | 7--19 字节 | '192.168.1.0/24', '2001:db8::/32' |
macaddr |
MAC 地址(IEEE 802 标准,6 字节) | 6 字节 | '08:00:2b:01:02:03' |
macaddr8 |
扩展 MAC 地址(8 字节,IEEE 802.2014+) | 8 字节 | '08:00:2b:01:02:03:04:05' |
说明:
-
inet:IP 地址(主机或带掩码)- 可表示单个主机(不带掩码)或带前缀的地址(常用于 ACL)
- 允许主机位非零(即使有掩码)
-
cidr:网络块(子网)- 严格表示网络地址:主机位必须全为 0
- 用于定义子网范围
- 常用于:IP 段分配表、VPC 网络配置、权限组按网段授权
-
macaddr:传统 MAC 地址(6 字节)- 支持多种输入格式,如
'08:00:2b:01:02:03'、'08-00-2b-01-02-03'、'08002b:010203'、'08002b010203' - 输出统一为
xx:xx:xx:xx:xx:xx格式
- 支持多种输入格式,如
-
macaddr8:扩展 MAC 地址(8 字节)- 用于 IEEE 802.2014+ 标准(如 InfiniBand、部分虚拟化环境)
- 格式:
xx:xx:xx:xx:xx:xx:xx:xx
2.8.2 常用操作符和函数
IP 地址操作:
| 操作 | 说明 | 示例 |
|---|---|---|
<< |
是否在子网内 | '192.168.1.5' << '192.168.1.0/24' → true |
>> |
子网是否包含该地址 | '192.168.1.0/24' >> '192.168.1.10' → true |
&& |
两个网络是否重叠 | '192.168.1.0/24' && '192.168.0.0/16' → true |
family() |
返回 IP 版本 | family('::1') → 6 |
masklen() |
获取掩码长度 | masklen('192.168.1.0/24') → 24 |
broadcast() |
广播地址 | broadcast('192.168.1.0/24') → 192.168.1.255 |
host() |
提取纯 IP(去掩码) | host('192.168.1.5/24') → '192.168.1.5' |
MAC 地址操作:
| 函数 | 说明 |
|---|---|
trunc(macaddr) |
清除最后 24 位(获取 OUI 厂商前缀) |
macaddr_not, macaddr_and, macaddr_or |
位运算 |
2.8.3 索引与性能
可创建普通 B-tree 索引(支持 =, <, > 等)
更推荐 GiST 或 SP-GiST 索引 用于子网包含查询
2.9 位串类型
2.9.1 位串类型介绍
PostgreSQL 的位串类型(Bit String Types) 用于存储和操作二进制位序列(0 和 1),适用于需要直接处理位数据的场景,如权限掩码、硬件通信、加密标志、压缩状态等。
PostgreSQL 支持的位串类型如下:
| 类型 | 全称 | 描述 | 长度限制 |
|---|---|---|---|
bit(n) |
bit varying |
固定长度位串,长度为 n |
必须指定 n(1 ≤ n ≤ 8388608) |
bit varying(n) |
varbit(n)(别名) |
可变长度位串,最大 n 位 |
可选 n;若省略则无上限(最大约 1 GB) |
说明:
-
bit(n):固定位数。- 插入时必须恰好
n位,否则报错或截断(取决于设置)常用于已知长度的位掩码 - 没有长度的
bit等效于bit(1)
- 插入时必须恰好
-
bit varying:可变长度。- 适合不确定位数的场景,更灵活,但略耗空间(需存储长度信息)
- 没有长度的
bit varying意思是没有长度限制
示例:
sql
-- 创建表:用 8 位表示 8 个布尔权限
CREATE TABLE user_roles (
id SERIAL,
perms BIT(8), -- 例如:00101101 表示启用第1、3、4、6项权限
data VARBIT(1024) -- 最多 1024 位
);
-- 插入(必须 8 位)
INSERT INTO user_roles (perms, data) VALUES (B'00101101', B'1010');
-- 或
INSERT INTO user_roles (perms, data) VALUES ('11000000', B'11110000111100001111');
-- 错误:长度不匹配
INSERT INTO user_roles (perms) VALUES ('101'); -- ERROR: bit string length 3 does not match type bit(8)
-- 无长度限制(慎用)
CREATE TABLE raw_bits (
payload VARBIT
);2.9.2 常用操作符与函数
操作:
| 操作 | 说明 | 示例 |
|---|---|---|
& |
按位 AND | B'1100' & B'1010' → B'1000' |
| ` | ` | 按位 OR |
# |
按位 XOR | B'1100' # B'1010' → B'0110' |
~ |
按位 NOT | ~B'1010' → B'0101'(注意:结果长度不变) |
<< / >> |
左/右移位 | B'1010' << 2 → B'1000' |
函数:
| 函数 | 说明 | 示例 |
|---|---|---|
length(bit) |
返回位数 | length(B'1010') → 4 |
substring(bit from m for n) |
截取子串 | substring(B'11001011' from 3 for 4) → B'0010' |
get_bit(bit, pos) |
获取某位(从 0 开始) | get_bit(B'1010', 1) → 0 |
set_bit(bit, pos, newval) |
设置某位 | set_bit(B'1010', 1, 1) → B'1110' |
2.9.3 存储与效率
存储方式:每 8 位对齐为 1 字节,bit(5) 占 1 字节,bit(9) 占 2 字节
空间效率高:比用 BOOLEAN[] 或多个 BOOLEAN 字段更紧凑
索引支持:可创建 B-tree 索引(适用于等值查询)
位运算无法使用普通索引加速(如 WHERE perms & B'1000' != B'0000'),需考虑表达式索引或应用层优化。
2.10 文本搜索类型
2.10.1 文本搜索类型介绍
PostgreSQL 的文本搜索类型(Text Search Types) 是其全文检索(Full-Text Search, FTS) 功能的核心组成部分,专为高效、智能地搜索自然语言文本而设计。
文本搜索类型远比简单的 LIKE '%keyword%' 更强大,支持:
- 词干提取(如 "running" → "run")
- 忽略停用词(如 "the", "and")
- 多语言分词
- 相关性排序(ranking)
- 短语与邻近搜索
PostgreSQL 支持的文本搜索类型如下:
| 类型 | 描述 | 用途 |
|---|---|---|
tsvector |
文档的标准化向量表示(包含词位 + 位置信息) | 存储被索引的文本内容 |
tsquery |
查询条件的结构化表示(包含关键词 + 逻辑操作符) | 表达搜索请求 |
tsvector:文档的内部表示。将原始文本解析、归一化后,生成一个有序的词位(lexeme)列表,每个词位附带其在文档中的出现位置(可选) 和权重(A/B/C/D)。
示例:
sql
SELECT to_tsvector('english', 'The quick brown fox jumps over the lazy dog.');
-- 结果:
-- 'brown':3 'dog':9 'fox':4 'jump':5 'lazi':8 'quick':2- 停用词
the、over被移除,jumps→ 词干jump,lazy→lazi(Porter 词干算法) - 数字表示词在原文中的位置(从1开始)
tsquery:查询的内部表示
支持的操作符:
| 操作符 | 含义 | 示例 |
|---|---|---|
& |
AND | 'cat & dog' |
| ` | ` | OR |
! |
NOT | 'cat & !dog' |
<-> |
邻近(相邻) | 'cat <-> dog' |
<N> |
N 个词以内 | 'cat <3> dog' |
这两个类型通常不直接由用户输入,而是通过函数(如 to_tsvector, to_tsquery)从普通文本转换而来。
2.10.2 基本使用流程
将文档转为 tsvector:
sql
CREATE TABLE articles (
id SERIAL,
title TEXT,
body TEXT,
-- 可选:预计算 tsvector 列(推荐用于大表)
doc_tsvector TSVECTOR
);
-- 插入时计算
INSERT INTO articles (title, body, doc_tsvector)
VALUES (
'How to use PostgreSQL',
'PostgreSQL is a powerful open-source database...',
to_tsvector('english', 'How to use PostgreSQL. PostgreSQL is a powerful open-source database...')
);执行搜索:
sql
-- 搜索包含 "postgres" 或 "database" 的文章
SELECT id, title
FROM articles
WHERE doc_tsvector @@ to_tsquery('english', 'postgres & database');@@是 匹配操作符:tsvector @@ tsquery返回BOOLEAN
2.10.3 相关性排序
使用 ts_rank() 或 ts_rank_cd() 计算匹配度:
sql
SELECT
id,
title,
ts_rank(doc_tsvector, query) AS rank
FROM articles,
to_tsquery('english', 'postgres & database') AS query
WHERE doc_tsvector @@ query
ORDER BY rank DESC;2.10.4 索引
对 tsvector 列创建 GIN 索引(最常用)或 GiST 索引:
sql
-- GIN:适合静态数据,查询快,更新慢
CREATE INDEX idx_articles_fts ON articles USING GIN (doc_tsvector);
-- GiST:适合频繁更新,查询稍慢
CREATE INDEX idx_articles_fts_gist ON articles USING GiST (doc_tsvector);2.10.5 高级功能
多字段搜索:
sql
-- 合并标题和正文,给标题更高权重
UPDATE articles SET doc_tsvector =
setweight(to_tsvector('english', title), 'A') ||
setweight(to_tsvector('english', body), 'B');权重:A > B > C > D(默认 D),查询时可按权重调整排名
高亮匹配结果:
sql
SELECT
ts_headline('english', body, to_tsquery('english', 'postgres'))
FROM articles
WHERE doc_tsvector @@ to_tsquery('english', 'postgres');返回:"...powerful open-source PostgreSQL..."
多语言支持:内置 20+ 语言的分词器(english, chinese 需扩展),中文需配合 zhparser 或 jieba 扩展
PostgreSQL 原生不支持中文分词!需安装扩展:
- 方案 1:
zhparser+SCWS - 方案 2:应用层分词 +
simple配置
2.11 UUID 类型
2.11.1 UUID 类型介绍
PostgreSQL 的 UUID 类型 是一种专门用于存储通用唯一标识符(Universally Unique Identifier) 的数据类型。它在分布式系统、微服务架构、高并发场景中被广泛使用,因其全局唯一性、无序性和安全性,常作为主键替代自增整数(SERIAL/BIGINT)。
UUID 存储大小为 16 字节(128 位),标准格式为 32 位十六进制 + 4 个连字符:xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx,例如:a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11。
PostgreSQL 本身不提供 UUID 生成函数,但可通过内置扩展实现:
sql
-- 启用 uuid-ossp 扩展,首次使用需创建(需超级用户权限)
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";2.11.2 常用函数
| 函数 | 说明 | 示例 |
|---|---|---|
uuid_generate_v4() |
随机 UUID(最常用) | a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11 |
uuid_generate_v1() |
基于 MAC 地址 + 时间戳 | 可排序,但泄露主机信息 |
gen_random_uuid() |
来自 pgcrypto 扩展(更安全) |
推荐用于生产环境 |
使用示例:
sql
CREATE EXTENSION IF NOT EXISTS "pgcrypto";
CREATE TABLE users (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email TEXT NOT NULL UNIQUE,
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- 插入(无需指定 id)
INSERT INTO users (email) VALUES ('alice@example.com');
-- 查询
SELECT * FROM users;
-- id: "f47ac10b-58cc-4372-a567-0e02b2c3d479"2.12 XML 类型
PostgreSQL 的 XML 类型 用于存储和操作 XML(可扩展标记语言)文档或片段。它支持验证、解析、XPath 查询、XSLT 转换等高级功能,适用于需要处理结构化 XML 数据的场景(如与旧系统集成、医疗/金融行业标准数据交换等)。
XML 类型内部以二进制格式高效存储(非纯文本),可存储完整 XML 文档或 XML 片段。
示例:
sql
CREATE TABLE documents (
id SERIAL,
content XML
);XML 通过类型修饰符可以对内容进行验证控制:
| 用法 | 说明 |
|---|---|
XML |
默认:仅检查是否良好格式(well-formed) |
XML DOCUMENT |
必须是完整 XML 文档(有单个根元素) |
XML CONTENT |
允许文档或片段(默认行为) |
XML STRIP WHITESPACE |
自动去除无意义空白(实验性) |
函数:
| 函数 | 说明 |
|---|---|
xmlelement(name, content) |
创建元素 |
xmlforest(col1, col2) |
将多列转为子元素 |
xmlconcat(...) |
拼接 XML 片段 |
table_to_xml(tbl) |
整表转 XML |
索引:
2.13 JSON 类型
PostgreSQL 提供了两种强大的 JSON 数据类型:JSON 和 JSONB,用于高效存储和查询半结构化数据。
| 特性 | JSON |
JSONB |
|---|---|---|
| 存储格式 | 原始文本(保留空格、键顺序、重复键) | 二进制格式(解析后存储) |
| 存储空间 | 较大 | 更小(无冗余) |
| 写入性能 | 快(直接存字符串) | 稍慢(需解析) |
| 读取/查询性能 | 慢(每次需解析) | 极快(已解析) |
| 索引支持 | 不支持 GIN 索引 | 支持 GIN 索引 |
| 重复键处理 | 保留所有 | 仅保留最后一个 |
| 键顺序 | 保留 | 不保留(按哈希排序) |
| 适用场景 | 需要精确原始格式(如审计日志) | 绝大多数场景 |
操作符与函数:
| 操作符 | 说明 | 示例 | 结果类型 |
|---|---|---|---|
-> |
返回 JSON 对象 | attributes -> 'brand' |
jsonb |
->> |
返回文本 | attributes ->> 'brand' |
text |
#> |
按路径数组取值 | attributes #> '{specs, screen}' |
jsonb |
#>> |
按路径数组取文本 | attributes #>> '{specs, screen}' |
text |
索引:
- GIN 索引:支持:
?,?|,?&,@>,<@等操作符,适合动态 schema、未知查询模式 - 表达式索引
JSONB路径索引
2.14 数组类型
PostgreSQL 的数组类型(Array Types) 是其最具特色的功能之一,允许在单个字段中存储多个同类型值,如整数列表、标签集合、坐标序列等。
所有内置类型和用户自定义类型都支持数组,语法为 type[](如 INT[], TEXT[], UUID[])。
数组类型支持多维数组(如 INT[][]),数组的长度是可变可,不需要预定义大小,数组的索引从 1 开始(不是 0!)。
示例:
sql
-- 创建表
CREATE TABLE posts (
id SERIAL PRIMARY KEY,
title TEXT,
tags TEXT[], -- 字符串数组
ratings INT[], -- 整数数组
matrix FLOAT[][] -- 二维浮点数组
);
-- 插入数据
-- 方式1:使用花括号(标准 SQL)
INSERT INTO posts (tags, ratings)
VALUES ('{postgresql,sql,database}', '{5,4,5,3}');
-- 方式2:使用 ARRAY 构造器(更灵活)
INSERT INTO posts (tags, ratings)
VALUES (ARRAY['json','nosql'], ARRAY[4,5]);
-- 二维数组
INSERT INTO posts (matrix)
VALUES ('{{1.0,2.0},{3.0,4.0}}');2.15 复合类型
PostgreSQL 的复合类型(Composite Types) 是一种用户自定义的数据结构,类似于 C 语言的 struct、Python 的 namedtuple 或 Java 的轻量级 POJO。
复合类型将多个字段组合成一个单一值,用于表示复杂对象(如地址、坐标、范围等),并在表、函数、变量中使用。
创建复合类型使用 CREATE TYPE ... AS 语句,示例:
sql
-- 定义一个"地址"复合类型
CREATE TYPE address AS (
street TEXT,
city TEXT,
postal_code TEXT,
country TEXT
);
-- 定义一个"价格范围"
CREATE TYPE price_range AS (
min_price NUMERIC(10,2),
max_price NUMERIC(10,2)
);
-- 使用符合类型字段
CREATE TABLE companies (
id SERIAL PRIMARY KEY,
name TEXT,
headquarters address, -- 使用复合类型
budget price_range
);
-- 插入数据
INSERT INTO companies (name, headquarters, budget) VALUES
('Acme Corp',
('123 Main St', 'New York', '10001', 'USA')::address,
(50000.00, 200000.00)::price_range
);- 复合类型中的字段可为任意 PostgreSQL 类型。
- 值必须用
(...)包裹,并显式转换为类型(如::address),否则会被当作行字面量。
2.16 范围类型
PostgreSQL 的范围类型(Range Types) 是一种强大而优雅的数据类型,用于表示连续区间,如时间范围、数值区间、IP 地址段等。它原生支持区间包含、重叠、相邻等操作,并可配合 GiST 索引 实现高效查询,非常适合日程安排、价格策略、资源分配等场景。
PostgreSQL 支持的范围类型如下:
| 范围类型 | 对应元素类型 | 示例 |
|---|---|---|
int4range |
INTEGER |
[10, 20) |
int8range |
BIGINT |
[100, 200] |
numrange |
NUMERIC |
(1.5, 5.0] |
tsrange |
TIMESTAMP |
["2025-01-01 09:00", "2025-01-01 17:00") |
tstzrange |
TIMESTAMPTZ |
["2025-01-01 09:00+08", "2025-01-01 17:00+08") |
daterange |
DATE |
["2025-01-01", "2025-01-31"] |
-
所有范围类型都支持 开区间 ( / 闭区间 [ 的任意组合。
[a, b]:闭区间:包含 a 和 b(a, b):开区间:不包含 a 和 b[a, b):左闭右开:包含 a,不包含 b(a, b]:左开右闭:不包含 a,包含 b[a,):从 a 到正无穷(,b]:从负无穷到 bempty:空范围(长度为 0)
示例:
sql
CREATE TABLE room_bookings (
id SERIAL PRIMARY KEY,
room_name TEXT,
during tstzrange -- 使用带时区的时间范围
);
-- 插入一个预订
INSERT INTO room_bookings (room_name, during) VALUES (
'Meeting Room A',
tstzrange('2025-12-05 14:00+08', '2025-12-05 15:30+08')
);操作符与函数:
区间关系判断:
| 操作符 | 含义 | 示例 |
|---|---|---|
&& |
重叠(有交集) | r1 && r2 |
@> |
包含(左包含右) | during @> '2025-12-05 14:30+08'::timestamptz |
<@ |
被包含 | '2025-12-05'::date <@ during |
<< |
严格在左(不接触) | r1 << r2 |
>> |
严格在右 | r1 >> r2 |
&< |
不延伸到右边(左 ≤ 右.end) | 用于"结束前"查询 |
&> |
不延伸到左边 | 用于"开始后"查询 |
| `- | -` | 相邻(如 1,2 和 2,3) |
函数:
| 函数 | 说明 |
|---|---|
lower(range) |
下界 |
upper(range) |
上界 |
isempty(range) |
是否为空 |
range_merge(r1, r2) |
合并两个重叠/相邻范围 |
索引:对范围列创建 GiST 索引 以加速重叠、包含等查询
自定义范围类型
2.17 对象标识符类型
PostgreSQL 的对象标识符类型(Object Identifier Types) 是一组用于内部系统管理的特殊数据类型,主要用于存储数据库系统目录(system catalogs)中的 OID(Object Identifier)值。
对象标识符类型在普通应用开发中极少直接使用,但在系统监控、扩展开发或深入理解 PostgreSQL 内部机制时非常重要。
OID(Object Identifier)在 PostgreSQL 早期用于唯一标识系统对象(如表、函数、类型等)的 32 位无符号整数,从 PostgreSQL 8.1 起,默认创建的用户表不再自动生成 OID 列(default_with_oids = off),因为:
- OID 空间有限(约 40 亿,可能溢出)
- 不适合分布式环境
- 主键应显式定义(如 SERIAL 或 UUID)
PostgreSQL 支持的对象标识符类型如下:
| 类型 | 描述 | 典型用途 |
|---|---|---|
oid |
通用对象 ID | 系统表主键(如 pg_class.oid) |
regproc |
注册的函数名 | pg_proc.oid 的别名,显示为函数名 |
regprocedure |
带参数的函数签名 | 如 'substr(text,integer)' |
regoper |
操作符名 | 如 '+' |
regoperator |
带类型的完整操作符 | 如 '+(integer,integer)' |
regclass |
表/索引/序列名 | 最常用!可安全转换为表名 |
regtype |
数据类型名 | 如 'int4', 'text' |
regconfig |
文本搜索配置名 | 如 'english' |
regdictionary |
文本搜索字典名 | 如 'simple' |
2.18 伪类型
PostgreSQL 类型系统包含一系列特殊用途的条目, 它们按照类别来说叫做伪类型。伪类型不能作为字段的数据类型, 但是它可以用于声明一个函数的参数或者结果类型。 伪类型在一个函数不只是简单地接受并返回某种SQL 数据类型的情况下很有用。
PostgreSQL 支持的伪类型如下:
| 名字 | 描述 |
|---|---|
any |
表示一个函数接受任何输入数据类型。 |
anyelement |
表示一个函数接受任何数据类型。 |
anyarray |
表示一个函数接受任意数组数据类型。 |
anynonarray |
表示一个函数接受任意非数组数据类型。 |
anyenum |
表示一个函数接受任意枚举数据类型。 |
anyrange |
表示一个函数接受任意范围数据类型。 |
cstring |
表示一个函数接受或者返回一个空结尾的 C 字符串。 |
internal |
表示一个函数接受或者返回一种服务器内部的数据类型。 |
language_handler |
一个过程语言调用处理器声明为返回 language_handler。 |
fdw_handler |
一个外部数据封装器声明为返回 fdw_handler。 |
record |
标识一个函数返回一个未声明的行类型。 |
trigger |
一个触发器函数声明为返回 trigger。 |
void |
表示一个函数不返回数值。 |
opaque |
一个已经过时的类型,以前用于所有上面这些用途。 |
三、PostgreSQL 运算符
3.1 算术运算符
PostgreSQL 支持如下算术运算符:假设变量 a 为 2,变量 b 为 3
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | a + b 结果为 5 |
| - | 减 | a - b 结果为 -1 |
| * | 乘 | a * b 结果为 6 |
| / | 除 | b / a 结果为 1 |
| % | 模(取余) | b % a 结果为 1 |
| ^ | 指数 | a ^ b 结果为 8 |
| |/ | 平方根 | |/ 25.0 结果为 5 |
| ||/ | 立方根 | ||/ 27.0 结果为 3 |
| ! | 阶乘 | 5 ! 结果为 120 |
| !! | 阶乘(前缀操作符) | !! 5 结果为 120 |
3.2 比较运算符
PostgreSQL 支持如下比较运算符:假设变量 a 为 10,变量 b 为 20
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 等于 | (a = b) 为 false。 |
| != | 不等于 | (a != b) 为 true。 |
| <> | 不等于 | (a <> b) 为 true。 |
| > | 大于 | (a > b) 为 false。 |
| < | 小于 | (a < b) 为 true。 |
| >= | 大于等于 | (a >= b) 为 false。 |
| <= | 小于等于 | (a <= b) 为 true。 |
3.3 逻辑运算符
PostgreSQL 支持如下逻辑运算符:
AND:逻辑与运算符。如果两个操作数都非零,则条件为真。NOT:逻辑非运算符。用来逆转操作数的逻辑状态,如果条件为真则逻辑非运算符将使其为假。OR:逻辑或运算符。如果两个操作数中有任意一个非零,则条件为真。
AND 和 OR 示例:
| a | b | a AND b | a OR b |
|---|---|---|---|
| TRUE | TRUE | TRUE | TRUE |
| TRUE | FALSE | FALSE | TRUE |
| TRUE | NULL | NULL | TRUE |
| FALSE | FALSE | FALSE | FALSE |
| FALSE | NULL | FALSE | NULL |
| NULL | NULL | NULL | NULL |
NOT 示例:
| a | NOT a |
|---|---|
| TRUE | FALSE |
| FALSE | TRUE |
| NULL | NULL |
3.4 按位运算符
位运算符作用于位,并逐位执行操作。PostgreSQL 支持如下按位运算符:假设变量 A 的值为 60,变量 B 的值为 13
| 运算符 | 描述 | 运算规则 | 实例 |
|---|---|---|---|
& |
按位与操作,按二进制位进行"与"运算。 | 0&0=0; 0&1=0; 1&0=0; 1&1=1; |
A & B = 12,即为 0000 1100 |
| ` | ` | 按位或运算符,按二进制位进行"或"运算。 | `0 |
# |
异或运算符,按二进制位进行"异或"运算。 | 0#0=0; 0#1=1; 1#0=1; 1#1=0; |
A # B = 49,即为 0011 0001 |
~ |
取反运算符,按二进制位进行"取反"运算。 | ~1=0; ~0=1; |
~A = -61,即为 1100 0011,一个有符号二进制数的补码形式。 |
<< |
二进制左移运算符。将一个运算对象的各二进制位全部左移若干位(左边的二进制位丢弃,右边补0)。 | A << 2 = 240,即为 1111 0000 |
|
>> |
二进制右移运算符。将一个数的各二进制位全部右移若干位,正数左补0,负数左补1,右边丢弃。 | A >> 2 = 15,即为 0000 1111 |
第二章 PostgreSQL 语法
一、PostgreSQL 数据库表操作
1.1 数据库操作
1.1.1 创建数据库
PostgreSQL 创建数据库可以用以下三种方式:
- 使用
CREATE DATABASE语句来创建。 - 使用
createdb命令来创建。 - 使用 pgAdmin 工具等可视化工具。
CREATE DATABASE 命令需要在 PostgreSQL 命令窗口来执行,其语法如下:
sql
CREATE DATABASE dbname;示例:
sql
CREATE DATABASE mysql_test_db1;createdb 是一个 SQL 命令 CREATE DATABASE 的封装,其语法如下:
sql
createdb [option...] [dbname [description]]参数说明:
-
dbname:要创建的数据库名。 -
description:关于新创建的数据库相关的说明。 -
options:参数可选项,可以是以下值:-D tablespace:指定数据库默认表空间。-e:将createdb生成的命令发送到服务端。-E encoding:指定数据库的编码。-l locale:指定数据库的语言环境。-T template:指定创建此数据库的模板。--help:显示createdb命令的帮助信息。-h host:指定服务器的主机名。-p port:指定服务器监听的端口,或者 socket 文件。-U username:连接数据库的用户名。-w:忽略输入密码。-W:连接时强制要求输入密码。
示例:
sql
createdb -h localhost -p 5432 -U postgres mysql_test_db21.1.2 选择数据库
在 PostgreSQL 命令窗口中,通过命令 \n 可以查询已经存在的数据库,如下:

如果要使用具体的数据库,可以使用命令 \c [dbName],如下:

1.1.3 删除数据库
PostgreSQL 提供三种删除数据库的方式:
- 使用
DROP DATABASE语句来删除。 - 使用
dropdb命令来删除。 - 使用
pgAdmin等可视化工具。
DROP DATABASE 语句:
-
DROP DATABASE语句会删除数据库的系统目录项并且删除包含数据的文件目录,只能由超级管理员或数据库拥有者执行。 -
DROP DATABASE语句命令需要在 PostgreSQL 命令窗口来执行。
DROP DATABASE 语法如下:
sql
DROP DATABASE [ IF EXISTS ] name参数说明:
-
IF EXISTS:如果数据库不存在则发出提示信息,而不是错误信息吗,不添加这个选项的时候,如果删除的数据库不存在则会报错。 -
name:要删除的数据库的名称。
示例:
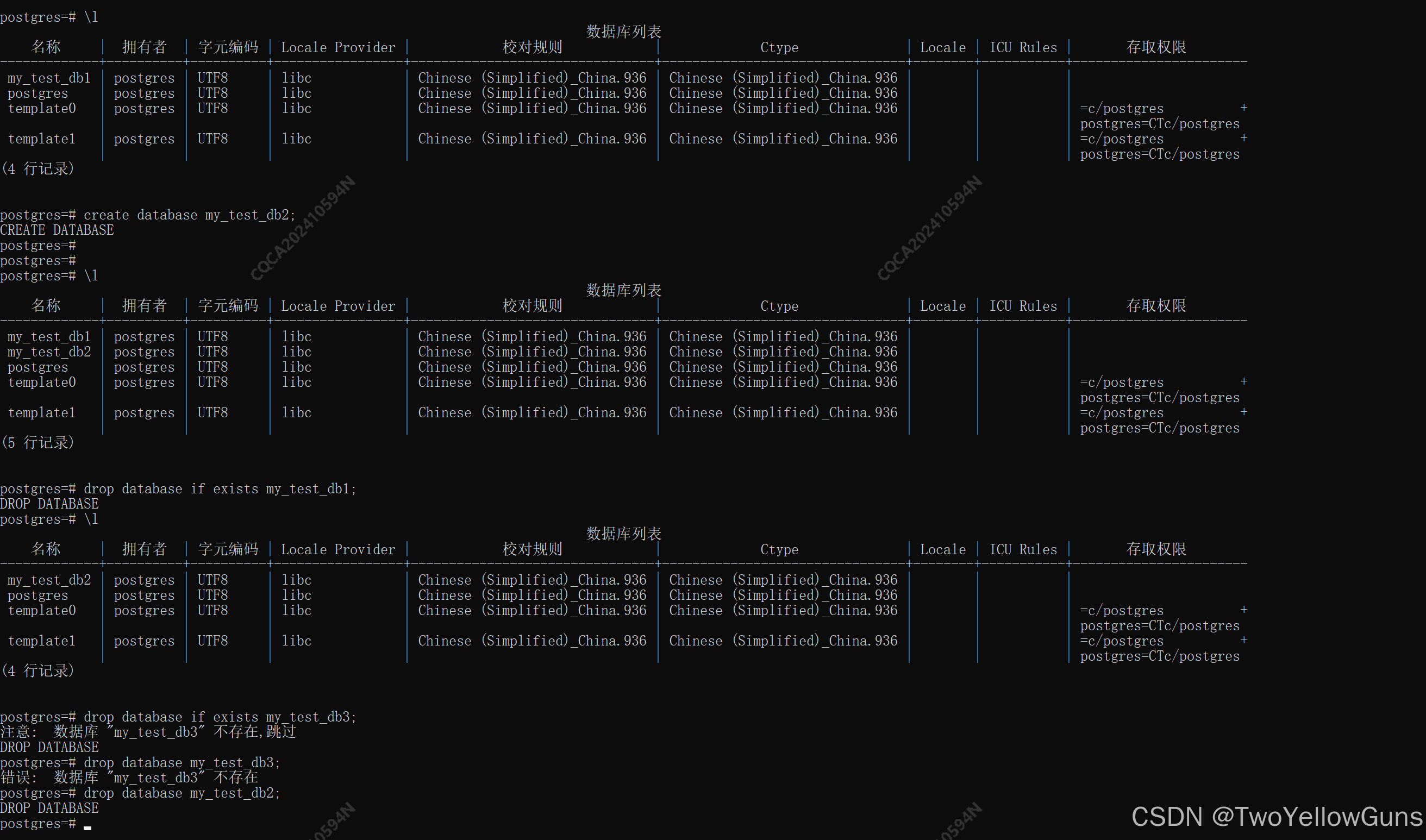
dropdb 命令:
dropdb是DROP DATABASE的包装器, 用于删除 PostgreSQL 数据库。dropdb命令一般只能由超级管理员或数据库拥有者执行。
dropdb 语法如下:
sql
dropdb [connection-option...] [option...] dbname参数说明:
-
dbname:要删除的数据库名。 -
options:参数可选项,可以是以下值:-e:显示dropdb生成的命令并发送到数据库服务器。-i:在做删除的工作之前发出一个验证提示。-V:打印dropdb版本并退出。--if-exists:如果数据库不存在则发出提示信息,而不是错误信息。--help:显示有关dropdb命令的帮助信息。-h host:指定运行服务器的主机名。-p port:指定服务器监听的端口,或者 socket 文件。-U username:连接数据库的用户名。-w:连接时忽略输入密码。-W:连接时强制要求输入密码。--maintenance-db=dbname:删除数据库时指定连接的数据库,默认为postgres,如果它不存在则使用template1。
示例:

1.2 数据表操作
1.2.1 创建表
PostgreSQL 使用 CREATE TABLE 语句来创建数据库表,语法如下:
sql
CREATE TABLE [table_name] (
column1 datatype,
column2 datatype,
column3 datatype,
.....
columnN datatype,
PRIMARY KEY( 一个或多个列 )
);CREATE TABLE 在当前数据库创建一个新的空白表,该表将由发出此命令的用户所拥有。
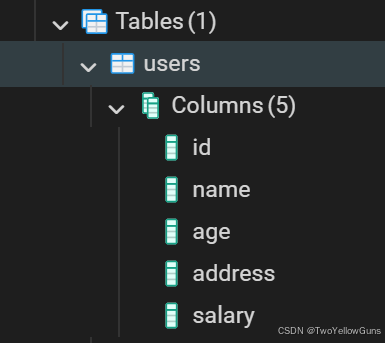
示例:
sql
CREATE TABLE USERS (
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);创建结果:
1.2.2 查看表
在 PostgreSQL 命令窗口中,可以通过命令 \d 查询已有的表,通过命令 \d tablename 查看具体的表格信息:
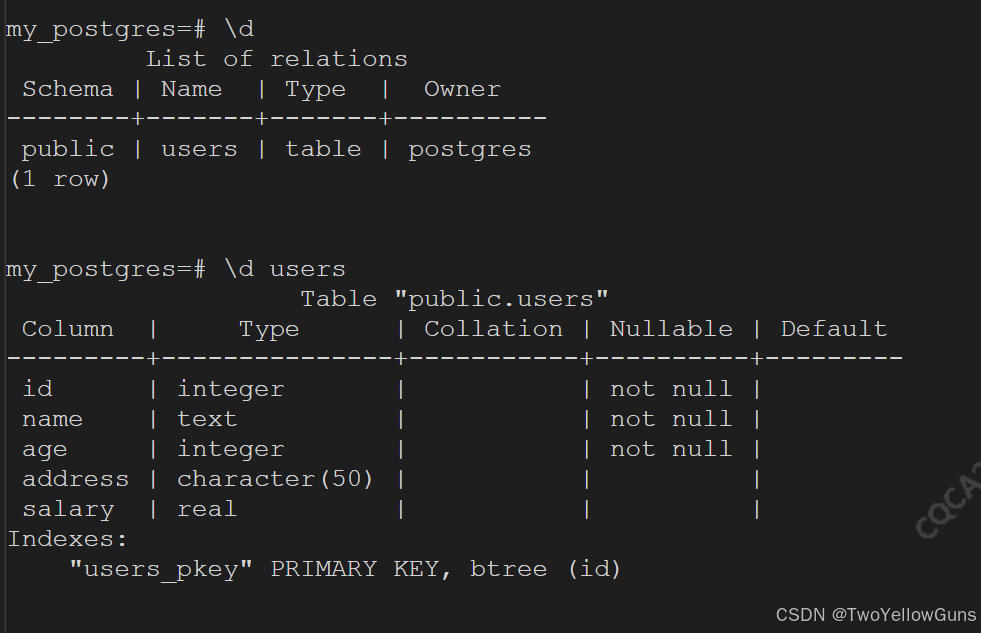
1.2.3 删除表
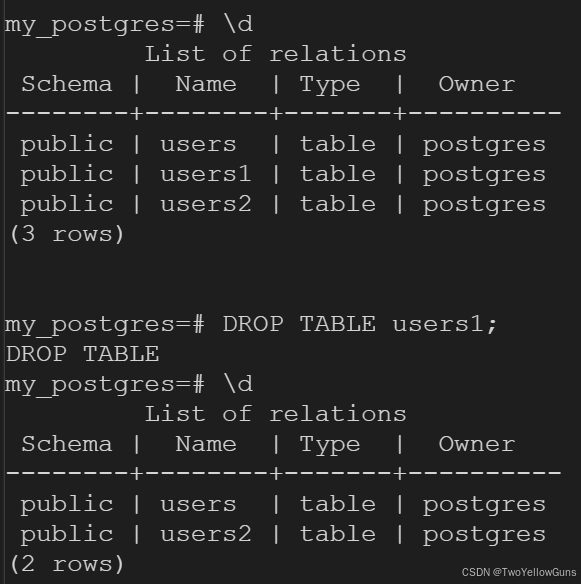
PostgreSQL 使用 DROP TABLE 语句来删除表格,包含表格数据、规则、触发器等。语法如下:
sql
DROP TABLE table_name;示例:
1.3 SCHEMA
在 PostgreSQL 中,模式(Schema) 是数据库对象(如表、视图、函数、索引等)的命名空间容器。它提供了一种逻辑分组机制,用于组织和管理数据库对象,同时支持多用户环境下的权限控制和命名隔离。
一个数据库可以包含多个模式,每个模式可以包含多个数据库对象(如表、序列、函数等)。默认情况下,每个新数据库都包含一个名为 public 的模式,用户在未指定模式名时,默认使用 search_path 中的第一个可用模式(通常是 public)。
1.3.1 创建 SCHEMA
PostgreSQL 使用 CREATE SCHEMA 语句创建模式,语法如下:
sql
CREATE SCHEMA myschema;
-- 或者指定拥有者
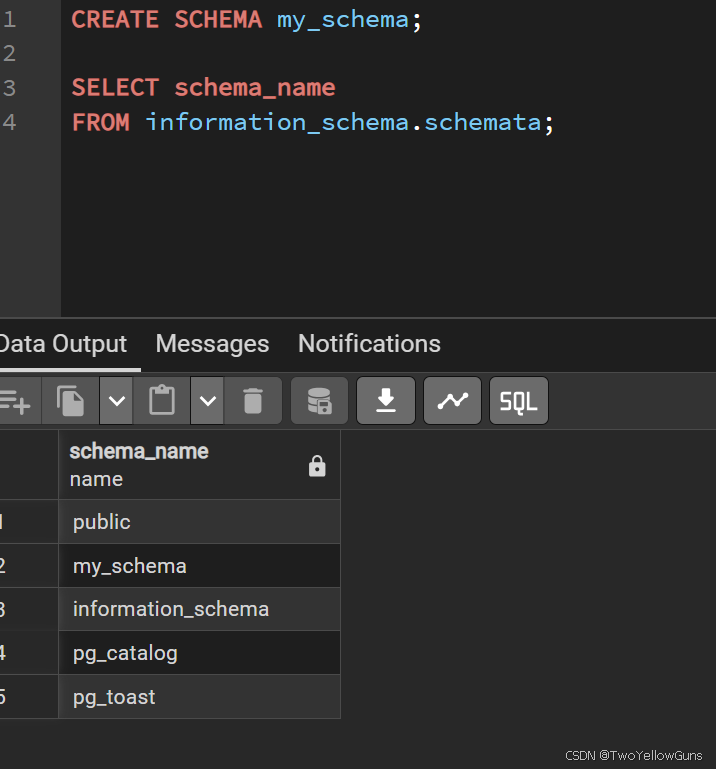
CREATE SCHEMA schema_name AUTHORIZATION user_name;1.3.2 查看 SCHEMA
在 PostgreSQL 命令窗口通过 \dn 命令可以查看当前的所有 SCHEMA,也可以通过 SQL 语句查看,语法如下
sql
\dn -- 在 psql 命令行中
-- 或
SELECT schema_name
FROM information_schema.schemata;示例:
1.3.3 删除 SCHEMA
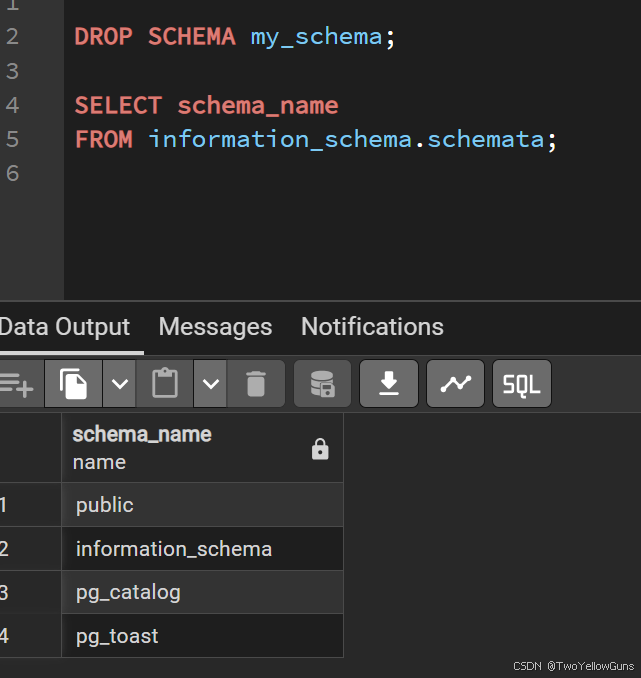
PostgreSQL 使用 DROP SCHEMA 语句删除模式,语法如下:
sql
-- 删除空模式
DROP SCHEMA schema_name;
-- 删除模式及其所有对象(级联删除)
DROP SCHEMA schema_name CASCADE;示例:
1.4 ALTER 命令
在 PostgreSQL 中,ALTER TABLE 命令用于添加,修改,删除一张已经存在表的列,也可以用来添加和删除约束。
ALTER TABLE 命令语法:
sql
ALTER TABLE [IF EXISTS] table_name
action [, ...];语法详解:
table_name:要修改的表名(可带schema,如public.users)action:一个或多个修改操作,多个操作时用逗号分隔IF EXISTS:防止表不存在时报错
1.4.1 ALTER 表字段
添加新列:ADD COLUMN
sql
ALTER TABLE users
ADD COLUMN phone TEXT;
-- 带默认值和非空约束
ALTER TABLE users
ADD COLUMN status TEXT NOT NULL DEFAULT 'active';- 给已有表加 NOT NULL 列时,必须提供 DEFAULT 值,否则会失败。
删除列:DROP COLUMN
sql
ALTER TABLE users
DROP COLUMN phone;
-- 如果列不存在也不报错
ALTER TABLE users
DROP COLUMN IF EXISTS old_field;- 不能删除被视图、索引、外键引用的列(需先删依赖)
- 不能删除分区键列
修改列的数据类型:ALTER COLUMN ... TYPE
sql
-- 将 age 从 INT 改为 SMALLINT
ALTER TABLE users
ALTER COLUMN age TYPE SMALLINT;
-- 需要转换格式(例如字符串转日期)
ALTER TABLE logs
ALTER COLUMN created_at TYPE TIMESTAMPTZ
USING created_at::TIMESTAMPTZ;USING子句:当 PostgreSQL 无法自动转换时,手动指定转换逻辑。
设置/删除默认值:SET/DROP DEFAULT
sql
-- 设置默认值
ALTER TABLE users
ALTER COLUMN created_at SET DEFAULT NOW();
-- 删除默认值
ALTER TABLE users
ALTER COLUMN created_at DROP DEFAULT;设置/移除非空约束:SET/DROP NOT NULL
sql
-- 禁止为空
ALTER TABLE users
ALTER COLUMN email SET NOT NULL;
-- 允许为空
ALTER TABLE user
ALTER COLUMN email DROP NOT NULL;SET NOT NULL会扫描全表!确保现有数据都非空,否则失败。
重命名列:RENAME COLUMN
sql
ALTER TABLE users
RENAME COLUMN username TO nickname;- 视图、函数中引用的列名不会自动更新,需手动调整。
1.4.2 ALTER 表
重命名表:RENAME TO
sql
ALTER TABLE users
RENAME TO user_accounts;- 所有索引、约束、外键会自动跟随新表名。
更改表的 Owner:
sql
ALTER TABLE users
OWNER TO new_user;设置表级选项:SET ..
sql
-- 启用/禁用行级安全
ALTER TABLE users ENABLE ROW LEVEL SECURITY;
-- 设置填充因子(影响 UPDATE 性能)
ALTER TABLE users SET (fillfactor = 80);
-- 设置表空间
ALTER TABLE users SET TABLESPACE fast_ssd;1.4.3 ALTER 表约束
添加约束:ADD CONSTRAINT
sql
-- 添加主键约束
ALTER TABLE users
ADD CONSTRAINT users_pkey PRIMARY KEY (id);
-- 添加唯一约束
ALTER TABLE users
ADD CONSTRAINT uk_users_email UNIQUE (email);
-- 添加检查约束
ALTER TABLE users
ADD CONSTRAINT chk_age CHECK (age >= 0 AND age <= 150);
-- 添加外键约束
ALTER TABLE orders
ADD CONSTRAINT fk_orders_user
FOREIGN KEY (user_id) REFERENCES users(id)
ON DELETE CASCADE;删除约束:DROP CONSTRAINT
sql
ALTER TABLE users
DROP CONSTRAINT uk_users_email;
-- 如果约束不存在也不报错
ALTER TABLE users
DROP CONSTRAINT IF EXISTS non_existent_constraint;通过查系统表可以查看所有约束:SELECT conname FROM pg_constraint WHERE conrelid = 'users'::regclass;
1.4.4 ALTER 其他操作
批量 ALTER
sql
ALTER TABLE users
ADD COLUMN bio TEXT,
ALTER COLUMN email SET NOT NULL,
RENAME COLUMN name TO full_name;结合 IF EXISTS / IF NOT EXISTS 条件性修改:
sql
ALTER TABLE users
ADD COLUMN IF NOT EXISTS last_login TIMESTAMPTZ;处理大表时的性能优化:添加带 DEFAULT 的列,新版本(PostgreSQL ≥11)不会重写全表,但如果是旧版本(<11),会锁表并重写
sql
-- v11+:瞬间完成(即使表有 10 亿行)
ALTER TABLE huge_table ADD COLUMN flag BOOLEAN DEFAULT false;二、PostgreSQL 数据行操作
2.1 插入数据
在 PostgreSQL 中,插入数据使用 INSERT INTO 语句,语法如下:
sql
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
-- 插入多行数据
INSERT INTO table_name (column1, column2, ...)
VALUES
(value1, value2, ...),
(value1, value2, ...),
(value1, value2, ...);示例:
sql
-- 插入单行数据
INSERT INTO users(id, name, age, address, salary)
VALUES (1, '张三', 18, '北京市', 3000);
-- 插入多行数据
INSERT INTO users(id, name, age, address, salary)
VALUES
(2, '李四', 100, '成都市', 18000),
(3, '王二', 50, '西安市', 50000),
(4, '麻子', 10, '重庆市', 10000);数据表结果:
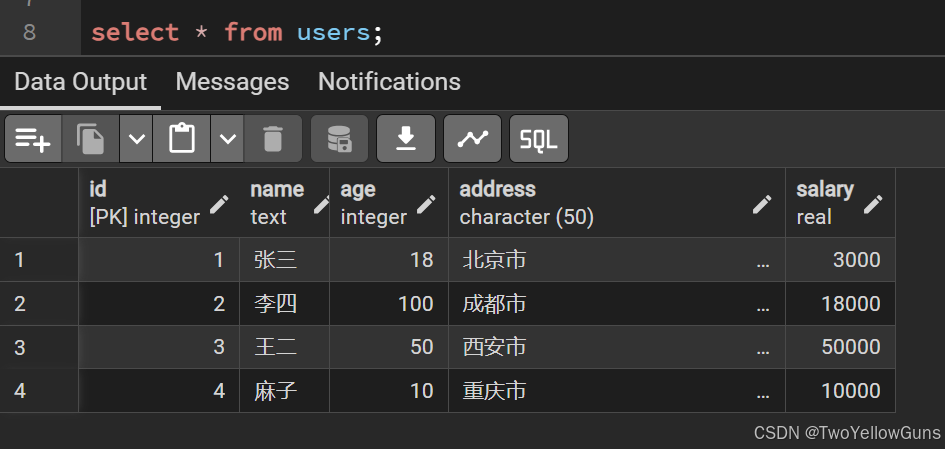
PostgreSQL 支持直接从一个表中查询数据来新增到另一个表中,使用 INSERT INTO ... SELECT 语句,语法如下:
sql
INSERT INTO table_name (column1, column2, ...)
SELECT column1, column2, ...
FROM table_name1;示例:
sql
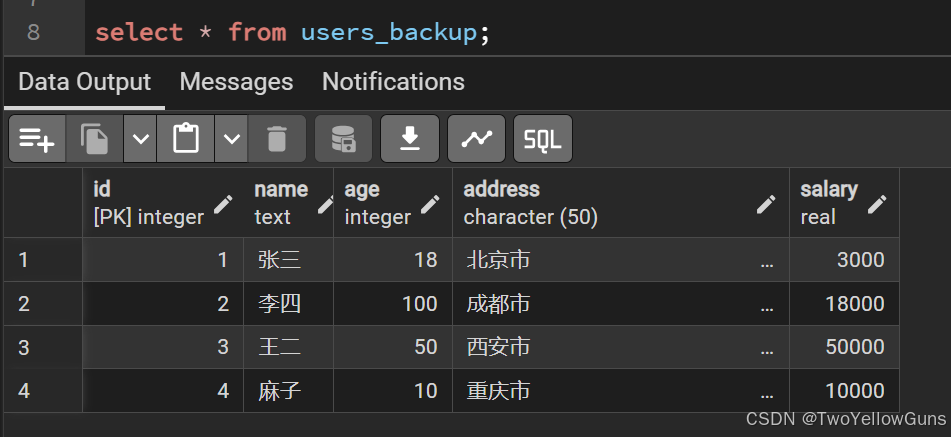
INSERT INTO users_backup (id, name, age, address, salary)
SELECT id, name, age, address, salary
FROM users;数据表结果:
PostgreSQL 支持在插入数据后返回插入的行,常用于获取自增主键。使用 RETURNING 语句,语法如下
sql
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
RETURNING column1, column2;
-- 常用于获取自增主键示例:
sql
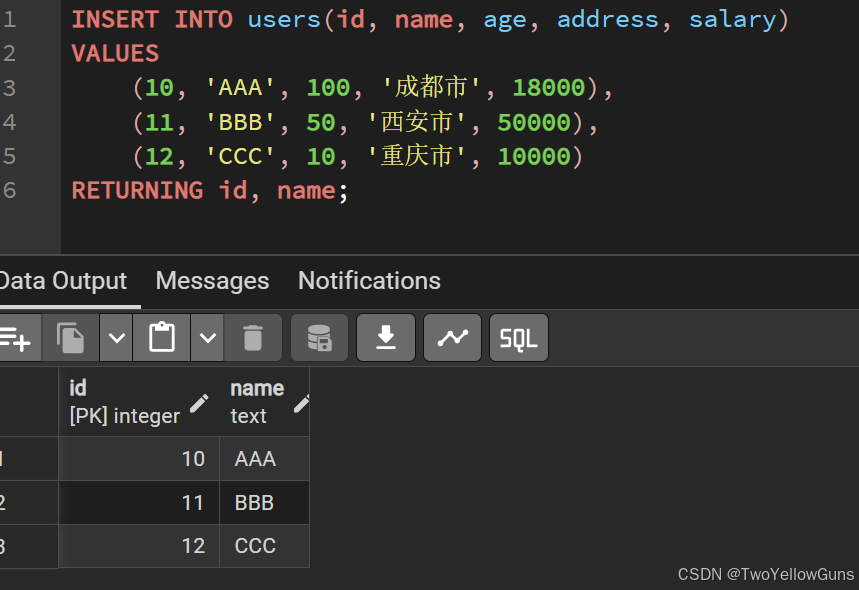
INSERT INTO users(id, name, age, address, salary)
VALUES
(10, 'AAA', 100, '成都市', 18000),
(11, 'BBB', 50, '西安市', 50000),
(12, 'CCC', 10, '重庆市', 10000)
RETURNING id, name;结果:
2.2 删除数据
PostgreSQL 删除数据语法如下:
sql
DELETE FROM [table_name] WHERE [condition];condition是由WHERE开头的筛选条件,如果省略WHERE会删除整张表的所有行!
示例:
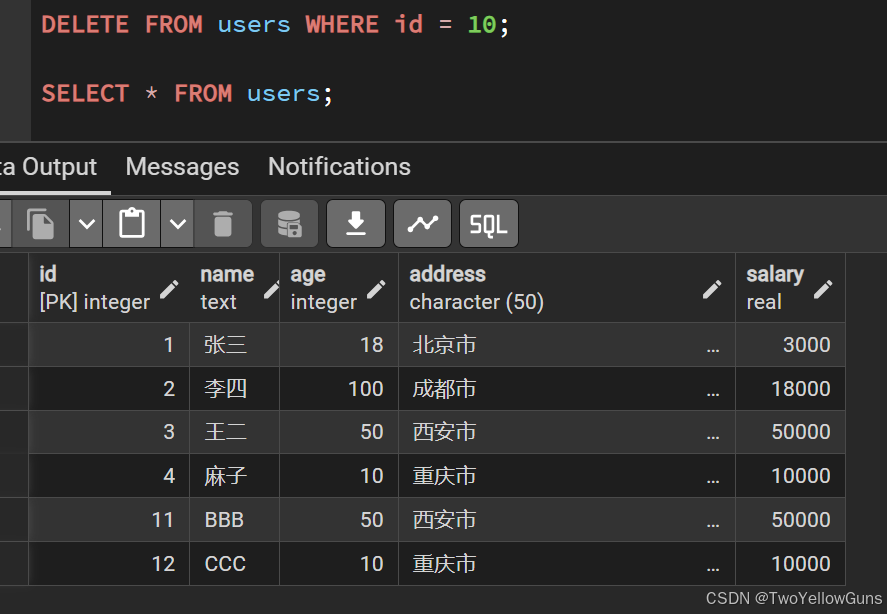
sql
DELETE FROM users WHERE id = 10;结果:
PostgreSQL 支持删除后返回被删除的行,使用 RETURNNING 语句,语法如下:
sql
DELETE FROM [table_name] WHERE [condition]
RETURNNING *;示例:
sql
DELETE FROM users WHERE id = 11
RETURNING *;结果:
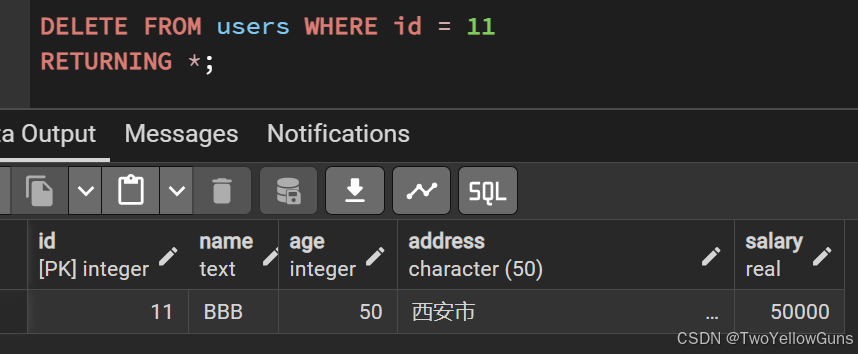
PostgreSQL 支持基于其他表进行条件删除,使用 USING 语句,语法如下:
sql
DELETE FROM [table_name1]
USING [table_name2]
WHERE [table_name1和table_name2的关联条件];示例,有如下两个表的数据:
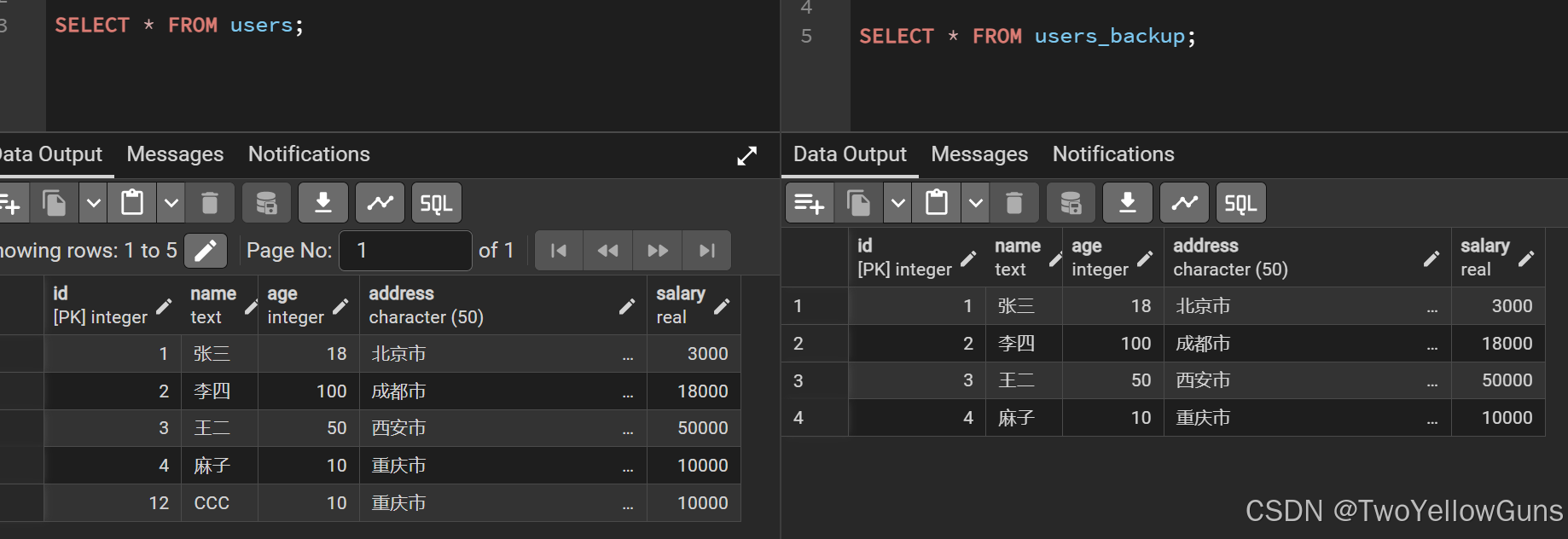
从 users 表中删除 id 等于 users_backup 表的 id 的数据:
sql
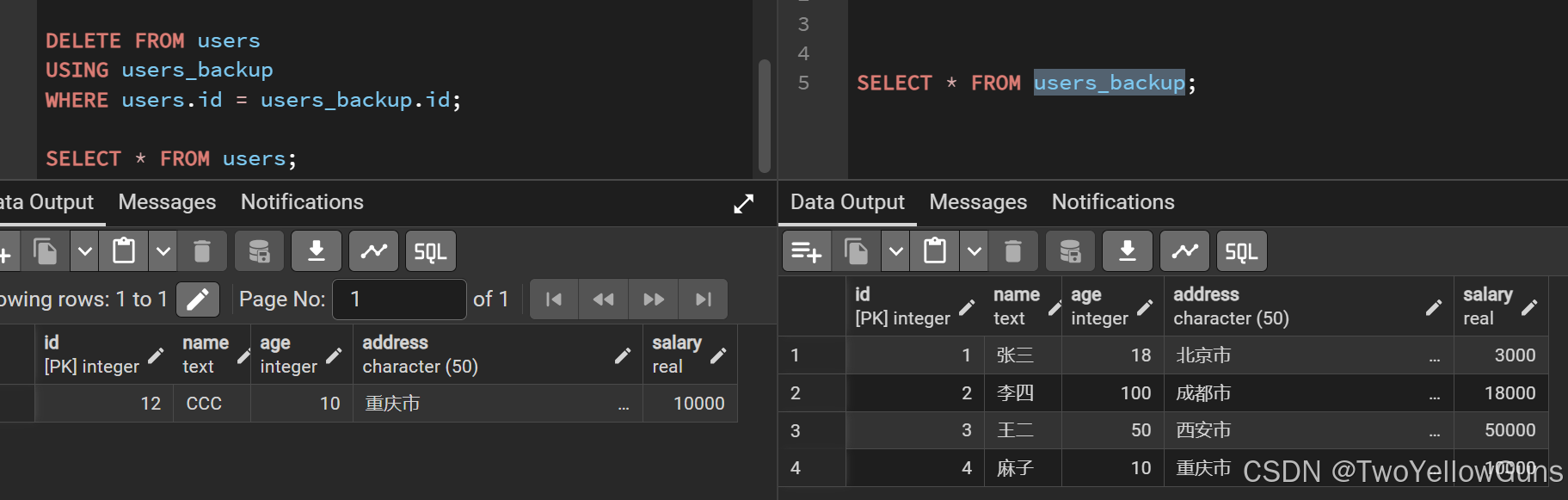
DELETE FROM users
USING users_backup
WHERE users.id = users_backup.id;结果:
2.3 编辑数据
PostgreSQL 编辑数据语法如下:
sql
UPDATE [table_name]
SET [colunm_name]= [value]
WHERE [condition];示例:
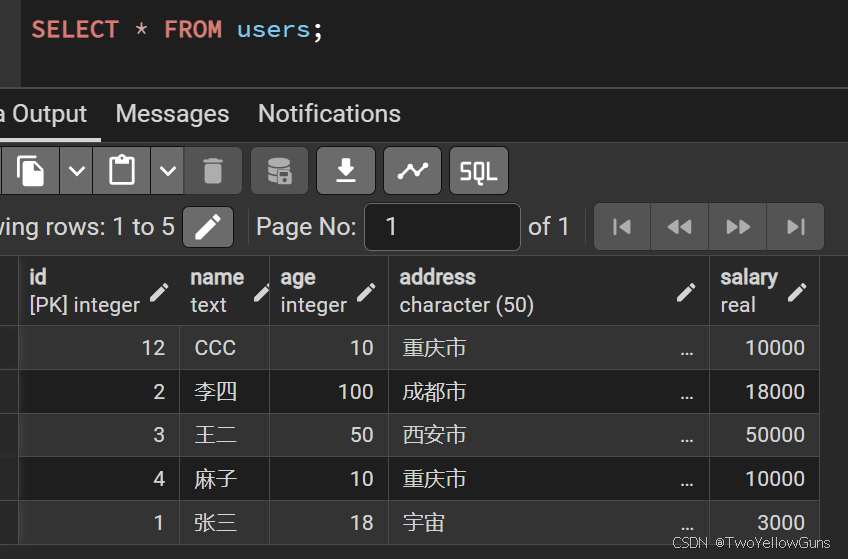
sql
UPDATE users SET address = '宇宙' WHERE id = 1;结果:
PostgreSQL 支持编辑后返回被编辑的行,使用 RETURNNING 语句,语法如下:
sql
UPDATE [table_name]
SET [colunm_name]= [value]
WHERE [condition]
RETURNING *;示例:
sql
UPDATE users SET address = '宇宙' WHERE id = 2
RETURNING *;结果:
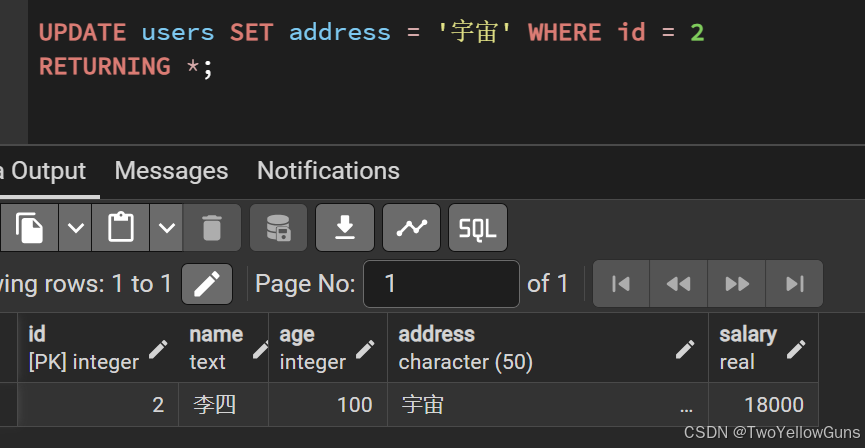
PostgreSQL 支持基于其他表进行条件编辑,使用 USING 语句,语法如下:
sql
UPDATE [table_name1]
SET [colunm_name]= [value]
FROM [table_name2]
WHERE [table_name1和table_name2的关联条件];示例,有如下两个表的数据:
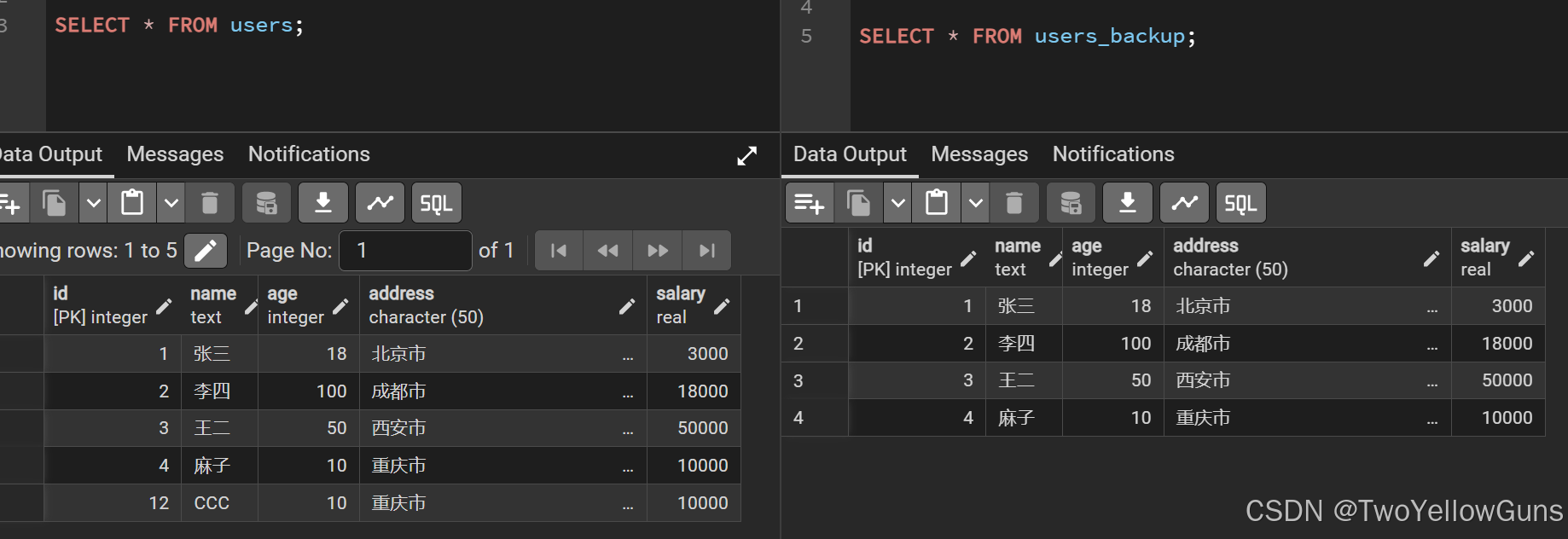
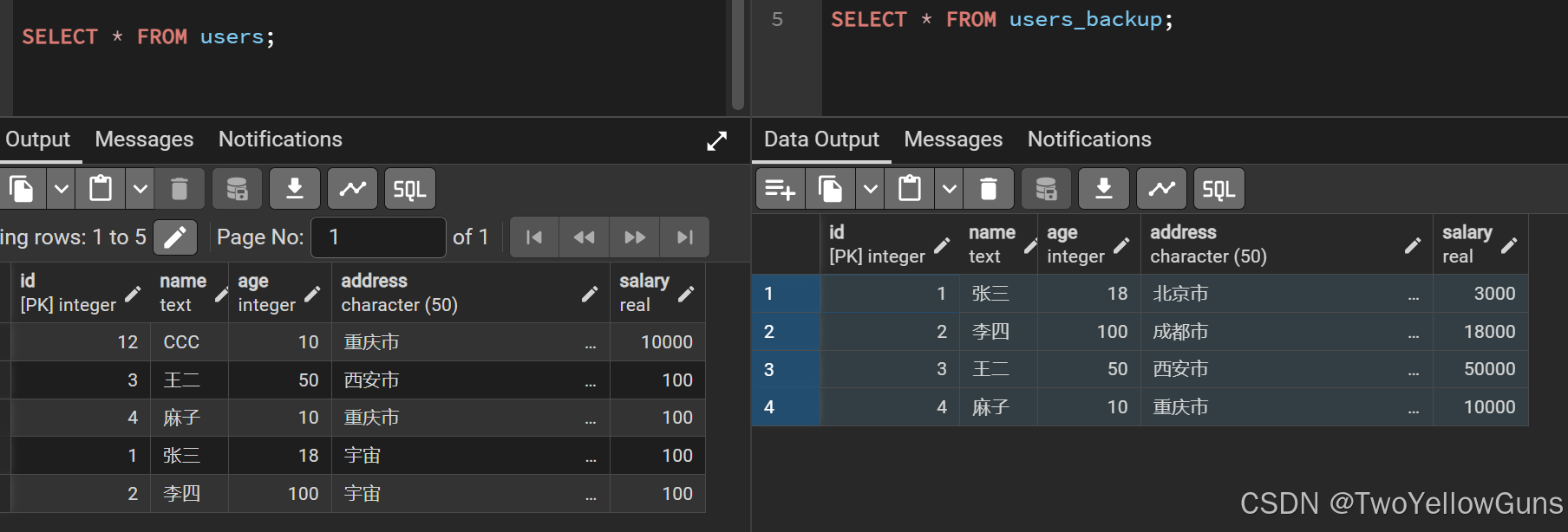
从 users 表中修改 id 等于 users_backup 表的 id 的数据,将 salary 修改为100,如下:
sql
UPDATE users
SET salary = 100
FROM users_backup
WHERE users.id = users_backup.id;结果:
2.4 查询数据
2.4.1 基础查询
PostgreSQL 中,基础查询语法如下:
sql
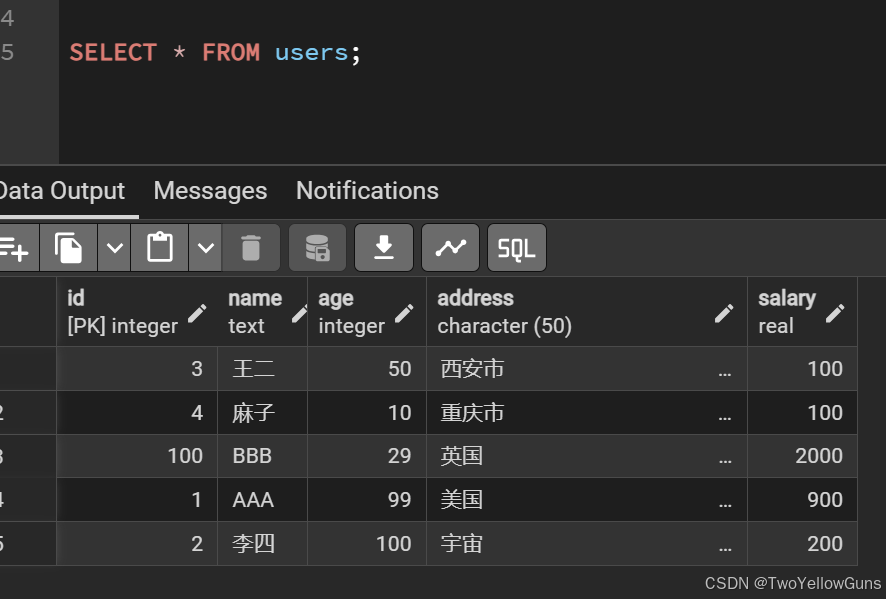
SELECT [columns] FROM [db_name] 示例:
sql
SELECT * FROM users;查询结果:
PostgreSQL 的查询支持很多语句,如 WHERE 条件查询、GROUP BY 分组、ORDER BY 排序等。完整的查询语句语法如下:
sql
[ WITH [ RECURSIVE ] with_query [, ...] ]
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ [ AS ] output_name ] [, ...]
FROM from_item [, ...]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING group_condition ]
[ WINDOW window_name AS ( window_definition ) [, ...] ]
[ ORDER BY sort_expression [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start [ ROW | ROWS ] ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY ]
[ FOR { UPDATE | NO KEY UPDATE | SHARE | KEY SHARE } [ OF table_name [, ...] ] [ NOWAIT | SKIP LOCKED ] [...] ]虽然书写顺序是 SELECT ... FROM ... WHERE ...,但 SQL 引擎的逻辑执行顺序 是:
sql
FROM → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY → LIMIT/OFFSET2.4.2 WHERE 子句
在 PostgreSQL 中,WHERE 子句用于过滤行,只返回满足指定条件的记录,除了用于 SELECT,也常用于 UPDATE、DELETE 等 DML 语句。
WHERE 子句语法:
sql
-- 查询
SELECT [columns] FROM [table_name] WHERE [condition];
-- 编辑
UPDATE [table_name] SET ... WHERE [condition];
-- 删除
DELETE FROM [table_name] WHERE [condition];WHERE 后的条件可以是任意返回布尔值(true/false/unknown)的表达式,表达式可以由各种运算符或SQL语句组成。
users 表有如下数据:
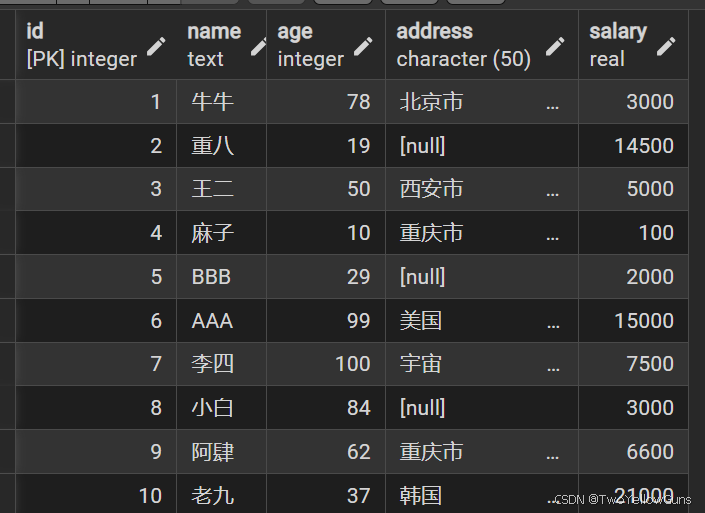
查询示例:
sql
select * from users where age > 50;
select * from users where salary = 3000;AND / OR / NOT:
-
AND:所有条件都为真 -
OR:任一条件为真 -
NOT:取反 -
NOT>AND>OR
sql
-- AND
select * from users where name = '牛牛' and salary = 3000;
-- OR
select * from users where name = '牛牛' or salary = 3000;
-- NOT
select * from users where not (name = '牛牛' or salary = 3000);IS NULL / IS NOT NULL:
-
IS NULL:字段的值为null -
IS NOT NULL:字段的值不为null
sql
select * from users where address is null;
select * from users where address is not null;IN / NOT IN:
IN:字段的值在指定的value中NOT IN:字段的不值在指定的value中
sql
select * from users where id in (1,3,5,7,9);
select * from users where id not in (1,3,5,7,9);BETWEEN AND:
- 查询字段的值在指定范围内的数据,返回包含左右边界
sql
select * from users where salary between 3000 and 15000;LIKE / ILIKE
-
模糊查询,
LIKE区分大小写,ILIKE不区分大小写 -
模糊查询通过通配符实现:
%:匹配任意多个字符,_:匹配单个字符
-
如果添加通配符,则语句等价于
=语句,如a like 'b'等价于a = 'b'
sql
select * from users where address like '%重庆%'; -- 匹配 重庆市
select * from users where address like '重庆%'; -- 匹配 重庆市
select * from users where address like '%重庆'; -- 匹配无数据
-- LIKE / ILIKE 对比
select * from users where name like '%A%'; -- 匹配 AAA
select * from users where name like '%a%'; -- 匹配 无数据
select * from users where name ilike '%A%'; -- 匹配 AAA
select * from users where name ilike '%a%'; -- 匹配 AAA
-- 通配符对比
select * from users where name like '%A%'; -- 匹配 AAA
select * from users where name like '_A_'; -- 匹配 无数据
select * from users where name like 'A%'; -- 匹配 AAA
select * from users where name like 'A_'; -- 匹配 无数据
select * from users where name like '%A'; -- 匹配 AAA
select * from users where name like '_A'; -- 匹配 无数据ANY / ALL:
- 批量匹配,通常配合数组或子查询
ANY:只要匹配指定数据中的任意一个,就算满足条件ALL:必须匹配指定数据中的每一个才算满足条件
sql
-- age>40 且 age>70
select * from users where age > all(ARRAY[40,70]);
-- age>40 或 age>70
select * from users where age > ANY(ARRAY[40,70]);2.4.3 ORDER BY / LIMIT
在 PostgreSQL 中,ORDER BY 用于对一列或者多列数据进行排序:
ASC:升序,不指定排序方式时默认是ASCDESC:降序
语法:
sql
SELECT column-list
FROM [table_name]
WHERE [condition]
ORDER BY [column1, column2, .. columnN] [ASC | DESC];示例:
sql
select * from users order by age asc; -- age从小到大
select * from users order by age; -- age从小到大
select * from users order by age desc; -- age从大到小ORDER BY 通常搭配 LIMIT 使用,PostgreSQL 中 LIMIT 子句用于限制查询的数据的数量。
LIMIT 语法:
sql
SELECT [columns]
FROM [table_name]
LIMIT [no of rows] OFFSET [row num]LIMIT:限制查询多少条数据OFFSET:偏移量,从第几条开始查询,初始值为0
示例:
sql
-- 100,99,84,78,62,50,37,29,19,10
select * from users order by age desc
select * from users order by age desc limit 4; -- 100,99,84,78
select * from users order by age desc limit 4 offset 0; -- 78,62,50,372.4.4 GROUP BY / HAVING
(1)GROUP BY
在 PostgreSQL 中,GROUP BY 语句用将结果集按一个或多个列(或表达式)相同的数据进行分组,通常与聚合函数(如 COUNT()、SUM()、AVG()、MAX()、MIN() 等)一起使用,对每个分组进行统计计算。
GROUP BY 子句必须放在 WHERE 子句中的条件之后,必须放在 ORDER BY 子句之前。
sql
-- 分组并取每个组的salary总和
select address, sum(salary) from users group by address;
-- 分组并取每个组的salary最大值
select address, max(salary) from users group by address;
-- 分组并取每个组的salary最小值
select address, min(salary) from users group by address;
-- 分组并取每个组的salary平均值
select address, avg(salary) from users group by address;(2)HAVING
GROUP BY 常与 HAVING 配合使用,HAVING 也是用于过滤数据,其与 WHERE 的区别如下:
WHERE:在分组前执行,用于过滤原始行HAVING:在分组后执行,用于过滤分组的结果
sql
select address, avg(salary) from users group by address having avg(salary) > 5000;常与 GROUP BY 结合的聚合函数:
| 聚合函数 | 说明 | 聚合函数 | 说明 |
|---|---|---|---|
COUNT(*) |
行数(含 NULL) | MAX(created_at) |
最大值 |
COUNT(col) |
非 NULL 值数量 | MIN(id) |
最小值 |
SUM(price) |
求和 | STRING_AGG(name, ', ') |
字符串拼接 |
AVG(score) |
平均值(忽略 NULL) | ARRAY_AGG(email) |
聚合成数组 |
(3)高级分组功能
在 PostgreSQL 中,GROUPING SETS、ROLLUP 和 CUBE 是 高级分组功能,用于在单个查询中生成 多个维度的聚合汇总结果(类似"多级小计"和"总计"),常用于报表和数据分析场景。
GROUPING SETS:精确控制分组组合,显式指定想要的所有分组维度组合。ROLLUP:层级式小计(从细到粗),自动生成层级递进的小计,适用于有天然层次结构的数据(如:年 → 季度 → 月)。CUBE:所有维度组合的交叉汇总,生成所有可能的分组组合(笛卡尔积式的汇总),适合多维分析(OLAP)。
GROUPING SETS 示例:
sql
-- 假设 sales 表有如下数据
/*
product region amount
A North 100
A South 150
B North 200
*/
-- 查询sql
SELECT
product,
region,
SUM(amount) AS total
FROM sales
GROUP BY GROUPING SETS (
(product, region), -- 组合1:按产品+区域分组
(product), -- 组合2:只按产品分组
(region), -- 组合3:只按区域分组
() -- 组合4:全局总计(无分组)
)
ORDER BY product, region;
-- 结果查询结果:
| product | region | total | 对应的 GROUPING SETS 分组 | 说明 |
|---|---|---|---|---|
| A | North | 100 | (product, region) |
A 在 North 的销售额 |
| A | South | 150 | (product, region) |
A 在 South 的销售额 |
| A | NULL | 250 | (product) |
A 产品的总销售额(North + South) |
| B | North | 200 | (product, region) |
B 在 North 的销售额 |
| B | NULL | 200 | (product) |
B 产品的总销售额 |
| NULL | North | 300 | (region) |
North 区域总销售额(A+ B) |
| NULL | South | 150 | (region) |
South 区域总销售额(A) |
| NULL | NULL | 450 | () |
全局总销售额 |
ROLLUP 语法:
sql
SELECT col1, col2, ..., aggregate_function(...)
FROM table
GROUP BY ROLLUP(col1, col2, ..., colN);
-- 等价于
SELECT col1, col2, ..., aggregate_function(...)
FROM table
GROUP BY GROUPING SETS (
(col1, col2, ..., colN),
(col1, col2, ..., colN-1),
...,
(col1),
()
)ROLLUP 示例:
sql
-- 假设表 orders 有如下数据
/*
order_id order_date amount
1 2024-01-10 100
2 2024-01-15 200
3 2024-02-05 150
4 2025-01-20 300
*/
-- 查询SQL
SELECT
EXTRACT(YEAR FROM order_date) AS year,
EXTRACT(MONTH FROM order_date) AS month,
SUM(amount) AS total
FROM orders
GROUP BY ROLLUP(year, month)
ORDER BY year, month;PostgreSQL 允许在
GROUP BY中直接使用SELECT列别名(如year,month),这是它的扩展特性。
查询结果分析:
| year | month | total | 对应的分组层级 | 含义 |
|---|---|---|---|---|
| 2024 | 1 | 300 | (year, month) |
2024 年 1 月销售额(100+200) |
| 2024 | 2 | 150 | (year, month) |
2024 年 2 月销售额 |
| 2024 | NULL | 450 | (year) |
2024 年小计(1月+2月) |
| 2025 | 1 | 300 | (year, month) |
2025 年 1 月销售额 |
| 2025 | NULL | 300 | (year) |
2025 年小计 |
| NULL | NULL | 750 | () |
总计(所有年月) |
CUBE 语法:
sql
SELECT col1, col2, ..., aggregate_function(...)
FROM table
GROUP BY CUBE(col1, col2, ..., colN);
-- 等价于
SELECT col1, col2, ..., aggregate_function(...)
FROM table
GROUP BY GROUPING SETS (
(col1, col2, ..., colN),
(col1, col2, ..., colN-1),
...,
(col1, col3),
(col2, col3),
...,
(col1),
(col2),
...,
()
)
-- 所有可能的子集组合(共 2^N 个)CUBE 示例:
sql
-- 假设表 sales 数据如下:
/*
product region salesperson amount
A North Alice 100
A South Bob 150
B North Alice 200
*/
-- 查询SQL
SELECT
product,
region,
salesperson,
SUM(amount) AS total
FROM sales
GROUP BY CUBE(product, region, salesperson)
ORDER BY product, region, salesperson;查询结果分析:共 2³ = 8 种分组,实际结果行数可能少于 18 行,因为某些组合在数据中不存在,就不会出现在分组结果中。
| product | region | salesperson | total | 对应分组 | 含义 |
|---|---|---|---|---|---|
| A | North | Alice | 100 | (A,R,S) | 明细:A 在 North 由 Alice 卖出 |
| A | South | Bob | 150 | (A,R,S) | 明细 |
| B | North | Alice | 200 | (A,R,S) | 明细 |
| A | North | NULL | 100 | (A,R) | A 在 North 的总销售额(不管谁卖) |
| A | South | NULL | 150 | (A,R) | A 在 South 的总销售额 |
| B | North | NULL | 200 | (B,R) | B 在 North 的总销售额 |
| A | NULL | Alice | 100 | (A,S) | A 由 Alice 卖出的总额(不管地区) |
| A | NULL | Bob | 150 | (A,S) | A 由 Bob 卖出的总额 |
| B | NULL | Alice | 200 | (B,S) | B 由 Alice 卖出的总额 |
| NULL | North | Alice | 300 | (R,S) | North 由 Alice 卖出的总额(A+B) |
| NULL | South | Bob | 150 | (R,S) | South 由 Bob 卖出的总额 |
| A | NULL | NULL | 250 | (A) | 产品 A 的总销售额 |
| B | NULL | NULL | 200 | (B) | 产品 B 的总销售额 |
| NULL | North | NULL | 300 | ® | North 区域总销售额 |
| NULL | South | NULL | 150 | ® | South 区域总销售额 |
| NULL | NULL | Alice | 300 | (S) | Alice 的总销售额 |
| NULL | NULL | Bob | 150 | (S) | Bob 的总销售额 |
| NULL | NULL | NULL | 450 | () | 全局总计 |
如果要区分结果集中的
NULL是原始值还是汇总占位符,可以使用GROUPING()函数,示例:
sqlSELECT product, region, salesperson, SUM(amount) AS total, GROUPING(product) AS g_product, GROUPING(region) AS g_region, GROUPING(salesperson) AS g_salesperson FROM sales GROUP BY CUBE(product, region, salesperson);
g_product = 1表示product列是被聚合掉的(显示的NULL是汇总标志)g_product = 0表示product是真实值(即使它本身是NULL)
2.4.5 WITH 子句
(1)WITH 子句
在 PostgreSQL 中,WITH 子句(也称为 公共表表达式,Common Table Expression,简称 CTE)是一种非常强大且可读性高的 SQL 结构,用于定义临时命名结果集,这些结果可以在主查询中被引用一次或多次。
WITH 子句是在多次执行子查询时特别有用,定义之后,就可以在后续的查询中通过它的名称一次或多次引用。
WITH 特点:
- 临时性:
CTE只在当前查询中存在,不会持久化 - 可读性高:将复杂逻辑拆分为命名步骤,类似"变量"
- 可递归:使用
WITH RECURSIVE实现树形/图遍历 - 非物化(默认):PostgreSQL 默认将
CTE作为优化器提示(可能内联),但可通过MATERIALIZED强制物化(PG 12+)
WITH 语法:
sql
-- 定义一个 WITH
WITH cte_name AS (
SELECT ...
)
SELECT ... FROM cte_name;
-- 定义多个 WITH
WITH
cte1 AS (SELECT ...),
cte2 AS (SELECT ... FROM cte1),
cte3 AS (SELECT ...)
SELECT * FROM cte2 JOIN cte3 ...;示例:
sql
-- 常规查询
SELECT *
FROM (
SELECT user_id, SUM(amount) AS total
FROM orders
WHERE created_at > '2024-01-01'
GROUP BY user_id
) AS recent_spending
WHERE total > 1000;
-- 使用 WITH 替代
WITH recent_spending AS (
SELECT user_id, SUM(amount) AS total
FROM orders
WHERE created_at > '2024-01-01'
GROUP BY user_id
)
SELECT *
FROM recent_spending
WHERE total > 1000;多次引用示例:
sql
WITH top_customers AS (
SELECT user_id, SUM(amount) AS total
FROM orders
GROUP BY user_id
ORDER BY total DESC
LIMIT 10
)
SELECT
'High Value' AS segment,
COUNT(*) AS count
FROM top_customers
UNION ALL
SELECT
'Avg Order Value',
AVG(total)
FROM top_customers;(2)递归查询
递归查询 WITH RECURSIVE 用于处理树形结构(如组织架构、评论回复链、物料清单等)。
示例:
sql
WITH RECURSIVE org_chart AS (
-- 基础情况:CEO(无上级)
SELECT id, name, manager_id, 1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 递归情况:下属
SELECT e.id, e.name, e.manager_id, oc.level + 1
FROM employees e
JOIN org_chart oc ON e.manager_id = oc.id
)
SELECT * FROM org_chart ORDER BY level;(3)数据修改使用 CTE
PostgreSQL 允许在 WITH 中使用 INSERT / UPDATE / DELETE,并返回结果供后续使用(数据修改 CTE)。
示例:删除旧日志并记录删除数量
sql
WITH deleted_logs AS (
DELETE FROM logs
WHERE created_at < NOW() - INTERVAL '30 days'
RETURNING id
)
SELECT COUNT(*) AS deleted_count FROM deleted_logs;示例:插入后立即更新
sql
WITH new_user AS (
INSERT INTO users (name, email)
VALUES ('Alice', 'alice@example.com')
RETURNING id
)
UPDATE profiles
SET status = 'active'
WHERE user_id = (SELECT id FROM new_user);(4)强制物化 CTE
这是 PostgreSQL 12+ 的高级特性,用于避免重复计算。
sql
WITH my_cte AS MATERIALIZED (
SELECT expensive_function(x) AS result
FROM large_table
)
SELECT * FROM my_cte WHERE result > 0;MATERIALIZED:确保CTE只计算一次,结果存入临时空间- 无
MATERIALIZED:PostgreSQL 可能将CTE内联展开(像宏一样),导致多次执行(如果引用多次)
2.4.8 DISTINCT 子句
(1)DISTINCT
在 PostgreSQL 中,DISTINCT 是一个用于去除结果集中重复行的关键字,常用于 SELECT 语句中,确保返回的结果唯一。
DISTINCT 语法如下:
sql
SELECT DISTINCT column1, column2, ...
FROM [table_name];示例:
sql
select distinct sex from users; -- 男,女
select count(sex) from users; -- 10
select count(distinct sex) from users; -- 2(2)DISTINCT ON (expression)
DISTINCT ON (expression) 是 PostgreSQL 特有的功能,用于对某列去重,但保留该组中的第一行(按指定顺序)
DISTINCT ON (expression) 语法:
sql
SELECT DISTINCT ON (column_or_expr)
select_list
FROM table
ORDER BY column_or_expr [, ...];- 必须配合
ORDER BY,且ORDER BY的第一个表达式必须与DISTINCT ON的表达式一致。
示例:获取每个用户最近的一条订单
sql
SELECT DISTINCT ON (user_id)
user_id,
order_id,
order_date,
total
FROM orders
ORDER BY user_id, order_date DESC; -- 每个 user_id 组内,按时间倒序,取第一条2.5 高级行操作
2.5.1 UPSERT
UPSERT(INSERT ON CONFLICT):实现"存在则更新,不存在则插入":
ON CONFLICT (column):指定冲突判断列(必须有唯一约束或主键)。EXCLUDED:代表试图插入但冲突的那一行。
示例,users 表有如下数据:
往 users 表中新增两条数据:
sql
INSERT INTO users(id, name, age, address, salary)
values
(1, 'AAA', 99, '美国', 1000),
(100, 'BBB', 29, '英国', 2000)
ON CONFLICT (id) DO UPDATE
SET name = EXCLUDED.name,
age = EXCLUDED.age,
address = EXCLUDED.address,
salary = EXCLUDED.salary;执行结果:
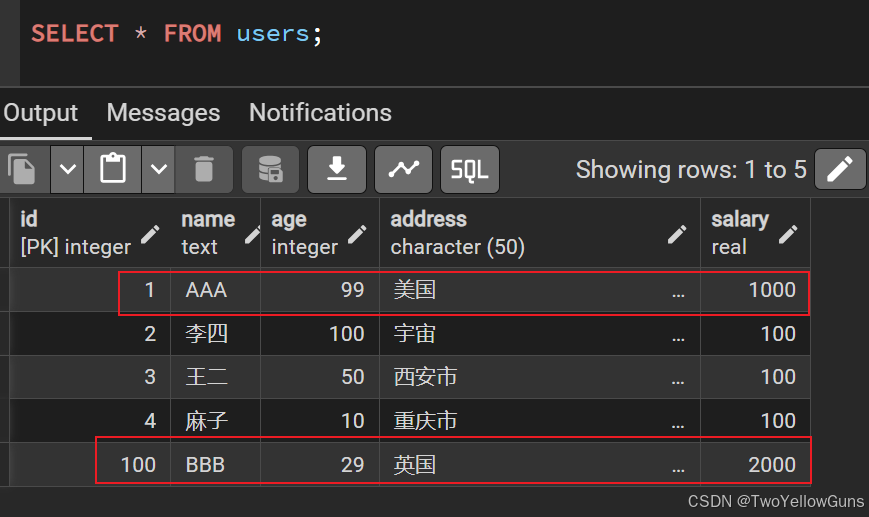
id=1的数据已存在,则执行了更新id=100的数据不存在,则执行了新增
2.5.2 批量操作与事务
多个行操作通常放在事务中保证一致性:
sql
BEGIN;
UPDATE users SET salary = salary - 100 WHERE id = 1;
UPDATE users SET salary = salary + 100 WHERE id = 2;
COMMIT;2.5.3 行级锁
行级锁 FOR UPDATE 可以在事务中锁定特定行防止并发修改:
sql
SELECT * FROM users WHERE id = 1 FOR UPDATE;
-- 其他会话对该行的 UPDATE/DELETE 将被阻塞2.5.4 TRUNCATE 命令
PostgreSQL 中 TRUNCATE TABLE 用于删除表的数据,但不删除表结构。
TRUNCATE TABLE 与 DELETE 具有相同的效果,但是由于它实际上并不扫描表,所以速度更快。 此外,TRUNCATE TABLE 可以立即释放表空间,而不需要后续 VACUUM 操作,这在大型表上非常有用。
PostgreSQL VACUUM 操作用于释放、再利用更新/删除行所占据的磁盘空间。
TRUNCATE TABLE 语法如下:
sql
TRUNCATE TABLE table_name;2.5.5 AUTO INCREMENT
PostgreSQL 中,AUTO INCREMENT 表示自动增长,设置了这个的列会在新记录插入表中时自动生成一个唯一的数字。
PostgreSQL 使用序列 SERIAL 来标识字段的自增长,数据类型有 smallserial、serial 和 bigserial,这些属性类似于 MySQL 数据库支持的 AUTO_INCREMENT 属性。
SERIAL 数据类型语法如下:
sql
CREATE TABLE tablename (
colname SERIAL
);示例:
sql
-- MySQL 设置自动增长
CREATE TABLE IF NOT EXISTS `test_table`(
`id` INT UNSIGNED AUTO_INCREMENT,
`name` VARCHAR(100) NOT NULL
PRIMARY KEY ( `runoob_id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- PostgreSQL 使用序列来标识字段的自增长
CREATE TABLE test_table
(
id serial NOT NULL,
name text
)SMALLSERIAL、SERIAL 和 BIGSERIAL 范围:
| 类型 | 存储大小 | 范围 |
|---|---|---|
SMALLSERIAL |
2字节 | 1 到 32,767 |
SERIAL |
4字节 | 1 到 2,147,483,647 |
BIGSERIAL |
8字节 | 1 到 922,337,2036,854,775,807 |
三、PostgreSQL 约束
PostgreSQL 中的约束(Constraints)用于限制表中数据的类型,以保证数据的完整性和一致性。
3.1 NOT NULL
NOT NULL 用于确保列不能有 NULL 值。
默认情况下,列可以保存为 NULL 值,如果不希望某列有 NULL 值,那么需要在该列上定义此约束,指定在该列上不允许 NULL 值。
NULL 与没有数据是不一样的,它代表着未知的数据。
sql
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL
);3.2 UNIQUE
UNIQUE 用于确保列(或列组合)中的所有值都是唯一的。
sql
-- 单列唯一
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email TEXT UNIQUE
);
-- 多列唯一
CREATE TABLE user_roles (
user_id INT,
role_name TEXT,
UNIQUE (user_id, role_name)
);3.3 PRIMARY KEY
PRIMARY KEY 是表的主键,是数据表中每一条记录的唯一标识。如果一个表在任何字段上定义了一个主键,那么在这些字段上不能有两个记录具有相同的值。
PRIMARY KEY = NOT NULL + UNIQUE,用于唯一标识表中的每一行。
每个表只能有一个主键,它可以由一个或多个字段组成,当多个字段作为主键,它们被称为复合键。
sql
CREATE TABLE products (
product_id SERIAL PRIMARY KEY,
name TEXT
);3.4 FOREIGN KEY
FOREIGN KEY 是表的外键,外键用于建立和强制两个表之间的引用完整性。
子表中的外键值必须在父表的主键(或唯一键)中存在,或者为 NULL(除非同时声明 NOT NULL)。
sql
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
product_id INT REFERENCES products(product_id)
);也可以显式命名外键约束:
sql
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
product_id INT,
CONSTRAINT fk_product
FOREIGN KEY (product_id)
REFERENCES products(product_id)
ON DELETE CASCADE
);支持的操作选项:
-
ON DELETE / ON UPDATE:
- NO ACTION(默认)
- RESTRICT
- CASCADE
- SET NULL
- SET DEFAULT
3.5 CHECK
CHECK 约束用于保证列中的所有值满足指定取值范围或满足某一条件,即对输入一条记录要进行检查。如果条件值为 false,则记录违反了约束,且不能输入到表。
sql
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
age INT CHECK (age >= 18),
salary NUMERIC CHECK (salary > 0)
);3.6 EXCLUSION
排他约束(Exclusion Constraint)是 PostgreSQL 特有的高级约束,用于确保任意两行在指定操作符下不"重叠",即确保如果使用指定的运算符在指定列或表达式上比较任意两行,至少其中一个运算符比较将返回 false 或 null。
通常与 btree_gist 或 btree_gin 扩展一起使用。
sql
-- 示例:确保同一房间在同一时间段内不能被重复预订
CREATE EXTENSION IF NOT EXISTS btree_gist;
CREATE TABLE reservations (
room TEXT,
during TSRANGE,
EXCLUDE USING GIST (room WITH =, during WITH &&)
);3.7 查看约束信息
可通过系统目录查看约束
sql
SELECT conname AS constraint_name,
contype AS constraint_type,
conrelid::regclass AS table_name
FROM pg_constraint
WHERE conrelid = 'users'::regclass;-
contype含义:p=PRIMARY KEYu=UNIQUEf=FOREIGN KEYc=CHECKx=EXCLUDE
3.8 添加/删除约束
添加约束语法:
sql
ALTER TABLE [table_name]
ADD CONSTRAINT [some_name] UNIQUE ([cloumn_name]);删除约束语法:
sql
ALTER TABLE [table_name]
DROP CONSTRAINT [some_name];第三章 PostgreSQL 进阶
一、PostgreSQL 进阶查询
1.1 PostgreSQL JOIN
在 PostgreSQL 中,JOIN 用于根据两个或多个表之间的相关列组合数据,它是关系型数据库中实现表关联查询的核心操作。
常见的 JOIN 类型如下:
CROSS JOIN:交叉连接INNER JOIN:内连接LEFT OUTER JOIN:左外连接RIGHT OUTER JOIN:右外连接FULL OUTER JOIN:全外连接
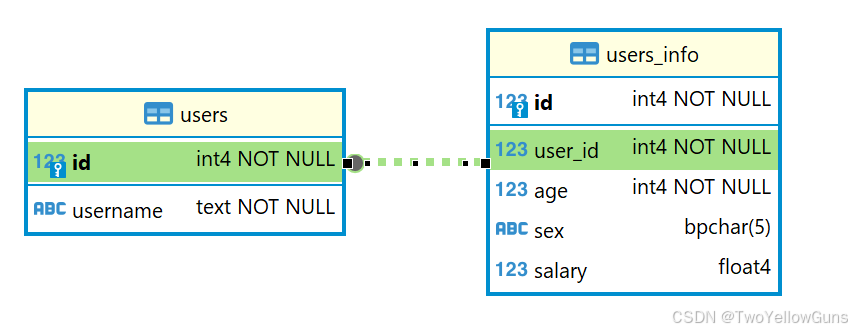
假设有 users 表和 users_info 表,如下:
两个表的数据分别如下:
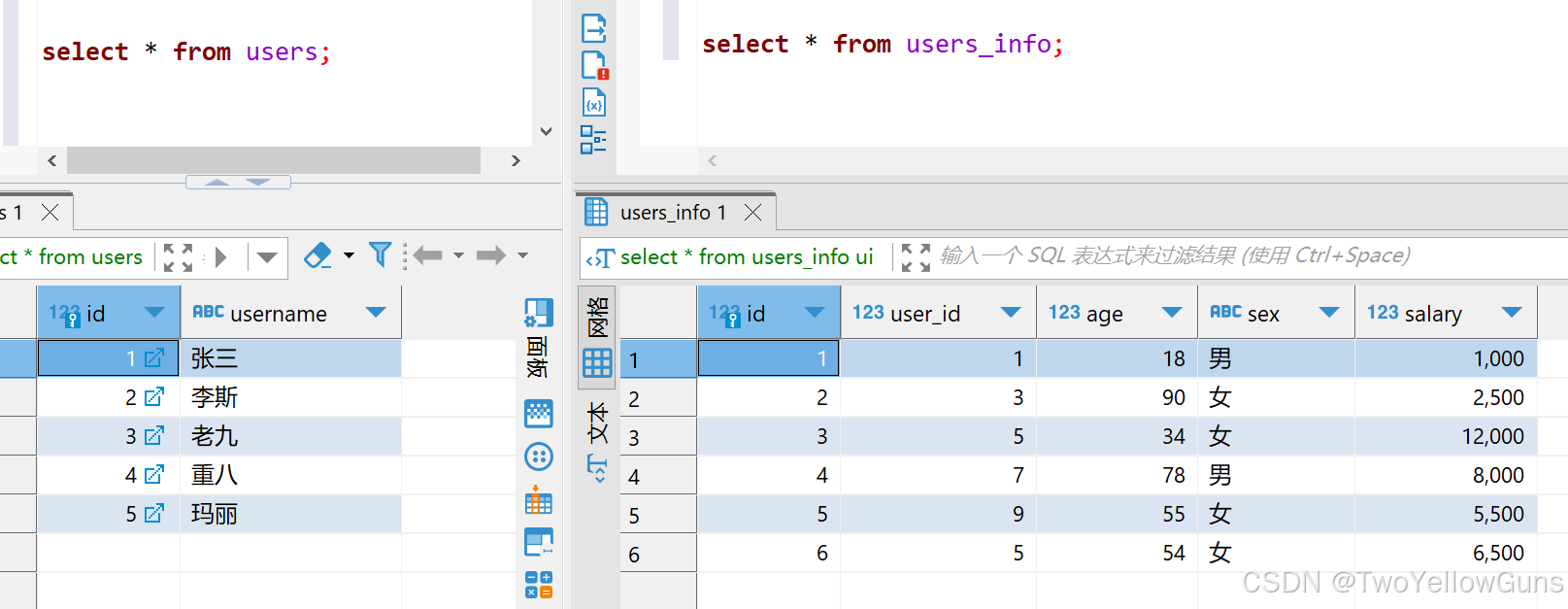
1.1.1 INNER JOIN
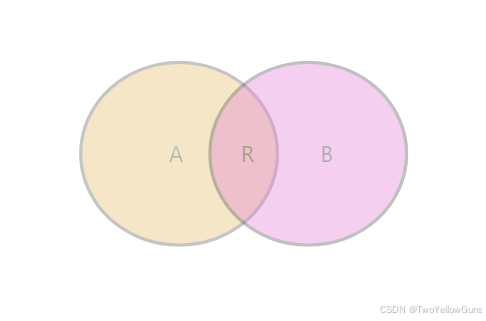
INNER JOIN:内连接,只返回两个表中匹配的行。用于联合查询几个表的数据,只有当几个表都满足连接条件才符合,并自动结合成一条数据。
INNER 关键字是可选的,不写 INNER 时,默认为 INNER JOIN,即 JOIN = INNER JOIN。
INNER JOIN 的语法如下:
sql
SELECT table1.column1, table2.column2...
FROM table1
INNER JOIN table2
ON table1.common_filed = table2.common_field;INNER JOIN 的结果集可以表示为 R:
示例:
sql
SELECT users.*, users_info.*
FROM users
INNER JOIN users_info
ON users.id = users_info.user_id;查询结果:
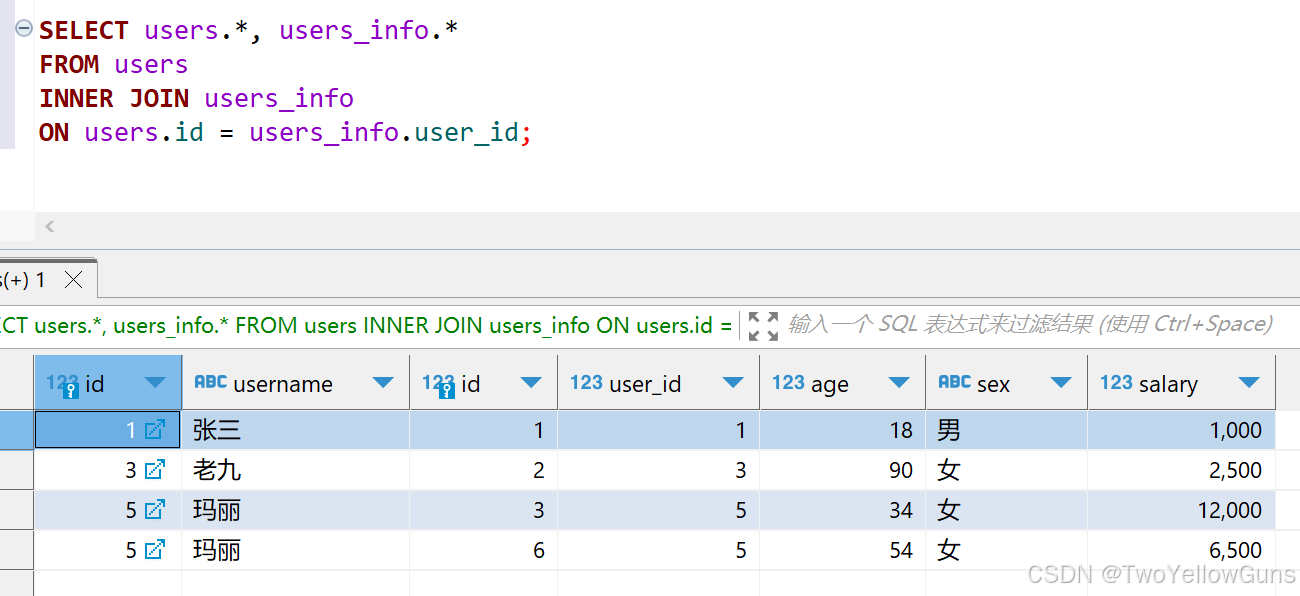
关联的表中如果有多条数据,则多条数据都会被查询除来,如 users 表中的 id=5 的数据在 users_info 表中存在两条数据,则这两条数据都会关联查询到,但是对应的 users 表的字段的值是一样的。
1.1.2 LEFT OUTER JOIN
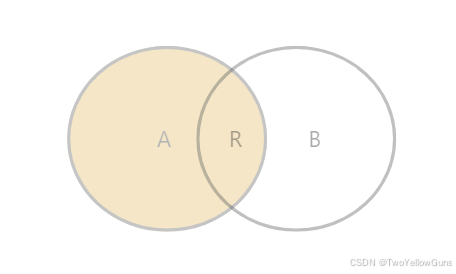
LEFT OUTER JOIN 表示左外连接,即 LEFT OUTER JOIN 左边的表为主表,右边的表为副表。查询的时候会以主表为主,主表返回所有数据行,主表的数据在副表中存在则有值,不存在则为 NULL。
LEFT OUTER JOIN 也用 LEFT JOIN 表示,OUTER 可以省略。
LEFT OUTER JOIN 的语法如下:
sql
SELECT ... FROM table1
LEFT OUTER JOIN table2 ON conditional_expression ...LEFT OUTER JOIN 的结果集可以表示为 A+R:
示例:
sql
SELECT users.*, users_info.*
FROM users
LEFT JOIN users_info
ON users.id = users_info.user_id;查询结果:
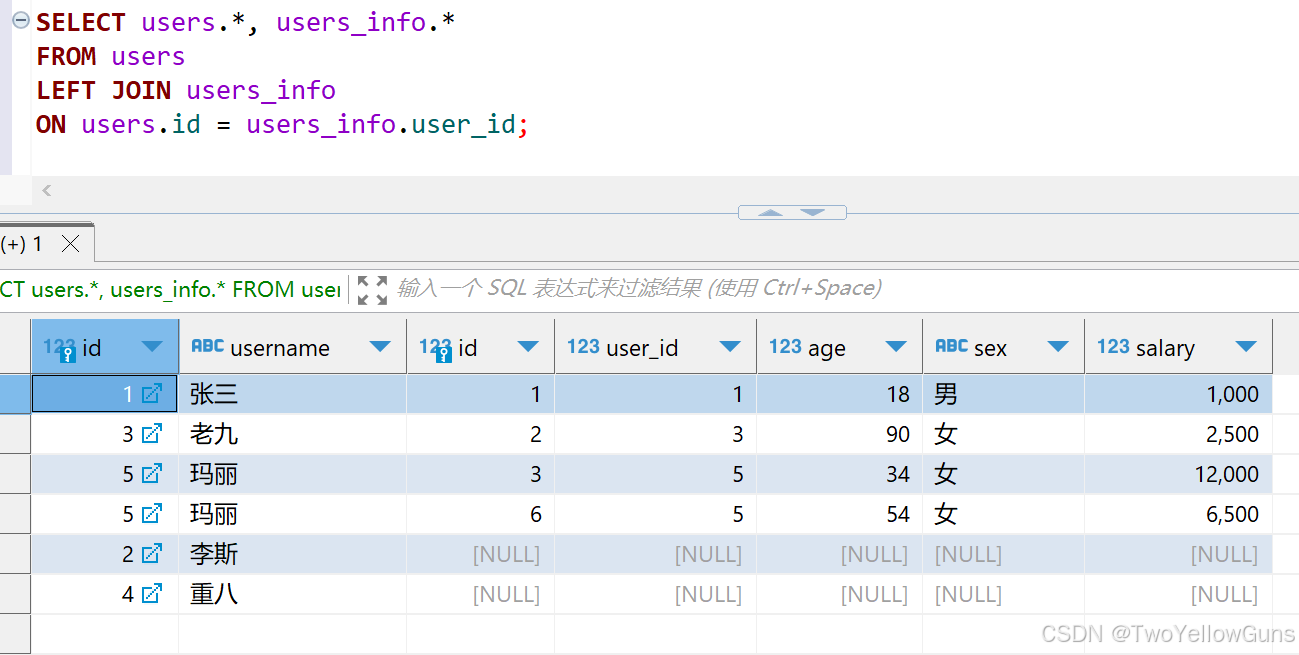
主表(左边的表)返回了所有的数据,主表中 id=2 和 id=4 的数据在副表中不存在,则附表对应的字段为 NULL。
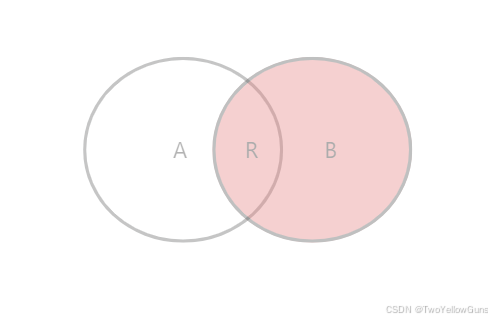
1.1.3 RIGHT OUTER JOIN
RIGHT OUTER JOIN 表示右外连接,与 LEFT OUTER JOIN 的左右相反,即 RIGHT OUTER JOIN 右边的表为主表,左边的表为副表。查询的时候会以右边的表为主,主表返回所有数据行,主表的数据在副表中存在则有值,不存在则为 NULL。
RIGHT OUTER JOIN 也用 RIGH TJOIN 表示,OUTER 可以省略。
RIGHT OUTER JOIN 的语法如下:
sql
SELECT ... FROM table1
RIGHT OUTER JOIN table2 ON conditional_expression ...RIGHT OUTER JOIN 的结果集可以表示为 B+R:
示例:
sql
SELECT users.*, users_info.*
FROM users
RIGHT JOIN users_info
ON users.id = users_info.user_id;查询结果:
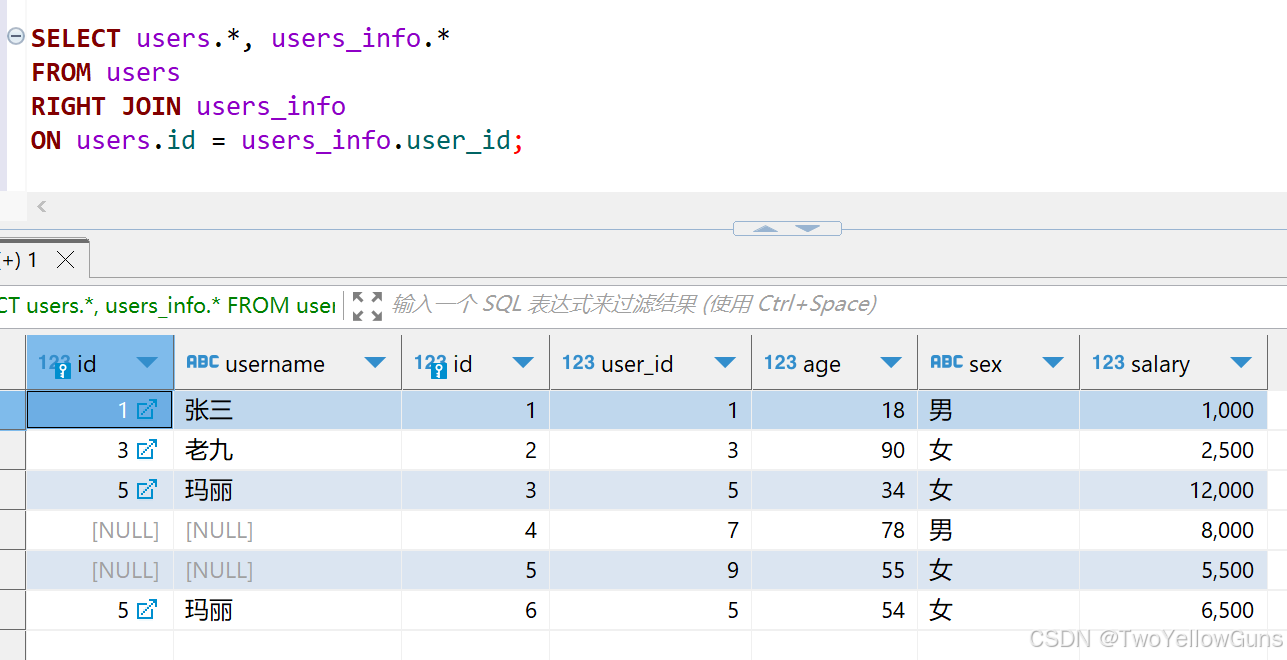
主表(右边的表)返回了所有的数据,主表中 id=4 和 id=5 的数据在副表中不存在,则附表对应的字段为 NULL。
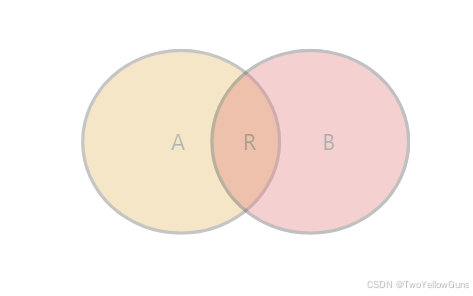
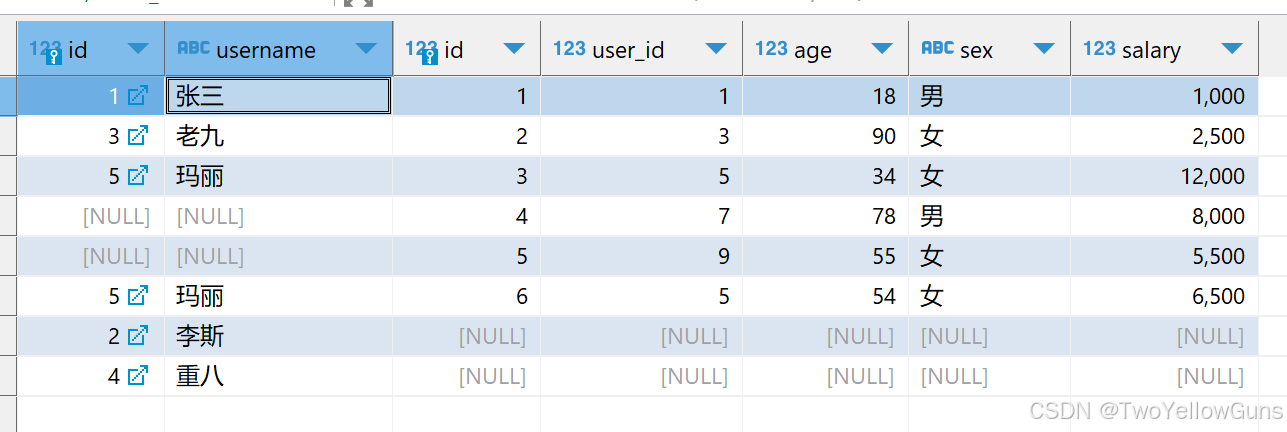
1.1.4 FULL OUTER JOIN
FULL OUTER JOIN 表示全外连接,查询的时候会返回两个表的所有行,不匹配的部分用 NULL 填充。。
FULL OUTER JOIN 也用 FULL JOIN 表示,OUTER 可以省略。
FULL OUTER JOIN 的语法如下:
sql
SELECT ... FROM table1
FULL OUTER JOIN table2 ON conditional_expression ...FULL OUTER JOIN 的结果集可以表示为 A+B+R:
示例:
sql
SELECT users.*, users_info.*
FROM users
FULL JOIN users_info
ON users.id = users_info.user_id;查询结果:
1.1.5 CROSS JOIN
CROSS JOIN 表示笛卡尔积,查询时会返回两个表的所有可能的组合,等价于无条件连接表查询。
CROSS JOIN 的语法如下:
sql
SELECT ... FROM table1
CROSS JOIN table2
-- 等价于
SELECT ... FROM table1, table2示例:
sql
SELECT users.*, users_info.*
FROM users
CROSS JOIN users_info;
-- 等价于
SELECT users.*, users_info.*
FROM users, users_info;查询结果:
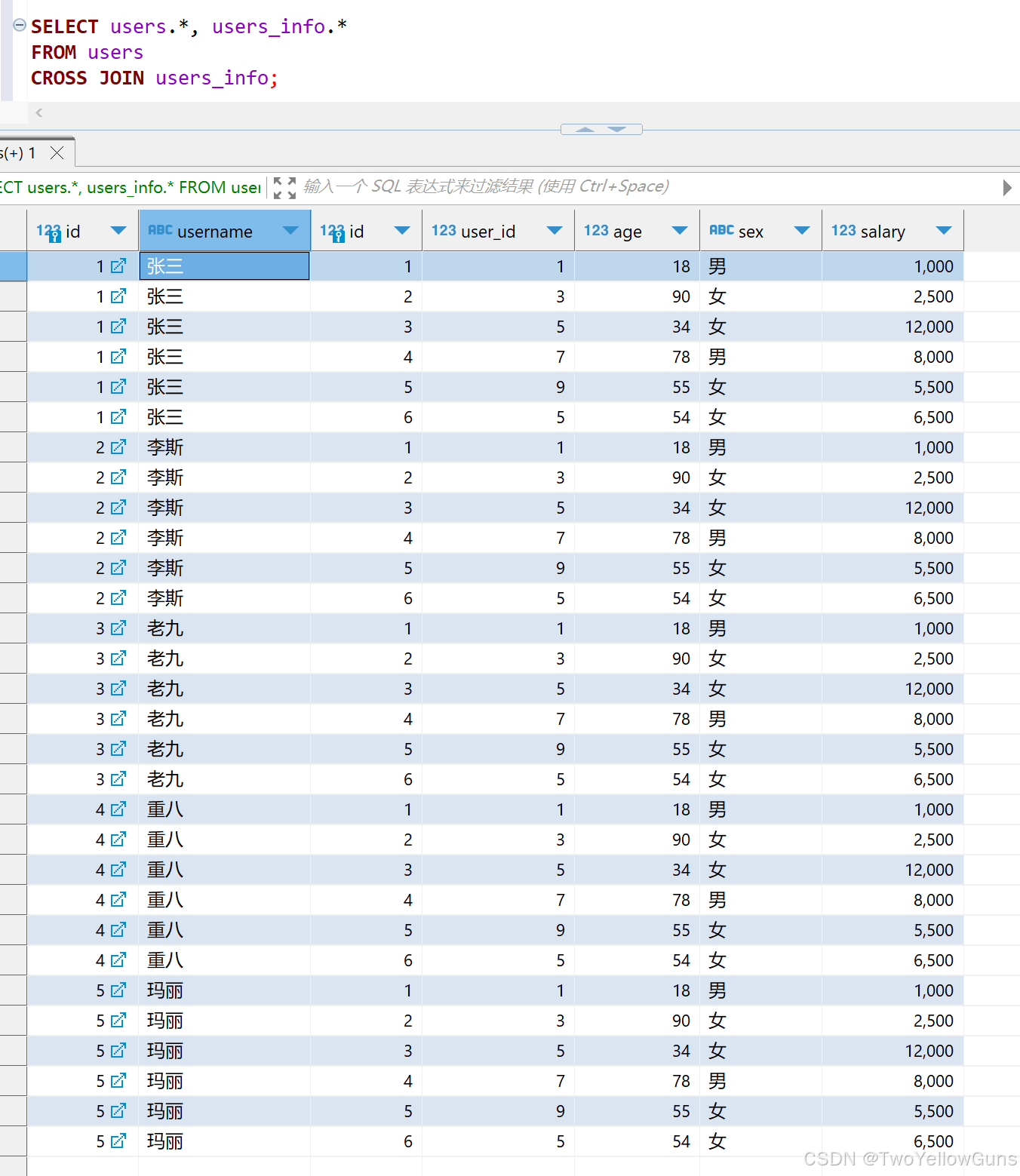
users 表有5条数据,users_info 表有6条数据,则结果集有30条数据。
1.1.6 USING vs ON
当多个表连接查询,连接的列名相同时,可使用 USING 简化,语法如下:
sql
-- 使用 ON
SELECT * FROM orders
JOIN customers ON orders.customer_id = customers.customer_id;
-- 使用 USING
SELECT * FROM orders
JOIN customers USING (customer_id);1.2 PostgreSQL UNION
1.2.1 UNION 介绍
在 PostgreSQL 中,UNION 是一种用于合并多个 SELECT 查询结果集的操作符。
UNION 语法如下:
sql
SELECT column1, column2, ... FROM table1
UNION [ALL]
SELECT column1, column2, ... FROM table2
[UNION [ALL] SELECT ...]
[ORDER BY ...];UNION 要求每个 SELECT 语句的列数必须相同,且对应列的数据类型必须兼容(PostgreSQL 会尝试自动转换),结果集的列名会以第一个 SELECT 的列名为准。
UNION vs UNION ALL
| 特性 | UNION |
UNION ALL |
|---|---|---|
| 去重 | 自动去除重复行 | 保留所有行(包括重复) |
| 性能 | 较慢(需排序去重) | 更快(直接拼接) |
| 使用场景 | 需要唯一结果集 | 允许重复,或已知无重复 |
1.2.2 UNION 排序
使用 UNION 查询时,不能对单个 SELECT 子句排序(除非用子查询),ORDER BY 必须放在整个 UNION 语句的末尾。
sql
SELECT colunm_name FROM table1
UNION
SELECT colunm_name FROM table2
ORDER BY colunm_name;如果需要对子查询排序(通常用于 LIMIT),需用子查询包裹:
sql
SELECT * FROM (
(SELECT colunm_name FROM table1 ORDER BY colunm_name DESC LIMIT 5)
UNION ALL
(SELECT colunm_name FROM table2 ORDER BY colunm_name DESC LIMIT 5)
) AS table_new
ORDER BY colunm_name;1.2.3 INTERSECT / EXCEPT
PostgreSQL 还支持集合操作:
INTERSECT:取两个结果集的交集(默认去重)EXCEPT:取第一个结果集减去第二个(差集)
INTERSECT / EXCEPT 和 UNION 具有相同的数据结构要求,并遵循类似的去重规则(可用 ALL 变体)。
示例:
sql
SELECT id FROM table_a
EXCEPT
SELECT id FROM table_b; -- 在 a 中但不在 b 中的 id1.2.4 UNION 注意事项
(1)NULL 值处理
UNION 会将两个 NULL 视为"相等",因此会被去重。
sql
SELECT NULL::INT
UNION
SELECT NULL::INT;
-- 结果:只有一行 NULL(2)性能影响
UNION 需要临时排序(类似 DISTINCT),大数据量时较慢,如果确定无重复数据,优先用 UNION ALL。
(3)使用 LIMIT / OFFSET
不能直接在 UNION 中使用 LIMIT / OFFSET,除非包裹在子查询中。
二、PostgreSQL 函数
2.1 函数介绍
PostgreSQL 的函数(Functions)是数据库编程的核心能力之一,它允许你将复杂的逻辑封装成可重用的代码单元,在 SQL 查询、触发器、存储过程、应用调用等场景中高效执行。
函数必须有返回值,可用于 SELECT, WHERE, FROM 等 SQL 中,函数不能执行数据库事务控制。
函数的语法如下:
sql
CREATE [ OR REPLACE ] FUNCTION name ( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] )
[ RETURNS rettype
| RETURNS TABLE ( column_name column_type [, ...] )
]
{ LANGUAGE lang_name
| TRANSFORM { FOR TYPE type_name } [, ... ]
| WINDOW
| { IMMUTABLE | STABLE | VOLATILE }
| { LEAKPROOF | NOT LEAKPROOF }
| { CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT }
| { SECURITY INVOKER | SECURITY DEFINER }
| PARALLEL { UNSAFE | RESTRICTED | SAFE }
| COST execution_cost
| ROWS result_rows
| SET configuration_parameter { TO value | = value | FROM CURRENT }
| AS 'definition'
| AS 'obj_file', 'link_symbol'
} ...
$$
-- 函数体(通常用 $$...$$ 或 $tag$...$tag$ 包裹)
$$语法说明:
-
方括号
[...]表示可选,花括号{...}表示必选其一,...表示可重复。 -
CREATE [OR REPLACE] FUNCTION name (...):创建一个函数-
OR REPLACE:如果函数已存在,则替换(保留权限和依赖关系)。 -
函数名:可带
schema,如my_schema.my_func。 -
重载:PostgreSQL 支持同名函数,只要参数类型不同(数量或类型)。
sqlCREATE OR REPLACE FUNCTION add(a INT, b INT) RETURNS INT ...; CREATE OR REPLACE FUNCTION add(a NUMERIC, b NUMERIC) RETURNS NUMERIC ...; -- 重载
-
-
([argmode] [argname] argtype [= default_expr]):函数的参数类型。-
argmode:参数模式-
IN:输入参数,这是函数默认的参数模式,所以可省略不写 -
OUT:输出参数(函数返回多值)sqlCREATE FUNCTION get_user_info(uid INT, OUT name TEXT, OUT email TEXT, OUT age INT) AS $$ SELECT u.name, u.email, u.age FROM users u WHERE u.id = uid; $$ LANGUAGE sql; -- 调用 SELECT * FROM get_user_info(100); -- 或 SELECT (get_user_info(100)).name; -
INOUT:输入+输出 -
VARIADIC:可变参数(数组形式)sqlCREATE FUNCTION sum_all(VARIADIC nums INT[]) RETURNS INT AS $$ DECLARE total INT := 0; BEGIN FOREACH n IN ARRAY nums LOOP total := total + n; END LOOP; RETURN total; END; $$ LANGUAGE plpgsql; SELECT sum_all(1, 2, 3, 4); -- 10
-
-
argname:参数名,可选,但建议命名以提高可读性,在函数体内通过名称引用(PL/pgSQL)。 -
argtype:参数类型,必须指定(如INT,TEXT,TIMESTAMPTZ,users%ROWTYPE等),支持复合类型、域类型、数组(INT[])。 -
DEFAULT 或 =:参数的默认值sqlCREATE FUNCTION greet(name TEXT DEFAULT 'Guest') RETURNS TEXT AS $$ BEGIN RETURN 'Hello, ' || name || '!'; END; $$ LANGUAGE plpgsql; SELECT greet(); -- Hello, Guest! SELECT greet('Alice'); -- Hello, Alice! -
特殊类型:
ANYELEMENT,ANYARRAY,ANYENUM用于泛型函数(需配合RETURNS使用)。
-
-
RETURNS ...:函数的返回类型。-
标量返回:如
RETURNS INTEGER、RETURNS TEXT、RETURNS my_domain_typesqlRETURNS INTEGER RETURNS TEXT RETURNS NUMERIC(10,2) -
表返回(多列):如
RETURNS TABLE(id INT, name TEXT),需要函数体内用RETURN QUERY或RETURN NEXTsqlRETURNS TABLE(id INT, name TEXT) -- 示例 CREATE FUNCTION active_users() RETURNS TABLE(id INT, name TEXT) AS $$ BEGIN RETURN QUERY SELECT u.id, u.name FROM users u WHERE u.active; END; $$ LANGUAGE plpgsql; -- 调用 SELECT * FROM active_users(); -
集合返回(
SETOF):sqlRETURNS SETOF users -- 示例 CREATE FUNCTION top_customers(limit_count INT) RETURNS SETOF customers AS $$ BEGIN RETURN QUERY SELECT * FROM customers ORDER BY total_spent DESC LIMIT limit_count; END; $$ LANGUAGE plpgsql; -
无返回:
RETURNS VOID -
RETURNS TABLE(...)是OUT参数的语法糖,RETURNS SETOF和RETURNS TABLE都可用于SELECT * FROM func()
-
-
LANGUAGE lang_name:指定函数体使用的语言,支持的语言如下:sql:纯SQL,单条语句(可多条用;分隔)plpgsql:过程语言,支持变量、控制流、异常internal:C 内置函数(如upper)c:外部 C 函数(需编译.so文件)plpython3u、plv8等扩展语言
sqlCREATE FUNCTION square(x INT) RETURNS INT LANGUAGE sql AS $$ SELECT x * x; $$; -
TRANSFORM { FOR TYPE type_name }:为特定数据类型注册I/O转换规则,这是比较高级的用法,通常用于外部语言如 Python。 -
WINDOW:表示该函数可用作窗口函数,如row_number(),这个仅适用于用 C 编写的函数,SQL/PLpgSQL无法创建窗口函数。 -
{ IMMUTABLE | STABLE | VOLATILE }:函数稳定性,用于决定优化器如何处理,正确设置可极大提升性能IMMUTABLE:对相同输入永远返回相同结果,且不访问数据库,可用于缓存和索引STABLE:单次查询中结果不变(如now()),单次查询内可以用缓存,但不可用于索引VOLATILE:默认值,结果可能随时变,或有副作用(如random()),不可用于缓存和索引
sql-- 错误示例(危险!): CREATE FUNCTION get_user_name_bad(id INT) RETURNS TEXT IMMUTABLE -- ❌ 错误!会访问数据库 AS $$ SELECT name FROM users WHERE id = $1; $$ LANGUAGE sql; -- 正确应为: STABLE -
{ LEAKPROOF | NOT LEAKPROOF }:表示函数是否会泄露参数信息,默认NOT LEAKPROOF(会泄露参数信息)。LEAKPROOF表示函数不会泄露参数信息(即使执行失败),用于高安全场景(如 RLS 策略中的函数),普通函数无需设置。 -
{ CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT }:对空参数值的处理,对纯计算函数推荐使用STRICT提升性能CALLED ON NULL INPUT:这是默认值,表示即使参数为NULL也调用函数RETURNS NULL ON NULL INPUT或STRICT:任一参数为NULL时,直接返回NULL,不执行函数体
sqlCREATE FUNCTION safe_div(a NUMERIC, b NUMERIC) RETURNS NUMERIC STRICT -- 若 a 或 b 为 NULL,直接返回 NULL AS $$ SELECT a / b; $$ LANGUAGE sql; -
{ SECURITY INVOKER | SECURITY DEFINER }:安全上下文。-
SECURITY INVOKER:默认的方式,以调用者权限执行 -
SECURITY DEFINER:以函数定义者权限执行(类似sudo),使用SECURITY DEFINER时,必须防止search_path攻击sqlCREATE FUNCTION dangerous() RETURNS VOID SECURITY DEFINER SET search_path = pg_catalog, pg_temp -- 关键防护! AS $$ ... $$ LANGUAGE plpgsql;
-
-
PARALLEL { UNSAFE | RESTRICTED | SAFE }:并行安全性(PG ≥10),用于WHERE/JOIN的函数若标记为SAFE,可加速并行查询。PARALLEL UNSAFE:默认的方式,不能在并行worker中运行PARALLEL RESTRICTED:可在并行worker中运行,但不能写数据PARALLEL SAFE:完全安全,可并行
-
COST execution_cost:估算函数的执行代价(单位:cpu_operator_cost,默认 1),方便优化器用于选择执行计划。ql函数默认值为100,plpgsql函数默认值为1000。sqlCREATE FUNCTION fast_hash(x TEXT) RETURNS BYTEA COST 10 -- 告诉优化器这个函数很快 ... -
ROWS result_rows:估算返回的行数(默认 1000),仅用于SETOF或TABLE返回的函数,改配置会影响连接顺序和内存分配。sqlCREATE FUNCTION get_active_users() RETURNS SETOF users ROWS 50 -- 预计只返回约 50 行 ... -
SET configuration_parameter { TO value | = value | FROM CURRENT }:临时修改GUC参数,这个修改仅在函数内生效sqlCREATE FUNCTION use_english() RETURNS TEXT SET lc_messages = 'en_US.UTF-8' AS $$ ... $$ LANGUAGE plpgsql;- 常用于
search_path、timezone、client_min_messages等场景。
- 常用于
-
AS ...:函数体定义-
AS 'definition':内联定义,最常见的使用方式:sqlAS $$ BEGIN RETURN x + y; END; $$ -
AS 'obj_file', 'link_symbol':外部文件,如AS '/path/to/lib.so', 'func_symbol'
-
2.2 函数操作
2.2.1 创建函数
创建一个函数:计算阶乘
sql
CREATE FUNCTION factorial(n INT)
RETURNS INT
IMMUTABLE
AS $$
BEGIN
IF n <= 1 THEN
RETURN 1;
ELSE
RETURN n * factorial(n - 1);
END IF;
END;
$$ LANGUAGE plpgsql;2.2.2 查看函数
PostgreSQL 中,查看已有的函数可以通过下面的方式
sql
-- 列出所有函数
\df
-- 查看函数定义
\df+ function_name示例:

还可以通过查询系统表来查看函数:
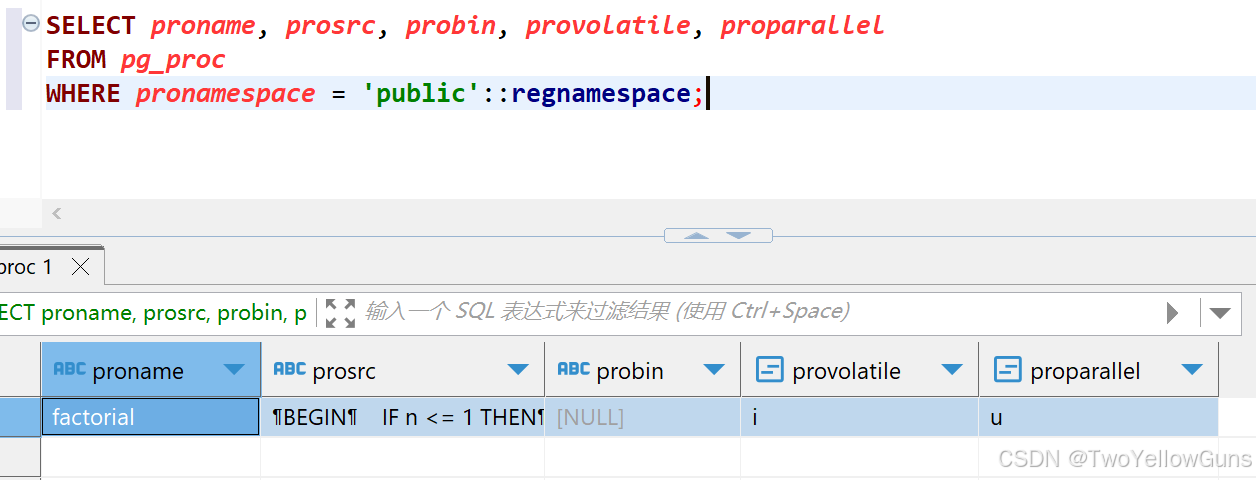
sql
SELECT proname, prosrc, probin, provolatile, proparallel
FROM pg_proc
WHERE pronamespace = 'public'::regnamespace;结果:
2.2.3 使用函数
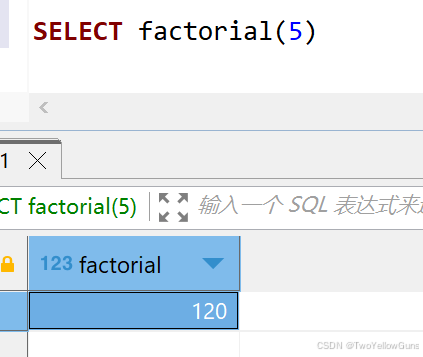
使用已经创建的函数,如前面创建的阶乘函数:
sql
SELECT factorial(5)结果:
2.2.4 删除函数
删除函数的语法如下:
sql
DROP FUNCTION IF EXISTS function_name(
[arg_name] arg_type [= default_value],
...
);删除函数需指定参数类型,因为函数可以重载。
示例:

三、PostgreSQL 存储过程
3.1 存储过程介绍
PostgreSQL 从版本 11(2018年发布) 开始正式支持存储过程(Stored Procedures),通过 CREATE PROCEDURE 语句实现。
存储过程的语法如下:
sql
CREATE [ OR REPLACE ] PROCEDURE name ( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] )
{ LANGUAGE lang_name
| TRANSFORM { FOR TYPE type_name } [, ... ]
| { IMMUTABLE | STABLE | VOLATILE }
| { LEAKPROOF | NOT LEAKPROOF }
| { CALLED ON NULL INPUT | STRICT }
| { SECURITY INVOKER | SECURITY DEFINER }
| PARALLEL { UNSAFE | RESTRICTED | SAFE }
| COST execution_cost
| SET configuration_parameter { TO value | = value | FROM CURRENT }
| AS 'definition'
| AS 'obj_file', 'link_symbol'
} ...
$$
-- 过程体(通常用 $$...$$ 包裹)
$$语法详解:
-
CREATE [ OR REPLACE ] PROCEDURE name ():创建语句OR REPLACE:如果同名过程已存在,则替换它(保留权限和依赖关系)。name:存储过程的名字,可以携带schema,如admin.cleanup_logs。存储过程支持重载,只要参数类型不同(数量或类型)。
sqlCREATE PROCEDURE log_event(msg TEXT); CREATE PROCEDURE log_event(msg TEXT, level TEXT DEFAULT 'INFO'); -- 重载 -
[ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ]:存储过程的参数列表-
argmode:参数模式IN:输入参数,默认的模式,所以可省略不写OUT:输出参数(调用后可获取值)INOUT:输入+输出VARIADIC:可变参数(转为数组)
-
argtype:参数类型,必须指定(如INT,TEXT[],my_table%ROWTYPE)。
sqlCREATE PROCEDURE notify_user( user_id INT, message TEXT, channel TEXT DEFAULT 'email' ) ... -
-
LANGUAGE lang_name:指定过程体使用的语言plpgsql:最常用,支持变量、控制流、异常、事务控制sql:仅支持简单SQL语句(不支持COMMIT/ROLLBACK)plpython3u:等外部语言(需扩展)
-
TRANSFORM { FOR TYPE type_name } [, ... ]:表示过程是否会泄露参数信息,默认NOT LEAKPROOF(会泄露参数信息)。LEAKPROOF表示过程不会泄露参数信息(即使执行失败),用于高安全场景(如 RLS 策略中的函数),普通过程无需设置。 -
{ IMMUTABLE | STABLE | VOLATILE }:行为属性IMMUTABLE:结果永不随时间/数据变化,适用于仅纯计算(但过程通常修改数据,故极少用)STABLE:单次查询中结果不变,过程不用于SELECTVOLATILE:默认的行为属性,结果可能变化,或有副作用,绝大多数存储过程应为VOLATILE
-
{ LEAKPROOF | NOT LEAKPROOF }: -
{ CALLED ON NULL INPUT | STRICT }:空值处理CALLED ON NULL INPUT:默认的空值处理方式,即使参数为NULL也执行STRICT:任一IN参数为NULL时,跳过执行(但OUT参数仍会被赋值为NULL)
-
{ SECURITY INVOKER | SECURITY DEFINER }:SECURITY INVOKER:默认的方式,以调用者权限执行SECURITY DEFINER:以过程定义者权限执行(类似sudo),使用SECURITY DEFINER时,必须防止search_path攻击
sqlCREATE PROCEDURE safe_drop() SECURITY DEFINER SET search_path = pg_catalog, pg_temp LANGUAGE plpgsql AS $$ BEGIN DROP TABLE IF EXISTS temp_data; COMMIT; END; $$; -
PARALLEL { UNSAFE | RESTRICTED | SAFE }:并行安全性(PG ≥10),用于WHERE/JOIN的过程若标记为SAFE,可加速并行查询。PARALLEL UNSAFE:默认的方式,不能在并行worker中运行PARALLEL RESTRICTED:可在并行worker中运行,但不能写数据PARALLEL SAFE:完全安全,可并行
-
COST execution_cost:估算过程的执行代价(单位:cpu_operator_cost,默认 1),方便优化器用于选择执行计划。ql函数默认值为100,plpgsql函数默认值为1000。 -
SET configuration_parameter { TO value | = value | FROM CURRENT }:临时修改GUC参数,这个修改仅在过程内生效sqlCREATE PROCEDURE set_timezone() SET timezone = 'UTC' LANGUAGE plpgsql AS $$ BEGIN INSERT INTO logs(event_time) VALUES (NOW()); -- 使用 UTC COMMIT; END; $$; -
AS ...:过程体定义AS 'definition':内联定义,最常见的使用方式:AS 'obj_file', 'link_symbol':外部文件,如AS '/path/to/lib.so', 'func_symbol'
-
$$ ... $$:过程体-
必须是字符串字面量,推荐
$$ ... $$避免引号转义 -
在
plpgsql中,可包含:- 变量声明(
DECLARE) - 控制结构(
IF,LOOP,FOR) - SQL 语句(
INSERT,UPDATE等) - 事务命令:
COMMIT,ROLLBACK,SAVEPOINT
- 变量声明(
-
示例:
sql
CREATE PROCEDURE batch_process()
LANGUAGE plpgsql
AS $$
BEGIN
-- 第一批处理
UPDATE orders SET status = 'processed' WHERE batch = 1;
COMMIT; -- ✅ 允许!
-- 第二批处理
UPDATE orders SET status = 'processed' WHERE batch = 2;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
ROLLBACK;
RAISE;
END;
$$;存储过程与传统的 函数(Function) 有本质区别,尤其在事务控制和调用方式上:
| 特性 | 存储过程(Procedure) | 函数(Function) |
|---|---|---|
| 创建语句 | CREATE PROCEDURE |
CREATE FUNCTION |
| 返回值 | 不能直接返回值(但可通过 INOUT/OUT 参数传递) |
必须声明 RETURNS |
| 调用方式 | CALL procedure_name(...) |
可在 SQL 中直接调用(如 SELECT func()) |
| 事务控制 | 支持 COMMIT、ROLLBACK、SAVEPOINT |
不允许(函数必须在单一事务中) |
| 使用场景 | 批处理、ETL、复杂业务流程、需要分步提交的操作 | 计算、转换、触发器、SQL 表达式中使用 |
3.2 存储过程操作
3.2.1 创建存储过程
创建一个存储过程,在存储过程中修改指定用户的名称
sql
CREATE PROCEDURE update_username(user_id INT)
LANGUAGE plpgsql
AS $$
BEGIN
UPDATE users SET name = '666' WHERE id = user_id;
EXCEPTION
WHEN OTHERS THEN
ROLLBACK;
RAISE;
END;
$$;3.2.2 查看存储过程
通过以下命令可以查看已存在的存储过程
\dfp:列出所有存储过程\dfp+ proc_name:查看存储过程的定义
示例:

也可以通过查询系统表来查看存储过程
sql
SELECT * FROM pg_proc WHERE prokind = 'p';示例:
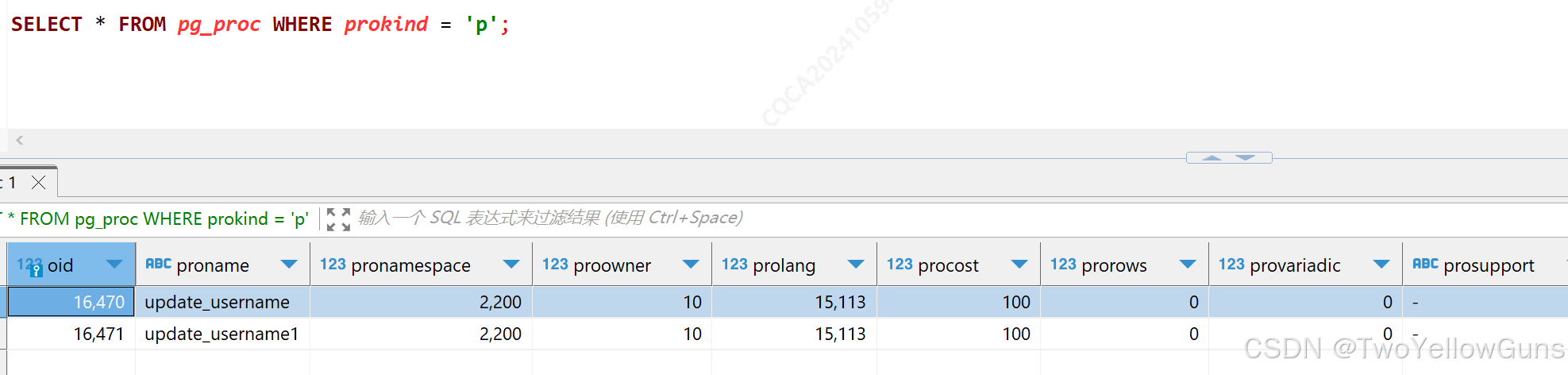
3.2.3 使用存储过程
存储过程调用语法:
sql
CALL procedure_name(arg1, arg2, ..., argN);说明:
- 必须使用
CALL,不能在SELECT中调用
示例:
sql
CALL update_username(2);3.2.4 删除存储过程
存储过程删除语法:
sql
DROP PROCEDURE IF EXISTS procedure_name();示例:
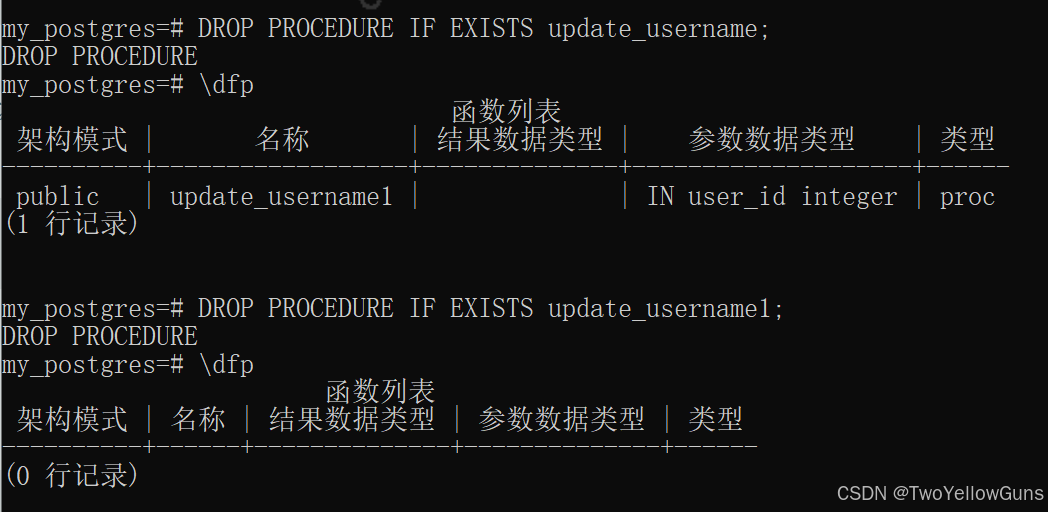
四、PostgreSQL 触发器
4.1 触发器介绍
在 PostgreSQL 中的触发器(Trigger)是一种特殊的数据库对象,触发器不是独立执行的 SQL 语句,而是一种事件驱动机制,当对表(或视图)执行 INSERT、UPDATE、DELETE 或 TRUNCATE 操作时,数据库引擎会自动调用与该事件绑定的触发器函数,该函数可以访问操作前后的数据(OLD / NEW),并决定是否允许操作继续、修改数据、记录日志等。
触发器的分类:
-
按触发时机分:
BEFORE:在数据写入前触发(可修改NEW,可取消操作)AFTER:在数据写入且约束检查通过后触发(不能修改数据)INSTEAD OF:仅用于视图,替代原操作(实现可更新视图)
-
按触发粒度分
FOR EACH ROW:每行触发一次(可访问OLD/NEW)FOR EACH STATEMENT:整条SQL语句触发一次(不可访问OLD/NEW)
-
特殊类型:事件触发器
- 监听
DDL事件(如CREATE TABLE,DROP INDEX) - 不绑定到具体表,而是全局生效
- 使用
CREATE EVENT TRIGGER(本文聚焦普通触发器)
- 监听
触发器的创建语法:
sql
CREATE TRIGGER trigger_name [BEFORE|AFTER|INSTEAD OF] event_name
ON table_name
[
-- 触发器逻辑....
];语法详解:
-
CREATE [ CONSTRAINT ] TRIGGER trigger_name:创建触发器trigger_name:触发器名称,不能重复CONSTRAINT:用于创建约束触发器(Constraint Trigger),支持延迟检查(DEFERRABLE),常用于实现跨行/跨表业务规则(如预算控制)
sqlCREATE CONSTRAINT TRIGGER check_total_expense AFTER INSERT OR UPDATE ON expenses DEFERRABLE INITIALLY DEFERRED FOR EACH ROW EXECUTE FUNCTION validate_budget(); -
{ BEFORE | AFTER | INSTEAD OF }:触发器的触发时机BEFORE:在行写入前触发,可修改数据NEW,常用于数据校验、默认值填充。BEFORE返回NULL则取消当前行操作AFTER:在行写入且约束通过后触发,不可修改数据,常用于审计日志、通知、缓存失效INSTEAD OF:仅用于视图,替代原操作, 可以自定义逻辑,常用于实现可更新视图
-
{ event [ OR ... ] }:事件,支持以下事件组合INSERT:用于插入,BEFORE、AFTER、INSTEAD OF都可以触发UPDATE [ OF column\_name [, ...] ]:用于更新(可指定列),BEFORE、AFTER、INSTEAD OF都可以触发DELETE:用于删除,BEFORE、AFTER、INSTEAD OF都可以触发TRUNCATE:用于清空表(DDL操作),仅AFTER+STATEMENT配置时触发
sqlCREATE TRIGGER tr_salary_change AFTER UPDATE OF salary, bonus ON employees FOR EACH ROW EXECUTE FUNCTION log_compensation_change(); -- 仅当 salary 或 bonus 被更新时才触发 -
ON table_name:必须指定目标表(或 可更新视图),指定后触发器属于该表的元数据,如果是分区表则需在每个子分区上单独创建(父表触发器不继承) -
[ FROM referenced_table_name ]:仅用于外键相关的约束触发器,通常由系统自动生成,用户极少手动使用,如当引用表被删除时,触发级联操作 -
[ NOT DEFERRABLE | [ DEFERRABLE ] { INITIALLY IMMEDIATE | INITIALLY DEFERRED } ]:仅当配置使用CONSTRAINT TRIGGER时有效NOT DEFERRABLE:触发器默认的方式,在语句结束时立即检查DEFERRABLE INITIALLY IMMEDIATE:默认是立即检查,但可临时延迟检查DEFERRABLE INITIALLY DEFERRED:默认是延迟到事务提交时检查
-
[ FOR [ EACH ] { ROW | STATEMENT } ]:触发器触发的频率FOR EACH ROW:每行数据被修改时触发一次,可用变量为OLD/NEW,性能开销较高,常用于行级校验、审计FOR EACH STATEMENT:每条SQL执行时触发一次,性能开销低,常用于发送通知、清理全局状态
-
[ WHEN ( condition ) ]:仅行级触发器支持。- 条件为
boolean表达式,可引用OLD、NEW、表列 - 避免函数调用,会影响性能
sql-- 高效示例: WHEN (OLD.status IS DISTINCT FROM NEW.status) -- 比 WHEN (OLD.status != NEW.status) 更安全(处理 NULL) -- 低效示例: WHEN (expensive_function(NEW.id)) -- 每行都调用! - 条件为
-
EXECUTE { FUNCTION | PROCEDURE } function_name ( arguments ):- 必须是触发器函数,不能是普通函数或存储过程(尽管语法允许
PROCEDURE,但实际必须返回TRIGGER),函数必须声明为RETURNS TRIGGER - 参数传递:参数在函数中通过
TG_ARGV数组访问(TEXT[]类型),索引从 0 开始
sql-- 创建函数 CREATE FUNCTION log_change(table_name TEXT, action TEXT) RETURNS TRIGGER AS $$ BEGIN RAISE NOTICE 'Table: %, Action: %', TG_ARGV[0], TG_ARGV[1]; RETURN NEW; END; $$ LANGUAGE plpgsql; -- 创建触发器 CREATE TRIGGER tr_example BEFORE UPDATE ON users FOR EACH ROW EXECUTE FUNCTION log_change('users', 'update'); -- TG_ARGV[0] = 'users', TG_ARGV[1] = 'update' - 必须是触发器函数,不能是普通函数或存储过程(尽管语法允许
触发器执行顺序规则:
-
同一表上的多个触发器:
- 所有
BEFORE先于AFTER - 同类触发器按创建顺序执行
- 可通过
ALTER TRIGGER name DEPENDS ON other_trigger调整依赖
- 所有
-
与约束的顺序:
BEFORE 触发器 → 行约束(CHECK/NOT NULL) → 唯一/外键约束 → AFTER 触发器 -
递归触发:默认允许递归触发(可能无限循环),可以用
pg_trigger_depth()限制:IF pg_trigger_depth() > 1 THEN RETURN NEW; END IF;
4.2 触发器操作
4.2.1 创建触发器
创建一个触发器:当 users 每新增一条数据吗,就往 users_info 表插入一条用的数据
sql
-- 创建触发器函数
CREATE OR REPLACE FUNCTION sync_user_to_info()
RETURNS TRIGGER AS $$
DECLARE
random_id INT4;
BEGIN
-- 生成 1 到 2147483647 之间的随机 int4
random_id := floor(random() * 2147483647 + 1)::INT4;
INSERT INTO users_info (id, user_id)
VALUES (random_id , NEW.id);
RETURN NULL; -- AFTER 触发器通常返回 NULL
END;
$$ LANGUAGE plpgsql;NEW 代表刚插入的行,因为是 AFTER INSERT,此时 NEW.id 已经生成(即使是 SERIAL)。
创建触发器
sql
CREATE TRIGGER tr_sync_users_to_info
AFTER INSERT ON users
FOR EACH ROW
EXECUTE FUNCTION sync_user_to_info();4.2.2 查看触发器
通过命令 \d + table_name 可以查看表上所有触发器
示例:
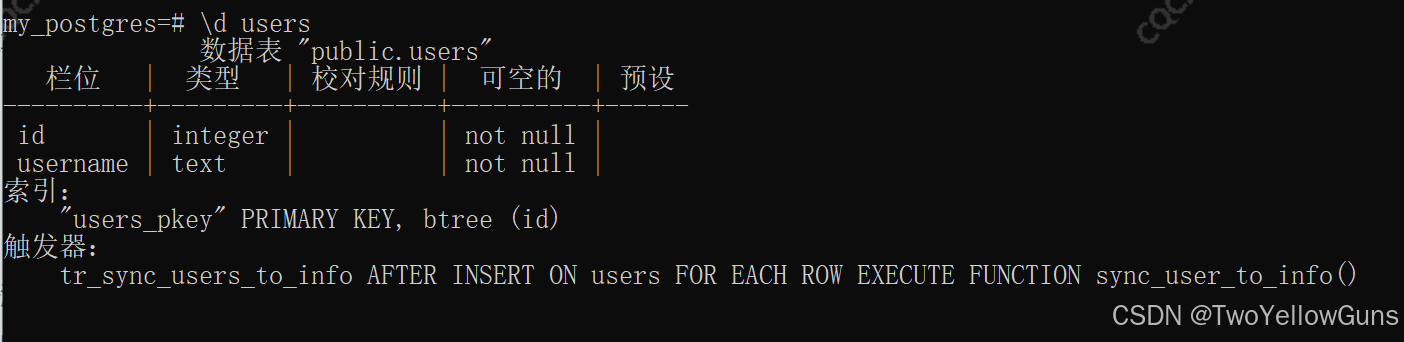
通过查询触发器表列出所有触发器
sql
SELECT tgname, tgenabled FROM pg_trigger;tgenabled 字段含义:
O= Origin(默认,主库执行)D= DisabledR= Replica(仅在逻辑复制从库执行)A= Always(主从都执行)
示例:
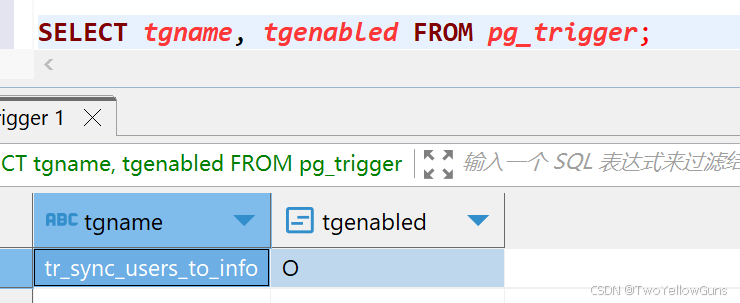
4.2.3 使用触发器
这是目前 users 表和 users_info 表的数据:
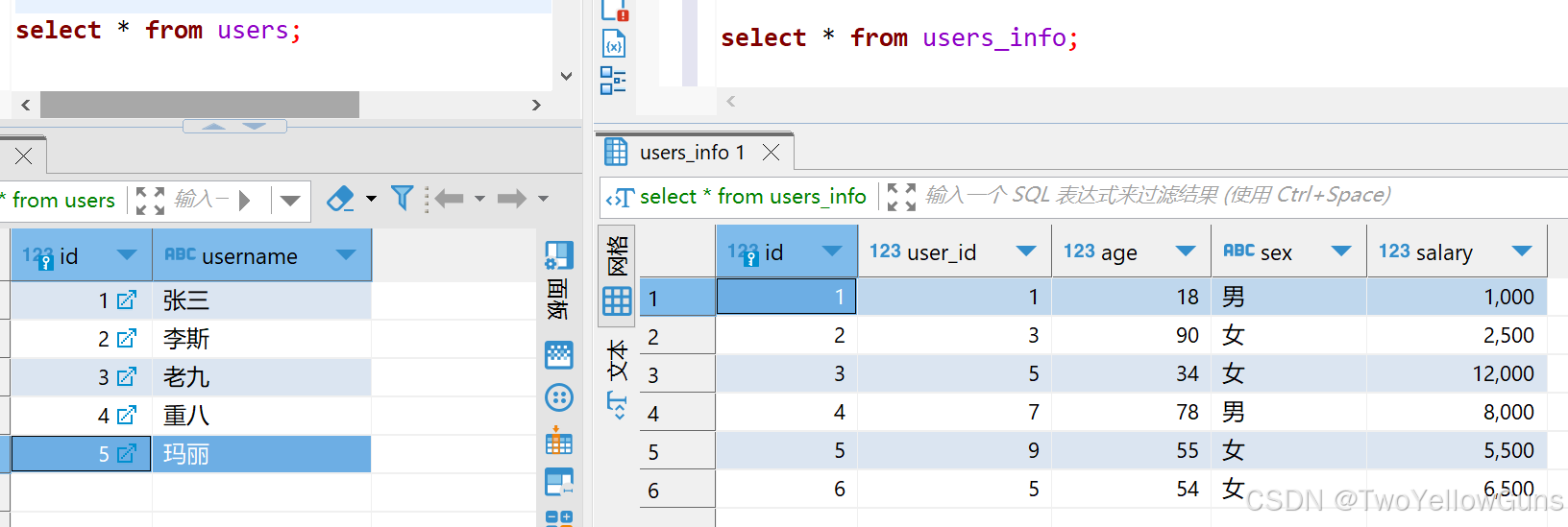
现在往 users 表中新增一条数据:
sql
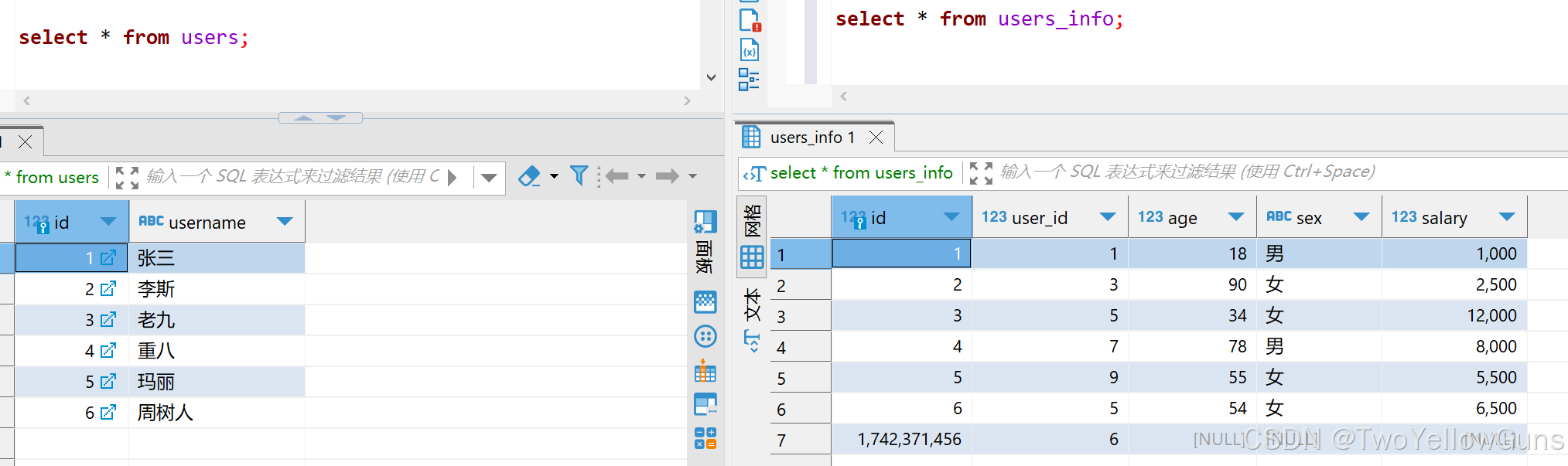
INSERT INTO users (id,username) VALUES (6,'周树人');新增成功后,users 表和 users_info 表的数据:
4.2.4 启用/禁用触发器
禁用触发器:
sql
ALTER TABLE tbl DISABLE TRIGGER tr_name;启用触发器:
sql
ALTER TABLE tbl ENABLE TRIGGER tr_name;永久启用触发器:
sql
ALTER TABLE tbl ENABLE ALWAYS TRIGGER tr_name;示例:
sql
-- 禁用触发器
ALTER TABLE users DISABLE TRIGGER tr_sync_users_to_info;
-- 启用触发器
ALTER TABLE users ENABLE TRIGGER tr_sync_users_to_info;
-- 永久启用触发器
ALTER TABLE users ENABLE ALWAYS TRIGGER tr_sync_users_to_info;4.2.5 删除触发器
删除触发器语法:
sql
DROP TRIGGER [IF EXISTS] tr_name ON table_name;示例:
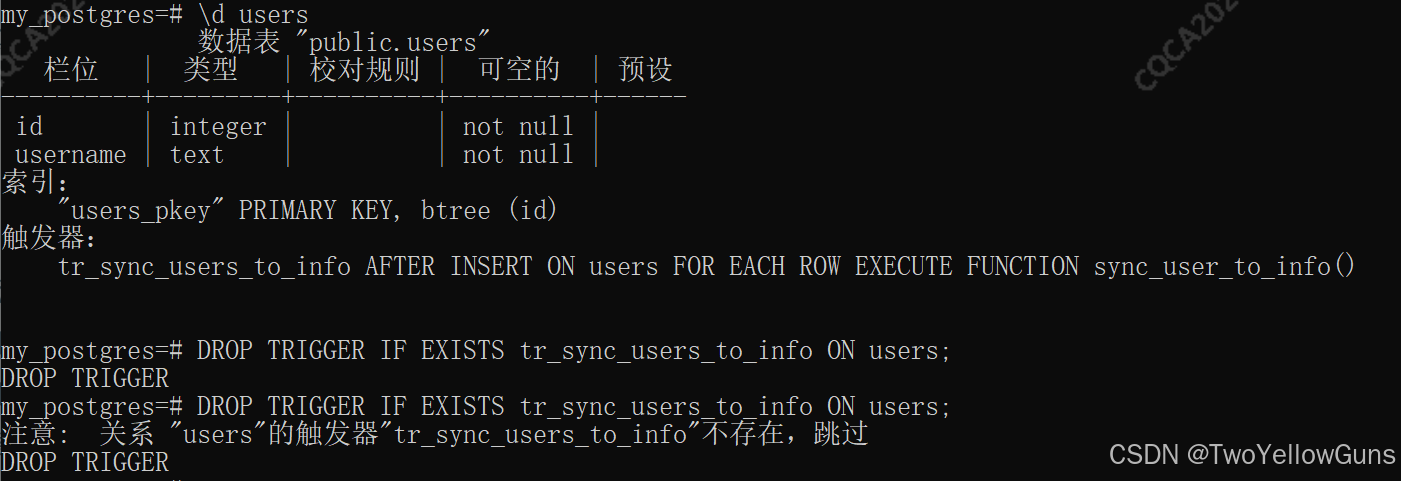
五、PostgreSQL 视图
5.1 视图介绍
在PostgreSQL中,视图(View)是一种虚拟表,其内容由查询定义。与普通表不同的是,视图本身不存储数据;相反,它是在你访问视图时运行一个预定义的查询来动态生成数据。
视图常用于简化复杂的查询、提供额外的安全层以及帮助组织和展示数据。
创建视图的语法如下:
sql
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;5.2 视图操作
5.2.1 创建视图
在 user 表上创建如下两个视图:
sql
CREATE VIEW test_view1 AS
SELECT * FROM users;
CREATE VIEW test_view2 AS
SELECT * FROM users
WHERE id < 5;5.2.2 查看/使用视图
使用如下命令可以查看视图:
\dv:列出当前 schema(通常是 public)下的所有视图。\dv+:加+可显示更多信息\dv schemaname.*:指定 schema 查看视图
示例:
使用视图:
sql
SELECT * FROM view_name示例:
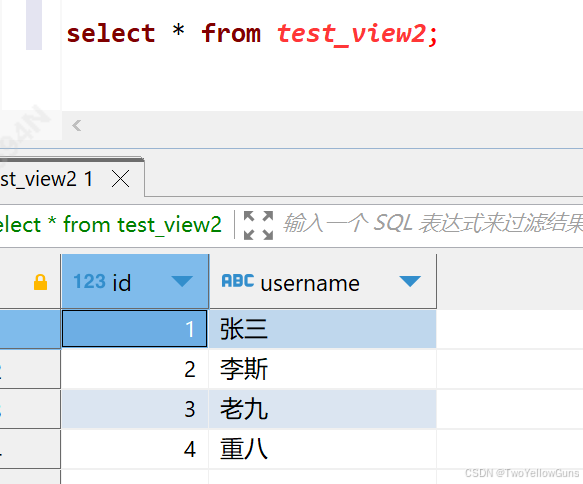
5.2.3 修改视图
修改视图可以使用 CREATE OR REPLACE VIEW 命令:
sql
CREATE OR REPLACE VIEW view_name AS
SELECT column1, column2, ...
FROM table_name
WHERE condition;示例:
sql
CREATE OR REPLACE VIEW test_view2 AS
SELECT * FROM users
WHERE id < 5;5.2.4 删除视图
删除视图可以使用 DROP VIEW 命令:
sql
DROP VIEW IF EXISTS view_name;示例:
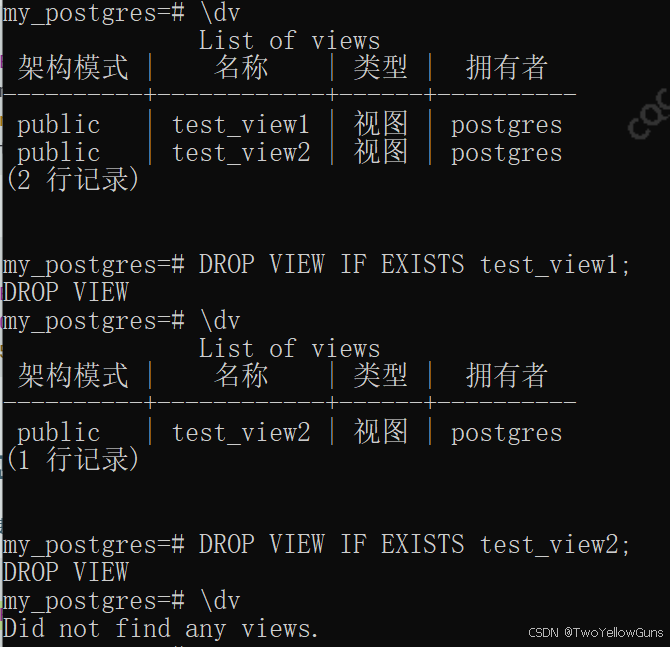
六、PostgreSQL 索引
6.1 索引介绍
索引是加速搜索引擎检索数据的一种特殊表查询,PostgreSQL 的索引是提升查询性能的核心机制,合理使用索引,可以让百万级甚至十亿级数据的查询从"几秒"降到"毫秒"。
按逻辑用途/创建方式分类,PostgreSQL 支持以下索引:
| 索引类型 | 定义 | 创建方式 | 适用场景 | 是否自动创建 |
|---|---|---|---|---|
| 单列索引 | 在单个列上创建的索引 | CREATE INDEX idx ON table (col); |
高频查询、过滤、排序的单字段 | 否(主键/唯一约束除外) |
| 组合索引 | 也叫复合索引,在多个列上创建的索引 | CREATE INDEX idx ON table (col1, col2, ...); |
多条件联合查询、覆盖索引优化 | 否 |
| 唯一索引 | 保证索引列的值全局唯一 | CREATE UNIQUE INDEX idx ON table (col); |
防止重复(如用户名、邮箱) | 是(当定义 UNIQUE 约束时) |
| 局部索引 | 也叫部分索引,只对满足 WHERE 条件的行建索引 |
CREATE INDEX idx ON table (col) WHERE condition; |
状态过滤(如只查"未删除"数据) | 否 |
| 隐式索引 | 系统自动创建的索引 | 无需手动创建 | 主键、唯一约束、排除约束等 | 是 |
按数据结构/算法分类,PostgreSQL 支持以下索引:
| 索引类型 | 适用场景 | 是否默认 | 支持操作符 |
|---|---|---|---|
| B-tree | 通用(等值、范围、排序) | 是 | =, <, <=, >, >=, BETWEEN, IN, LIKE 'abc%' |
| Hash | 仅等值查询(=) |
否 | = |
| GiST | 多维数据(几何、全文检索、GIS) |
否 | 多种(如 &&, @>, <@) |
| SP-GiST | 非平衡树(如四叉树、k-d 树) |
否 | 类似 GiST |
| GIN | 倒排索引(数组、JSON、全文检索) |
否 | @>, &&, = ANY() |
| BRIN | 超大表(按物理顺序存储的数据) | 否 | =, <, <=, >, >= |
| RUM(需扩展) | 全文检索 + 排序 | 否 | <->, ts_rank |
6.2 索引用途
6.2.1 单列索引
单列索引是一个只基于表的单个列上创建的索引,是最基础、最常用的索引。
单列索引常用于单字段的高频查询、过滤和排序等场景,建立索引时应该优先考虑高选择性字段(如邮箱、手机号),不适用于性别(只有男/女)这类低区分度字段。
单列索引创建语法:
sql
CREATE INDEX index_name ON table_name (column_name);示例:
sql
CREATE INDEX idx_userId ON users_info (user_id);6.2.2 组合索引
组合索引是基于表的多个列创建的索引,创建时遵循"最左前缀原则",查询时条件的顺序必须从最左列开始连续使用。
索引创建语法:
sql
CREATE INDEX index_name
ON table_name (column1_name, column2_name);示例:
sql
CREATE INDEX idx_userId_createdTime ON users_info (user_id, created_time);组合索引的使用必须严格按照创建时使用的列顺序,否则会导致索引失效,如下示例:
sql
-- 先 user_id,再 created_time
CREATE INDEX idx_userId_createdTime ON users_info (user_id, created_time);
-- 能用索引
SELECT * FROM users_info WHERE user_id = 100;
SELECT * FROM users_info WHERE user_id = 100 AND created_time > '2025-01-01';
-- 不能用索引(跳过 user_id)
SELECT * FROM users_info WHERE created_time > '2025-01-01';组合索引的创建建议:
- 等值列优先放在前面,范围列放后面,如
user_id, created_time比created_time, user_id更高效,因为user_id是等值查询。 - 索引包含的列建议 3~4 列,太多会增加维护开销。
6.2.3 唯一索引
唯一索引强制索引列(或列组合)的值不能重复,插入/更新时自动检查唯一性,冲突则报错。唯一约束(UNIQUE)底层就是唯一索引。
唯一索引可以手动创建,也可以通过添加约束时由系统自动创建。
索引创建语法:
sql
-- 手动创建
CREATE UNIQUE INDEX index_name on table_name (column_name);
-- 通过约束创建
ALTER TABLE table_name ADD CONSTRAINT index_name UNIQUE (column_name);示例:
sql
-- 手动创建唯一索引
CREATE INDEX uk_mobile ON users_info (mobile);
-- 通过约束创建
ALTER TABLE users ADD CONSTRAINT uk_mobile UNIQUE (mobile);唯一索引允许
NULL,且多个NULL不视为重复(符合 SQL 标准)。
6.2.4 局部索引
局部索引是在表的子集上构建的索引,子集由一个条件表达式上定义,索引只包含满足条件的行。
索引创建语法:
sql
CREATE INDEX index_name
ON table_name(column_list)
WHERE condition;column_list:是想要索引的列的列表condition:布尔表达式,用于定义哪些行将被包含在索引中。
示例:
sql
-- 只为 状态正常的用户 建索引
CREATE INDEX idx_statusNormal
ON users (status)
WHERE status = 1 AND is_deleted = 0;查询时,必须按照创建索引时添加的相同条件才能使用索引:
sql
SELECT * FROM users
WHERE status = 1
AND is_deleted = 0;典型场景:
- 软删除:
WHERE is_deleted = false - 状态过滤:
WHERE order_status = 'pending' - 分区逻辑:
WHERE region = 'CN'
6.2.5 隐式索引
在 PostgreSQL 中,隐式索引是在创建对象时,由数据库服务器自动创建的索引,这类索引通常为主键约束和唯一约束自动创建。
当在创建表时声明一个列为主键、唯一约束或外键时,PostgreSQL 会自动为该列创建一个隐式索引。
| 约束类型 | 是否创建隐式索引 | 索引类型 |
|---|---|---|
PRIMARY KEY |
是 | 唯一 B-tree 索引 |
UNIQUE |
是 | 唯一 B-tree 索引 |
EXCLUDE |
是 | GiST 索引(或其他) |
FOREIGN KEY |
否 | 需手动建索引 |
示例:
sql
-- 创建带主键的表
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name TEXT UNIQUE
);
-- 查看索引(psql)
\d products6.3 索引结构/算法
6.3.1 B-tree
适用场景:
- 等值查询:
WHERE id = 100 - 范围查询:
WHERE age BETWEEN 20 AND 30 - 排序:
ORDER BY created_at - 前缀匹配:
WHERE name LIKE 'John%'
复合索引的"最左前缀"原则,索引 (a, b, c) 可用于:
WHERE a = 1WHERE a = 1 AND b = 2WHERE a = 1 AND b = 2 AND c = 3WHERE a = 1 ORDER BY b
不能用于:
WHERE b = 2(跳过 a)WHERE c = 3WHERE b = 2 AND c = 3
6.3.2 Hash
适用场景:
- 只用于
=查询 - 内存中快速查找(比
B-tree快 10~20%) - PostgreSQL 10+ 开始支持
WAL日志(可安全用于生产)
创建语法:
sql
CREATE INDEX index_name ON table_name USING HASH (column_name);6.3.3 GiST
GiST(Generalized Search Tree,泛化搜索树) 是 PostgreSQL 中一种高度灵活的索引结构,专为复杂数据类型(如几何、全文检索、GIS、自定义类型)设计。它不是单一算法,而是一个可扩展的框架,允许开发者为其支持的数据类型定义自己的"搜索策略"。
GiST = 通用索引框架 + 可插拔操作符类。GiST 不直接存储数据,而是通过一致性函数(consistent) 和联合函数(union) 来组织索引页,每个支持 GiST 的数据类型需提供一组操作符类(Operator Class),告诉 GiST 如何比较、合并和搜索。
GiST 索引的优缺点
-
优点
- 支持复杂数据类型(几何、范围、全文等)
- 写入性能好(比
GIN快,WAL友好) - 索引体积较小
- 支持
KNN(K 最近邻)搜索(如<->距离排序)
-
缺点
- 不支持唯一约束
- 查询性能略低于
GIN(对包含类查询) - 不能用于普通等值/范围查询(如
WHERE id = 100)
GiST 支持的数据类型与操作符:
| 数据类型 | 常见操作符 | 说明 |
|---|---|---|
几何类型 point, box, circle, polygon |
&&(相交), <@(在内), @>(包含), <->(距离) |
空间关系查询 |
范围类型 int4range, tsrange, daterange |
&&(重叠), @>(包含), <@(被包含) |
时间/数值区间查询 |
全文检索 tsvector |
@@(匹配) |
需配合 tsquery |
hstore(键值对) |
@>, ?, ?& |
键是否存在、包含等 |
inet/cidr |
>>, <<, && |
IP 地址包含、重叠 |
| 自定义类型 | --- | 通过扩展实现 |
示例 1:地理空间查询(找附近餐厅)
sql
-- 创建表(使用 PostGIS 扩展,底层基于 GiST)
CREATE EXTENSION postgis;
CREATE TABLE restaurants (
id SERIAL PRIMARY KEY,
name TEXT,
location GEOGRAPHY(POINT) -- 经纬度点
);
-- 插入数据
INSERT INTO restaurants (name, location)
VALUES
('A', ST_Point(-73.994454, 40.750042)), -- 纽约
('B', ST_Point(-0.127758, 51.507351)); -- 伦敦
-- 创建 GiST 索引(关键!)
CREATE INDEX idx_restaurants_location ON restaurants USING GIST (location);
-- 查询:找纽约 10 公里内的餐厅
SELECT name,
ST_Distance(location, ST_Point(-73.99, 40.75)) AS dist_meters
FROM restaurants
WHERE ST_DWithin(location, ST_Point(-73.99, 40.75), 10000); -- 10km示例 2:时间范围重叠(会议预约冲突检测)
sql
-- 会议表:每个会议有开始和结束时间
CREATE TABLE meetings (
id SERIAL PRIMARY KEY,
title TEXT,
during TSRANGE -- 时间范围类型
);
-- 插入数据
INSERT INTO meetings (title, during)
VALUES
('Team Sync', '[2025-06-01 09:00, 2025-06-01 10:00)'),
('Review', '[2025-06-01 09:30, 2025-06-01 11:00)');
-- 创建 GiST 索引(用于范围重叠查询)
CREATE INDEX idx_meetings_during ON meetings USING GIST (during);
-- 查询:是否有会议与 [09:15, 09:45) 冲突?
SELECT * FROM meetings
WHERE during && '[2025-06-01 09:15, 2025-06-01 09:45)'::tsrange;
-- 返回 "Team Sync" 和 "Review"示例 3:全文检索(替代 GIN 的轻量方案)
sql
-- 创建文章表
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT,
tsv TSVECTOR -- 全文向量
);
-- 生成 tsvector(可用触发器自动维护)
UPDATE articles SET tsv = to_tsvector('english', title || ' ' || content);
-- 创建 GiST 索引(比 GIN 小,写入更快,但查询稍慢)
CREATE INDEX idx_articles_tsv ON articles USING GIST (tsv);
-- 查询
SELECT title FROM articles
WHERE tsv @@ to_tsquery('english', 'database & postgres');示例 4:IP 地址包含查询
sql
CREATE TABLE networks (
id SERIAL PRIMARY KEY,
name TEXT,
net CIDR
);
INSERT INTO networks VALUES
(1, 'LAN', '192.168.0.0/16'),
(2, 'DMZ', '10.0.0.0/8');
-- GiST 索引加速 IP 包含查询
CREATE INDEX idx_networks_net ON networks USING GIST (net);
-- 查询:192.168.1.100 属于哪个网络?
SELECT name FROM networks
WHERE net >> '192.168.1.100'; -- >> 表示"包含"6.3.4 SP-GiST
SP-GiST(Space-Partitioned Generalized Search Tree,空间分区泛化搜索树) 是 PostgreSQL 中一种专为非平衡、分区型数据结构设计的索引方法。它是 GiST 的"表亲",但内部使用分区树(如四叉树、k-d 树、前缀树) 而非平衡树,特别适合处理具有自然聚类或层次结构的数据。
SP-GiST = 分区索引框架 + 支持非平衡树结构:
- 与
GiST不同,SP-GiST不要求树是平衡的,允许某些分支很深、某些很浅。 - 它将数据空间划分为互斥的子区域(partitioning),每个节点代表一个区域。
- 查询时,只需遍历可能包含目标的分区,跳过无关区域。
类比理解:
B-tree:像字典目录(严格排序)GiST:像图书馆主题分类(可重叠)SP-GiST:像电话区号树或IP 地址前缀树,1xx→13x→138→13800138000,路径不等长,但查找极快!
SP-GiST 的优缺点:
-
优点
- 索引体积小(比
B-tree/GiST更紧凑) - 写入性能极佳(适合高频插入)
- 天然支持前缀/分层数据
KNN搜索高效
- 索引体积小(比
-
缺点
- 不支持范围重叠查询(如
tsrange && tsrange) - 不支持全文检索、
JSONB、数组 - 社区使用较少,文档和案例不如
GiST/GIN丰富 - 对均匀分布数据优势不明显
- 不支持范围重叠查询(如
SP-GiST 支持的数据类型与操作符:
| 数据类型 | 操作符 | 说明 |
|---|---|---|
标量类型 text, varchar, char |
=, <, <=, >, >=, LIKE 'abc%' |
前缀搜索优化 |
网络类型 inet, cidr |
=, >>, <<, &&, ~ |
IP 地址前缀匹配(路由表) |
几何类型 point |
=, <->(KNN) |
2D/3D 点位置查询 |
范围类型 int4range 等 |
= |
精确范围匹配(不支持重叠 &&!) |
SP-GiST 不支持 tsvector(全文检索)或 jsonb。
示例 1:手机号前缀搜索(高效 LIKE '138%')
sql
-- 用户表
CREATE TABLE users (
id SERIAL PRIMARY KEY,
phone TEXT -- 存储为 '13800138000'
);
-- 插入 100 万条测试数据(略)
-- 创建 SP-GiST 索引(针对前缀)
CREATE INDEX idx_users_phone_spgist ON users USING SPGIST (phone);
-- 查询:所有 138 开头的用户
EXPLAIN ANALYZE
SELECT * FROM users WHERE phone LIKE '138%';
-- 执行计划结果:
Index Scan using idx_users_phone_spgist on users
Index Cond: (phone ~>=~ '138'::text)
Filter: (phone ~~ '138%'::text)示例 2:IP 路由表(最长前缀匹配)
sql
-- 网络路由表
CREATE TABLE routes (
cidr_block CIDR PRIMARY KEY,
gateway INET
);
INSERT INTO routes VALUES
('192.168.0.0/16', '10.0.0.1'),
('192.168.1.0/24', '10.0.0.2'),
('10.0.0.0/8', '10.0.0.3');
-- 创建 SP-GiST 索引(优化 IP 包含查询)
CREATE INDEX idx_routes_cidr ON routes USING SPGIST (cidr_block);
-- 查询:IP 192.168.1.100 属于哪个网段?(最长匹配)
SELECT * FROM routes
WHERE cidr_block >> '192.168.1.100' -- >> 表示"包含"
ORDER BY masklen(cidr_block) DESC -- 最长前缀优先
LIMIT 1;示例 3:2D 点最近邻搜索(KNN)
sql
-- 地点表(仅点,无 PostGIS)
CREATE TABLE locations (
name TEXT,
pos POINT -- PostgreSQL 内置 point 类型
);
INSERT INTO locations VALUES
('A', POINT(0, 0)),
('B', POINT(1, 1)),
('C', POINT(3, 4));
-- 创建 SP-GiST 索引
CREATE INDEX idx_locations_pos ON locations USING SPGIST (pos);
-- 找离 (0.5, 0.5) 最近的点
SELECT name, pos <-> POINT(0.5, 0.5) AS dist
FROM locations
ORDER BY pos <-> POINT(0.5, 0.5)
LIMIT 1;6.3.5 GIN
GIN 索引又叫倒排索引,GIN 索引写入开销大,适合读多写少场景。
适用场景:
- 数组包含:
WHERE tags @> ARRAY['postgres'] JSONB包含:WHERE data @> '{"role": "admin"}'- 全文检索:
WHERE to_tsvector('english', content) @@ to_tsquery('database')
创建语法:
sql
-- 数组索引
CREATE INDEX index_name ON table_name USING GIN (column_name);
-- JSONB 索引
CREATE INDEX index_name ON table_name USING GIN (column_name);
-- 全文检索索引
CREATE INDEX index_name ON table_name USING GIN (to_tsvector('english', content));JSONB 查询加速:
sql
-- 表
CREATE TABLE profiles (id INT, data JSONB);
INSERT INTO profiles VALUES (1, '{"name": "Alice", "skills": ["SQL", "Python"]}');
-- 创建 GIN 索引
CREATE INDEX idx_profiles_data ON profiles USING GIN (data);
-- 查询(走索引)
SELECT * FROM profiles WHERE data @> '{"skills": ["SQL"]}';6.3.6 BRIN
BRIN 索引适用于超大表,数据按照物理顺序插入(如时间、自增),并且查询条件与物理顺序相关的场景。
BRIN 索引的原理是每 N 个数据块(默认 128)记录一个 min / max 范围,查询时先看哪些块可能包含目标数据,跳过无关块。
创建语法:
sql
CREATE INDEX idx_name ON table_name USING BRIN (column_name);示例:优化日志表
sql
-- 10 亿行日志表,按时间顺序插入
SELECT * FROM logs WHERE created_at > '2025-01-01'; -- 全表扫描很慢
-- 创建 BRIN 索引后
CREATE INDEX idx_logs_time_brin ON logs USING BRIN (created_at);
-- 查询速度提升 100 倍+,索引大小仅为 B-tree 的 1%6.3.7 RUM
RUM 索引 是 PostgreSQL 中一种专为高级全文检索(Full-Text Search)设计的索引类型,它在 GIN 索引的基础上扩展了对位置信息和排序支持,特别适合需要 "按相关性排序" 的搜索场景(如 ORDER BY ts_rank(...))。
RUM 不是 PostgreSQL 内置索引,而是通过开源扩展 rum 提供(由 Postgres Professional 开发)。
GIN 的问题:
- 无法在索引中存储词频/位置信息,
ts_rank()必须在过滤后逐行计算 ORDER BY ts_rank(...)无法使用索引,需要Sort + Limit,大数据量时极慢- 不支持距离操作符(如
phrase <-> search)
RUM 索引在倒排列表中额外存储了每个词的出现位置(positions)和时间戳(可选),从而支持:
| 功能 | GIN | RUM |
|---|---|---|
基础匹配 @@ |
支持 | 支持 |
ts_rank() 计算 |
不支持(需回表) | 支持(索引内完成) |
ORDER BY ts_rank(...) LIMIT N |
不支持(全排序) | 支持(索引直接返回 Top-N) |
距离操作符 <-> |
不支持 | 支持(词间距离) |
| 时间感知搜索 | 不支持 | 支持(结合 timestamp) |
6.4 索引操作
6.4.2 创建索引
创建索引语法:
sql
# CREATE INDEX index_name ON table_name (column_name);6.4.2 查看索引
查看表的所有索引:
sql
-- psql 命令
\d users
-- SQL 查询
SELECT indexname, indexdef
FROM pg_indexes
WHERE tablename = [table_name];6.4.3 删除索引
删除索引语法:
sql
DROP INDEX index_name;6.5 索引优化
查看索引是否生效:
sql
EXPLAIN ANALYZE [query_sql];结果:
Index Scan using idx_users_email ...:走索引Seq Scan on users ...:全表扫描
七、PostgreSQL 事务
7.1 事务介绍
PostgreSQL 的事务(Transaction) 是保障数据一致性、可靠性和并发控制的核心机制。
事务的四大特性(ACID):
| 特性 | 说明 | PostgreSQL 实现 |
|---|---|---|
| A - Atomicity(原子性) | 事务是不可分割的最小单元,要么全做,要么全不做 | WAL + 回滚段(Undo via MVCC) |
| C - Consistency(一致性) | 事务使数据库从一个合法状态转移到另一个合法状态(如外键、唯一约束) | 约束检查在事务提交时验证 |
| I - Isolation(隔离性) | 并发事务互不干扰(看似串行执行) | MVCC(多版本并发控制) + 隔离级别 |
| D - Durability(持久性) | 一旦提交,数据永久保存(即使断电) | WAL(Write-Ahead Logging) |
事务控制语句:
| 语句 | 作用 | 说明 |
|---|---|---|
BEGIN 或 START TRANSACTION |
开始事务 | 显式开启一个事务块 |
COMMIT |
提交事务 | 永久保存所有更改 |
ROLLBACK |
回滚事务 | 撤销所有未提交的更改 |
SAVEPOINT name |
创建保存点 | 可部分回滚 |
ROLLBACK TO SAVEPOINT name |
回滚到保存点 | 保留保存点之后的操作可继续 |
RELEASE SAVEPOINT name |
删除保存点 | (可选) |
在 psql 或大多数客户端中,每条 SQL 自动包裹在 BEGIN; ... COMMIT; 中,默认自动提交,只有显式写 BEGIN 才进入"事务模式"。
示例1:转账(完整事务)
sql
-- 假设有 accounts 表:id, name, balance
BEGIN;
-- 扣款
UPDATE accounts SET balance = balance - 100 WHERE name = 'Alice';
-- 加款
UPDATE accounts SET balance = balance + 100 WHERE name = 'Bob';
-- 检查是否足够(可选业务逻辑)
-- 如果 Alice 余额 < 0,可主动 ROLLBACK
COMMIT; -- 两笔更新同时生效示例 2:回滚(模拟错误)
sql
BEGIN;
UPDATE products SET stock = stock - 1 WHERE id = 100;
-- 假设库存不足,程序检测到错误
ROLLBACK; -- 所有更改撤销,stock 不变示例 3:保存点(部分回滚)
sql
BEGIN;
INSERT INTO logs VALUES ('step1');
SAVEPOINT sp1;
INSERT INTO logs VALUES ('step2');
-- 出错了!但不想回滚 step1
ROLLBACK TO sp1;
INSERT INTO logs VALUES ('step3');
COMMIT;
-- 最终 logs 有:step1, step37.2 事务隔离级别
7.2.1 事务隔离级别介绍
事务隔离级别(Transaction Isolation Levels) 决定了并发事务之间如何相互影响,它直接关系到你的应用是否会出现"脏读"、"不可重复读"或"幻读"等问题。
PostgreSQL 支持 4 种 SQL 标准隔离级别
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(Non-Repeatable Read) | 幻读(Phantom Read) | PostgreSQL 是否支持 | 实际行为 |
|---|---|---|---|---|---|
| READ UNCOMMITTED | 可能 | 可能 | 可能 | 不支持 | 自动降级为 READ COMMITTED |
| READ COMMITTED | 不可能 | 可能 | 可能 | 默认 | 每条 SQL 看到已提交的最新快照 |
| REPEATABLE READ | 不可能 | 不可能 | 不可能(优于标准!) | 支持 | 整个事务看到同一快照 |
| SERIALIZABLE | 不可能 | 不可能 | 不可能 | 支持 | 严格串行化,冲突时报错 |
PostgreSQL 的 REPEATABLE READ 能防止幻读(大多数数据库做不到),这是其 MVCC 机制的强大之处!
设置隔离级别:
sql
-- 方法1:启动事务时指定
BEGIN ISOLATION LEVEL REPEATABLE READ;
-- 方法2:会话级设置(影响后续所有事务)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- 方法3:全局默认(postgresql.conf)
default_transaction_isolation = 'read committed'7.2.2 MVCC 机制
PostgreSQL 不用读锁,而是通过多版本并发控制(MVCC) 实现高并发,其核心思想是:
-
每行数据包含两个隐藏字段:
xmin:创建该行的事务 IDxmax:删除/更新该行的事务 ID(0 表示未删除)
-
每个事务开始时获取一个"快照(Snapshot)",记录:
- 当前活跃事务列表
- 下一个事务 ID
-
查询时,只返回 对当前快照可见的行版本
-
每行数据有
xmin(创建事务ID) 和xmax(删除/更新事务ID) -
每个事务看到的是 符合其快照(snapshot)的行版本
-
更新 = 插入新版本 + 标记旧版本
xmax
7.2.3 READ COMMITTED
PostgreSQL 默认的隔离级别,每条 SQL 语句执行时,获取一个新的快照,能看到在该语句开始前已提交的更改。
READ COMMITTED 适用于大多数 Web 应用,对一致性要求不极端严格的业务。
示例:不可重复读
sql
-- Session A
BEGIN; -- 默认 READ COMMITTED
SELECT balance FROM accounts WHERE id = 1; -- 返回 1000
-- 此时 Session B 执行:
-- BEGIN; UPDATE accounts SET balance = 2000 WHERE id=1; COMMIT;
SELECT balance FROM accounts WHERE id = 1; -- 返回 2000!(不可重复读)
COMMIT;7.2.4 REPEATABLE READ
整个事务使用同一个快照(事务开始时创建),事务内多次查询结果一致,能防止幻读(PostgreSQL 特有!)
示例:防止幻读
sql
-- Session A
BEGIN ISOLATION LEVEL REPEATABLE READ;
SELECT COUNT(*) FROM orders WHERE status = 'pending'; -- 返回 5
-- Session B 插入新订单:
-- INSERT INTO orders (status) VALUES ('pending');
SELECT COUNT(*) FROM orders WHERE status = 'pending'; -- 仍返回 5!(无幻读)
COMMIT;READ COMMITTED 隔离级别中,写偏斜(Write Skew)仍可能发生,示例:
sql
场景:两人同时从共享账户转账
- 初始余额:1000
- 每人最多转 600
Session A: SELECT balance → 1000; if <1200 then UPDATE -600
Session B: SELECT balance → 1000; if <1200 then UPDATE -600
结果:余额 = -200!(逻辑错误)适用场景:
- 报表生成(需一致快照)
- 金融对账
- 任何需要"事务内多次查询结果一致"的场景
7.2.5 SERIALIZABLE
最高的隔离级别,提供完全串行化的执行效果,如果检测到可能导致串行化异常的操作,直接报错 ERROR: could not serialize access due to concurrent update,应用必须捕获异常并重试事务。
示例:写偏斜被阻止
sql
-- Session A
BEGIN ISOLATION LEVEL SERIALIZABLE;
SELECT balance FROM accounts WHERE id = 1; -- 1000
-- (假设业务逻辑:若 <1200 则扣 600)
-- Session B 同时执行相同逻辑
-- 其中一个 COMMIT 会成功,另一个会报错:
-- ERROR: serialization failure适用场景:
- 银行核心交易系统
- 严格一致性要求的分布式事务模拟
- 无法容忍任何逻辑冲突的业务
缺点:
- 可能频繁报错,需重试逻辑
- 性能略低于
REPEATABLE READ
7.2.6 READ UNCOMMITTED
PostgreSQL 不支持此级别,即使 SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;,PostgreSQL 实际生效的是 READ COMMITTED。
7.3 并发问题与解决方案
| 问题 | 描述 | 解决方案 |
|---|---|---|
| 丢失更新 | 两个事务读同一值,各自修改后覆盖对方 | 用 SELECT FOR UPDATE 或应用层锁 |
| 写偏斜(Write Skew) | 两个事务基于过期读做决策 | 升级到 SERIALIZABLE 隔离级别 |
| 死锁(Deadlock) | 事务互相等待对方释放锁 | PostgreSQL 自动检测并终止一个事务 |
防止丢失更新:SELECT FOR UPDATE
sql
BEGIN;
-- 锁住这行,其他事务不能读(FOR UPDATE)或改
SELECT balance FROM accounts WHERE id = 1 FOR UPDATE;
-- 基于当前值计算
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
COMMIT;7.4 高级特性
两阶段提交(2PC) ------ 分布式事务
sql
PREPARE TRANSACTION 'txn1'; -- 第一阶段:准备
COMMIT PREPARED 'txn1'; -- 第二阶段:提交
-- 或 ROLLBACK PREPARED 'txn1';事务 ID 回卷(Wraparound)防护:
- PostgreSQL 事务
ID是 32 位,约 20 亿后回卷 - 必须定期
VACUUM,否则数据库会只读保护!
只读事务(Read-Only Transaction):
sql
BEGIN READ ONLY;
SELECT ...; -- 不能 UPDATE/DELETE
COMMIT;适用于报表、分析查询,提升并发性。
7.5 监控事务
查看活跃事务:
sql
SELECT pid, usename, xact_start, query
FROM pg_stat_activity
WHERE state = 'active' AND xact_start IS NOT NULL;查看长事务:
sql
SELECT pid, now() - xact_start AS duration, query
FROM pg_stat_activity
WHERE xact_start < now() - INTERVAL '5 minutes';八、PostgreSQL 锁
8.1 PostgreSQL 锁介绍
PostgreSQL 的锁(Locking)机制是保障数据一致性和并发控制的核心组件。与许多数据库不同,PostgreSQL 极少使用表级写锁,而是通过 MVCC(多版本并发控制) + 精细锁 实现高并发。
PostgreSQL 支持 6 种锁粒度,从粗到细:
| 锁级别 | 说明 | 典型场景 |
|---|---|---|
| Database Lock | 锁整个数据库 | DROP DATABASE |
| Tablespace Lock | 锁表空间 | DROP TABLESPACE |
| Relation (Table) Lock | 最常见表级锁 | ALTER TABLE, VACUUM FULL |
| Page Lock | 锁数据页(8KB) | 内部使用,用户不可见 |
| Tuple (Row) Lock | 行级锁 | SELECT FOR UPDATE |
| Transaction ID Lock | 锁事务ID | 内部用于 2PC |
表级锁:
PostgreSQL 有 8 种表级锁模式,按强度递增:
| 锁模式 | 获取方式 | 允许并发读? | 允许并发写? | 典型命令 |
|---|---|---|---|---|
| ACCESS SHARE | SELECT |
✅ | ✅ | 普通查询 |
| ROW SHARE | SELECT FOR SHARE/UPDATE |
✅ | ✅ | 行锁前先加此锁 |
| ROW EXCLUSIVE | INSERT/UPDATE/DELETE |
✅ | ✅ | DML 操作 |
| SHARE UPDATE EXCLUSIVE | VACUUM (non-full), ANALYZE |
✅ | ❌ | 阻止结构变更 |
| SHARE | CREATE INDEX |
✅ | ❌ | 建索引(非并发) |
| SHARE ROW EXCLUSIVE | --- | ✅ | ❌ | 几乎不用 |
| EXCLUSIVE | --- | ❌ | ❌ | 极少用 |
| ACCESS EXCLUSIVE | ALTER TABLE, DROP TABLE, VACUUM FULL |
❌ | ❌ | 阻塞所有操作! |
行级锁:
行锁通过 SELECT ... FOR UPDATE/SHARE 显式获取,或由 UPDATE/DELETE 自动加锁。
4 种行锁模式:
| 锁模式 | SQL 语法 | 作用 | 兼容性 |
|---|---|---|---|
| FOR UPDATE | SELECT ... FOR UPDATE |
获取排他锁,阻止其他 UPDATE/DELETE/FOR UPDATE |
仅与 FOR KEY SHARE 兼容 |
| FOR NO KEY UPDATE | SELECT ... FOR NO KEY UPDATE |
更新非主键列时使用(9.6+) | 比 FOR UPDATE 稍宽松 |
| FOR SHARE | SELECT ... FOR SHARE |
共享锁,阻止 UPDATE/DELETE,但允许多个 FOR SHARE |
与 FOR SHARE / FOR KEY SHARE 兼容 |
| FOR KEY SHARE | SELECT ... FOR KEY SHARE |
最弱行锁,仅阻止删除或更新主键 | 与所有行锁兼容 |
8.2 锁冲突与死锁
PostgreSQL 自动检测死锁(默认 deadlock_timeout = 1s),检测到死锁时自动终止其中一个事务,报错:
sql
ERROR: deadlock detected
DETAIL: Process 12345 waits for ShareLock on transaction 67890;
blocked by process 54321.
HINT: See server log for query details.九、PostgreSQL 权限
9.1 PostgreSQL 权限介绍
PostgreSQL 的权限系统(Privileges System)是保障数据安全的核心机制,它基于角色(Roles)模型,支持精细的访问控制,从数据库连接、表操作,到列、行甚至特定函数的调用。
角色(Roles)代替用户/组:PostgreSQL 没有"用户"和"组"的区分,统一使用 ROLE。
- 登录角色(Login Role) = 传统"用户"
- 非登录角色(Non-Login Role) = 传统"用户组"或"权限集合"
创建角色:
sql
-- 创建可登录用户(带密码)
CREATE ROLE alice WITH LOGIN PASSWORD 'secure123';
-- 创建权限组(不可登录)
CREATE ROLE analysts;
-- 将用户加入组
GRANT analysts TO alice;9.2 权限层级与对象类型
PostgreSQL 权限作用于数据库对象,层级如下:
sql
Cluster(实例)
└── Database
├── Schema
│ ├── Table / View / Sequence
│ ├── Column(列级)
│ └── Function / Procedure
└── Language / Tablespace支持权限的对象类型:
| 对象类型 | 可授予权限 |
|---|---|
| DATABASE | CONNECT, CREATE, TEMPORARY |
| SCHEMA | USAGE, CREATE |
| TABLE / VIEW | SELECT, INSERT, UPDATE, DELETE, TRUNCATE, REFERENCES, TRIGGER |
| COLUMN | SELECT, INSERT, UPDATE(列级) |
| SEQUENCE | USAGE, SELECT, UPDATE |
| FUNCTION | EXECUTE |
9.3 权限操作
PostgreSQL 中,权限操作使用 GRANT / REVOKE 命令,语法如下:
sql
-- 授予权限
GRANT privilege [, ...] ON object_type object_name TO role_name;
-- 撤销权限
REVOKE privilege [, ...] ON object_type object_name FROM role_name;示例 1:基础表权限
sql
-- 创建表(属于当前用户,如 postgres)
CREATE TABLE sales (
id SERIAL,
amount NUMERIC,
region TEXT,
created_by TEXT
);
-- 创建只读角色
CREATE ROLE reader;
GRANT CONNECT ON DATABASE mydb TO reader;
GRANT USAGE ON SCHEMA public TO reader;
GRANT SELECT ON TABLE sales TO reader;
-- 创建分析员角色(可读写)
CREATE ROLE analyst;
GRANT SELECT, INSERT, UPDATE ON sales TO analyst;示例 2:列级权限(敏感字段保护)
sql
-- 防止 analyst 修改 created_by 字段
REVOKE UPDATE(created_by) ON sales FROM analyst;
-- 或只允许更新特定列
GRANT UPDATE(amount, region) ON sales TO analyst;避免每次建新表都要手动授权,可用 默认权限 ALTER DEFAULT PRIVILEGES。
示例:自动授权给新表
sql
-- 设置:未来所有由 postgres 创建的表,自动给 analyst 读写权
ALTER DEFAULT PRIVILEGES
FOR ROLE postgres -- 谁创建的对象
IN SCHEMA public -- 在哪个 schema
GRANT SELECT, INSERT, UPDATE ON TABLES TO analyst;
-- 同样适用于序列、函数等
ALTER DEFAULT PRIVILEGES IN SCHEMA public
GRANT USAGE ON SEQUENCES TO analyst;所有权(Ownership)与超级用户:
- 对象创建者 = 所有者(Owner)
- 所有者自动拥有
ALL权限,且不能被REVOKE - 只有所有者或超级用户能
DROP/ALTER对象 - 超级用户(SUPERUSER)绕过所有权限检查
查看对象所有者:
sql
SELECT tablename, tableowner
FROM pg_tables
WHERE schemaname = 'public';十、PostgreSQL 操作符与函数
10.1 日期/时间操作符
| 操作符 | 例子 | 结果 |
|---|---|---|
+ |
date '2001-09-28' + integer '7' |
date '2001-10-05' |
+ |
date '2001-09-28' + interval '1 hour' |
timestamp '2001-09-28 01:00:00' |
+ |
date '2001-09-28' + time '03:00' |
timestamp '2001-09-28 03:00:00' |
+ |
interval '1 day' + interval '1 hour' |
interval '1 day 01:00:00' |
+ |
timestamp '2001-09-28 01:00' + interval '23 hours' |
timestamp '2001-09-29 00:00:00' |
+ |
time '01:00' + interval '3 hours' |
time '04:00:00' |
- |
- interval '23 hours' |
interval '-23:00:00' |
- |
date '2001-10-01' - date '2001-09-28' |
integer '3' (days) |
- |
date '2001-10-01' - integer '7' |
date '2001-09-24' |
- |
date '2001-09-28' - interval '1 hour' |
timestamp '2001-09-27 23:00:00' |
- |
time '05:00' - time '03:00' |
interval '02:00:00' |
- |
time '05:00' - interval '2 hours' |
time '03:00:00' |
- |
timestamp '2001-09-28 23:00' - interval '23 hours' |
timestamp '2001-09-28 00:00:00' |
- |
interval '1 day' - interval '1 hour' |
interval '1 day -01:00:00' |
- |
timestamp '2001-09-29 03:00' - timestamp '2001-09-27 12:00' |
interval '1 day 15:00:00' |
* |
900 * interval '1 second' |
interval '00:15:00' |
* |
21 * interval '1 day' |
interval '21 days' |
* |
double precision '3.5' * interval '1 hour' |
interval '03:30:00' |
/ |
interval '1 hour' / double precision '1.5' |
interval '00:40:00' |
10.2 日期/时间函数
| 函数 | 返回类型 | 描述 | 示例 | 结果 |
|---|---|---|---|---|
age(timestamp, timestamp) |
interval |
减去参数后的"符号化"结果,使用年和月,不只是使用天 | age(timestamp '2001-04-10', timestamp '1957-06-13') |
43 years 9 mons 27 days |
age(timestamp) |
interval |
从 current_date 减去参数后的结果(在午夜) |
age(timestamp '1957-06-13') |
43 years 8 mons 3 days |
clock_timestamp() |
timestamp with time zone |
实时时钟的当前时间戳(在语句执行时变化) | --- | --- |
current_date |
date |
当前的日期 | --- | --- |
current_time |
time with time zone |
当日时间 | --- | --- |
current_timestamp |
timestamp with time zone |
当前事务开始时的时间戳 | --- | --- |
date_part(text, timestamp) |
double precision |
获取子域(等效于 extract) |
date_part('hour', timestamp '2001-02-16 20:38:40') |
20 |
date_part(text, interval) |
double precision |
获取子域(等效于 extract) |
date_part('month', interval '2 years 3 months') |
3 |
date_trunc(text, timestamp) |
timestamp |
截断成指定的精度 | date_trunc('hour', timestamp '2001-02-16 20:38:40') |
2001-02-16 20:00:00 |
date_trunc(text, interval) |
interval |
截取指定的精度 | date_trunc('hour', interval '2 days 3 hours 40 minutes') |
2 days 03:00:00 |
extract(field from timestamp) |
double precision |
获取子域 | extract(hour from timestamp '2001-02-16 20:38:40') |
20 |
extract(field from interval) |
double precision |
获取子域 | extract(month from interval '2 years 3 months') |
3 |
isfinite(date) |
boolean |
测试是否为有穷日期(不是 ±∞) | isfinite(date '2001-02-16') |
true |
isfinite(timestamp) |
boolean |
测试是否为有穷时间戳(不是 ±∞) | isfinite(timestamp '2001-02-16 21:28:30') |
true |
isfinite(interval) |
boolean |
测试是否为有穷时间间隔 | isfinite(interval '4 hours') |
true |
justify_days(interval) |
interval |
按照每月 30 天调整时间间隔 | justify_days(interval '35 days') |
1 mon 5 days |
justify_hours(interval) |
interval |
按照每天 24 小时调整时间间隔 | justify_hours(interval '27 hours') |
1 day 03:00:00 |
justify_interval(interval) |
interval |
使用 justify_days 和 justify_hours 调整时间间隔的同时进行正负号调整 |
justify_interval(interval '1 mon -1 hour') |
29 days 23:00:00 |
localtime |
time |
当日时间 | --- | --- |
localtimestamp |
timestamp |
当前事务开始时的时间戳 | --- | --- |
make_date(year int, month int, day int) |
date |
为年、月和日字段创建日期 | make_date(2013, 7, 15) |
2013-07-15 |
make_interval(years int DEFAULT 0, months int DEFAULT 0, weeks int DEFAULT 0, days int DEFAULT 0, hours int DEFAULT 0, mins int DEFAULT 0, secs double precision DEFAULT 0.0) |
interval |
从年、月、周、天、小时、分钟和秒字段中创建间隔 | make_interval(days := 10) |
10 days |
make_time(hour int, min int, sec double precision) |
time |
从小时、分钟和秒字段中创建时间 | make_time(8, 15, 23.5) |
08:15:23.5 |
make_timestamp(year int, month int, day int, hour int, min int, sec double precision) |
timestamp |
从年、月、日、小时、分钟和秒字段中创建时间戳 | make_timestamp(2013, 7, 15, 8, 15, 23.5) |
2013-07-15 08:15:23.5 |
make_timestamptz(year int, month int, day int, hour int, min int, sec double precision, [ timezone text ]) |
timestamp with time zone |
从年、月、日、小时、分钟和秒字段中创建带有时区的时间戳。未指定 timezone 时,使用当前时区。 |
make_timestamptz(2013, 7, 15, 8, 15, 23.5) |
2013-07-15 08:15:23.5+01 |
now() |
timestamp with time zone |
当前事务开始时的时间戳 | --- | --- |
statement_timestamp() |
timestamp with time zone |
实时时钟的当前时间戳(语句开始执行时) | --- | --- |
timeofday() |
text |
与 clock_timestamp 相同,但结果是 text 字符串 |
--- | --- |
transaction_timestamp() |
timestamp with time zone |
当前事务开始时的时间戳(等价于 now()) |
--- | --- |
聚合函数
| 函数 | 说明 | 示例 | 备注 |
|---|---|---|---|
COUNT(*) |
统计行数(含 NULL) | SELECT COUNT(*) FROM users; |
最常用 |
COUNT(column) |
统计非 NULL 值数量 | SELECT COUNT(email) FROM users; |
忽略 NULL |
MAX(column) |
返回列中最大值 | SELECT MAX(salary) FROM employees; |
支持数字、日期、字符串 |
MIN(column) |
返回列中最小值 | SELECT MIN(created_at) FROM logs; |
同上 |
AVG(column) |
计算列的平均值 | SELECT AVG(score) FROM exams; |
仅数字类型 |
SUM(column) |
计算列的总和 | SELECT SUM(amount) FROM orders; |
仅数字类型 |
10.3 数学函数
| 函数 | 返回类型 | 描述 | 示例 |
|---|---|---|---|
abs(x) |
绝对值 | abs(-17.4) = 17.4 | |
cbrt(double) |
立方根 | cbrt(27.0) = 3 | |
ceil(double/numeric) |
不小于参数的最小的整数 | ceil(-42.8) = -42 | |
degrees(double) |
把弧度转为角度 | degrees(0.5) = 28.6478897565412 | |
exp(double/numeric) |
自然指数 | exp(1.0) = 2.71828182845905 | |
floor(double/numeric) |
不大于参数的最大整数 | floor(-42.8) = -43 | |
ln(double/numeric) |
自然对数 | ln(2.0) = 0.693147180559945 | |
log(double/numeric) |
10为底的对数 | log(100.0) = 2 | |
log(b numeric,x numeric) |
numeric |
指定底数的对数 | log(2.0, 64.0) = 6.0000000000 |
mod(y, x) |
取余数 | mod(9,4) = 1 | |
pi() |
double |
"π"常量 | pi() = 3.14159265358979 |
power(a double, b double) |
double |
求a的b次幂 | power(9.0, 3.0) = 729 |
power(a numeric, b numeric) |
numeric |
求a的b次幂 | power(9.0, 3.0) = 729 |
radians(double) |
double |
把角度转为弧度 | radians(45.0) =0.785398163397448 |
random() |
double |
0.0到1.0之间的随机数值 | random() |
round(double/numeric) |
圆整为最接近的整数 | round(42.4) = 42 | |
round(v numeric, s int) |
numeric |
圆整为s位小数数字 | round(42.438,2) = 42.44 |
sign(double/numeric) |
参数的符号(-1,0,+1) | sign(-8.4) = -1 | |
sqrt(double/numeric) |
平方根 | sqrt(2.0) = 1.4142135623731 | |
trunc(double/numeric) |
截断(向零靠近) | trunc(42.8) = 42 | |
trunc(v numeric, s int) |
numeric |
截断为s小数位置的数字 | trunc(42.438,2) = 42.43 |
10.4 三角函数
| 函数 | 说明 | 输入 | 输出 | 示例 |
|---|---|---|---|---|
sin(x) |
正弦 | 弧度 | 浮点数 | sin(radians(30)) → 0.5 |
cos(x) |
余弦 | 弧度 | 浮点数 | cos(radians(60)) → 0.5 |
cot(x) |
余切(需自定义) | 弧度 | 浮点数 | 1 / tan(radians(45)) → 1.0 |
tan(x) |
正切 | 弧度 | 浮点数 | tan(radians(45)) → 1.0 |
asin(x) |
反正弦 (arcsin) | -1, 1 | 弧度 | degrees(asin(0.5)) → 30 |
acos(x) |
反余弦 (arccos) | -1, 1 | 弧度 | degrees(acos(0)) → 90 |
atan(x) |
反正切 (arctan) | 任意实数 | 弧度 | degrees(atan(1)) → 45 |
atan2(y, x) |
四象限反正切 | 任意实数 | 弧度(-π 到 π) | degrees(atan2(1, -1)) → 135 |
弧度与角度的转换函数:
radians(角度):角度 → 弧度degrees(弧度):弧度 → 角度
10.5 字符串函数和操作符
| 函数 | 返回类型 | 描述 | 示例 | 结果 |
|---|---|---|---|---|
| `string | string` | text |
字符串连接 | |
bit_length(string) |
int |
字符串中二进制位的个数 | bit_length('jose') |
32 |
char_length(string) |
int |
字符串中的字符个数 | char_length('jose') |
4 |
convert(string using conversion_name) |
text |
使用指定的转换名改变编码 | convert('PostgreSQL' using iso_8859_1_to_utf8) |
'PostgreSQL' |
lower(string) |
text |
将字符串转为小写 | lower('TOM') |
tom |
octet_length(string) |
int |
字符串中的字节数 | octet_length('jose') |
4 |
overlay(string placing string from int [for int]) |
text |
替换子字符串 | overlay('Txxxxas' placing 'hom' from 2 for 4) |
Thomas |
position(substring in string) |
int |
指定子字符串的位置(从1开始) | position('om' in 'Thomas') |
3 |
substring(string [from int] [for int]) |
text |
抽取子字符串(按位置) | substring('Thomas' from 2 for 3) |
hom |
substring(string from pattern) |
text |
抽取匹配 POSIX 正则表达式的子串 | substring('Thomas' from '...$') |
mas |
substring(string from pattern for escape) |
text |
抽取匹配 SQL 正则表达式的子串 | substring('Thomas' from '%#"o_a#"_' for '#') |
oma |
| `trim([leading | trailing | both] [characters] from string)` | text |
从字符串开头/结尾/两边删除指定字符(默认空白) |
upper(string) |
text |
将字符串转为大写 | upper('tom') |
TOM |
ascii(text) |
int |
返回参数第一个字符的 ASCII 码 | ascii('x') |
120 |
btrim(string [, characters]) |
text |
从字符串两端删除指定字符(默认空白) | btrim('xyxtrimyyx', 'xy') |
trim |
chr(int) |
text |
返回对应 ASCII 码的字符 | chr(65) |
A |
convert(string, [src_encoding,] dest_encoding) |
text |
将字符串从一种编码转换为另一种 | convert('text_in_utf8', 'UTF8', 'LATIN1') |
以 ISO 8859-1 编码表示的 text_in_utf8 |
initcap(text) |
text |
将每个单词首字母大写,其余小写 | initcap('hi thomas') |
Hi Thomas |
length(string) |
int |
字符串中字符的数目(同 char_length) |
length('jose') |
4 |
lpad(string, length [, fill]) |
text |
在左侧用 fill 填充至指定长度 |
lpad('hi', 5, 'xy') |
xyxhi |
ltrim(string [, characters]) |
text |
从字符串开头删除指定字符 | ltrim('zzzytrim','xyz') |
trim |
md5(string) |
text |
计算字符串的 MD5 散列(十六进制) | md5('abc') |
900150983cd24fb0d6963f7d28e17f72 |
repeat(string, number) |
text |
重复字符串指定次数 | repeat('Pg', 4) |
PgPgPgPg |
replace(string, from, to) |
text |
将字符串中所有 from 子串替换为 to |
replace('abcdefabcdef', 'cd', 'XX') |
abXXefabXXef |
rpad(string, length [, fill]) |
text |
在右侧用 fill 填充至指定长度 |
rpad('hi', 5, 'xy') |
hixyx |
rtrim(string [, characters]) |
text |
从字符串结尾删除指定字符 | rtrim('trimxxxx','x') |
trim |
split_part(string, delimiter, field) |
text |
按分隔符拆分,返回第 field 个字段(从1开始) |
split_part('abc~@~def~@~ghi', '~@~', 2) |
def |
strpos(string, substring) |
int |
子字符串位置(等价于 position) |
strpos('high','ig') |
2 |
substr(string, from [, count]) |
text |
抽取子字符串(等价于 substring) |
substr('alphabet', 3, 2) |
ph |
to_ascii(text [, encoding]) |
text |
将文本从其他编码转换为 ASCII(去除重音等) | to_ascii('Karel') |
Karel |
to_hex(number) |
text |
将整数转为十六进制字符串 | to_hex(9223372036854775807) |
7fffffffffffffff |
translate(string, from, to) |
text |
将 string 中 from 的每个字符替换为 to 中对应字符 |
translate('12345', '14', 'ax') |
a23x5 |
length()与char_length()功能相同。strpos()是position()的别名,但参数顺序更符合直觉(strpos(str, substr))。substr()是substring()的别名。md5()返回 32 位小写十六进制字符串。convert()和to_ascii()用于多语言或编码迁移场景,需确保数据库支持相应编码。
10.6 类型转换相关函数
| 函数 | 返回类型 | 描述 | 示例 |
|---|---|---|---|
to_char(timestamp, text) |
text |
将时间戳转换为格式化字符串 | to_char(current_timestamp, 'HH12:MI:SS') |
to_char(interval, text) |
text |
将时间间隔转换为格式化字符串 | to_char(interval '15h 2m 12s', 'HH24:MI:SS') |
to_char(int, text) |
text |
将整型数字转换为格式化字符串 | to_char(125, '999') |
to_char(double precision, text) |
text |
将双精度浮点数转换为格式化字符串 | to_char(125.8::real, '999D9') |
to_char(numeric, text) |
text |
将 numeric 类型数字转换为格式化字符串 | to_char(-125.8, '999D99S') |
to_date(text, text) |
date |
将符合格式的字符串解析为日期 | to_date('05 Dec 2000', 'DD Mon YYYY') |
to_number(text, text) |
numeric |
将格式化字符串解析为数字 | to_number('12,454.8-', '99G999D9S') |
to_timestamp(text, text) |
timestamp |
将符合格式的字符串解析为时间戳(不带时区) | to_timestamp('05 Dec 2000', 'DD Mon YYYY') |
to_timestamp(double precision) |
timestamp with time zone |
将 UNIX 时间戳(秒)转换为带时区的时间戳 | to_timestamp(1284352323) |
to_char(..., format)和to_timestamp/to_date/to_number(text, format)是互逆操作。- 使用
to_timestamp(unix_time)时,输入单位为秒(可含小数) ,返回timestamptz。 - 格式模板区分大小写,且必须与输入字符串严格匹配,否则会报错。
10.7 常用格式化符号
| 符号 | 含义 | 示例 |
|---|---|---|
YYYY |
四位年份 | 2025 |
MM / Mon / Month |
月份数字 / 缩写 / 全名 | 12 / Dec / December |
DD |
日 | 05 |
HH24 / HH12 |
24小时制 / 12小时制 | 14 / 02 |
MI |
分钟 | 30 |
SS |
秒 | 45 |
D |
小数点(本地化) | 125.8 → '999D9' → '125.8' |
G |
千位分隔符(本地化) | '12,454' |
S |
符号(正/负) | -125.8 → '999D99S' → '125.80-' |
FM |
填充模式(去除前导/尾随空格) | to_char(5, 'FM00') → '05' |
相关资源:
- 官网:https://www.postgresql.org/
- 文档:https://www.postgresql.org/docs/
- 中文社区:https://www.postgres.cn/
- 书籍推荐:《PostgreSQL 实战》《The Art of PostgreSQL》