文章目录
项目介绍
项目背景
随着美团业务的不断扩展,客服人员需要应对海量的用户咨询,包括订单问题、退款流程、配送异常、优惠政策等。传统的知识库客服系统依赖规则匹配,回答僵硬,难以及时覆盖最新的业务规则。
为提升客户体验和客服效率,本项目基于 RAG(Retrieval-Augmented Generation,检索增强生成) 技术构建智能客服问答系统,将美团内部文档知识与大语言模型结合,实现更智能、更准确的自动化答复。
项目功能
针对智能客服系统本身,我们将采用RAG + LLM来完成这一需求。结合前面所学的知识,这个智能客服系统应该具备以下功能:
- 支持历史记忆功能,并且能够实现历史记忆持久化。
- 使用LCEL 表达式来构建链。
- 支持RAG 检索功能,使大语言模型能够根据知识库文档内容进行作答。
- 编写完善的提示词模板,内容包括历史对话信息、RAG 检索的上下文信息、用户提问,以及AI 作为客服的系统提示词。
系统架构
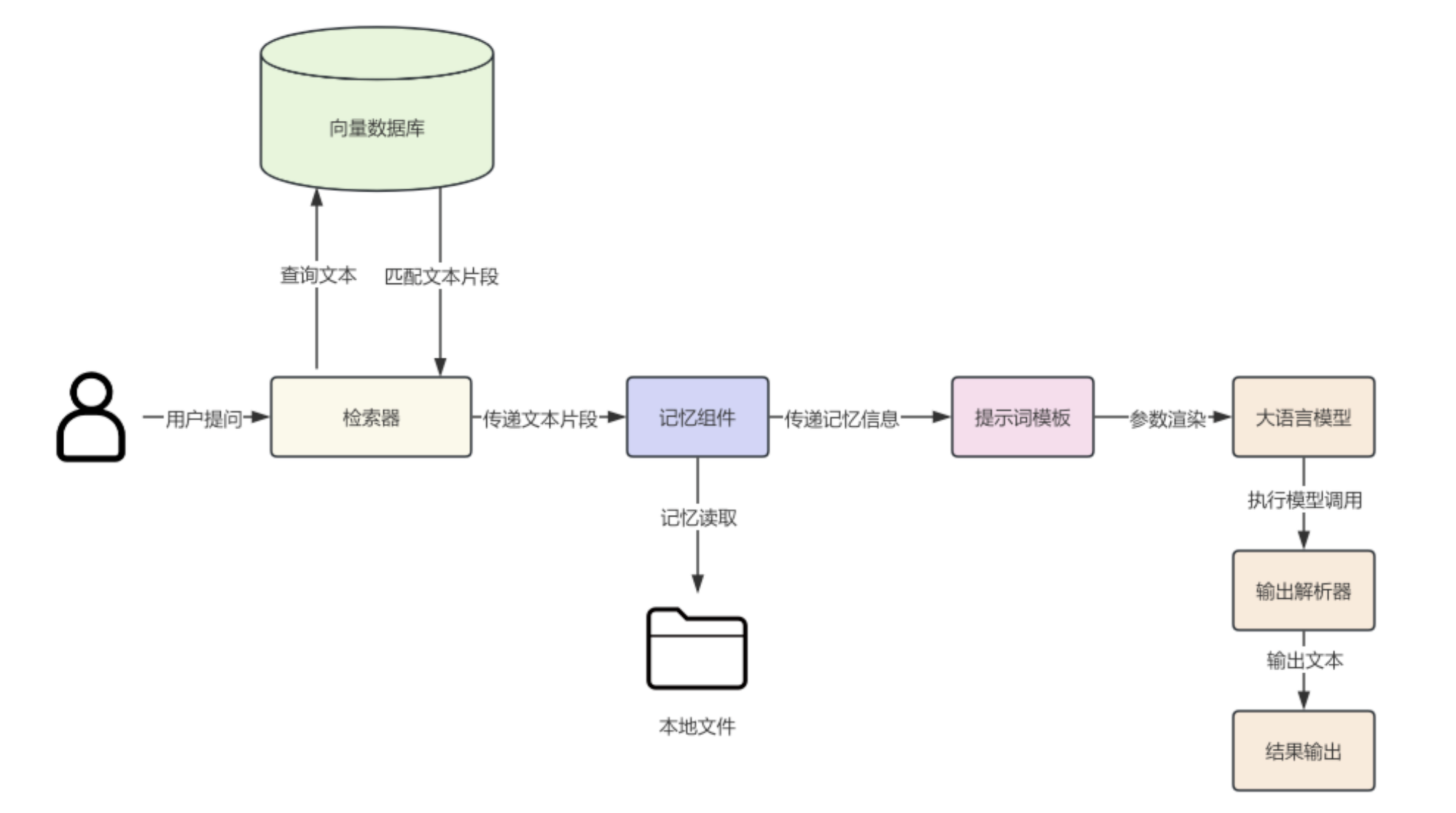
RAG 准备阶段
在 RAG 准备阶段,我们需要进行文档收集、文档处理、文档数据向量化操作以及文档相似性检索测试。
文档收集
收集美团客服相关知识文档,例如:
- 业务手册(退款规则、订单处理流程)
- 常见问题 FAQ
- 内部客服知识库
- 实时更新的运营公告
以美团外卖常见问题为例,文档地址:https://waimai.meituan.com/help/faq,我们通过playwright 工具爬虫获取页面数据并写入本地 txt 文件中。
安装依赖包
python
# 安装浏览器插件库
pip install playwright chromium
playwright install
# 安装浏览器中文依赖
sudo apt update && sudo apt install fonts-wqy-zenhei fonts-wqy-microhei -y代码如下:
python
from playwright.sync_api import sync_playwright
def collect_faq(url):
"""
收集指定URL页面中的FAQ内容
参数:
url (str): 目标网页URL地址
返回:
str: 提取的FAQ内容html代码
"""
# 启动Playwright浏览器自动化工具
with sync_playwright() as p:
# 启动Chromium浏览器,设置为非无头模式并指定中文语言
browser = p.chromium.launch(
headless=False,
args=['--lang=zh-CN'] # 浏览器语言
)
# 创建新页面,配置中文环境
page = browser.new_page(
locale='zh-CN', # 页面 locale
user_agent=(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0"
),
extra_http_headers={
"Accept-Language": "zh-CN,zh;q=0.9"
}
)
# 访问目标URL并等待页面加载完成
page.goto(url, timeout=30_000)
page.wait_for_load_state("networkidle")
# 提取FAQ列表区域的html代码
raw_text = page.locator("#faq-list").first.inner_html()
browser.close()
return raw_text
def save_faq(cleaned_text: str, output_file: str):
"""
将FAQ内容保存到指定文件
参数:
cleaned_text (str): 要保存的FAQ内容
output_file (str): 输出文件路径
"""
# 写入文件
with open(output_file, "w", encoding="utf-8") as f:
f.write(cleaned_text)
print(f"FAQ 已保存到 {output_file}")
if __name__ == "__main__":
cleaned_text = collect_faq(url="https://waimai.meituan.com/help/faq")
output_file = "faq.html"
save_faq(cleaned_text, output_file)获取到的原始文件内容如下:
python
# cat faq.html
<ul>
<li class="faq-head head1">
<h1>在线支付问题</h1>
<span></span>
</li>
<li>
<dl>
<dt><a href="javascript:;" class="questions">Q:在线支付取消订单后钱怎么返还?<i class="icon i-triangledown fr"></i></a></dt>
<dd class="answers hidden ">
订单取消后,款项会在一个工作日内,直接返还到您的美团账户余额。
</dd>
</dl>
</li>
......文档处理
我们已经爬取了 FAQ 文档,接下来就需要对收集到的文档进行统一处理,内容包括:
- 文本清洗(去除 HTML 标签、无关字符)
- 分段切分(按规则或语义将文档拆分成小片段,便于检索)
- 元数据标注(来源、时间、业务类别等)。
代码如下:
python
import json
from bs4 import BeautifulSoup
from langchain.schema import Document
def parse_faq_html(file_path):
"""
解析FAQ HTML文件,提取问题和答案信息并封装为Document对象列表。
参数:
file_path (str): FAQ HTML文件的路径。
返回:
list: 包含Document对象的列表,每个对象的metadata包含分类、问题、答案和来源信息。
"""
docs = []
with open(file_path, "r", encoding="utf-8") as f:
soup = BeautifulSoup(f, "html.parser")
current_category = None
# 遍历所有<ul>标签,解析其中的<li>元素
for ul in soup.find_all("ul"):
for li in ul.find_all("li", recursive=False):
h1 = li.find("h1")
if h1: # 分类标题
current_category = h1.get_text(strip=True)
continue
dl = li.find("dl")
if dl:
# 去掉 Q:
question_raw = dl.find("dt").get_text(strip=True)
question = question_raw.lstrip("Q:").strip()
answer = dl.find("dd").get_text(strip=True)
docs.append(
Document(
page_content="",
metadata={
"source": file_path,
"category": current_category,
"question": question,
"answer": answer
}
)
)
return docs
def save_docs_to_json(docs, output_file):
"""
将Document对象列表保存为JSON格式文件。
参数:
docs (list): 包含Document对象的列表。
output_file (str): 输出JSON文件的路径。
返回:
None
"""
data = [
{
"question": doc.metadata["question"],
"answer": doc.metadata["answer"],
"category": doc.metadata["category"],
"source": doc.metadata["source"]
}
for doc in docs
]
with open(output_file, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print(f"FAQ 已保存到 {output_file}")
if __name__ == "__main__":
faq_docs = parse_faq_html("faq.html")
for d in faq_docs:
print(d.metadata)
save_docs_to_json(faq_docs, "faq.json")执行后的结果如下:
python
# cat faq.json
[
{
"question": "在线支付取消订单后钱怎么返还?",
"answer": "订单取消后,款项会在一个工作日内,直接返还到您的美团账户余额。",
"category": "在线支付问题",
"source": "faq.html"
},
......文档数据向量化
我们将 FAQ 数据格式化成 json 数据后,接下来就要转成向量数据并存储到向量数据库中,此处以 redis 为例,操作内容包括:
使用 向量化模型(Embedding Model,如 BGE、OpenAI Embedding) 将文档片段转换为向量表示。
存储至向量数据库(如 Milvus、Weaviate、Redis Vector、Faiss),支持高效的相似度搜索。
代码如下
python
import json
from langchain_ollama import OllamaEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
def insert_faq(texts, meta_data):
"""
将FAQ文本数据插入到Redis向量存储中
Args:
texts (list): 包含问题文本的列表
meta_data (list): 包含每个问题对应元数据的列表,每个元素为字典格式
Returns:
None
"""
# 配置Redis连接参数和索引名称
config = RedisConfig(
index_name="faq",
redis_url="redis://localhost:6379",
)
# 初始化 Embedding 模型
embedding = OllamaEmbeddings(model="deepseek-r1:14b")
# 创建Redis向量存储实例
vector_store = RedisVectorStore(embedding, config=config)
vector_store.add_texts(texts=texts, metadatas=meta_data)
def insert_from_file(file_path):
"""
从JSON文件中读取FAQ数据并插入到向量存储中
Args:
file_path (str): 包含FAQ数据的JSON文件路径
Returns:
None
"""
with open(file_path, "r", encoding="utf-8") as f:
docs = json.load(f)
texts = []
meta_data = []
# 解析文档数据,提取问题文本和元数据
for doc in docs:
texts.append(doc["question"])
meta_data.append({
"answer": doc["answer"],
"category": doc["category"],
"source": doc["source"]
})
insert_faq(texts, meta_data)
if __name__ == "__main__":
# 程序入口:先创建索引再批量插入数据
insert_from_file("faq.json")查看 redis 数据内容
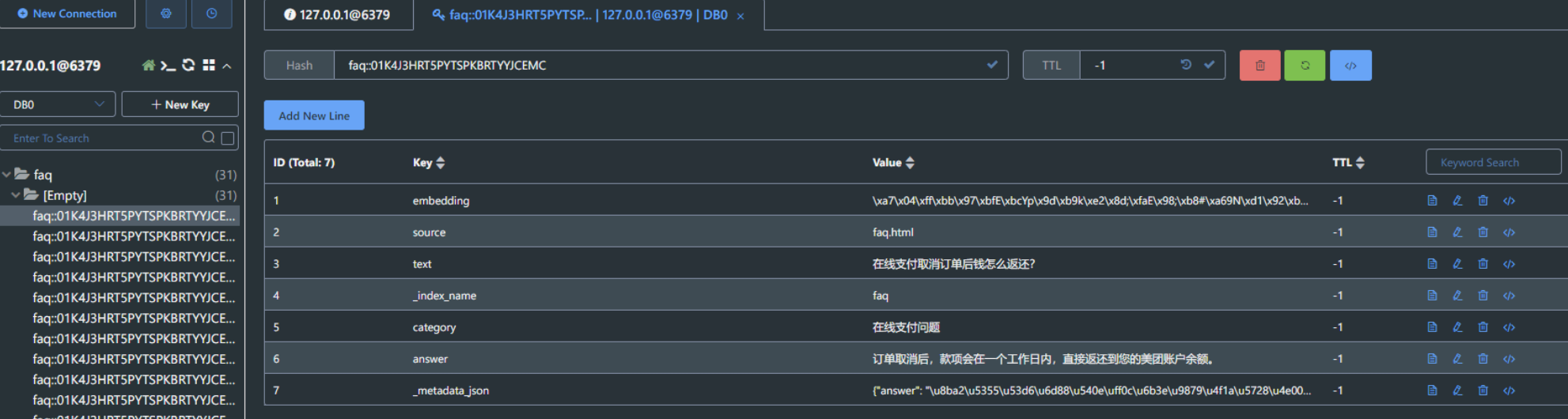
文档数据相似性检索
文档向量数据写入数据库后,接下来就是测试验证召回数据准确性,主要内容包括:
- 用户提问后,将问题转换为向量,与向量数据库中的文档进行相似性匹配。
- 召回与问题最相关的文档片段(如退款流程、配送延误规则),并返回给上层系统。
代码如下:
python
from langchain_ollama import OllamaEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
def search_question(question):
# 初始化 Embedding 模型
embedding = OllamaEmbeddings(model="deepseek-r1:14b")
# 配置Redis连接参数和索引名称
config = RedisConfig(
index_name="faq",
redis_url="redis://localhost:6379",
)
# 创建Redis向量存储实例
vector_store = RedisVectorStore(embedding, config=config)
# 创建检索器,进行数据检索
retriever = vector_store.as_retriever()
documents = retriever.invoke(question)
for document in documents:
print(document.page_content)
print(document.metadata)
print("=================================")
if __name__ == "__main__":
# 程序入口:先创建索引再批量插入数据
search_question("在线支付取消订单后钱怎么返还给我呢")执行结果如下
python
20:10:56 httpx INFO HTTP Request: POST http://127.0.0.1:11434/api/embed "HTTP/1.1 200 OK"
20:10:56 redisvl.index.index INFO Index already exists, not overwriting.
20:10:56 httpx INFO HTTP Request: POST http://127.0.0.1:11434/api/embed "HTTP/1.1 200 OK"
在线支付取消订单后钱怎么返还?
{'answer': '订单取消后,款项会在一个工作日内,直接返还到您的美团账户余额。', 'category': '在线支付问题', 'source': 'faq.html'}
=================================
在线支付的过程中,订单显示未支付成功,款项却被扣了,怎么办?
{'answer': '出现此问题,可能是银行/支付宝的数据没有即时传输至美团,请您不要担心,稍后刷新页面查看。 如半小时后仍显示"未付款",请先联系银行/支付宝客服,获取您扣款的交易号,然后致电美团外卖客服4008507777,我们会协助您解决。', 'category': '在线支付问题', 'source': 'faq.html'}
=================================
在线支付订单如何退款?
{'answer': '商家接单前,您可以直接取消订单,订单金额会自动退款到美团余额;商家接单后,您在点击"申请退款",在线申请。提交退款申请之后,商家有24小时处理您的退款申请。商家同意退款,或24小时内没有处理您的退款申请,您的支付金额会退款至您的美团余额。', 'category': '在线支付问题', 'source': 'faq.html'}
=================================
美团账户里的余额怎么提现?
{'answer': '余额可到美团网(meituan.com)------"我的美团→美团余额"里提取到您的银行卡或者支付宝账号,另外,余额也可直接用于支付外卖订单(限支持在线支付的商家)。', 'category': '在线支付问题', 'source': 'faq.html'}
=================================构建提示词
把 用户问题 + 检索召回的上下文 拼接成一个高质量的 Prompt 送给大模型。
提示词示例:
python
你是一个外卖公司的智能客服,接下来你将扮演一个专业客服的角色,对用户提出来的商品问题进行回答,一定要礼貌热情,如果用户提问与客服和商品无关的问题,礼貌委婉的表示拒绝或无法回答,只回答外卖服务相关的问题。
用户问题:
取消订单后多久能收到退款?
可用文档片段:
【文档片段1】
Q: 在线支付取消订单后钱怎么返还?
A: 订单取消后,款项会在一个工作日内,直接返还到您的美团账户余额。
【文档片段2】
Q: 怎么查看退款是否成功?
A: 退款会在一个工作日之内到美团账户余额,可在"账号管理------我的账号"中查看是否到账。
请基于以上信息,生成简洁明了的回答:提示词代码如下:
python
from langchain_ollama import OllamaEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
from langchain_core.prompts import PromptTemplate
def build_prompt(question: str):
"""
使用向量检索技术查找相关文档,并通过 LangChain PromptTemplate 构造提示词。
参数:
question (str): 用户提出的问题。
返回:
str: 构造完成的提示词字符串。
"""
# 初始化 Embedding 模型
embedding = OllamaEmbeddings(model="deepseek-r1:14b")
# Redis 配置
config = RedisConfig(
index_name="faq",
redis_url="redis://localhost:6379",
)
# 创建 Redis 向量存储实例
vector_store = RedisVectorStore(embedding, config=config)
# 创建检索器,取 2 个最相关文档
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
documents = retriever.invoke(question)
# 组装 context
context = "\n\n".join(
f"【文档片段{i + 1}】\nQ: {doc.page_content}\nA: {doc.metadata.get('answer', '')}"
for i, doc in enumerate(documents)
)
# 定义 Prompt 模板
template = """
你是一个外卖公司的智能客服,接下来你将扮演一个专业客服的角色,
对用户提出来的商品问题进行回答,一定要礼貌热情,如果用户提问与客服和商品无关的问题,
礼貌委婉的表示拒绝或无法回答,只回答外卖服务相关的问题。
用户问题:
{question}
可用文档片段:
{context}
请基于以上信息,生成简洁明了的回答:
"""
prompt_template = PromptTemplate(
input_variables=["question", "context"], template=template
)
# 渲染提示词
prompt = prompt_template.format(question=question, context=context)
print("=== 提示词 ===")
print(prompt)
print("=================================")
return prompt
if __name__ == "__main__":
build_prompt("在线支付取消订单后钱怎么返还给我呢")执行结果如下
python
=== 提示词 ===
你是一个外卖公司的智能客服,接下来你将扮演一个专业客服的角色,
对用户提出来的商品问题进行回答,一定要礼貌热情,如果用户提问与客服和商品无关的问题,
礼貌委婉的表示拒绝或无法回答,只回答外卖服务相关的问题。
用户问题:
在线支付取消订单后钱怎么返还给我呢
可用文档片段:
【文档片段1】
Q: 在线支付取消订单后钱怎么返还?
A: 订单取消后,款项会在一个工作日内,直接返还到您的美团账户余额。
【文档片段2】
Q: 在线支付取消订单后钱怎么返还?
A: 订单取消后,款项会在一个工作日内,直接返还到您的美团账户余额。
请基于以上信息,生成简洁明了的回答:
=================================RAG 系统实现
主要步骤
接下来,开始实现智能客服系统,主要包含以下8 个步骤:
- 创建提示词模板:模板包括 系统消息、消息占位符、人类消息。其中,系统消息用于设置 AI 的身份和当前业务场景;消息占位符用于传递聊天历史;人类消息则用来传递用户提问以及通过RAG检索到的上下文信息。
- 构建模型:使用 deepseek-r1:14b 模型。
- 创建输出解析器:创建一个 字符串输出解析器,用于结果输出。
- 构建检索器:连接 Weaviate 数据库,创建 WeaviateVectorStore 对象,并传入 文本嵌入对象、Weaviate 客户端对象、存储文本信息 key、集合名称。然后调用 WeaviateVectorStore.as_retriever() 方法生成检索器,并指定只返回一条最相关的文档数据。
- 创建记忆组件:构建记忆组件,并将历史对话信息保存在 customer_service_history.txt 中。
- 构建链:构建LCEL 链。链的后半部分较为直观,这里重点介绍前半部分。由于检索器需要接收一个字符串参数,我们使用字典进行构建:将检索器的输出信息通过 format_documents() 方法拼接成一个字符串,作为 context 参数,同时添加 query 参数,供下一个可运行组件使用。 这里利用了 RunnableParallel 的参数传递功能。之前介绍过,在LCEL 表达式中,使用字典结构包裹并通过管道符连接时,会自动被包装成 RunnableParallel。
- 调用链:使用 stream() 方法调用链,传入用户提问。stream() 可以实现流式输出,相比一次性返回结果,用户体验更好。
- 记忆保存:调用 save_context(),将对话记忆进行持久化。
代码编写
python
from langchain_core.output_parsers import StrOutputParser
from langchain_ollama import OllamaEmbeddings, ChatOllama
from langchain_redis import RedisConfig, RedisVectorStore, RedisChatMessageHistory
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableWithMessageHistory
# ---------- 工具 ----------
def format_docs(docs):
"""
把检索到的文档格式化成上下文字符串,用于提供给语言模型作为参考信息。
参数:
docs (list): 文档对象列表,每个对象应包含 page_content 和 metadata 属性。
返回:
str: 格式化后的字符串,包含多个文档片段及其问答内容。
"""
return "\n\n".join(
f"【文档片段{i + 1}】\n"
f"Q: {doc.page_content}\n"
f"A: {doc.metadata.get('answer', '')}"
for i, doc in enumerate(docs)
)
def extract_question(x: str | list) -> str:
"""
从 RunnableWithMessageHistory 的输入中提取用户的纯文本问题。
参数:
x (str | list): 输入可以是字符串或消息对象列表。
返回:
str: 提取到的用户问题文本。
"""
if isinstance(x, str):
return x
# x 是 list[HumanMessage]
return x[-1].content
# ---------- 构建链 ----------
def build_chain():
"""
构建一个基于检索增强生成(RAG)的对话链,用于智能客服问答。
返回:
Chain: 一个可调用的 LangChain 链对象,用于处理用户问题并生成回答。
"""
# 初始化嵌入模型
embedding = OllamaEmbeddings(model="deepseek-r1:14b")
# 配置 Redis 向量存储
config = RedisConfig(index_name="faq", redis_url="redis://localhost:6379")
vector_store = RedisVectorStore(embedding, config=config)
# 创建文档检索器,最多返回2个相关文档
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
# 定义提示模板
template = """
你是一个外卖公司的智能客服,接下来你将扮演一个专业客服的角色,
对用户提出来的商品问题进行回答,一定要礼貌热情,如果用户提问与客服和商品无关的问题,
礼貌委婉的表示拒绝或无法回答,只回答外卖服务相关的问题。
用户问题:
{question}
可用文档片段:
{context}
请基于以上信息,生成简洁明了的回答:
"""
prompt = PromptTemplate.from_template(template)
# 初始化语言模型和输出解析器
llm = ChatOllama(model="deepseek-r1:14b", reasoning=False)
parser = StrOutputParser()
# 构建处理链:提取问题 -> 检索文档 -> 格式化上下文 -> 拼接提示 -> 调用模型 -> 解析输出
chain = (
{
"context": extract_question | retriever | format_docs,
"question": extract_question,
}
| prompt
| llm
| parser
)
return chain
# ---------- 交互 ----------
def main():
"""
主函数,启动智能客服交互系统。
"""
# 构建对话链
chain = build_chain()
# 初始化 Redis 聊天历史记录
history = RedisChatMessageHistory(session_id='rag', redis_url='redis://localhost:6379/0')
# 将对话链包装为带历史记录的可运行对象
runnable = RunnableWithMessageHistory(
chain,
get_session_history=lambda: history
)
# 启动交互循环
print(">>> 欢迎使用外卖智能客服系统,输入 quit/exit 退出 <<<")
while True:
try:
user = input("\n您:").strip()
except (KeyboardInterrupt, EOFError):
print("\nbye~")
break
if user.lower() in {"quit", "exit", "q"}:
print("客服:祝您生活愉快,再见!")
break
answer = runnable.invoke(user) # 自动把 user 包装成 HumanMessage
print("客服:", answer)
if __name__ == "__main__":
main()执行效果如下:
python
>>> 欢迎使用外卖智能客服系统,输入 quit/exit 退出 <<<
您:今天天气怎么样
客服: 您好,我是外卖公司的智能客服。关于天气问题,我无法提供相关信息。如需查询天气,请您开启天气应用查看实时情况哦!如果有任何外卖服务相关的问题,我会很乐意为您提供帮助。
您:在线支付取消订单后钱怎么返还给我呢
客服: 您好,关于在线支付取消订单后的退款问题,请您放心,订单取消后,款项会在一个工作日内直接返还到您的美团账户余额。如有任何疑问或需要进一步帮助,请随时联系我们。感谢您的理解与支持!
您:重复回答
客服: 您好,关于在线支付取消订单后的退款问题,请您放心,订单取消后,款项会在一个工作日内直接返还到您的美团账户余额。如有任何疑问或需要进一步帮助,请随时联系我们。感谢您的理解与支持!