本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。

本项目旨在对微博文本进行六种情感类别(angry、happy、neutral、sad、surprise、fear)的自动分类。项目基于PyTorch与Hugging Face Transformers框架,使用BERT预训练模型(如 hfl/chinese-bert-wwm)对微博文本进行特征抽取,并通过微调得到可用于六分类任务的模型。相比传统的 RNN、LSTM 模型,BERT 等预训练模型能够更好地理解上下文语义,在情感分析任务上通常能取得更高的准确率和鲁棒性。
创新点
引入预训练语言模型 (PLM) 相较于传统的人工设计特征或纯 LSTM/RNN 模型,使用 BERT 这类大规模预训练语言模型能够更有效地捕捉中文文本的上下文关系及语义信息,在小规模标注数据上也能取得更好的泛化表现。
多类别情感分类 并非常见的二元或三元情感分类,而是涵盖了愤怒(angry)、开心(happy)、中性(neutral)、悲伤(sad)、惊讶(surprise)、恐惧(fear)六种情感类型,为更多下游微博情感场景(如舆情分析、用户态度监测等)提供了更细粒度的情感信息支持。
封装模型并保存 采用 Hugging Face Transformers 的 save_pretrained / from_pretrained 机制将训练好的模型本地化,方便后续直接调用,用于推理部署或整合到其他系统中。
数据集介绍
数据来源:本项目的数据来自微博文本,存储于 ./data/usual_train.csv 文件。其中包含两列:
文本:文本
情绪标签:情绪标签(取值为 angry, happy, neutral, sad, surprise, fear)
数据规模:到数万条微博。

数据示例:
数据划分:使用 train_test_split 将数据划分为:训练集(80%)、验证集(10%)、测试集(10%)。
训练集:用于模型训练
验证集:用于调整超参数、选择模型
测试集:用于最终评估模型的效果
模型网络结构介绍
预训练模型 - BERT
BERT(Bidirectional Encoder Representations from Transformers) 是由 Google 提出的双向 Transformer 语言模型,能够高效地建模文本上下文语义。本项目采用 BERT 进行特征提取,并基于其进行分类任务。
(1) 输入层
输入原始文本后,需要进行如下预处理:
分词(Tokenization):使用 BertTokenizer 进行 WordPiece 分词,将文本拆分成子词级别的 tokens。
映射(Encoding):将 token 映射为词汇表索引(input_ids),同时生成:
attention_mask:标识有效 token(1)和 padding token(0)。
token_type_ids(可选):用于区分句子 A/B,在单句子任务中通常为 0。
设输入文本为:
X=(x1,x2,...,xT)
其中,T 表示最大序列长度。经过 BertTokenizer 处理后,得到:
input_ids: I=(i1,i2,...,iT)
attention_mask: M=(m1,m2,...,mT)
token_type_ids: T=(t1,t2,...,tT)
最终输入格式:
X=(CLS,w1,w2,...,wn,SEP)
(2) BERT Encoder
BERT 由多层 Transformer Encoder 组成,每层由 自注意力机制(Self-Attention) 和 前馈神经网络(Feed-Forward Network, FFN) 组成。
① 自注意力机制(Self-Attention)
每个 Transformer 层使用 多头自注意力机制(Multi-Head Self-Attention, MHSA) 计算 token 之间的关系,计算公式如下:
Attention
(
Q
,
K
,
V
)
softmax
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(
d
k
QK
T
)V
其中:
Q=XWQ, K=XW, V=XW 分别是 Query、Key、Value 矩阵,
dkd_kdk 为注意力维度,
softmax 用于归一化权重。
最终,多头注意力(Multi-Head Attention) 形式为:
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
C
o
n
c
a
t
(
h
e
a
d
1
,
h
e
a
d
2
,
.
.
.
,
h
e
a
d
h
)
MultiHead(Q,K,V)=Concat(head1,head2,...,headh)
其中:
headi=Attention(QWQi,KWKi,VWVi)
② 前馈神经网络(FFN)
Transformer 的每层还包含一个两层的前馈神经网络:
FFN(x)=max(0,xW1+b1)
其中:
W1,W2,b1,b2为可训练参数。
BERT 由多个 Transformer 编码器堆叠组成,每一层都包含上述 自注意力 + FFN 结构。
最终,BERT 输出 最后一层隐藏状态:
H=(h1,h2,...,hT)∈RT×d
其中 d为隐藏状态维度(如 BERT-base 为 768)。
(3) CLS 池化与分类层
BERT 的第一个 token CLS 的向量 hCLS代表整个句子的上下文表示。我们对其进行池化并送入分类层:
线性变换:
Z=WhCLS+b
其中:
W∈Rd×CW \in \mathbb{R}^{d \times C}W∈Rd×C(可训练参数),
b∈RCb \in \mathbb{R}^{C}b∈RC(可训练参数),
CCC 为类别数(本任务中 C=6C = 6C=6)。
Softmax 激活 计算类别概率:
P(y∣X)=softmax(Z)=eZi∑j=1CeZjP(y | X) = \text{softmax}(Z) = \frac{e{Z_i}}{\sum_{j=1}{C} e^{Z_j}}P(y∣X)=softmax(Z)=∑j=1CeZjeZi
(4) 输出层
最终输出 logits 维度:
logits∈R(batch_size,6)\text{logits} \in \mathbb{R}^{(batch_size, 6)}logits∈R(batch_size,6)
每个类别的概率由 Softmax 计算得到:
y^=argmax(P(y∣X))\hat{y} = \arg\max (P(y | X))y^=argmax(P(y∣X))
训练与损失函数
(1) 交叉熵损失(Cross-Entropy Loss)
对于分类任务,损失函数使用 交叉熵(Cross-Entropy Loss):
L=−∑i=1CyilogP(yi∣X)\mathcal{L} = -\sum_{i=1}^{C} y_i \log P(y_i | X)L=−i=1∑CyilogP(yi∣X)
其中:
yiy_iyi 为真实类别的独热编码(one-hot vector),
P(yi∣X)P(y_i | X)P(yi∣X) 为预测类别的概率。
PyTorch 代码:
python
CopyEdit
import torch.nn.functional as F loss_fn = torch.nn.CrossEntropyLoss() loss = loss_fn(logits, labels)
训练流程
(1) 前向传播
python
CopyEdit
outputs = model(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids) logits = outputs.logits loss = loss_fn(logits, labels)
(2) 反向传播与优化
python
CopyEdit
optimizer.zero_grad() loss.backward() optimizer.step()
总结
BERT 作为预训练语言模型,通过 Transformer 结构 进行 上下文建模,利用 CLS 池化表示 进行分类,最终通过 Softmax 计算类别概率。训练时使用 交叉熵损失 并进行 梯度优化,实现高效的文本分类任务。
训练流程
损失函数:BERT 自带的 labels 输入会自动返回交叉熵损失 (CrossEntropyLoss)。
优化器:使用 AdamW 进行权重更新。
学习率调度器:采用线性预热与衰减 (get_linear_schedule_with_warmup)。
批训练:对每个 batch 计算损失,反向传播梯度并更新模型参数。
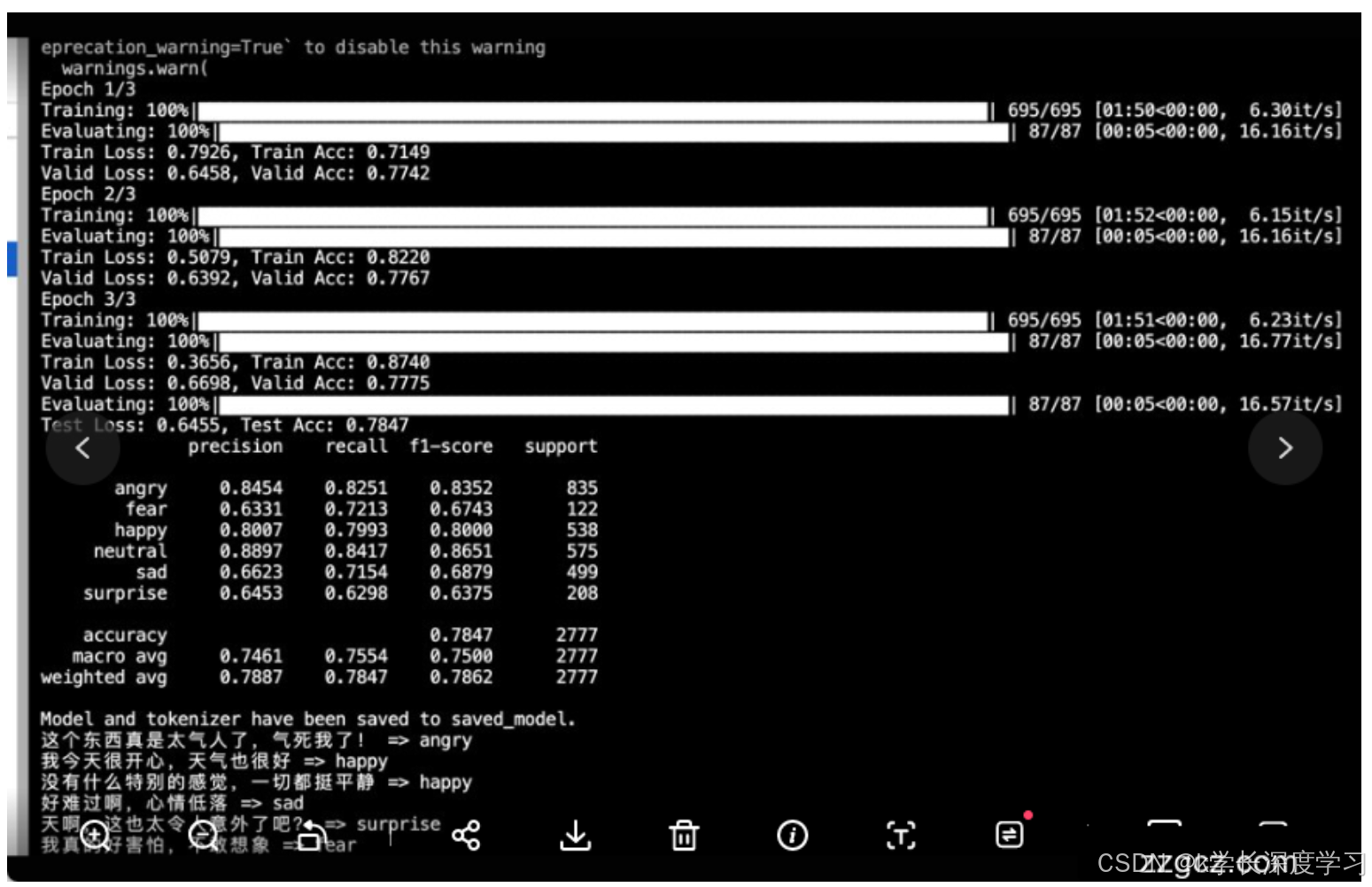
验证:在每个 epoch 结束后在验证集上评估模型,监控 loss 和 accuracy。
测试:在测试集上进行最终评估,报告 accuracy、F1 等指标。
改进方向
尝试更强大的预训练模型 在中文领域,可以选择 MacBERT、RoBERTa-wwm、ERNIE 等更适合中文的预训练模型;或者使用更大规模的中文预训练模型(如 hfl/chinese-roberta-wwm-ext)提高文本理解能力。
超参数调优
不同的批大小(batch size)
学习率(learning rate)及其衰减策略
训练轮次(epochs)
使用早停(Early Stopping)策略,监控验证集损失,及时停止训练以防过拟合。
数据增强与预处理
对微博文本使用文本清洗、表情符号与特殊符号的预处理。
使用同义词替换、随机插入等数据增强策略,提升模型鲁棒性。
多任务学习 / 联合学习 如果有相关任务(如情感强度分析、观点抽取等),可考虑多任务联合训练,让模型学习更丰富的语义表示。
知识蒸馏或模型量化 在需要部署到资源受限环境(移动设备、嵌入式平台)时,可以对模型进行蒸馏或量化,减小模型体积并加快推理速度。
本文来源:k学长的深度学习宝库,点击查看源码&详细教程。深度学习,从入门到进阶,你想要的,都在这里。包含学习专栏、视频课程、论文源码、实战项目、云盘资源等。