前言
在前两篇中,我们已经比较系统地梳理了 AI Agent 的发展历程,也对 AI Agent 和 AI Workflow 之间的区别做过一次完整的拆解,同时重点讲解了目前最经典、也是被讨论最多的 ReAct 模式。这一篇我们继续介绍另一个在工程实践中同样非常重要、并且经常和 ReAct 搭配使用的模式:Plan and Execute(简称 P&E)。
P&E 的核心思想其实并不复杂,本质就是一句话:先计划,再执行 。但正是这一步先计划,在很多真实场景中,往往会决定一个 Agent 系统最终能不能跑通。
如果你实际用过 ReAct,就会很容易遇到一个问题:一个标准的 ReAct Agent,几乎在每一轮都会把整个任务的执行过程和执行结果重新喂回给模型,从而让模型始终持有完整的上下文。这个机制在短任务中非常好用,但当任务本身无法在几步之内完成时,上下文就会持续膨胀,尤其是在涉及文件读写、长文本处理或者多轮工具调用的情况下,这种膨胀几乎是不可避免的。
从表面上看,模型的上下文窗口已经越来越大,128k 早已不是极限,200k 甚至 1M 的模型也已经出现。但在工程实践中,一个很现实的问题是:上下文变大,并不会线性提升效果,反而在很多情况下,会让模型更容易偏离最初的目标。当上下文中无关信息的比例不断上升时,信噪比会明显下降,模型对早期约束的关注度会逐渐被稀释,从而更容易出现目标偏移、遗漏约束,甚至产生不必要的幻觉。因此,在实际系统中,通常会尽量将单轮上下文控制在一个相对安全的范围内(例如 100k 左右?),避免无限逼近模型的上下文上限。
除了上下文规模的问题,在面对复杂任务、强约束任务时,ReAct 还存在一个常见的问题:对长期目标和多重约束的保持能力不足。比如下面这个需求,本身并不模糊,甚至可以说写得非常清楚:
请为我制定一份7天6晚的山水主题旅游计划,包含往返交通,总预算严格控制在10000元以内。
目的地需具备明显的山水景观,并避开旅游高峰期,请说明该地的最佳出行时间及是否需避开节假日。
行程安排需详细到每日景点顺序、活动建议与交通衔接,合理融合自然与人文体验。
同时,请结合目的地气候提供1月的温湿度、降水概率及相应穿衣指南,介绍当地重要的文化习俗、礼仪禁忌与特色美食,并给出预算分项估算、住宿区域建议、必备物品及安全提示。
希望整体计划注重可操作性,并适当体现地方特色。上面这个可以说是一个非常完整的提示词,但如果你真的让一个单 Agent、基于 ReAct 的模型去完整执行这个任务,执行到后半段时,往往会发现它开始只关注"最近正在生成的内容",而对前面提出的一些硬约束,比如预算上限、时间避峰、文化禁忌等,逐渐变得不那么敏感。最终的结果通常不是完全错误,而是只满足了一部分要求。
这里需要强调的是,这并不是 ReAct 本身的问题,而是当一个 Agent 同时承担全局目标管理和具体执行这两种职责时,在长链路任务中很容易顾此失彼。
这一点其实和我们自己做项目非常像。如果你接到一个稍微复杂一点的需求,一上来就直接开始写代码,哪怕经验再丰富,做到后面也很容易发现有些功能漏了、有些约束没对齐,甚至前后端和产品的理解并不完全一致。所以在真实的开发过程中,我们往往会先做一些看似"很浪费时间"的事,比如列 TODO、写方案、拆阶段目标,把整个任务先在脑子里走一遍。
P&E 模式,本质上就是把这种人类项目管理式的思考方式,显式地引入到了 Agent 系统中。
在 P&E 中,我们不再指望一个 Agent 从头到尾既想清楚全局、又把所有细节一次性做好,而是先让模型生成一份明确的执行计划,然后再让执行 Agent 按计划逐步完成。每一次执行,只需要关注当前这个子目标,而不需要同时背负所有约束。这也是 P&E 能够在长任务中显著提升稳定性的根本原因。
需要提前说明的一点是:P&E 本质上是一种控制和编排模式,而不是必须使用多个 Agent。你完全可以用同一个模型,通过不同的 system prompt 来分别扮演 Planner 和 Executor;是否拆成多 Agent,更多是工程层面的选择,而不是模式本身的前提。
当然,P&E 也不是没有代价。对于非常简单的任务,引入规划阶段本身就是额外开销,不管是 token 消耗还是系统复杂度,都会比直接用 ReAct 更高。因此,它更适合用在那些任务链路长、约束多、失败成本高的场景中。
Plan And Execute 模式
核心思想
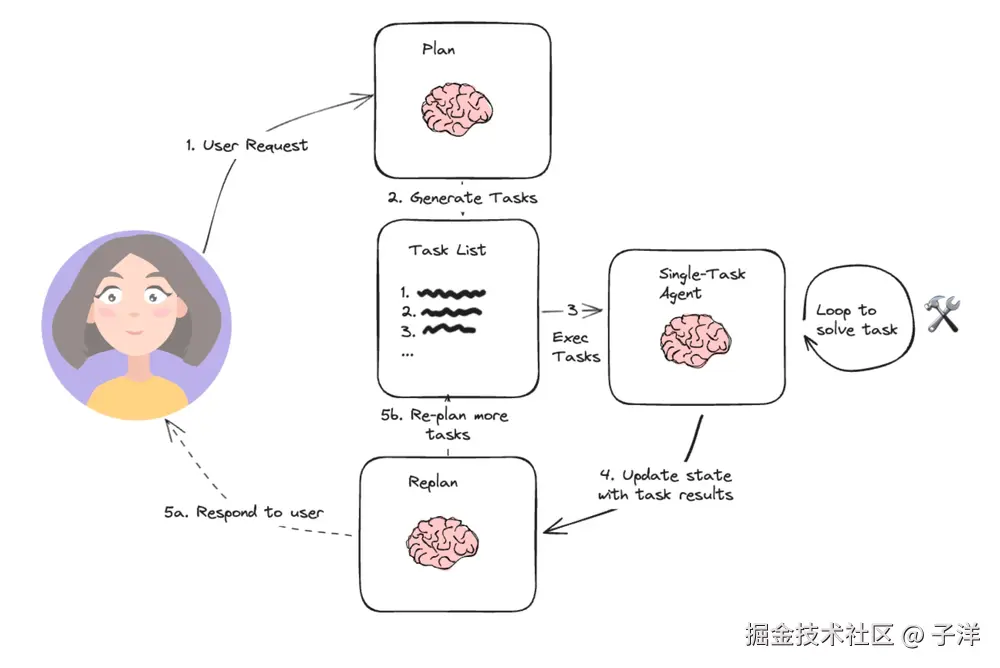
这张图来自 LangChain 博客,对 Plan and Execute 模式给出了一个非常工程化的抽象。从流程上看,它并没有试图强调模型怎么思考,而是把注意力放在任务是如何在不同阶段之间流转的:用户问题先进入规划阶段,被拆解成一组明确的步骤;随后这些步骤被依次交给执行模块处理;执行过程中持续产生中间结果,并由上层进行监控;一旦某一步失败,就会触发重新规划,再次回到 Plan 阶段。
我个人比较喜欢这张图的一点在于,它几乎完全是从系统视角出发的。你可以把它理解成一条控制流,而不是一段 Prompt 技巧。它回答的不是模型该怎么想,而是一个复杂任务在系统中应该如何被组织和调度。在实际工程中,这种视角往往比单纯讨论 prompt 更有价值。

相比之下,P&E 论文中的这张图关注点就不太一样了。它并不是在强调系统流程,而是在强调 Plan 本身的作用。图中可以看到,模型并不是一开始就直接进入逐步推理或执行,而是先生成一个高层次的计划结构,然后再围绕这个计划逐步完成任务。
这张图想表达的核心,其实是:通过显式的规划阶段,把原本隐含在模型推理过程中的全局结构提前抽象出来,从而减少执行阶段的负担。执行模型不需要时刻记住所有目标,只需要在当前步骤下,把事情做好即可。这也是为什么 P&E 在长任务、强约束任务中,往往比单纯依赖逐步推理的方式更加稳定。
如果说前一张图更像是在描述系统怎么跑 ,那这张图更像是在回答为什么要先规划。
核心实现
三层架构设计
在工程实现上,P&E 通常可以抽象为三个角色:规划、执行和监控。规划阶段负责生成一份高层次的 TODO 列表,它只关心要完成什么,而不关心具体怎么做;执行阶段负责完成每一个具体步骤,可以使用 ReAct,也可以使用其他形式的 Agent;监控阶段则负责判断执行是否成功,并在失败时触发重规划。
通过下面这段伪代码可以清晰地体现这一点:Plan Agent 只负责生成计划,Execute Agent 专注于执行当前步骤,而在失败时,会把失败上下文重新交给 Planner,让它生成一份新的、完整的计划。
JavaScript
// 1. 规划层 - 生成蓝图
async function generatePlan(task) {
// 提示词强调"做什么",而不是"怎么做"
const prompt = `你是一位项目经理,请将任务分解为3-6个可执行的步骤。
任务:${task}
要求:
- 每个步骤描述要达到的目标
- 不要描述具体实现细节
- 步骤间有逻辑顺序
输出格式:{ "steps": [{"step": "描述"}] }`;
return await llmGenerate(prompt);
}
// 2. 执行层 - 执行每个步骤(可用ReAct)
async function executeStep(step) {
// 对每个步骤使用ReAct执行
return await runReAct({ task: step.step });
}
// 3. 监控层 - 处理失败和重规划
async function monitorExecution(plan, results) {
for (let i = 0; i < plan.steps.length; i++) {
const result = results[i];
if (result.failed) {
// 触发重规划
const newPlan = await replan({
originalTask,
failedStep: plan.steps[i],
failureReason: result.error,
completedSteps: results.slice(0, i)
});
// 用新计划重新开始
return await executePlan(newPlan);
}
}
}重规划机制详解
RePlan 并不是简单地再生成一次计划,而是一次基于当前状态的条件规划。一个有效的 RePlan,至少需要考虑以下信息:哪些步骤已经成功完成、当前失败的具体步骤是什么、失败的原因或异常信息、是否需要改变执行顺序或策略等等,否则,模型很容易生成一个看似不同、实则重复失败路径的新计划。
JavaScript
async function replan(context) {
const prompt = `原任务:${context.originalTask}
执行情况:
- 已完成:${context.completedSteps.length}个步骤
- 失败步骤:${context.failedStep.step}
- 失败原因:${context.failureReason}
请生成新的计划,避免同样的失败。`;
// LLM会分析失败原因,调整后续步骤
const newPlan = await llmGenerate(prompt);
return {
...newPlan,
// 保留已成功的步骤
completedSteps: context.completedSteps
};
}具体实现
下面这份代码,是一个简化但逻辑完整的 P&E Agent 实现。但这里的实现更多是为了说明 P&E 的整体结构,而不是一个可以直接在生产环境使用的最终方案。在真实系统中,通常还需要对重规划次数、token 预算以及最终 Summary 阶段的幻觉风险进行更严格的控制。
不过,即便如此,这个实现已经完整覆盖了 P&E 的核心流程,也很好地展示了 Planner、Executor 和 RePlanner 之间的职责边界。
P&E 主逻辑
js
import { llmGenerate } from "../llm/provider.js";
import { runReAct } from "./react-agent.js";
const SYSTEM = `You are a professional Planner in a Plan-and-Execute agent architecture.
Your responsibility is to analyze the user's task and produce a clear, minimal,
and executable high-level plan.
Rules and constraints:
- You ONLY generate the plan. You do NOT execute any step.
- You MUST NOT call tools or mention tool names.
- You MUST NOT describe implementation details or low-level actions.
- Each step should describe WHAT needs to be achieved, not HOW it is done.
- Steps must be logically ordered and independent when possible.
- Prefer fewer, clearer steps (3--6 steps).
- Each step should be actionable, unambiguous, and verifiable by an executor.
Output format (strict JSON only):
{
"steps": [
{ "step": "..." }
]
}
Do not include any explanation, commentary, or extra text outside the JSON.`;
export async function planAndExecute({
task,
options = {},
replanOnFailure = true,
availableTools,
} = {}) {
const { text } = await llmGenerate({
system: SYSTEM,
prompt: `Task: ${task}`,
});
let plan;
try {
plan = JSON.parse(text);
console.log("Plan:\n", plan);
} catch (e) {
return { final: "Plan parse failed", error: String(e), raw: text };
}
const trace = [];
for (const [idx, s] of plan.steps.entries()) {
const reactRes = await runReAct({ task: s.step, maxLoops: 10 });
const observation = reactRes.final
? { ok: true, message: reactRes.final }
: { ok: false, error: "No final from ReAct" };
trace.push({
idx: idx + 1,
step: s.step,
observation,
reactTrace: reactRes.trace,
});
if (replanOnFailure && !observation.ok) {
const replanPrompt = `Original task:
${task}
The previous plan failed.
Failure details:
- Failed step index: ${idx + 1}
- Failed step description: ${s.step}
- Observation at failure:
${JSON.stringify(observation)}
Execution trace so far:
${JSON.stringify(reactRes.trace || [])}
Your task:
Generate a revised plan that resolves the failure and allows the task to complete successfully.
Output requirements:
- Respond with a single valid JSON object only
- Do NOT include any explanations, comments, or Markdown
- The JSON must represent a complete revised plan, not a partial patch
- The revised plan must avoid repeating the failed step in the same form
Return JSON only.`;
const { text: newPlanText } = await llmGenerate({
system: SYSTEM,
prompt: replanPrompt,
});
try {
const newPlan = JSON.parse(newPlanText);
plan = newPlan;
console.log("New Plan:\n", newPlan);
return await planAndExecute({
task,
options,
replanOnFailure,
availableTools,
});
} catch (e) {
trace.push({
idx: idx + 1,
step: "REPLAN_FAILED",
error: String(e),
raw: newPlanText,
});
}
}
}
const summaryPrompt = `Given the plan execution trace, summarize final result for task: ${task}.\nTRACE:\n${JSON.stringify(trace, null, 2)}`;
const { text: final } = await llmGenerate({
system: "Summarizer",
prompt: summaryPrompt,
});
return { final, plan, trace };
}结语
这篇文章里介绍的 P&E 模式,本质上并不是某种 更高级 的 Agent,而是我们在工程实践中,为了解决长任务和复杂约束问题,总结出来的一种更稳妥的组织方式。不同的模式并不存在绝对的优劣,更多是取决于你面对的是什么样的问题。
原本我是打算下一篇继续写 Reflexion 模式的,但最近有一些其他事情要做,也有一些目前更感兴趣的方向,比如 Spec Coding、Agent Skill、Mem0 这一类的技术,再加上 25 年 Qwen 团队在 NeurIPS 上获得最佳论文的关于门控注意力机制的研究,也都值得花时间去看一看。Agent 这条线本身还远没有收敛到一个稳定范式,有太多东西值得慢慢拆、慢慢写,所以这部分内容就先告一段落,后面有时间再继续展开。
上面的实现代码已经开源在 GitHub,可以下载到本地进行运行调试 github.com/Alessandro-...