关键词:空间权重矩阵、回归建模、随机森林/XGBoost、MaxEnt、GWR/MGWR、地图对比
"空间关系建模"工具集 适用场景:你不仅想知道"有没有空间聚集",更想回答------哪些因素在驱动空间现象?这种关系在不同地方会不会不一样?两张分区图到底像不像?
1. "空间关系建模(Modeling Spatial Relationships)"工具集到底解决什么问题?
在 ArcGIS Pro 的空间统计里,"空间关系建模(Modeling Spatial Relationships)"是一组用来量化变量关系的工具:
- 一类是"把空间关系写进模型"(比如 OLS/GLR/GWR/MGWR);
- 一类是"把邻接关系定义清楚"(Generate Spatial Weights Matrix / Generate Network Spatial Weights);
- 一类是"用机器学习做预测并解释变量作用"(Forest-based & Boosted Classification and Regression);
- 还有一些专门回答"点与点是否协同出现""两张分区图有多像"等问题的工具。
你可以把它理解为:从"看图说话"升级到"能算、能解释、能预测"。
2. 快速上手前的 3 个准备
2.1 统一投影与空间尺度
- 尽量把数据投影到适合的平面坐标系(米/千米),避免用经纬度直接跑距离。
- 多数模型对"空间尺度"很敏感:邻域设 500m vs 5km,结果可能完全不同。
2.2 先想清楚"邻居"怎么定义(空间权重矩阵)
空间统计里很多工具都需要"谁和谁算邻居"。ArcGIS 用 .swm 文件保存这种关系;你可以自己生成,也可以让工具默认用最近邻。
3. 工具清单
路径提示:Geoprocessing(地理处理)→ Toolbox → Spatial Statistics Tools → Modeling Spatial Relationships
| 工具 | 一句话用途 |
|---|---|
| 协同区位分析(Colocation Analysis) | 两类点要素在局部范围内是否"更容易一起出现" |
| 探索性回归(Exploratory Regression) | 在一堆候选解释变量里,自动筛出"更合格"的 OLS 组合 |
| 基于森林的分类与回归(Forest-based & Boosted...) | 用随机森林或 XGBoost 建模预测,并给出变量重要性等解释信息 |
| 广义线性回归(GLR) | 一套工具兼容连续(OLS)、二元(Logistic)、计数(Poisson)回归 |
| 生成网络空间权重(Generate Network Spatial Weights) | 用路网距离/时间/成本来定义"邻居"并输出 .swm |
| 生成空间权重矩阵(Generate Spatial Weights Matrix) | 用距离带、K 近邻、面邻接等方式生成 .swm |
| 地理加权回归(GWR) | 关系随空间变化:给每个位置拟合"本地回归" |
| 局部二元关系(Local Bivariate Relationships) | 用局部熵识别两变量在不同地方的关系类型(线性/凹/凸/复杂) |
| 多比例地理加权回归(MGWR) | 比 GWR 更进一步:不同解释变量可以有不同作用尺度 |
| 普通最小二乘(OLS) | 全局线性回归:一套系数解释整个研究区(常作为起点) |
| 仅存在预测(Presence-only Prediction / MaxEnt) | 只有"出现点",没有"缺失点"时,用 MaxEnt 做出现概率面 |
| 区域之间的空间关联(Spatial Association Between Zones) | 两张分区/分区图层到底有多"对齐"(0~1) |
4. 每个工具:通俗解释 + 案例 + 操作要点
4.1 协同区位分析(Colocation Analysis)
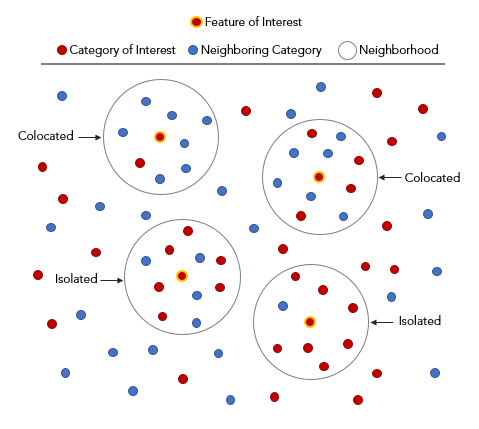
它回答的问题:
A 类点(例如"共享单车停放点")在某个邻域内,是否比随机情况下更倾向于出现在 B 类点(例如"地铁出入口")附近?它用 colocation quotient 度量这种"协同出现"。
案例:
城市治理想判断:投诉点 是否更容易出现在夜市/餐饮点附近(用于夜间巡查布点)。
怎么做(ArcGIS Pro 操作思路):
- 准备两类点图层(可以是一个点图层里用"类别字段"区分,也可以是两个点图层)。
- 打开工具:
Colocation Analysis - 关键参数:
- Category of Interest / Neighboring Category(或输入图层与类别字段)
- Neighborhood:用"距离阈值"或"最近邻数量"定义邻域
- 可选:如果有时间字段,可设置空间-时间窗口(做"同一时段是否协同出现")
- 输出解读:
- 重点看 colocation quotient 值 与 p-value:值越大且显著,协同越强。
常见坑:
- 距离阈值选得太大,所有点都成邻居,结果会"被稀释";太小则容易没统计意义。建议先用业务常识给一个合理半径,再做敏感性对比。
4.2 探索性回归(Exploratory Regression)
它回答的问题:
当你有 10~30 个候选解释变量,想做 OLS,却不知道用哪几个更"合格",它会穷举变量组合,筛出满足你设定诊断阈值的模型,并且(在满足阈值后)会对残差做 Moran's I 检查是否仍聚集。
案例:
你要解释"社区层面噪声投诉量(或噪声指数)",候选变量有:道路密度、餐饮 POI 密度、绿地率、人口密度、夜间灯光、建筑密度等------让工具自动帮你找"更靠谱"的变量组合。
怎么做(操作思路):
-
Exploratory Regression -
设置:
- Dependent Variable(因变量,连续数值)
- Candidate Explanatory Variables(候选解释变量列表)
- 诊断阈值:最小 Adj-R²、最大 p-value、最大 VIF、最小 Jarque--Bera p-value 等
- 可选:输入
.swm(用于残差空间自相关检验);不提供时默认用最近邻(如 8 邻居)进行检查
-
输出:
- 结果表会列出通过筛选的模型组合,以及各项诊断指标。
常见坑:
- 候选变量过多时组合爆炸,运行会很慢:建议先做相关性筛查/理论筛查,把变量压到"可解释的最小集合"。
text
https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/exploratory-regression.htm4.3 基于森林的分类与回归(Forest-based & Boosted Classification and Regression)
它回答的问题:
用随机森林或**XGBoost(梯度提升树)**做监督学习:
- 既能做回归(预测连续值),也能做分类(预测类别);
- 支持训练、预测到要素、预测到栅格等模式;并提供变量重要性等解释输出。
案例:洪涝易发区预测(回归/分类都行)
- 因变量(要预测):历史积水深度(回归)或"是否积水(0/1)"(分类)
- 解释变量:地形(坡度/高程)、距河道、下垫面不透水率、道路密度、排水设施密度、降雨强度等(字段或栅格抽样后字段)
怎么做(操作思路):
-
Forest-based and Boosted Classification and Regression -
关键参数:
- Model Type:Forest-based / Gradient boosted(RF vs XGBoost)
- Prediction Type:Train only(先看效果)/ Predict to features / Predict to raster
- Explanatory variables:可来自字段、栅格、距离要素等
-
解读:
- 先关注验证指标(误差/准确率等),再看变量重要性与响应曲线(理解"谁更关键、影响方向如何")。
常见坑:
- 样本不平衡(例如"积水=1"太少)会让分类偏置;建议做样本均衡或分层抽样(新版本里还有"Prepare Data for Prediction / Evaluate Predictions with Cross-validation"等可配合使用,见文末补充)。
工具页(可截屏参数面板):
text
https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/forestbasedclassificationregression.htm4.4 广义线性回归(GLR)
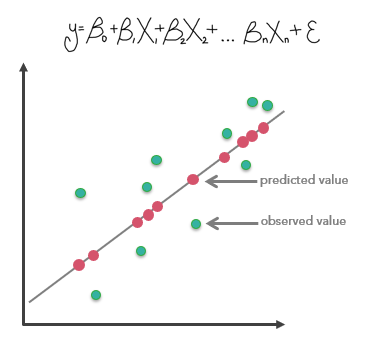
它回答的问题:
一套 GLR 工具里可以拟合:
- 连续型(相当于 OLS)
- 二元型(Logistic)
- 计数型(Poisson)
案例:交通事故"是否发生"预测(Logistic)
以道路网格为单位,因变量为"过去一年是否发生事故(0/1)",解释变量为车流量、路口密度、限速、照明、雨天比例等。
怎么做(操作思路):
-
Generalized Linear Regression -
关键参数:
- 选择模型类型(连续/二元/计数)
- 设置因变量字段与解释变量字段
-
输出解读:
- 看系数符号与显著性(p-value),以及整体拟合指标;如果是二元/计数,还要关注是否存在过度离散、异常点等。
常见坑:
- 计数模型要求因变量为非负整数;二元模型要求 0/1 编码干净,否则很容易报错或结果奇怪。
工具页:
text
https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/generalized-linear-regression.htm4.5 生成网络空间权重(Generate Network Spatial Weights)
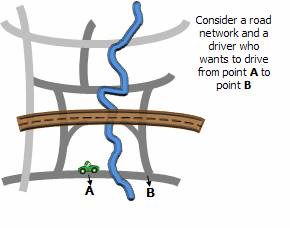
它回答的问题:
有些"邻近"不是直线距离,而是路网通达时间/路网距离/通行成本 。这个工具用 Network Dataset 构建 .swm,把邻居关系定义在网络上。
案例:急救站点服务圈的"可达邻居"
你想用"10 分钟车程内的站点互为邻居",再把这个 .swm 用于后续统计或模型。
怎么做(操作思路):
-
准备 Network Dataset(道路网络,含速度/时间阻抗)
-
Generate Network Spatial Weights -
设置:
- Input Features(通常是点:站点/事件)
- Network Dataset
- Impedance(距离/时间/成本)
- 阈值(如 10 分钟)
-
输出
.swm:可被多种空间统计工具直接调用。
注意点:
- 工具会把要素投影到网络数据集的空间参考;不要指望它遵从"输出坐标系环境"。
工具页:
text
https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/generate-network-spatial-weights.htm4.6 生成空间权重矩阵(Generate Spatial Weights Matrix)
它回答的问题:
把"谁是谁的邻居"写成 .swm,常用方式包括:距离阈值、K 近邻、面邻接(Queen/Rook)等;并且 .swm 采用稀疏矩阵存储以节省资源。
案例:街道(面)尺度的邻接关系
你要做街道尺度的残差 Moran's I 或热点分析,希望邻居按"共享边界(Rook)或共享边界/角点(Queen)"定义。
怎么做(操作思路):
-
Generate Spatial Weights Matrix -
参数:
- Input Feature Class(点/面均可)
- Unique ID Field
- Conceptualization of Spatial Relationships(选邻接或距离等)
- Row Standardization(是否行标准化,影响权重归一)
-
输出
.swm:后续给 Moran's I、Gi*、Local Moran's I 等工具使用。
工具页:
text
https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/generate-spatial-weights-matrix.htm4.7 地理加权回归(GWR)
它回答的问题:
OLS 给你一组"全局系数";但现实里很多关系是"到不同地方就变了"。GWR 会对每个位置拟合一个局部回归,让系数随空间变化。
案例:PM2.5 与交通/工业的关系是否因地而异
- 因变量:PM2.5 年均值
- 解释变量:道路密度、工业用地比例、风速、绿地率等
你想知道:在城市核心区"道路密度"的系数是否更大?
怎么做(操作思路):
- 建议优先使用 ArcGIS Pro 的"增强版" GWR 工具页面(非 legacy),并设置邻域类型与带宽选择方法。
- 输出后常做三件事:
- 地图上制图:各解释变量的局部系数 、局部R²
- 看残差是否仍有空间自相关(如果有,说明还缺机制或尺度不对)
- 对比 OLS:GWR 是否显著改善拟合或解释力
常见坑:
- 样本量太小或邻域太窄会导致系数不稳定;面要素如果用质心算距离,形状复杂时邻居会"看起来不合理"。
工具页(增强版说明见 how works):
text
https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/how-geographicallyweightedregression-works.htm4.8 局部二元关系(Local Bivariate Relationships)
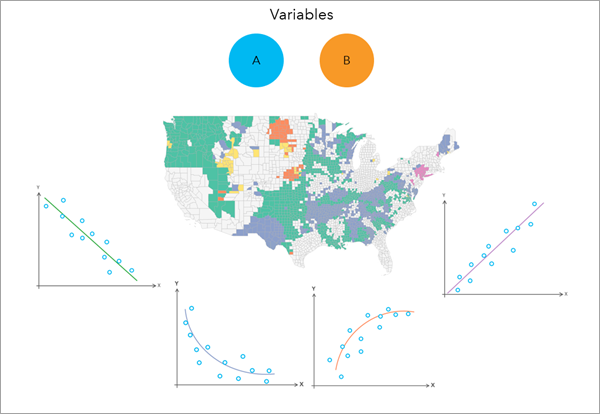
它回答的问题:
它不是传统相关系数,也不是只能抓线性关系的回归,而是用局部熵判断两变量在不同地方是否显著相关,并把关系分成 6 类:
- Not Significant
- Positive Linear / Negative Linear
- Concave / Convex
- Undefined Complex(显著相关但形态难以归类)
案例:地表温度(LST)与 NDVI 的关系在城市/郊区是否不同
在城市核心区可能是强负线性,在山地/水系附近可能出现更复杂的非线性。
怎么做(操作思路):
-
Local Bivariate Relationships -
输入:点或面都行,但变量必须是连续型,不适合二元/类别数据。
-
关键参数:
- Dependent Variable / Explanatory Variable(不确定就互换跑两次,关系类型可能变化)
- Number of Neighbors(局部邻域大小)
- Number of Permutations(置换次数)
- Apply FDR Correction(多重检验控制假阳性)
-
输出:一张"关系类型分区图",并且弹窗可看局部散点图。
工具页:
text
https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/localbivariaterelationships.htm4.9 多尺度地理加权回归(MGWR)
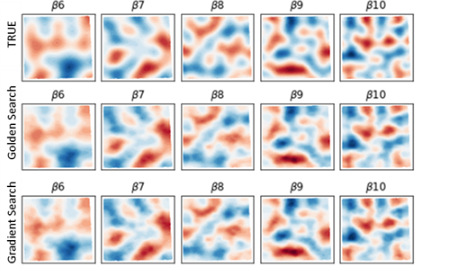
它回答的问题:
GWR 默认"所有解释变量共享同一个带宽/尺度";MGWR 允许不同解释变量有不同作用尺度(有的更局地,有的更区域)。
案例:房价的驱动因素作用尺度不同
- 距地铁:强局地
- 学区资源:中尺度
- 城市整体产业结构:大尺度
MGWR 会告诉你这些变量各自更像"局部机制"还是"区域机制"。
怎么做(操作思路):
-
Multiscale Geographically Weighted Regression (MGWR) -
核心解读点:
- 每个解释变量对应的带宽/邻域大小(尺度信息)
- 局部系数面与不确定性
-
若你需要输出系数栅格,可能需要更高许可。
工具页:
text
https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/multiscale-geographically-weighted-regression.htm4.10 普通最小二乘(OLS)
它回答的问题:
OLS 是最常见的回归,也是很多空间回归分析的起点:给出一个全局方程来解释/预测整个研究区。
案例:解释"街区犯罪率"
因变量:街区犯罪率;解释变量:人口密度、酒吧密度、路网密度、照明覆盖等。
怎么做(操作思路):
Ordinary Least Squares (OLS)- 常看四类输出:
- 系数与显著性(p-value)
- 共线性(VIF)
- 残差正态性(Jarque-Bera)
- 残差是否还存在空间聚集(若有,说明模型缺空间结构或遗漏变量)
提醒:ArcGIS Pro 里 GLR 已经包含 OLS 的能力,很多时候你可以直接用 GLR 做连续模型。
工具页:
text
https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/ordinary-least-squares.htm4.11 仅存在预测(Presence-only Prediction / MaxEnt)
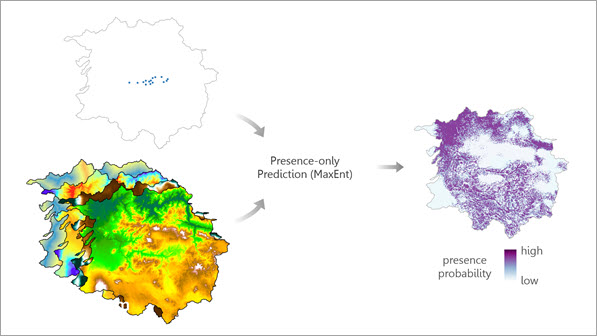
它回答的问题:
很多生态/风险问题只有"出现点"(例如物种目击点、病虫害发现点、滑坡点),但没有"没出现"的可靠样本。MaxEnt 用已知出现点、研究区与解释变量来估计"出现概率面"。
案例:野生动物栖息地适宜性(经典用法)
- 出现点:相机陷阱拍到的物种点位
- 解释变量:海拔、坡度、距水体、植被指数、土地覆盖等(多为栅格)
- 输出:全域"出现概率/适宜性"栅格(0~1)
怎么做(操作思路):
Presence-only Prediction (MaxEnt)- 三个核心输入:出现点、研究区、解释变量。
- 输出解读:
- 概率栅格(适宜性分布)
- 响应曲线表(类似"单变量的边际影响/部分依赖")
工具页:
text
https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/presence-only-prediction.htm4.12 区域之间的空间关联(Spatial Association Between Zones)
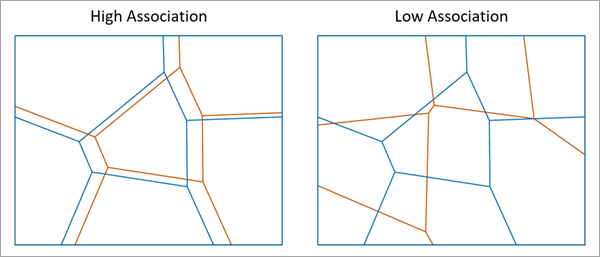
它回答的问题:
你有两张"分区图"(同一区域的两种分类/分区结果),想知道它们到底有多像。工具会输出一个 0~1 的全局空间关联值:越接近 1 越一致。
案例:对比"旧版土地利用分区"与"新版国土空间规划分区"
- 输入:两套分区(面或栅格分区都可)
- 输出:整体相似度 + 分区对应关系表(哪些区域主要对应到哪些类别)
怎么做(操作思路):
-
Spatial Association Between Zones -
设置:
- Input Zones(分区A)+ 分区字段
- Overlay Zones(分区B)+ 分区字段
-
输出解读:
- Global Measure(0~1)
- 还能看"某个分区内部主要被分到哪些类别"(做结构变化诊断特别方便)。
工具页:
text
https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/spatial-association-between-zones.htm5. 一个更"完整"的推荐工作流(避免跑完不知道怎么用)
(1)先定义空间邻居
- 距离/邻接:Generate Spatial Weights Matrix
- 通达时间:Generate Network Spatial Weights
(2)先跑全局模型做基线
- 连续:OLS 或 GLR(continuous)
- 二元/计数:GLR(logistic/Poisson)
(3)再判断是否需要"局部模型"
- 如果你怀疑机制因地而异:GWR / MGWR
- 如果关系可能是非线性的:Local Bivariate Relationships(先看形态)
(4)如果目标是预测
- 用 Forest-based/XGBoost 或 MaxEnt(取决于是否有缺失样本)
- 强烈建议做交叉验证与空间分组验证(避免"看起来很准其实是空间泄漏")
6. 补充:新版本 Pro(latest)里,这个工具集还有哪些"更全"的扩展?
如果你用的是较新的 ArcGIS Pro 版本,在该工具集中还可能看到:
- Bivariate Spatial Association (Lee's L) 双变量空间关联(Lee 的 L)
- Predict Using Spatial Statistics Model File 使用空间统计模型文件进行预测
- Prepare Data for Prediction 为预测准备数据
- Evaluate Predictions with Cross-validation 使用交叉验证评估预测结果
- Causal Inference Analysis 因果推断分析
这些更偏"预测流程规范化"和"因果推断"